 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Universal Adversarial Perturbations for Speech Recognition Systems
May 09, 2019
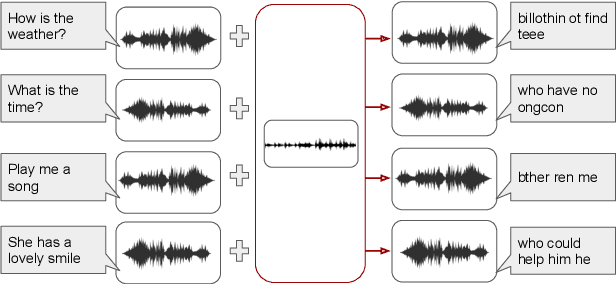
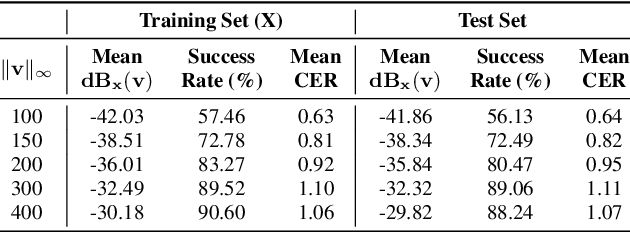
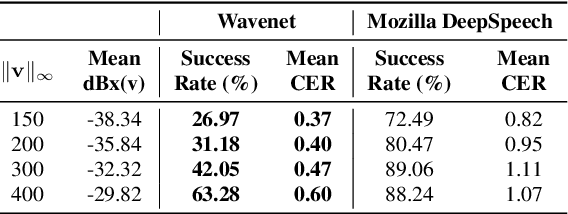
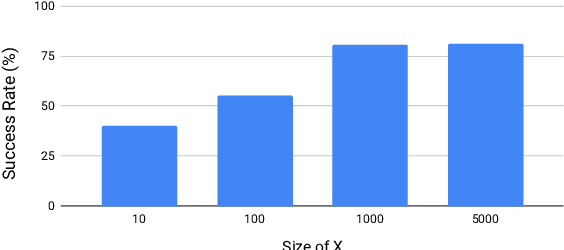
In this work, we demonstrate the existence of universal adversarial audio perturbations that cause mis-transcription of audio signals by automatic speech recognition (ASR) systems. We propose an algorithm to find a single quasi-imperceptible perturbation, which when added to any arbitrary speech signal, will most likely fool the victim speech recognition model. Our experiments demonstrate the application of our proposed technique by crafting audio-agnostic universal perturbations for the state-of-the-art ASR system -- Mozilla DeepSpeech. Additionally, we show that such perturbations generalize to a significant extent across models that are not available during training, by performing a transferability test on a WaveNet based ASR system.
Phone Duration Modeling for Speaker Age Estimation in Children
Sep 03, 2021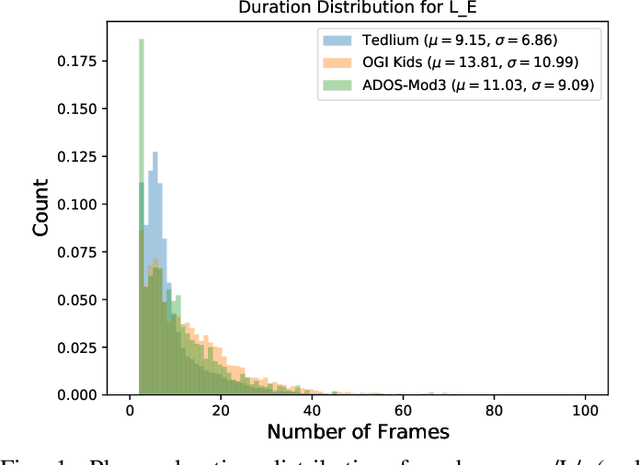
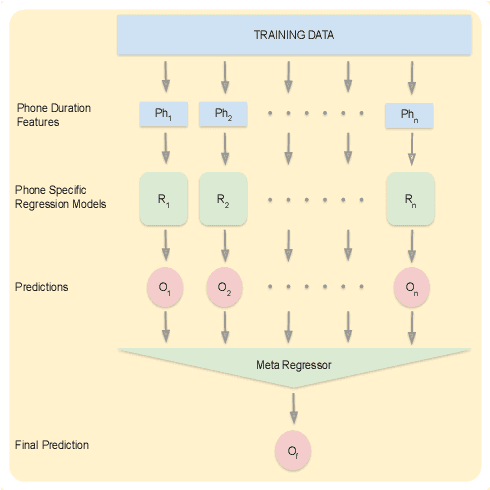
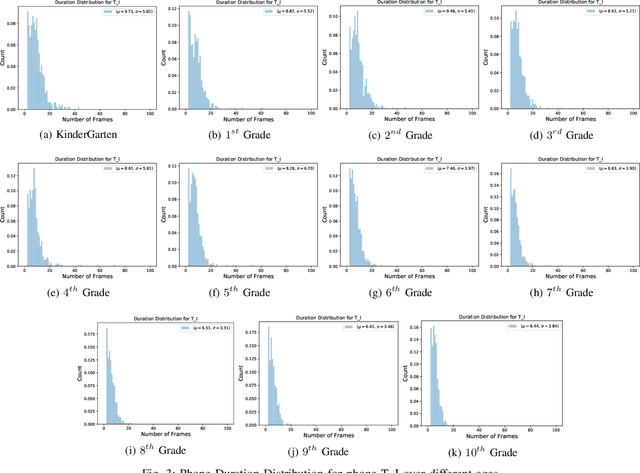
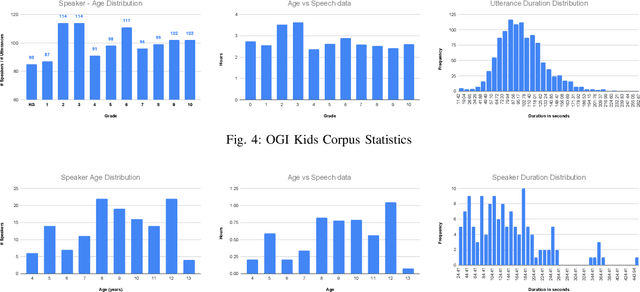
Automatic inference of important paralinguistic information such as age from speech is an important area of research with numerous spoken language technology based applications. Speaker age estimation has applications in enabling personalization and age-appropriate curation of information and content. However, research in speaker age estimation in children is especially challenging due to paucity of relevant speech data representing the developmental spectrum, and the high signal variability especially intra age variability that complicates modeling. Most approaches in children speaker age estimation adopt methods directly from research on adult speech processing. In this paper, we propose features specific to children and focus on speaker's phone duration as an important biomarker of children's age. We propose phone duration modeling for predicting age from child's speech. To enable that, children speech is first forced aligned with the corresponding transcription to derive phone duration distributions. Statistical functionals are computed from phone duration distributions for each phoneme which are in turn used to train regression models to predict speaker age. Two children speech datasets are employed to demonstrate the robustness of phone duration features. We perform age regression experiments on age categories ranging from children studying in kindergarten to grade 10. Experimental results suggest phone durations contain important development-related information of children. Phonemes contributing most to estimation of children speaker age are analyzed and presented.
Breaking the Data Barrier: Towards Robust Speech Translation via Adversarial Stability Training
Oct 08, 2019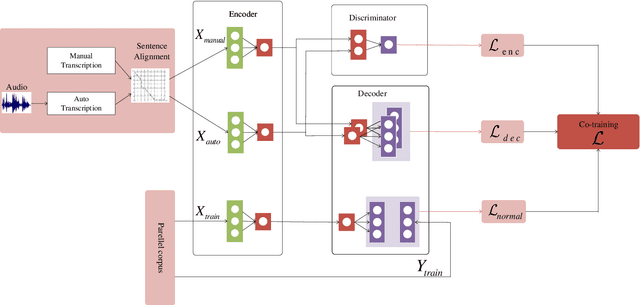
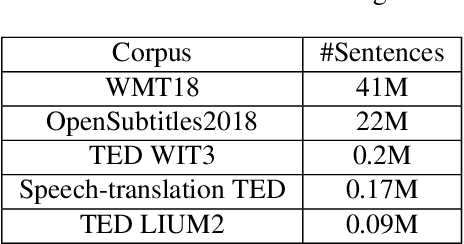
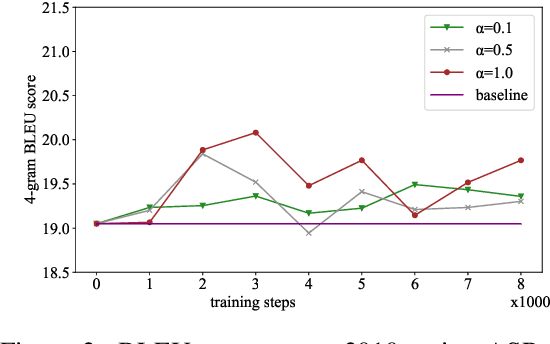
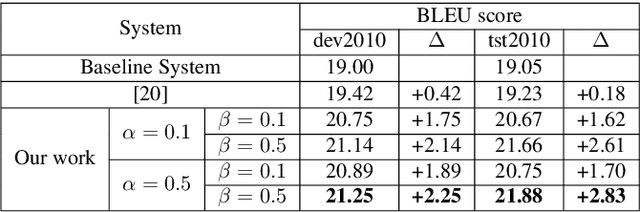
In a pipeline speech translation system, automatic speech recognition (ASR) system will transmit errors in recognition to the downstream machine translation (MT) system. A standard machine translation system is usually trained on parallel corpus composed of clean text and will perform poorly on text with recognition noise, a gap well known in speech translation community. In this paper, we propose a training architecture which aims at making a neural machine translation model more robust against speech recognition errors. Our approach addresses the encoder and the decoder simultaneously using adversarial learning and data augmentation, respectively. Experimental results on IWSLT2018 speech translation task show that our approach can bridge the gap between the ASR output and the MT input, outperforms the baseline by up to 2.83 BLEU on noisy ASR output, while maintaining close performance on clean text.
ATCSpeech: a multilingual pilot-controller speech corpus from real Air Traffic Control environment
Nov 26, 2019
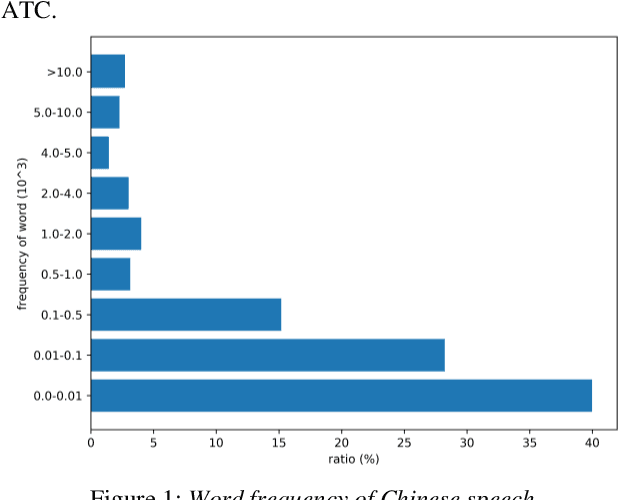
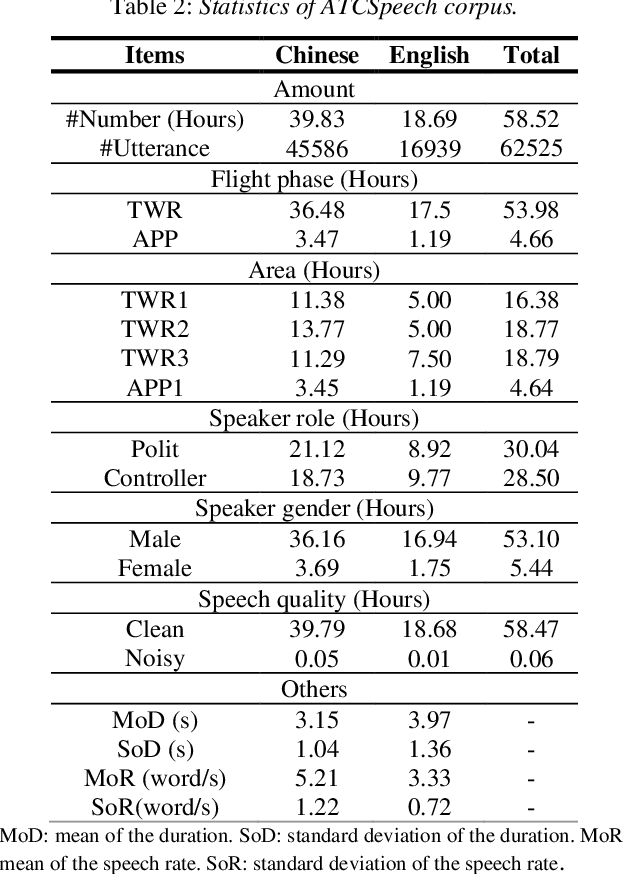
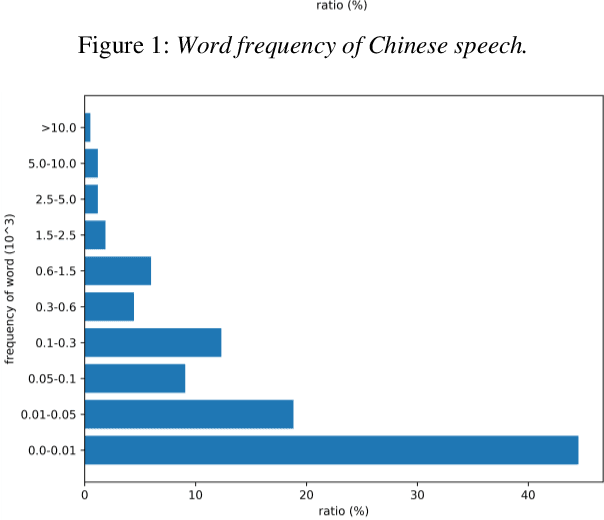
Automatic Speech Recognition (ASR) is greatly developed in recent years, which expedites many applications on other fields. For the ASR research, speech corpus is always an essential foundation, especially for the vertical industry, such as Air Traffic Control (ATC). There are some speech corpora for common applications, public or paid. However, for the ATC, it is difficult to collect raw speeches from real systems due to safety issues. More importantly, for a supervised learning task like ASR, annotating the transcription is a more laborious work, which hugely restricts the prospect of ASR application. In this paper, a multilingual speech corpus (ATCSpeech) from real ATC systems, including accented Mandarin Chinese and English, is built and released to encourage the non-commercial ASR research in ATC domain. The corpus is detailly introduced from the perspective of data amount, speaker gender and role, speech quality and other attributions. In addition, the performance of our baseline ASR models is also reported. A community edition for our speech database can be applied and used under a special contrast. To our best knowledge, this is the first work that aims at building a real and multilingual ASR corpus for the air traffic related research.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
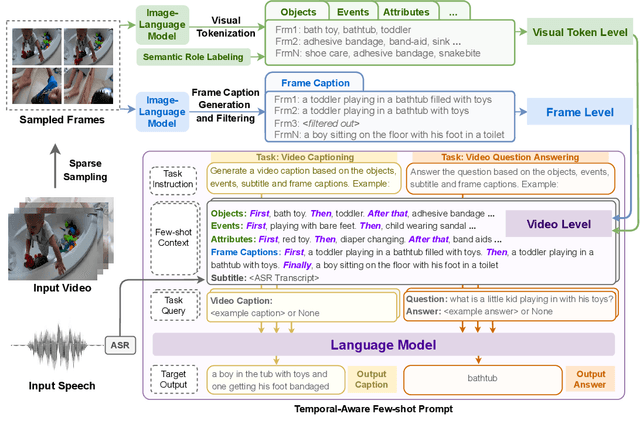
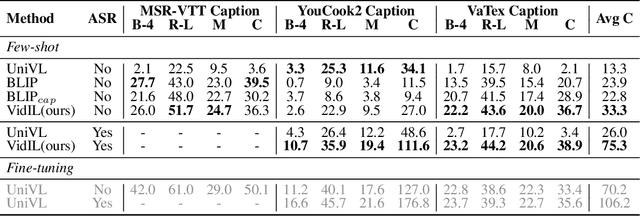

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Survey on Deep Neural Networks in Speech and Vision Systems
Aug 16, 2019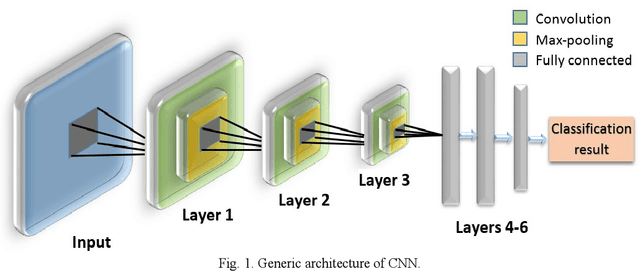
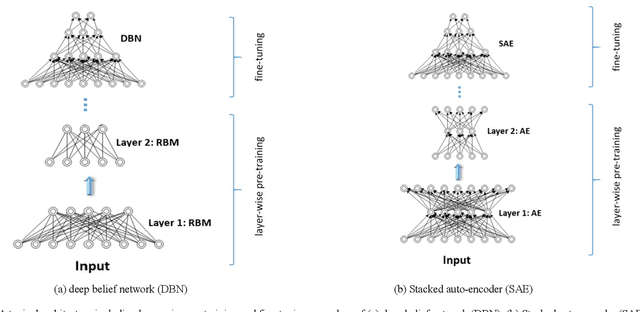
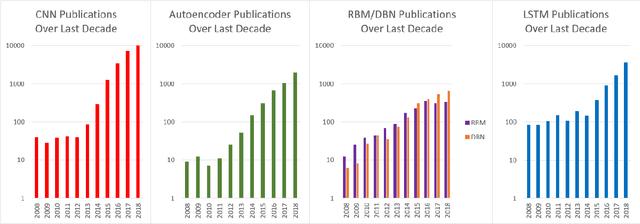
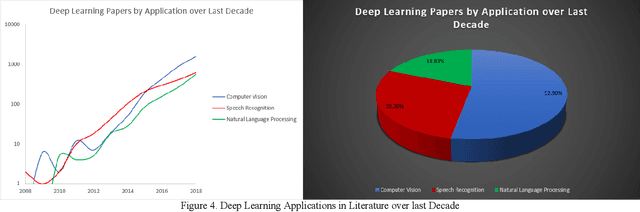
This survey presents a review of state-of-the-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advances in deep artificial neural network algorithms and architectures have spurred rapid innovation and development of intelligent vision and speech systems. With availability of vast amounts of sensor data and cloud computing for processing and training of deep neural networks, and with increased sophistication in mobile and embedded technology, the next-generation intelligent systems are poised to revolutionize personal and commercial computing. This survey begins by providing background and evolution of some of the most successful deep learning models for intelligent vision and speech systems to date. An overview of large-scale industrial research and development efforts is provided to emphasize future trends and prospects of intelligent vision and speech systems. Robust and efficient intelligent systems demand low-latency and high fidelity in resource constrained hardware platforms such as mobile devices, robots, and automobiles. Therefore, this survey also provides a summary of key challenges and recent successes in running deep neural networks on hardware-restricted platforms, i.e. within limited memory, battery life, and processing capabilities. Finally, emerging applications of vision and speech across disciplines such as affective computing, intelligent transportation, and precision medicine are discussed. To our knowledge, this paper provides one of the most comprehensive surveys on the latest developments in intelligent vision and speech applications from the perspectives of both software and hardware systems. Many of these emerging technologies using deep neural networks show tremendous promise to revolutionize research and development for future vision and speech systems.
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020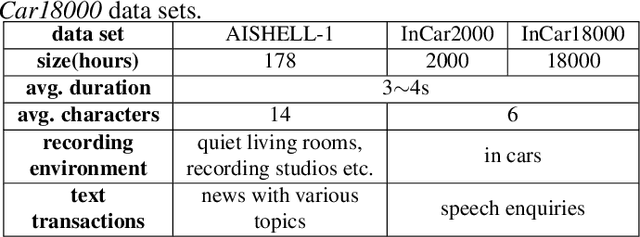
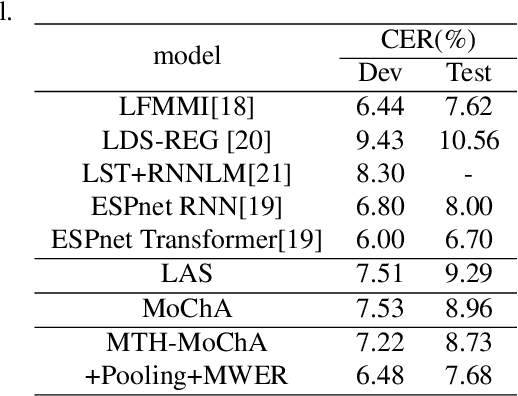
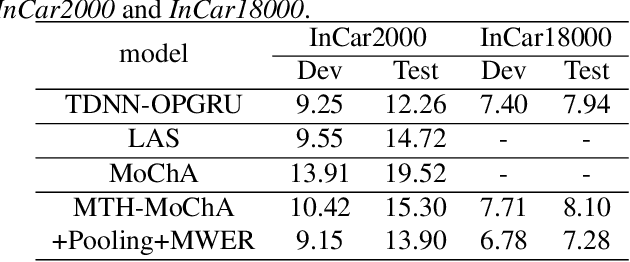
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.
Revisiting the Boundary between ASR and NLU in the Age of Conversational Dialog Systems
Dec 10, 2021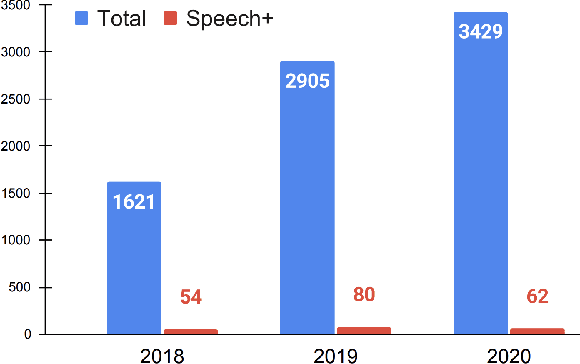

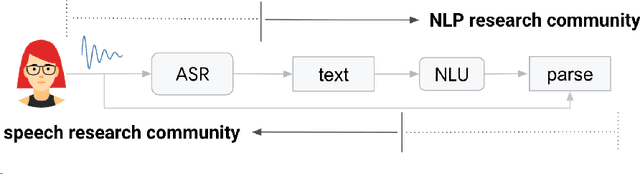
As more users across the world are interacting with dialog agents in their daily life, there is a need for better speech understanding that calls for renewed attention to the dynamics between research in automatic speech recognition (ASR) and natural language understanding (NLU). We briefly review these research areas and lay out the current relationship between them. In light of the observations we make in this paper, we argue that (1) NLU should be cognizant of the presence of ASR models being used upstream in a dialog system's pipeline, (2) ASR should be able to learn from errors found in NLU, (3) there is a need for end-to-end datasets that provide semantic annotations on spoken input, (4) there should be stronger collaboration between ASR and NLU research communities.
A survey on recently proposed activation functions for Deep Learning
Apr 07, 2022
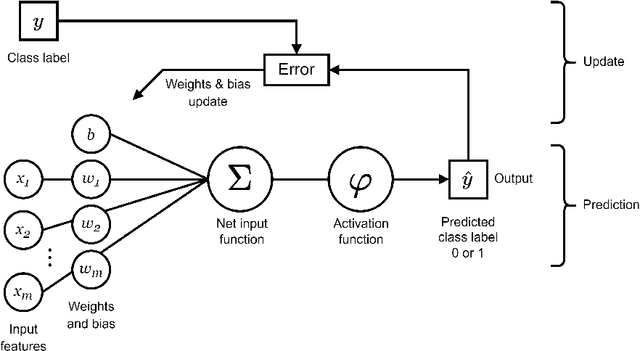
Artificial neural networks (ANN), typically referred to as neural networks, are a class of Machine Learning algorithms and have achieved widespread success, having been inspired by the biological structure of the human brain. Neural networks are inherently powerful due to their ability to learn complex function approximations from data. This generalization ability has been able to impact multidisciplinary areas involving image recognition, speech recognition, natural language processing, and others. Activation functions are a crucial sub-component of neural networks. They define the output of a node in the network given a set of inputs. This survey discusses the main concepts of activation functions in neural networks, including; a brief introduction to deep neural networks, a summary of what are activation functions and how they are used in neural networks, their most common properties, the different types of activation functions, some of the challenges, limitations, and alternative solutions faced by activation functions, concluding with the final remarks.
Transformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Jan 15, 2020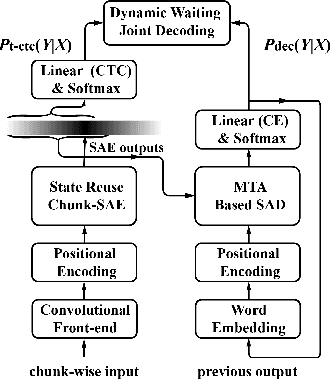

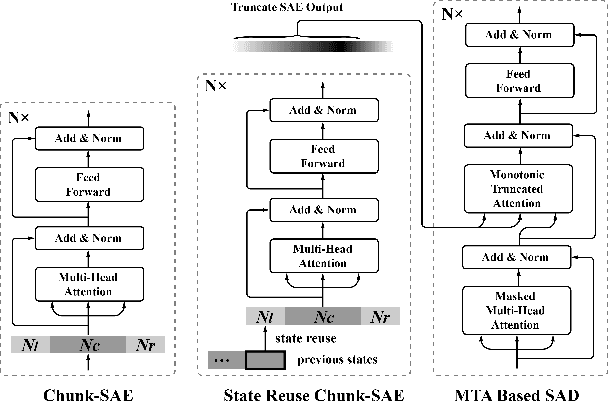
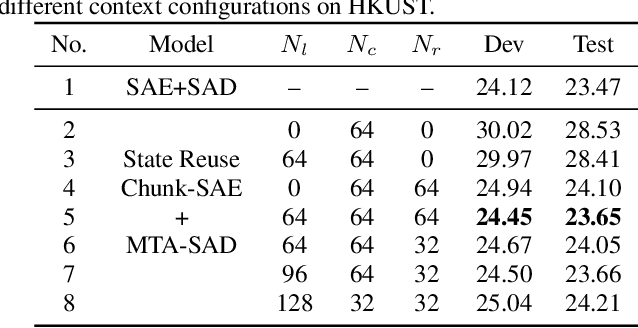
Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as $0.19\%$ absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.