 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Frequency Gating: Improved Convolutional Neural Networks for Speech Enhancement in the Time-Frequency Domain
Nov 08, 2020
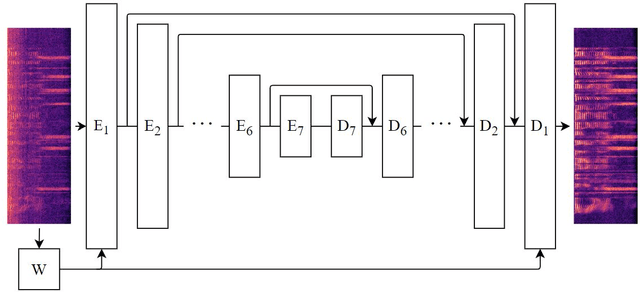
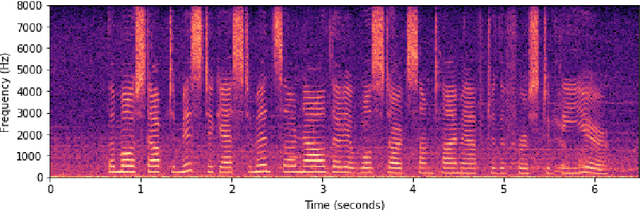
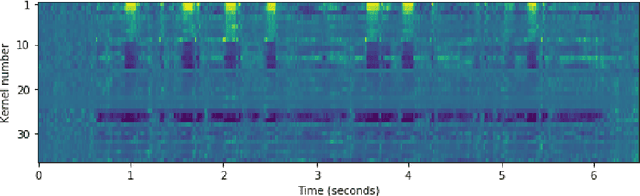
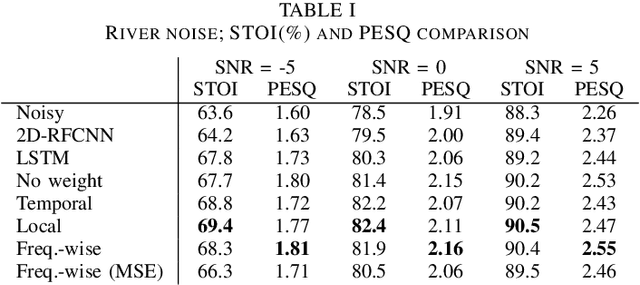
One of the strengths of traditional convolutional neural networks (CNNs) is their inherent translational invariance. However, for the task of speech enhancement in the time-frequency domain, this property cannot be fully exploited due to a lack of invariance in the frequency direction. In this paper we propose to remedy this inefficiency by introducing a method, which we call Frequency Gating, to compute multiplicative weights for the kernels of the CNN in order to make them frequency dependent. Several mechanisms are explored: temporal gating, in which weights are dependent on prior time frames, local gating, whose weights are generated based on a single time frame and the ones adjacent to it, and frequency-wise gating, where each kernel is assigned a weight independent of the input data. Experiments with an autoencoder neural network with skip connections show that both local and frequency-wise gating outperform the baseline and are therefore viable ways to improve CNN-based speech enhancement neural networks. In addition, a loss function based on the extended short-time objective intelligibility score (ESTOI) is introduced, which we show to outperform the standard mean squared error (MSE) loss function.
Speaker recognition improvement using blind inversion of distortions
Feb 23, 2022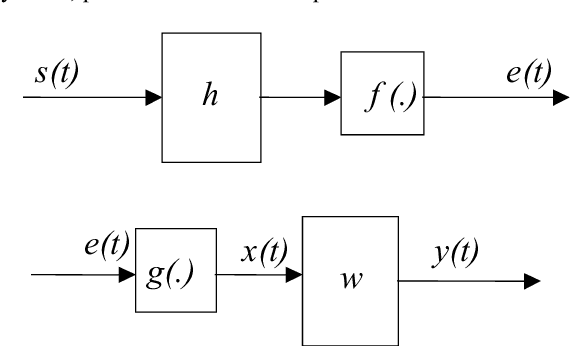
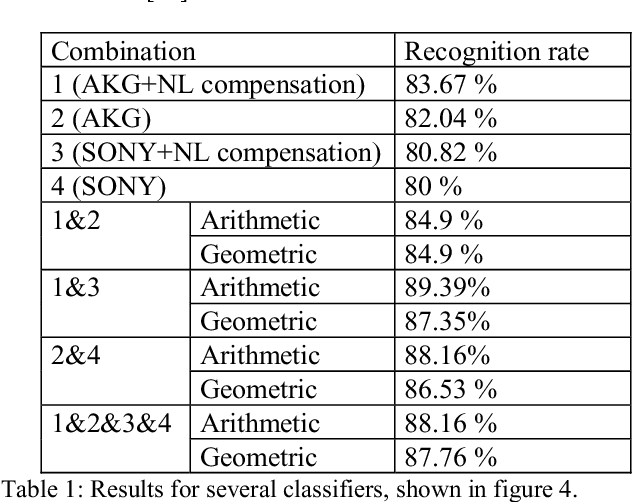
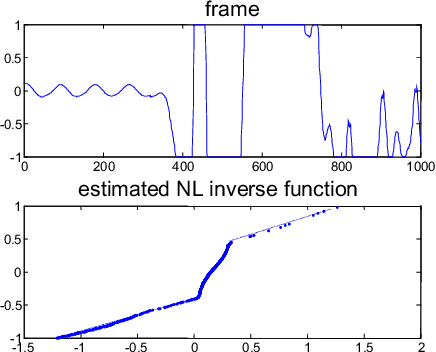
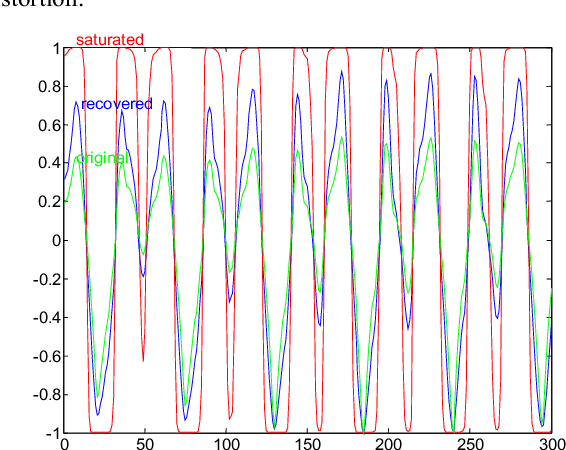
In this paper we propose the inversion of nonlinear distortions in order to improve the recognition rates of a speaker recognizer system. We study the effect of saturations on the test signals, trying to take into account real situations where the training material has been recorded in a controlled situation but the testing signals present some mismatch with the input signal level (saturations). The experimental results shows that a combination of data fusion with and without nonlinear distortion compensation can improve the recognition rates with saturated test sentences from 80% to 88.57%, while the results with clean speech (without saturation) is 87.76% for one microphone.
* 4 pages
WNARS: WFST based Non-autoregressive Streaming End-to-End Speech Recognition
Apr 08, 2021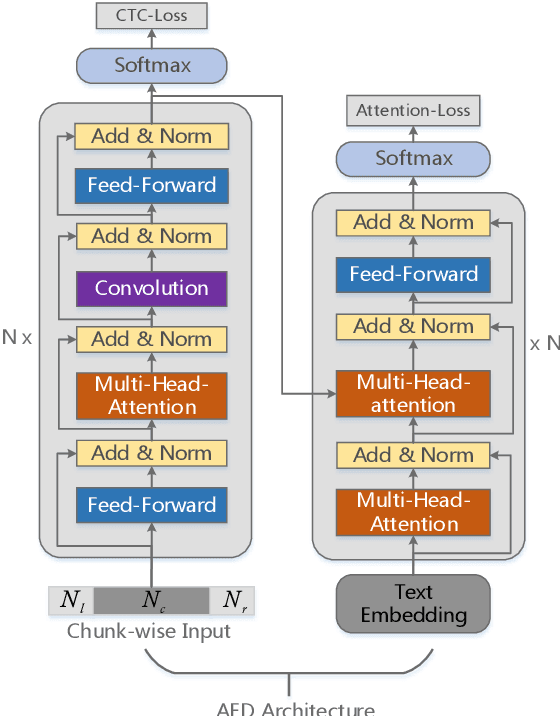


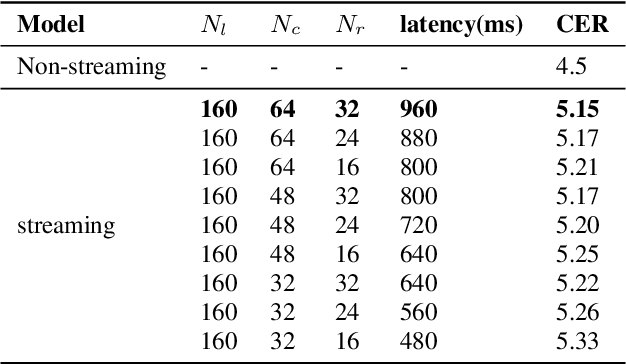
Recently, attention-based encoder-decoder (AED) end-to-end (E2E) models have drawn more and more attention in the field of automatic speech recognition (ASR). AED models, however, still have drawbacks when deploying in commercial applications. Autoregressive beam search decoding makes it inefficient for high-concurrency applications. It is also inconvenient to integrate external word-level language models. The most important thing is that AED models are difficult for streaming recognition due to global attention mechanism. In this paper, we propose a novel framework, namely WNARS, using hybrid CTC-attention AED models and weighted finite-state transducers (WFST) to solve these problems together. We switch from autoregressive beam search to CTC branch decoding, which performs first-pass decoding with WFST in chunk-wise streaming way. The decoder branch then performs second-pass rescoring on the generated hypotheses non-autoregressively. On the AISHELL-1 task, our WNARS achieves a character error rate of 5.22% with 640ms latency, to the best of our knowledge, which is the state-of-the-art performance for online ASR. Further experiments on our 10,000-hour Mandarin task show the proposed method achieves more than 20% improvements with 50% latency compared to a strong TDNN-BLSTM lattice-free MMI baseline.
Who Needs Words? Lexicon-Free Speech Recognition
Apr 09, 2019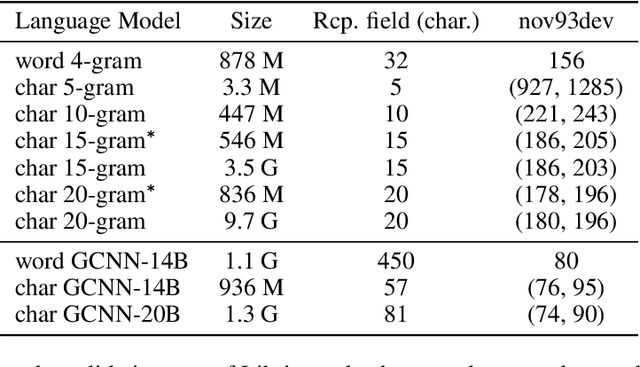
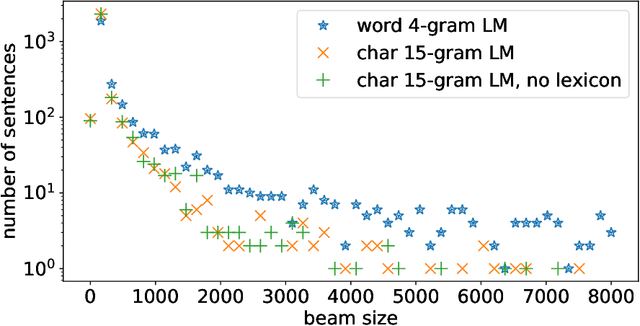
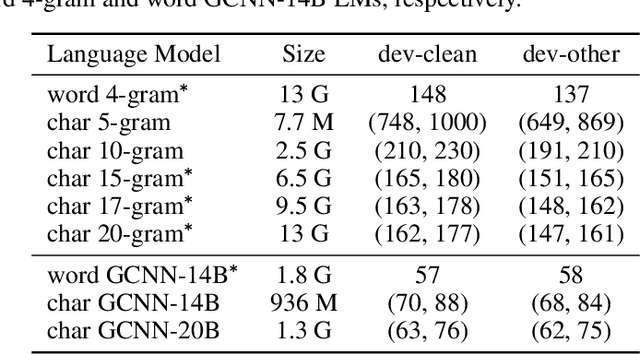
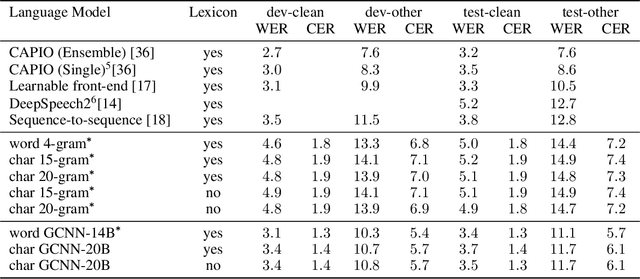
Lexicon-free speech recognition naturally deals with the problem of out-of-vocabulary (OOV) words. In this paper, we show that character-based language models (LM) can perform as well as word-based LMs for speech recognition, in word error rates (WER), even without restricting the decoding to a lexicon. We study character-based LMs and show that convolutional LMs can effectively leverage large (character) contexts, which is key for good speech recognition performance downstream. We specifically show that the lexicon-free decoding performance (WER) on utterances with OOV words using character-based LMs is better than lexicon-based decoding, both with character or word-based LMs.
Hallucination of speech recognition errors with sequence to sequence learning
Mar 31, 2021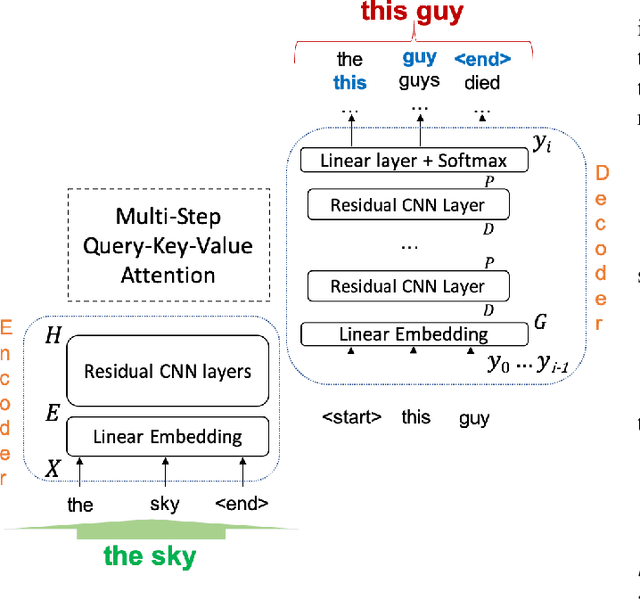
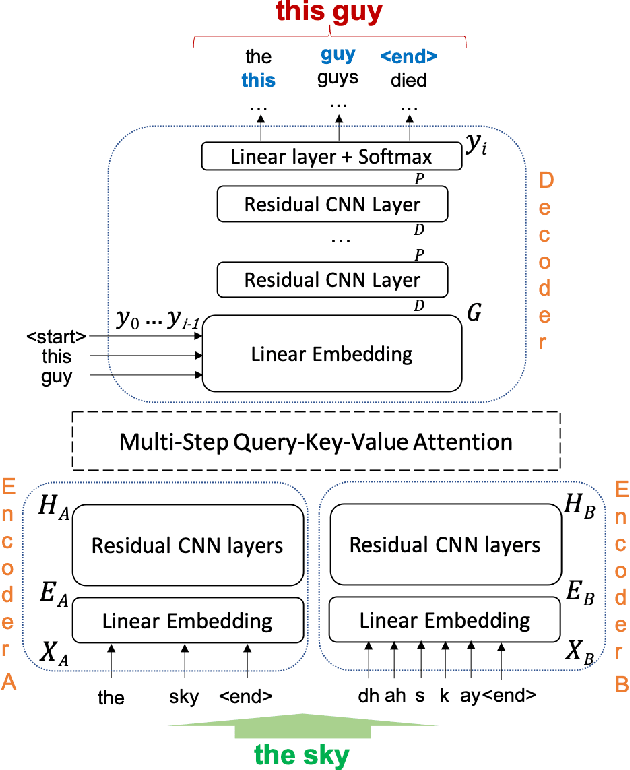
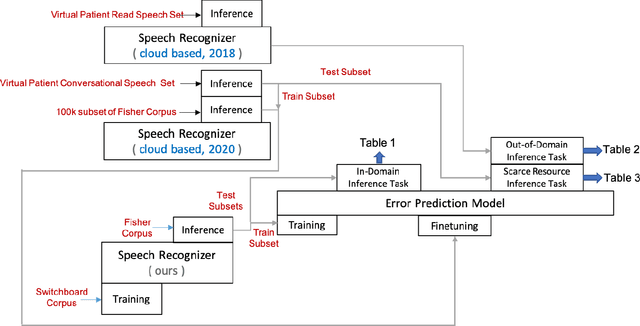
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system's transcription of unseen data, as well as an out-of-domain ASR system's transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.
Noise-robust blind reverberation time estimation using noise-aware time-frequency masking
Dec 09, 2021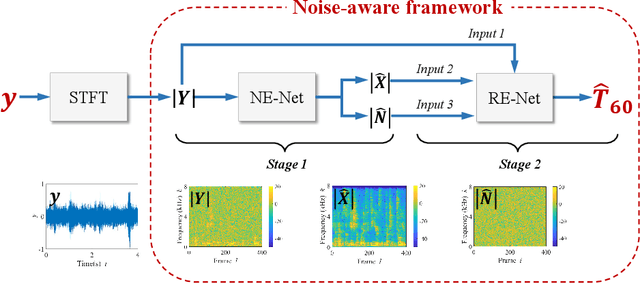
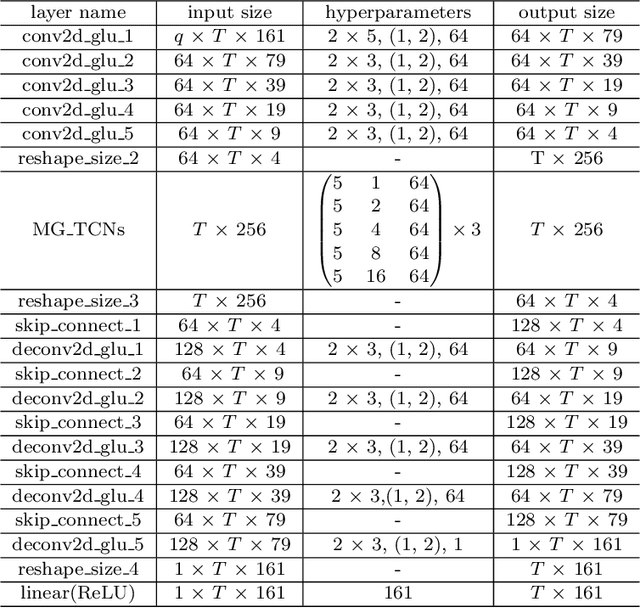

The reverberation time is one of the most important parameters used to characterize the acoustic property of an enclosure. In real-world scenarios, it is much more convenient to estimate the reverberation time blindly from recorded speech compared to the traditional acoustic measurement techniques using professional measurement instruments. However, the recorded speech is often corrupted by noise, which has a detrimental effect on the estimation accuracy of the reverberation time. To address this issue, this paper proposes a two-stage blind reverberation time estimation method based on noise-aware time-frequency masking. This proposed method has a good ability to distinguish the reverberation tails from the noise, thus improving the estimation accuracy of reverberation time in noisy scenarios. The simulated and real-world acoustic experimental results show that the proposed method significantly outperforms other methods in challenging scenarios.
A Novel Decision Tree for Depression Recognition in Speech
Feb 22, 2020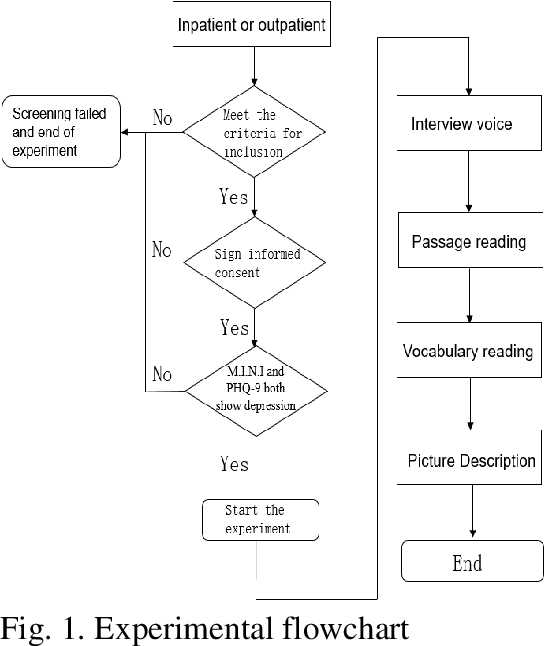
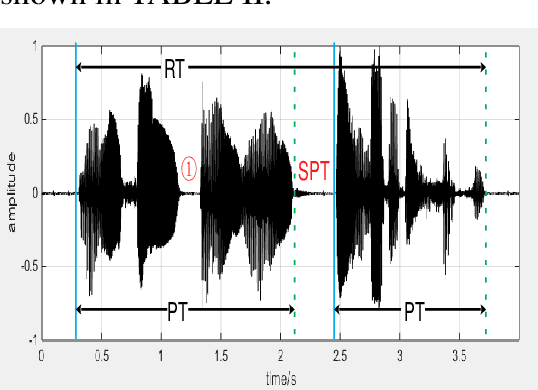
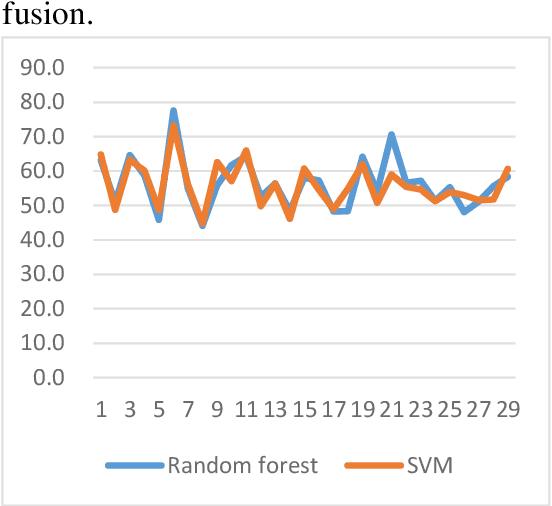
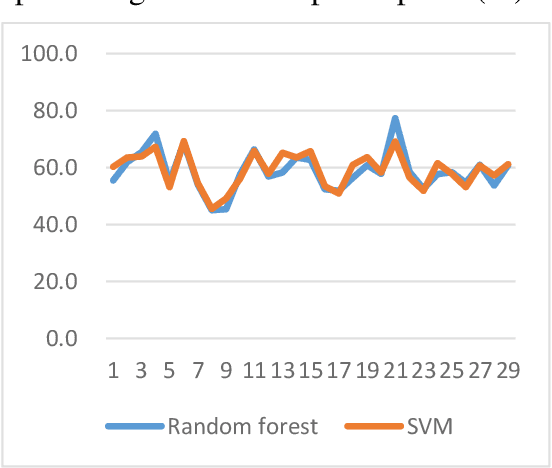
Depression is a common mental disorder worldwide which causes a range of serious outcomes. The diagnosis of depression relies on patient-reported scales and psychiatrist interview which may lead to subjective bias. In recent years, more and more researchers are devoted to depression recognition in speech , which may be an effective and objective indicator. This study proposes a new speech segment fusion method based on decision tree to improve the depression recognition accuracy and conducts a validation on a sample of 52 subjects (23 depressed patients and 29 healthy controls). The recognition accuracy are 75.8% and 68.5% for male and female respectively on gender-dependent models. It can be concluded from the data that the proposed decision tree model can improve the depression classification performance.
A Review of Language and Speech Features for Cognitive-Linguistic Assessment
Jun 04, 2019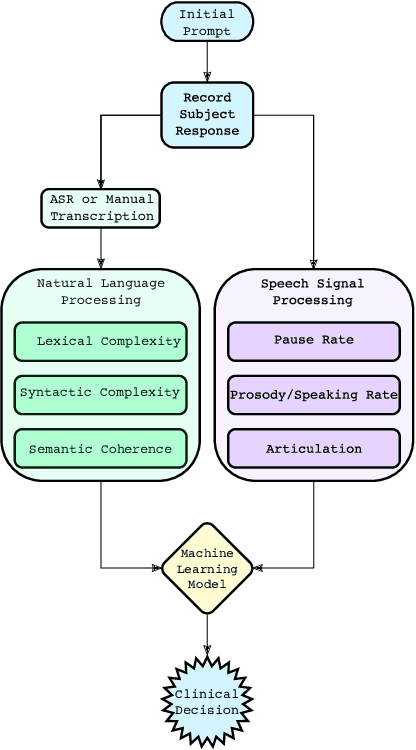

It is widely accepted that information derived from analyzing speech (the acoustic signal) and language production (words and sentences) serves as a useful window into the health of an individual's cognitive ability. In fact, most neuropsychological batteries used in cognitive assessment have a component related to speech and language where clinicians elicit speech from patients for subjective evaluation across a broad set of dimensions. With advances in speech signal processing and natural language processing, there has been recent interest in developing tools to detect more subtle changes in cognitive-linguistic function. This work relies on extracting a set of features from recorded and transcribed speech for objective assessments of cognition, early diagnosis of neurological disease, and objective tracking of disease after diagnosis. In this paper we provide a review of existing speech and language features used in this domain, discuss their clinical application, and highlight their advantages and disadvantages. Broadly speaking, the review is split into two categories: language features based on natural language processing and speech features based on speech signal processing. Within each category, we consider features that aim to measure complementary dimensions of cognitive-linguistics, including language diversity, syntactic complexity, semantic coherence, and timing. We conclude the review with a proposal of new research directions to further advance the field.
Efficient Non-Autoregressive GAN Voice Conversion using VQWav2vec Features and Dynamic Convolution
Mar 31, 2022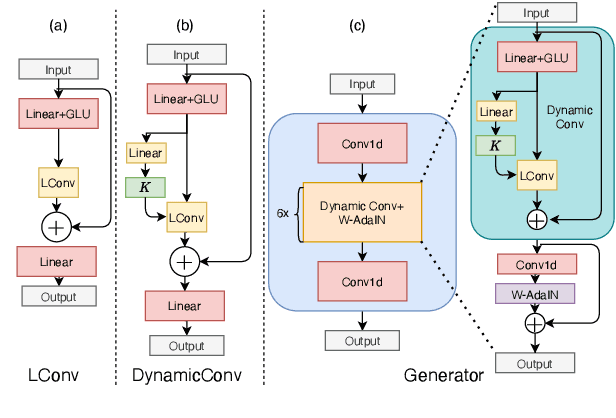
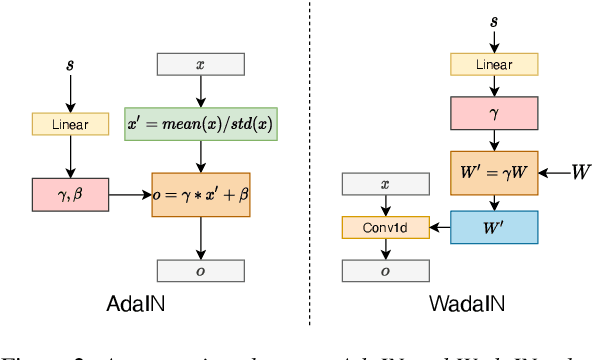
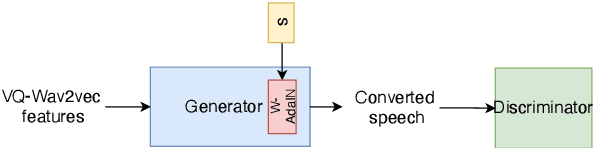

It was shown recently that a combination of ASR and TTS models yield highly competitive performance on standard voice conversion tasks such as the Voice Conversion Challenge 2020 (VCC2020). To obtain good performance both models require pretraining on large amounts of data, thereby obtaining large models that are potentially inefficient in use. In this work we present a model that is significantly smaller and thereby faster in processing while obtaining equivalent performance. To achieve this the proposed model, Dynamic-GAN-VC (DYGAN-VC), uses a non-autoregressive structure and makes use of vector quantised embeddings obtained from a VQWav2vec model. Furthermore dynamic convolution is introduced to improve speech content modeling while requiring a small number of parameters. Objective and subjective evaluation was performed using the VCC2020 task, yielding MOS scores of up to 3.86, and character error rates as low as 4.3\%. This was achieved with approximately half the number of model parameters, and up to 8 times faster decoding speed.
Deep Embeddings for Robust User-Based Amateur Vocal Percussion Classification
Apr 10, 2022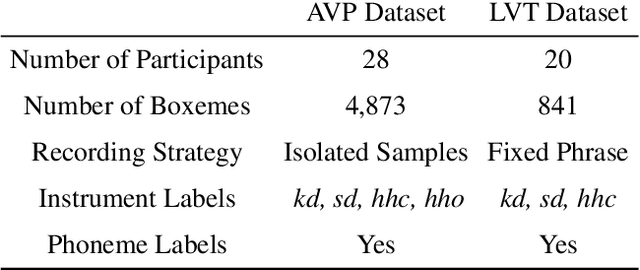
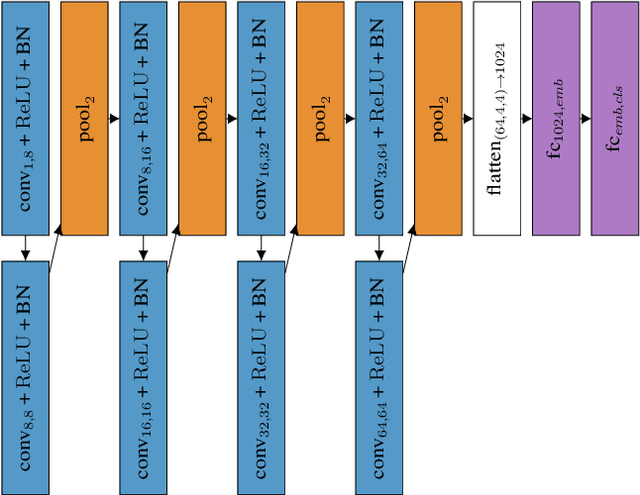

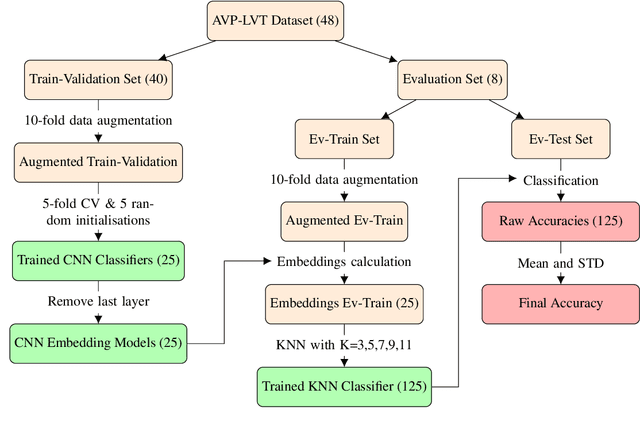
Vocal Percussion Transcription (VPT) is concerned with the automatic detection and classification of vocal percussion sound events, allowing music creators and producers to sketch drum lines on the fly. Classifier algorithms in VPT systems learn best from small user-specific datasets, which usually restrict modelling to small input feature sets to avoid data overfitting. This study explores several deep supervised learning strategies to obtain informative feature sets for amateur vocal percussion classification. We evaluated the performance of these sets on regular vocal percussion classification tasks and compared them with several baseline approaches including feature selection methods and a speech recognition engine. These proposed learning models were supervised with several label sets containing information from four different levels of abstraction: instrument-level, syllable-level, phoneme-level, and boxeme-level. Results suggest that convolutional neural networks supervised with syllable-level annotations produced the most informative embeddings for classification, which can be used as input representations to fit classifiers with. Finally, we used back-propagation-based saliency maps to investigate the importance of different spectrogram regions for feature learning.