 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Sub-band Knowledge Distillation Framework for Speech Enhancement
May 29, 2020



In single-channel speech enhancement, methods based on full-band spectral features have been widely studied. However, only a few methods pay attention to non-full-band spectral features. In this paper, we explore a knowledge distillation framework based on sub-band spectral mapping for single-channel speech enhancement. Specifically, we divide the full frequency band into multiple sub-bands and pre-train an elite-level sub-band enhancement model (teacher model) for each sub-band. These teacher models are dedicated to processing their own sub-bands. Next, under the teacher models' guidance, we train a general sub-band enhancement model (student model) that works for all sub-bands. Without increasing the number of model parameters and computational complexity, the student model's performance is further improved. To evaluate our proposed method, we conducted a large number of experiments on an open-source data set. The final experimental results show that the guidance from the elite-level teacher models dramatically improves the student model's performance, which exceeds the full-band model by employing fewer parameters.
Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
May 29, 2019
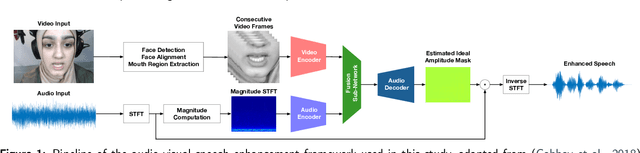
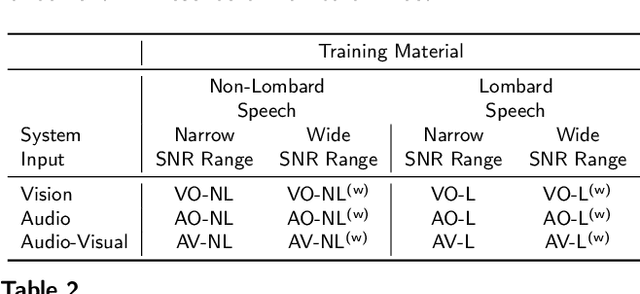
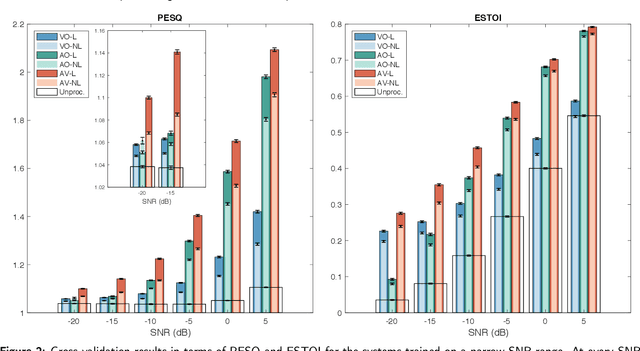
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field. We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by 54 different talkers. The results show that training deep-learning-based models with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility at low signal to noise ratios, where the visual modality can play an important role in acoustically challenging situations. We also find that a performance difference between genders exists due to the distinct Lombard speech exhibited by males and females, and we analyse it in relation with acoustic and visual features. Furthermore, listening tests conducted with audio-visual stimuli show that the speech quality of the signals processed with systems trained using Lombard speech is statistically significantly better than the one obtained using systems trained with non-Lombard speech at a signal to noise ratio of -5 dB. Regarding speech intelligibility, we find a general tendency of the benefit in training the systems with Lombard speech.
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 14, 2022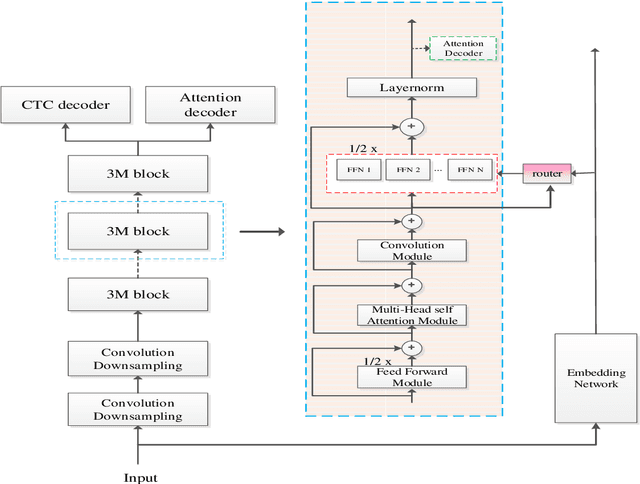
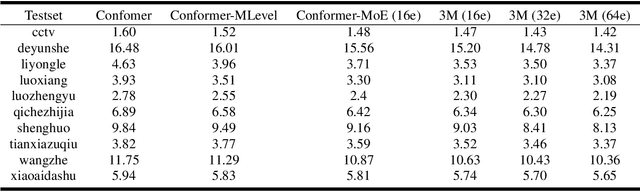
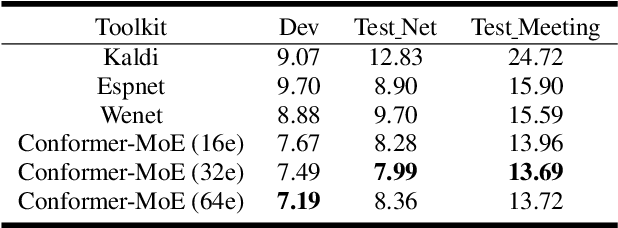
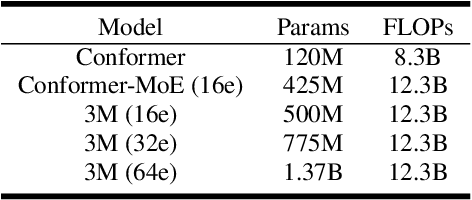
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model. Code is publicly available at https://github.com/tencent-ailab/3m-asr.
WEMAC: Women and Emotion Multi-modal Affective Computing dataset
Mar 01, 2022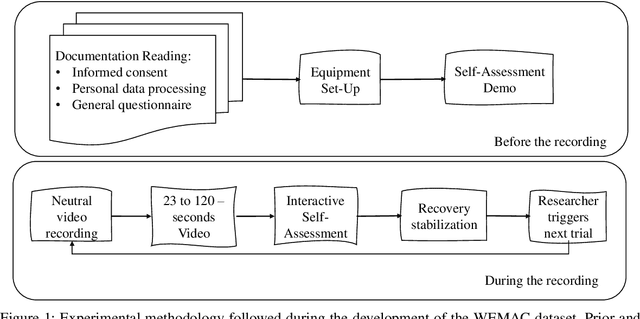


Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the Fifth SDG is a call for action to turn Gender Equality into a fundamental human right and an essential foundation for a better world. It includes the eradication of all types of violence against women. Within this context, the UC3M4Safety research team aims to develop Bindi. This is a cyber-physical system which includes embedded Artificial Intelligence algorithms, for user real-time monitoring towards the detection of affective states, with the ultimate goal of achieving the early detection of risk situations for women. On this basis, we make use of wearable affective computing including smart sensors, data encryption for secure and accurate collection of presumed crime evidence, as well as the remote connection to protecting agents. Towards the development of such system, the recordings of different laboratory and into-the-wild datasets are in process. These are contained within the UC3M4Safety Database. Thus, this paper presents and details the first release of WEMAC, a novel multi-modal dataset, which comprises a laboratory-based experiment for 47 women volunteers that were exposed to validated audio-visual stimuli to induce real emotions by using a virtual reality headset while physiological, speech signals and self-reports were acquired and collected. We believe this dataset will serve and assist research on multi-modal affective computing using physiological and speech information.
DNNAbacus: Toward Accurate Computational Cost Prediction for Deep Neural Networks
May 24, 2022
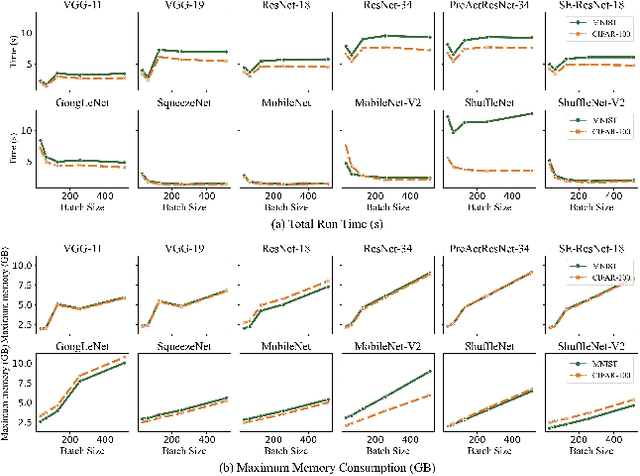
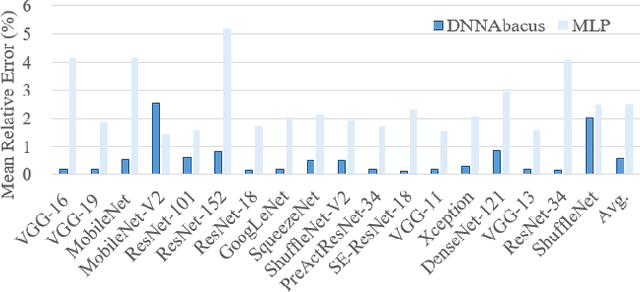
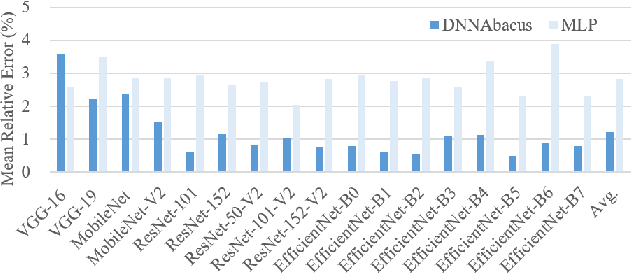
Deep learning is attracting interest across a variety of domains, including natural language processing, speech recognition, and computer vision. However, model training is time-consuming and requires huge computational resources. Existing works on the performance prediction of deep neural networks, which mostly focus on the training time prediction of a few models, rely on analytical models and result in high relative errors. %Optimizing task scheduling and reducing job failures in data centers are essential to improve resource utilization and reduce carbon emissions. This paper investigates the computational resource demands of 29 classical deep neural networks and builds accurate models for predicting computational costs. We first analyze the profiling results of typical networks and demonstrate that the computational resource demands of models with different inputs and hyperparameters are not obvious and intuitive. We then propose a lightweight prediction approach DNNAbacus with a novel network structural matrix for network representation. DNNAbacus can accurately predict both memory and time cost for PyTorch and TensorFlow models, which is also generalized to different hardware architectures and can have zero-shot capability for unseen networks. Our experimental results show that the mean relative error (MRE) is 0.9% with respect to time and 2.8% with respect to memory for 29 classic models, which is much lower than the state-of-the-art works.
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021
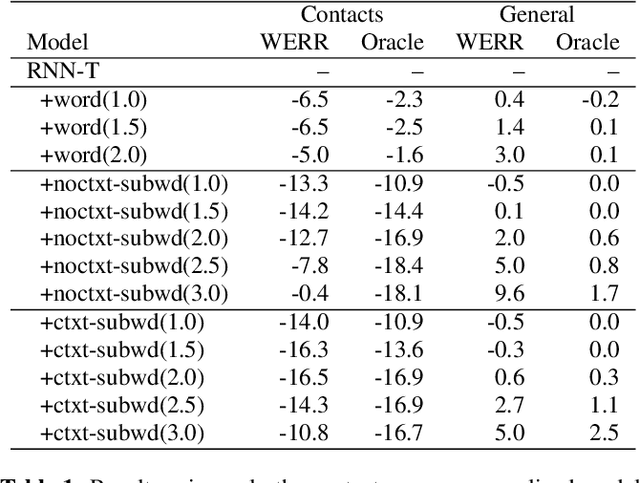
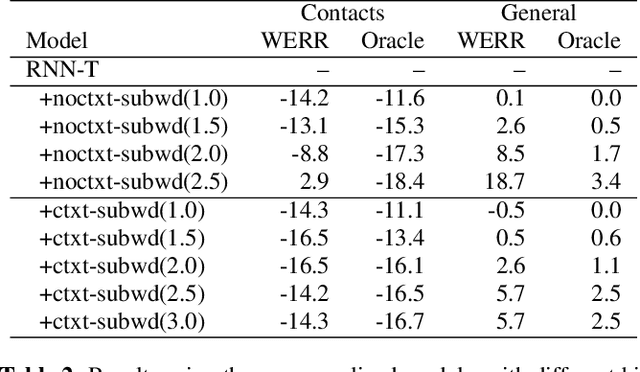
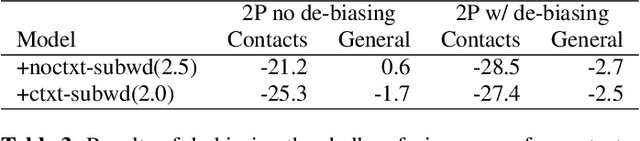
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
A Multi Purpose and Large Scale Speech Corpus in Persian and English for Speaker and Speech Recognition: the DeepMine Database
Dec 08, 2019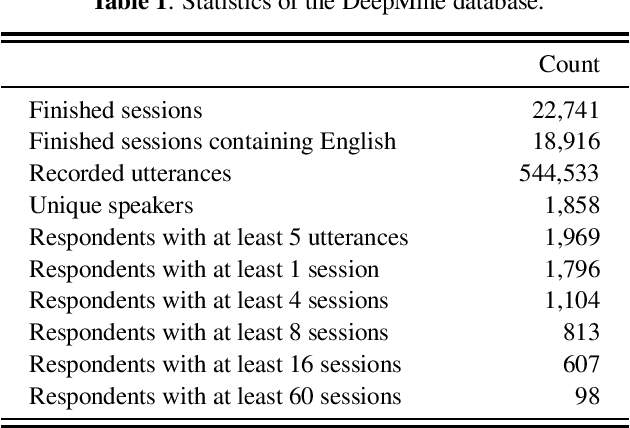

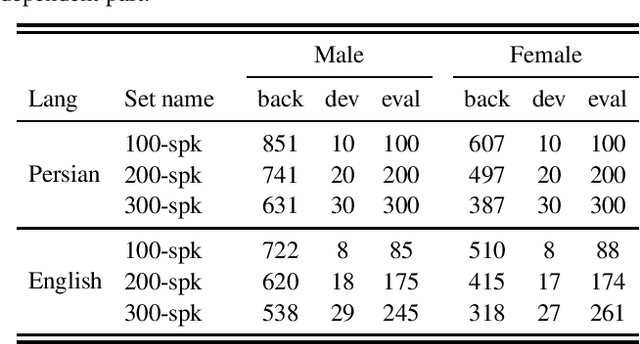
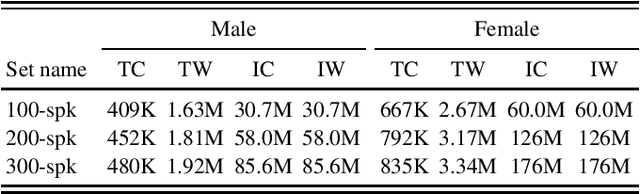
DeepMine is a speech database in Persian and English designed to build and evaluate text-dependent, text-prompted, and text-independent speaker verification, as well as Persian speech recognition systems. It contains more than 1850 speakers and 540 thousand recordings overall, more than 480 hours of speech are transcribed. It is the first public large-scale speaker verification database in Persian, the largest public text-dependent and text-prompted speaker verification database in English, and the largest public evaluation dataset for text-independent speaker verification. It has a good coverage of age, gender, and accents. We provide several evaluation protocols for each part of the database to allow for research on different aspects of speaker verification. We also provide the results of several experiments that can be considered as baselines: HMM-based i-vectors for text-dependent speaker verification, and HMM-based as well as state-of-the-art deep neural network based ASR. We demonstrate that the database can serve for training robust ASR models.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022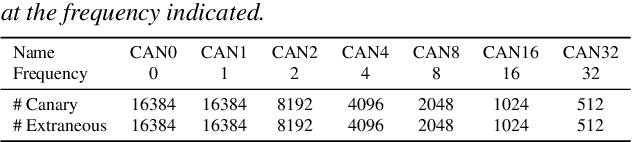
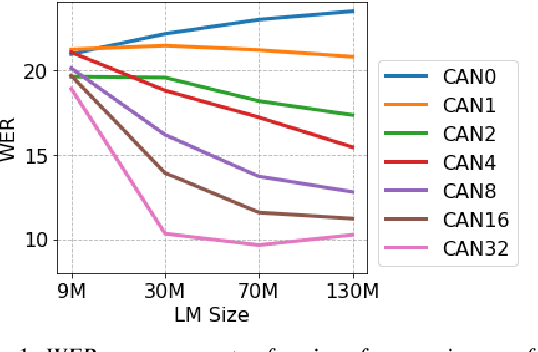
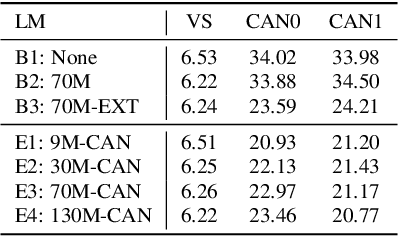
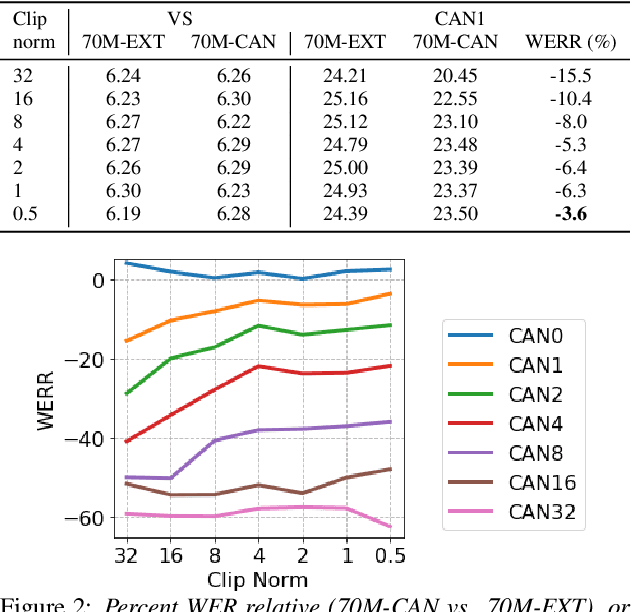
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
SpeedySpeech: Efficient Neural Speech Synthesis
Aug 09, 2020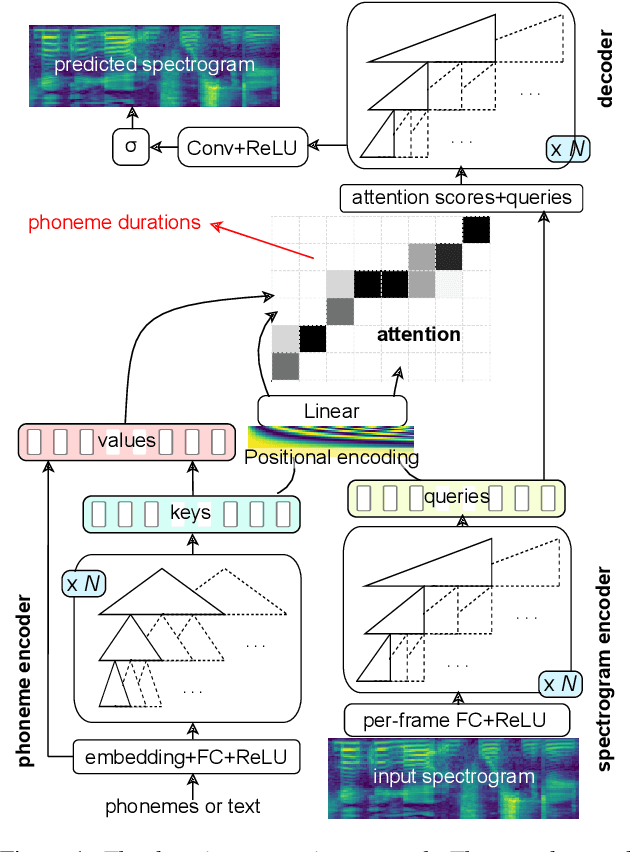
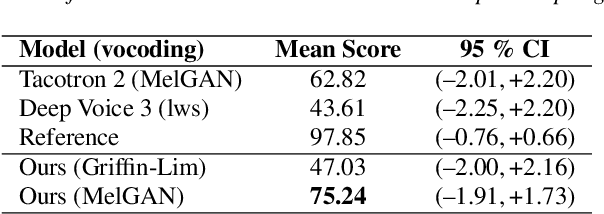
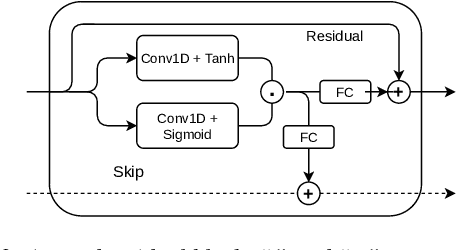
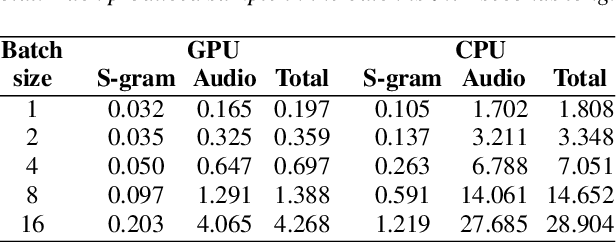
While recent neural sequence-to-sequence models have greatly improved the quality of speech synthesis, there has not been a system capable of fast training, fast inference and high-quality audio synthesis at the same time. We propose a student-teacher network capable of high-quality faster-than-real-time spectrogram synthesis, with low requirements on computational resources and fast training time. We show that self-attention layers are not necessary for generation of high quality audio. We utilize simple convolutional blocks with residual connections in both student and teacher networks and use only a single attention layer in the teacher model. Coupled with a MelGAN vocoder, our model's voice quality was rated significantly higher than Tacotron 2. Our model can be efficiently trained on a single GPU and can run in real time even on a CPU. We provide both our source code and audio samples in our GitHub repository.
Enhancing Segment-Based Speech Emotion Recognition by Deep Self-Learning
Mar 30, 2021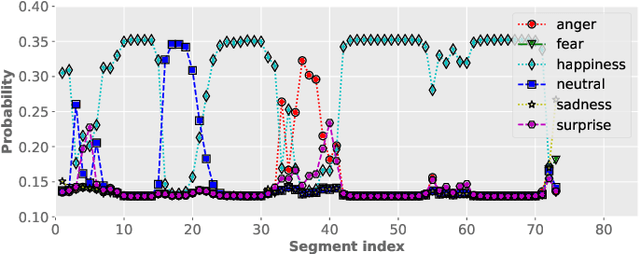
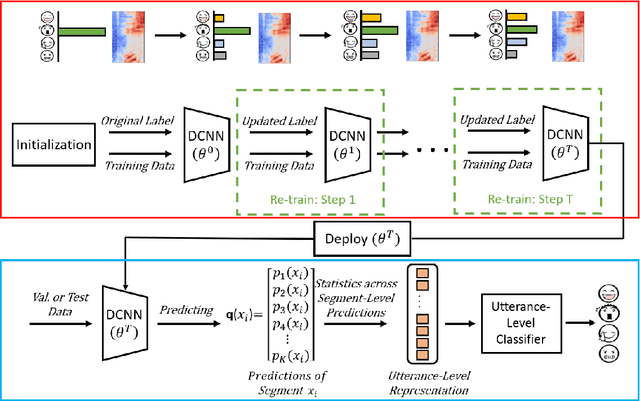
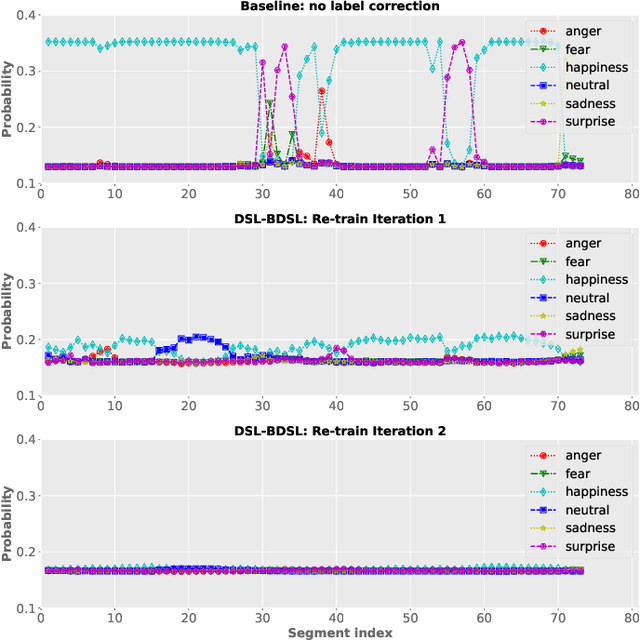
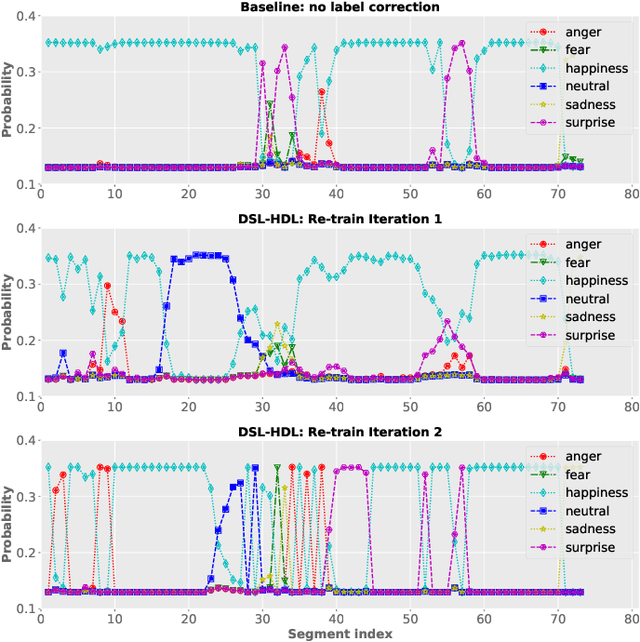
Despite the widespread utilization of deep neural networks (DNNs) for speech emotion recognition (SER), they are severely restricted due to the paucity of labeled data for training. Recently, segment-based approaches for SER have been evolving, which train backbone networks on shorter segments instead of whole utterances, and thus naturally augments training examples without additional resources. However, one core challenge remains for segment-based approaches: most emotional corpora do not provide ground-truth labels at the segment level. To supervisely train a segment-based emotion model on such datasets, the most common way assigns each segment the corresponding utterance's emotion label. However, this practice typically introduces noisy (incorrect) labels as emotional information is not uniformly distributed across the whole utterance. On the other hand, DNNs have been shown to easily over-fit a dataset when being trained with noisy labels. To this end, this work proposes a simple and effective deep self-learning (DSL) framework, which comprises a procedure to progressively correct segment-level labels in an iterative learning manner. The DSL method produces dynamically-generated and soft emotion labels, leading to significant performance improvements. Experiments on three well-known emotional corpora demonstrate noticeable gains using the proposed method.