 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evolution of Part-of-Speech in Classical Chinese
Sep 23, 2020
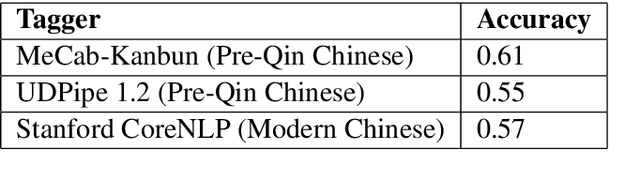
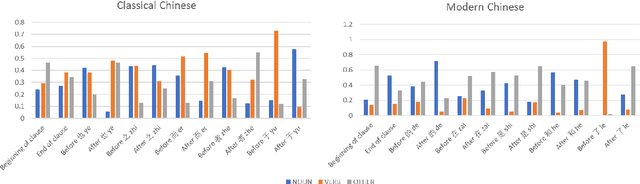

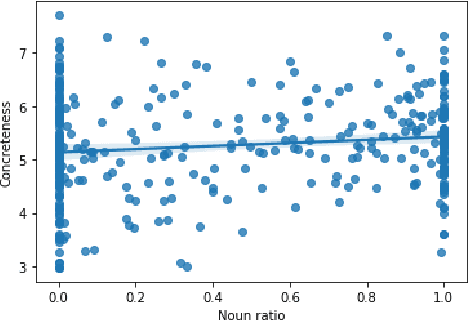
Classical Chinese is a language notable for its word class flexibility: the same word may often be used as a noun or a verb. Bisang (2008) claimed that Classical Chinese is a precategorical language, where the syntactic position of a word determines its part-of-speech category. In this paper, we apply entropy-based metrics to evaluate these claims on historical corpora. We further explore differences between nouns and verbs in Classical Chinese: using psycholinguistic norms, we find a positive correlation between concreteness and noun usage. Finally, we align character embeddings from Classical and Modern Chinese, and find that verbs undergo more semantic change than nouns.
Pre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 21, 2022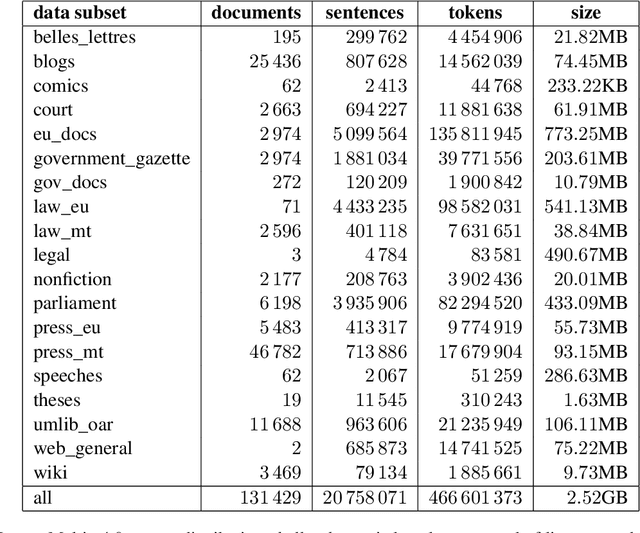
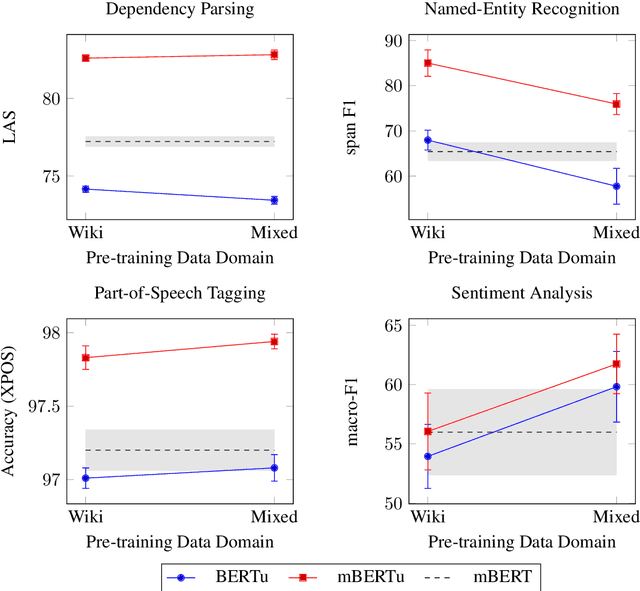
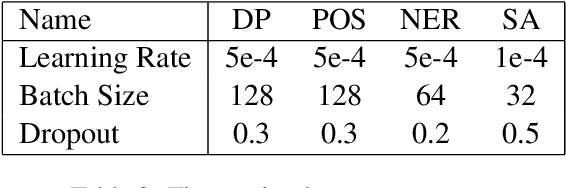
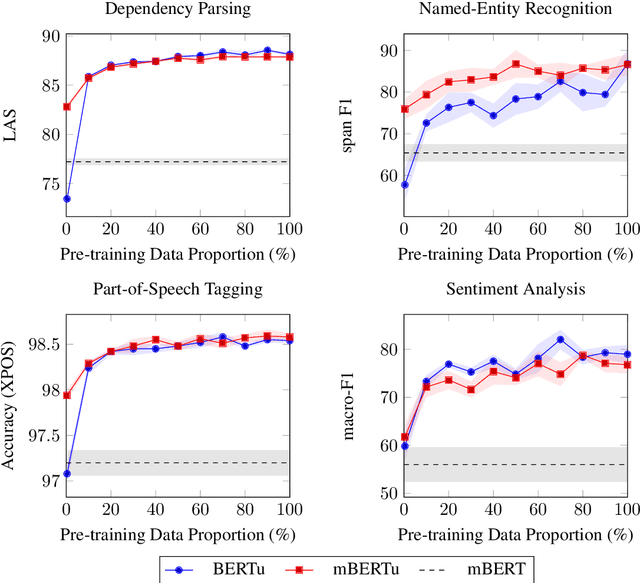
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.
A high quality and phonetic balanced speech corpus for Vietnamese
Apr 11, 2019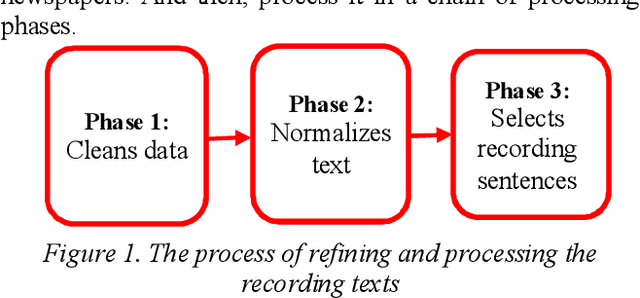
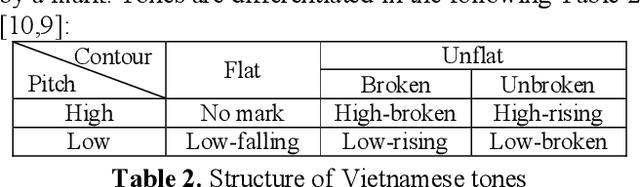
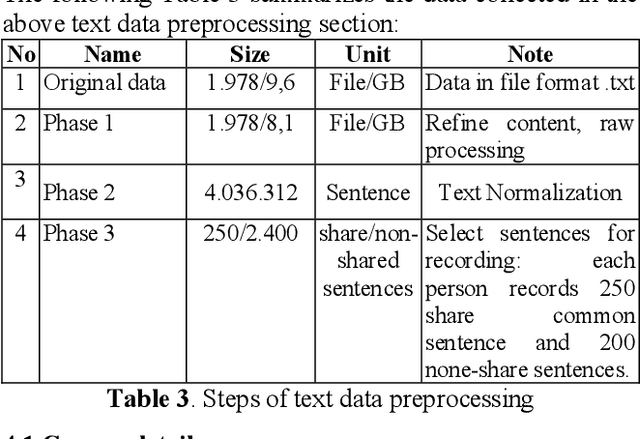
This paper presents a high quality Vietnamese speech corpus that can be used for analyzing Vietnamese speech characteristic as well as building speech synthesis models. The corpus consists of 5400 clean-speech utterances spoken by 12 speakers including 6 males and 6 females. The corpus is designed with phonetic balanced in mind so that it can be used for speech synthesis, especially, speech adaptation approaches. Specifically, all speakers utter a common dataset contains 250 phonetic balanced sentences. To increase the variety of speech context, each speaker also utters another 200 non-shared, phonetic-balanced sentences. The speakers are selected to cover a wide range of age and come from different regions of the North of Vietnam. The audios are recorded in a soundproof studio room, they are sampling at 48 kHz, 16 bits PCM, mono channel.
* 5 pages
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020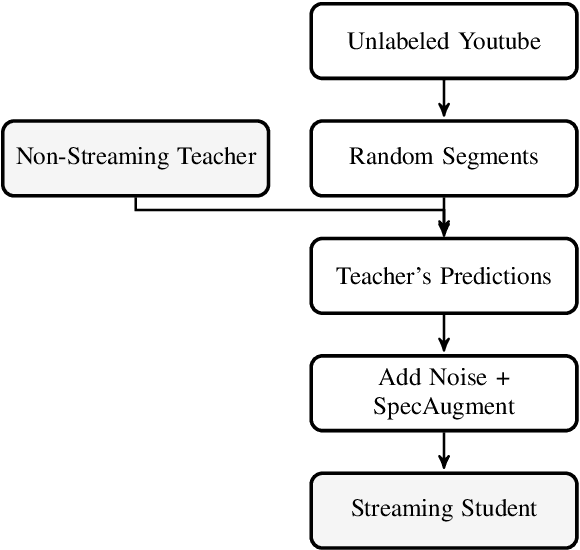
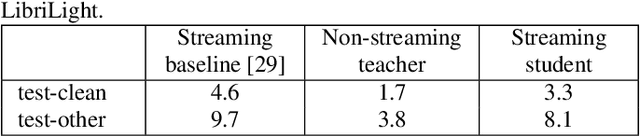
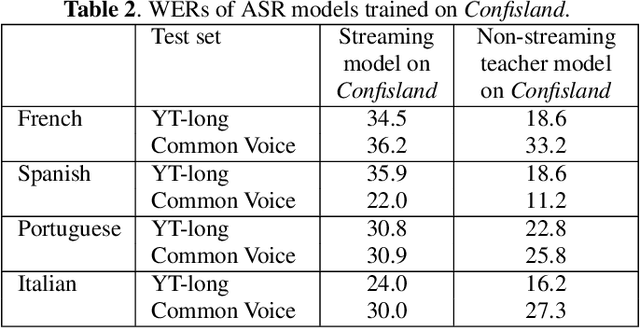
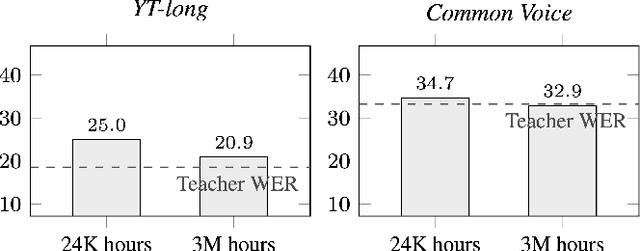
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
Don't shoot butterfly with rifles: Multi-channel Continuous Speech Separation with Early Exit Transformer
Oct 23, 2020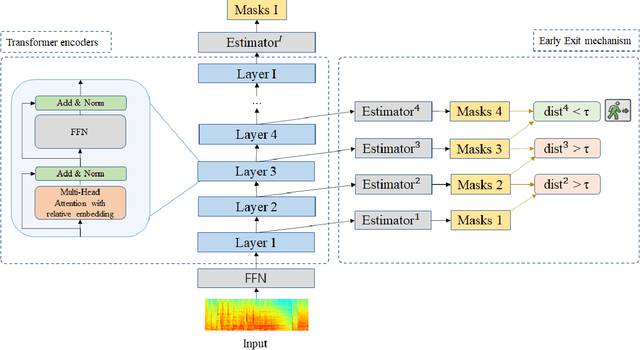
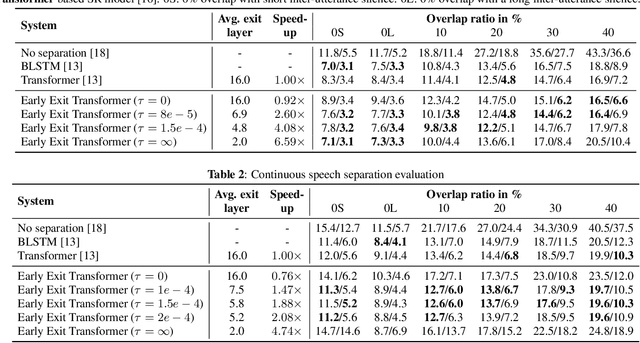
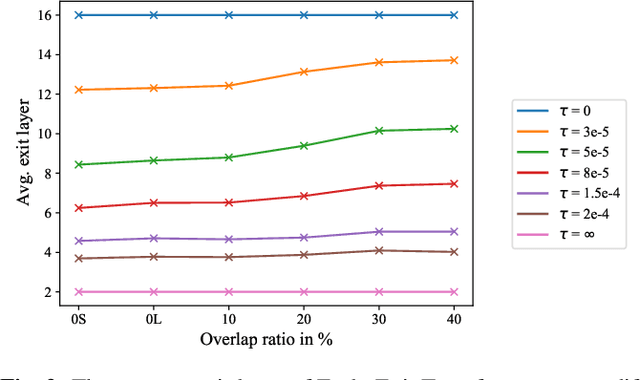
With its strong modeling capacity that comes from a multi-head and multi-layer structure, Transformer is a very powerful model for learning a sequential representation and has been successfully applied to speech separation recently. However, multi-channel speech separation sometimes does not necessarily need such a heavy structure for all time frames especially when the cross-talker challenge happens only occasionally. For example, in conversation scenarios, most regions contain only a single active speaker, where the separation task downgrades to a single speaker enhancement problem. It turns out that using a very deep network structure for dealing with signals with a low overlap ratio not only negatively affects the inference efficiency but also hurts the separation performance. To deal with this problem, we propose an early exit mechanism, which enables the Transformer model to handle different cases with adaptive depth. Experimental results indicate that not only does the early exit mechanism accelerate the inference, but it also improves the accuracy.
Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Apr 15, 2021


Developing Text Normalization (TN) systems for Text-to-Speech (TTS) on new languages is hard. We propose a novel architecture to facilitate it for multiple languages while using data less than 3% of the size of the data used by the state of the art results on English. We treat TN as a sequence classification problem and propose a granular tokenization mechanism that enables the system to learn majority of the classes and their normalizations from the training data itself. This is further combined with minimal precoded linguistic knowledge for other classes. We publish the first results on TN for TTS in Spanish and Tamil and also demonstrate that the performance of the approach is comparable with the previous work done on English. All annotated datasets used for experimentation will be released at https://github.com/amazon-research/proteno.
The DKU-Duke-Lenovo System Description for the Third DIHARD Speech Diarization Challenge
Feb 06, 2021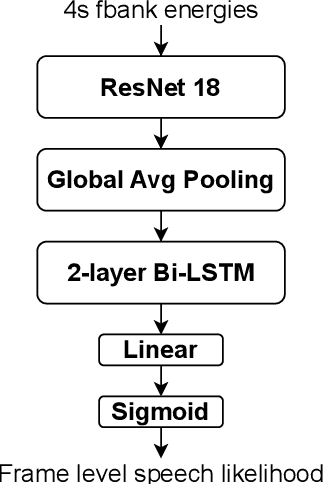
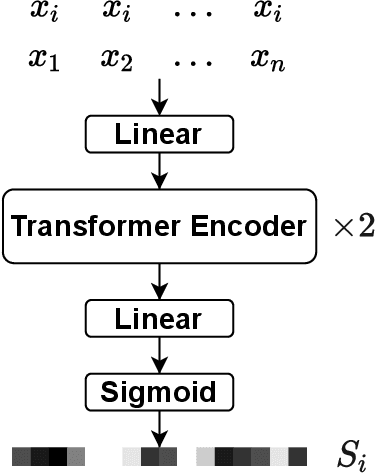
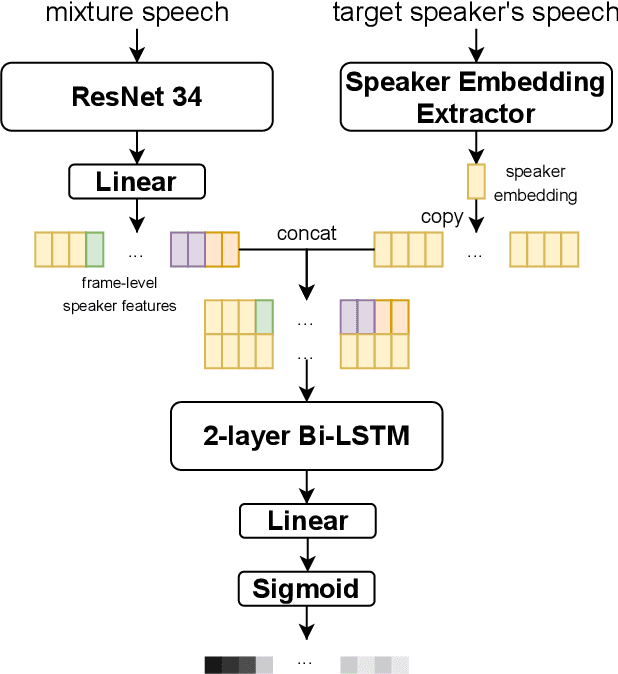

In this paper, we present the submitted system for the third DIHARD Speech Diarization Challenge from the DKU-Duke-Lenovo team. Our system consists of several modules: voice activity detection (VAD), segmentation, speaker embedding extraction, attentive similarity scoring, agglomerative hierarchical clustering. In addition, the target speaker VAD (TSVAD) is used for the phone call data to further improve the performance. Our final submitted system achieves a DER of 15.43% for the core evaluation set and 13.39% for the full evaluation set on task 1, and we also get a DER of 21.63% for core evaluation set and 18.90% for full evaluation set on task 2.
VRAIN-UPV MLLP's system for the Blizzard Challenge 2021
Oct 29, 2021
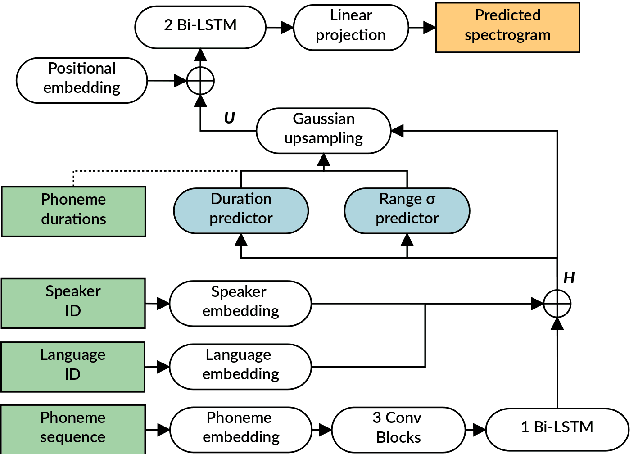

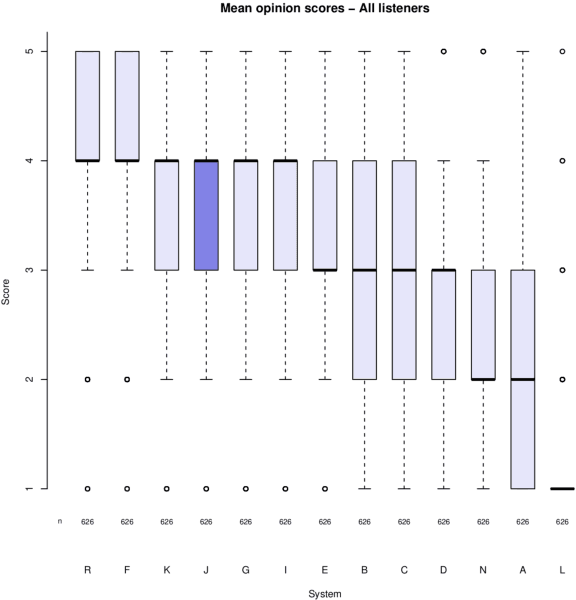
This paper presents the VRAIN-UPV MLLP's speech synthesis system for the SH1 task of the Blizzard Challenge 2021. The SH1 task consisted in building a Spanish text-to-speech system trained on (but not limited to) the corpus released by the Blizzard Challenge 2021 organization. It included 5 hours of studio-quality recordings from a native Spanish female speaker. In our case, this dataset was solely used to build a two-stage neural text-to-speech pipeline composed of a non-autoregressive acoustic model with explicit duration modeling and a HiFi-GAN neural vocoder. Our team is identified as J in the evaluation results. Our system obtained very good results in the subjective evaluation tests. Only one system among other 11 participants achieved better naturalness than ours. Concretely, it achieved a naturalness MOS of 3.61 compared to 4.21 for real samples.
Customizable End-to-end Optimization of Online Neural Network-supported Dereverberation for Hearing Devices
Apr 06, 2022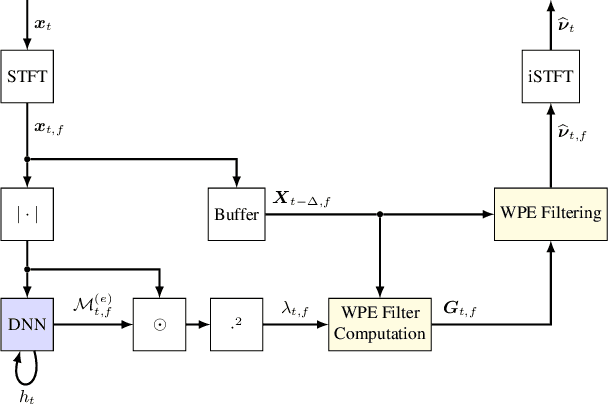


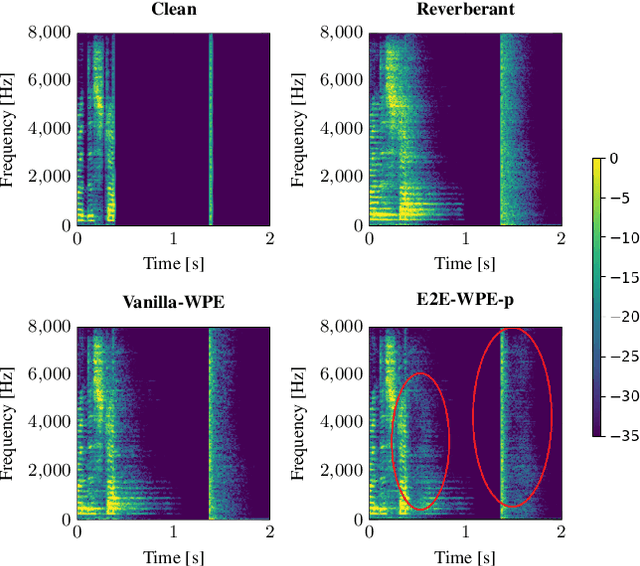
This work focuses on online dereverberation for hearing devices using the weighted prediction error (WPE) algorithm. WPE filtering requires an estimate of the target speech power spectral density (PSD). Recently deep neural networks (DNNs) have been used for this task. However, these approaches optimize the PSD estimate which only indirectly affects the WPE output, thus potentially resulting in limited dereverberation. In this paper, we propose an end-to-end approach specialized for online processing, that directly optimizes the dereverberated output signal. In addition, we propose to adapt it to the needs of different types of hearing-device users by modifying the optimization target as well as the WPE algorithm characteristics used in training. We show that the proposed end-to-end approach outperforms the traditional and conventional DNN-supported WPEs on a noise-free version of the WHAMR! dataset.
* \copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022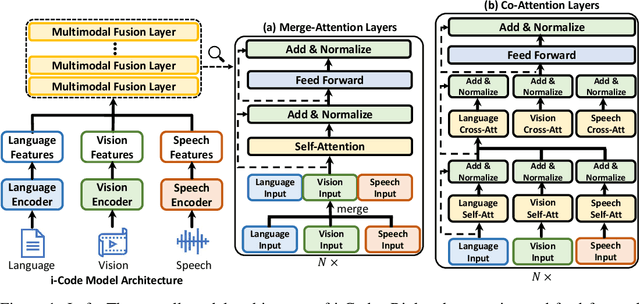
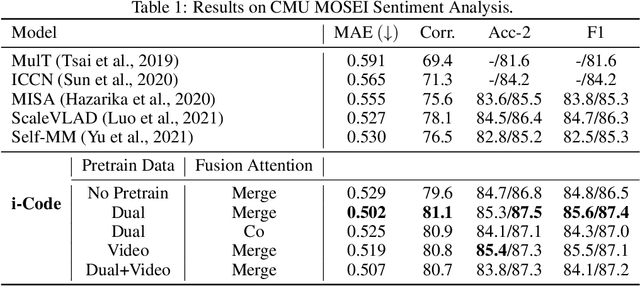
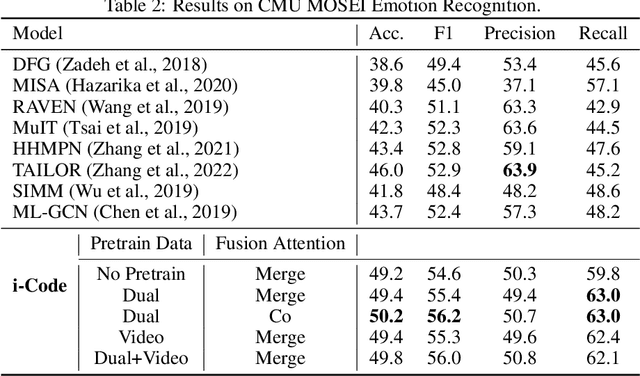

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.