 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech Emotion Recognition with Multiscale Area Attention and Data Augmentation
Feb 03, 2021
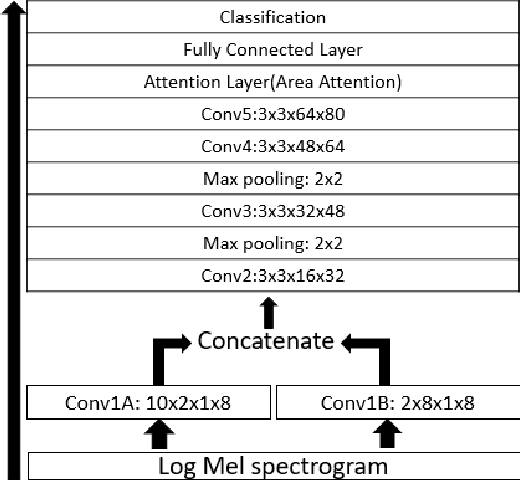

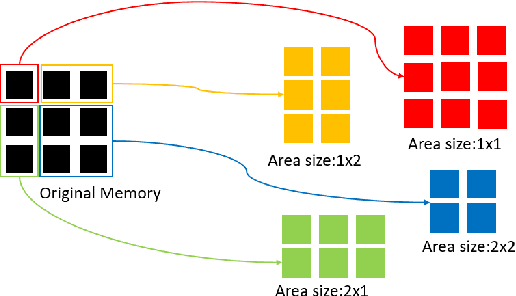
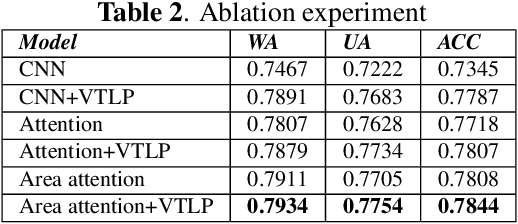
In Speech Emotion Recognition (SER), emotional characteristics often appear in diverse forms of energy patterns in spectrograms. Typical attention neural network classifiers of SER are usually optimized on a fixed attention granularity. In this paper, we apply multiscale area attention in a deep convolutional neural network to attend emotional characteristics with varied granularities and therefore the classifier can benefit from an ensemble of attentions with different scales. To deal with data sparsity, we conduct data augmentation with vocal tract length perturbation (VTLP) to improve the generalization capability of the classifier. Experiments are carried out on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved 79.34% weighted accuracy (WA) and 77.54% unweighted accuracy (UA), which, to the best of our knowledge, is the state of the art on this dataset.
Hopeful_Men@LT-EDI-EACL2021: Hope Speech Detection Using Indic Transliteration and Transformers
Feb 24, 2021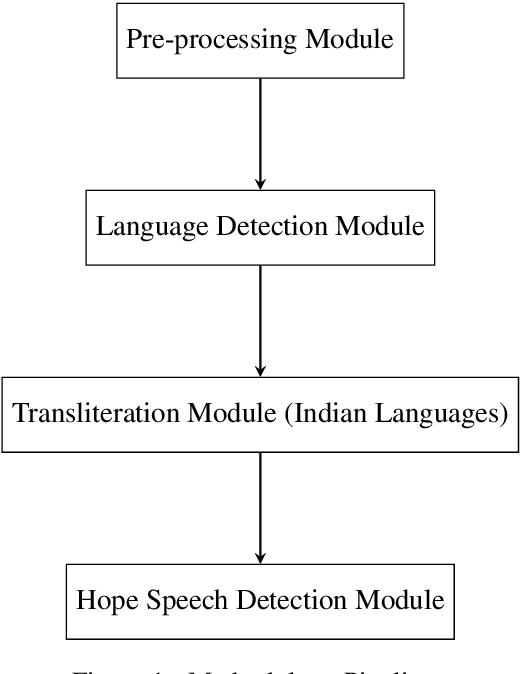
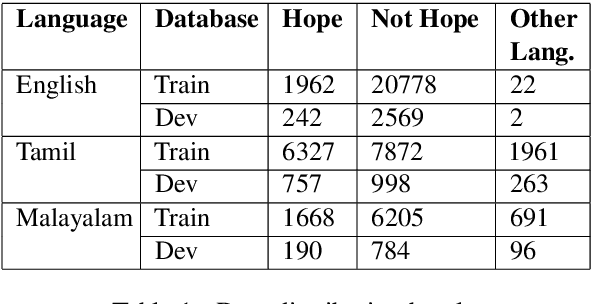
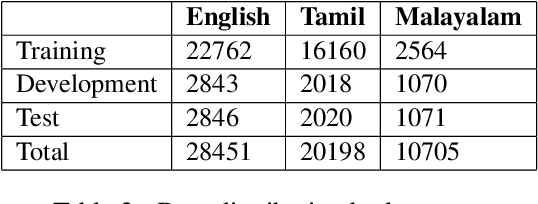
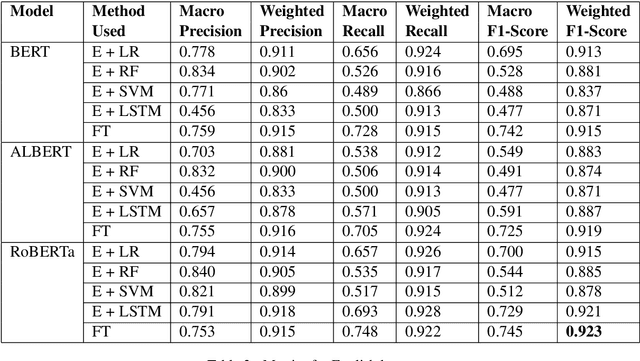
This paper aims to describe the approach we used to detect hope speech in the HopeEDI dataset. We experimented with two approaches. In the first approach, we used contextual embeddings to train classifiers using logistic regression, random forest, SVM, and LSTM based models.The second approach involved using a majority voting ensemble of 11 models which were obtained by fine-tuning pre-trained transformer models (BERT, ALBERT, RoBERTa, IndicBERT) after adding an output layer. We found that the second approach was superior for English, Tamil and Malayalam. Our solution got a weighted F1 score of 0.93, 0.75 and 0.49 for English,Malayalam and Tamil respectively. Our solution ranked first in English, eighth in Malayalam and eleventh in Tamil.
WaveCycleGAN2: Time-domain Neural Post-filter for Speech Waveform Generation
Apr 09, 2019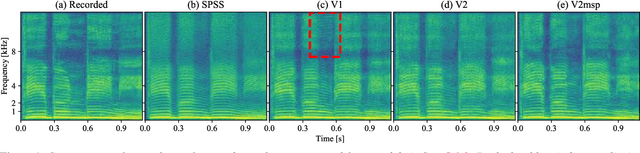
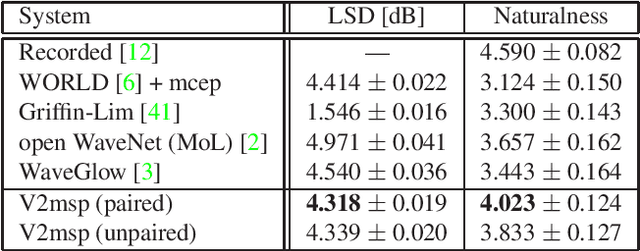
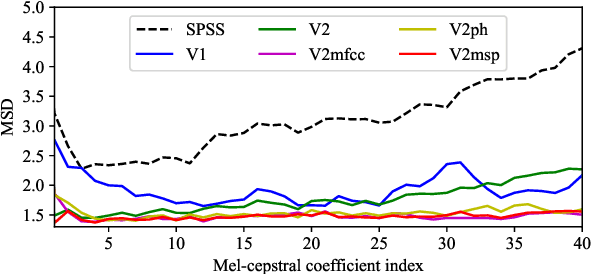
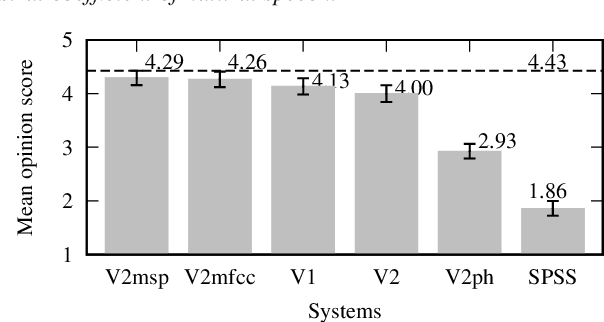
WaveCycleGAN has recently been proposed to bridge the gap between natural and synthesized speech waveforms in statistical parametric speech synthesis and provides fast inference with a moving average model rather than an autoregressive model and high-quality speech synthesis with the adversarial training. However, the human ear can still distinguish the processed speech waveforms from natural ones. One possible cause of this distinguishability is the aliasing observed in the processed speech waveform via down/up-sampling modules. To solve the aliasing and provide higher quality speech synthesis, we propose WaveCycleGAN2, which 1) uses generators without down/up-sampling modules and 2) combines discriminators of the waveform domain and acoustic parameter domain. The results show that the proposed method 1) alleviates the aliasing well, 2) is useful for both speech waveforms generated by analysis-and-synthesis and statistical parametric speech synthesis, and 3) achieves a mean opinion score comparable to those of natural speech and speech synthesized by WaveNet (open WaveNet) and WaveGlow while processing speech samples at a rate of more than 150 kHz on an NVIDIA Tesla P100.
Phonetically-Oriented Word Error Alignment for Speech Recognition Error Analysis in Speech Translation
Apr 24, 2019
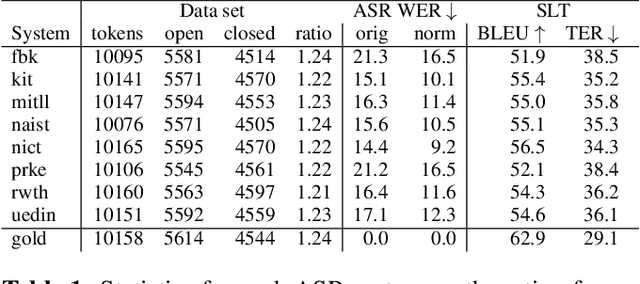
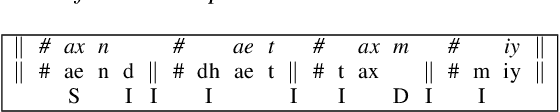
We propose a variation to the commonly used Word Error Rate (WER) metric for speech recognition evaluation which incorporates the alignment of phonemes, in the absence of time boundary information. After computing the Levenshtein alignment on words in the reference and hypothesis transcripts, spans of adjacent errors are converted into phonemes with word and syllable boundaries and a phonetic Levenshtein alignment is performed. The aligned phonemes are recombined into aligned words that adjust the word alignment labels in each error region. We demonstrate that our Phonetically-Oriented Word Error Rate (POWER) yields similar scores to WER with the added advantages of better word alignments and the ability to capture one-to-many word alignments corresponding to homophonic errors in speech recognition hypotheses. These improved alignments allow us to better trace the impact of Levenshtein error types on downstream tasks such as speech translation.
Speaker independence of neural vocoders and their effect on parametric resynthesis speech enhancement
Nov 14, 2019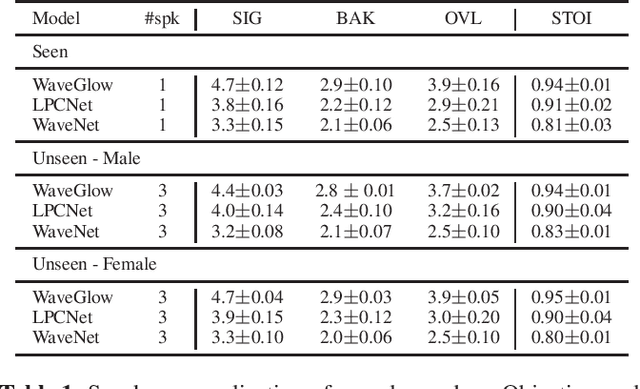

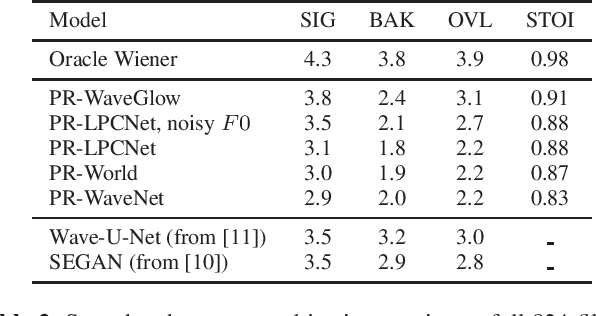
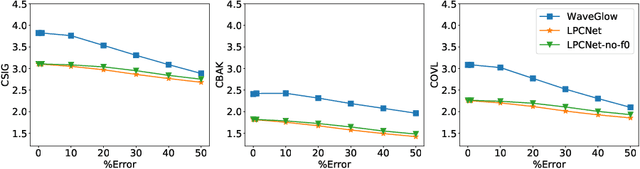
Traditional speech enhancement systems produce speech with compromised quality. Here we propose to use the high quality speech generation capability of neural vocoders for better quality speech enhancement. We term this parametric resynthesis (PR). In previous work, we showed that PR systems generate high quality speech for a single speaker using two neural vocoders, WaveNet and WaveGlow. Both these vocoders are traditionally speaker dependent. Here we first show that when trained on data from enough speakers, these vocoders can generate speech from unseen speakers, both male and female, with similar quality as seen speakers in training. Next using these two vocoders and a new vocoder LPCNet, we evaluate the noise reduction quality of PR on unseen speakers and show that objective signal and overall quality is higher than the state-of-the-art speech enhancement systems Wave-U-Net, Wavenet-denoise, and SEGAN. Moreover, in subjective quality, multiple-speaker PR out-performs the oracle Wiener mask.
Training Efficient CNNS: Tweaking the Nuts and Bolts of Neural Networks for Lighter, Faster and Robust Models
May 23, 2022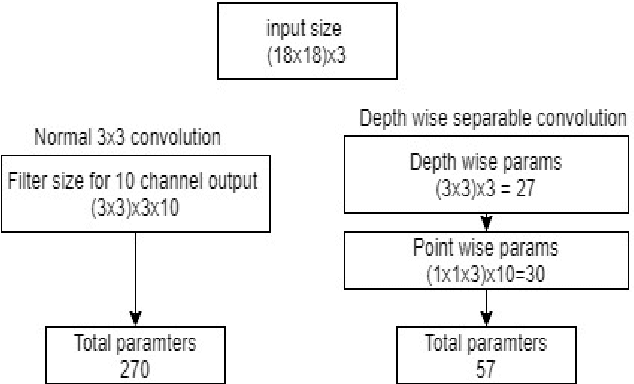
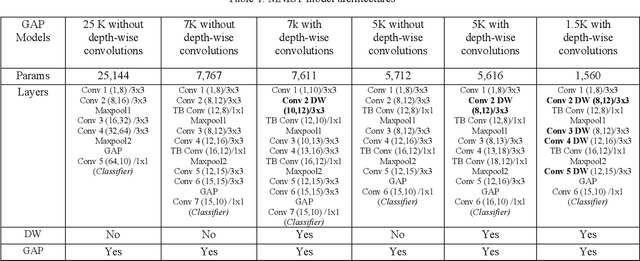
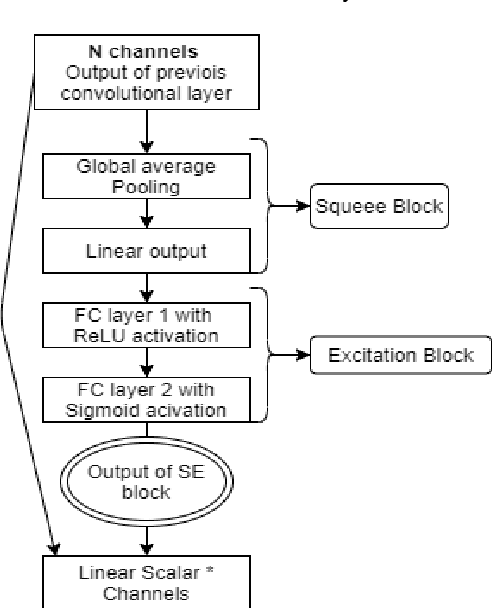
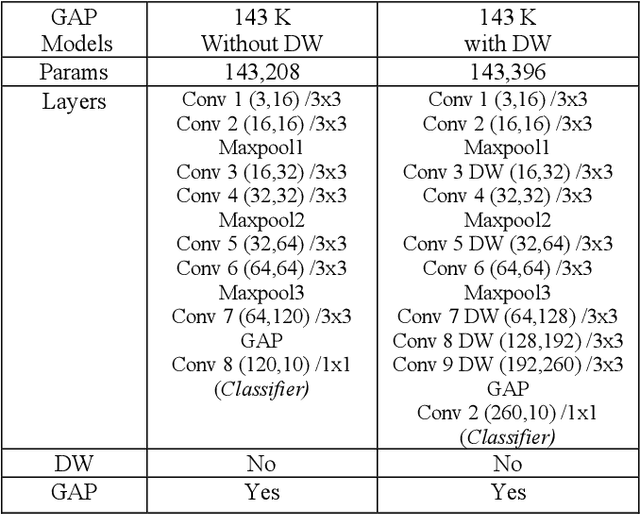
Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. Many techniques have evolved over the past decade that made models lighter, faster, and robust with better generalization. However, many deep learning practitioners persist with pre-trained models and architectures trained mostly on standard datasets such as Imagenet, MS-COCO, IMDB-Wiki Dataset, and Kinetics-700 and are either hesitant or unaware of redesigning the architecture from scratch that will lead to better performance. This scenario leads to inefficient models that are not suitable on various devices such as mobile, edge, and fog. In addition, these conventional training methods are of concern as they consume a lot of computing power. In this paper, we revisit various SOTA techniques that deal with architecture efficiency (Global Average Pooling, depth-wise convolutions & squeeze and excitation, Blurpool), learning rate (Cyclical Learning Rate), data augmentation (Mixup, Cutout), label manipulation (label smoothing), weight space manipulation (stochastic weight averaging), and optimizer (sharpness aware minimization). We demonstrate how an efficient deep convolution network can be built in a phased manner by sequentially reducing the number of training parameters and using the techniques mentioned above. We achieved a SOTA accuracy of 99.2% on MNIST data with just 1500 parameters and an accuracy of 86.01% with just over 140K parameters on the CIFAR-10 dataset.
Residual Energy-Based Models for End-to-End Speech Recognition
Mar 25, 2021


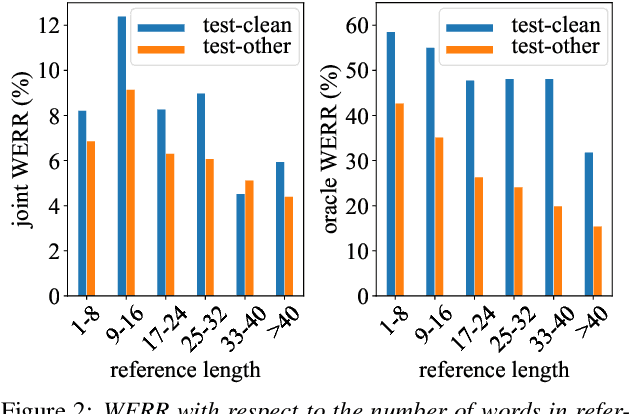
End-to-end models with auto-regressive decoders have shown impressive results for automatic speech recognition (ASR). These models formulate the sequence-level probability as a product of the conditional probabilities of all individual tokens given their histories. However, the performance of locally normalised models can be sub-optimal because of factors such as exposure bias. Consequently, the model distribution differs from the underlying data distribution. In this paper, the residual energy-based model (R-EBM) is proposed to complement the auto-regressive ASR model to close the gap between the two distributions. Meanwhile, R-EBMs can also be regarded as utterance-level confidence estimators, which may benefit many downstream tasks. Experiments on a 100hr LibriSpeech dataset show that R-EBMs can reduce the word error rates (WERs) by 8.2%/6.7% while improving areas under precision-recall curves of confidence scores by 12.6%/28.4% on test-clean/test-other sets. Furthermore, on a state-of-the-art model using self-supervised learning (wav2vec 2.0), R-EBMs still significantly improves both the WER and confidence estimation performance.
Transformer VQ-VAE for Unsupervised Unit Discovery and Speech Synthesis: ZeroSpeech 2020 Challenge
May 24, 2020
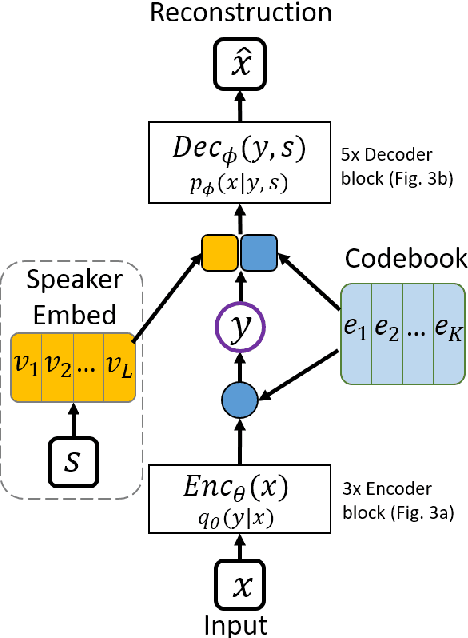

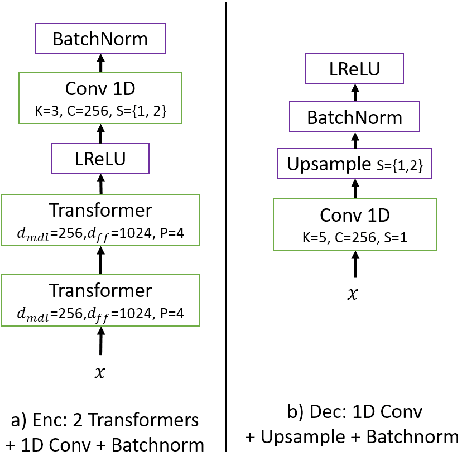
In this paper, we report our submitted system for the ZeroSpeech 2020 challenge on Track 2019. The main theme in this challenge is to build a speech synthesizer without any textual information or phonetic labels. In order to tackle those challenges, we build a system that must address two major components such as 1) given speech audio, extract subword units in an unsupervised way and 2) re-synthesize the audio from novel speakers. The system also needs to balance the codebook performance between the ABX error rate and the bitrate compression rate. Our main contribution here is we proposed Transformer-based VQ-VAE for unsupervised unit discovery and Transformer-based inverter for the speech synthesis given the extracted codebook. Additionally, we also explored several regularization methods to improve performance even further.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022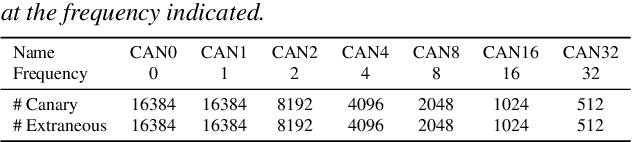
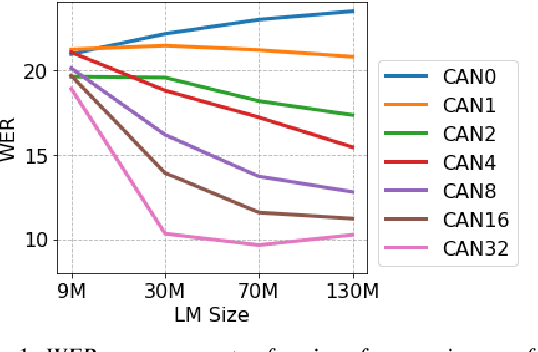
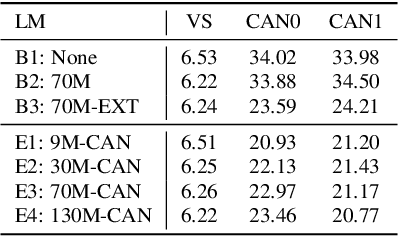
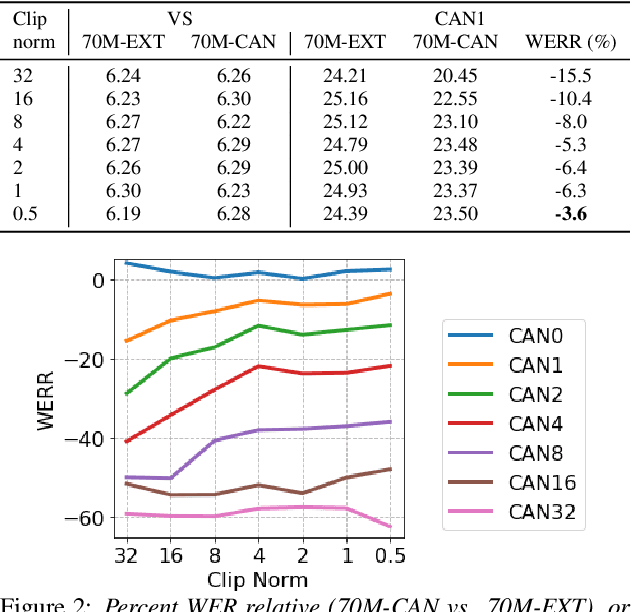
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
The ASRU 2019 Mandarin-English Code-Switching Speech Recognition Challenge: Open Datasets, Tracks, Methods and Results
Jul 12, 2020

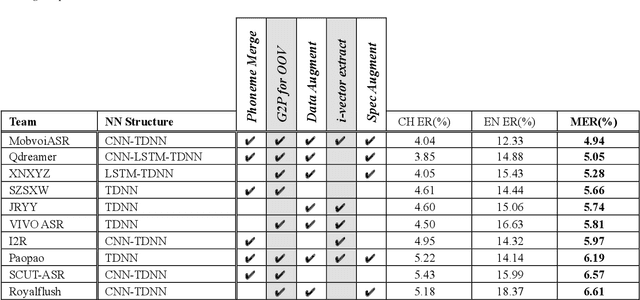
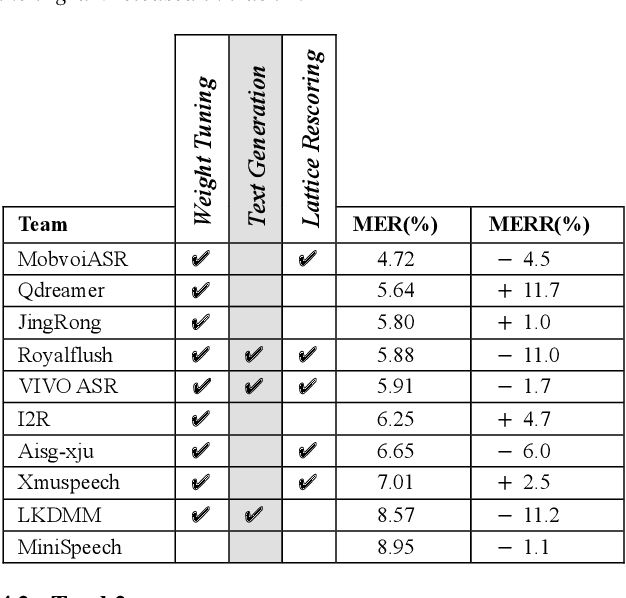
Code-switching (CS) is a common phenomenon and recognizing CS speech is challenging. But CS speech data is scarce and there' s no common testbed in relevant research. This paper describes the design and main outcomes of the ASRU 2019 Mandarin-English code-switching speech recognition challenge, which aims to improve the ASR performance in Mandarin-English code-switching situation. 500 hours Mandarin speech data and 240 hours Mandarin-English intra-sentencial CS data are released to the participants. Three tracks were set for advancing the AM and LM part in traditional DNN-HMM ASR system, as well as exploring the E2E models' performance. The paper then presents an overview of the results and system performance in the three tracks. It turns out that traditional ASR system benefits from pronunciation lexicon, CS text generating and data augmentation. In E2E track, however, the results highlight the importance of using language identification, building-up a rational set of modeling units and spec-augment. The other details in model training and method comparsion are discussed.