 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evolution of Part-of-Speech in Classical Chinese
Sep 23, 2020
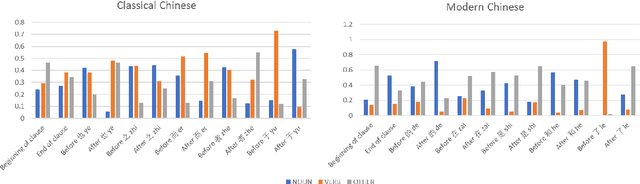

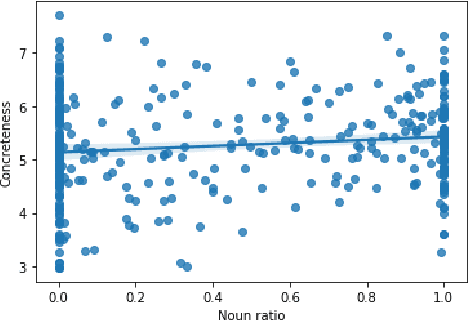
Classical Chinese is a language notable for its word class flexibility: the same word may often be used as a noun or a verb. Bisang (2008) claimed that Classical Chinese is a precategorical language, where the syntactic position of a word determines its part-of-speech category. In this paper, we apply entropy-based metrics to evaluate these claims on historical corpora. We further explore differences between nouns and verbs in Classical Chinese: using psycholinguistic norms, we find a positive correlation between concreteness and noun usage. Finally, we align character embeddings from Classical and Modern Chinese, and find that verbs undergo more semantic change than nouns.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020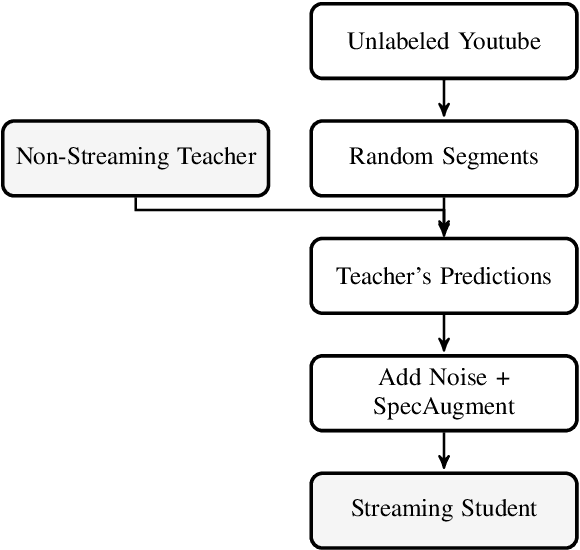
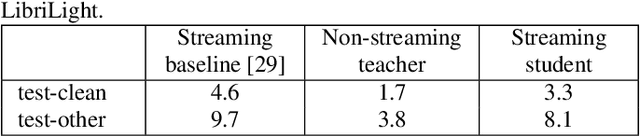
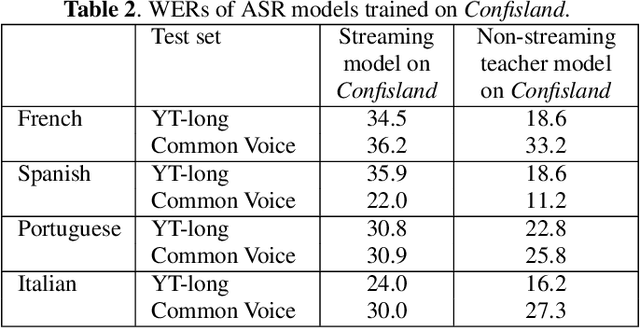
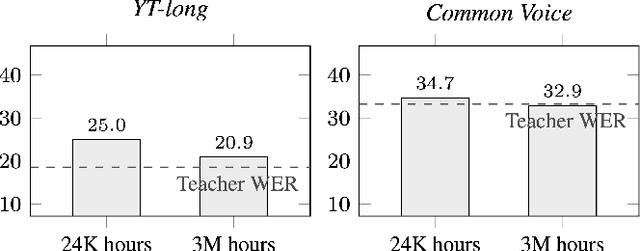
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
Don't shoot butterfly with rifles: Multi-channel Continuous Speech Separation with Early Exit Transformer
Oct 23, 2020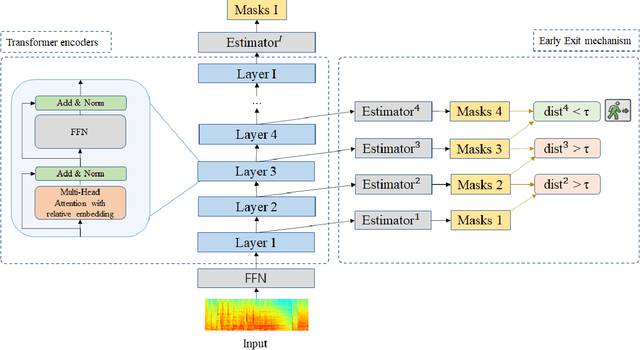
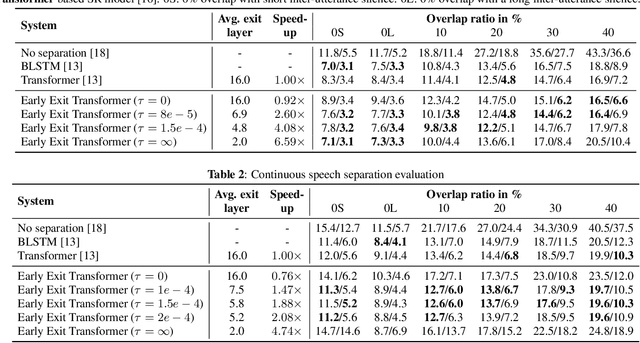
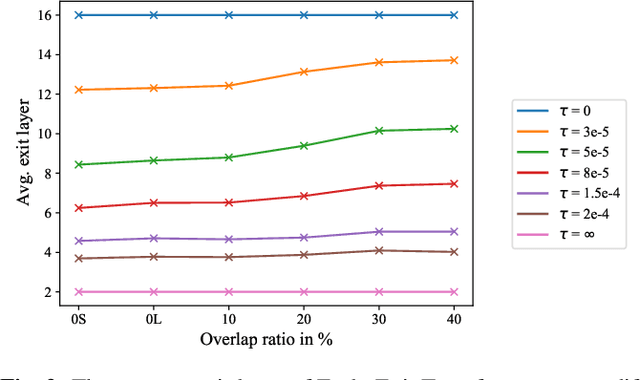
With its strong modeling capacity that comes from a multi-head and multi-layer structure, Transformer is a very powerful model for learning a sequential representation and has been successfully applied to speech separation recently. However, multi-channel speech separation sometimes does not necessarily need such a heavy structure for all time frames especially when the cross-talker challenge happens only occasionally. For example, in conversation scenarios, most regions contain only a single active speaker, where the separation task downgrades to a single speaker enhancement problem. It turns out that using a very deep network structure for dealing with signals with a low overlap ratio not only negatively affects the inference efficiency but also hurts the separation performance. To deal with this problem, we propose an early exit mechanism, which enables the Transformer model to handle different cases with adaptive depth. Experimental results indicate that not only does the early exit mechanism accelerate the inference, but it also improves the accuracy.
PSO-Convolutional Neural Networks with Heterogeneous Learning Rate
May 20, 2022
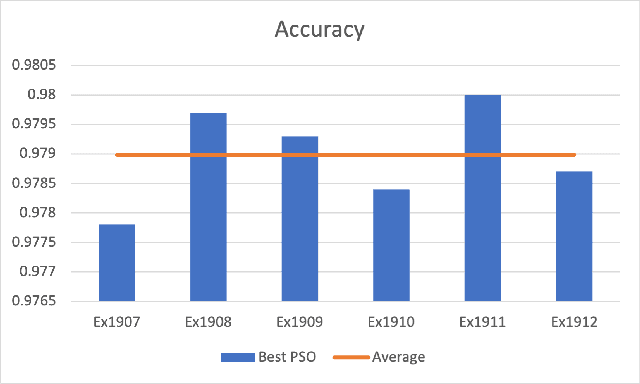
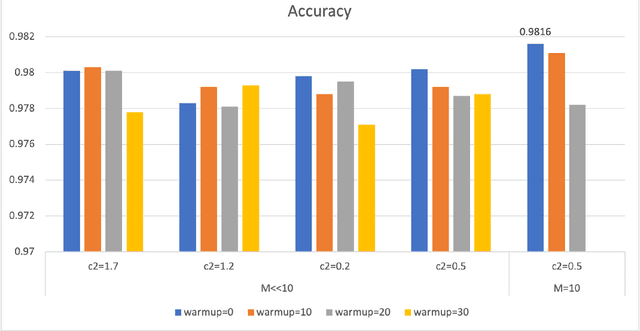
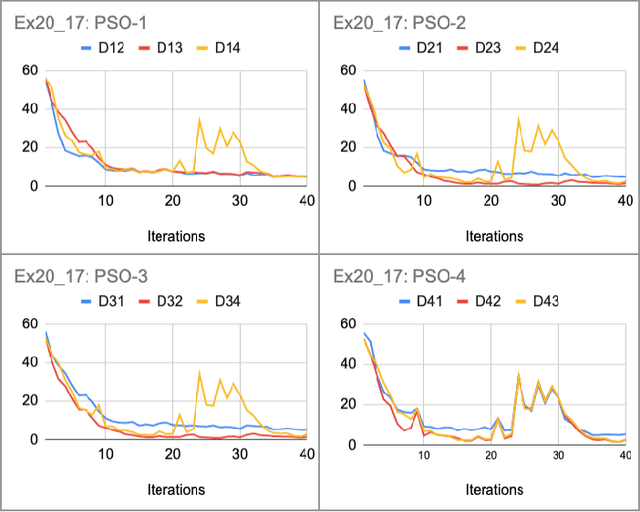
Convolutional Neural Networks (ConvNets) have been candidly deployed in the scope of computer vision and related fields. Nevertheless, the dynamics of training of these neural networks lie still elusive: it is hard and computationally expensive to train them. A myriad of architectures and training strategies have been proposed to overcome this challenge and address several problems in image processing such as speech, image and action recognition as well as object detection. In this article, we propose a novel Particle Swarm Optimization (PSO) based training for ConvNets. In such framework, the vector of weights of each ConvNet is typically cast as the position of a particle in phase space whereby PSO collaborative dynamics intertwines with Stochastic Gradient Descent (SGD) in order to boost training performance and generalization. Our approach goes as follows: i) [warm-up phase] each ConvNet is trained independently via SGD; ii) [collaborative phase] ConvNets share among themselves their current vector of weights (or particle-position) along with their gradient estimates of the Loss function. Distinct step sizes are coined by distinct ConvNets. By properly blending ConvNets with large (possibly random) step-sizes along with more conservative ones, we propose an algorithm with competitive performance with respect to other PSO-based approaches on Cifar-10 (accuracy of 98.31%). These accuracy levels are obtained by resorting to only four ConvNets -- such results are expected to scale with the number of collaborative ConvNets accordingly. We make our source codes available for download https://github.com/leonlha/PSO-ConvNet-Dynamics.
FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations
Mar 25, 2022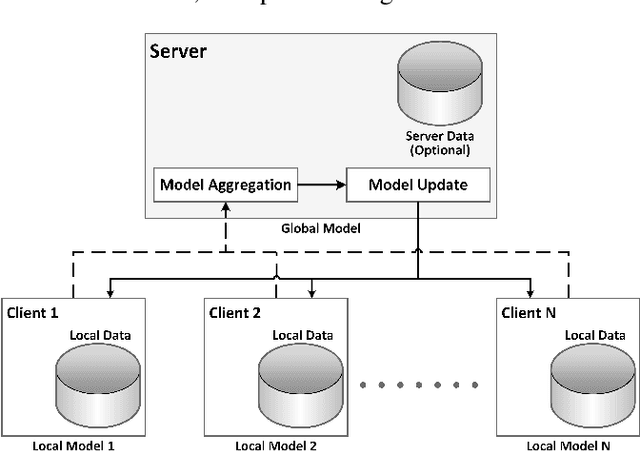
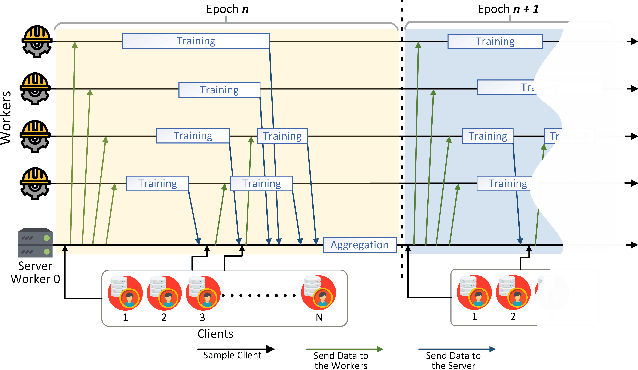
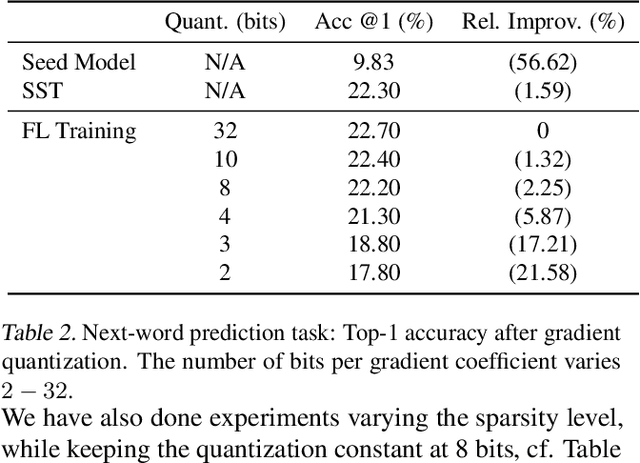
In this paper we introduce "Federated Learning Utilities and Tools for Experimentation" (FLUTE), a high-performance open source platform for federated learning research and offline simulations. The goal of FLUTE is to enable rapid prototyping and simulation of new federated learning algorithms at scale, including novel optimization, privacy, and communications strategies. We describe the architecture of FLUTE, enabling arbitrary federated modeling schemes to be realized, we compare the platform with other state-of-the-art platforms, and we describe available features of FLUTE for experimentation in core areas of active research, such as optimization, privacy and scalability. We demonstrate the effectiveness of the platform with a series of experiments for text prediction and speech recognition, including the addition of differential privacy, quantization, scaling and a variety of optimization and federation approaches.
Analyzing the Intensity of Complaints on Social Media
Apr 20, 2022
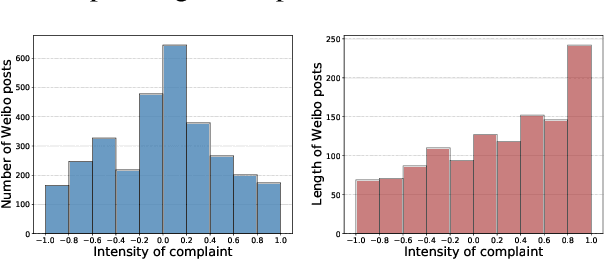

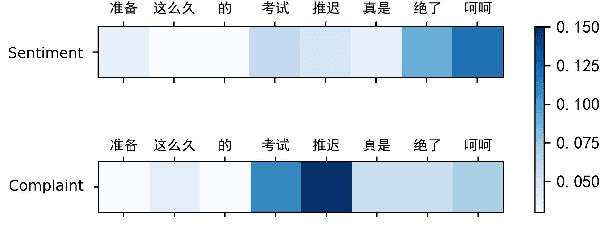
Complaining is a speech act that expresses a negative inconsistency between reality and human expectations. While prior studies mostly focus on identifying the existence or the type of complaints, in this work, we present the first study in computational linguistics of measuring the intensity of complaints from text. Analyzing complaints from such perspective is particularly useful, as complaints of certain degrees may cause severe consequences for companies or organizations. We create the first Chinese dataset containing 3,103 posts about complaints from Weibo, a popular Chinese social media platform. These posts are then annotated with complaints intensity scores using Best-Worst Scaling (BWS) method. We show that complaints intensity can be accurately estimated by computational models with the best mean square error achieving 0.11. Furthermore, we conduct a comprehensive linguistic analysis around complaints, including the connections between complaints and sentiment, and a cross-lingual comparison for complaints expressions used by Chinese and English speakers. We finally show that our complaints intensity scores can be incorporated for better estimating the popularity of posts on social media.
Low-Latency Speaker-Independent Continuous Speech Separation
Apr 13, 2019
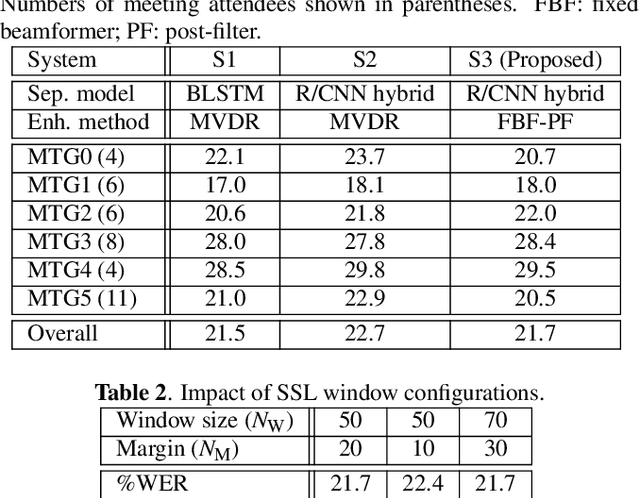

Speaker independent continuous speech separation (SI-CSS) is a task of converting a continuous audio stream, which may contain overlapping voices of unknown speakers, into a fixed number of continuous signals each of which contains no overlapping speech segment. A separated, or cleaned, version of each utterance is generated from one of SI-CSS's output channels nondeterministically without being split up and distributed to multiple channels. A typical application scenario is transcribing multi-party conversations, such as meetings, recorded with microphone arrays. The output signals can be simply sent to a speech recognition engine because they do not include speech overlaps. The previous SI-CSS method uses a neural network trained with permutation invariant training and a data-driven beamformer and thus requires much processing latency. This paper proposes a low-latency SI-CSS method whose performance is comparable to that of the previous method in a microphone array-based meeting transcription task.This is achieved (1) by using a new speech separation network architecture combined with a double buffering scheme and (2) by performing enhancement with a set of fixed beamformers followed by a neural post-filter.
Improving Voice Separation by Incorporating End-to-end Speech Recognition
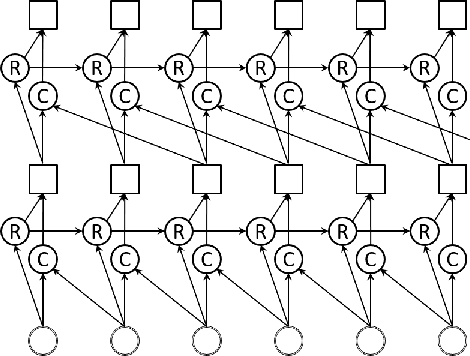
Nov 29, 2019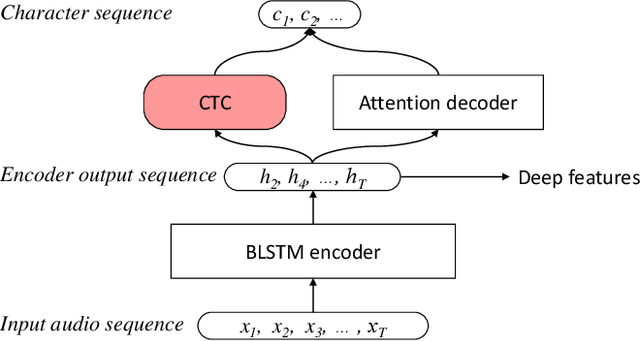
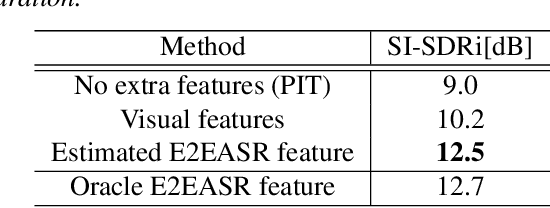
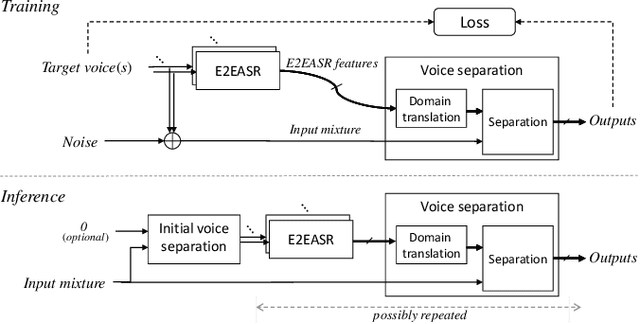

Despite recent advances in voice separation methods, many challenges remain in realistic scenarios such as noisy recording and the limits of available data. In this work, we propose to explicitly incorporate the phonetic and linguistic nature of speech by taking a transfer learning approach using an end-to-end automatic speech recognition (E2EASR) system. The voice separation is conditioned on deep features extracted from E2EASR to cover the long-term dependence of phonetic aspects. Experimental results on speech separation and enhancement task on the AVSpeech dataset show that the proposed method significantly improves the signal-to-distortion ratio over the baseline model and even outperforms an audio visual model, that utilizes visual information of lip movements.
Dynamic Prosody Generation for Speech Synthesis using Linguistics-Driven Acoustic Embedding Selection
Dec 02, 2019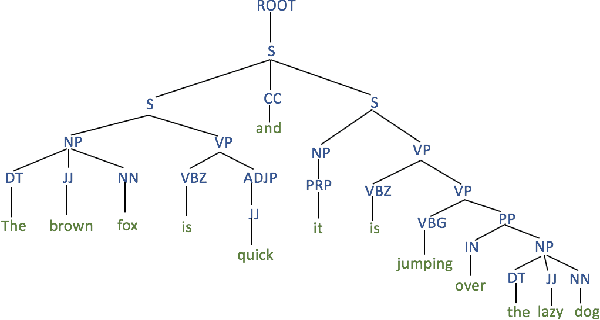

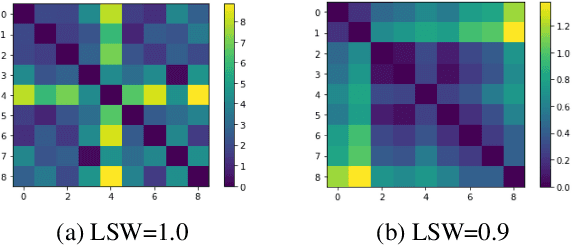
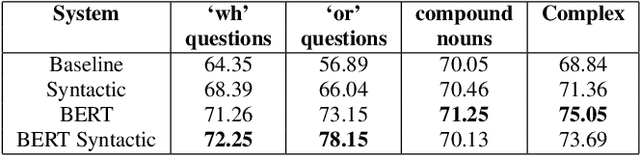
Recent advances in Text-to-Speech (TTS) have improved quality and naturalness to near-human capabilities when considering isolated sentences. But something which is still lacking in order to achieve human-like communication is the dynamic variations and adaptability of human speech. This work attempts to solve the problem of achieving a more dynamic and natural intonation in TTS systems, particularly for stylistic speech such as the newscaster speaking style. We propose a novel embedding selection approach which exploits linguistic information, leveraging the speech variability present in the training dataset. We analyze the contribution of both semantic and syntactic features. Our results show that the approach improves the prosody and naturalness for complex utterances as well as in Long Form Reading (LFR).
SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
Apr 06, 2021
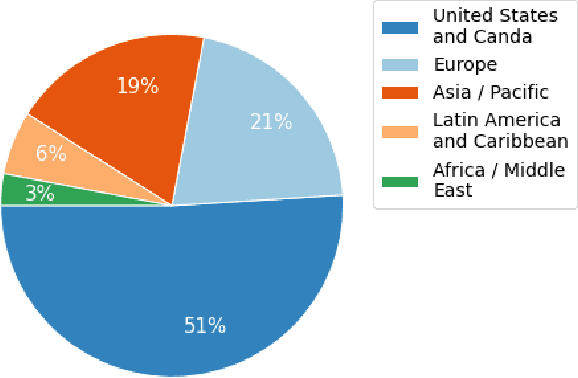

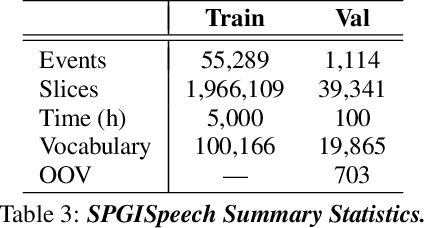
In the English speech-to-text (STT) machine learning task, acoustic models are conventionally trained on uncased Latin characters, and any necessary orthography (such as capitalization, punctuation, and denormalization of non-standard words) is imputed by separate post-processing models. This adds complexity and limits performance, as many formatting tasks benefit from semantic information present in the acoustic signal but absent in transcription. Here we propose a new STT task: end-to-end neural transcription with fully formatted text for target labels. We present baseline Conformer-based models trained on a corpus of 5,000 hours of professionally transcribed earnings calls, achieving a CER of 1.7. As a contribution to the STT research community, we release the corpus free for non-commercial use at https://datasets.kensho.com/datasets/scribe.