 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SNP2Vec: Scalable Self-Supervised Pre-Training for Genome-Wide Association Study
Apr 14, 2022
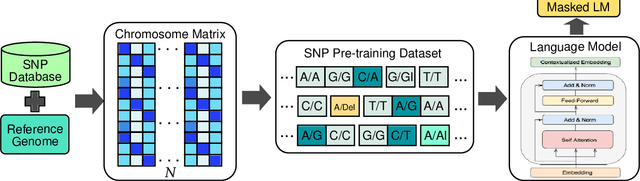
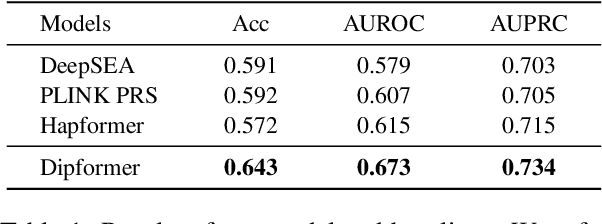
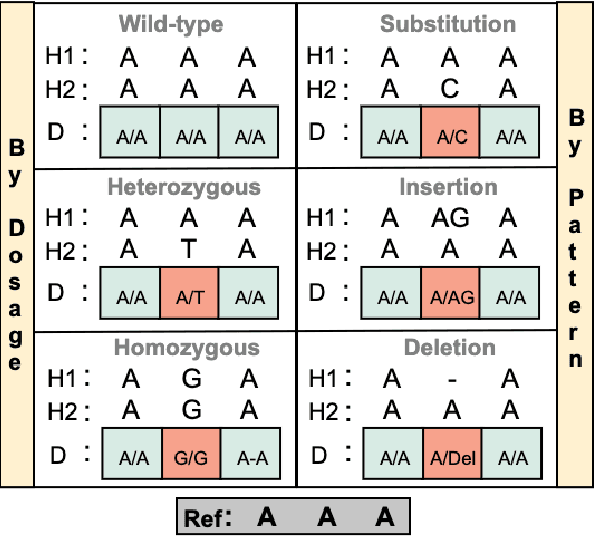

Self-supervised pre-training methods have brought remarkable breakthroughs in the understanding of text, image, and speech. Recent developments in genomics has also adopted these pre-training methods for genome understanding. However, they focus only on understanding haploid sequences, which hinders their applicability towards understanding genetic variations, also known as single nucleotide polymorphisms (SNPs), which is crucial for genome-wide association study. In this paper, we introduce SNP2Vec, a scalable self-supervised pre-training approach for understanding SNP. We apply SNP2Vec to perform long-sequence genomics modeling, and we evaluate the effectiveness of our approach on predicting Alzheimer's disease risk in a Chinese cohort. Our approach significantly outperforms existing polygenic risk score methods and all other baselines, including the model that is trained entirely with haploid sequences. We release our code and dataset on https://github.com/HLTCHKUST/snp2vec.
Human-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021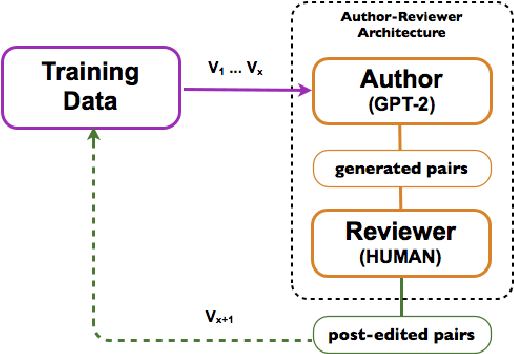
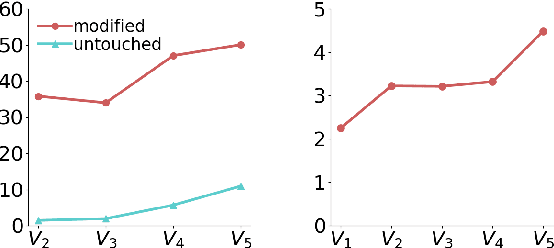
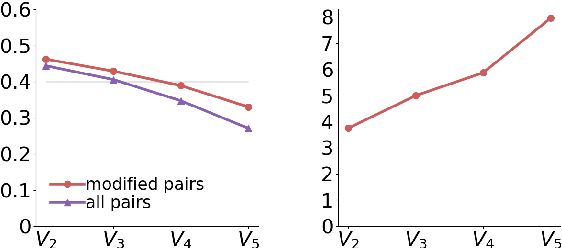
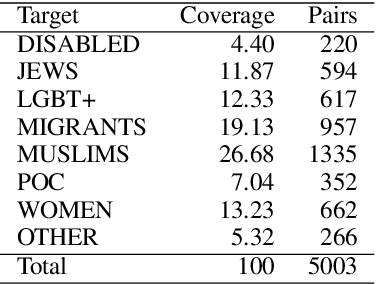
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.
Hopeful_Men@LT-EDI-EACL2021: Hope Speech Detection Using Indic Transliteration and Transformers
Feb 25, 2021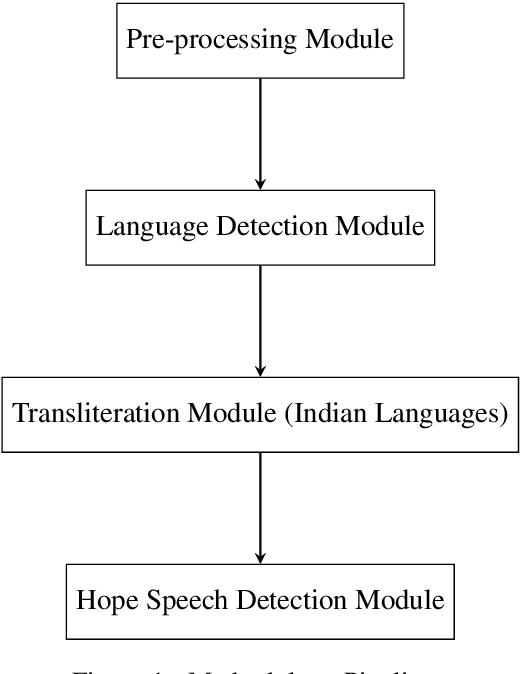
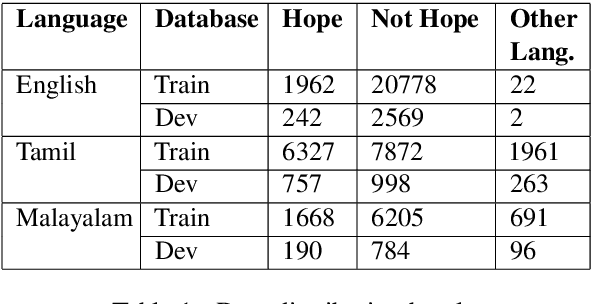
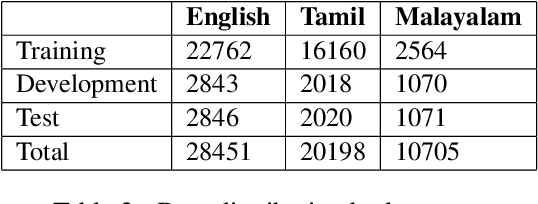
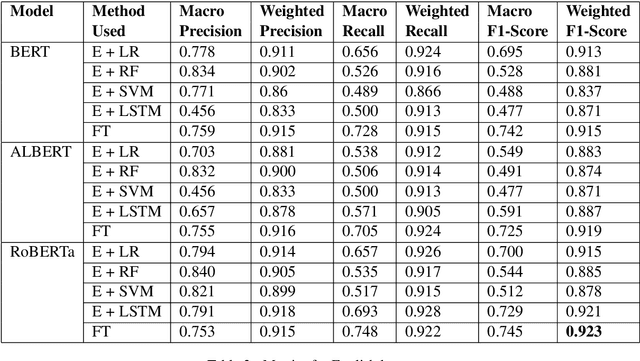
This paper aims to describe the approach we used to detect hope speech in the HopeEDI dataset. We experimented with two approaches. In the first approach, we used contextual embeddings to train classifiers using logistic regression, random forest, SVM, and LSTM based models.The second approach involved using a majority voting ensemble of 11 models which were obtained by fine-tuning pre-trained transformer models (BERT, ALBERT, RoBERTa, IndicBERT) after adding an output layer. We found that the second approach was superior for English, Tamil and Malayalam. Our solution got a weighted F1 score of 0.93, 0.75 and 0.49 for English,Malayalam and Tamil respectively. Our solution ranked first in English, eighth in Malayalam and eleventh in Tamil.
Pre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 26, 2022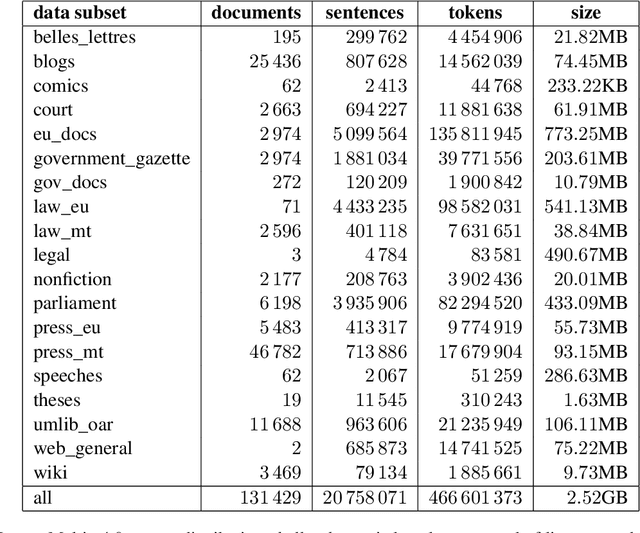
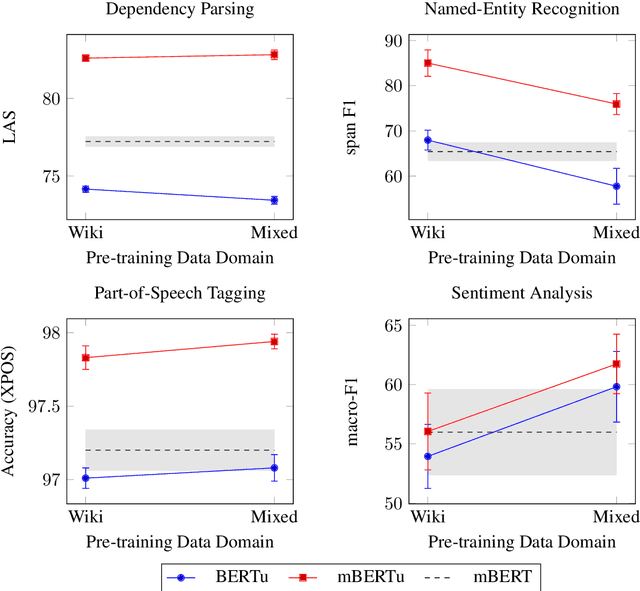
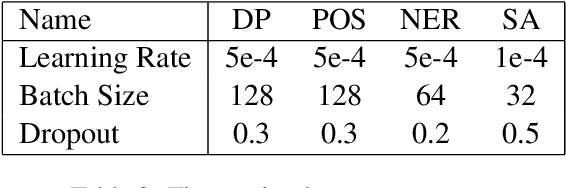
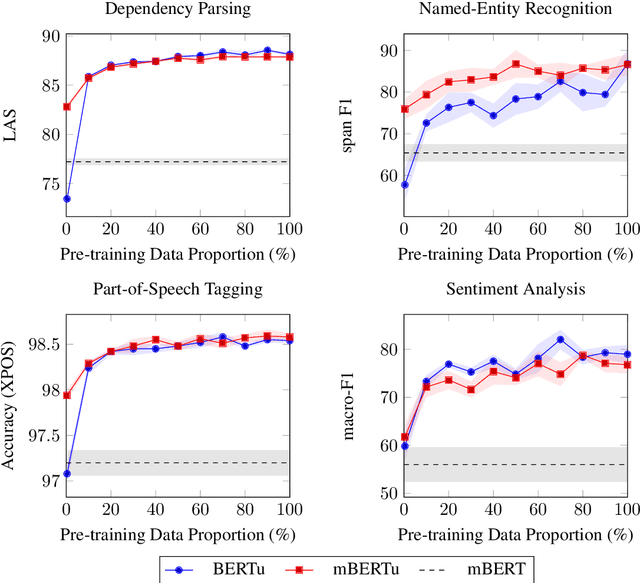
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.
Speaker independence of neural vocoders and their effect on parametric resynthesis speech enhancement
Nov 14, 2019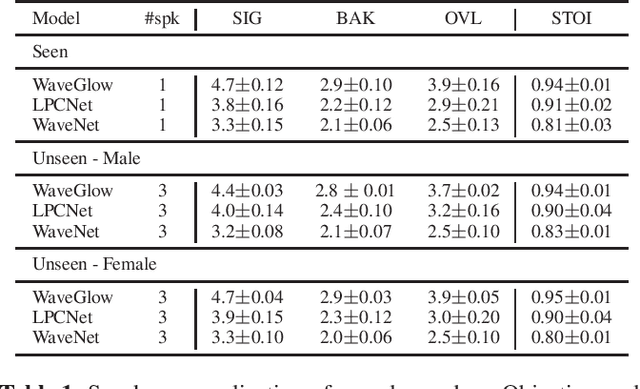

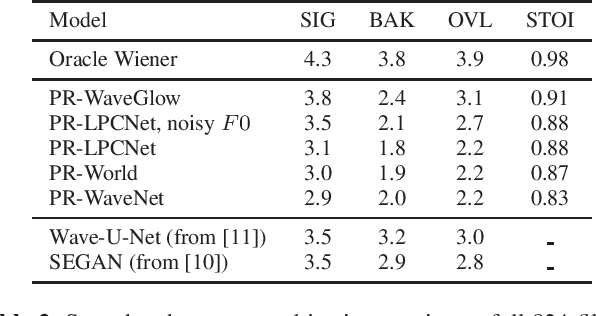
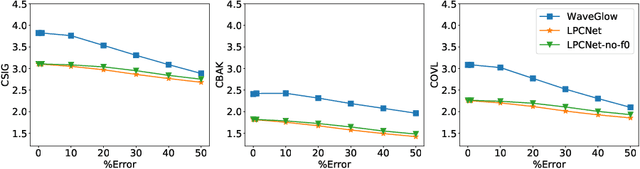
Traditional speech enhancement systems produce speech with compromised quality. Here we propose to use the high quality speech generation capability of neural vocoders for better quality speech enhancement. We term this parametric resynthesis (PR). In previous work, we showed that PR systems generate high quality speech for a single speaker using two neural vocoders, WaveNet and WaveGlow. Both these vocoders are traditionally speaker dependent. Here we first show that when trained on data from enough speakers, these vocoders can generate speech from unseen speakers, both male and female, with similar quality as seen speakers in training. Next using these two vocoders and a new vocoder LPCNet, we evaluate the noise reduction quality of PR on unseen speakers and show that objective signal and overall quality is higher than the state-of-the-art speech enhancement systems Wave-U-Net, Wavenet-denoise, and SEGAN. Moreover, in subjective quality, multiple-speaker PR out-performs the oracle Wiener mask.
Investigating Active-learning-based Training Data Selection for Speech Spoofing Countermeasure
Mar 28, 2022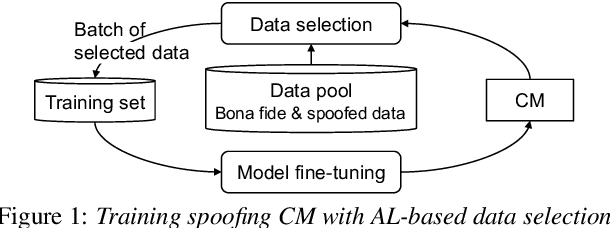
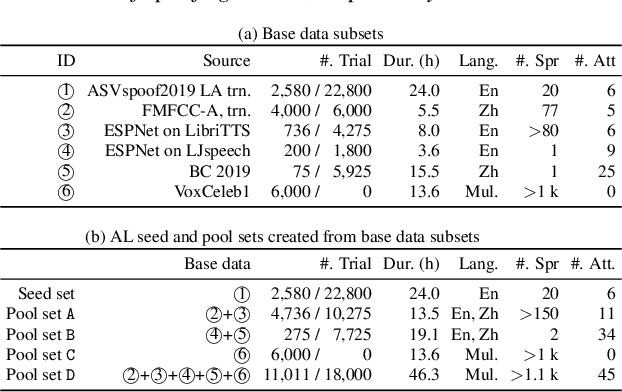
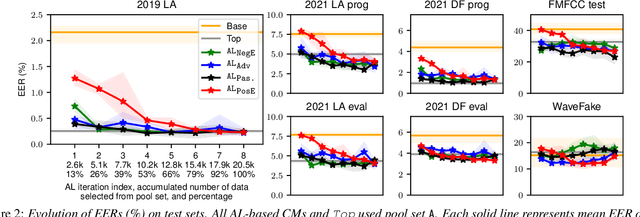
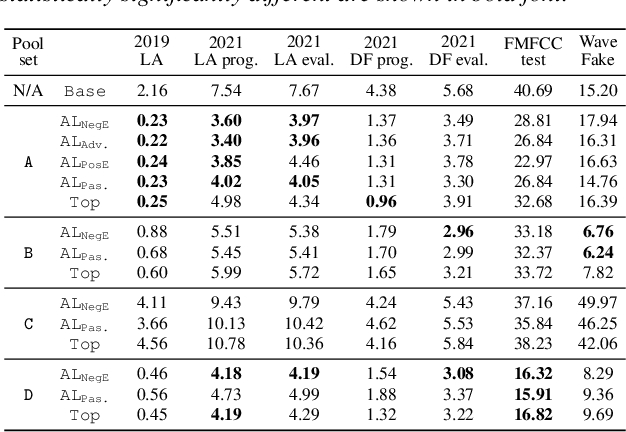
Training a spoofing countermeasure (CM) that generalizes to various unseen data is desired but challenging. While methods such as data augmentation and self-supervised learning are applicable, the imperfect CM performance on diverse test sets still calls for additional strategies. This study took the initiative and investigated CM training using active learning (AL), a framework that iteratively selects useful data from a large pool set and fine-tunes the CM. This study compared a few methods to measure the data usefulness and the impact of using different pool sets collected from various sources. The results showed that the AL-based CMs achieved better generalization than our strong baseline on multiple test tests. Furthermore, compared with a top-line CM that simply used the whole data pool set for training, the AL-based CMs achieved similar performance using less training data. Although no single best configuration was found for AL, the rule of thumb is to include diverse spoof and bona fide data in the pool set and to avoid any AL data selection method that selects the data that the CM feels confident in.
Speech Emotion Recognition with Multiscale Area Attention and Data Augmentation
Feb 03, 2021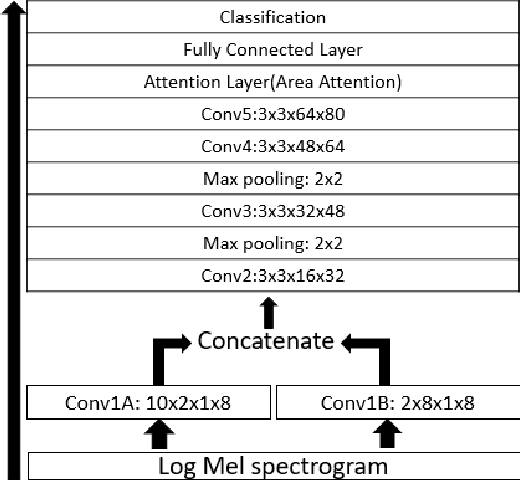

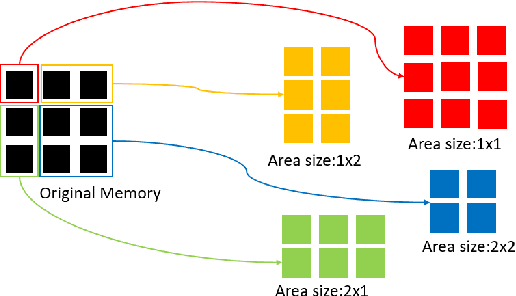
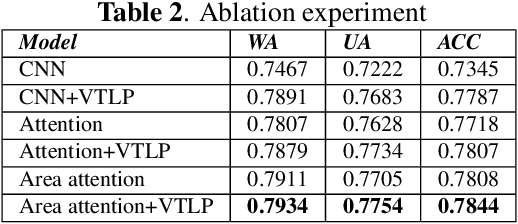
In Speech Emotion Recognition (SER), emotional characteristics often appear in diverse forms of energy patterns in spectrograms. Typical attention neural network classifiers of SER are usually optimized on a fixed attention granularity. In this paper, we apply multiscale area attention in a deep convolutional neural network to attend emotional characteristics with varied granularities and therefore the classifier can benefit from an ensemble of attentions with different scales. To deal with data sparsity, we conduct data augmentation with vocal tract length perturbation (VTLP) to improve the generalization capability of the classifier. Experiments are carried out on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved 79.34% weighted accuracy (WA) and 77.54% unweighted accuracy (UA), which, to the best of our knowledge, is the state of the art on this dataset.
Transformer VQ-VAE for Unsupervised Unit Discovery and Speech Synthesis: ZeroSpeech 2020 Challenge
May 24, 2020
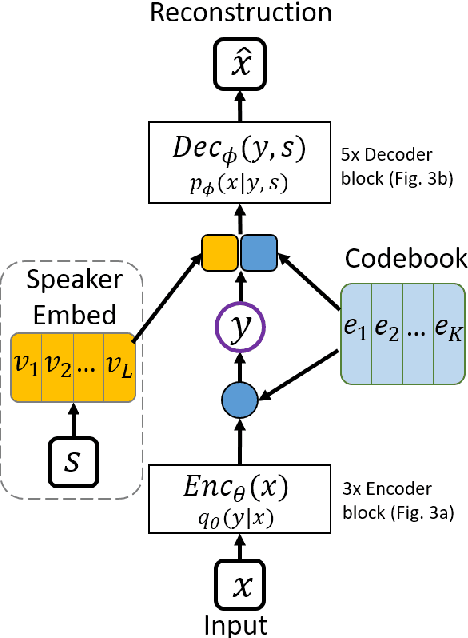

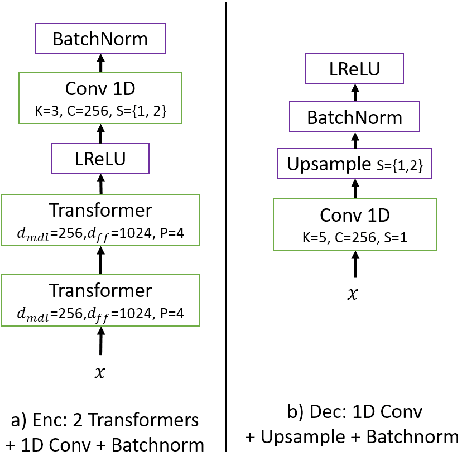
In this paper, we report our submitted system for the ZeroSpeech 2020 challenge on Track 2019. The main theme in this challenge is to build a speech synthesizer without any textual information or phonetic labels. In order to tackle those challenges, we build a system that must address two major components such as 1) given speech audio, extract subword units in an unsupervised way and 2) re-synthesize the audio from novel speakers. The system also needs to balance the codebook performance between the ABX error rate and the bitrate compression rate. Our main contribution here is we proposed Transformer-based VQ-VAE for unsupervised unit discovery and Transformer-based inverter for the speech synthesis given the extracted codebook. Additionally, we also explored several regularization methods to improve performance even further.
The ASRU 2019 Mandarin-English Code-Switching Speech Recognition Challenge: Open Datasets, Tracks, Methods and Results
Jul 12, 2020

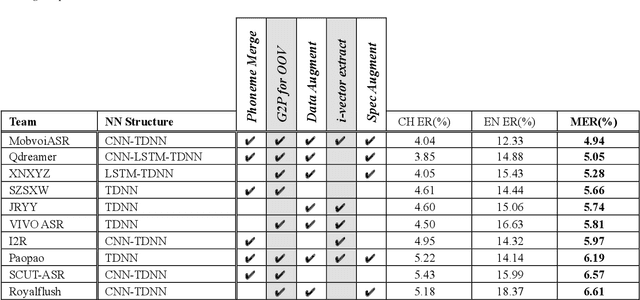
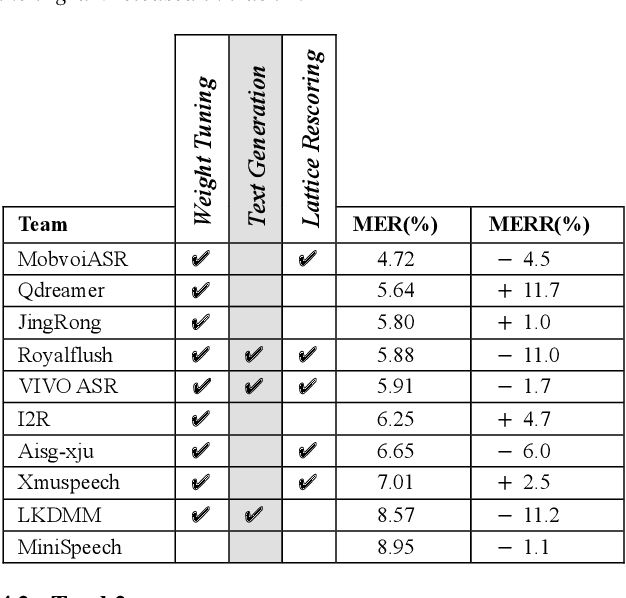
Code-switching (CS) is a common phenomenon and recognizing CS speech is challenging. But CS speech data is scarce and there' s no common testbed in relevant research. This paper describes the design and main outcomes of the ASRU 2019 Mandarin-English code-switching speech recognition challenge, which aims to improve the ASR performance in Mandarin-English code-switching situation. 500 hours Mandarin speech data and 240 hours Mandarin-English intra-sentencial CS data are released to the participants. Three tracks were set for advancing the AM and LM part in traditional DNN-HMM ASR system, as well as exploring the E2E models' performance. The paper then presents an overview of the results and system performance in the three tracks. It turns out that traditional ASR system benefits from pronunciation lexicon, CS text generating and data augmentation. In E2E track, however, the results highlight the importance of using language identification, building-up a rational set of modeling units and spec-augment. The other details in model training and method comparsion are discussed.