 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021
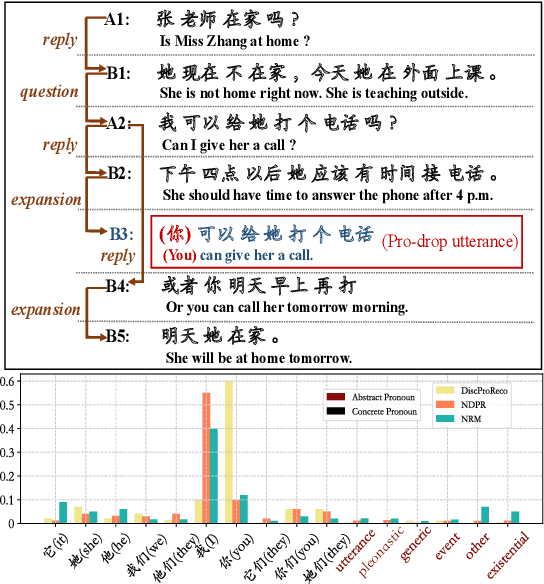
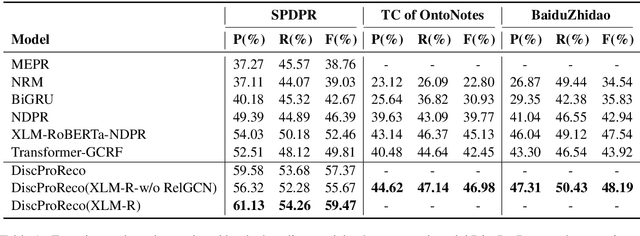
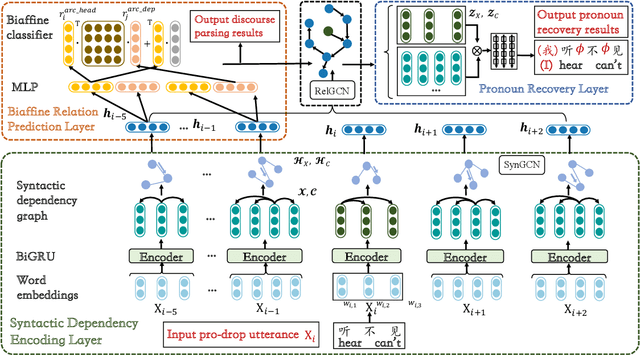
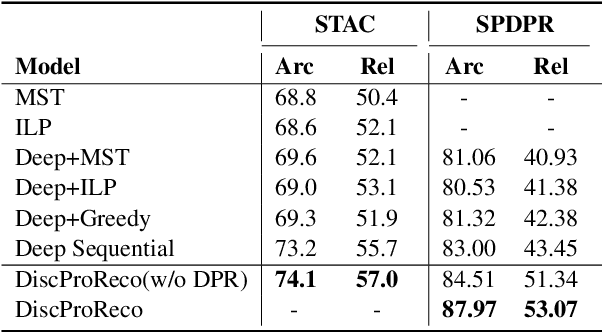
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Speech Prediction in Silent Videos using Variational Autoencoders
Nov 14, 2020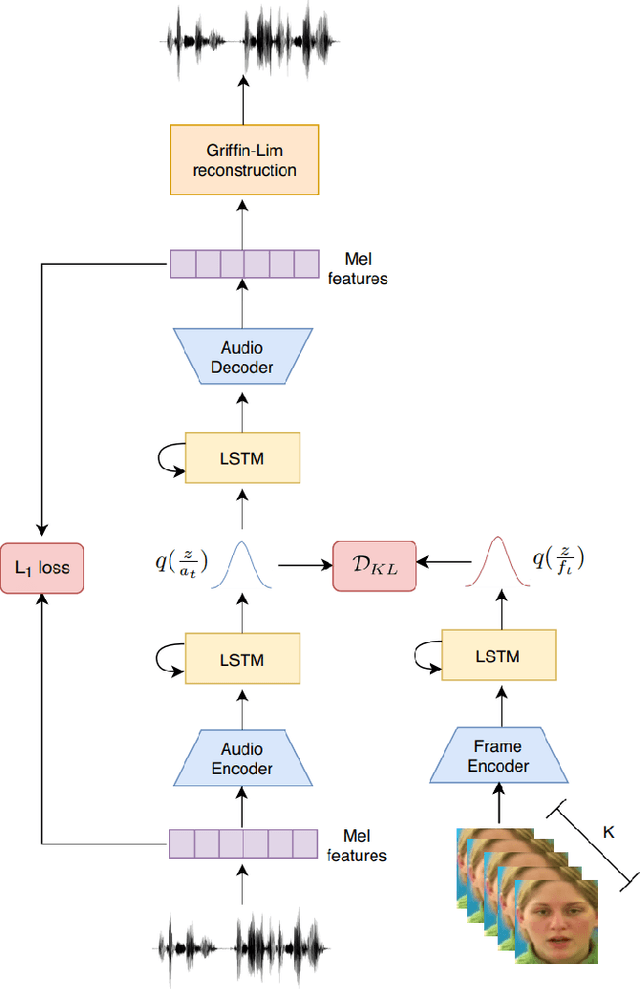
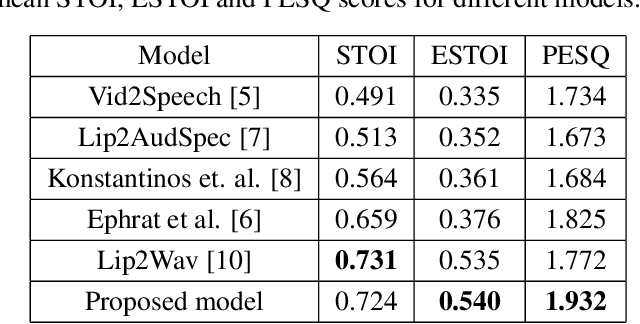
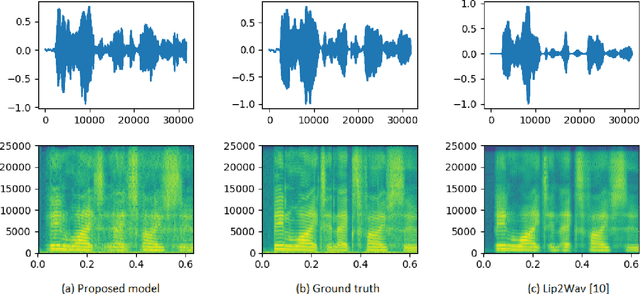
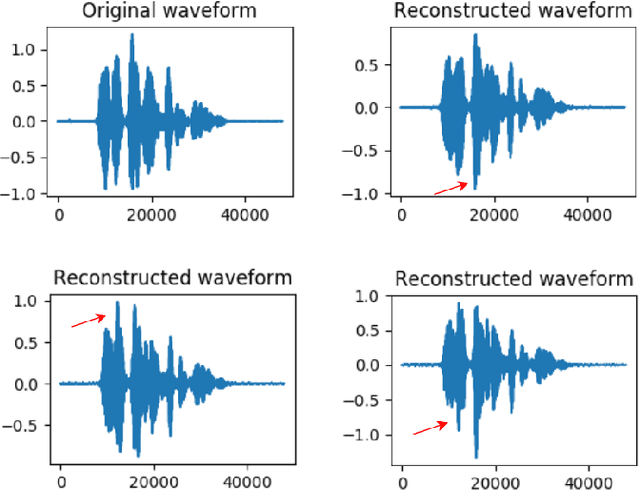
Understanding the relationship between the auditory and visual signals is crucial for many different applications ranging from computer-generated imagery (CGI) and video editing automation to assisting people with hearing or visual impairments. However, this is challenging since the distribution of both audio and visual modality is inherently multimodal. Therefore, most of the existing methods ignore the multimodal aspect and assume that there only exists a deterministic one-to-one mapping between the two modalities. It can lead to low-quality predictions as the model collapses to optimizing the average behavior rather than learning the full data distributions. In this paper, we present a stochastic model for generating speech in a silent video. The proposed model combines recurrent neural networks and variational deep generative models to learn the auditory signal's conditional distribution given the visual signal. We demonstrate the performance of our model on the GRID dataset based on standard benchmarks.
SyncNet: Using Causal Convolutions and Correlating Objective for Time Delay Estimation in Audio Signals
Mar 28, 2022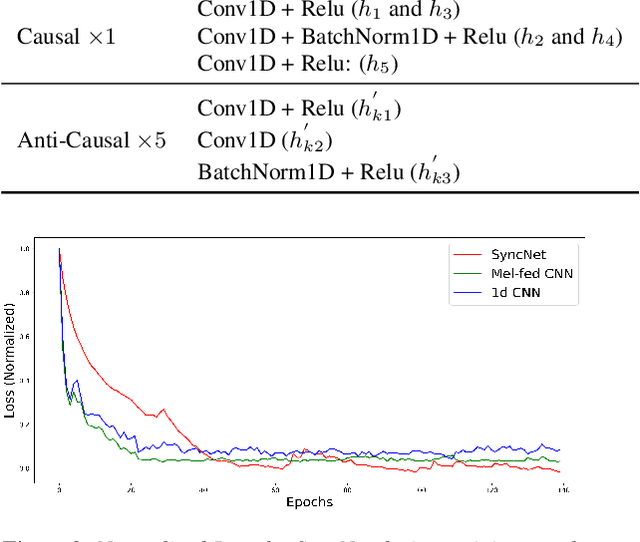
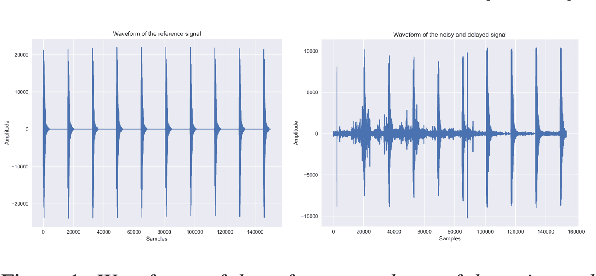
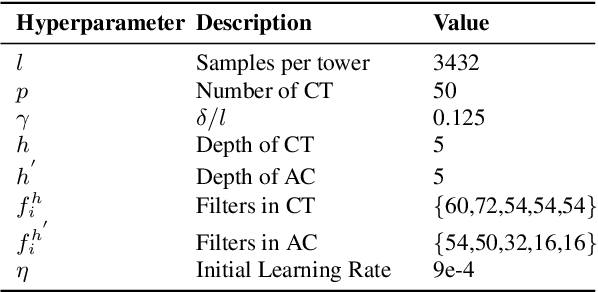
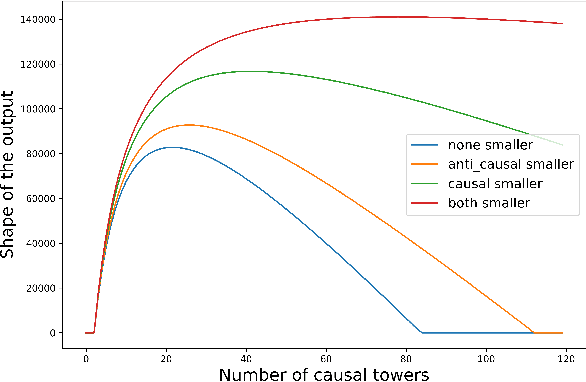
This paper addresses the task of performing robust and reliable time-delay estimation in audio-signals in noisy and reverberating environments. In contrast to the popular signal processing based methods, this paper proposes machine learning based method, i.e., a semi-causal convolutional neural network consisting of a set of causal and anti-causal layers with a novel correlation-based objective function. The causality in the network ensures non-leakage of representations from future time-intervals and the proposed loss function makes the network generate sequences with high correlation at the actual time delay. The proposed approach is also intrinsically interpretable as it does not lose time information. Even a shallow convolution network is able to capture local patterns in sequences, while also correlating them globally. SyncNet outperforms other classical approaches in estimating mutual time delays for different types of audio signals including pulse, speech and musical beats.
Breaking the Data Barrier: Towards Robust Speech Translation via Adversarial Stability Training
Sep 25, 2019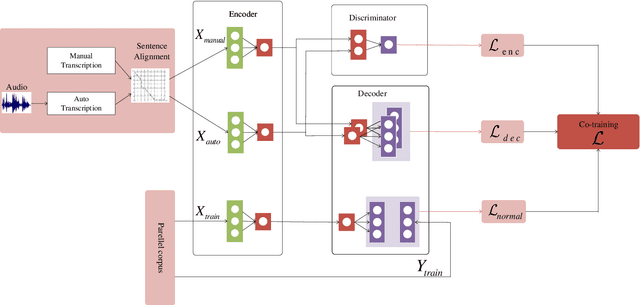
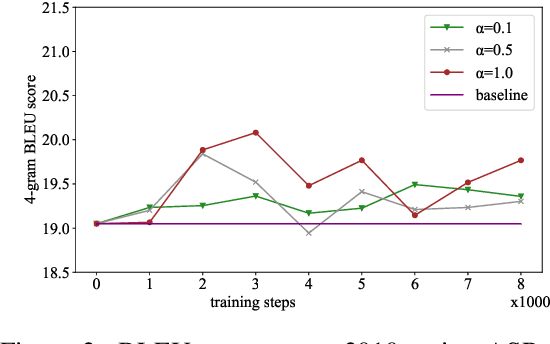
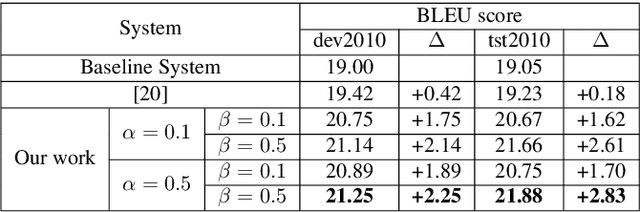
In a pipeline speech translation system, automatic speech recognition (ASR) system will transmit errors in recognition to the downstream machine translation (MT) system. A standard machine translation system is usually trained on parallel corpus composed of clean text and will perform poorly on text with recognition noise, a gap well known in speech translation community. In this paper, we propose a training architecture which aims at making a neural machine translation model more robust against speech recognition errors. Our approach addresses the encoder and the decoder simultaneously using adversarial learning and data augmentation, respectively. Experimental results on IWSLT2018 speech translation task show that our approach can bridge the gap between the ASR output and the MT input, outperforms the baseline by up to 2.83 BLEU on noisy ASR output, while maintaining close performance on clean text.
ETHOS: an Online Hate Speech Detection Dataset
Jun 11, 2020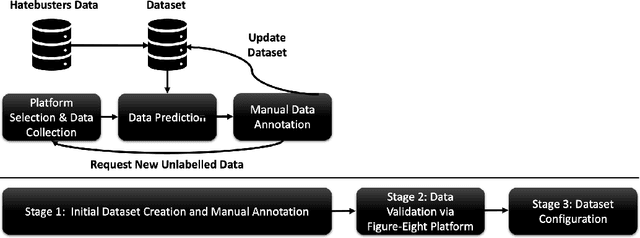
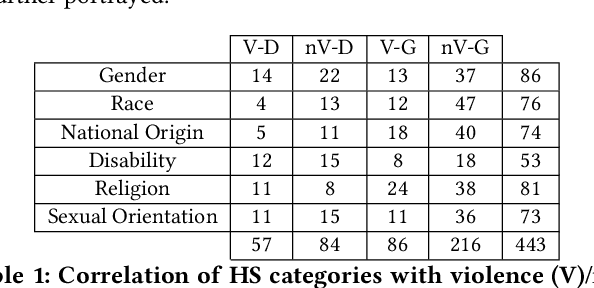
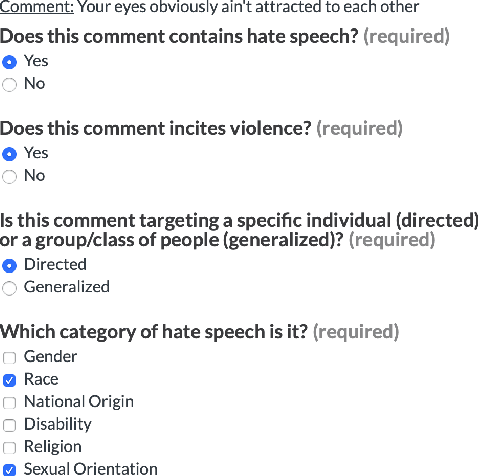

Online hate speech is a newborn problem in our modern society which is growing at a steady rate exploiting weaknesses of the corresponding regimes that characterise several social media platforms. Therefore, this phenomenon is mainly cultivated through such comments, either during users' interaction or on posted multimedia context. Nowadays, giant companies own platforms where many millions of users log in daily. Thus, protection of their users from exposure to similar phenomena for keeping up with the corresponding law, as well as for retaining a high quality of offered services, seems mandatory. Having a robust and reliable mechanism for identifying and preventing the uploading of related material would have a huge effect on our society regarding several aspects of our daily life. On the other hand, its absence would deteriorate heavily the total user experience, while its erroneous operation might raise several ethical issues. In this work, we present a protocol for creating a more suitable dataset, regarding its both informativeness and representativeness aspects, favouring the safer capture of hate speech occurrence, without at the same time restricting its applicability to other classification problems. Moreover, we produce and publish a textual dataset with two variants: binary and multi-label, called `ETHOS', based on YouTube and Reddit comments validated through figure-eight crowdsourcing platform. Our assumption about the production of more compatible datasets is further investigated by applying various classification models and recording their behaviour over several appropriate metrics.
Decoupling Speaker-Independent Emotions for Voice Conversion Via Source-Filter Networks
Oct 04, 2021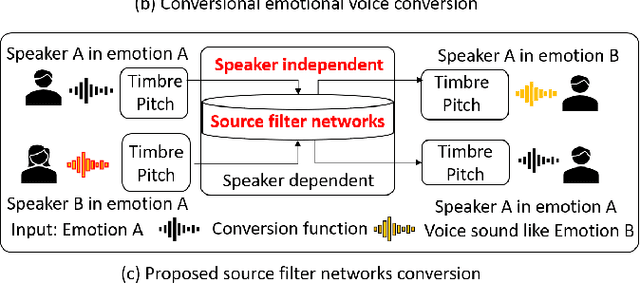
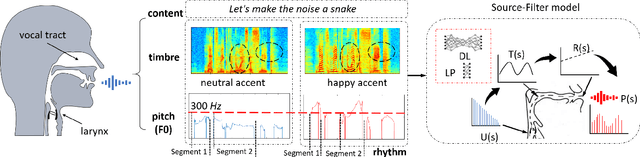
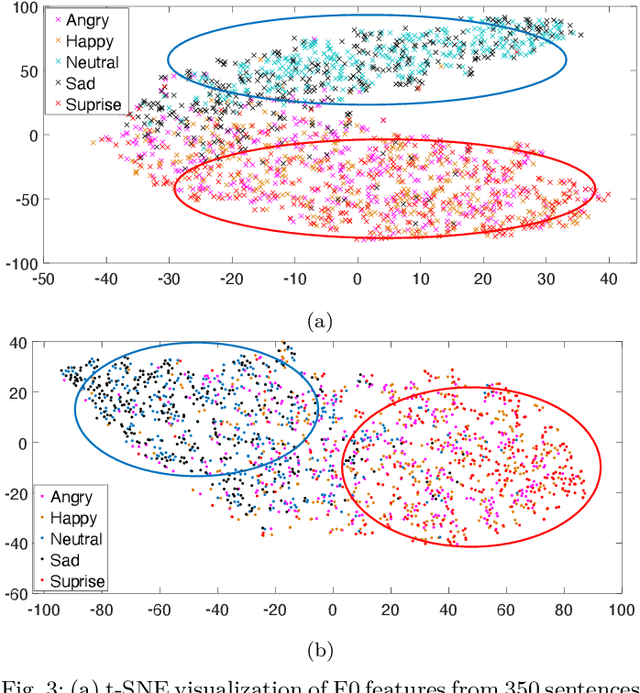
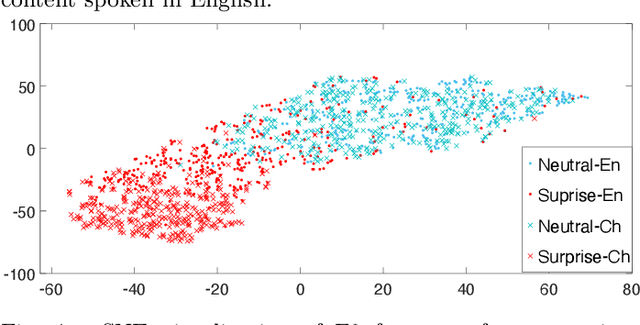
Emotional voice conversion (VC) aims to convert a neutral voice to an emotional (e.g. happy) one while retaining the linguistic information and speaker identity. We note that the decoupling of emotional features from other speech information (such as speaker, content, etc.) is the key to achieving remarkable performance. Some recent attempts about speech representation decoupling on the neutral speech can not work well on the emotional speech, due to the more complex acoustic properties involved in the latter. To address this problem, here we propose a novel Source-Filter-based Emotional VC model (SFEVC) to achieve proper filtering of speaker-independent emotion features from both the timbre and pitch features. Our SFEVC model consists of multi-channel encoders, emotion separate encoders, and one decoder. Note that all encoder modules adopt a designed information bottlenecks auto-encoder. Additionally, to further improve the conversion quality for various emotions, a novel two-stage training strategy based on the 2D Valence-Arousal (VA) space was proposed. Experimental results show that the proposed SFEVC along with a two-stage training strategy outperforms all baselines and achieves the state-of-the-art performance in speaker-independent emotional VC with nonparallel data.
Deep Annotation of Therapeutic Working Alliance in Psychotherapy
Apr 12, 2022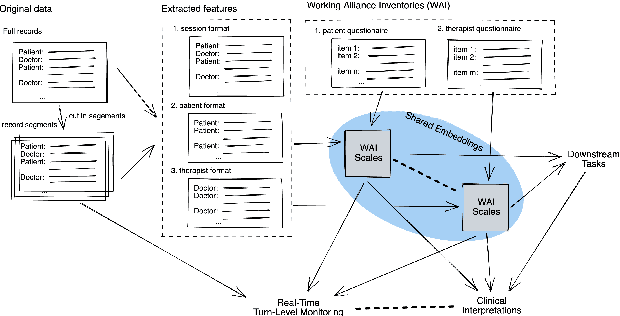



The therapeutic working alliance is an important predictor of the outcome of the psychotherapy treatment. In practice, the working alliance is estimated from a set of scoring questionnaires in an inventory that both the patient and the therapists fill out. In this work, we propose an analytical framework of directly inferring the therapeutic working alliance from the natural language within the psychotherapy sessions in a turn-level resolution with deep embeddings such as the Doc2Vec and SentenceBERT models. The transcript of each psychotherapy session can be transcribed and generated in real-time from the session speech recordings, and these embedded dialogues are compared with the distributed representations of the statements in the working alliance inventory. We demonstrate, in a real-world dataset with over 950 sessions of psychotherapy treatments in anxiety, depression, schizophrenia and suicidal patients, the effectiveness of this method in mapping out trajectories of patient-therapist alignment and the interpretability that can offer insights in clinical psychiatry. We believe such a framework can be provide timely feedback to the therapist regarding the quality of the conversation in interview sessions.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 24, 2022
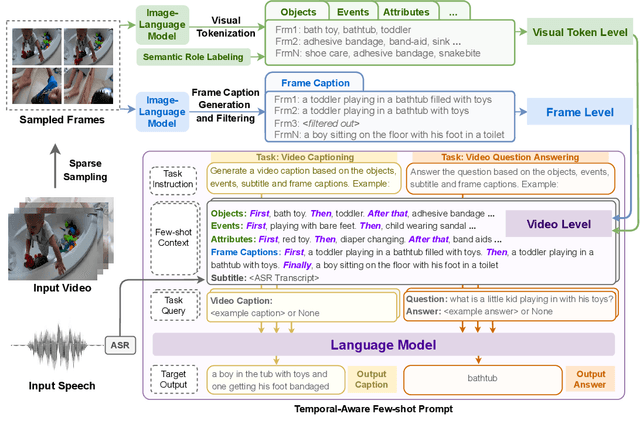
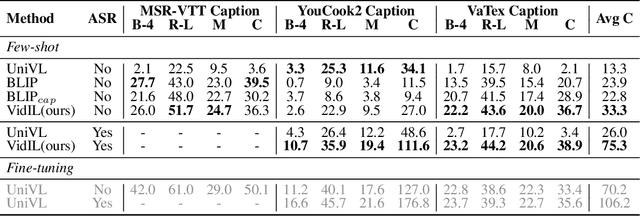

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Low-Latency Sequence-to-Sequence Speech Recognition and Translation by Partial Hypothesis Selection
May 22, 2020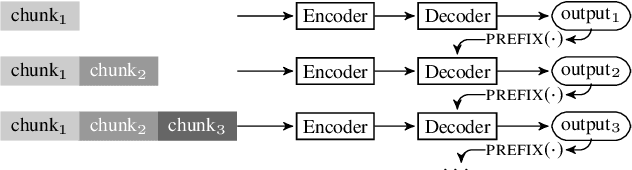
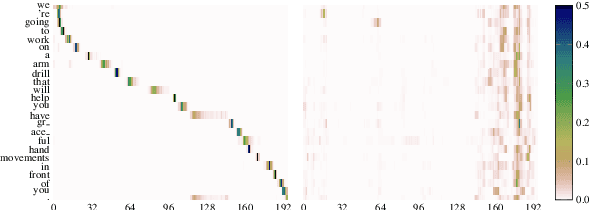
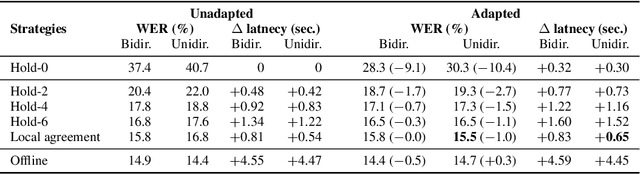
Encoder-decoder models provide a generic architecture for sequence-to-sequence tasks such as speech recognition and translation. While offline systems are often evaluated on quality metrics like word error rates (WER) and BLEU, latency is also a crucial factor in many practical use-cases. We propose three latency reduction techniques for chunk-based incremental inference and evaluate their efficiency in terms of accuracy-latency trade-off. On the 300-hour How2 dataset, we reduce latency by 83% to 0.8 second by sacrificing 1% WER (6% rel.) compared to offline transcription. Although our experiments use the Transformer, the hypothesis selection strategies are applicable to other encoder-decoder models. To avoid expensive re-computation, we use a unidirectionally-attending encoder. After an adaptation procedure to partial sequences, the unidirectional model performs on-par with the original model. We further show that our approach is also applicable to low-latency speech translation. On How2 English-Portuguese speech translation, we reduce latency to 0.7 second (-84% rel.) while incurring a loss of 2.4 BLEU points (5% rel.) compared to the offline system.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019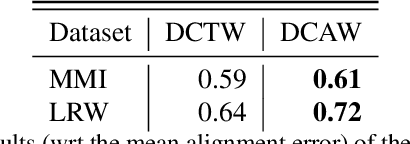
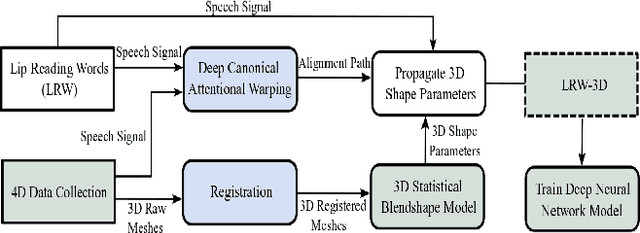

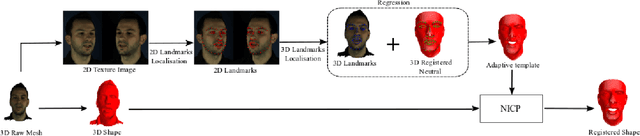
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.