 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving Word Recognition in Speech Transcriptions by Decision-level Fusion of Stemming and Two-way Phoneme Pruning
Jul 26, 2021

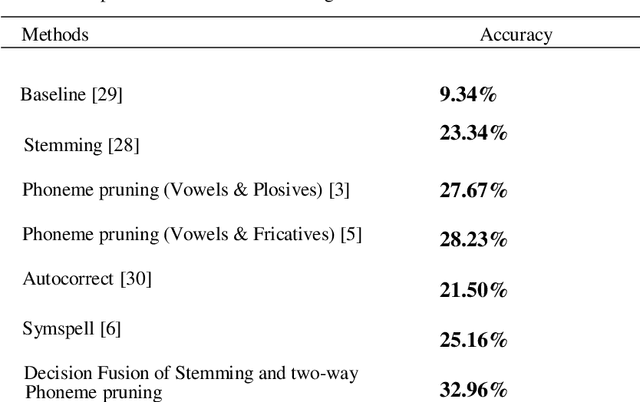


We introduce an unsupervised approach for correcting highly imperfect speech transcriptions based on a decision-level fusion of stemming and two-way phoneme pruning. Transcripts are acquired from videos by extracting audio using Ffmpeg framework and further converting audio to text transcript using Google API. In the benchmark LRW dataset, there are 500 word categories, and 50 videos per class in mp4 format. All videos consist of 29 frames (each 1.16 s long) and the word appears in the middle of the video. In our approach we tried to improve the baseline accuracy from 9.34% by using stemming, phoneme extraction, filtering and pruning. After applying the stemming algorithm to the text transcript and evaluating the results, we achieved 23.34% accuracy in word recognition. To convert words to phonemes we used the Carnegie Mellon University (CMU) pronouncing dictionary that provides a phonetic mapping of English words to their pronunciations. A two-way phoneme pruning is proposed that comprises of the two non-sequential steps: 1) filtering and pruning the phonemes containing vowels and plosives 2) filtering and pruning the phonemes containing vowels and fricatives. After obtaining results of stemming and two-way phoneme pruning, we applied decision-level fusion and that led to an improvement of word recognition rate upto 32.96%.
Are Neural Open-Domain Dialog Systems Robust to Speech Recognition Errors in the Dialog History? An Empirical Study
Aug 18, 2020
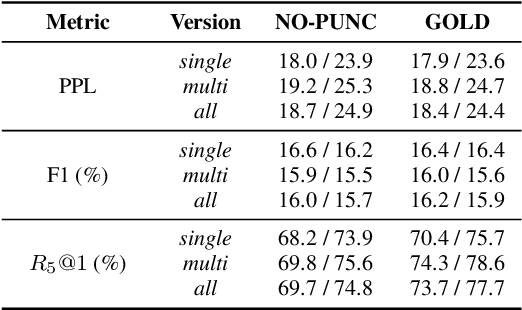

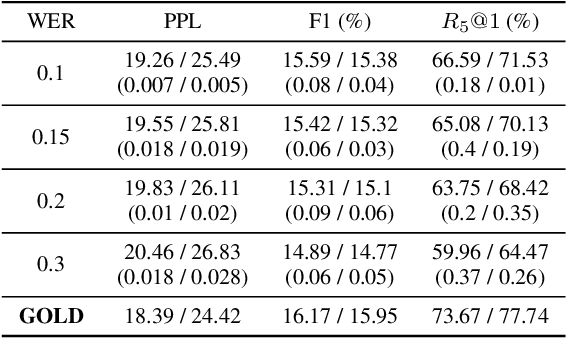
Large end-to-end neural open-domain chatbots are becoming increasingly popular. However, research on building such chatbots has typically assumed that the user input is written in nature and it is not clear whether these chatbots would seamlessly integrate with automatic speech recognition (ASR) models to serve the speech modality. We aim to bring attention to this important question by empirically studying the effects of various types of synthetic and actual ASR hypotheses in the dialog history on TransferTransfo, a state-of-the-art Generative Pre-trained Transformer (GPT) based neural open-domain dialog system from the NeurIPS ConvAI2 challenge. We observe that TransferTransfo trained on written data is very sensitive to such hypotheses introduced to the dialog history during inference time. As a baseline mitigation strategy, we introduce synthetic ASR hypotheses to the dialog history during training and observe marginal improvements, demonstrating the need for further research into techniques to make end-to-end open-domain chatbots fully speech-robust. To the best of our knowledge, this is the first study to evaluate the effects of synthetic and actual ASR hypotheses on a state-of-the-art neural open-domain dialog system and we hope it promotes speech-robustness as an evaluation criterion in open-domain dialog.
Speech Recognition for Endangered and Extinct Samoyedic languages
Dec 09, 2020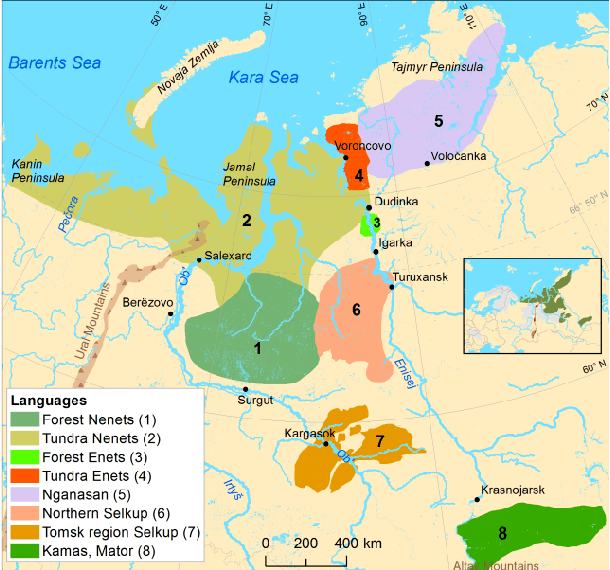
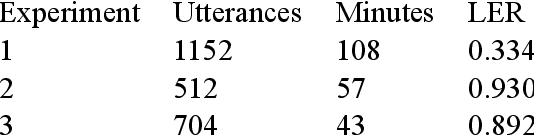

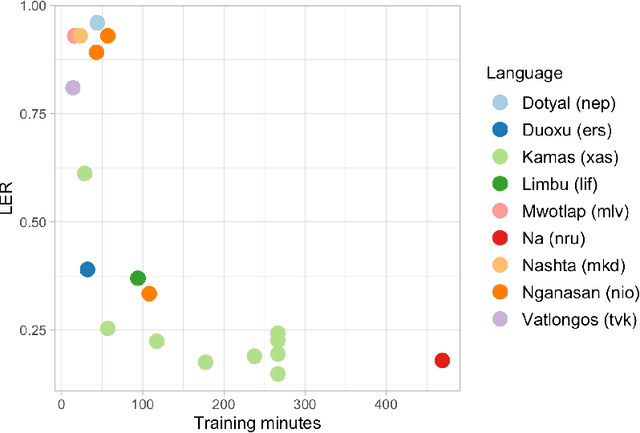
Our study presents a series of experiments on speech recognition with endangered and extinct Samoyedic languages, spoken in Northern and Southern Siberia. To best of our knowledge, this is the first time a functional ASR system is built for an extinct language. We achieve with Kamas language a Label Error Rate of 15\%, and conclude through careful error analysis that this quality is already very useful as a starting point for refined human transcriptions. Our results with related Nganasan language are more modest, with best model having the error rate of 33\%. We show, however, through experiments where Kamas training data is enlarged incrementally, that Nganasan results are in line with what is expected under low-resource circumstances of the language. Based on this, we provide recommendations for scenarios in which further language documentation or archive processing activities could benefit from modern ASR technology. All training data and processing scripts haven been published on Zenodo with clear licences to ensure further work in this important topic.
3-D Feature and Acoustic Modeling for Far-Field Speech Recognition
Nov 13, 2019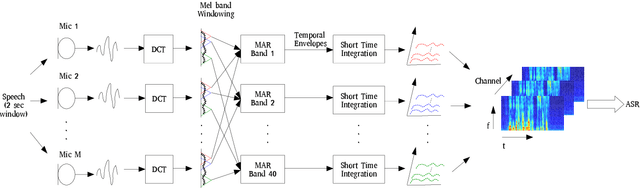
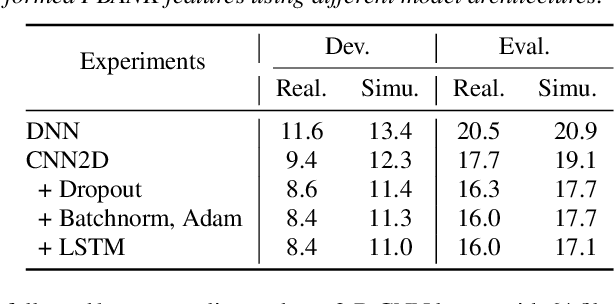

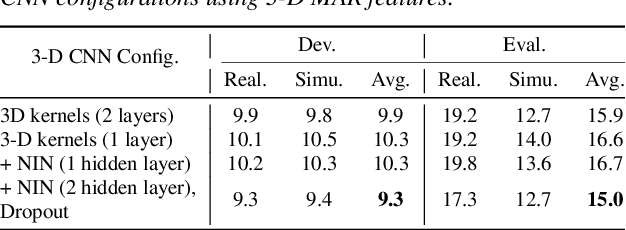
Automatic speech recognition in multi-channel reverberant conditions is a challenging task. The conventional way of suppressing the reverberation artifacts involves a beamforming based enhancement of the multi-channel speech signal, which is used to extract spectrogram based features for a neural network acoustic model. In this paper, we propose to extract features directly from the multi-channel speech signal using a multi variate autoregressive (MAR) modeling approach, where the correlations among all the three dimensions of time, frequency and channel are exploited. The MAR features are fed to a convolutional neural network (CNN) architecture which performs the joint acoustic modeling on the three dimensions. The 3-D CNN architecture allows the combination of multi-channel features that optimize the speech recognition cost compared to the traditional beamforming models that focus on the enhancement task. Experiments are conducted on the CHiME-3 and REVERB Challenge dataset using multi-channel reverberant speech. In these experiments, the proposed 3-D feature and acoustic modeling approach provides significant improvements over an ASR system trained with beamformed audio (average relative improvements of 10 % and 9 % in word error rates for CHiME-3 and REVERB Challenge datasets respectively.
Emotion Intensity and its Control for Emotional Voice Conversion
Jan 10, 2022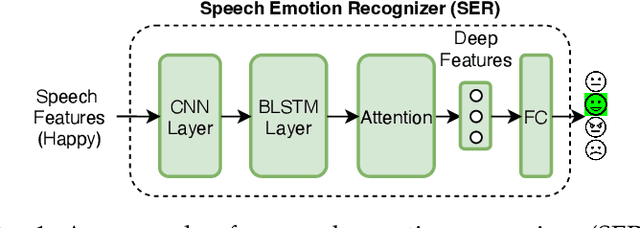

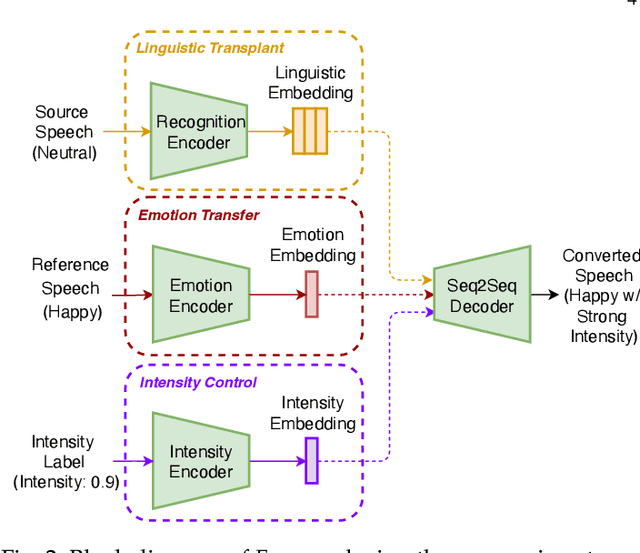

Emotional voice conversion (EVC) seeks to convert the emotional state of an utterance while preserving the linguistic content and speaker identity. In EVC, emotions are usually treated as discrete categories overlooking the fact that speech also conveys emotions with various intensity levels that the listener can perceive. In this paper, we aim to explicitly characterize and control the intensity of emotion. We propose to disentangle the speaker style from linguistic content and encode the speaker style into a style embedding in a continuous space that forms the prototype of emotion embedding. We further learn the actual emotion encoder from an emotion-labelled database and study the use of relative attributes to represent fine-grained emotion intensity. To ensure emotional intelligibility, we incorporate emotion classification loss and emotion embedding similarity loss into the training of the EVC network. As desired, the proposed network controls the fine-grained emotion intensity in the output speech. Through both objective and subjective evaluations, we validate the effectiveness of the proposed network for emotional expressiveness and emotion intensity control.
The Vicomtech Audio Deepfake Detection System based on Wav2Vec2 for the 2022 ADD Challenge
Mar 03, 2022
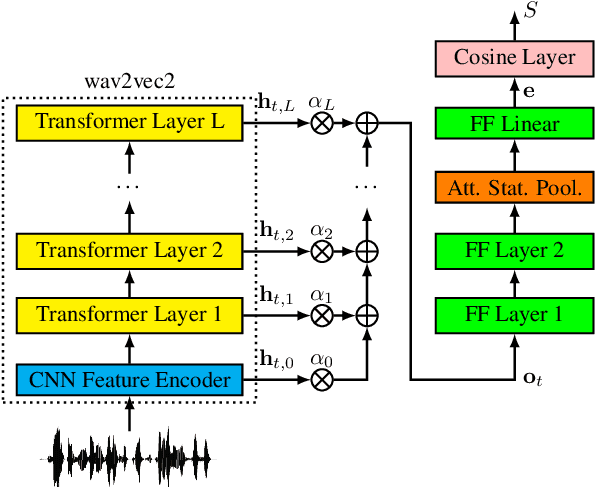
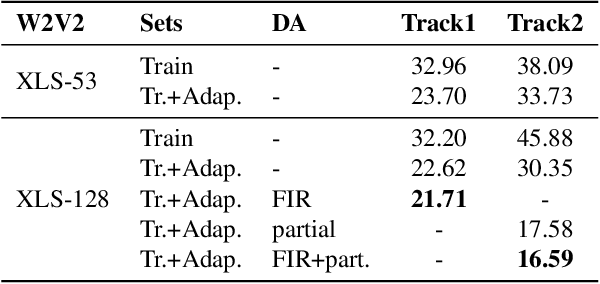
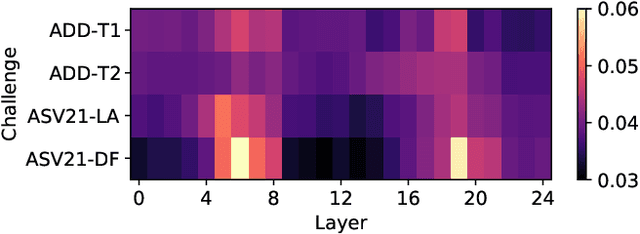
This paper describes our submitted systems to the 2022 ADD challenge withing the tracks 1 and 2. Our approach is based on the combination of a pre-trained wav2vec2 feature extractor and a downstream classifier to detect spoofed audio. This method exploits the contextualized speech representations at the different transformer layers to fully capture discriminative information. Furthermore, the classification model is adapted to the application scenario using different data augmentation techniques. We evaluate our system for audio synthesis detection in both the ASVspoof 2021 and the 2022 ADD challenges, showing its robustness and good performance in realistic challenging environments such as telephonic and audio codec systems, noisy audio, and partial deepfakes.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
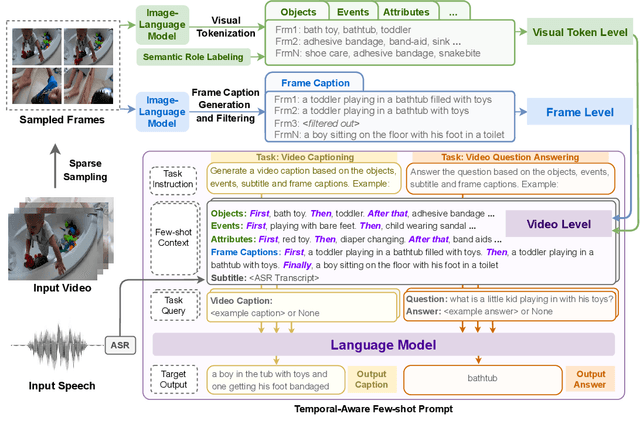
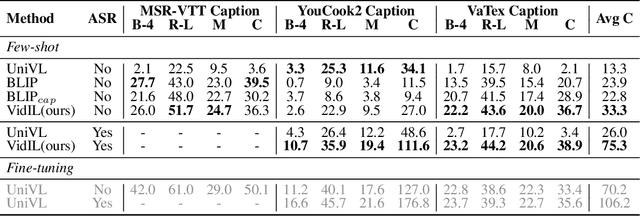

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Analyzing the Quality and Stability of a Streaming End-to-End On-Device Speech Recognizer
Jun 02, 2020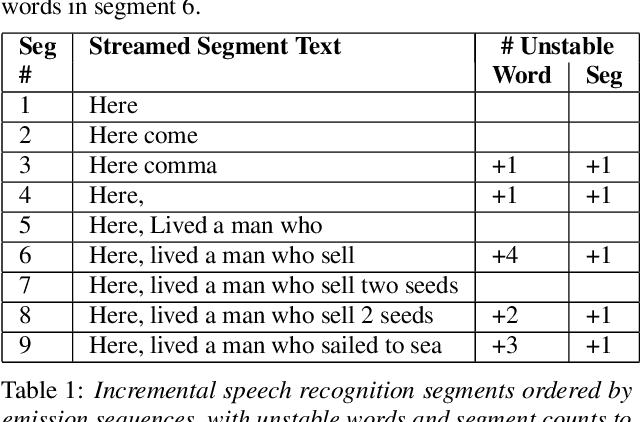
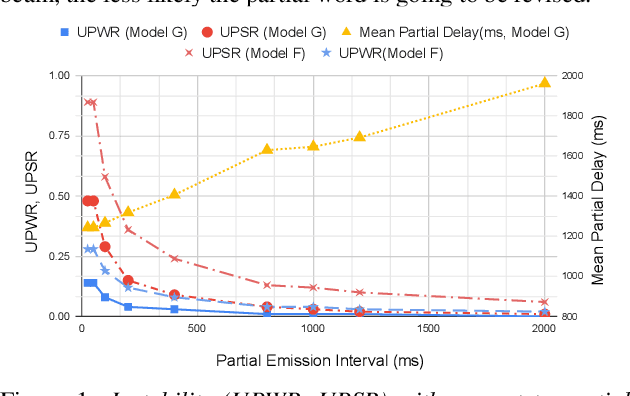
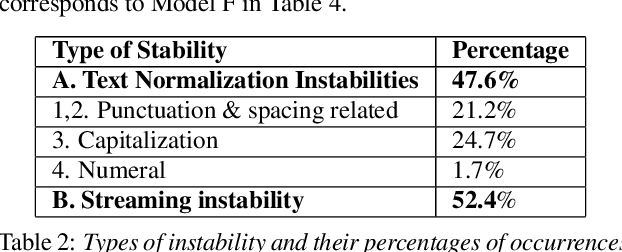
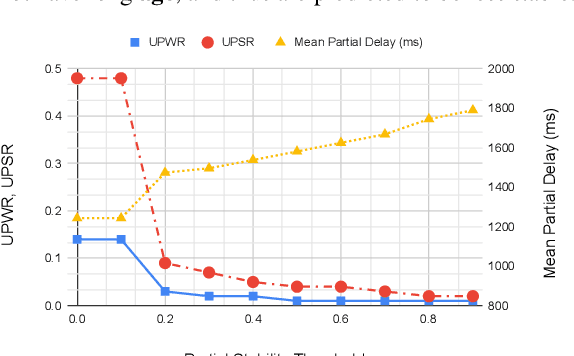
The demand for fast and accurate incremental speech recognition increases as the applications of automatic speech recognition (ASR) proliferate. Incremental speech recognizers output chunks of partially recognized words while the user is still talking. Partial results can be revised before the ASR finalizes its hypothesis, causing instability issues. We analyze the quality and stability of on-device streaming end-to-end (E2E) ASR models. We first introduce a novel set of metrics that quantify the instability at word and segment levels. We study the impact of several model training techniques that improve E2E model qualities but degrade model stability. We categorize the causes of instability and explore various solutions to mitigate them in a streaming E2E ASR system. Index Terms: ASR, stability, end-to-end, text normalization,on-device, RNN-T
Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech
Sep 14, 2019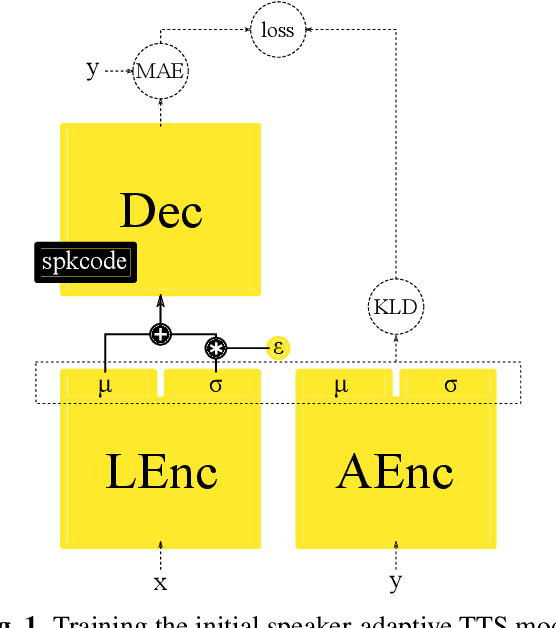
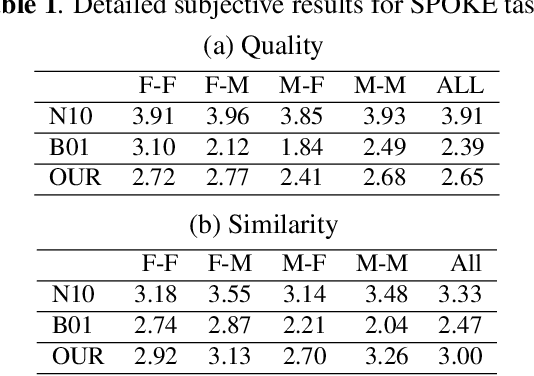
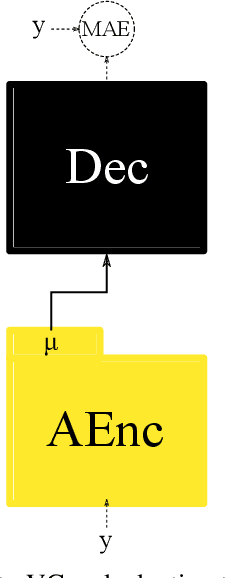
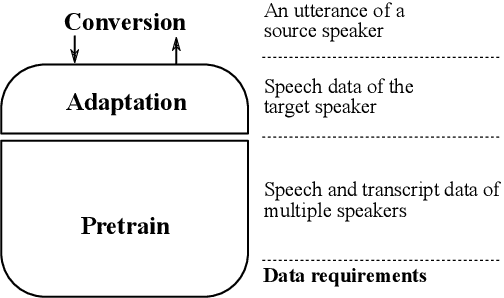
Voice conversion (VC) and text-to-speech (TTS) are two tasks that share a similar objective, generating speech with a target voice. However, they are usually developed independently under vastly different frameworks. In this paper, we propose a methodology to bootstrap a VC system from a pretrained speaker-adaptive TTS model and unify the techniques as well as the interpretations of these two tasks. Moreover by offloading the heavy data demand to the training stage of the TTS model, our VC system can be built using a small amount of target speaker speech data. It also opens up the possibility of using speech in a foreign unseen language to build the system. Our subjective evaluations show that the proposed framework is able to not only achieve competitive performance in the standard intra-language scenario but also adapt and convert using speech utterances in an unseen language.
A survey on recently proposed activation functions for Deep Learning
Apr 07, 2022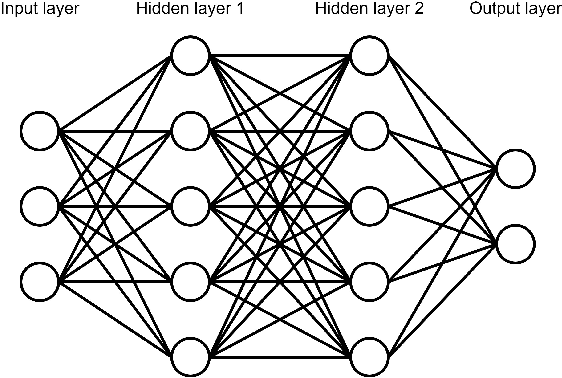
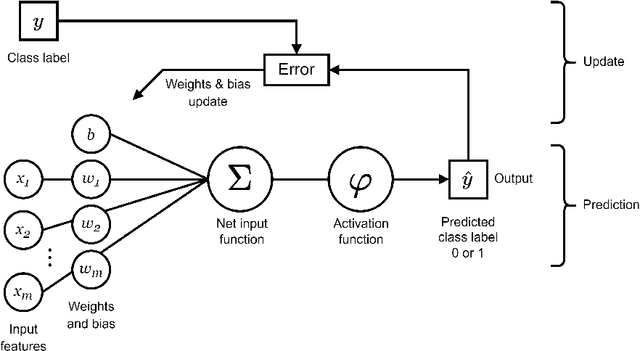
Artificial neural networks (ANN), typically referred to as neural networks, are a class of Machine Learning algorithms and have achieved widespread success, having been inspired by the biological structure of the human brain. Neural networks are inherently powerful due to their ability to learn complex function approximations from data. This generalization ability has been able to impact multidisciplinary areas involving image recognition, speech recognition, natural language processing, and others. Activation functions are a crucial sub-component of neural networks. They define the output of a node in the network given a set of inputs. This survey discusses the main concepts of activation functions in neural networks, including; a brief introduction to deep neural networks, a summary of what are activation functions and how they are used in neural networks, their most common properties, the different types of activation functions, some of the challenges, limitations, and alternative solutions faced by activation functions, concluding with the final remarks.