 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards Unsupervised Speech-to-Text Translation
Nov 04, 2018

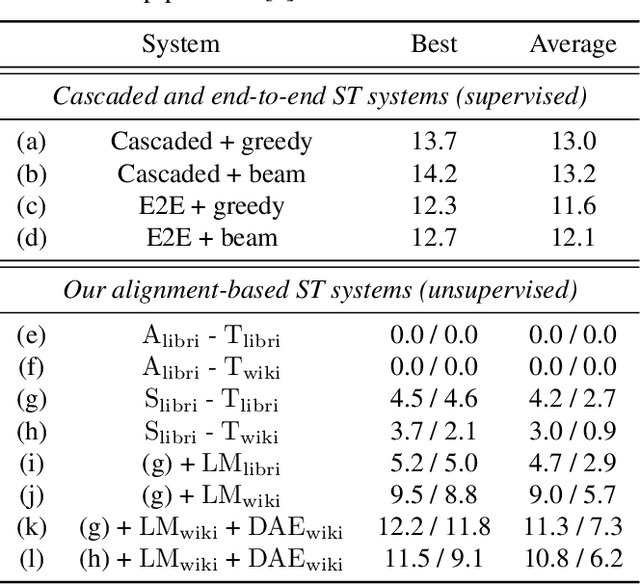
We present a framework for building speech-to-text translation (ST) systems using only monolingual speech and text corpora, in other words, speech utterances from a source language and independent text from a target language. As opposed to traditional cascaded systems and end-to-end architectures, our system does not require any labeled data (i.e., transcribed source audio or parallel source and target text corpora) during training, making it especially applicable to language pairs with very few or even zero bilingual resources. The framework initializes the ST system with a cross-modal bilingual dictionary inferred from the monolingual corpora, that maps every source speech segment corresponding to a spoken word to its target text translation. For unseen source speech utterances, the system first performs word-by-word translation on each speech segment in the utterance. The translation is improved by leveraging a language model and a sequence denoising autoencoder to provide prior knowledge about the target language. Experimental results show that our unsupervised system achieves comparable BLEU scores to supervised end-to-end models despite the lack of supervision. We also provide an ablation analysis to examine the utility of each component in our system.
MetaAudio: A Few-Shot Audio Classification Benchmark
Apr 10, 2022
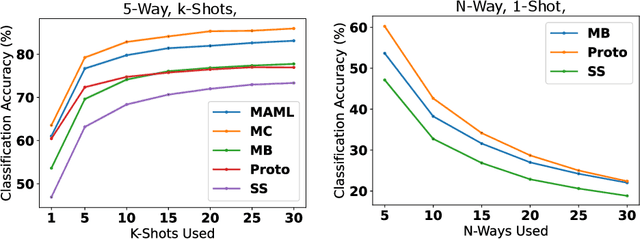
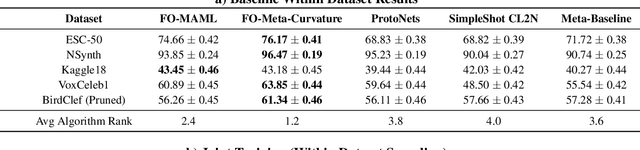
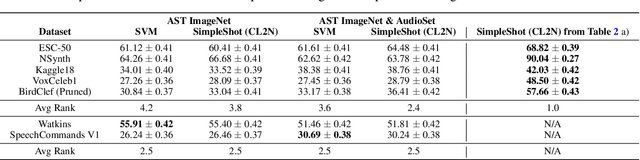
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.
MemeTector: Enforcing deep focus for meme detection
May 26, 2022
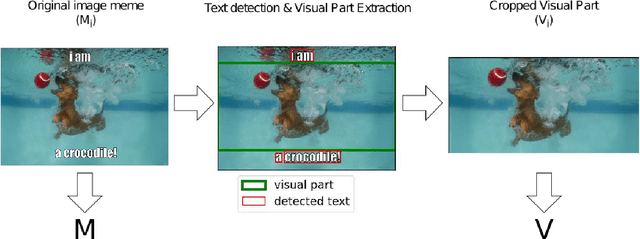

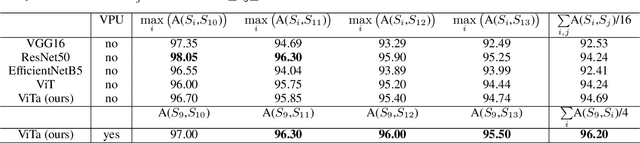
Image memes and specifically their widely-known variation image macros, is a special new media type that combines text with images and is used in social media to playfully or subtly express humour, irony, sarcasm and even hate. It is important to accurately retrieve image memes from social media to better capture the cultural and social aspects of online phenomena and detect potential issues (hate-speech, disinformation). Essentially, the background image of an image macro is a regular image easily recognized as such by humans but cumbersome for the machine to do so due to feature map similarity with the complete image macro. Hence, accumulating suitable feature maps in such cases can lead to deep understanding of the notion of image memes. To this end, we propose a methodology that utilizes the visual part of image memes as instances of the regular image class and the initial image memes as instances of the image meme class to force the model to concentrate on the critical parts that characterize an image meme. Additionally, we employ a trainable attention mechanism on top of a standard ViT architecture to enhance the model's ability to focus on these critical parts and make the predictions interpretable. Several training and test scenarios involving web-scraped regular images of controlled text presence are considered in terms of model robustness and accuracy. The findings indicate that light visual part utilization combined with sufficient text presence during training provides the best and most robust model, surpassing state of the art.
TSNAT: Two-Step Non-Autoregressvie Transformer Models for Speech Recognition
Apr 04, 2021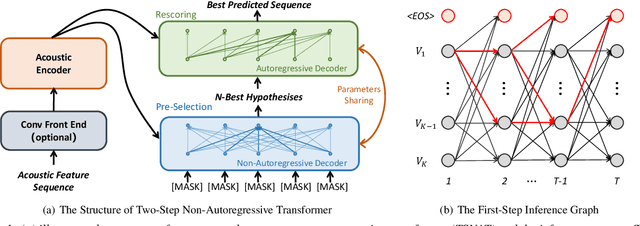
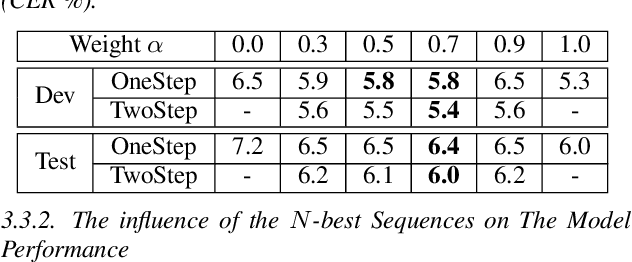
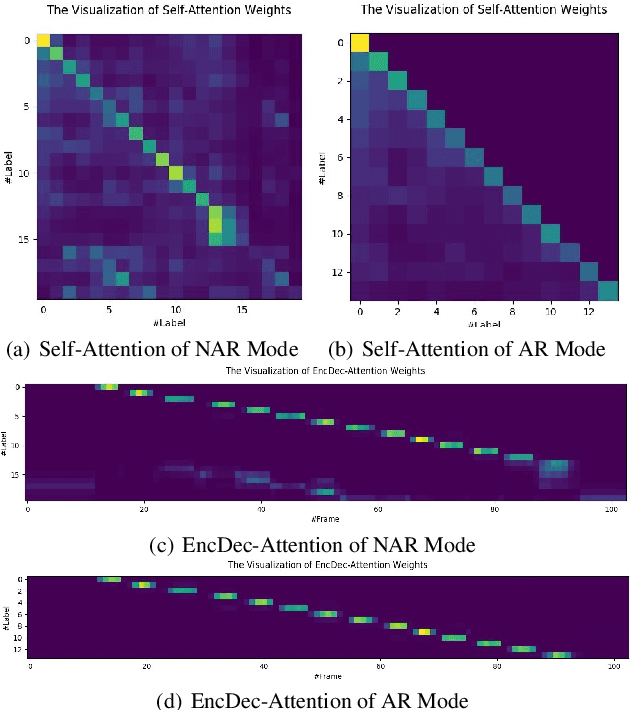
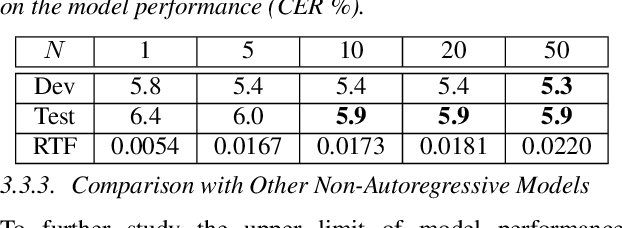
The autoregressive (AR) models, such as attention-based encoder-decoder models and RNN-Transducer, have achieved great success in speech recognition. They predict the output sequence conditioned on the previous tokens and acoustic encoded states, which is inefficient on GPUs. The non-autoregressive (NAR) models can get rid of the temporal dependency between the output tokens and predict the entire output tokens in at least one step. However, the NAR model still faces two major problems. On the one hand, there is still a great gap in performance between the NAR models and the advanced AR models. On the other hand, it's difficult for most of the NAR models to train and converge. To address these two problems, we propose a new model named the two-step non-autoregressive transformer(TSNAT), which improves the performance and accelerating the convergence of the NAR model by learning prior knowledge from a parameters-sharing AR model. Furthermore, we introduce the two-stage method into the inference process, which improves the model performance greatly. All the experiments are conducted on a public Chinese mandarin dataset ASIEHLL-1. The results show that the TSNAT can achieve a competitive performance with the AR model and outperform many complicated NAR models.
Improved Conformer-based End-to-End Speech Recognition Using Neural Architecture Search
Apr 13, 2021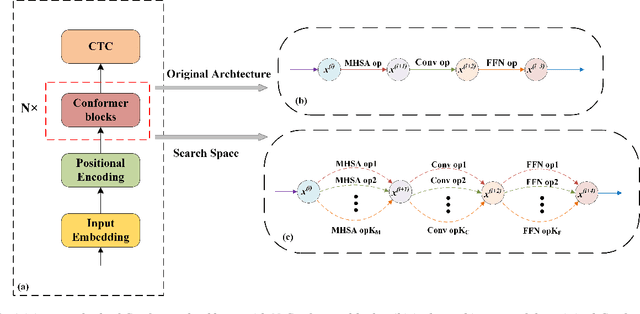

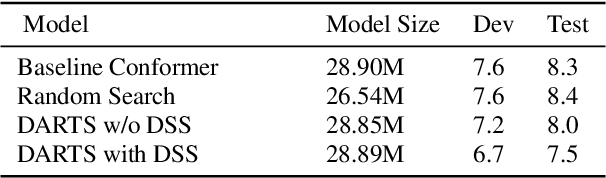
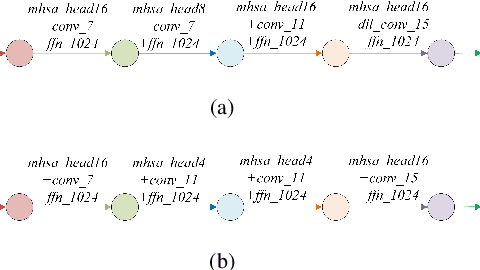
Recently neural architecture search(NAS) has been successfully used in image classification, natural language processing, and automatic speech recognition(ASR) tasks for finding the state-of-the-art(SOTA) architectures than those human-designed architectures. NAS can derive a SOTA and data-specific architecture over validation data from a pre-defined search space with a search algorithm. Inspired by the success of NAS in ASR tasks, we propose a NAS-based ASR framework containing one search space and one differentiable search algorithm called Differentiable Architecture Search(DARTS). Our search space follows the convolution-augmented transformer(Conformer) backbone, which is a more expressive ASR architecture than those used in existing NAS-based ASR frameworks. To improve the performance of our method, a regulation method called Dynamic Search Schedule(DSS) is employed. On a widely used Mandarin benchmark AISHELL-1, our best-searched architecture outperforms the baseline Conform model significantly with about 11% CER relative improvement, and our method is proved to be pretty efficient by the search cost comparisons.
Deep Learning based Emotion Recognition System Using Speech Features and Transcriptions
Jun 11, 2019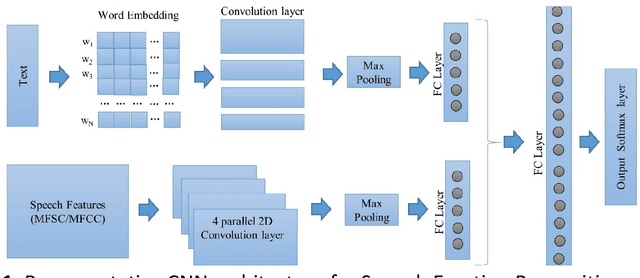
This paper proposes a speech emotion recognition method based on speech features and speech transcriptions (text). Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCC) help retain emotion-related low-level characteristics in speech whereas text helps capture semantic meaning, both of which help in different aspects of emotion detection. We experimented with several Deep Neural Network (DNN) architectures, which take in different combinations of speech features and text as inputs. The proposed network architectures achieve higher accuracies when compared to state-of-the-art methods on a benchmark dataset. The combined MFCC-Text Convolutional Neural Network (CNN) model proved to be the most accurate in recognizing emotions in IEMOCAP data.
Automatic analysis of Categorical Verbal Fluency for Mild Cognitive Impartment detection: a non-linear language independent approach
Mar 18, 2022
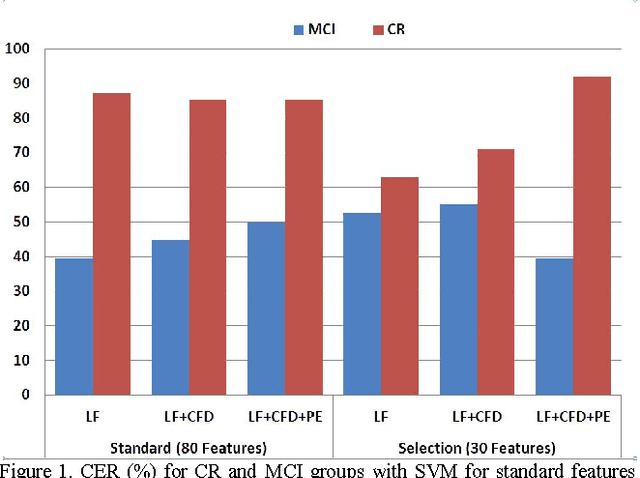
Alzheimer's disease (AD) is one the main causes of dementia in the world and the patients develop severe disability and sometime full dependence. In previous stages Mild Cognitive Impairment (MCI) produces cognitive loss but not severe enough to interfere with daily life. This work, on selection of biomarkers from speech for the detection of AD, is part of a wide-ranging cross study for the diagnosis of Alzheimer. Specifically in this work a task for detection of MCI has been used. The task analyzes Categorical Verbal Fluency. The automatic classification is carried out by SVM over classical linear features, Castiglioni fractal dimension and Permutation Entropy. Finally the most relevant features are selected by ANOVA test. The promising results are over 50% for MCI
* 4 pages, published in 2015 4th International Work Conference on Bioinspired Intelligence (IWOBI), pp. 101-104
The Vicomtech Spoofing-Aware Biometric System for the SASV Challenge
Apr 04, 2022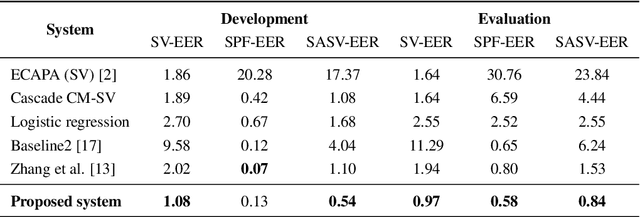
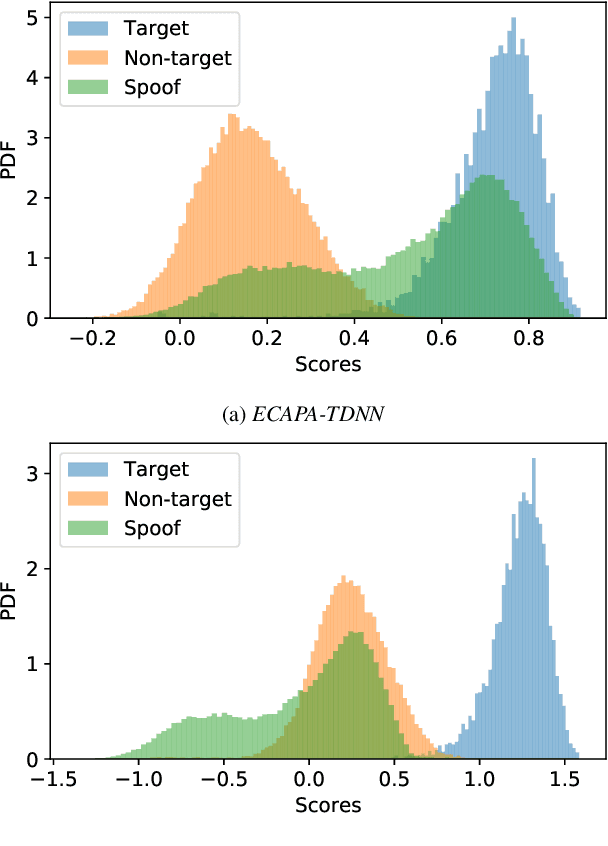
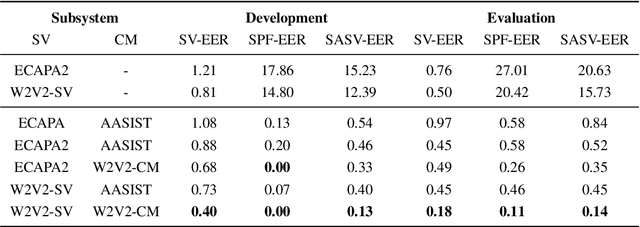
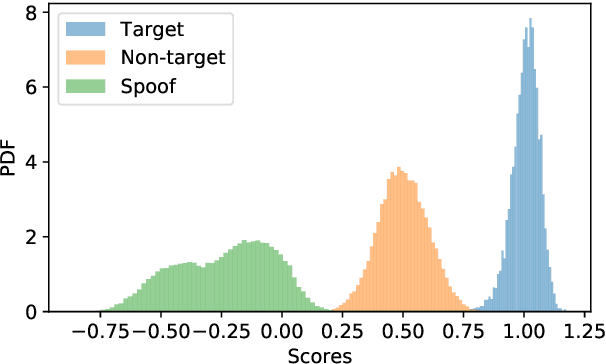
This paper describes our proposed integration system for the spoofing-aware speaker verification challenge. It consists of a robust spoofing-aware verification system that use the speaker verification and antispoofing embeddings extracted from specialized neural networks. First, an integration network, fed with the test utterance's speaker verification and spoofing embeddings, is used to compute a spoof-based score. This score is then linearly combined with the cosine similarity between the speaker verification embeddings from the enrollment and test utterances, thus obtaining the final scoring decision. Moreover, the integration network is trained using a one-class loss function to discriminate between target trials and unauthorized accesses. Our proposed system is evaluated in the ASVspoof19 database, exhibiting competitive performance compared to other integration approaches. In addition, we test, along with our integration approach, state of the art speaker verification and antispoofing systems based on self-supervised learning, yielding high-performance speech biometric systems.
tPLCnet: Real-time Deep Packet Loss Concealment in the Time Domain Using a Short Temporal Context
Apr 04, 2022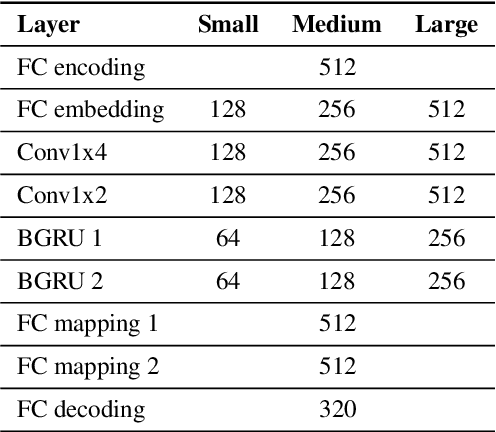
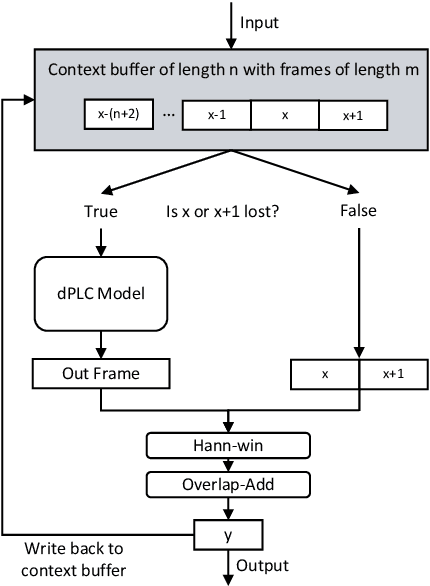
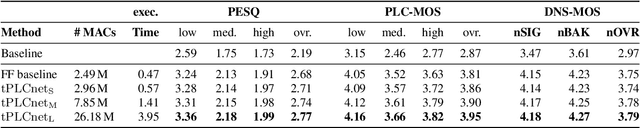
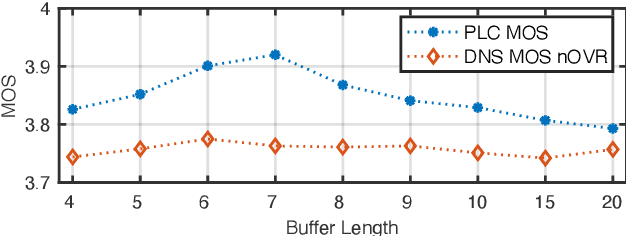
This paper introduces a real-time time-domain packet loss concealment (PLC) neural-network (tPLCnet). It efficiently predicts lost frames from a short context buffer in a sequence-to-one (seq2one) fashion. Because of its seq2one structure, a continuous inference of the model is not required since it can be triggered when packet loss is actually detected. It is trained on 64h of open-source speech data and packet-loss traces of real calls provided by the Audio PLC Challenge. The model with the lowest complexity described in this paper reaches a robust PLC performance and consistent improvements over the zero-filling baseline for all metrics. A configuration with higher complexity is submitted to the PLC Challenge and shows a performance increase of 1.07 compared to the zero-filling baseline in terms of PLC-MOS on the blind test set and reaches a competitive 3rd place in the challenge ranking.