 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Jan 18, 2022
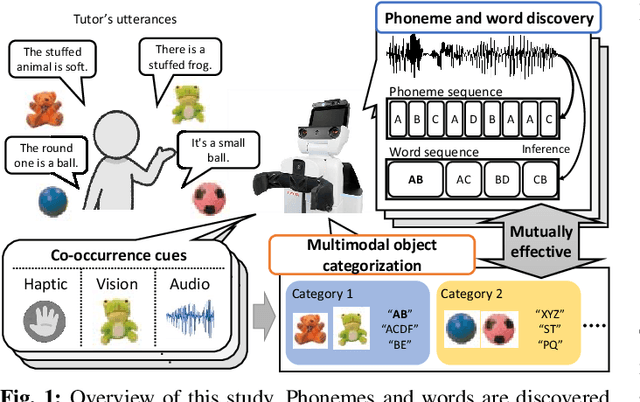
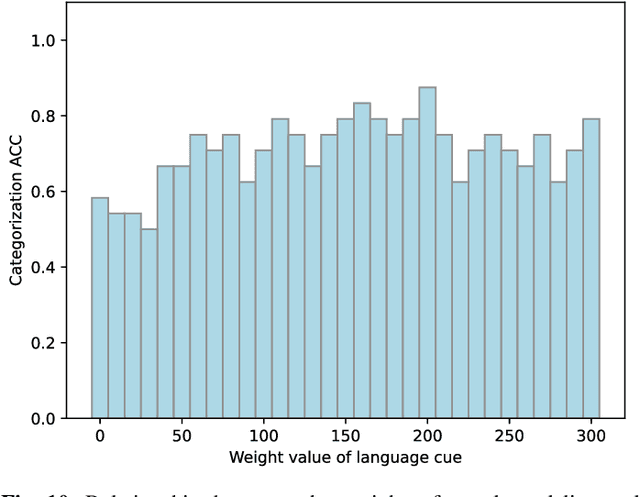
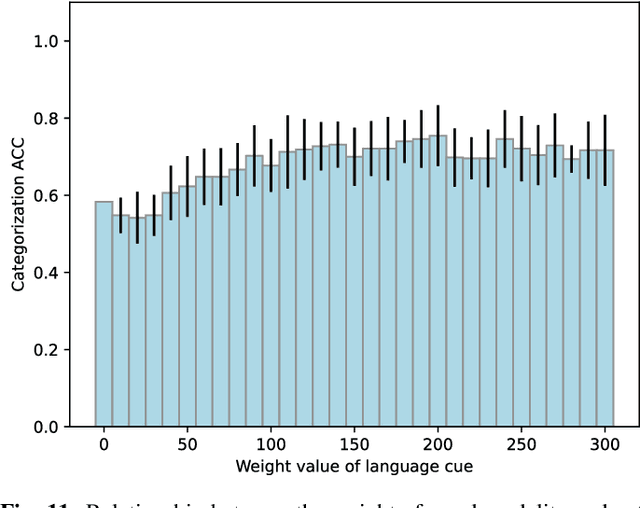
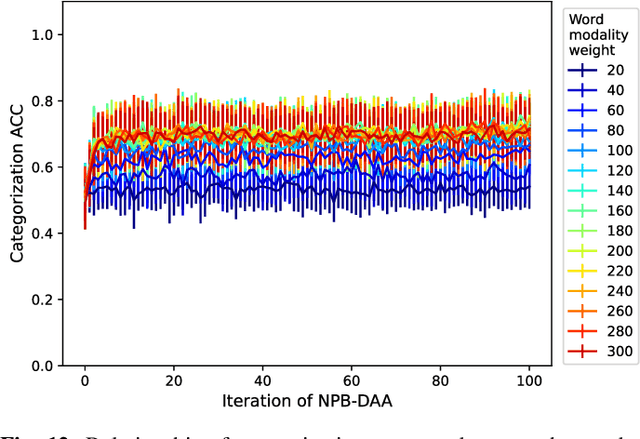
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.
A Review of Language and Speech Features for Cognitive-Linguistic Assessment
Jun 04, 2019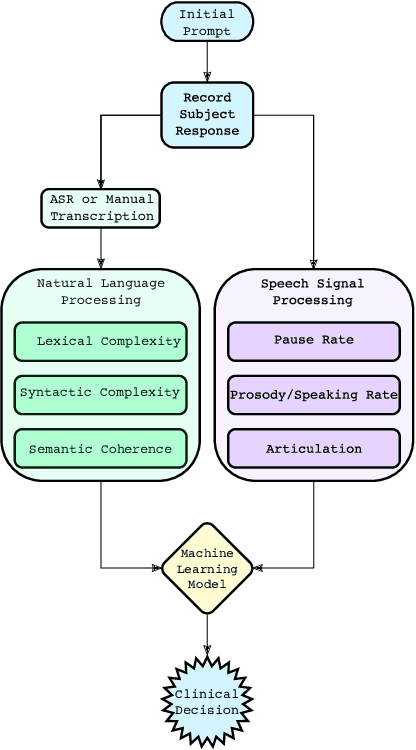

It is widely accepted that information derived from analyzing speech (the acoustic signal) and language production (words and sentences) serves as a useful window into the health of an individual's cognitive ability. In fact, most neuropsychological batteries used in cognitive assessment have a component related to speech and language where clinicians elicit speech from patients for subjective evaluation across a broad set of dimensions. With advances in speech signal processing and natural language processing, there has been recent interest in developing tools to detect more subtle changes in cognitive-linguistic function. This work relies on extracting a set of features from recorded and transcribed speech for objective assessments of cognition, early diagnosis of neurological disease, and objective tracking of disease after diagnosis. In this paper we provide a review of existing speech and language features used in this domain, discuss their clinical application, and highlight their advantages and disadvantages. Broadly speaking, the review is split into two categories: language features based on natural language processing and speech features based on speech signal processing. Within each category, we consider features that aim to measure complementary dimensions of cognitive-linguistics, including language diversity, syntactic complexity, semantic coherence, and timing. We conclude the review with a proposal of new research directions to further advance the field.
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition
Oct 20, 2020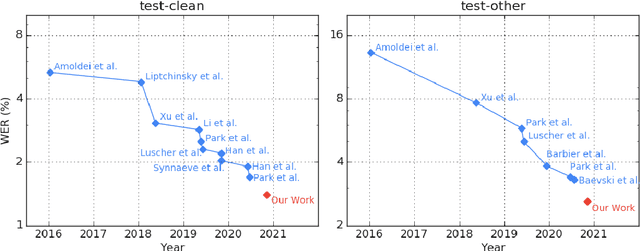

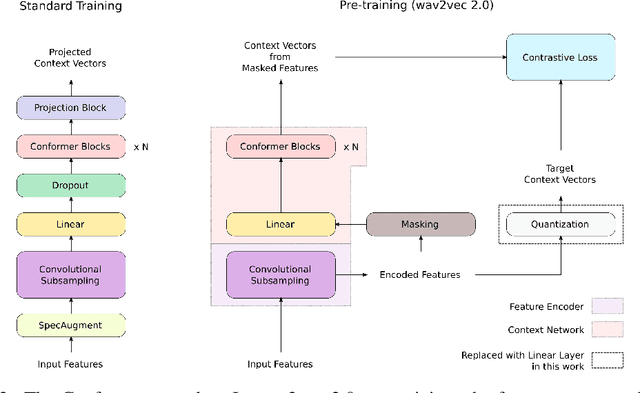
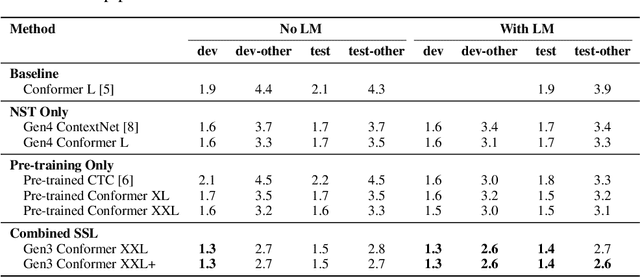
We employ a combination of recent developments in semi-supervised learning for automatic speech recognition to obtain state-of-the-art results on LibriSpeech utilizing the unlabeled audio of the Libri-Light dataset. More precisely, we carry out noisy student training with SpecAugment using giant Conformer models pre-trained using wav2vec 2.0 pre-training. By doing so, we are able to achieve word-error-rates (WERs) 1.4%/2.6% on the LibriSpeech test/test-other sets against the current state-of-the-art WERs 1.7%/3.3%.
From Inference to Generation: End-to-end Fully Self-supervised Generation of Human Face from Speech
Apr 13, 2020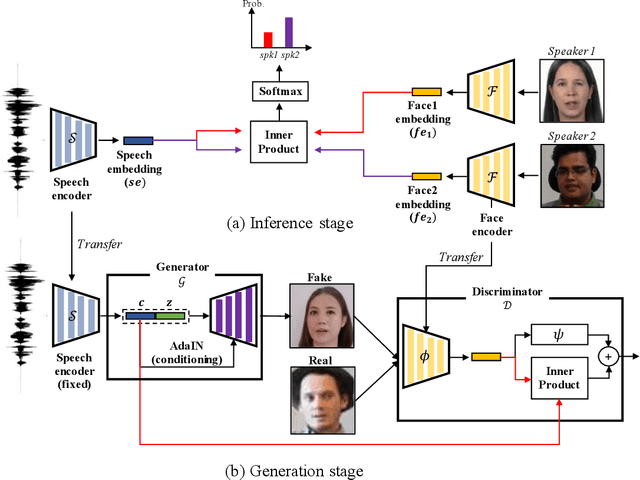
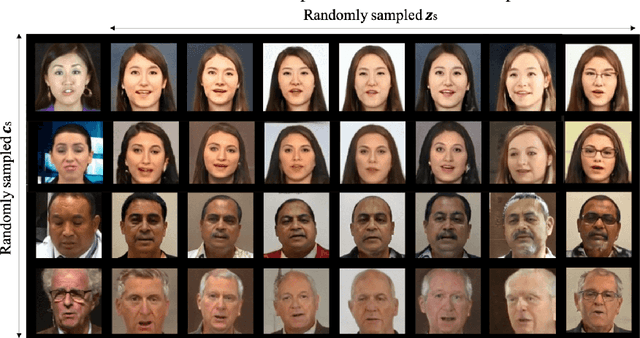

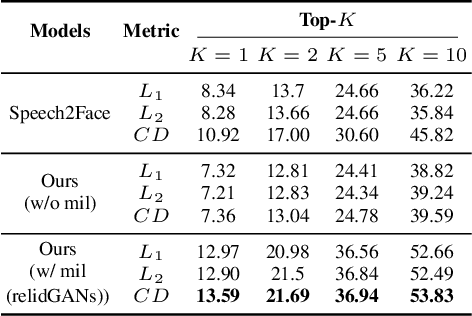
This work seeks the possibility of generating the human face from voice solely based on the audio-visual data without any human-labeled annotations. To this end, we propose a multi-modal learning framework that links the inference stage and generation stage. First, the inference networks are trained to match the speaker identity between the two different modalities. Then the trained inference networks cooperate with the generation network by giving conditional information about the voice. The proposed method exploits the recent development of GANs techniques and generates the human face directly from the speech waveform making our system fully end-to-end. We analyze the extent to which the network can naturally disentangle two latent factors that contribute to the generation of a face image - one that comes directly from a speech signal and the other that is not related to it - and explore whether the network can learn to generate natural human face image distribution by modeling these factors. Experimental results show that the proposed network can not only match the relationship between the human face and speech, but can also generate the high-quality human face sample conditioned on its speech. Finally, the correlation between the generated face and the corresponding speech is quantitatively measured to analyze the relationship between the two modalities.
Minimising Biasing Word Errors for Contextual ASR with the Tree-Constrained Pointer Generator
May 18, 2022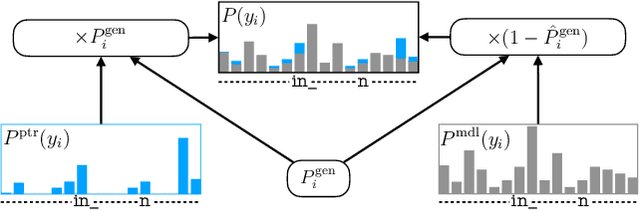
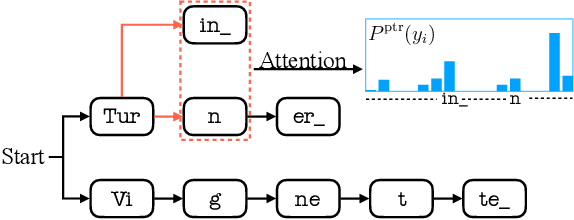
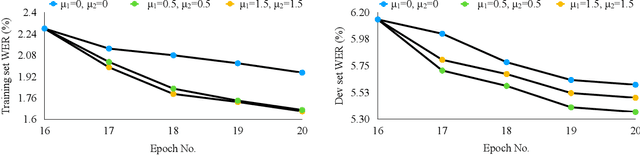
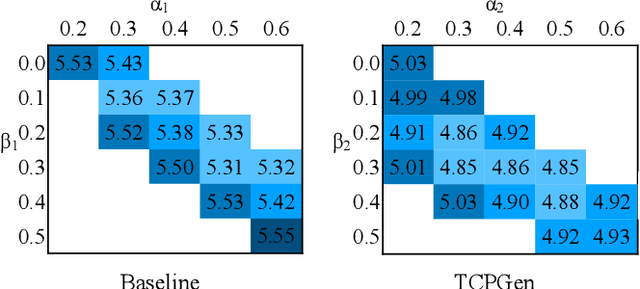
Contextual knowledge is essential for reducing speech recognition errors on high-valued long-tail words. This paper proposes a novel tree-constrained pointer generator (TCPGen) component that enables end-to-end ASR models to bias towards a list of long-tail words obtained using external contextual information. With only a small overhead in memory use and computation cost, TCPGen can structure thousands of biasing words efficiently into a symbolic prefix-tree and creates a neural shortcut between the tree and the final ASR output to facilitate the recognition of the biasing words. To enhance TCPGen, we further propose a novel minimum biasing word error (MBWE) loss that directly optimises biasing word errors during training, along with a biasing-word-driven language model discounting (BLMD) method during the test. All contextual ASR systems were evaluated on the public Librispeech audiobook corpus and the data from the dialogue state tracking challenges (DSTC) with the biasing lists extracted from the dialogue-system ontology. Consistent word error rate (WER) reductions were achieved with TCPGen, which were particularly significant on the biasing words with around 40\% relative reductions in the recognition error rates. MBWE and BLMD further improved the effectiveness of TCPGen and achieved more significant WER reductions on the biasing words. TCPGen also achieved zero-shot learning of words not in the audio training set with large WER reductions on the out-of-vocabulary words in the biasing list.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Jun 05, 2022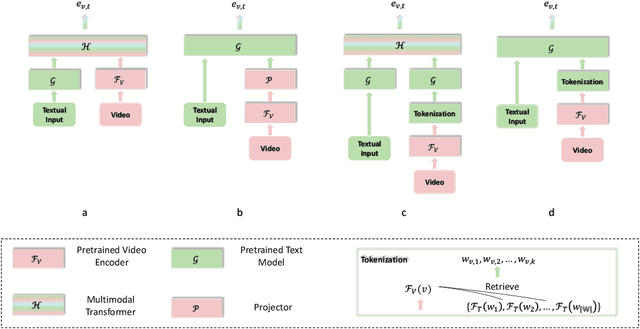

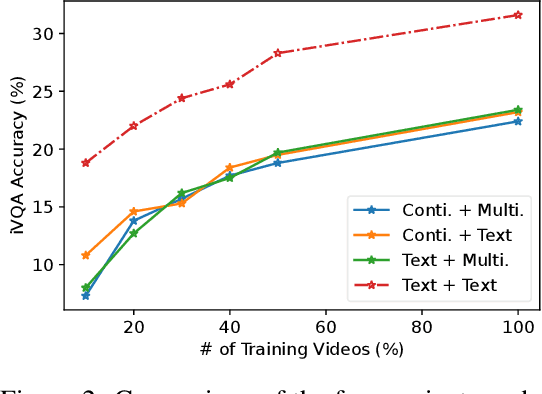
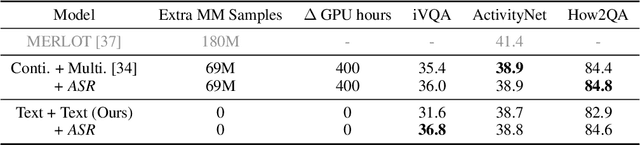
Multi-channel video-language retrieval require models to understand information from different modalities (e.g. video+question, video+speech) and real-world knowledge to correctly link a video with a textual response or query. Fortunately, multimodal contrastive models have been shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models have been extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. Their abilities are exactly needed by multi-channel video-language retrieval. However, it is not clear how to quickly adapt these two lines of models to multi-channel video-language retrieval-style tasks. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance. This combination can even outperform state-of-the-art on the iVQA dataset without the additional training on millions of video-language data. Further analysis shows that this is because representing videos as text tokens captures the key visual information with text tokens that are naturally aligned with text models and the text models obtained rich knowledge during contrastive pretraining process. All the empirical analysis we obtain for the four variants establishes a solid foundation for future research on leveraging the rich knowledge of pretrained contrastive models.
Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech
Aug 03, 2020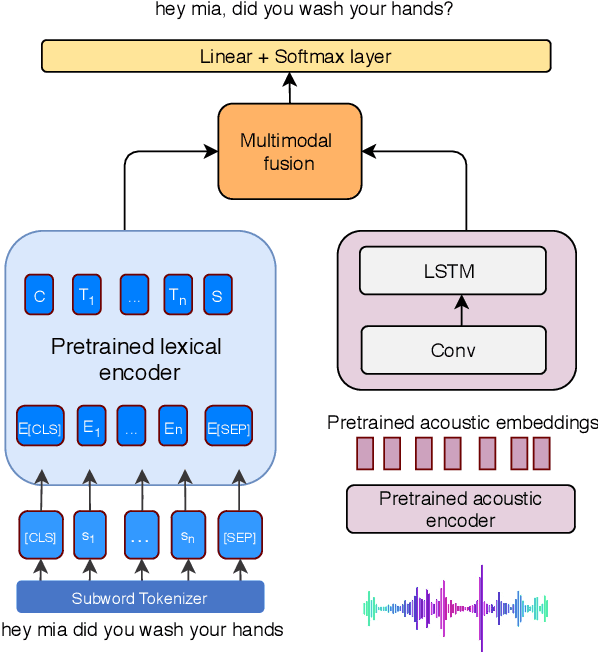
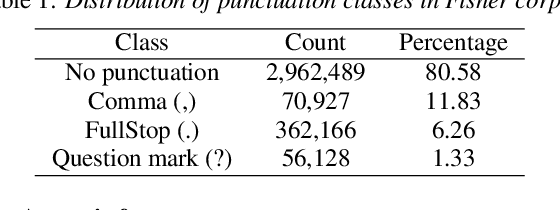
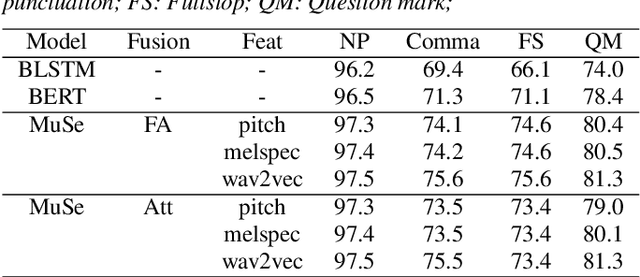
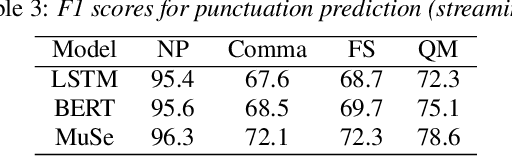
In this work, we explore a multimodal semi-supervised learning approach for punctuation prediction by learning representations from large amounts of unlabelled audio and text data. Conventional approaches in speech processing typically use forced alignment to encoder per frame acoustic features to word level features and perform multimodal fusion of the resulting acoustic and lexical representations. As an alternative, we explore attention based multimodal fusion and compare its performance with forced alignment based fusion. Experiments conducted on the Fisher corpus show that our proposed approach achieves ~6-9% and ~3-4% absolute improvement (F1 score) over the baseline BLSTM model on reference transcripts and ASR outputs respectively. We further improve the model robustness to ASR errors by performing data augmentation with N-best lists which achieves up to an additional ~2-6% improvement on ASR outputs. We also demonstrate the effectiveness of semi-supervised learning approach by performing ablation study on various sizes of the corpus. When trained on 1 hour of speech and text data, the proposed model achieved ~9-18% absolute improvement over baseline model.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021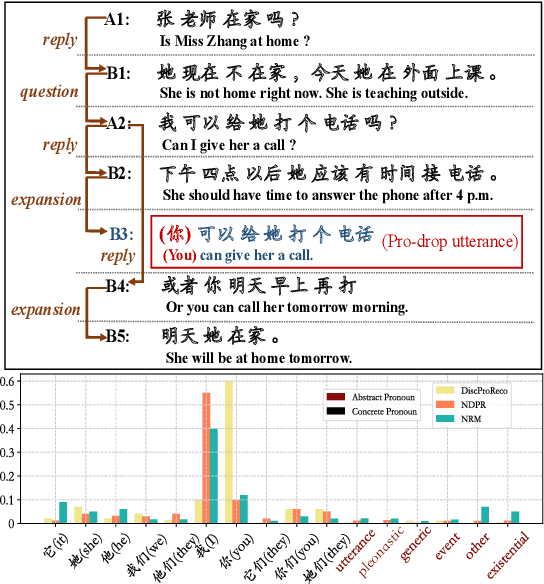
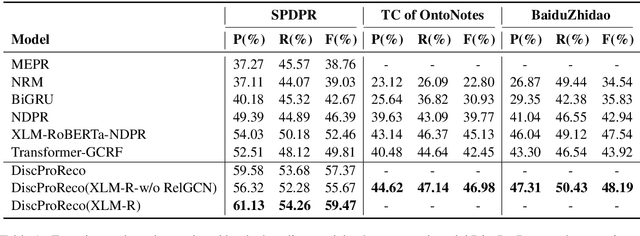
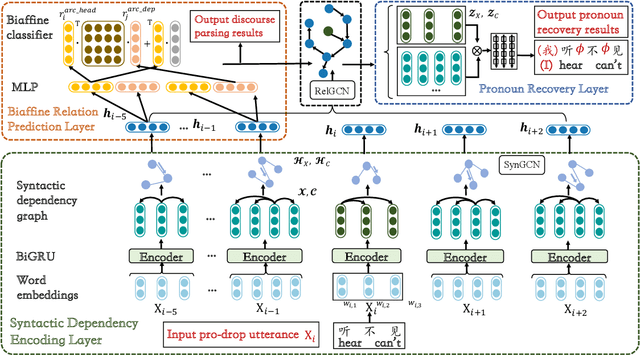
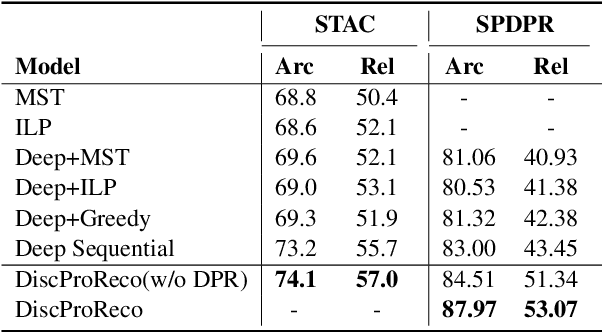
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
A survey on recently proposed activation functions for Deep Learning
Apr 07, 2022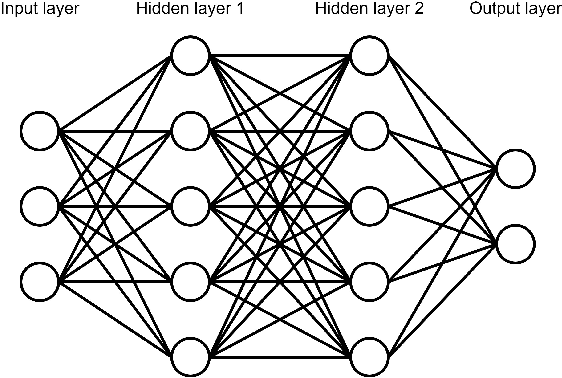
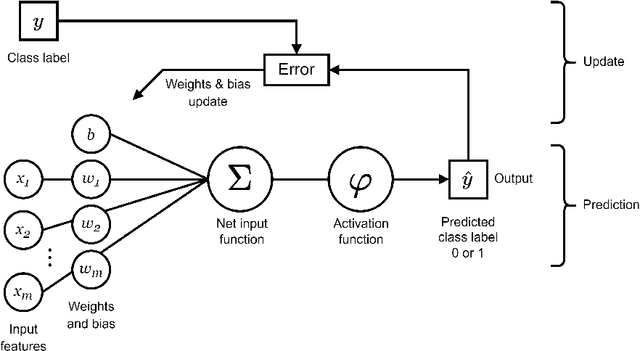
Artificial neural networks (ANN), typically referred to as neural networks, are a class of Machine Learning algorithms and have achieved widespread success, having been inspired by the biological structure of the human brain. Neural networks are inherently powerful due to their ability to learn complex function approximations from data. This generalization ability has been able to impact multidisciplinary areas involving image recognition, speech recognition, natural language processing, and others. Activation functions are a crucial sub-component of neural networks. They define the output of a node in the network given a set of inputs. This survey discusses the main concepts of activation functions in neural networks, including; a brief introduction to deep neural networks, a summary of what are activation functions and how they are used in neural networks, their most common properties, the different types of activation functions, some of the challenges, limitations, and alternative solutions faced by activation functions, concluding with the final remarks.
A Novel Decision Tree for Depression Recognition in Speech
Feb 22, 2020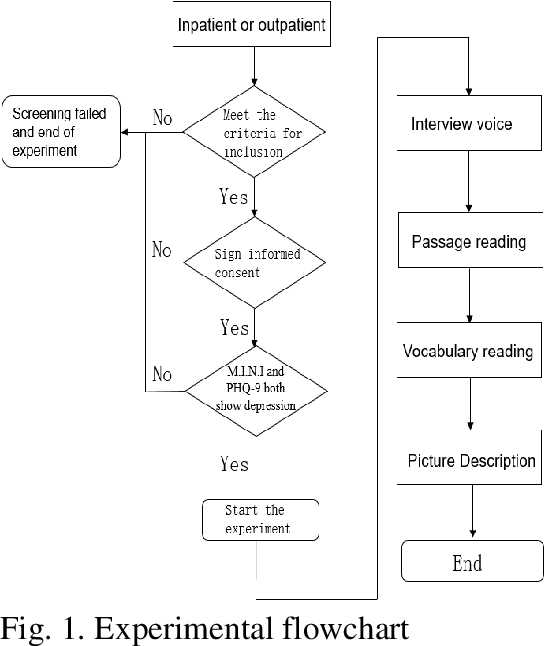
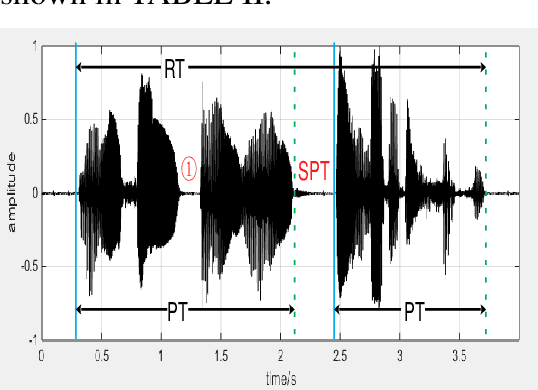
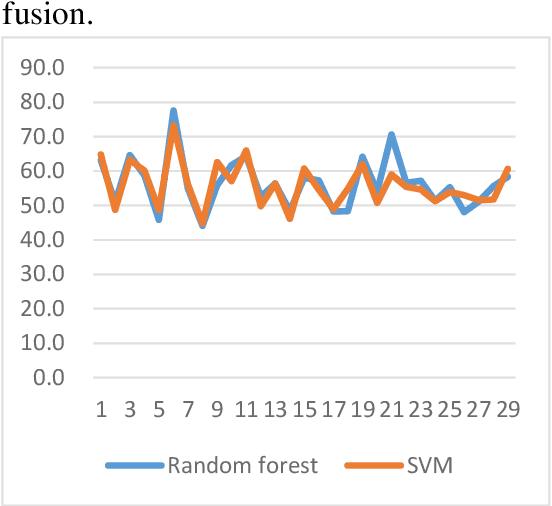
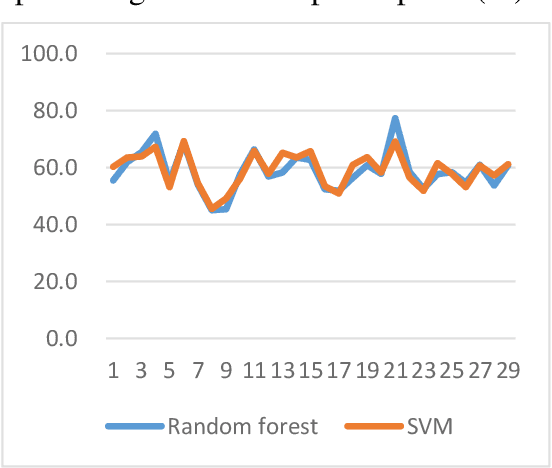
Depression is a common mental disorder worldwide which causes a range of serious outcomes. The diagnosis of depression relies on patient-reported scales and psychiatrist interview which may lead to subjective bias. In recent years, more and more researchers are devoted to depression recognition in speech , which may be an effective and objective indicator. This study proposes a new speech segment fusion method based on decision tree to improve the depression recognition accuracy and conducts a validation on a sample of 52 subjects (23 depressed patients and 29 healthy controls). The recognition accuracy are 75.8% and 68.5% for male and female respectively on gender-dependent models. It can be concluded from the data that the proposed decision tree model can improve the depression classification performance.