 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio Deep Fake Detection System with Neural Stitching for ADD 2022
Apr 20, 2022
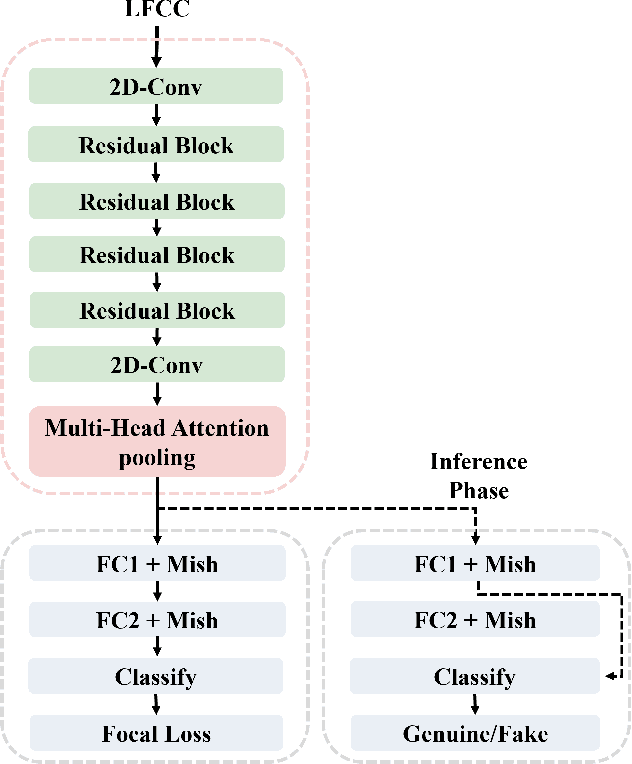
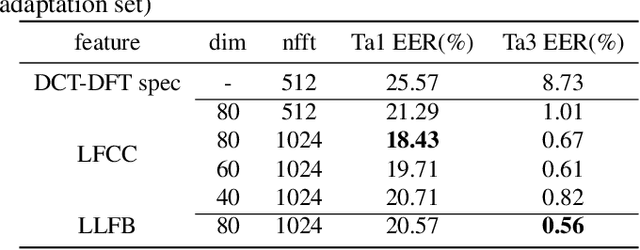


This paper describes our best system and methodology for ADD 2022: The First Audio Deep Synthesis Detection Challenge\cite{Yi2022ADD}. The very same system was used for both two rounds of evaluation in Track 3.2 with a similar training methodology. The first round of Track 3.2 data is generated from Text-to-Speech(TTS) or voice conversion (VC) algorithms, while the second round of data consists of generated fake audio from other participants in Track 3.1, aiming to spoof our systems. Our systems use a standard 34-layer ResNet, with multi-head attention pooling \cite{india2019self} to learn the discriminative embedding for fake audio and spoof detection. We further utilize neural stitching to boost the model's generalization capability in order to perform equally well in different tasks, and more details will be explained in the following sessions. The experiments show that our proposed method outperforms all other systems with a 10.1% equal error rate(EER) in Track 3.2.
Encrypted Speech Recognition using Deep Polynomial Networks
May 11, 2019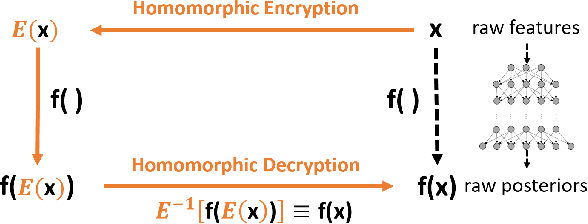
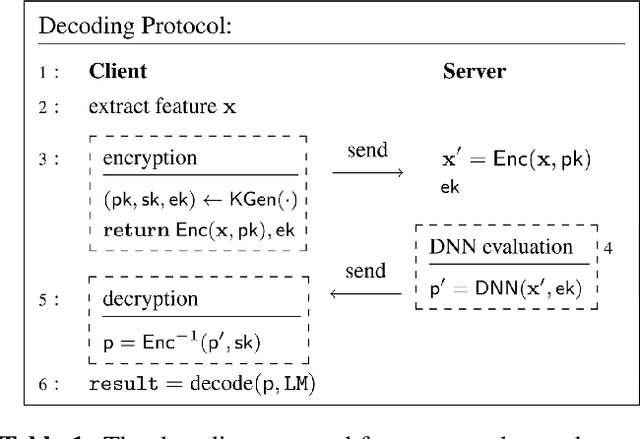
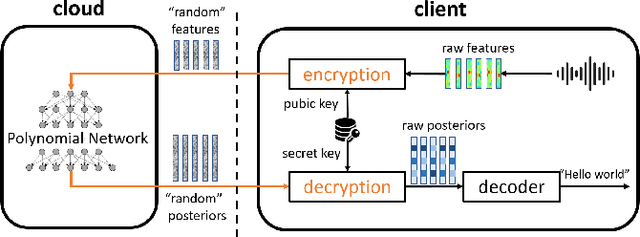
The cloud-based speech recognition/API provides developers or enterprises an easy way to create speech-enabled features in their applications. However, sending audios about personal or company internal information to the cloud, raises concerns about the privacy and security issues. The recognition results generated in cloud may also reveal some sensitive information. This paper proposes a deep polynomial network (DPN) that can be applied to the encrypted speech as an acoustic model. It allows clients to send their data in an encrypted form to the cloud to ensure that their data remains confidential, at mean while the DPN can still make frame-level predictions over the encrypted speech and return them in encrypted form. One good property of the DPN is that it can be trained on unencrypted speech features in the traditional way. To keep the cloud away from the raw audio and recognition results, a cloud-local joint decoding framework is also proposed. We demonstrate the effectiveness of model and framework on the Switchboard and Cortana voice assistant tasks with small performance degradation and latency increased comparing with the traditional cloud-based DNNs.
Sparsification via Compressed Sensing for Automatic Speech Recognition
Feb 09, 2021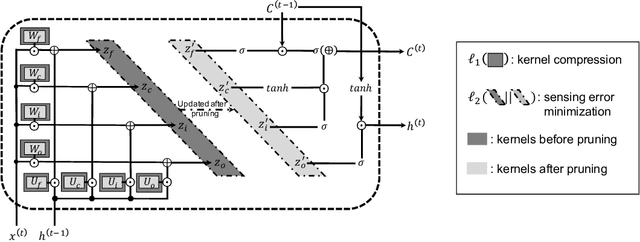
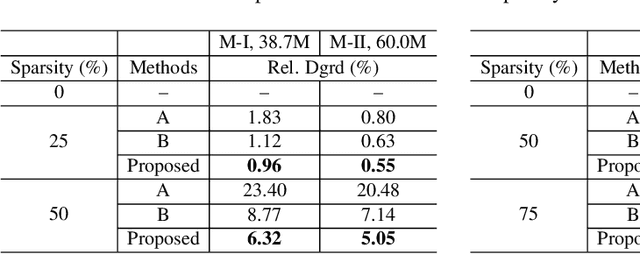
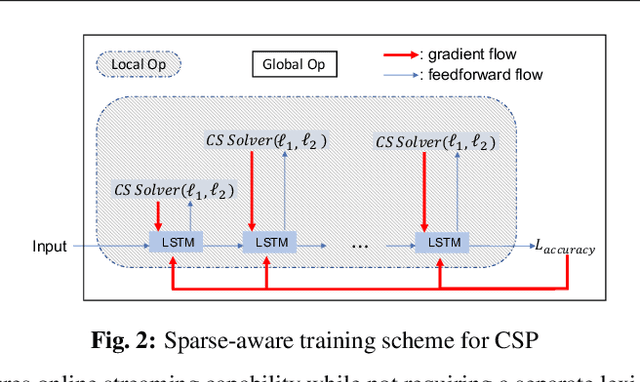
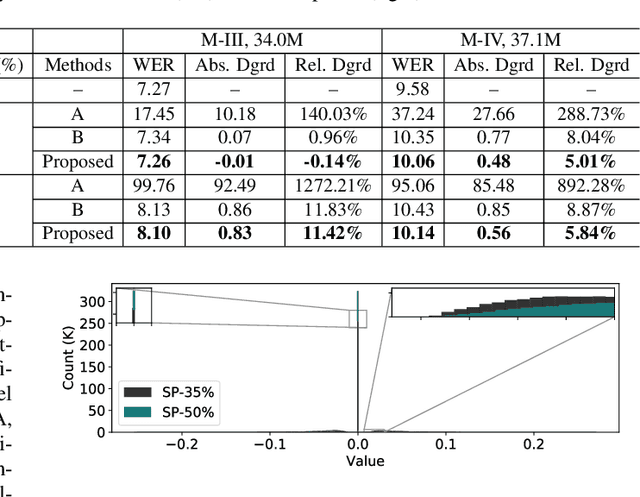
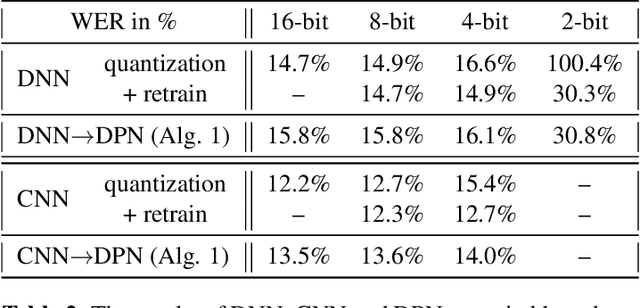
In order to achieve high accuracy for machine learning (ML) applications, it is essential to employ models with a large number of parameters. Certain applications, such as Automatic Speech Recognition (ASR), however, require real-time interactions with users, hence compelling the model to have as low latency as possible. Deploying large scale ML applications thus necessitates model quantization and compression, especially when running ML models on resource constrained devices. For example, by forcing some of the model weight values into zero, it is possible to apply zero-weight compression, which reduces both the model size and model reading time from the memory. In the literature, such methods are referred to as sparse pruning. The fundamental questions are when and which weights should be forced to zero, i.e. be pruned. In this work, we propose a compressed sensing based pruning (CSP) approach to effectively address those questions. By reformulating sparse pruning as a sparsity inducing and compression-error reduction dual problem, we introduce the classic compressed sensing process into the ML model training process. Using ASR task as an example, we show that CSP consistently outperforms existing approaches in the literature.
Joint Khmer Word Segmentation and Part-of-Speech Tagging Using Deep Learning
Mar 31, 2021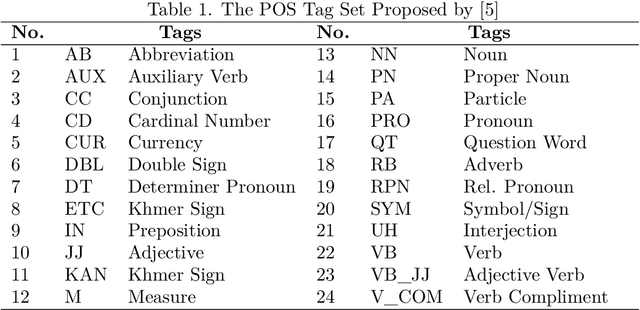
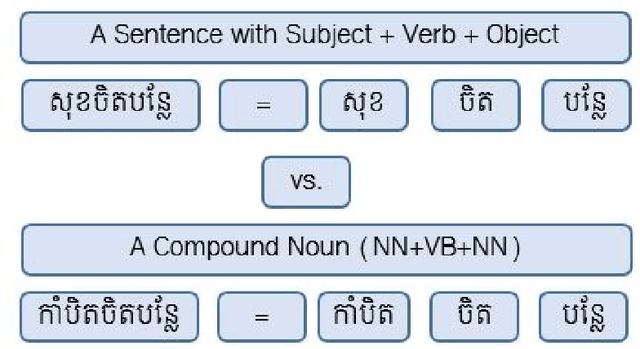
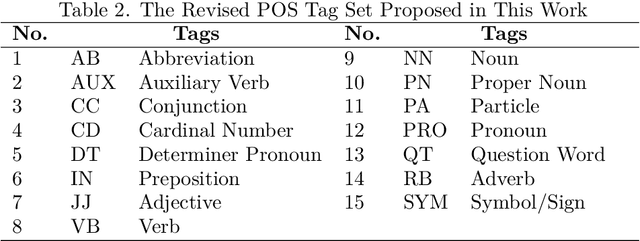
Khmer text is written from left to right with optional space. Space is not served as a word boundary but instead, it is used for readability or other functional purposes. Word segmentation is a prior step for downstream tasks such as part-of-speech (POS) tagging and thus, the robustness of POS tagging highly depends on word segmentation. The conventional Khmer POS tagging is a two-stage process that begins with word segmentation and then actual tagging of each word, afterward. In this work, a joint word segmentation and POS tagging approach using a single deep learning model is proposed so that word segmentation and POS tagging can be performed spontaneously. The proposed model was trained and tested using the publicly available Khmer POS dataset. The validation suggested that the performance of the joint model is on par with the conventional two-stage POS tagging.
Analysis of Disfluencies for automatic detection of Mild Cognitive Impartment: a deep learning approach
Mar 22, 2022
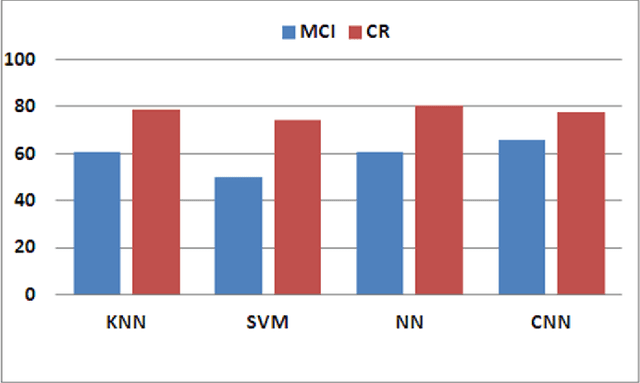
The so-called Mild Cognitive Impairment (MCI) or cognitive loss appears in a previous stage before Alzheimer's Disease (AD), but it does not seem sufficiently severe to interfere in independent abilities of daily life, so it usually does not receive an appropriate diagnosis. Its detection is a challenging issue to be addressed by medical specialists. This work presents a novel proposal based on automatic analysis of speech and disfluencies aimed at supporting MCI diagnosis. The approach includes deep learning by means of Convolutional Neural Networks (CNN) and non-linear multifeature modelling. Moreover, to select the most relevant features non-parametric Mann-Whitney U-testt and Support Vector Machine Attribute (SVM) evaluation are used.
* 5 pages, published in 2017 International Conference and Workshop on Bioinspired Intelligence (IWOBI), 2017, pp. 1-4, 10-12 July Funchal (Portugal)
Deep Representation Learning in Speech Processing: Challenges, Recent Advances, and Future Trends
Jan 02, 2020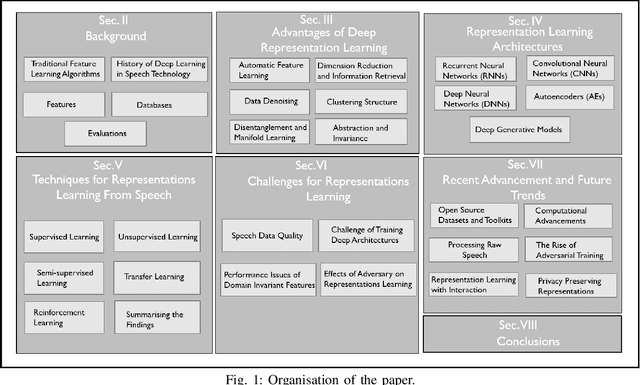
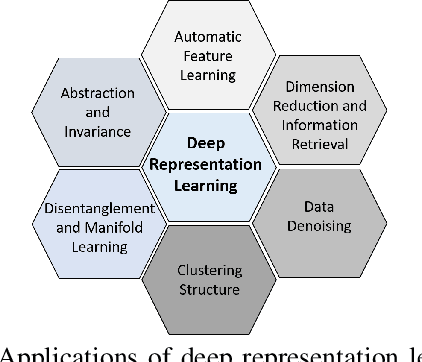
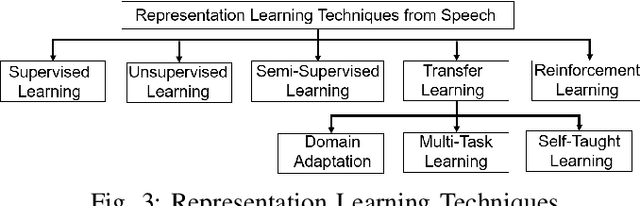
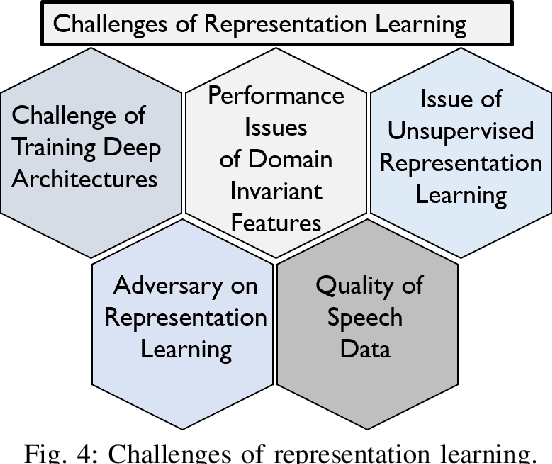
Research on speech processing has traditionally considered the task of designing hand-engineered acoustic features (feature engineering) as a separate distinct problem from the task of designing efficient machine learning (ML) models to make prediction and classification decisions. There are two main drawbacks to this approach: firstly, the feature engineering being manual is cumbersome and requires human knowledge; and secondly, the designed features might not be best for the objective at hand. This has motivated the adoption of a recent trend in speech community towards utilisation of representation learning techniques, which can learn an intermediate representation of the input signal automatically that better suits the task at hand and hence lead to improved performance. The significance of representation learning has increased with advances in deep learning (DL), where the representations are more useful and less dependent on human knowledge, making it very conducive for tasks like classification, prediction, etc. The main contribution of this paper is to present an up-to-date and comprehensive survey on different techniques of speech representation learning by bringing together the scattered research across three distinct research areas including Automatic Speech Recognition (ASR), Speaker Recognition (SR), and Speaker Emotion Recognition (SER). Recent reviews in speech have been conducted for ASR, SR, and SER, however, none of these has focused on the representation learning from speech---a gap that our survey aims to bridge.
Vector Representations of Idioms in Conversational Systems
May 07, 2022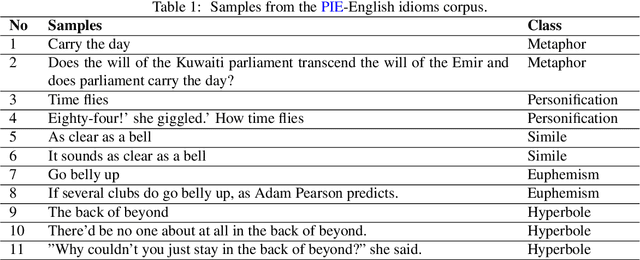
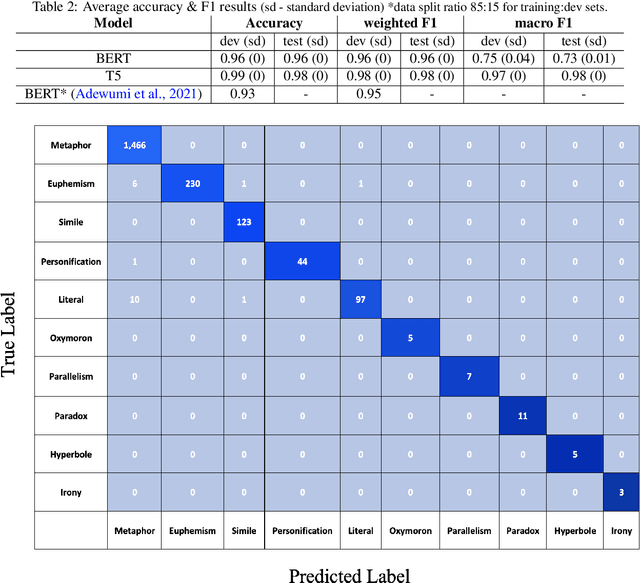
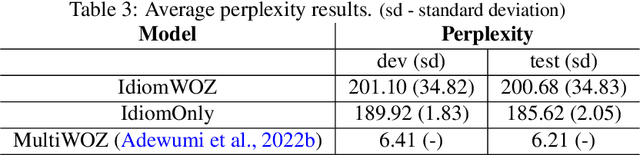
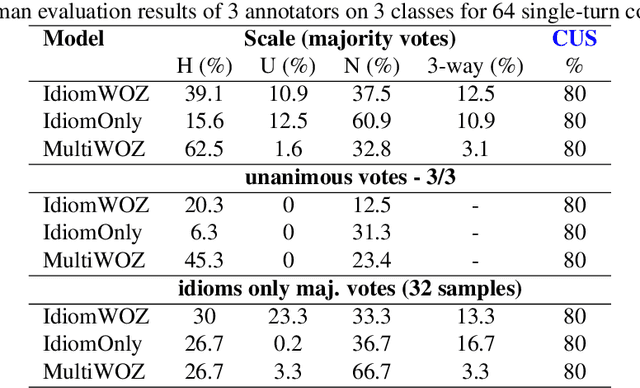
We demonstrate, in this study, that an open-domain conversational system trained on idioms or figurative language generates more fitting responses to prompts containing idioms. Idioms are part of everyday speech in many languages, across many cultures, but they pose a great challenge for many Natural Language Processing (NLP) systems that involve tasks such as Information Retrieval (IR) and Machine Translation (MT), besides conversational AI. We utilize the Potential Idiomatic Expression (PIE)-English idioms corpus for the two tasks that we investigate: classification and conversation generation. We achieve state-of-the-art (SoTA) result of 98% macro F1 score on the classification task by using the SoTA T5 model. We experiment with three instances of the SoTA dialogue model, Dialogue Generative Pre-trained Transformer (DialoGPT), for conversation generation. Their performances are evaluated using the automatic metric perplexity and human evaluation. The results show that the model trained on the idiom corpus generates more fitting responses to prompts containing idioms 71.9% of the time, compared to a similar model not trained on the idioms corpus. We contribute the model checkpoint/demo and code on the HuggingFace hub for public access.
Target Based Speech Act Classification in Political Campaign Text
May 20, 2019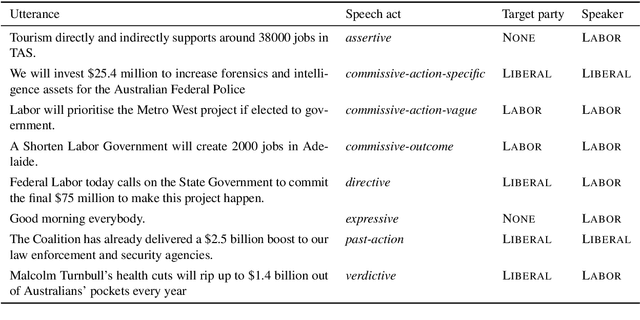
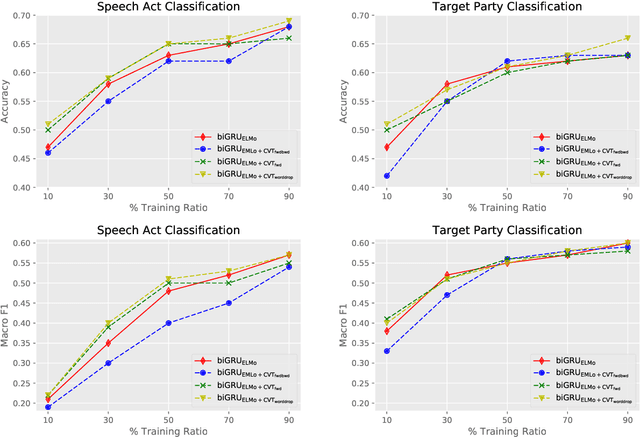

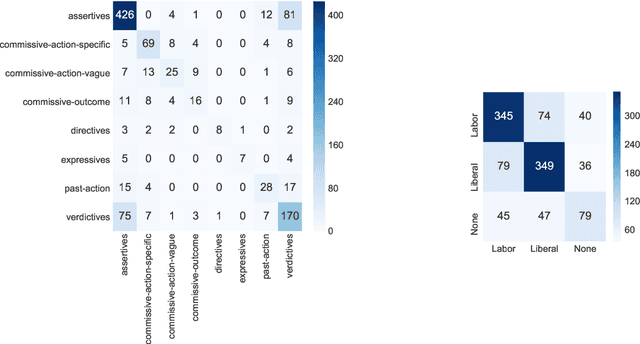
We study pragmatics in political campaign text, through analysis of speech acts and the target of each utterance. We propose a new annotation schema incorporating domain-specific speech acts, such as commissive-action, and present a novel annotated corpus of media releases and speech transcripts from the 2016 Australian election cycle. We show how speech acts and target referents can be modeled as sequential classification, and evaluate several techniques, exploiting contextualized word representations, semi-supervised learning, task dependencies and speaker meta-data.
AccentDB: A Database of Non-Native English Accents to Assist Neural Speech Recognition
May 16, 2020
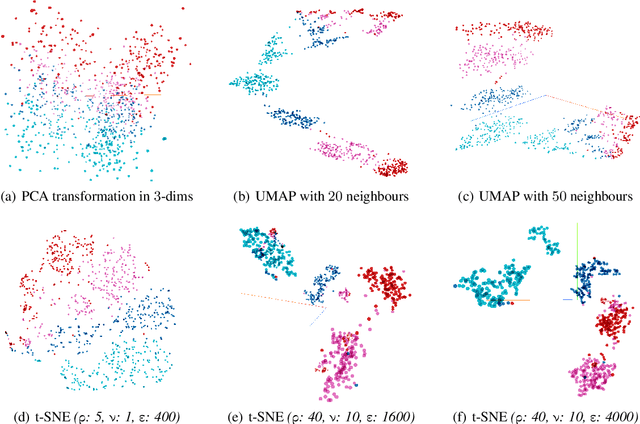
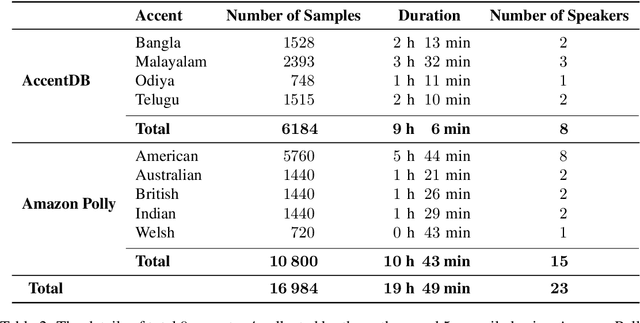
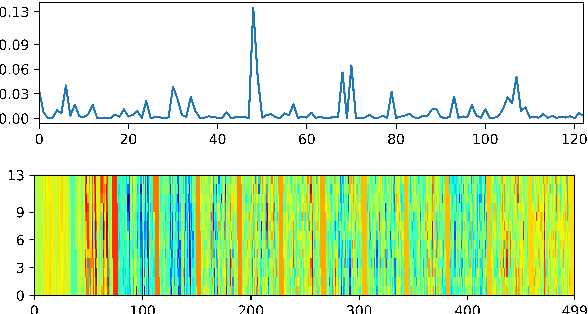
Modern Automatic Speech Recognition (ASR) technology has evolved to identify the speech spoken by native speakers of a language very well. However, identification of the speech spoken by non-native speakers continues to be a major challenge for it. In this work, we first spell out the key requirements for creating a well-curated database of speech samples in non-native accents for training and testing robust ASR systems. We then introduce AccentDB, one such database that contains samples of 4 Indian-English accents collected by us, and a compilation of samples from 4 native-English, and a metropolitan Indian-English accent. We also present an analysis on separability of the collected accent data. Further, we present several accent classification models and evaluate them thoroughly against human-labelled accent classes. We test the generalization of our classifier models in a variety of setups of seen and unseen data. Finally, we introduce the task of accent neutralization of non-native accents to native accents using autoencoder models with task-specific architectures. Thus, our work aims to aid ASR systems at every stage of development with a database for training, classification models for feature augmentation, and neutralization systems for acoustic transformations of non-native accents of English.
On the relevance of bandwidth extension for speaker identification
Feb 24, 2022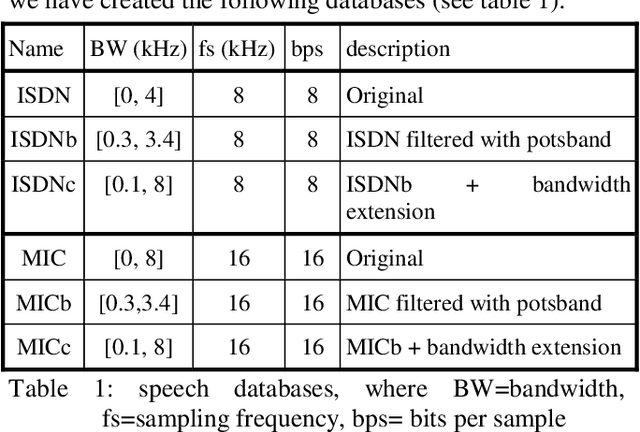
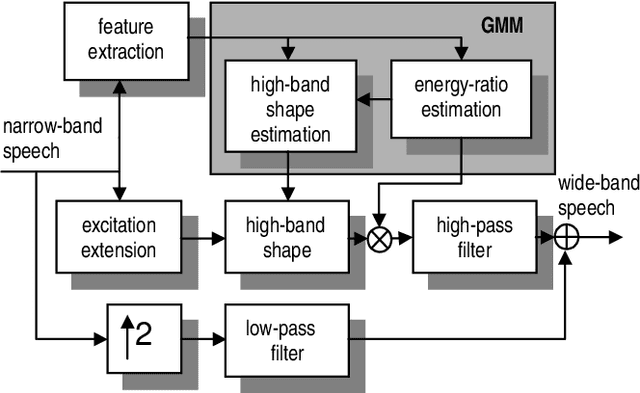
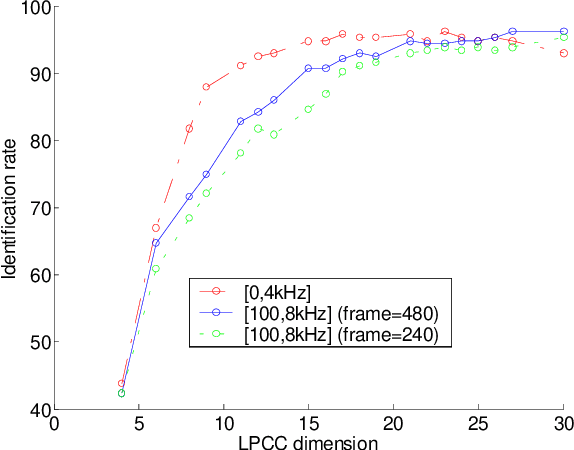
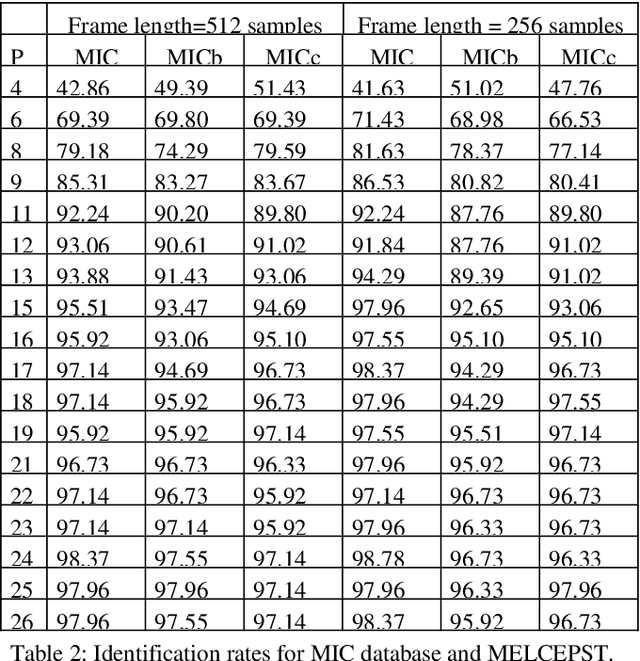
In this paper we discuss the relevance of bandwidth extension for speaker identification tasks. Mainly we want to study if it is possible to recognize voices that have been bandwith extended. For this purpose, we created two different databases (microphonic and ISDN) of speech signals that were bandwidth extended from telephone bandwidth ([300, 3400] Hz) to full bandwidth ([100, 8000] Hz). We have evaluated different parameterizations, and we have found that the MELCEPST parameterization can take advantage of the bandwidth extension algorithms in several situations.
* 4 pages