 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The Copenhagen Corpus of Eye Tracking Recordings from Natural Reading of Danish Texts
Apr 28, 2022
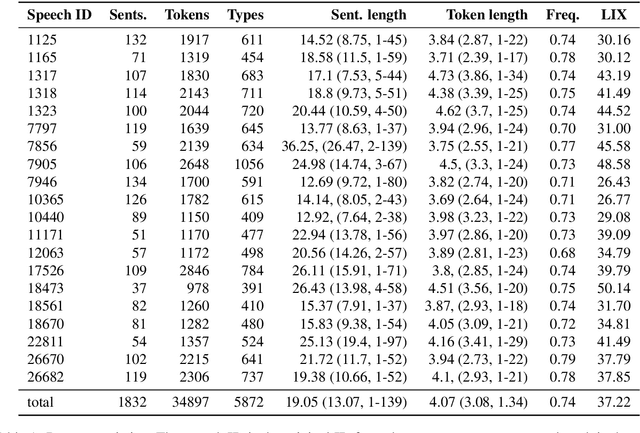
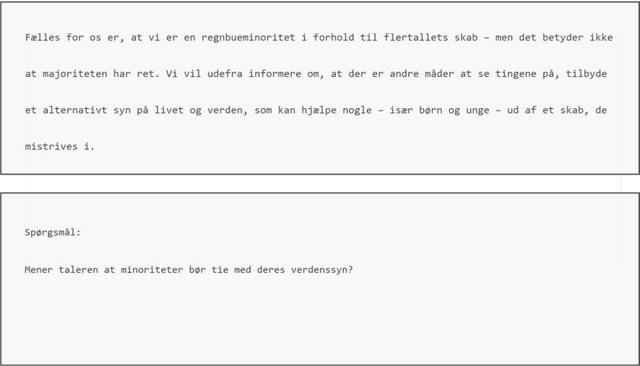
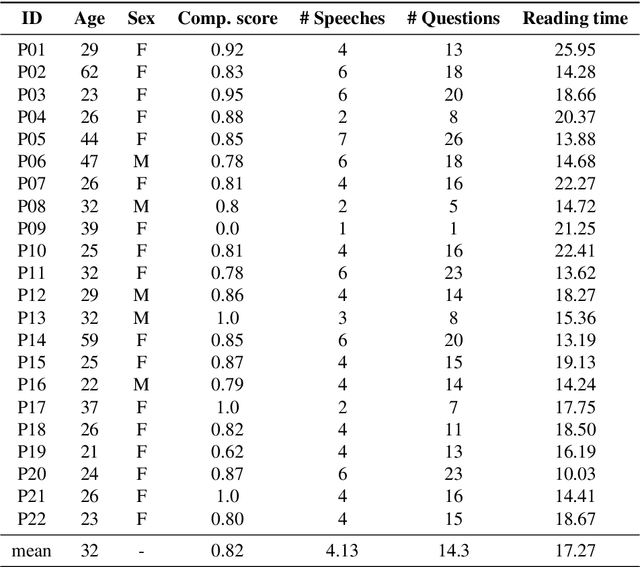
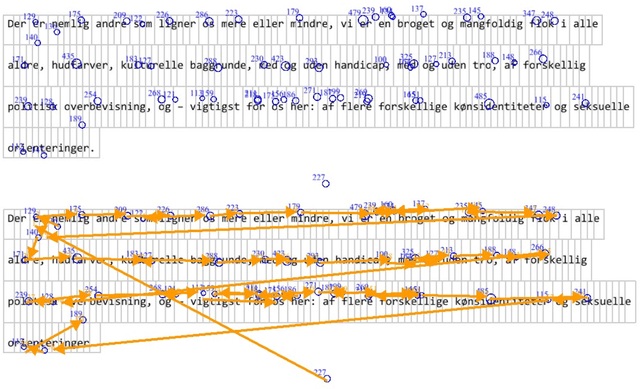
Eye movement recordings from reading are one of the richest signals of human language processing. Corpora of eye movements during reading of contextualized running text is a way of making such records available for natural language processing purposes. Such corpora already exist in some languages. We present CopCo, the Copenhagen Corpus of eye tracking recordings from natural reading of Danish texts. It is the first eye tracking corpus of its kind for the Danish language. CopCo includes 1,832 sentences with 34,897 tokens of Danish text extracted from a collection of speech manuscripts. This first release of the corpus contains eye tracking data from 22 participants. It will be extended continuously with more participants and texts from other genres. We assess the data quality of the recorded eye movements and find that the extracted features are in line with related research. The dataset available here: https://osf.io/ud8s5/.
Predicting electrode array impedance after one month from cochlear implantation surgery
May 20, 2022
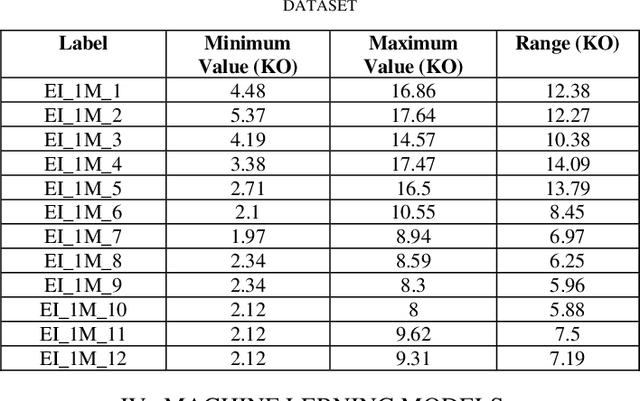
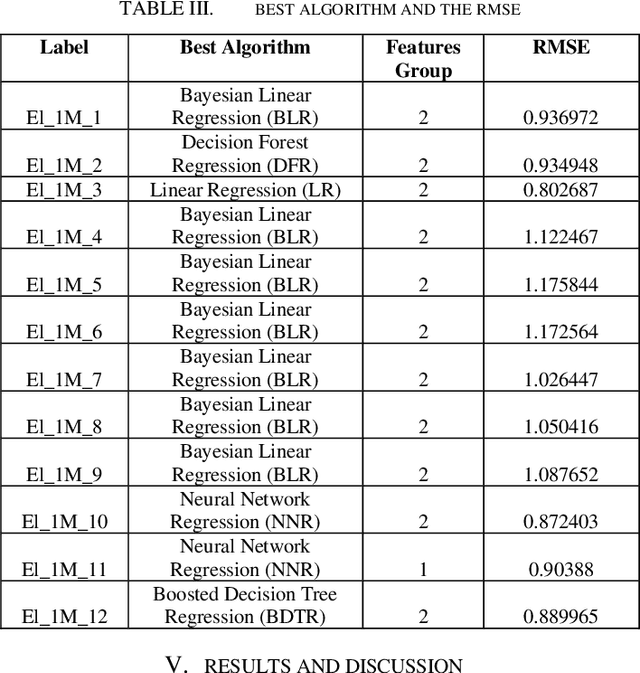
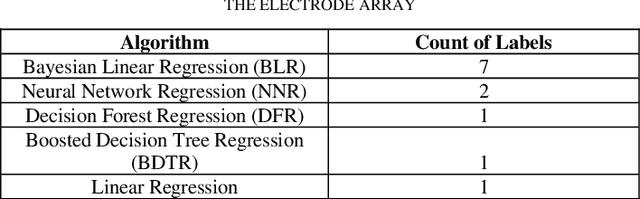
Sensorineural hearing loss can be treated using Cochlear implantation. After this surgery using the electrode array impedance measurements, we can check the stability of the impedance value and the dynamic range. Deterioration of speech recognition scores could happen because of increased impedance values. Medicines used to do these measures many times during a year after the surgery. Predicting the electrode impedance could help in taking decisions to help the patient get better hearing. In this research we used a dataset of 80 patients of children who did cochlear implantation using MED-EL FLEX28 electrode array of 12 channels. We predicted the electrode impedance on each channel after 1 month from the surgery date. We used different machine learning algorithms like neural networks and decision trees. Our results indicates that the electrode impedance can be predicted, and the best algorithm is different based on the electrode channel. Also, the accuracy level varies between 66% and 100% based on the electrode channel when accepting an error range between 0 and 3 KO. Further research is required to predict the electrode impedance after three months, six months and one year.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022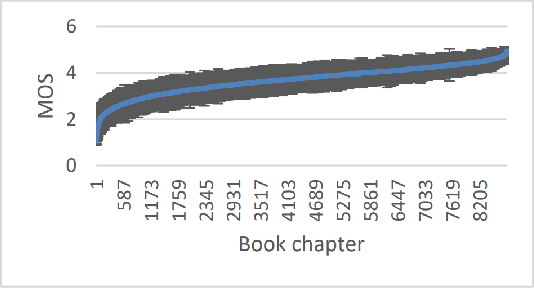
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.
Visually Supervised Speaker Detection and Localization via Microphone Array
Mar 07, 2022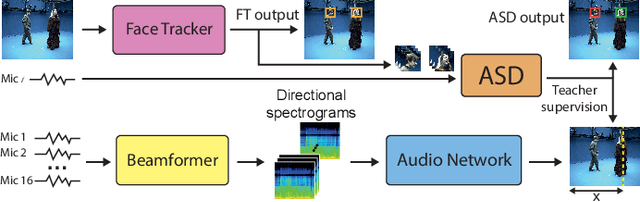
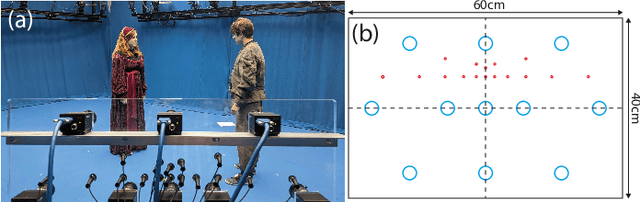
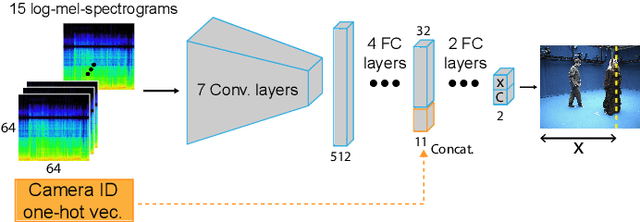
Active speaker detection (ASD) is a multi-modal task that aims to identify who, if anyone, is speaking from a set of candidates. Current audio-visual approaches for ASD typically rely on visually pre-extracted face tracks (sequences of consecutive face crops) and the respective monaural audio. However, their recall rate is often low as only the visible faces are included in the set of candidates. Monaural audio may successfully detect the presence of speech activity but fails in localizing the speaker due to the lack of spatial cues. Our solution extends the audio front-end using a microphone array. We train an audio convolutional neural network (CNN) in combination with beamforming techniques to regress the speaker's horizontal position directly in the video frames. We propose to generate weak labels using a pre-trained active speaker detector on pre-extracted face tracks. Our pipeline embraces the "student-teacher" paradigm, where a trained "teacher" network is used to produce pseudo-labels visually. The "student" network is an audio network trained to generate the same results. At inference, the student network can independently localize the speaker in the visual frames directly from the audio input. Experimental results on newly collected data prove that our approach significantly outperforms a variety of other baselines as well as the teacher network itself. It results in an excellent speech activity detector too.
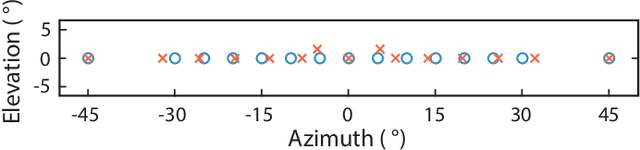
* Erratum: Due to a bug in the evaluation script, the correct average distance (aD) metric is here reported in yellow. The analysis remains unchanged from the original paper as the trend between the old and new measures are perfectly monotonic. The bug was caused by an incorrect normalization factor
Analysis of the Ethiopic Twitter Dataset for Abusive Speech in Amharic
Dec 09, 2019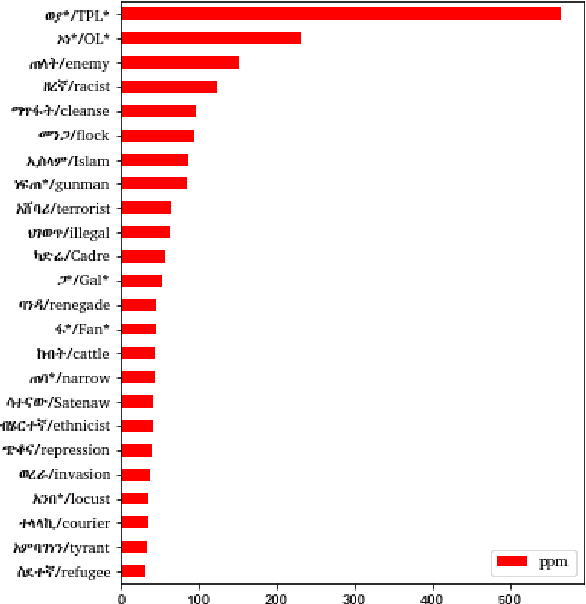
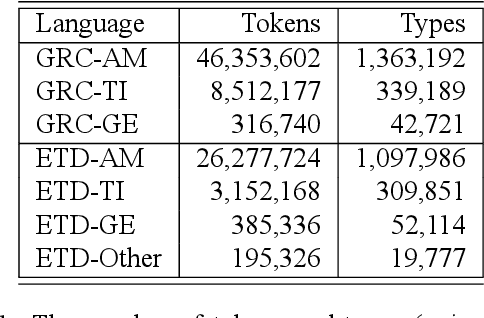
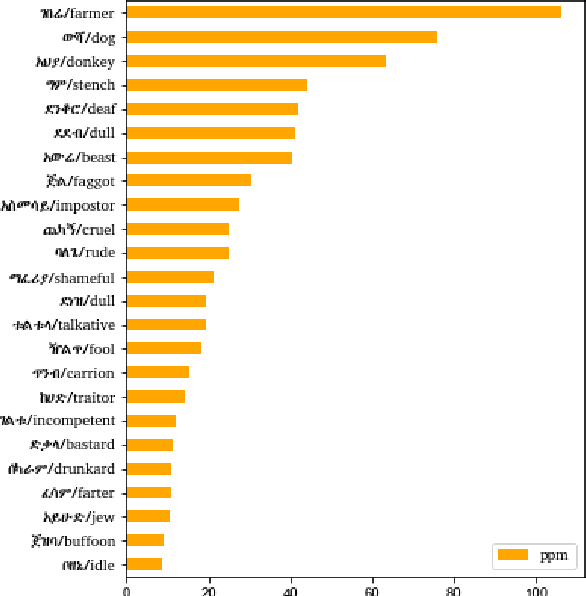
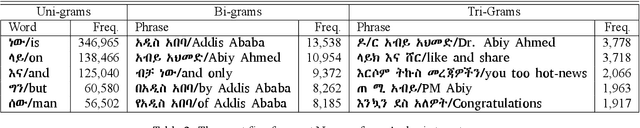
In this paper, we present an analysis of the first Ethiopic Twitter Dataset for the Amharic language targeted for recognizing abusive speech. The dataset has been collected since 2014 that is written in Fidel script. Since several languages can be written using the Fidel script, we have used the existing Amharic, Tigrinya and Ge'ez corpora to retain only the Amharic tweets. We have analyzed the tweets for abusive speech content with the following targets: Analyze the distribution and tendency of abusive speech content over time and compare the abusive speech content between a Twitter and general reference Amharic corpus.
End-to-end contextual asr based on posterior distribution adaptation for hybrid ctc/attention system
Feb 18, 2022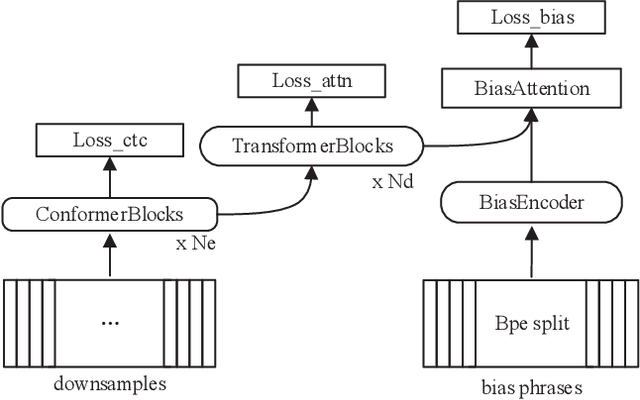
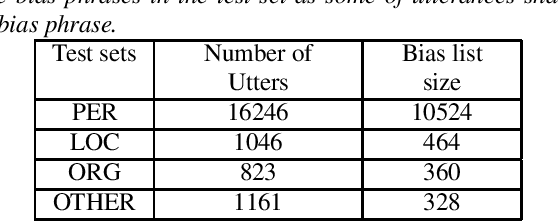
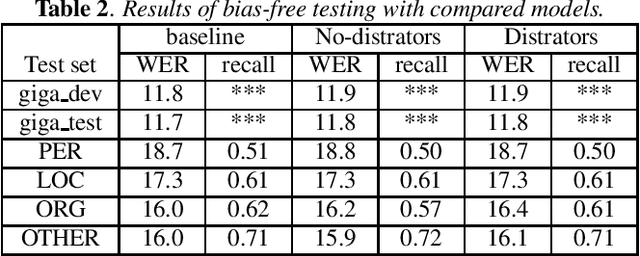
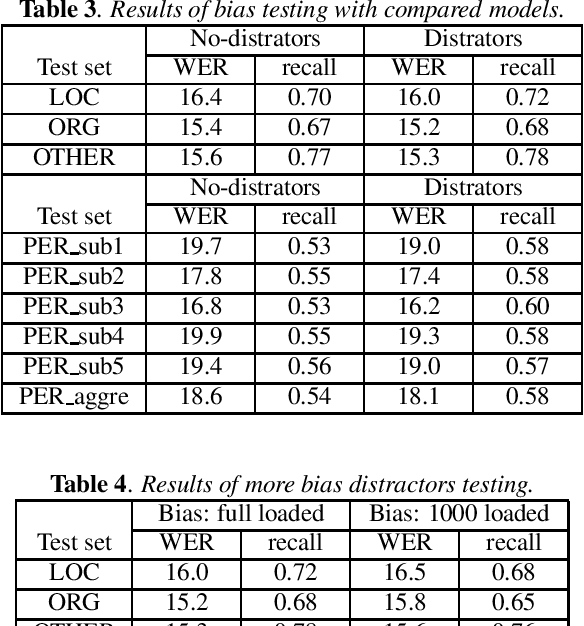
End-to-end (E2E) speech recognition architectures assemble all components of traditional speech recognition system into a single model. Although it simplifies ASR system, it introduces contextual ASR drawback: the E2E model has worse performance on utterances containing infrequent proper nouns. In this work, we propose to add a contextual bias attention (CBA) module to attention based encoder decoder (AED) model to improve its ability of recognizing the contextual phrases. Specifically, CBA utilizes the context vector of source attention in decoder to attend to a specific bias embedding. Jointly learned with the basic AED parameters, CBA can tell the model when and where to bias its output probability distribution. At inference stage, a list of bias phrases is preloaded and we adapt the posterior distributions of both CTC and attention decoder according to the attended bias phrase of CBA. We evaluate the proposed method on GigaSpeech and achieve a consistent relative improvement on recall rate of bias phrases ranging from 15% to 28% compared to the baseline model. Meanwhile, our method shows a strong anti-bias ability as the performance on general tests only degrades 1.7% even 2,000 bias phrases are present.
Wavesplit: End-to-End Speech Separation by Speaker Clustering
Feb 20, 2020
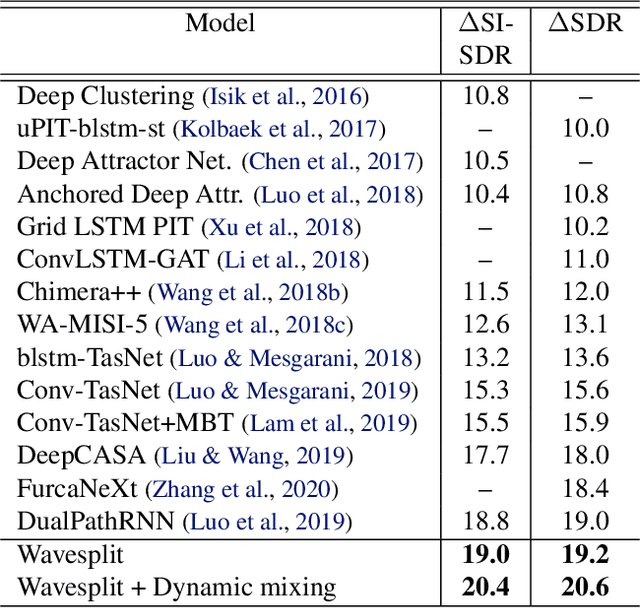
We introduce Wavesplit, an end-to-end speech separation system. From a single recording of mixed speech, the model infers and clusters representations of each speaker and then estimates each source signal conditioned on the inferred representations. The model is trained on the raw waveform to jointly perform the two tasks. Our model infers a set of speaker representations through clustering, which addresses the fundamental permutation problem of speech separation. Moreover, the sequence-wide speaker representations provide a more robust separation of long, challenging sequences, compared to previous approaches. We show that Wavesplit outperforms the previous state-of-the-art on clean mixtures of 2 or 3 speakers (WSJ0-2mix, WSJ0-3mix), as well as in noisy (WHAM!) and reverberated (WHAMR!) conditions. As an additional contribution, we further improve our model by introducing online data augmentation for separation.
Open Challenge for Correcting Errors of Speech Recognition Systems
Jan 09, 2020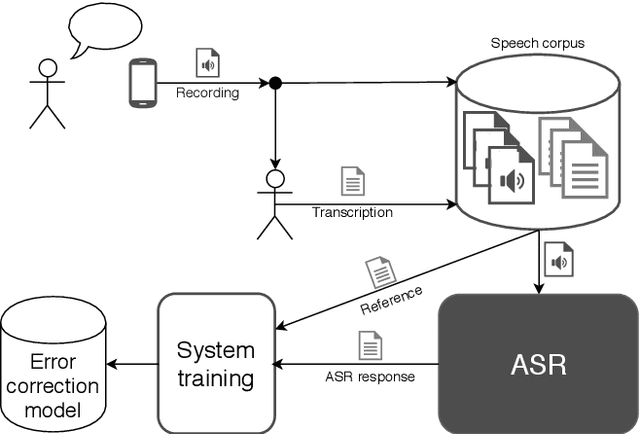
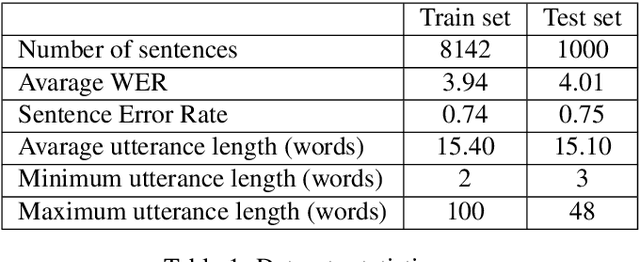
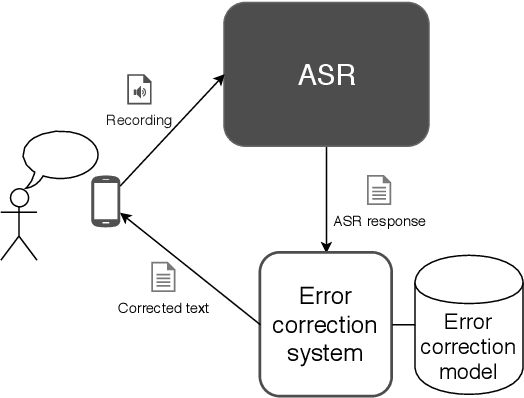
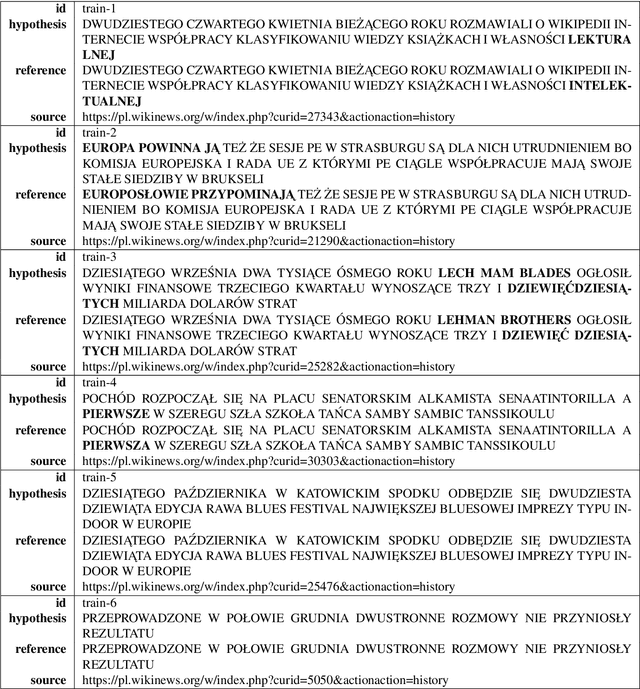
The paper announces the new long-term challenge for improving the performance of automatic speech recognition systems. The goal of the challenge is to investigate methods of correcting the recognition results on the basis of previously made errors by the speech processing system. The dataset prepared for the task is described and evaluation criteria are presented.
Hate is the New Infodemic: A Topic-aware Modeling of Hate Speech Diffusion on Twitter
Oct 09, 2020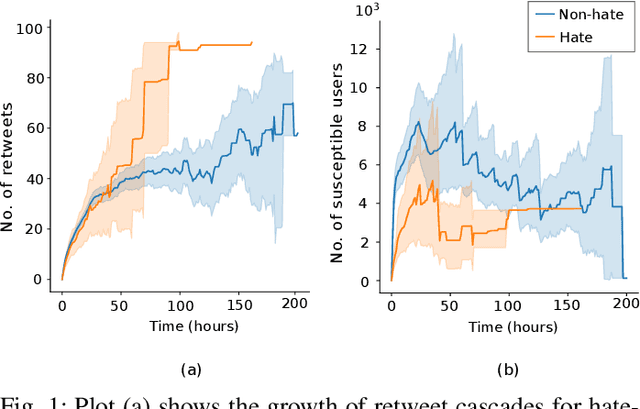
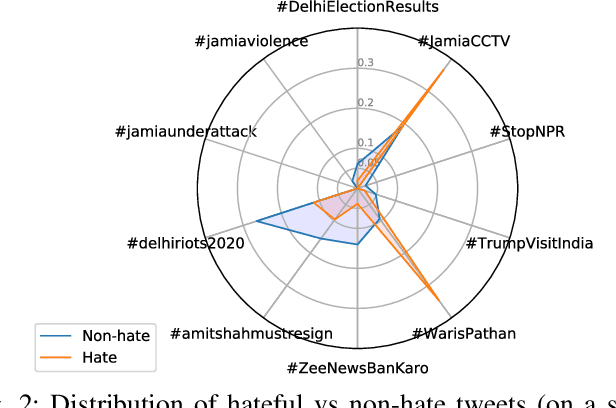
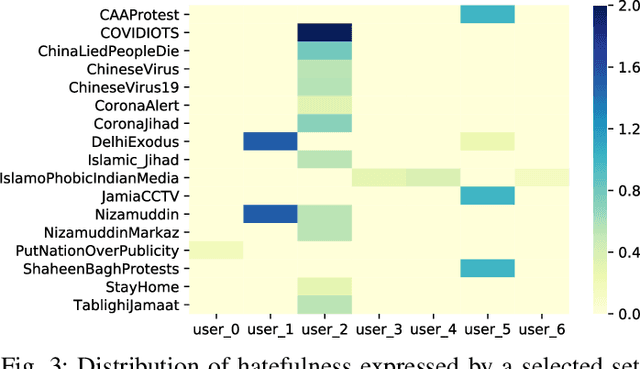
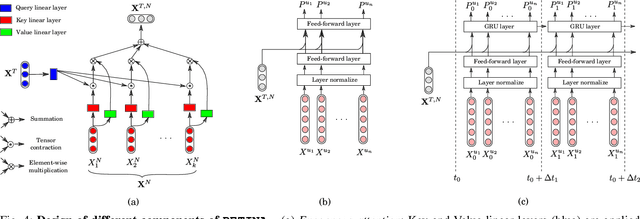
Online hate speech, particularly over microblogging platforms like Twitter, has emerged as arguably the most severe issue of the past decade. Several countries have reported a steep rise in hate crimes infuriated by malicious hate campaigns. While the detection of hate speech is one of the emerging research areas, the generation and spread of topic-dependent hate in the information network remain under-explored. In this work, we focus on exploring user behaviour, which triggers the genesis of hate speech on Twitter and how it diffuses via retweets. We crawl a large-scale dataset of tweets, retweets, user activity history, and follower networks, comprising over 161 million tweets from more than $41$ million unique users. We also collect over 600k contemporary news articles published online. We characterize different signals of information that govern these dynamics. Our analyses differentiate the diffusion dynamics in the presence of hate from usual information diffusion. This motivates us to formulate the modelling problem in a topic-aware setting with real-world knowledge. For predicting the initiation of hate speech for any given hashtag, we propose multiple feature-rich models, with the best performing one achieving a macro F1 score of 0.65. Meanwhile, to predict the retweet dynamics on Twitter, we propose RETINA, a novel neural architecture that incorporates exogenous influence using scaled dot-product attention. RETINA achieves a macro F1-score of 0.85, outperforming multiple state-of-the-art models. Our analysis reveals the superlative power of RETINA to predict the retweet dynamics of hateful content compared to the existing diffusion models.
Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition
Apr 19, 2021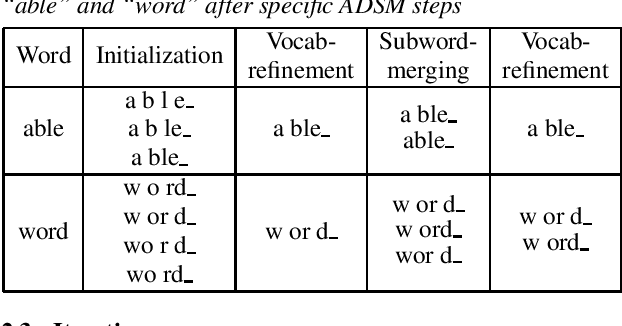
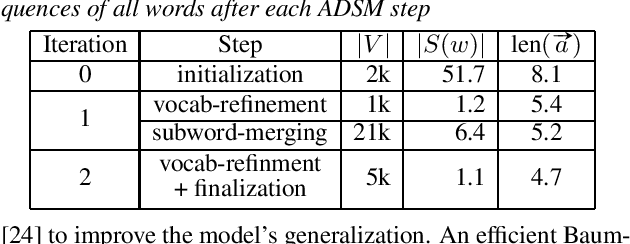
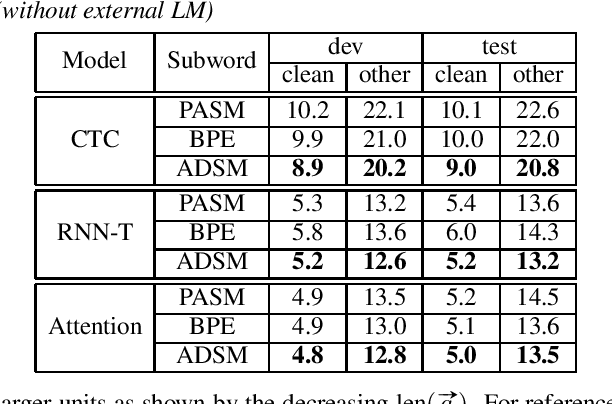

Subword units are commonly used for end-to-end automatic speech recognition (ASR), while a fully acoustic-oriented subword modeling approach is somewhat missing. We propose an acoustic data-driven subword modeling (ADSM) approach that adapts the advantages of several text-based and acoustic-based subword methods into one pipeline. With a fully acoustic-oriented label design and learning process, ADSM produces acoustic-structured subword units and acoustic-matched target sequence for further ASR training. The obtained ADSM labels are evaluated with different end-to-end ASR approaches including CTC, RNN-transducer and attention models. Experiments on the LibriSpeech corpus show that ADSM clearly outperforms both byte pair encoding (BPE) and pronunciation-assisted subword modeling (PASM) in all cases. Detailed analysis shows that ADSM achieves acoustically more logical word segmentation and more balanced sequence length, and thus, is suitable for both time-synchronous and label-synchronous models. We also briefly describe how to apply acoustic-based subword regularization and unseen text segmentation using ADSM.