 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Novel Decision Tree for Depression Recognition in Speech
Feb 22, 2020
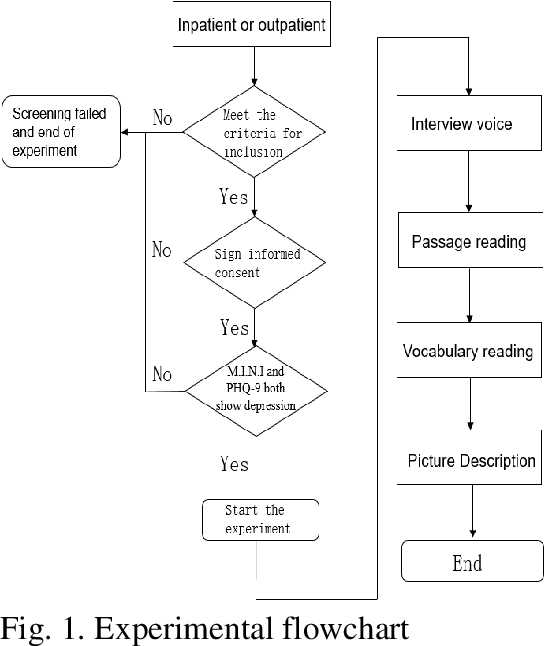
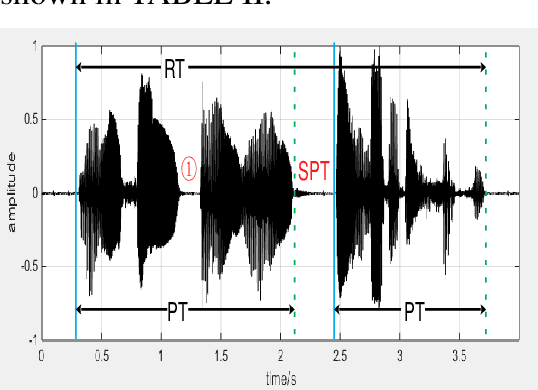
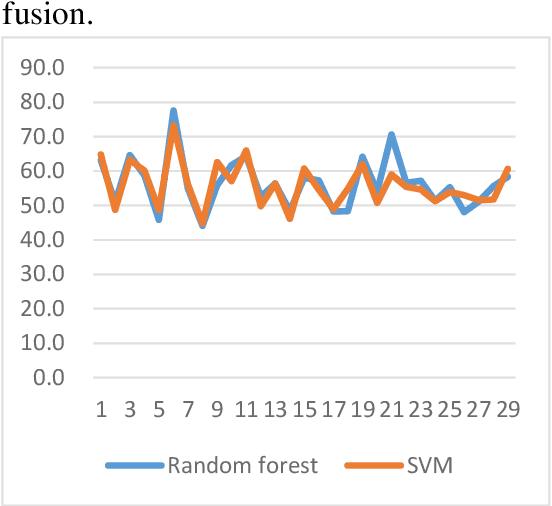
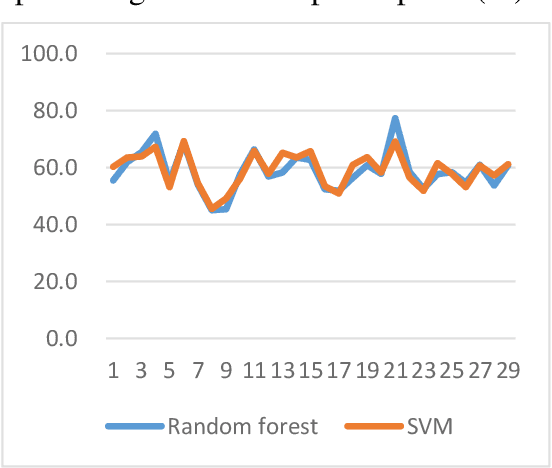
Depression is a common mental disorder worldwide which causes a range of serious outcomes. The diagnosis of depression relies on patient-reported scales and psychiatrist interview which may lead to subjective bias. In recent years, more and more researchers are devoted to depression recognition in speech , which may be an effective and objective indicator. This study proposes a new speech segment fusion method based on decision tree to improve the depression recognition accuracy and conducts a validation on a sample of 52 subjects (23 depressed patients and 29 healthy controls). The recognition accuracy are 75.8% and 68.5% for male and female respectively on gender-dependent models. It can be concluded from the data that the proposed decision tree model can improve the depression classification performance.
A Comparison of Discrete Latent Variable Models for Speech Representation Learning
Oct 24, 2020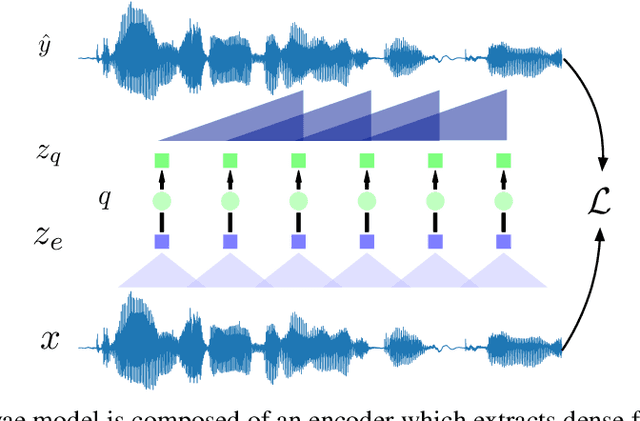
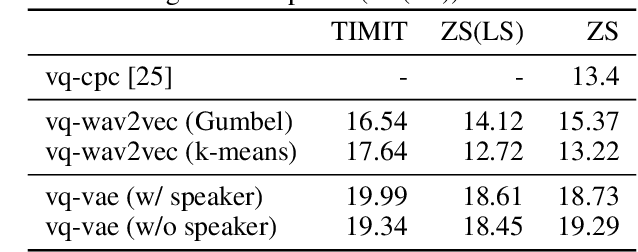
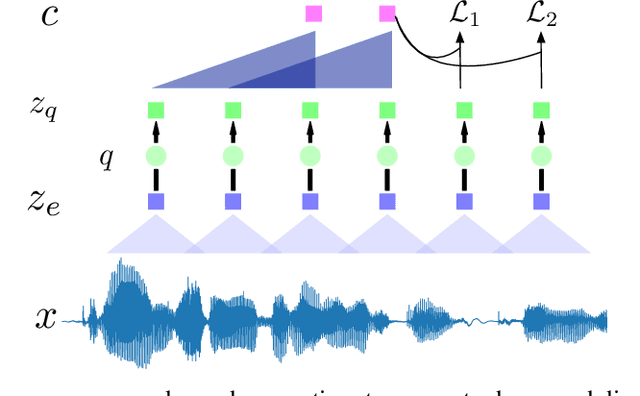
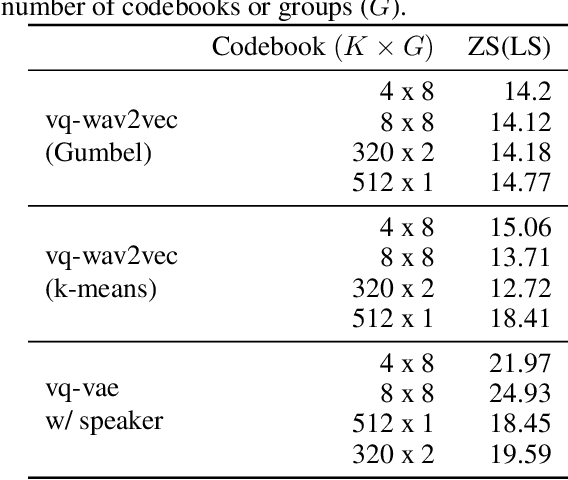
Neural latent variable models enable the discovery of interesting structure in speech audio data. This paper presents a comparison of two different approaches which are broadly based on predicting future time-steps or auto-encoding the input signal. Our study compares the representations learned by vq-vae and vq-wav2vec in terms of sub-word unit discovery and phoneme recognition performance. Results show that future time-step prediction with vq-wav2vec achieves better performance. The best system achieves an error rate of 13.22 on the ZeroSpeech 2019 ABX phoneme discrimination challenge
Who Needs Words? Lexicon-Free Speech Recognition
Apr 09, 2019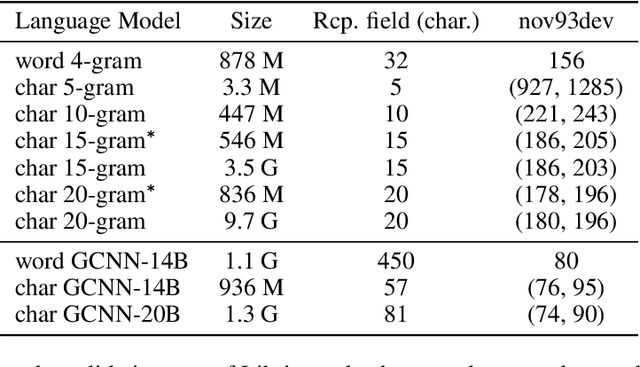
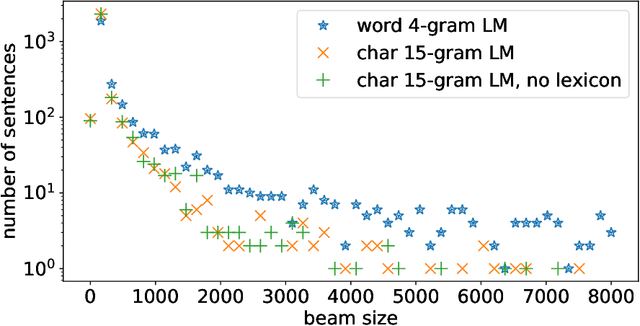
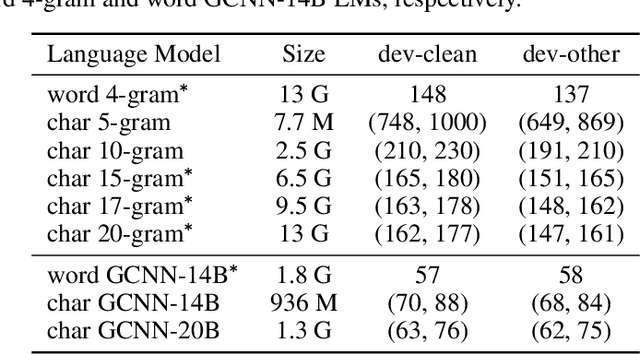
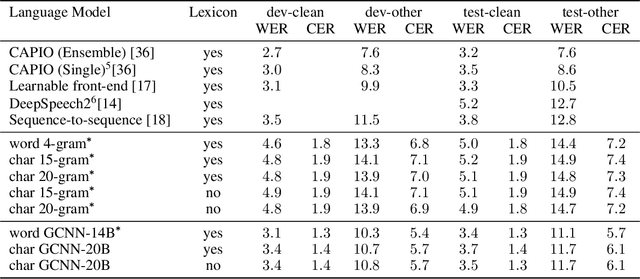
Lexicon-free speech recognition naturally deals with the problem of out-of-vocabulary (OOV) words. In this paper, we show that character-based language models (LM) can perform as well as word-based LMs for speech recognition, in word error rates (WER), even without restricting the decoding to a lexicon. We study character-based LMs and show that convolutional LMs can effectively leverage large (character) contexts, which is key for good speech recognition performance downstream. We specifically show that the lexicon-free decoding performance (WER) on utterances with OOV words using character-based LMs is better than lexicon-based decoding, both with character or word-based LMs.
Joint AEC AND Beamforming with Double-Talk Detection using RNN-Transformer
Nov 09, 2021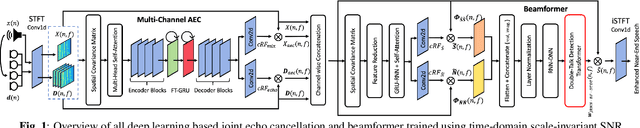
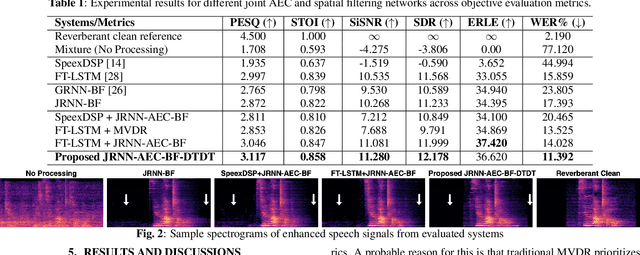
Acoustic echo cancellation (AEC) is a technique used in full-duplex communication systems to eliminate acoustic feedback of far-end speech. However, their performance degrades in naturalistic environments due to nonlinear distortions introduced by the speaker, as well as background noise, reverberation, and double-talk scenarios. To address nonlinear distortions and co-existing background noise, several deep neural network (DNN)-based joint AEC and denoising systems were developed. These systems are based on either purely "black-box" neural networks or "hybrid" systems that combine traditional AEC algorithms with neural networks. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. Furthermore, we propose a double-talk detection transformer (DTDT) module based on the multi-head attention transformer structure that computes attention over time by leveraging frame-wise double-talk predictions. Experiments show that our proposed method outperforms other approaches in terms of improving speech quality and speech recognition rate of an ASR system.
A Review of Language and Speech Features for Cognitive-Linguistic Assessment
Jun 04, 2019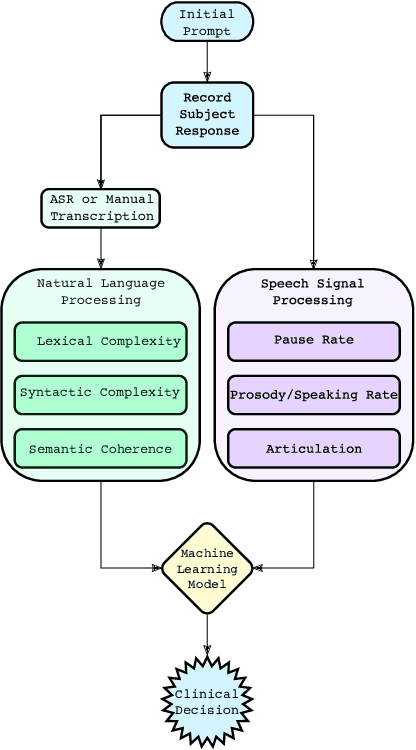

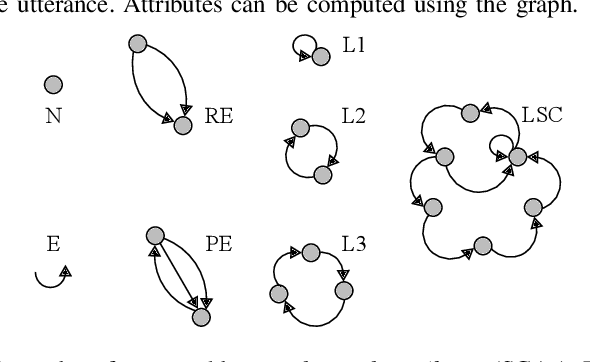
It is widely accepted that information derived from analyzing speech (the acoustic signal) and language production (words and sentences) serves as a useful window into the health of an individual's cognitive ability. In fact, most neuropsychological batteries used in cognitive assessment have a component related to speech and language where clinicians elicit speech from patients for subjective evaluation across a broad set of dimensions. With advances in speech signal processing and natural language processing, there has been recent interest in developing tools to detect more subtle changes in cognitive-linguistic function. This work relies on extracting a set of features from recorded and transcribed speech for objective assessments of cognition, early diagnosis of neurological disease, and objective tracking of disease after diagnosis. In this paper we provide a review of existing speech and language features used in this domain, discuss their clinical application, and highlight their advantages and disadvantages. Broadly speaking, the review is split into two categories: language features based on natural language processing and speech features based on speech signal processing. Within each category, we consider features that aim to measure complementary dimensions of cognitive-linguistics, including language diversity, syntactic complexity, semantic coherence, and timing. We conclude the review with a proposal of new research directions to further advance the field.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021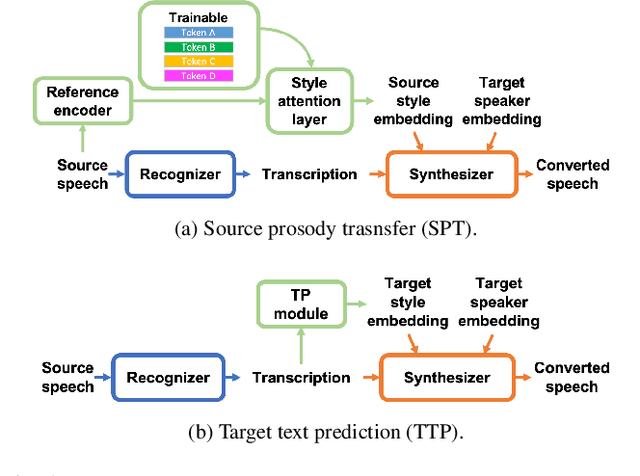

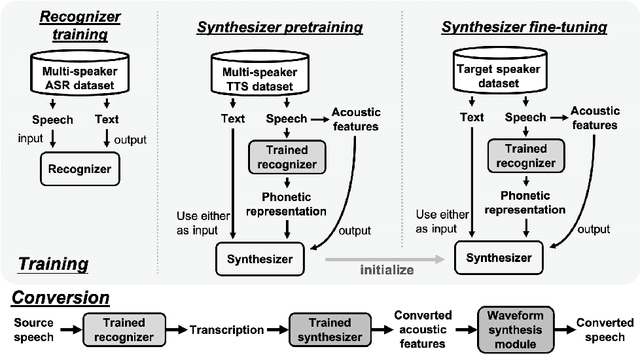

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
Probabilistic Spherical Discriminant Analysis: An Alternative to PLDA for length-normalized embeddings
Mar 28, 2022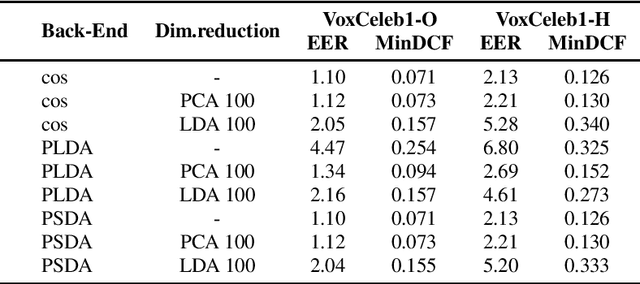
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring backends are commonly used, namely cosine scoring or PLDA. Both have advantages and disadvantages, depending on the context. Cosine scoring follows naturally from the spherical geometry, but for PLDA the blessing is mixed -- length normalization Gaussianizes the between-speaker distribution, but violates the assumption of a speaker-independent within-speaker distribution. We propose PSDA, an analogue to PLDA that uses Von Mises-Fisher distributions on the hypersphere for both within and between-class distributions. We show how the self-conjugacy of this distribution gives closed-form likelihood-ratio scores, making it a drop-in replacement for PLDA at scoring time. All kinds of trials can be scored, including single-enroll and multi-enroll verification, as well as more complex likelihood-ratios that could be used in clustering and diarization. Learning is done via an EM-algorithm with closed-form updates. We explain the model and present some first experiments.
Generalization Ability of MOS Prediction Networks
Oct 18, 2021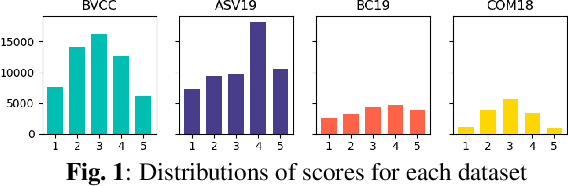
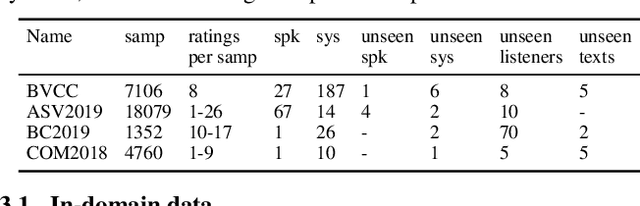
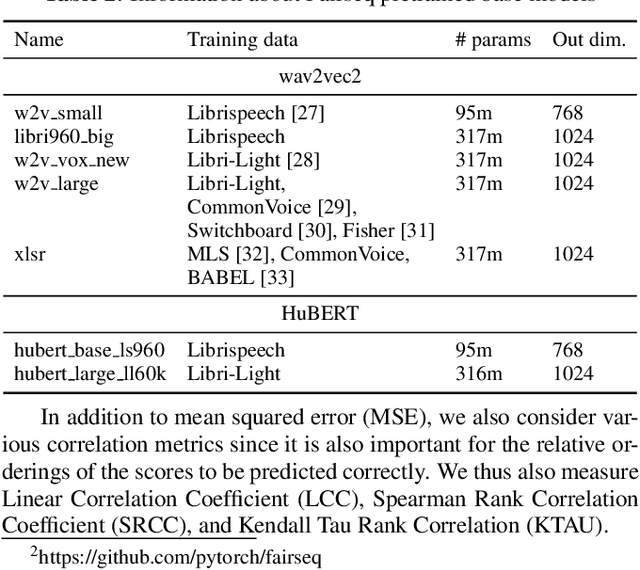
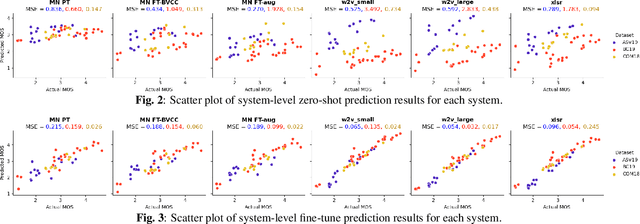
Automatic methods to predict listener opinions of synthesized speech remain elusive since listeners, systems being evaluated, characteristics of the speech, and even the instructions given and the rating scale all vary from test to test. While automatic predictors for metrics such as mean opinion score (MOS) can achieve high prediction accuracy on samples from the same test, they typically fail to generalize well to new listening test contexts. In this paper, using a variety of networks for MOS prediction including MOSNet and self-supervised speech models such as wav2vec2, we investigate their performance on data from different listening tests in both zero-shot and fine-tuned settings. We find that wav2vec2 models fine-tuned for MOS prediction have good generalization capability to out-of-domain data even for the most challenging case of utterance-level predictions in the zero-shot setting, and that fine-tuning to in-domain data can improve predictions. We also observe that unseen systems are especially challenging for MOS prediction models.
Assessing Progress of Parkinson s Disease Using Acoustic Analysis of Phonation
Mar 17, 2022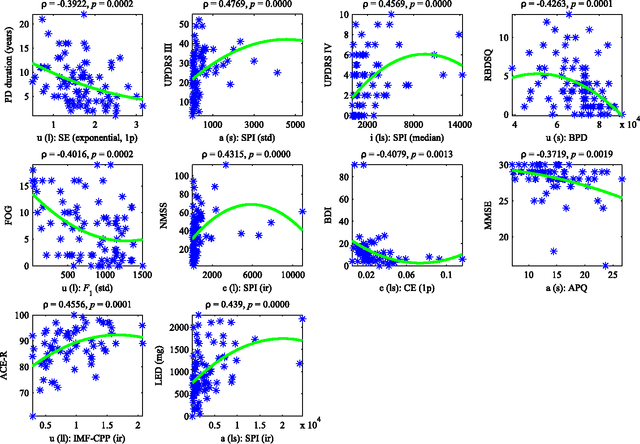
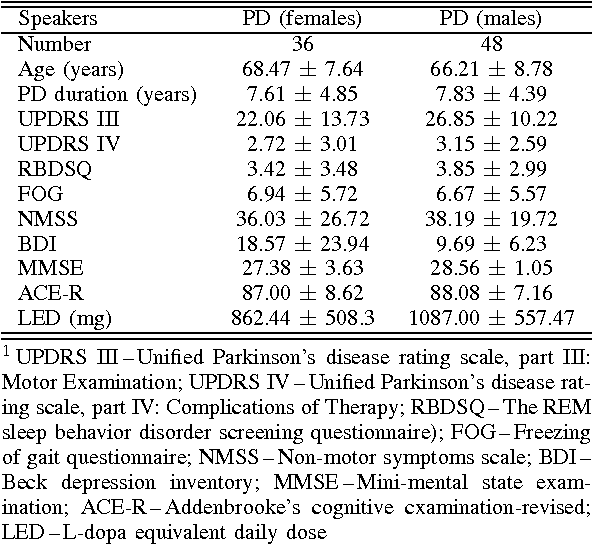
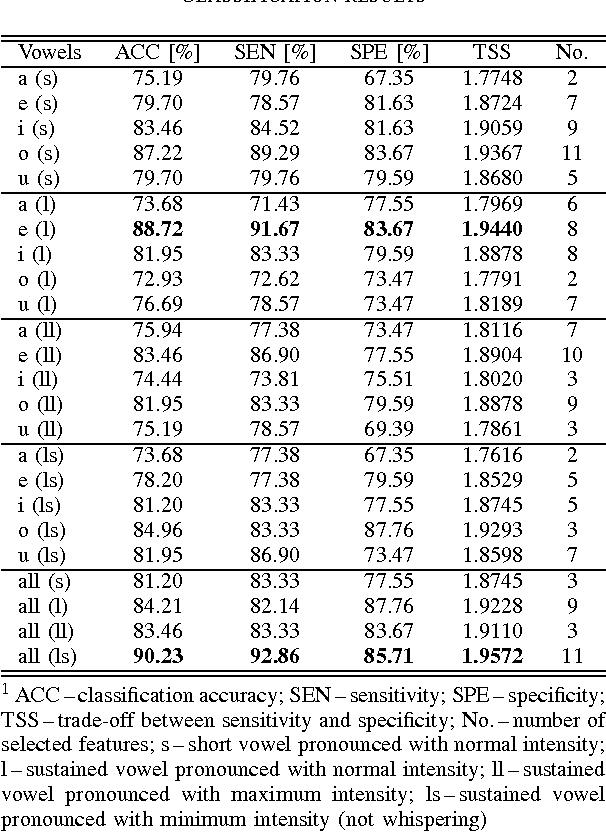
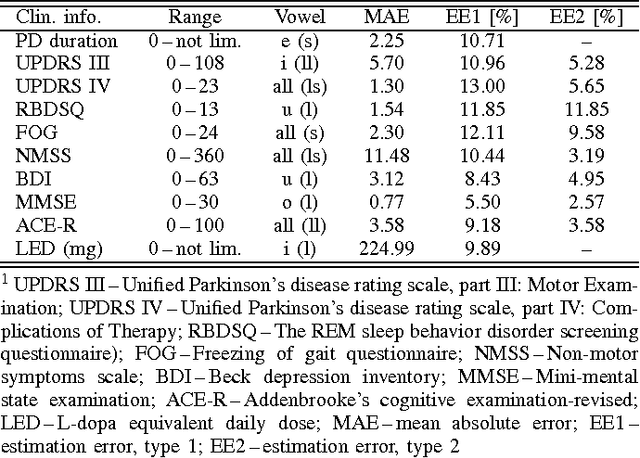
This paper deals with a complex acoustic analysis of phonation in patients with Parkinson's disease (PD) with a special focus on estimation of disease progress that is described by 7 different clinical scales ,e. g. Unified Parkinson's disease rating scale or Beck depression inventory. The analysis is based on parametrization of 5 Czech vowels pronounced by 84 PD patients. Using classification and regression trees we estimated all clinical scores with maximal error lower or equal to 13 %. Best estimation was observed in the case of Mini-mental state examination (MAE = 0.77, estimation error 5.50 %. Finally, we proposed a binary classification based on random forests that is able to identify Parkinson's disease with sensitivity SEN = 92.86 % (SPE = 85.71 %). The parametrization process was based on extraction of 107 speech features quantifying different clinical signs of hypokinetic dysarthria present in PD.
* 8 pages published in the 4th IEEE IWOBI 2015, pp. 115-122, 10-12 June, 2015 Donostia-San Sebastian. ISBN: 978-84-606-8733-7
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Mar 21, 2022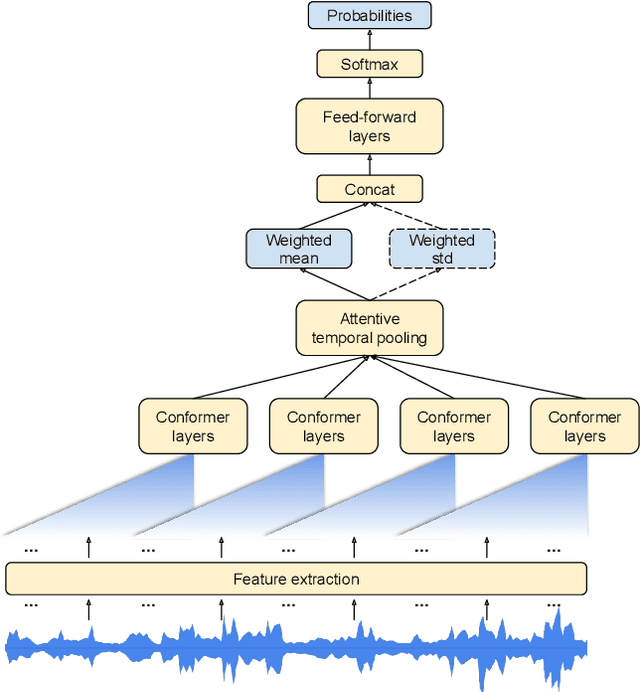
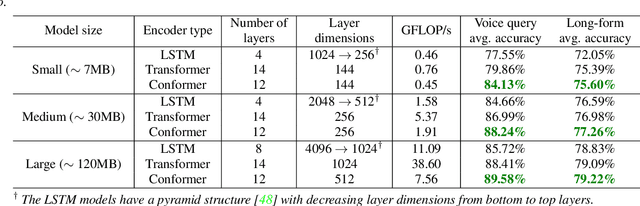
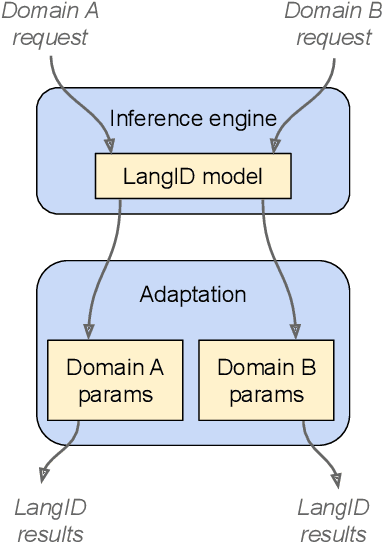
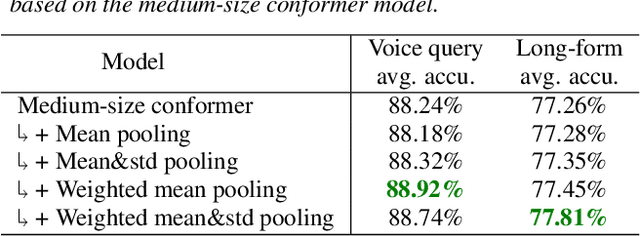
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.