 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-supervised Contrastive Video-Speech Representation Learning for Ultrasound
Aug 14, 2020



In medical imaging, manual annotations can be expensive to acquire and sometimes infeasible to access, making conventional deep learning-based models difficult to scale. As a result, it would be beneficial if useful representations could be derived from raw data without the need for manual annotations. In this paper, we propose to address the problem of self-supervised representation learning with multi-modal ultrasound video-speech raw data. For this case, we assume that there is a high correlation between the ultrasound video and the corresponding narrative speech audio of the sonographer. In order to learn meaningful representations, the model needs to identify such correlation and at the same time understand the underlying anatomical features. We designed a framework to model the correspondence between video and audio without any kind of human annotations. Within this framework, we introduce cross-modal contrastive learning and an affinity-aware self-paced learning scheme to enhance correlation modelling. Experimental evaluations on multi-modal fetal ultrasound video and audio show that the proposed approach is able to learn strong representations and transfers well to downstream tasks of standard plane detection and eye-gaze prediction.
Lookup-Table Recurrent Language Models for Long Tail Speech Recognition
Apr 09, 2021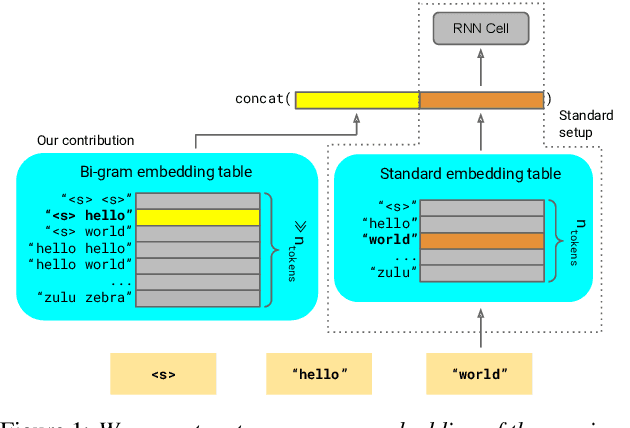
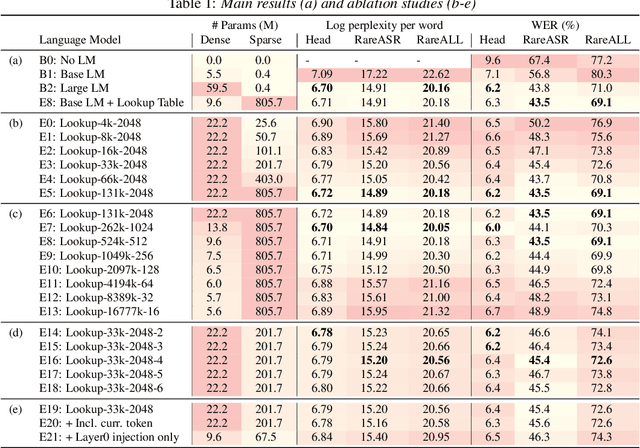
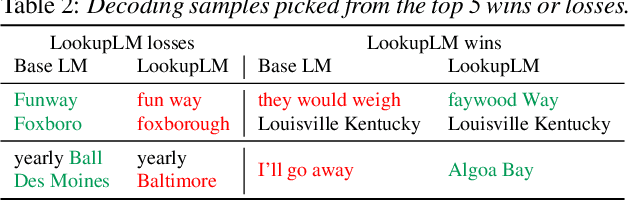

We introduce Lookup-Table Language Models (LookupLM), a method for scaling up the size of RNN language models with only a constant increase in the floating point operations, by increasing the expressivity of the embedding table. In particular, we instantiate an (additional) embedding table which embeds the previous n-gram token sequence, rather than a single token. This allows the embedding table to be scaled up arbitrarily -- with a commensurate increase in performance -- without changing the token vocabulary. Since embeddings are sparsely retrieved from the table via a lookup; increasing the size of the table adds neither extra operations to each forward pass nor extra parameters that need to be stored on limited GPU/TPU memory. We explore scaling n-gram embedding tables up to nearly a billion parameters. When trained on a 3-billion sentence corpus, we find that LookupLM improves long tail log perplexity by 2.44 and long tail WER by 23.4% on a downstream speech recognition task over a standard RNN language model baseline, an improvement comparable to a scaling up the baseline by 6.2x the number of floating point operations.
Compositional embedding models for speaker identification and diarization with simultaneous speech from 2+ speakers
Oct 22, 2020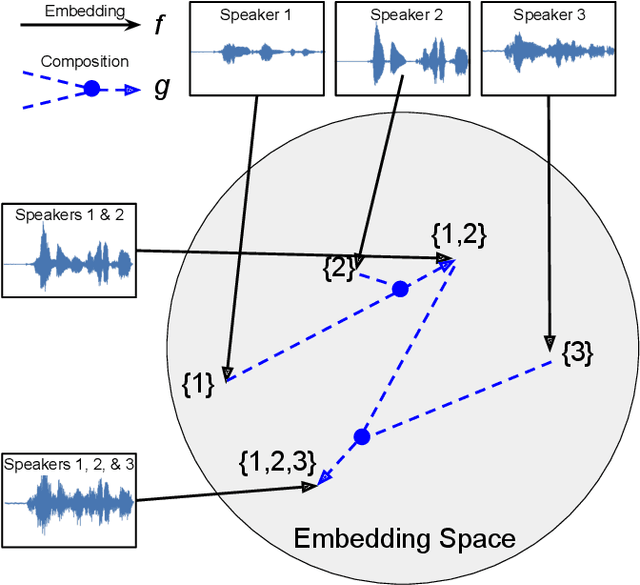
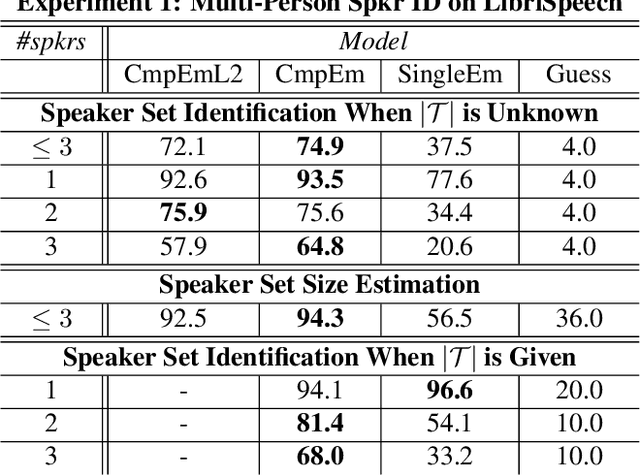

We propose a new method for speaker diarization that can handle overlapping speech with 2+ people. Our method is based on compositional embeddings [1]: Like standard speaker embedding methods such as x-vector [2], compositional embedding models contain a function f that separates speech from different speakers. In addition, they include a composition function g to compute set-union operations in the embedding space so as to infer the set of speakers within the input audio. In an experiment on multi-person speaker identification using synthesized LibriSpeech data, the proposed method outperforms traditional embedding methods that are only trained to separate single speakers (not speaker sets). In a speaker diarization experiment on the AMI Headset Mix corpus, we achieve state-of-the-art accuracy (DER=22.93%), slightly higher than the previous best result (23.82% from [3]).
Hindi-English Code-Switching Speech Corpus
Sep 24, 2018



Code-switching refers to the usage of two languages within a sentence or discourse. It is a global phenomenon among multilingual communities and has emerged as an independent area of research. With the increasing demand for the code-switching automatic speech recognition (ASR) systems, the development of a code-switching speech corpus has become highly desirable. However, for training such systems, very limited code-switched resources are available as yet. In this work, we present our first efforts in building a code-switching ASR system in the Indian context. For that purpose, we have created a Hindi-English code-switching speech database. The database not only contains the speech utterances with code-switching properties but also covers the session and the speaker variations like pronunciation, accent, age, gender, etc. This database can be applied in several speech signal processing applications, such as code-switching ASR, language identification, language modeling, speech synthesis etc. This paper mainly presents an analysis of the statistics of the collected code-switching speech corpus. Later, the performance results for the ASR task have been reported for the created database.
Memory-Efficient Training of RNN-Transducer with Sampled Softmax
Mar 31, 2022
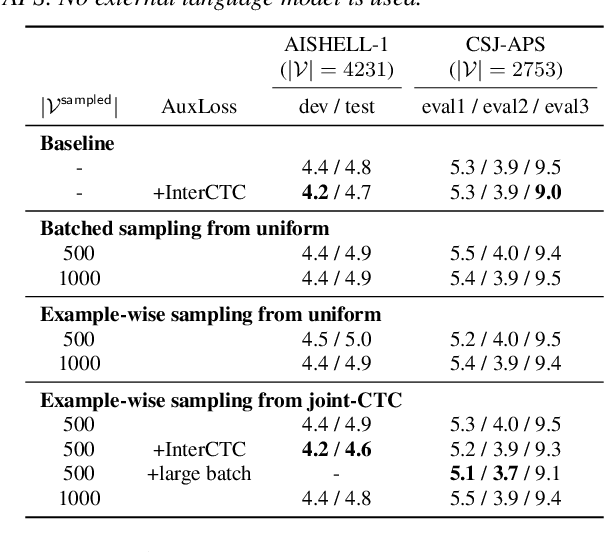
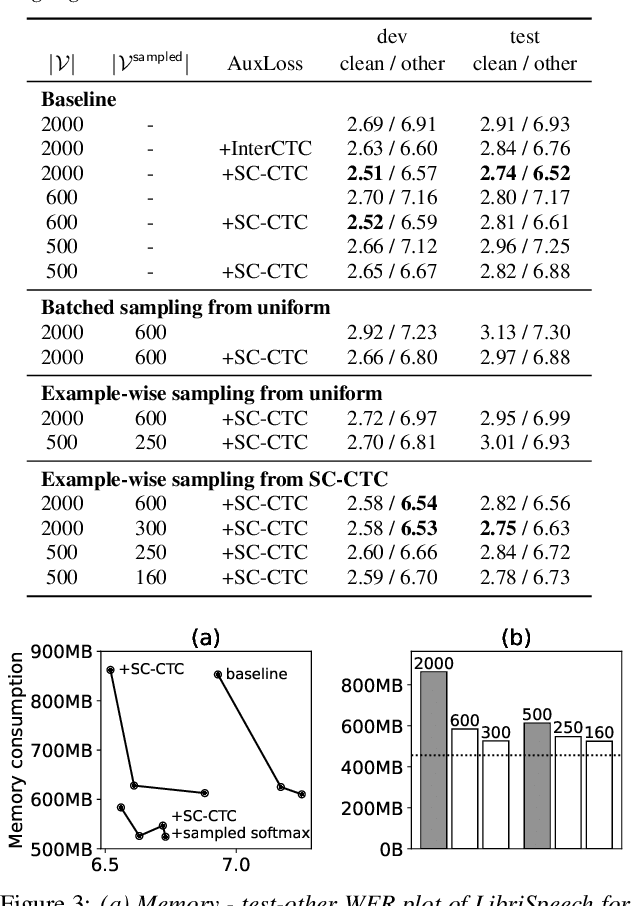
RNN-Transducer has been one of promising architectures for end-to-end automatic speech recognition. Although RNN-Transducer has many advantages including its strong accuracy and streaming-friendly property, its high memory consumption during training has been a critical problem for development. In this work, we propose to apply sampled softmax to RNN-Transducer, which requires only a small subset of vocabulary during training thus saves its memory consumption. We further extend sampled softmax to optimize memory consumption for a minibatch, and employ distributions of auxiliary CTC losses for sampling vocabulary to improve model accuracy. We present experimental results on LibriSpeech, AISHELL-1, and CSJ-APS, where sampled softmax greatly reduces memory consumption and still maintains the accuracy of the baseline model.
Towards countering hate speech and personal attack in social media
Dec 05, 2019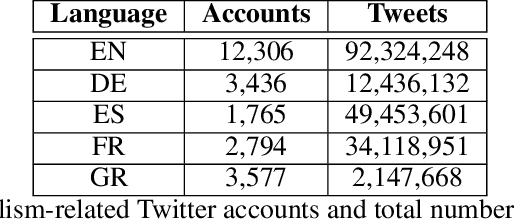
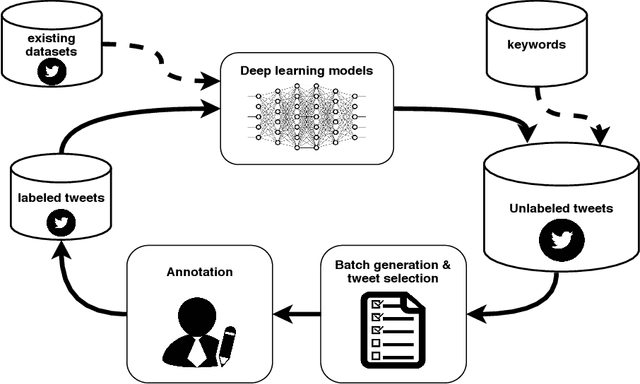
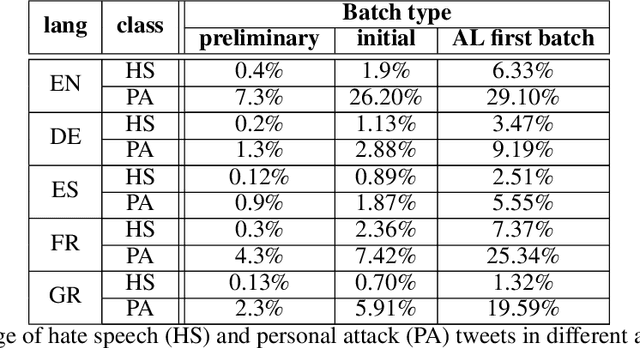
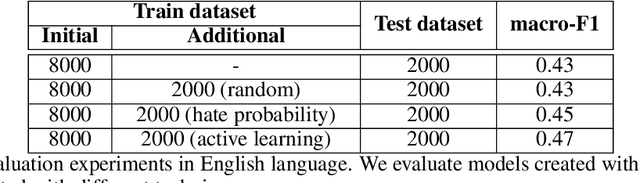
The damaging effects of hate speech in social media are evident during the last few years, and several organizations, researchers and the social media platforms themselves have tried to harness them without great success. Recently, following the advent of deep learning, several novel approaches appeared in the field of hate speech detection. However, it is apparent that such approaches depend on large-scale datasets in order to exhibit competitive performance. In this paper, we present a novel, publicly available collection of datasets in five different languages, that consists of tweets referring to journalism-related accounts, including high-quality human annotations for hate speech and personal attack. To build the datasets we follow a concise annotation strategy and employ an active learning approach. Additionally, we present a number of state-of-the-art deep learning architectures for hate speech detection and use these datasets to train and evaluate them. Finally, we propose an ensemble model that outperforms all individual models.
HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
Jun 10, 2020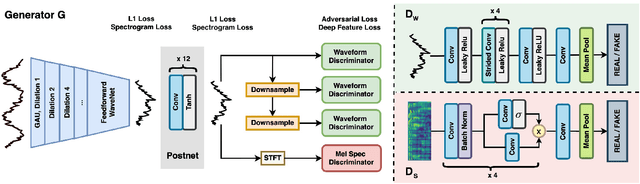
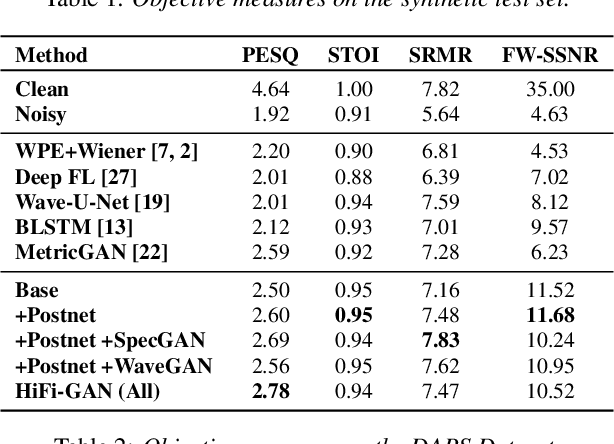
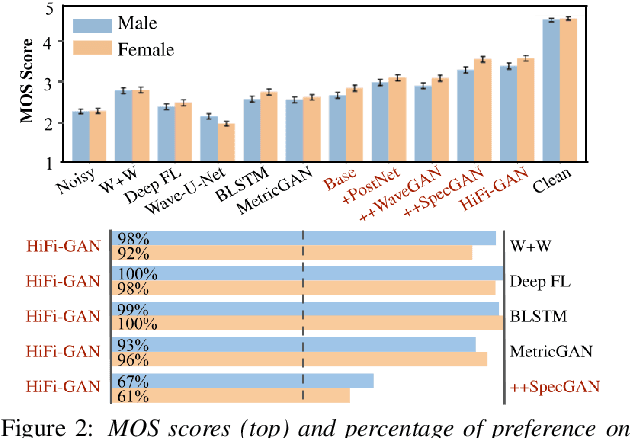
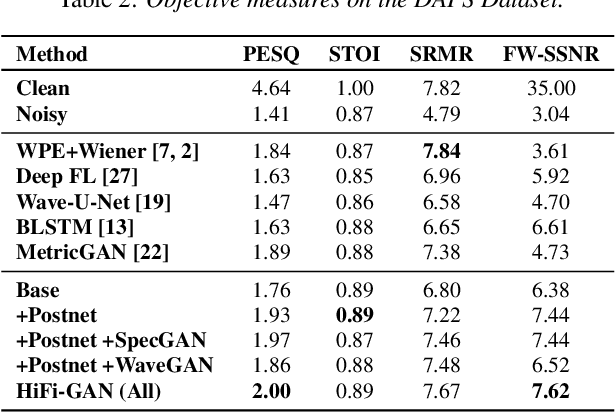
Real-world audio recordings are often degraded by factors such as noise, reverberation, and equalization distortion. This paper introduces HiFi-GAN, a deep learning method to transform recorded speech to sound as though it had been recorded in a studio. We use an end-to-end feed-forward WaveNet architecture, trained with multi-scale adversarial discriminators in both the time domain and the time-frequency domain. It relies on the deep feature matching losses of the discriminators to improve the perceptual quality of enhanced speech. The proposed model generalizes well to new speakers, new speech content, and new environments. It significantly outperforms state-of-the-art baseline methods in both objective and subjective experiments.
DNNAbacus: Toward Accurate Computational Cost Prediction for Deep Neural Networks
May 24, 2022
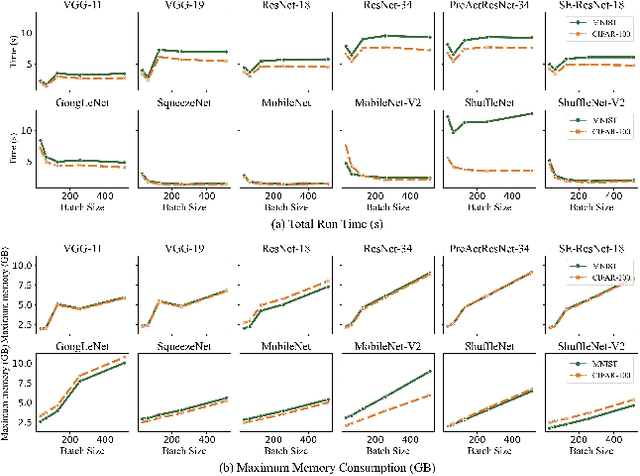
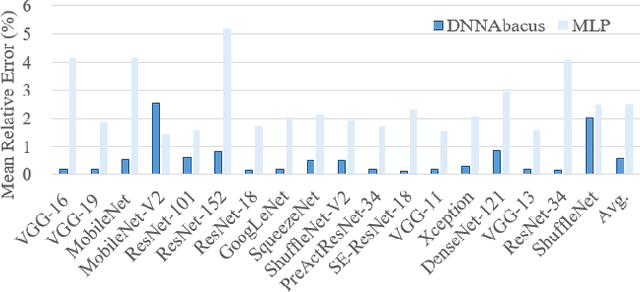
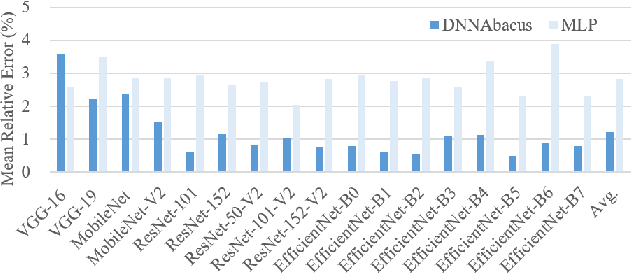
Deep learning is attracting interest across a variety of domains, including natural language processing, speech recognition, and computer vision. However, model training is time-consuming and requires huge computational resources. Existing works on the performance prediction of deep neural networks, which mostly focus on the training time prediction of a few models, rely on analytical models and result in high relative errors. %Optimizing task scheduling and reducing job failures in data centers are essential to improve resource utilization and reduce carbon emissions. This paper investigates the computational resource demands of 29 classical deep neural networks and builds accurate models for predicting computational costs. We first analyze the profiling results of typical networks and demonstrate that the computational resource demands of models with different inputs and hyperparameters are not obvious and intuitive. We then propose a lightweight prediction approach DNNAbacus with a novel network structural matrix for network representation. DNNAbacus can accurately predict both memory and time cost for PyTorch and TensorFlow models, which is also generalized to different hardware architectures and can have zero-shot capability for unseen networks. Our experimental results show that the mean relative error (MRE) is 0.9% with respect to time and 2.8% with respect to memory for 29 classic models, which is much lower than the state-of-the-art works.
FastSpeech: Fast, Robust and Controllable Text to Speech
May 29, 2019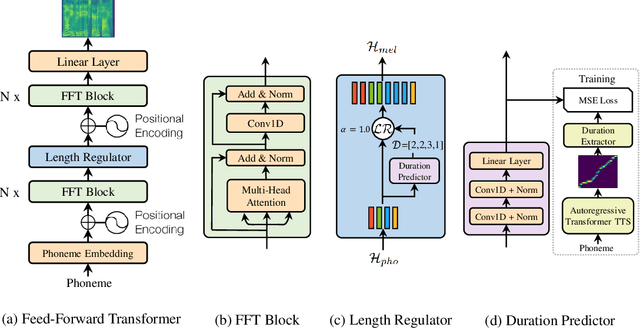


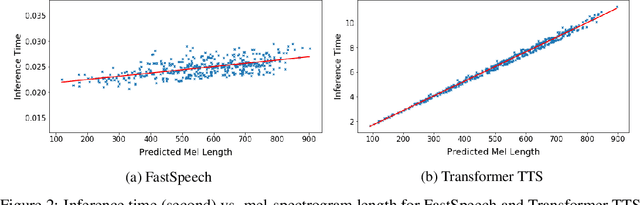
Neural network based end-to-end text to speech (TTS) has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron 2) usually first generate mel-spectrogram from text, and then synthesize speech from mel-spectrogram using vocoder such as WaveNet. Compared with traditional concatenative and statistical parametric approaches, neural network based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust (i.e., some words are skipped or repeated) and lack of controllability (voice speed or prosody control). In this work, we propose a novel feed-forward network based on Transformer to generate mel-spectrogram in parallel for TTS. Specifically, we extract attention alignments from an encoder-decoder based teacher model for phoneme duration prediction, which is used by a length regulator to expand the source phoneme sequence to match the length of target mel-spectrogram sequence for parallel mel-spectrogram generation. Experiments on the LJSpeech dataset show that our parallel model matches autoregressive models in terms of speech quality, nearly eliminates the problem of word skipping and repeating in particularly hard cases, and can adjust voice speed smoothly. Most importantly, compared with autoregressive Transformer TTS, our model speeds up the mel-spectrogram generation by 270x and the end-to-end speech synthesis by 38x. Therefore, we call our model FastSpeech. We will release the code on Github. Synthesized speech samples can be found in https://speechresearch.github.io/fastspeech/.
SpliceOut: A Simple and Efficient Audio Augmentation Method
Sep 30, 2021
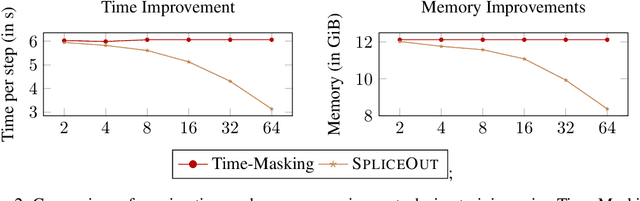
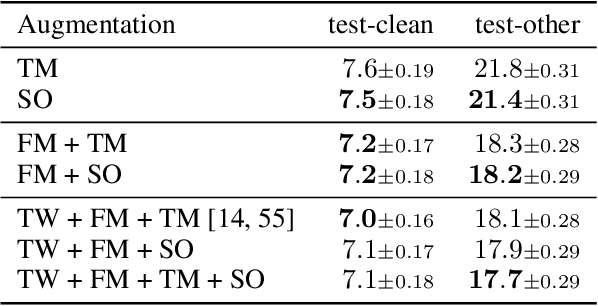
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.