 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Post-Training Embedding Alignment for Decoupling Enrollment and Runtime Speaker Recognition Models
Jan 23, 2024
Automated speaker identification (SID) is a crucial step for the personalization of a wide range of speech-enabled services. Typical SID systems use a symmetric enrollment-verification framework with a single model to derive embeddings both offline for voice profiles extracted from enrollment utterances, and online from runtime utterances. Due to the distinct circumstances of enrollment and runtime, such as different computation and latency constraints, several applications would benefit from an asymmetric enrollment-verification framework that uses different models for enrollment and runtime embedding generation. To support this asymmetric SID where each of the two models can be updated independently, we propose using a lightweight neural network to map the embeddings from the two independent models to a shared speaker embedding space. Our results show that this approach significantly outperforms cosine scoring in a shared speaker logit space for models that were trained with a contrastive loss on large datasets with many speaker identities. This proposed Neural Embedding Speaker Space Alignment (NESSA) combined with an asymmetric update of only one of the models delivers at least 60% of the performance gain achieved by updating both models in the standard symmetric SID approach.
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.
StreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
Enhancement of a Text-Independent Speaker Verification System by using Feature Combination and Parallel-Structure Classifiers
Jan 26, 2024Speaker Verification (SV) systems involve mainly two individual stages: feature extraction and classification. In this paper, we explore these two modules with the aim of improving the performance of a speaker verification system under noisy conditions. On the one hand, the choice of the most appropriate acoustic features is a crucial factor for performing robust speaker verification. The acoustic parameters used in the proposed system are: Mel Frequency Cepstral Coefficients (MFCC), their first and second derivatives (Deltas and Delta- Deltas), Bark Frequency Cepstral Coefficients (BFCC), Perceptual Linear Predictive (PLP), and Relative Spectral Transform - Perceptual Linear Predictive (RASTA-PLP). In this paper, a complete comparison of different combinations of the previous features is discussed. On the other hand, the major weakness of a conventional Support Vector Machine (SVM) classifier is the use of generic traditional kernel functions to compute the distances among data points. However, the kernel function of an SVM has great influence on its performance. In this work, we propose the combination of two SVM-based classifiers with different kernel functions: Linear kernel and Gaussian Radial Basis Function (RBF) kernel with a Logistic Regression (LR) classifier. The combination is carried out by means of a parallel structure approach, in which different voting rules to take the final decision are considered. Results show that significant improvement in the performance of the SV system is achieved by using the combined features with the combined classifiers either with clean speech or in the presence of noise. Finally, to enhance the system more in noisy environments, the inclusion of the multiband noise removal technique as a preprocessing stage is proposed.
Evaluating Self-supervised Speech Models on a Taiwanese Hokkien Corpus
Dec 06, 2023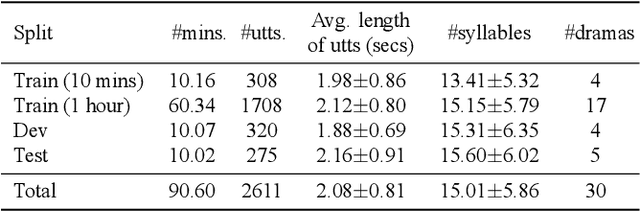
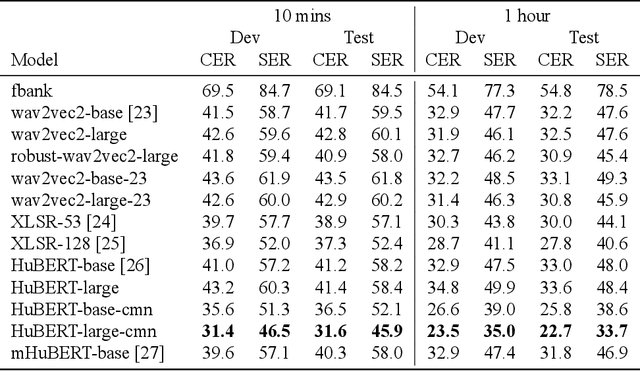
Taiwanese Hokkien is declining in use and status due to a language shift towards Mandarin in Taiwan. This is partly why it is a low resource language in NLP and speech research today. To ensure that the state of the art in speech processing does not leave Taiwanese Hokkien behind, we contribute a 1.5-hour dataset of Taiwanese Hokkien to ML-SUPERB's hidden set. Evaluating ML-SUPERB's suite of self-supervised learning (SSL) speech representations on our dataset, we find that model size does not consistently determine performance. In fact, certain smaller models outperform larger ones. Furthermore, linguistic alignment between pretraining data and the target language plays a crucial role.
Self-supervised Adaptive Pre-training of Multilingual Speech Models for Language and Dialect Identification
Dec 12, 2023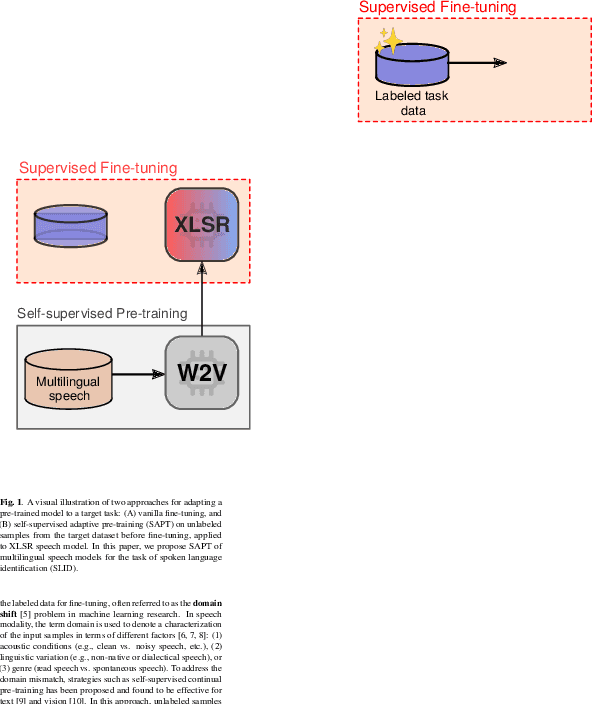
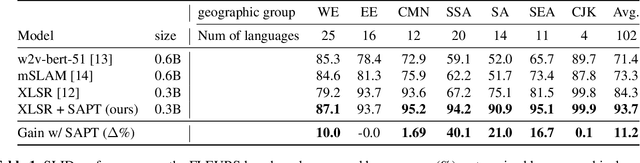
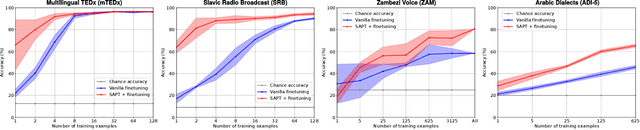
Pre-trained Transformer-based speech models have shown striking performance when fine-tuned on various downstream tasks such as automatic speech recognition and spoken language identification (SLID). However, the problem of domain mismatch remains a challenge in this area, where the domain of the pre-training data might differ from that of the downstream labeled data used for fine-tuning. In multilingual tasks such as SLID, the pre-trained speech model may not support all the languages in the downstream task. To address this challenge, we propose self-supervised adaptive pre-training (SAPT) to adapt the pre-trained model to the target domain and languages of the downstream task. We apply SAPT to the XLSR-128 model and investigate the effectiveness of this approach for the SLID task. First, we demonstrate that SAPT improves XLSR performance on the FLEURS benchmark with substantial gains up to 40.1% for under-represented languages. Second, we apply SAPT on four different datasets in a few-shot learning setting, showing that our approach improves the sample efficiency of XLSR during fine-tuning. Our experiments provide strong empirical evidence that continual adaptation via self-supervision improves downstream performance for multilingual speech models.
Evaluating and Personalizing User-Perceived Quality of Text-to-Speech Voices for Delivering Mindfulness Meditation with Different Physical Embodiments
Jan 07, 2024Mindfulness-based therapies have been shown to be effective in improving mental health, and technology-based methods have the potential to expand the accessibility of these therapies. To enable real-time personalized content generation for mindfulness practice in these methods, high-quality computer-synthesized text-to-speech (TTS) voices are needed to provide verbal guidance and respond to user performance and preferences. However, the user-perceived quality of state-of-the-art TTS voices has not yet been evaluated for administering mindfulness meditation, which requires emotional expressiveness. In addition, work has not yet been done to study the effect of physical embodiment and personalization on the user-perceived quality of TTS voices for mindfulness. To that end, we designed a two-phase human subject study. In Phase 1, an online Mechanical Turk between-subject study (N=471) evaluated 3 (feminine, masculine, child-like) state-of-the-art TTS voices with 2 (feminine, masculine) human therapists' voices in 3 different physical embodiment settings (no agent, conversational agent, socially assistive robot) with remote participants. Building on findings from Phase 1, in Phase 2, an in-person within-subject study (N=94), we used a novel framework we developed for personalizing TTS voices based on user preferences, and evaluated user-perceived quality compared to best-rated non-personalized voices from Phase 1. We found that the best-rated human voice was perceived better than all TTS voices; the emotional expressiveness and naturalness of TTS voices were poorly rated, while users were satisfied with the clarity of TTS voices. Surprisingly, by allowing users to fine-tune TTS voice features, the user-personalized TTS voices could perform almost as well as human voices, suggesting user personalization could be a simple and very effective tool to improve user-perceived quality of TTS voice.
Keyword spotting -- Detecting commands in speech using deep learning
Dec 09, 2023
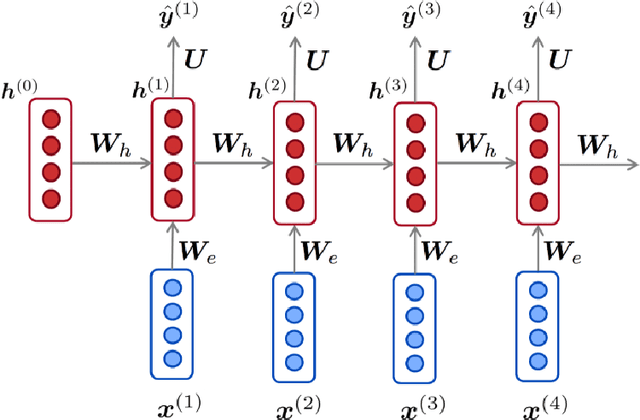
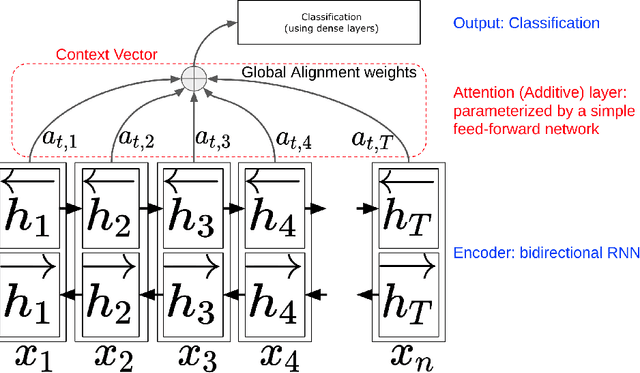
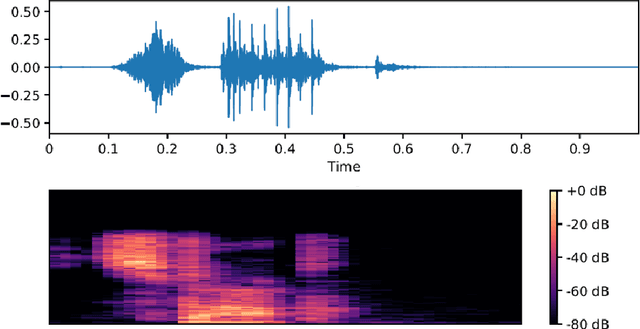
Speech recognition has become an important task in the development of machine learning and artificial intelligence. In this study, we explore the important task of keyword spotting using speech recognition machine learning and deep learning techniques. We implement feature engineering by converting raw waveforms to Mel Frequency Cepstral Coefficients (MFCCs), which we use as inputs to our models. We experiment with several different algorithms such as Hidden Markov Model with Gaussian Mixture, Convolutional Neural Networks and variants of Recurrent Neural Networks including Long Short-Term Memory and the Attention mechanism. In our experiments, RNN with BiLSTM and Attention achieves the best performance with an accuracy of 93.9 %
Boosting Unknown-number Speaker Separation with Transformer Decoder-based Attractor
Jan 23, 2024We propose a novel speech separation model designed to separate mixtures with an unknown number of speakers. The proposed model stacks 1) a dual-path processing block that can model spectro-temporal patterns, 2) a transformer decoder-based attractor (TDA) calculation module that can deal with an unknown number of speakers, and 3) triple-path processing blocks that can model inter-speaker relations. Given a fixed, small set of learned speaker queries and the mixture embedding produced by the dual-path blocks, TDA infers the relations of these queries and generates an attractor vector for each speaker. The estimated attractors are then combined with the mixture embedding by feature-wise linear modulation conditioning, creating a speaker dimension. The mixture embedding, conditioned with speaker information produced by TDA, is fed to the final triple-path blocks, which augment the dual-path blocks with an additional pathway dedicated to inter-speaker processing. The proposed approach outperforms the previous best reported in the literature, achieving 24.0 and 23.7 dB SI-SDR improvement (SI-SDRi) on WSJ0-2 and 3mix respectively, with a single model trained to separate 2- and 3-speaker mixtures. The proposed model also exhibits strong performance and generalizability at counting sources and separating mixtures with up to 5 speakers.
Leveraged Mel spectrograms using Harmonic and Percussive Components in Speech Emotion Recognition
Dec 18, 2023Speech Emotion Recognition (SER) affective technology enables the intelligent embedded devices to interact with sensitivity. Similarly, call centre employees recognise customers' emotions from their pitch, energy, and tone of voice so as to modify their speech for a high-quality interaction with customers. This work explores, for the first time, the effects of the harmonic and percussive components of Mel spectrograms in SER. We attempt to leverage the Mel spectrogram by decomposing distinguishable acoustic features for exploitation in our proposed architecture, which includes a novel feature map generator algorithm, a CNN-based network feature extractor and a multi-layer perceptron (MLP) classifier. This study specifically focuses on effective data augmentation techniques for building an enriched hybrid-based feature map. This process results in a function that outputs a 2D image so that it can be used as input data for a pre-trained CNN-VGG16 feature extractor. Furthermore, we also investigate other acoustic features such as MFCCs, chromagram, spectral contrast, and the tonnetz to assess our proposed framework. A test accuracy of 92.79% on the Berlin EMO-DB database is achieved. Our result is higher than previous works using CNN-VGG16.
* 12 pages