 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deep Photonic Reservoir Computer for Speech Recognition
Dec 11, 2023
Speech recognition is a critical task in the field of artificial intelligence and has witnessed remarkable advancements thanks to large and complex neural networks, whose training process typically requires massive amounts of labeled data and computationally intensive operations. An alternative paradigm, reservoir computing, is energy efficient and is well adapted to implementation in physical substrates, but exhibits limitations in performance when compared to more resource-intensive machine learning algorithms. In this work we address this challenge by investigating different architectures of interconnected reservoirs, all falling under the umbrella of deep reservoir computing. We propose a photonic-based deep reservoir computer and evaluate its effectiveness on different speech recognition tasks. We show specific design choices that aim to simplify the practical implementation of a reservoir computer while simultaneously achieving high-speed processing of high-dimensional audio signals. Overall, with the present work we hope to help the advancement of low-power and high-performance neuromorphic hardware.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages
Co-speech gestures for human-robot collaboration
Nov 30, 2023Collaboration between human and robot requires effective modes of communication to assign robot tasks and coordinate activities. As communication can utilize different modalities, a multi-modal approach can be more expressive than single modal models alone. In this work we propose a co-speech gesture model that can assign robot tasks for human-robot collaboration. Human gestures and speech, detected by computer vision and speech recognition, can thus refer to objects in the scene and apply robot actions to them. We present an experimental evaluation of the multi-modal co-speech model with a real-world industrial use case. Results demonstrate that multi-modal communication is easy to achieve and can provide benefits for collaboration with respect to single modal tools.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023
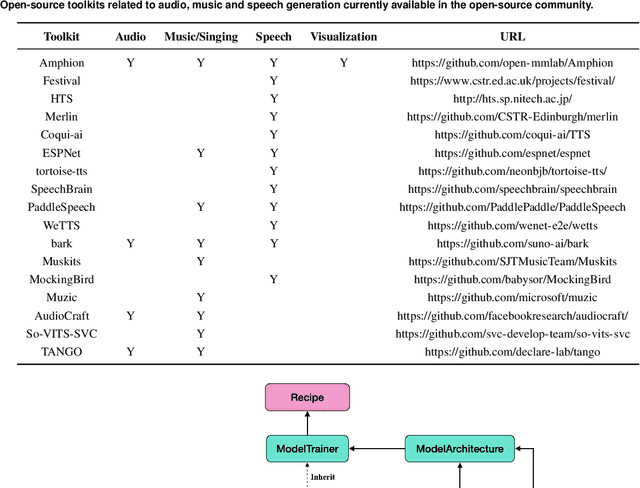
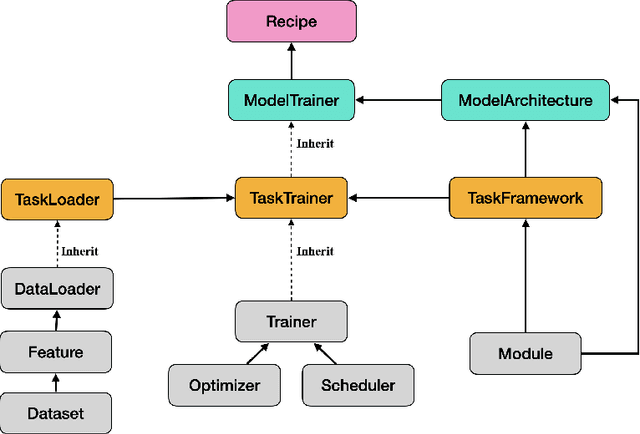
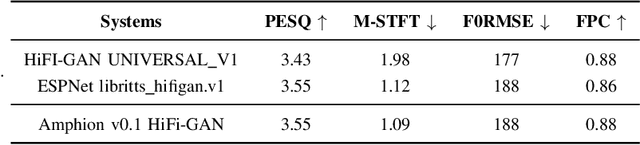
Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.
Head Orientation Estimation with Distributed Microphones Using Speech Radiation Patterns
Dec 04, 2023Determining the head orientation of a talker is not only beneficial for various speech signal processing applications, such as source localization or speech enhancement, but also facilitates intuitive voice control and interaction with smart environments or modern car assistants. Most approaches for head orientation estimation are based on visual cues. However, this requires camera systems which often are not available. We present an approach which purely uses audio signals captured with only a few distributed microphones around the talker. Specifically, we propose a novel method that directly incorporates measured or modeled speech radiation patterns to infer the talker's orientation during active speech periods based on a cosine similarity measure. Moreover, an automatic gain adjustment technique is proposed for uncalibrated, irregular microphone setups, such as ad-hoc sensor networks. In experiments with signals recorded in both anechoic and reverberant environments, the proposed method outperforms state-of-the-art approaches, using either measured or modeled speech radiation patterns.
Zero Shot Audio to Audio Emotion Transfer With Speaker Disentanglement
Jan 09, 2024The problem of audio-to-audio (A2A) style transfer involves replacing the style features of the source audio with those from the target audio while preserving the content related attributes of the source audio. In this paper, we propose an efficient approach, termed as Zero-shot Emotion Style Transfer (ZEST), that allows the transfer of emotional content present in the given source audio with the one embedded in the target audio while retaining the speaker and speech content from the source. The proposed system builds upon decomposing speech into semantic tokens, speaker representations and emotion embeddings. Using these factors, we propose a framework to reconstruct the pitch contour of the given speech signal and train a decoder that reconstructs the speech signal. The model is trained using a self-supervision based reconstruction loss. During conversion, the emotion embedding is alone derived from the target audio, while rest of the factors are derived from the source audio. In our experiments, we show that, even without using parallel training data or labels from the source or target audio, we illustrate zero shot emotion transfer capabilities of the proposed ZEST model using objective and subjective quality evaluations.
Transfer the linguistic representations from TTS to accent conversion with non-parallel data
Jan 07, 2024Accent conversion aims to convert the accent of a source speech to a target accent, meanwhile preserving the speaker's identity. This paper introduces a novel non-autoregressive framework for accent conversion that learns accent-agnostic linguistic representations and employs them to convert the accent in the source speech. Specifically, the proposed system aligns speech representations with linguistic representations obtained from Text-to-Speech (TTS) systems, enabling training of the accent voice conversion model on non-parallel data. Furthermore, we investigate the effectiveness of a pretraining strategy on native data and different acoustic features within our proposed framework. We conduct a comprehensive evaluation using both subjective and objective metrics to assess the performance of our approach. The evaluation results highlight the benefits of the pretraining strategy and the incorporation of richer semantic features, resulting in significantly enhanced audio quality and intelligibility.
LitE-SNN: Designing Lightweight and Efficient Spiking Neural Network through Spatial-Temporal Compressive Network Search and Joint Optimization
Jan 26, 2024Spiking Neural Networks (SNNs) mimic the information-processing mechanisms of the human brain and are highly energy-efficient, making them well-suited for low-power edge devices. However, the pursuit of accuracy in current studies leads to large, long-timestep SNNs, conflicting with the resource constraints of these devices. In order to design lightweight and efficient SNNs, we propose a new approach named LitESNN that incorporates both spatial and temporal compression into the automated network design process. Spatially, we present a novel Compressive Convolution block (CompConv) to expand the search space to support pruning and mixed-precision quantization while utilizing the shared weights and pruning mask to reduce the computation. Temporally, we are the first to propose a compressive timestep search to identify the optimal number of timesteps under specific computation cost constraints. Finally, we formulate a joint optimization to simultaneously learn the architecture parameters and spatial-temporal compression strategies to achieve high performance while minimizing memory and computation costs. Experimental results on CIFAR10, CIFAR100, and Google Speech Command datasets demonstrate our proposed LitESNNs can achieve competitive or even higher accuracy with remarkably smaller model sizes and fewer computation costs. Furthermore, we validate the effectiveness of our LitESNN on the trade-off between accuracy and resource cost and show the superiority of our joint optimization. Additionally, we conduct energy analysis to further confirm the energy efficiency of LitESNN
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.