 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Polish Read Speech Corpus for Speech Tools and Services
Jun 01, 2017
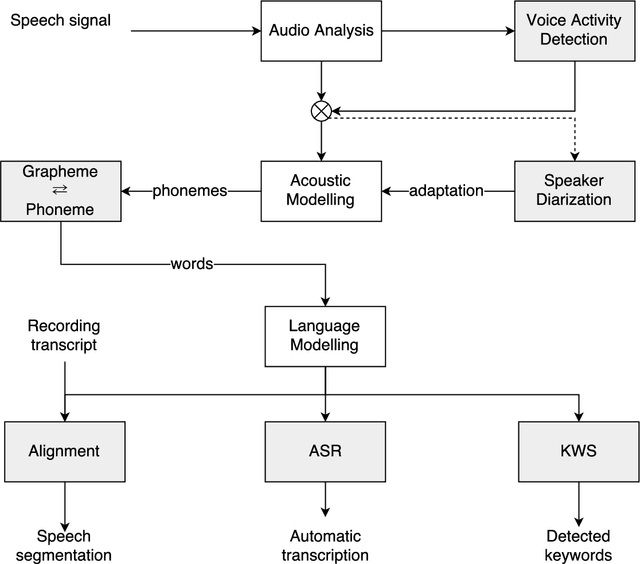


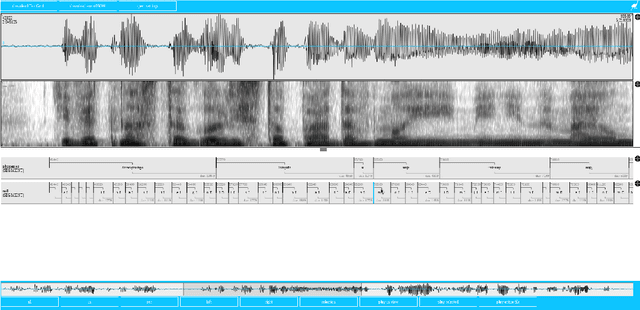
This paper describes the speech processing activities conducted at the Polish consortium of the CLARIN project. The purpose of this segment of the project was to develop specific tools that would allow for automatic and semi-automatic processing of large quantities of acoustic speech data. The tools include the following: grapheme-to-phoneme conversion, speech-to-text alignment, voice activity detection, speaker diarization, keyword spotting and automatic speech transcription. Furthermore, in order to develop these tools, a large high-quality studio speech corpus was recorded and released under an open license, to encourage development in the area of Polish speech research. Another purpose of the corpus was to serve as a reference for studies in phonetics and pronunciation. All the tools and resources were released on the the Polish CLARIN website. This paper discusses the current status and future plans for the project.
SpliceOut: A Simple and Efficient Audio Augmentation Method
Sep 30, 2021
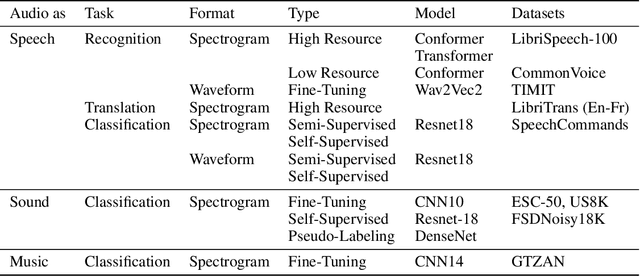
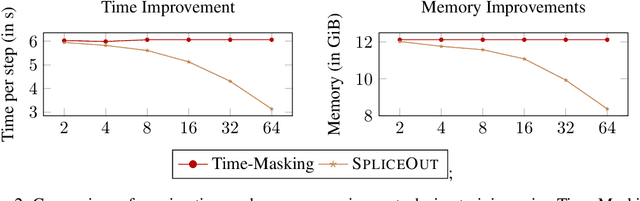
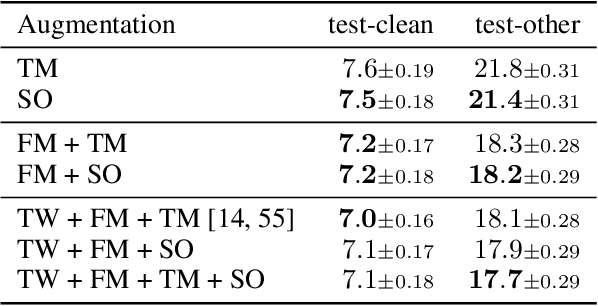
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.
Deep Learning Based Speech Beamforming
Feb 15, 2018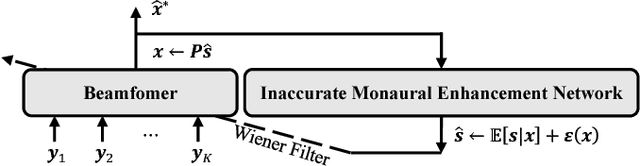
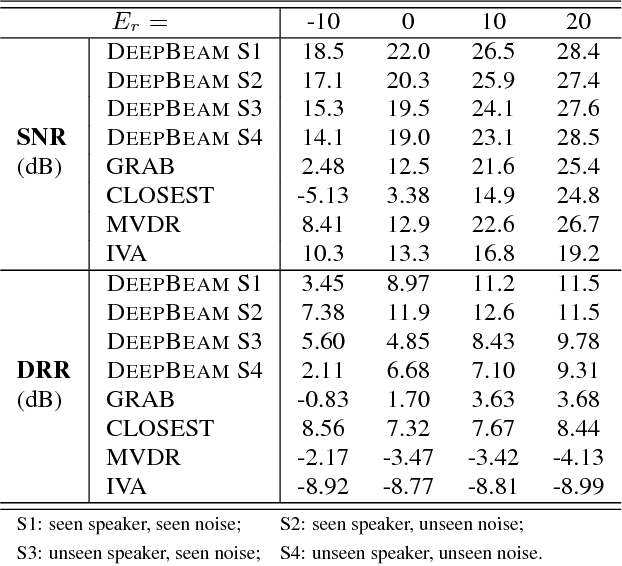
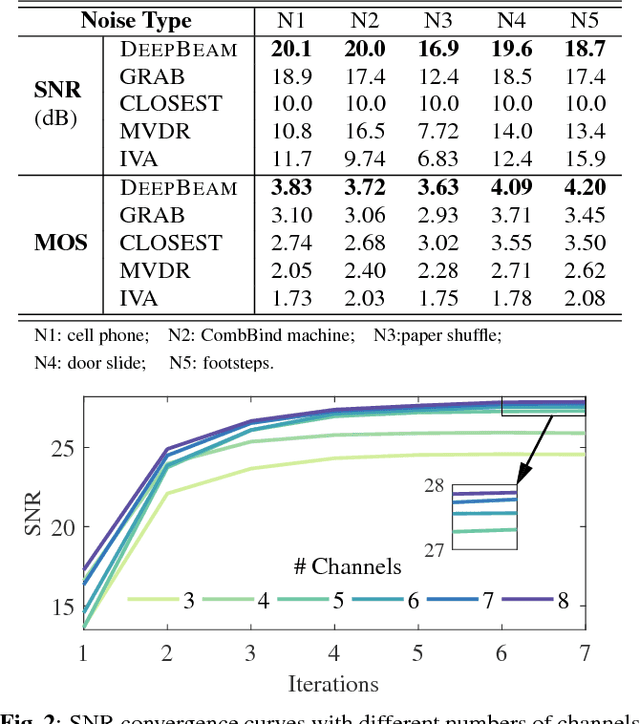
Multi-channel speech enhancement with ad-hoc sensors has been a challenging task. Speech model guided beamforming algorithms are able to recover natural sounding speech, but the speech models tend to be oversimplified or the inference would otherwise be too complicated. On the other hand, deep learning based enhancement approaches are able to learn complicated speech distributions and perform efficient inference, but they are unable to deal with variable number of input channels. Also, deep learning approaches introduce a lot of errors, particularly in the presence of unseen noise types and settings. We have therefore proposed an enhancement framework called DEEPBEAM, which combines the two complementary classes of algorithms. DEEPBEAM introduces a beamforming filter to produce natural sounding speech, but the filter coefficients are determined with the help of a monaural speech enhancement neural network. Experiments on synthetic and real-world data show that DEEPBEAM is able to produce clean, dry and natural sounding speech, and is robust against unseen noise.
Pre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 26, 2022
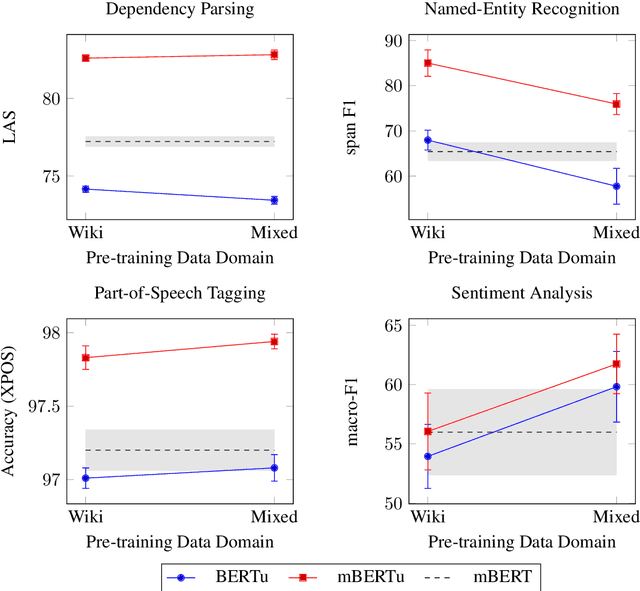
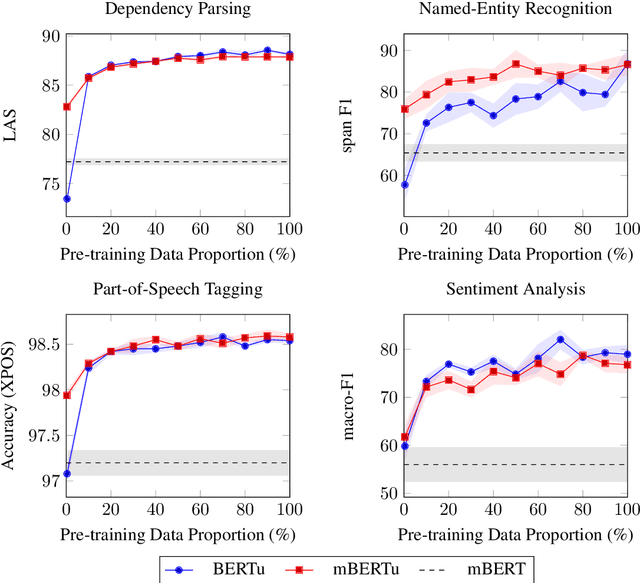
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.
Late reverberation suppression using U-nets
Oct 05, 2021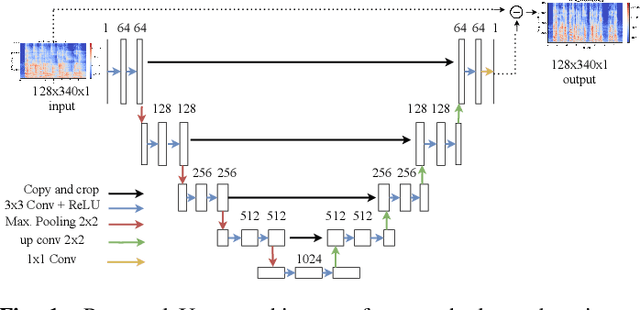
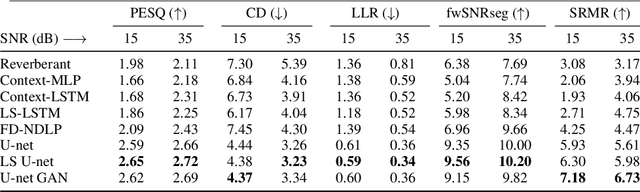
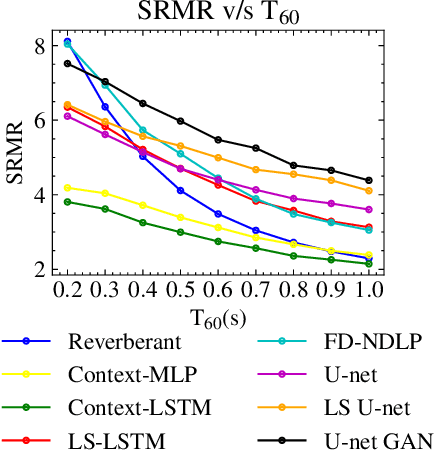
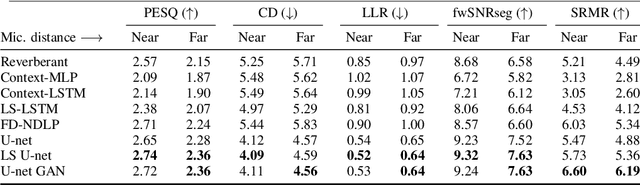
In real-world settings, speech signals are almost always affected by reverberation produced by the working environment; these corrupted signals need to be \emph{dereverberated} prior to performing, e.g., speech recognition, speech-to-text conversion, compression, or general audio enhancement. In this paper, we propose a supervised dereverberation technique using \emph{U-nets with skip connections}, which are fully-convolutional encoder-decoder networks with layers arranged in the form of an "U" and connections that "skip" some layers. Building on this architecture, we address speech dereverberation through the lens of Late Reverberation Suppression (LS). Via experiments on synthetic and real-world data with different noise levels and reverberation settings, we show that our proposed method termed "LS U-net" improves quality, intelligibility and other performance metrics compared to the original U-net method and it is on par with the state-of-the-art GAN-based approaches.
Sparsification via Compressed Sensing for Automatic Speech Recognition
Feb 09, 2021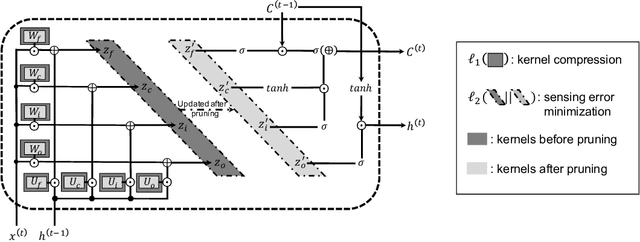
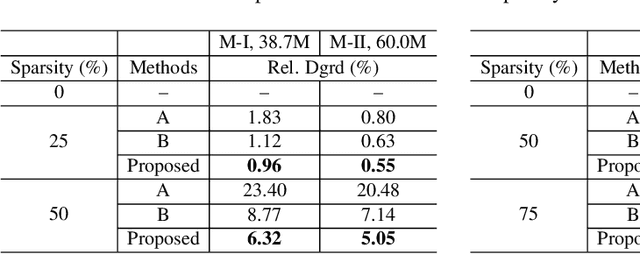
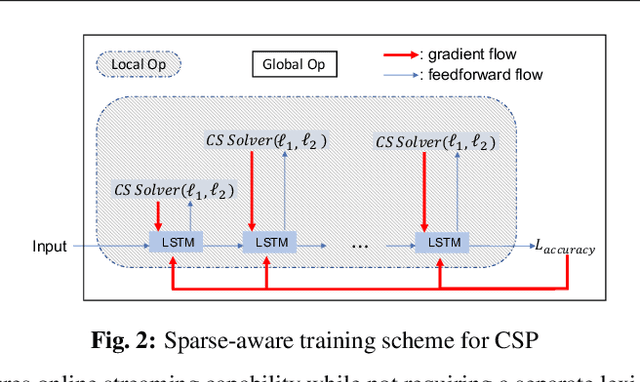
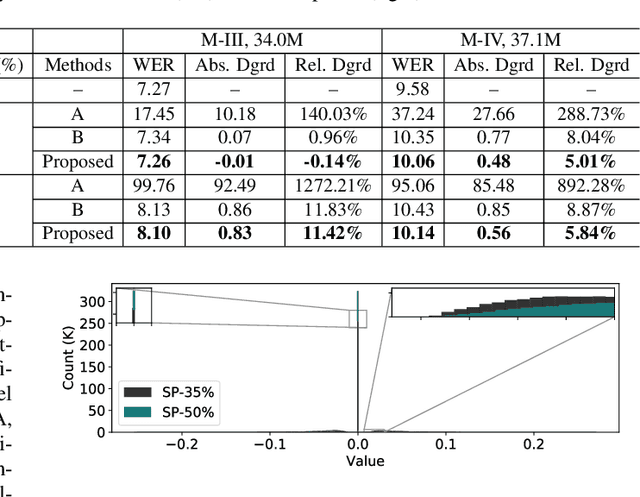
In order to achieve high accuracy for machine learning (ML) applications, it is essential to employ models with a large number of parameters. Certain applications, such as Automatic Speech Recognition (ASR), however, require real-time interactions with users, hence compelling the model to have as low latency as possible. Deploying large scale ML applications thus necessitates model quantization and compression, especially when running ML models on resource constrained devices. For example, by forcing some of the model weight values into zero, it is possible to apply zero-weight compression, which reduces both the model size and model reading time from the memory. In the literature, such methods are referred to as sparse pruning. The fundamental questions are when and which weights should be forced to zero, i.e. be pruned. In this work, we propose a compressed sensing based pruning (CSP) approach to effectively address those questions. By reformulating sparse pruning as a sparsity inducing and compression-error reduction dual problem, we introduce the classic compressed sensing process into the ML model training process. Using ASR task as an example, we show that CSP consistently outperforms existing approaches in the literature.
AccentDB: A Database of Non-Native English Accents to Assist Neural Speech Recognition
May 16, 2020
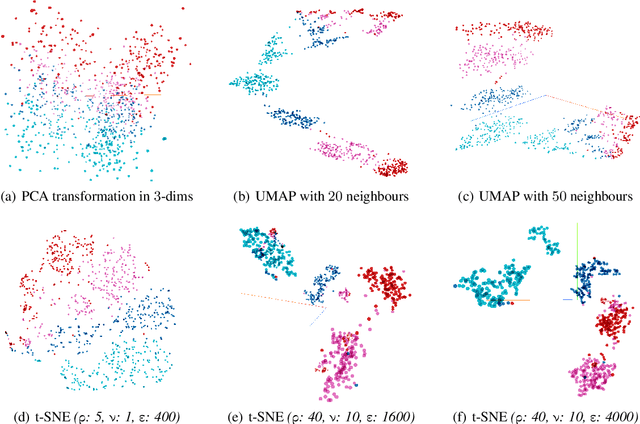
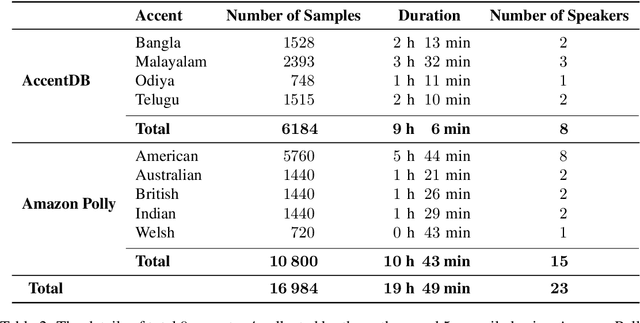
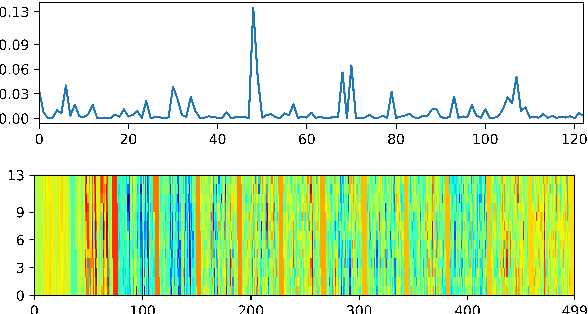
Modern Automatic Speech Recognition (ASR) technology has evolved to identify the speech spoken by native speakers of a language very well. However, identification of the speech spoken by non-native speakers continues to be a major challenge for it. In this work, we first spell out the key requirements for creating a well-curated database of speech samples in non-native accents for training and testing robust ASR systems. We then introduce AccentDB, one such database that contains samples of 4 Indian-English accents collected by us, and a compilation of samples from 4 native-English, and a metropolitan Indian-English accent. We also present an analysis on separability of the collected accent data. Further, we present several accent classification models and evaluate them thoroughly against human-labelled accent classes. We test the generalization of our classifier models in a variety of setups of seen and unseen data. Finally, we introduce the task of accent neutralization of non-native accents to native accents using autoencoder models with task-specific architectures. Thus, our work aims to aid ASR systems at every stage of development with a database for training, classification models for feature augmentation, and neutralization systems for acoustic transformations of non-native accents of English.
Learning with Learned Loss Function: Speech Enhancement with Quality-Net to Improve Perceptual Evaluation of Speech Quality
May 06, 2019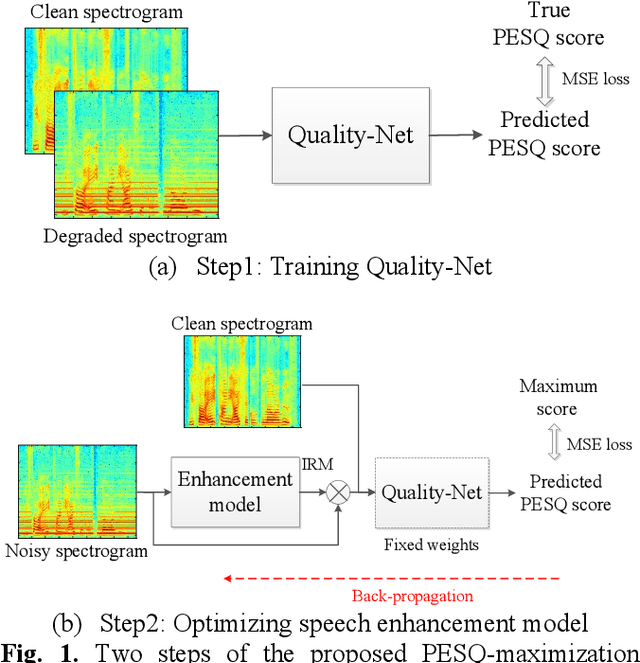
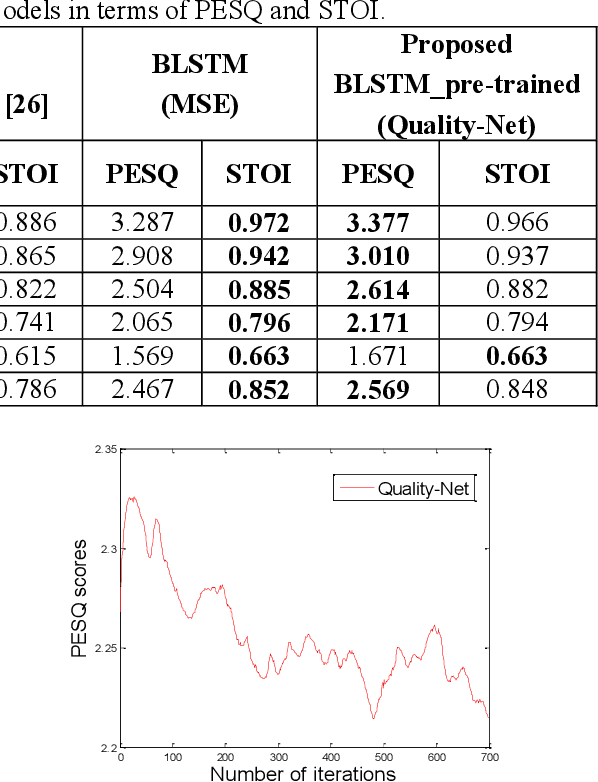
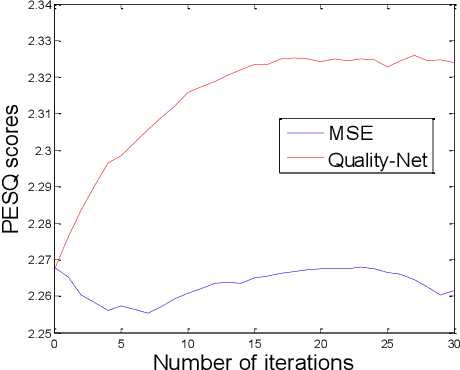
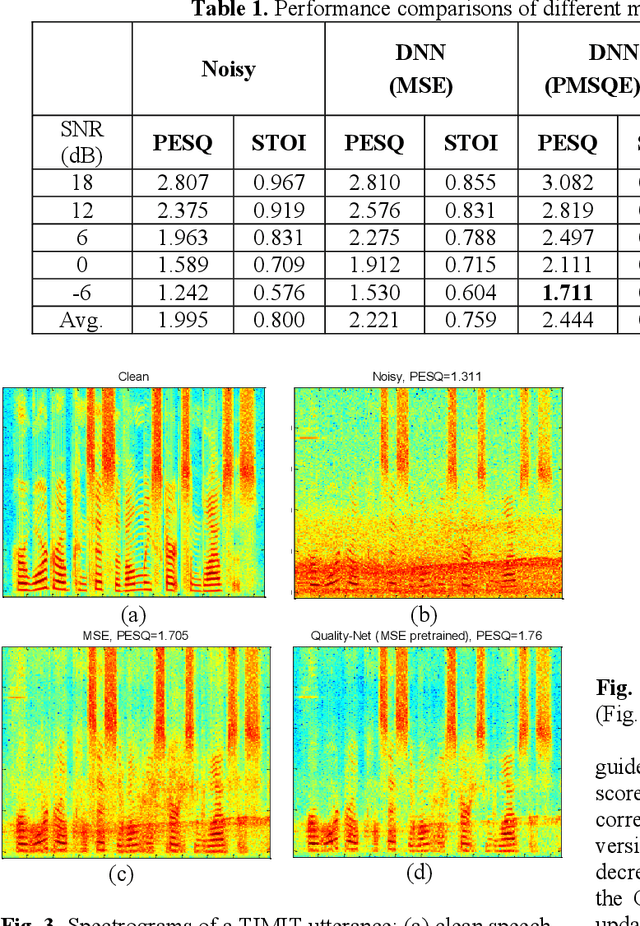
Utilizing a human-perception-related objective function to train a speech enhancement model has become a popular topic recently. This is primarily because the conventional mean squared error (MSE) loss cannot reflect auditory perception well. Among the human-perception-related metrics, the perceptual evaluation of speech quality (PESQ) is a typical one, and has been proven to provide a high correlation to the quality scores rated by humans. Owing to its complex and non-differentiable properties, however, the PESQ function may not be used to optimize speech enhancement models directly. In this study, we propose optimizing the enhancement model with an approximated PESQ function, which is differentiable and learned from the training data. The experimental results indicate that the average PESQ score of the enhanced speech fine-tuning by the learned loss function can further improve 0.1 points, as compared to that with the MSE-based pre-trained model.
Joint Khmer Word Segmentation and Part-of-Speech Tagging Using Deep Learning
Mar 31, 2021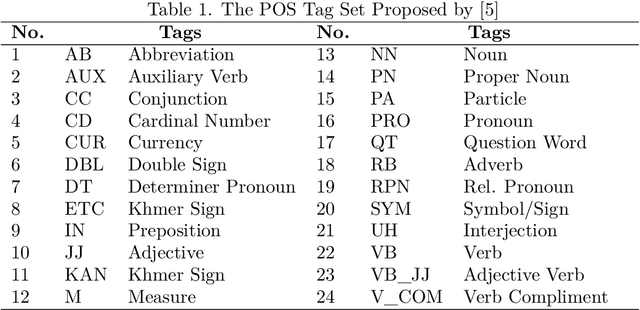
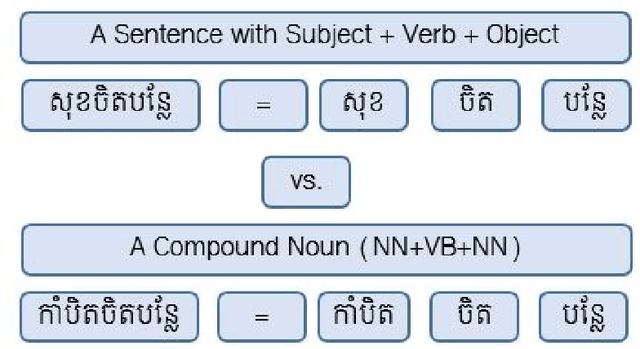
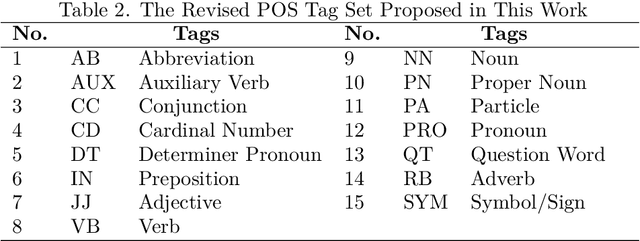
Khmer text is written from left to right with optional space. Space is not served as a word boundary but instead, it is used for readability or other functional purposes. Word segmentation is a prior step for downstream tasks such as part-of-speech (POS) tagging and thus, the robustness of POS tagging highly depends on word segmentation. The conventional Khmer POS tagging is a two-stage process that begins with word segmentation and then actual tagging of each word, afterward. In this work, a joint word segmentation and POS tagging approach using a single deep learning model is proposed so that word segmentation and POS tagging can be performed spontaneously. The proposed model was trained and tested using the publicly available Khmer POS dataset. The validation suggested that the performance of the joint model is on par with the conventional two-stage POS tagging.
Sub-band Knowledge Distillation Framework for Speech Enhancement
May 29, 2020


In single-channel speech enhancement, methods based on full-band spectral features have been widely studied. However, only a few methods pay attention to non-full-band spectral features. In this paper, we explore a knowledge distillation framework based on sub-band spectral mapping for single-channel speech enhancement. Specifically, we divide the full frequency band into multiple sub-bands and pre-train an elite-level sub-band enhancement model (teacher model) for each sub-band. These teacher models are dedicated to processing their own sub-bands. Next, under the teacher models' guidance, we train a general sub-band enhancement model (student model) that works for all sub-bands. Without increasing the number of model parameters and computational complexity, the student model's performance is further improved. To evaluate our proposed method, we conducted a large number of experiments on an open-source data set. The final experimental results show that the guidance from the elite-level teacher models dramatically improves the student model's performance, which exceeds the full-band model by employing fewer parameters.