 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hopeful_Men@LT-EDI-EACL2021: Hope Speech Detection Using Indic Transliteration and Transformers
Feb 24, 2021
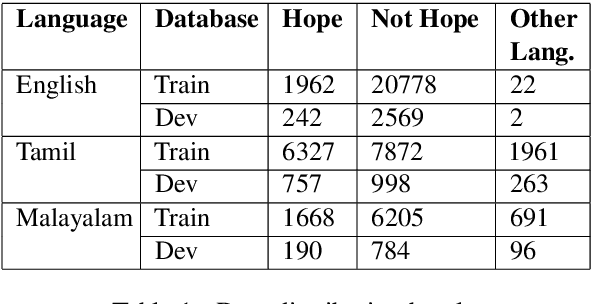
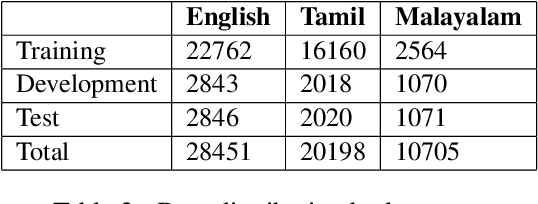
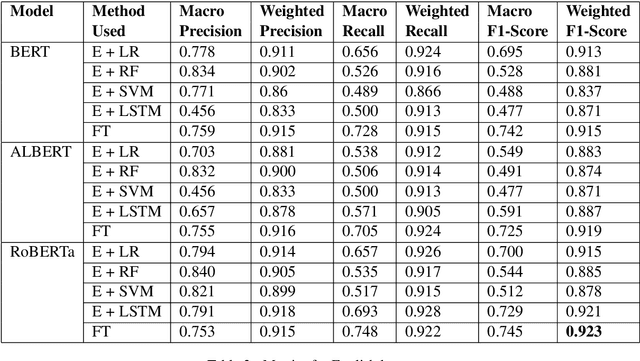
This paper aims to describe the approach we used to detect hope speech in the HopeEDI dataset. We experimented with two approaches. In the first approach, we used contextual embeddings to train classifiers using logistic regression, random forest, SVM, and LSTM based models.The second approach involved using a majority voting ensemble of 11 models which were obtained by fine-tuning pre-trained transformer models (BERT, ALBERT, RoBERTa, IndicBERT) after adding an output layer. We found that the second approach was superior for English, Tamil and Malayalam. Our solution got a weighted F1 score of 0.93, 0.75 and 0.49 for English,Malayalam and Tamil respectively. Our solution ranked first in English, eighth in Malayalam and eleventh in Tamil.
Building and curating conversational corpora for diversity-aware language science and technology
Mar 10, 2022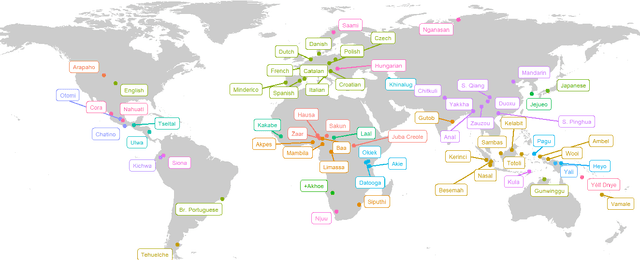
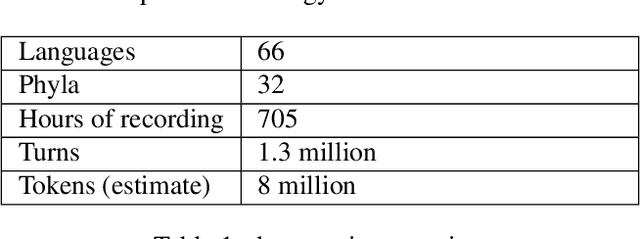
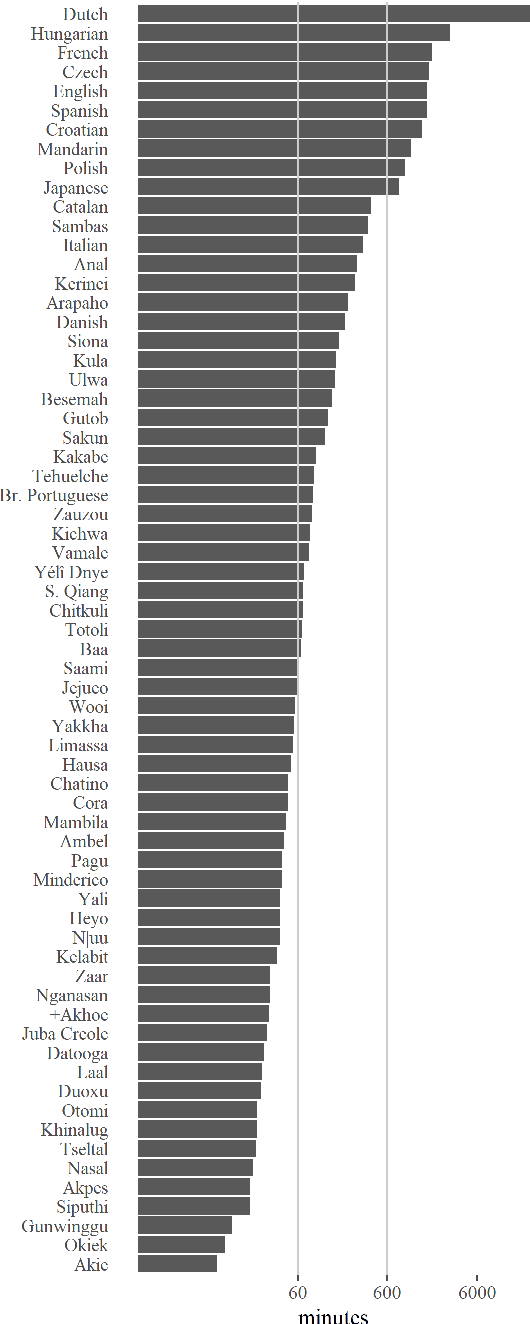
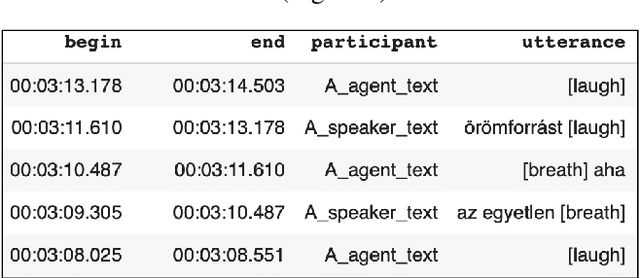
We present a pipeline and tools to build a maximally natural data set of conversational interaction that covers 66 languages and varieties from 32 phyla. We describe the curation and compilation process moving from diverse language documentation corpora to a unified format and describe an open-source tool "convo-parse" to help in quality control and assessment of conversational data. We conclude with two case studies of how diverse data sets can inform interactional linguistics and speech recognition technology and thus contribute to broadening the empirical foundations of language sciences and technologies of the future.
A Spectral Energy Distance for Parallel Speech Synthesis
Aug 03, 2020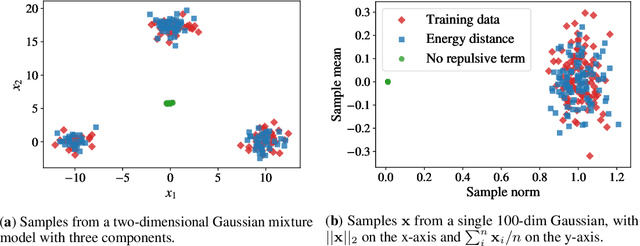
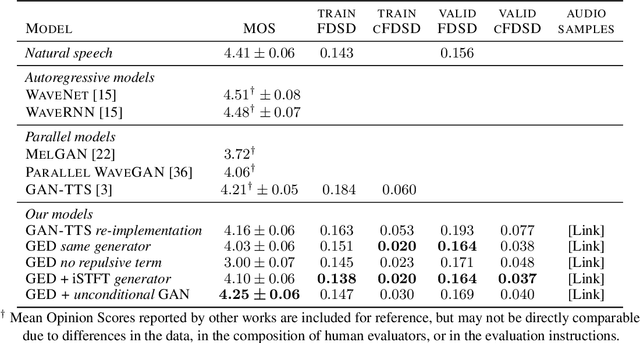
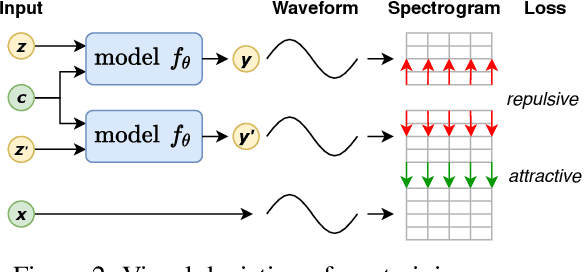
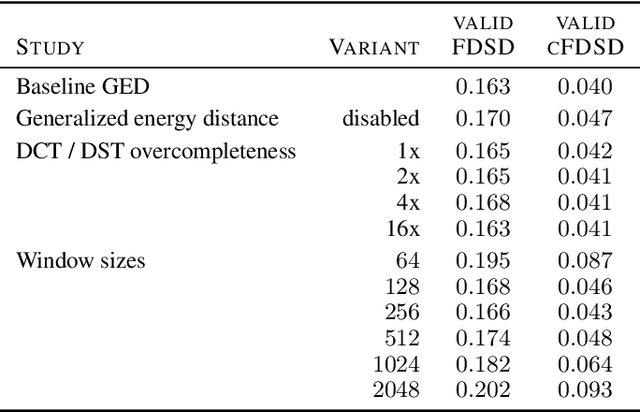
Speech synthesis is an important practical generative modeling problem that has seen great progress over the last few years, with likelihood-based autoregressive neural models now outperforming traditional concatenative systems. A downside of such autoregressive models is that they require executing tens of thousands of sequential operations per second of generated audio, making them ill-suited for deployment on specialized deep learning hardware. Here, we propose a new learning method that allows us to train highly parallel models of speech, without requiring access to an analytical likelihood function. Our approach is based on a generalized energy distance between the distributions of the generated and real audio. This spectral energy distance is a proper scoring rule with respect to the distribution over magnitude-spectrograms of the generated waveform audio and offers statistical consistency guarantees. The distance can be calculated from minibatches without bias, and does not involve adversarial learning, yielding a stable and consistent method for training implicit generative models. Empirically, we achieve state-of-the-art generation quality among implicit generative models, as judged by the recently-proposed cFDSD metric. When combining our method with adversarial techniques, we also improve upon the recently-proposed GAN-TTS model in terms of Mean Opinion Score as judged by trained human evaluators.
FAAG: Fast Adversarial Audio Generation through Interactive Attack Optimisation
Feb 11, 2022
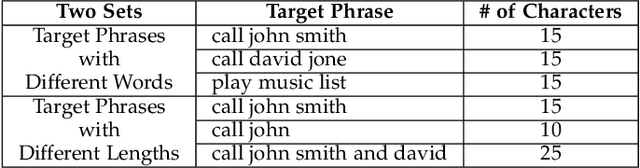
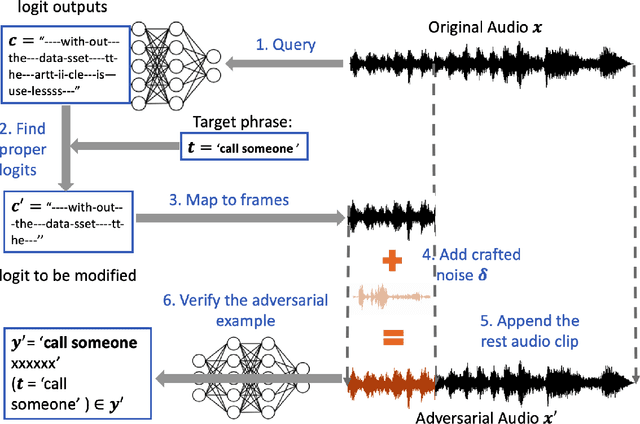
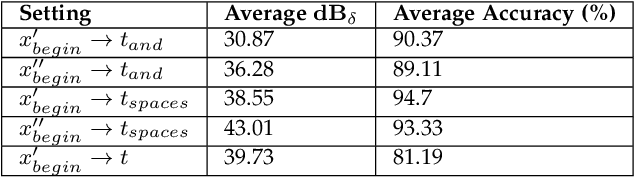
Automatic Speech Recognition services (ASRs) inherit deep neural networks' vulnerabilities like crafted adversarial examples. Existing methods often suffer from low efficiency because the target phases are added to the entire audio sample, resulting in high demand for computational resources. This paper proposes a novel scheme named FAAG as an iterative optimization-based method to generate targeted adversarial examples quickly. By injecting the noise over the beginning part of the audio, FAAG generates adversarial audio in high quality with a high success rate timely. Specifically, we use audio's logits output to map each character in the transcription to an approximate position of the audio's frame. Thus, an adversarial example can be generated by FAAG in approximately two minutes using CPUs only and around ten seconds with one GPU while maintaining an average success rate over 85%. Specifically, the FAAG method can speed up around 60% compared with the baseline method during the adversarial example generation process. Furthermore, we found that appending benign audio to any suspicious examples can effectively defend against the targeted adversarial attack. We hope that this work paves the way for inventing new adversarial attacks against speech recognition with computational constraints.
Artificial bandwidth extension using deep neural network and $H^\infty$ sampled-data control theory
Aug 30, 2021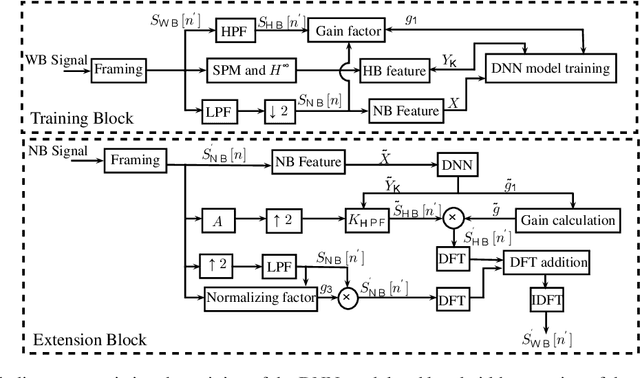


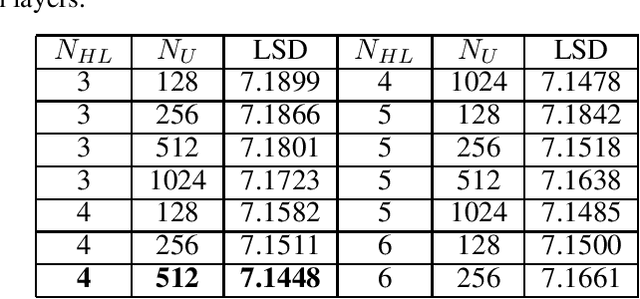
Artificial bandwidth extension is applied to speech signals to improve their quality in narrowband telephonic communication. For accomplishing this, the missing high-frequency (high-band) components of speech signals are recovered by utilizing a new extrapolation process based on sampled-data control theory and deep neural network (DNN). The $H^\infty$ sampled-data control theory helps in designing of a high-band filter to recover the high-frequency signals by optimally utilizing the inter-sample signals. Non-stationary (time-varying) characteristics of speech signals forces to use numerous high-band filters. Hence, we use a deep neural network for estimating the high-band filter information and a gain factor for a specified narrowband information of the unseen signal. The objective analysis is done on the TIMIT dataset and RSR15 dataset. Additionally, the objective analysis is performed separately for the voiced speech as well as for the unvoiced speech as generally needed in speech processing. Subjective analysis is done on the RSR15 dataset.
Toward Cross-Domain Speech Recognition with End-to-End Models
Mar 09, 2020
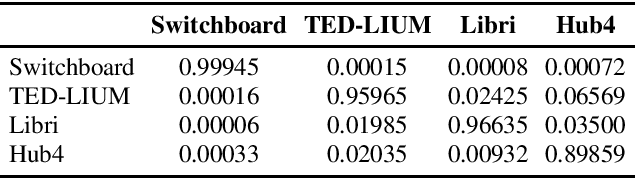
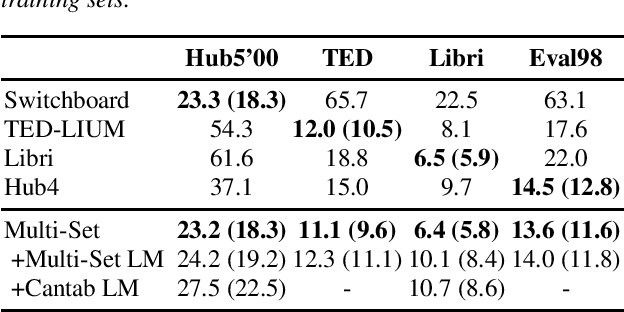
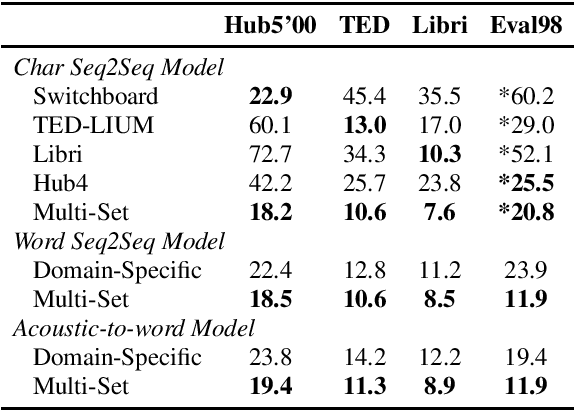
In the area of multi-domain speech recognition, research in the past focused on hybrid acoustic models to build cross-domain and domain-invariant speech recognition systems. In this paper, we empirically examine the difference in behavior between hybrid acoustic models and neural end-to-end systems when mixing acoustic training data from several domains. For these experiments we composed a multi-domain dataset from public sources, with the different domains in the corpus covering a wide variety of topics and acoustic conditions such as telephone conversations, lectures, read speech and broadcast news. We show that for the hybrid models, supplying additional training data from other domains with mismatched acoustic conditions does not increase the performance on specific domains. However, our end-to-end models optimized with sequence-based criterion generalize better than the hybrid models on diverse domains. In term of word-error-rate performance, our experimental acoustic-to-word and attention-based models trained on multi-domain dataset reach the performance of domain-specific long short-term memory (LSTM) hybrid models, thus resulting in multi-domain speech recognition systems that do not suffer in performance over domain specific ones. Moreover, the use of neural end-to-end models eliminates the need of domain-adapted language models during recognition, which is a great advantage when the input domain is unknown.
It's Raw! Audio Generation with State-Space Models
Feb 20, 2022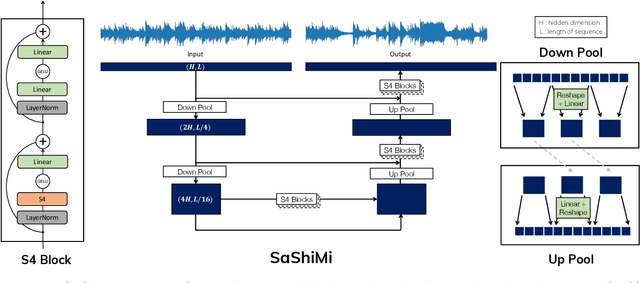

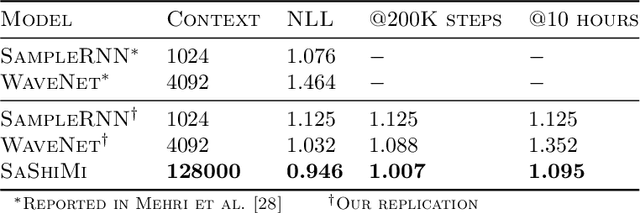
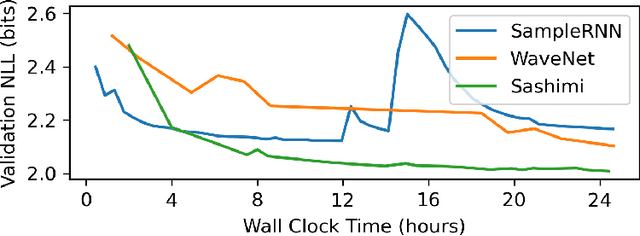
Developing architectures suitable for modeling raw audio is a challenging problem due to the high sampling rates of audio waveforms. Standard sequence modeling approaches like RNNs and CNNs have previously been tailored to fit the demands of audio, but the resultant architectures make undesirable computational tradeoffs and struggle to model waveforms effectively. We propose SaShiMi, a new multi-scale architecture for waveform modeling built around the recently introduced S4 model for long sequence modeling. We identify that S4 can be unstable during autoregressive generation, and provide a simple improvement to its parameterization by drawing connections to Hurwitz matrices. SaShiMi yields state-of-the-art performance for unconditional waveform generation in the autoregressive setting. Additionally, SaShiMi improves non-autoregressive generation performance when used as the backbone architecture for a diffusion model. Compared to prior architectures in the autoregressive generation setting, SaShiMi generates piano and speech waveforms which humans find more musical and coherent respectively, e.g. 2x better mean opinion scores than WaveNet on an unconditional speech generation task. On a music generation task, SaShiMi outperforms WaveNet on density estimation and speed at both training and inference even when using 3x fewer parameters. Code can be found at https://github.com/HazyResearch/state-spaces and samples at https://hazyresearch.stanford.edu/sashimi-examples.
On the Difficulty of Segmenting Words with Attention
Sep 21, 2021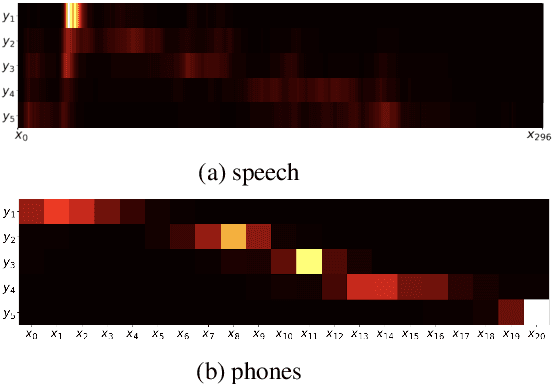

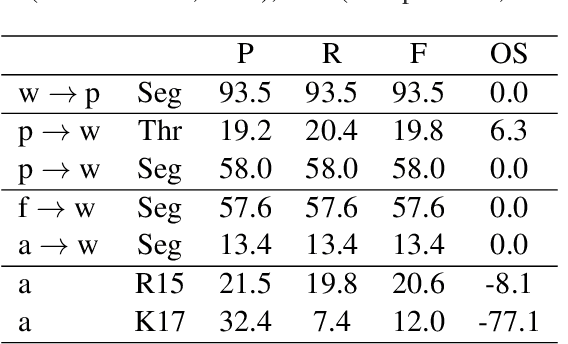
Word segmentation, the problem of finding word boundaries in speech, is of interest for a range of tasks. Previous papers have suggested that for sequence-to-sequence models trained on tasks such as speech translation or speech recognition, attention can be used to locate and segment the words. We show, however, that even on monolingual data this approach is brittle. In our experiments with different input types, data sizes, and segmentation algorithms, only models trained to predict phones from words succeed in the task. Models trained to predict words from either phones or speech (i.e., the opposite direction needed to generalize to new data), yield much worse results, suggesting that attention-based segmentation is only useful in limited scenarios.
Deep Noise Suppression Maximizing Non-Differentiable PESQ Mediated by a Non-Intrusive PESQNet
Nov 06, 2021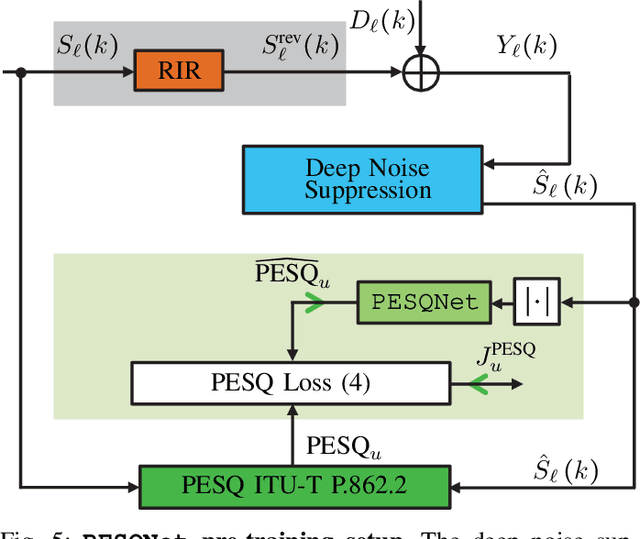
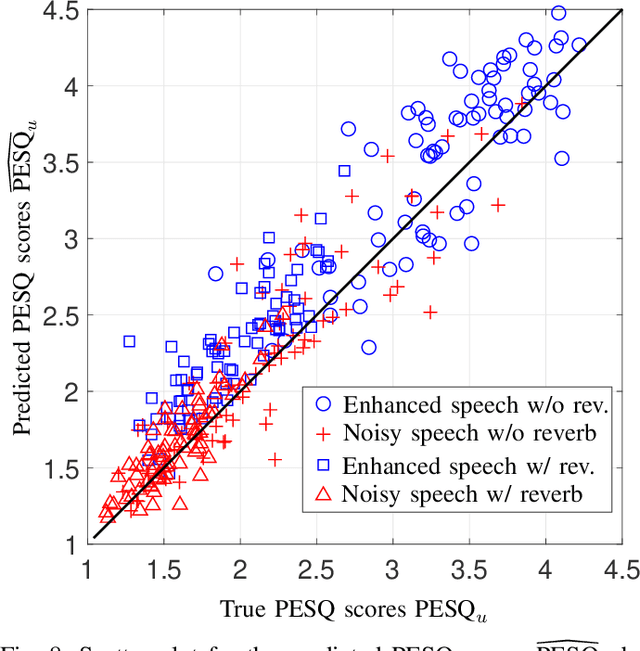
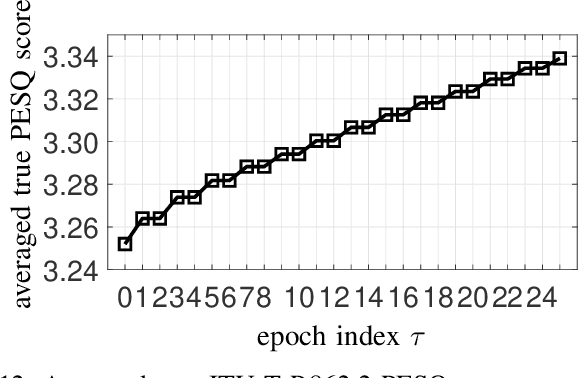
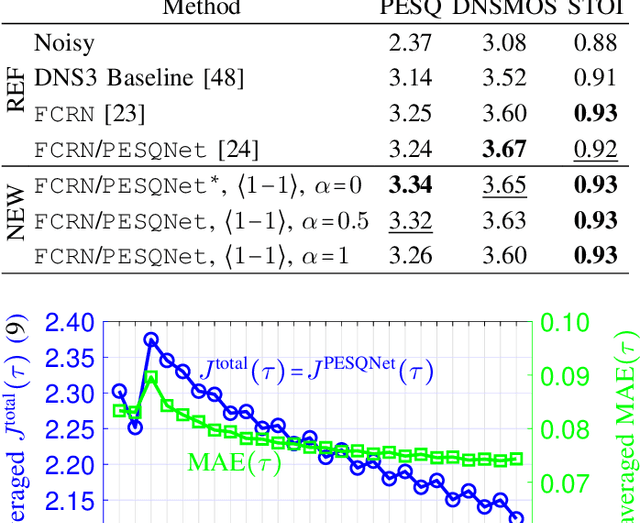
Speech enhancement employing deep neural networks (DNNs) for denoising are called deep noise suppression (DNS). During training, DNS methods are typically trained with mean squared error (MSE) type loss functions, which do not guarantee good perceptual quality. Perceptual evaluation of speech quality (PESQ) is a widely used metric for evaluating speech quality. However, the original PESQ algorithm is non-differentiable, and therefore cannot directly be used as optimization criterion for gradient-based learning. In this work, we propose an end-to-end non-intrusive PESQNet DNN to estimate the PESQ scores of the enhanced speech signal. Thus, by providing a reference-free perceptual loss, it serves as a mediator towards the DNS training, allowing to maximize the PESQ score of the enhanced speech signal. We illustrate the potential of our proposed PESQNet-mediated training on the basis of an already strong baseline DNS. As further novelty, we propose to train the DNS and the PESQNet alternatingly to keep the PESQNet up-to-date and perform well specifically for the DNS under training. Our proposed method is compared to the same DNS trained with MSE-based loss for joint denoising and dereverberation, and the Interspeech 2021 DNS Challenge baseline. Detailed analysis shows that the PESQNet mediation can further increase the DNS performance by about 0.1 PESQ points on synthetic test data and by 0.03 DNSMOS points on real test data, compared to training with the MSE-based loss. Our proposed method also outperforms the Challenge baseline by 0.2 PESQ points on synthetic test data and 0.1 DNSMOS points on real test data.
Human-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021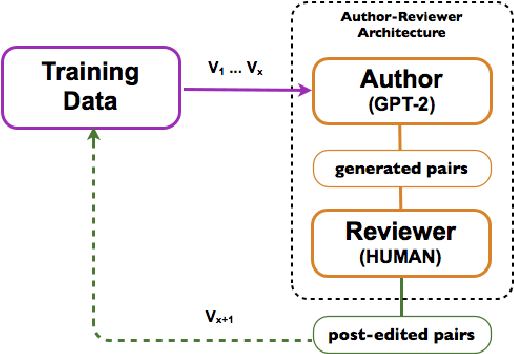
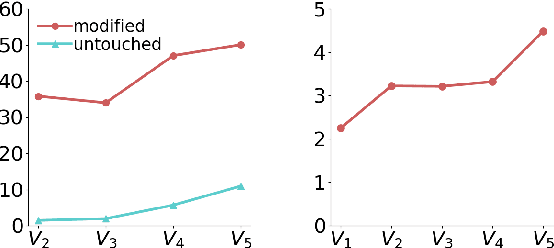
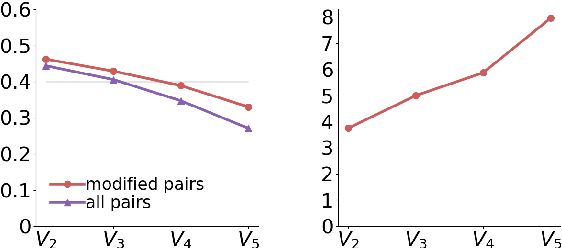
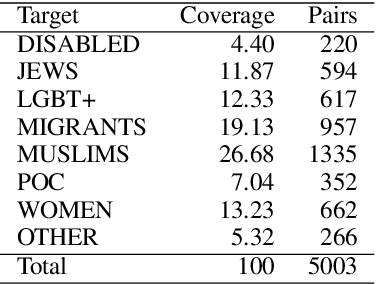
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.