 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Robust Speaker Recognition Using Speech Enhancement And Attention Model
Jan 14, 2020
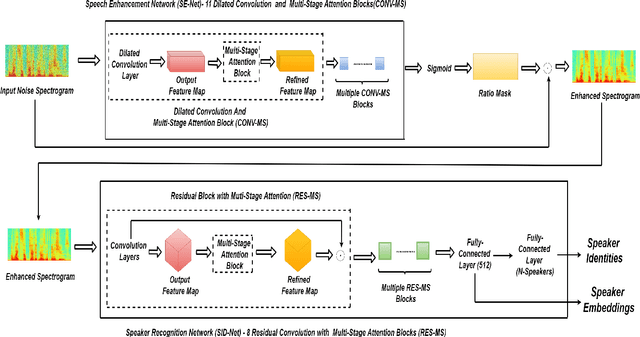
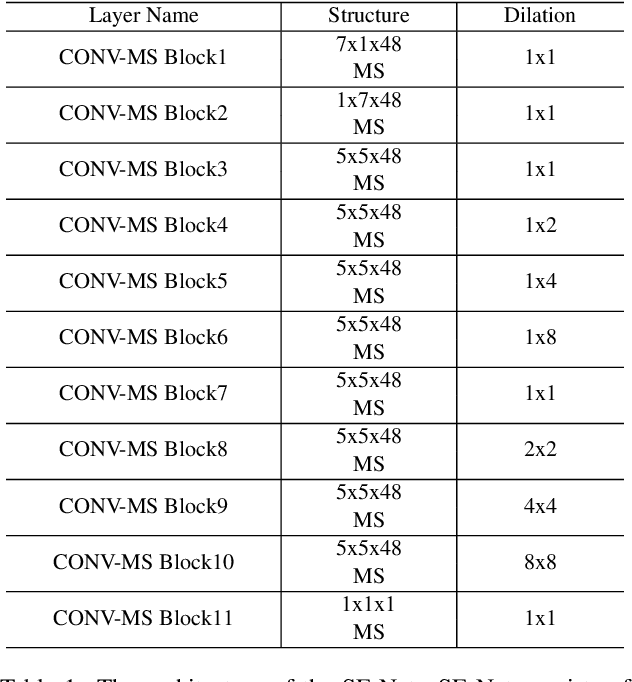
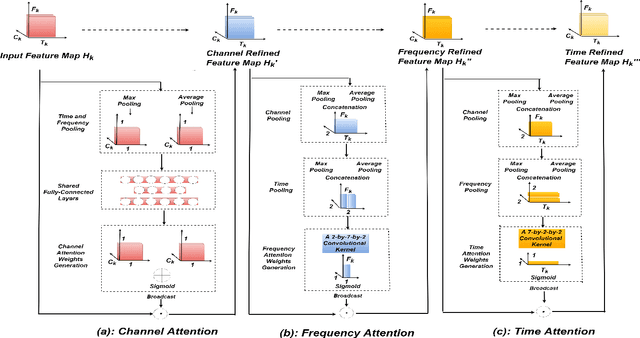
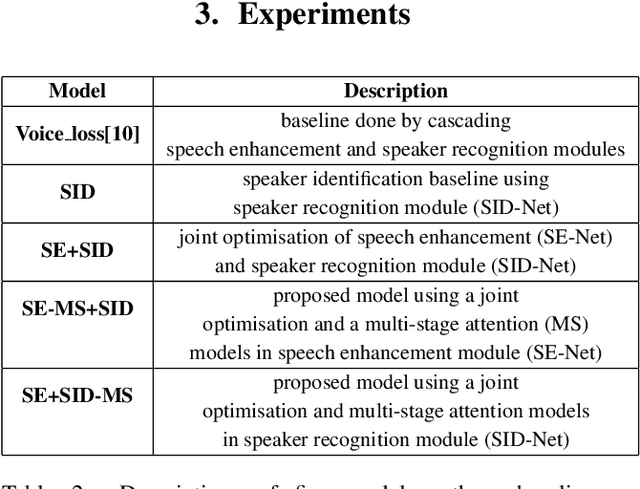
In this paper, a novel architecture for speaker recognition is proposed by cascading speech enhancement and speaker processing. Its aim is to improve speaker recognition performance when speech signals are corrupted by noise. Instead of individually processing speech enhancement and speaker recognition, the two modules are integrated into one framework by a joint optimisation using deep neural networks. Furthermore, to increase robustness against noise, a multi-stage attention mechanism is employed to highlight the speaker related features learned from context information in time and frequency domain. To evaluate speaker identification and verification performance of the proposed approach, we test it on the dataset of VoxCeleb1, one of mostly used benchmark datasets. Moreover, the robustness of our proposed approach is also tested on VoxCeleb1 data when being corrupted by three types of interferences, general noise, music, and babble, at different signal-to-noise ratio (SNR) levels. The obtained results show that the proposed approach using speech enhancement and multi-stage attention models outperforms two strong baselines not using them in most acoustic conditions in our experiments.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jun 18, 2021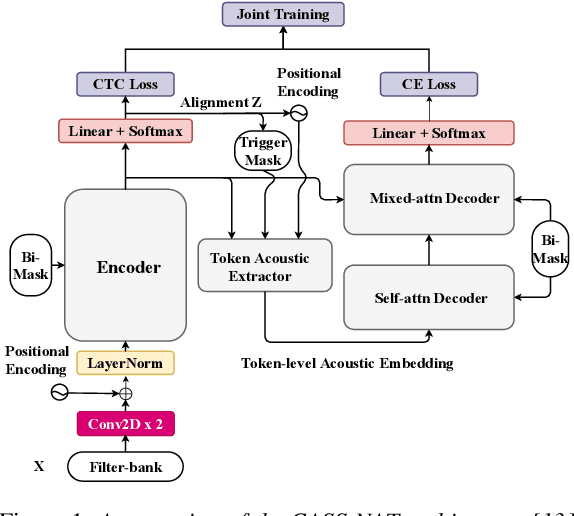
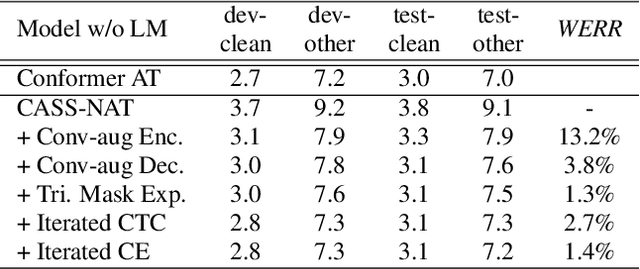
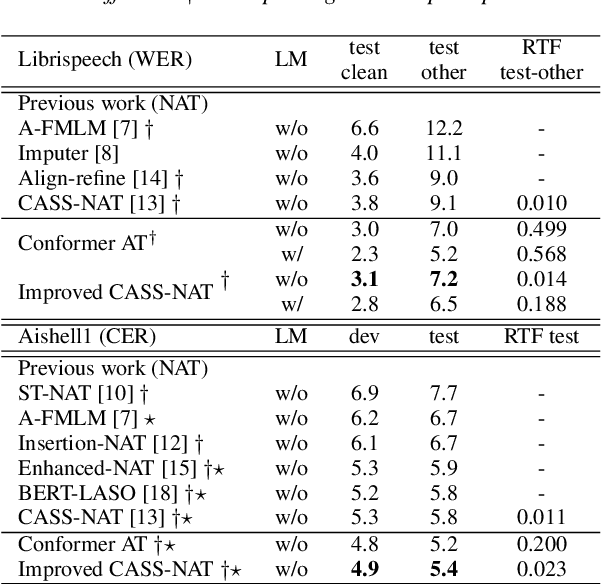
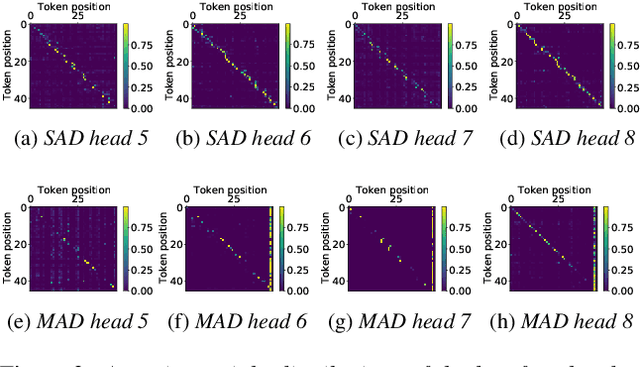
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Improving EEG based Continuous Speech Recognition
Nov 24, 2019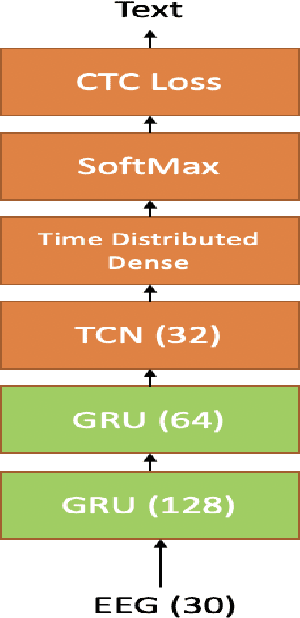
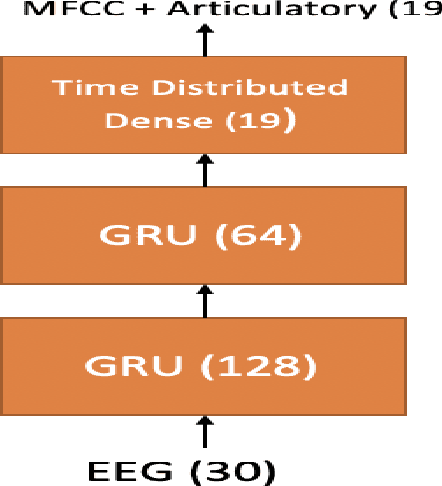
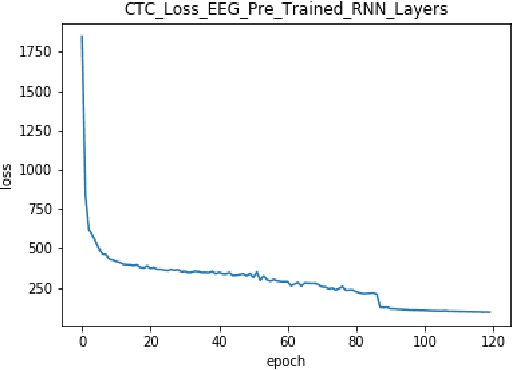
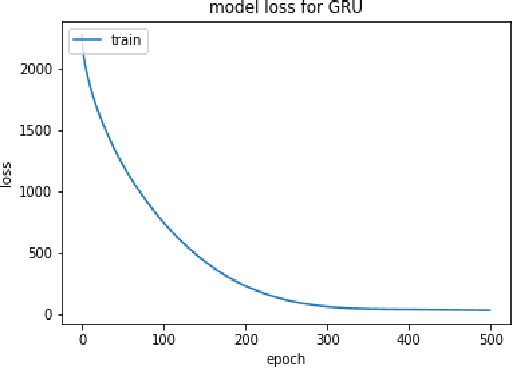
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Glottal Closure and Opening Instant Detection from Speech Signals
Dec 28, 2019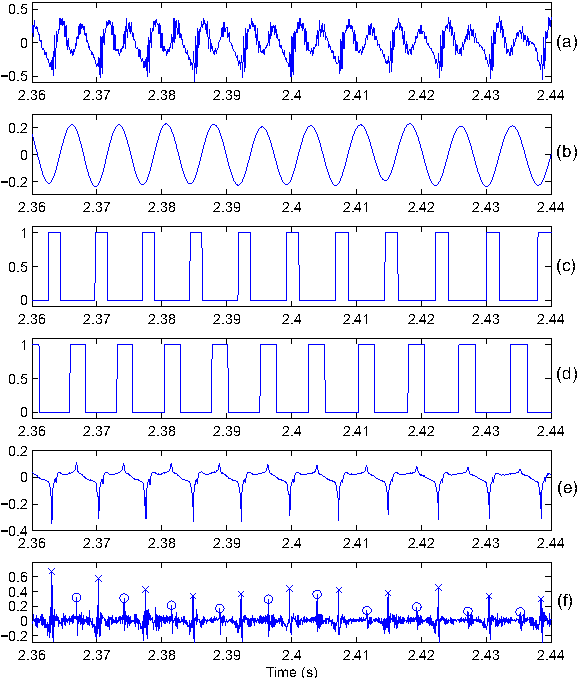
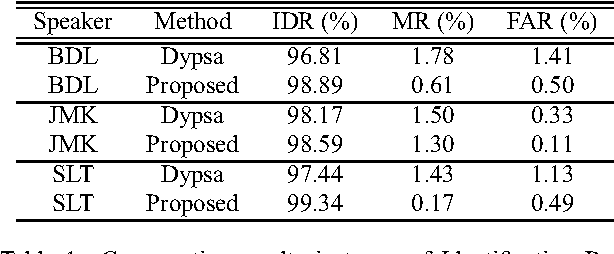
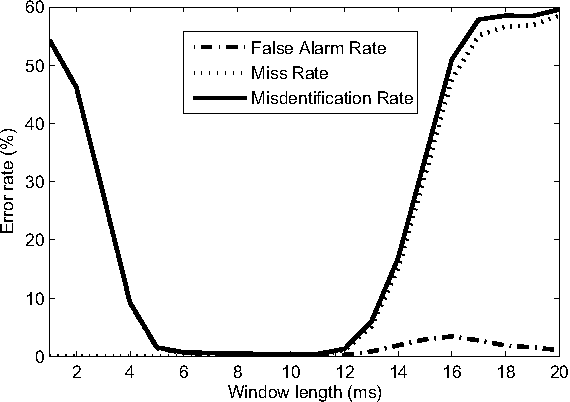
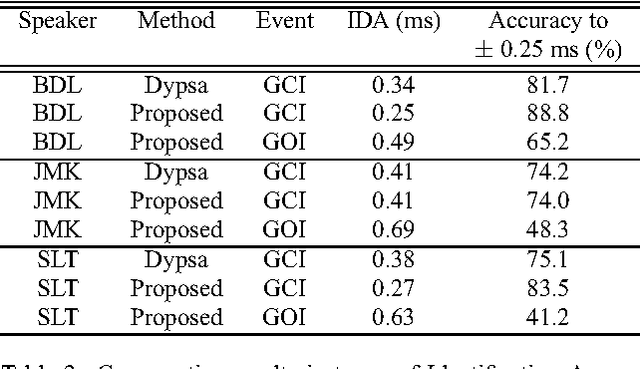
This paper proposes a new procedure to detect Glottal Closure and Opening Instants (GCIs and GOIs) directly from speech waveforms. The procedure is divided into two successive steps. First a mean-based signal is computed, and intervals where speech events are expected to occur are extracted from it. Secondly, at each interval a precise position of the speech event is assigned by locating a discontinuity in the Linear Prediction residual. The proposed method is compared to the DYPSA algorithm on the CMU ARCTIC database. A significant improvement as well as a better noise robustness are reported. Besides, results of GOI identification accuracy are promising for the glottal source characterization.
On the Usefulness of Self-Attention for Automatic Speech Recognition with Transformers
Nov 08, 2020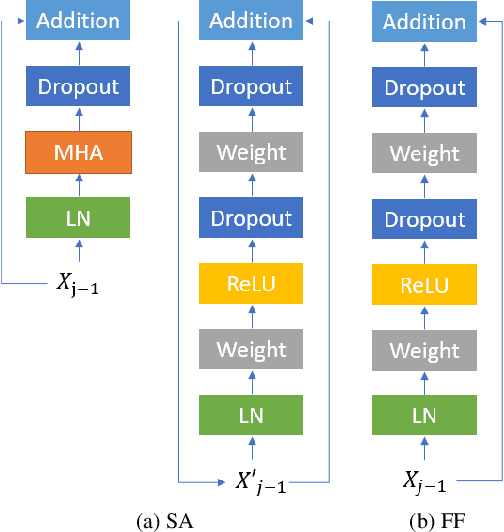
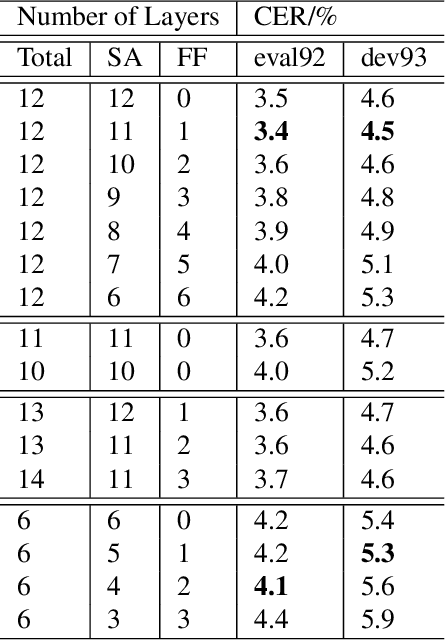
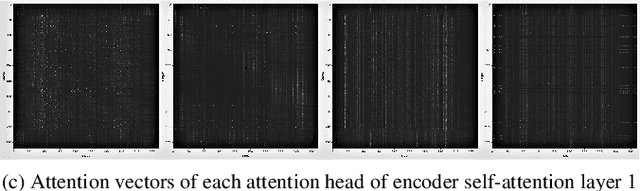
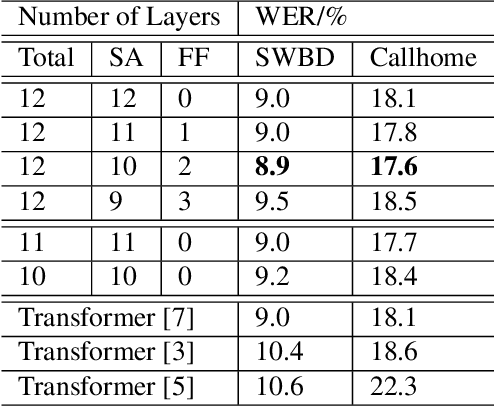
Self-attention models such as Transformers, which can capture temporal relationships without being limited by the distance between events, have given competitive speech recognition results. However, we note the range of the learned context increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence useful for the upper self-attention encoder layers in Transformers? To investigate this, we train models with lower self-attention/upper feed-forward layers encoders on Wall Street Journal and Switchboard. Compared to baseline Transformers, no performance drop but minor gains are observed. We further developed a novel metric of the diagonality of attention matrices and found the learned diagonality indeed increases from the lower to upper encoder self-attention layers. We conclude the global view is unnecessary in training upper encoder layers.
Parallel Neural Text-to-Speech
May 21, 2019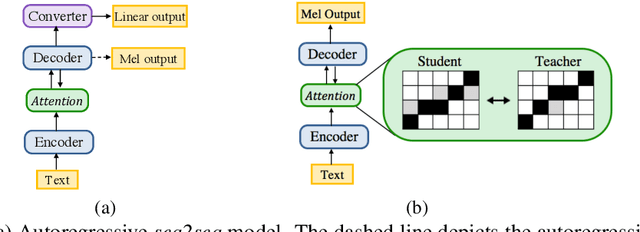
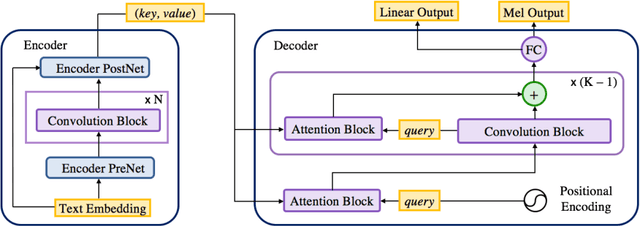

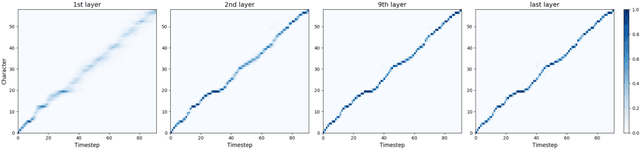
In this work, we propose a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and obtains about 17.5 times speed-up over Deep Voice 3 at synthesis while maintaining comparable speech quality using a WaveNet vocoder. Interestingly, it has even fewer attention errors than the autoregressive model on the challenging test sentences. Furthermore, we build the first fully parallel neural text-to-speech system by applying the inverse autoregressive flow~(IAF) as the parallel neural vocoder. Our system can synthesize speech from text through a single feed-forward pass. We also explore a novel approach to train the IAF from scratch as a generative model for raw waveform, which avoids the need for distillation from a separately trained WaveNet.
ConvMixer: Feature Interactive Convolution with Curriculum Learning for Small Footprint and Noisy Far-field Keyword Spotting
Jan 15, 2022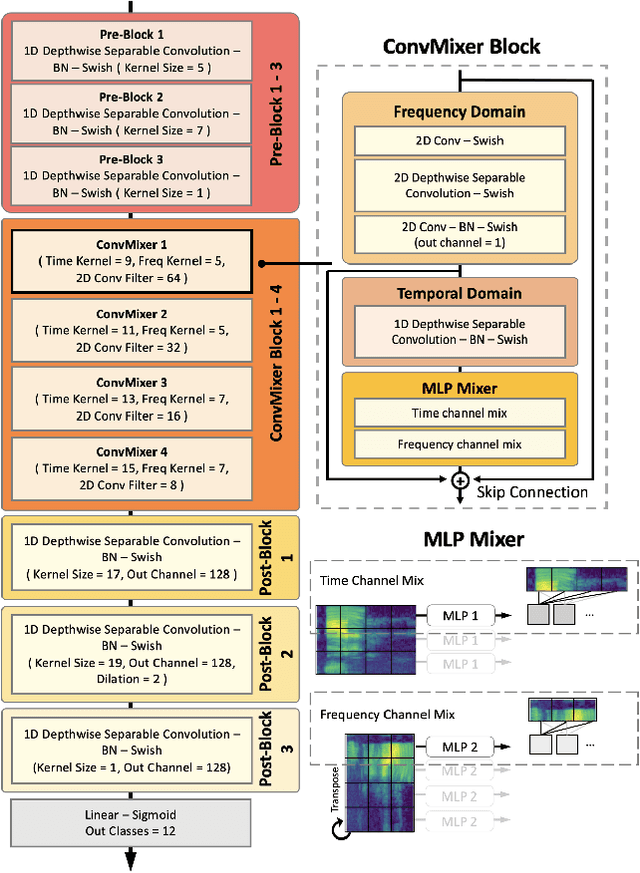
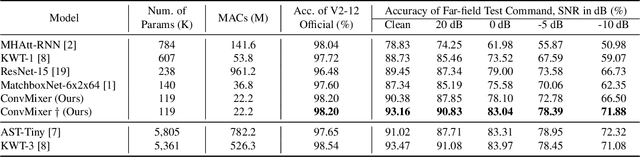
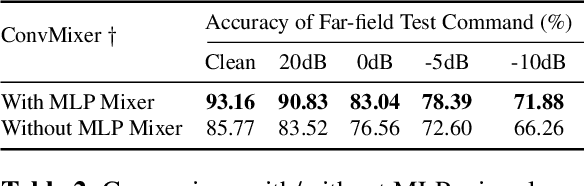
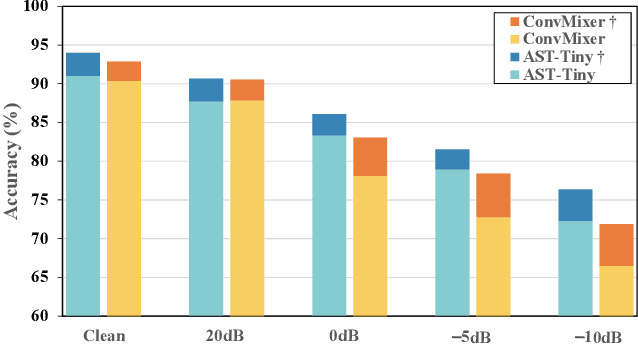
Building efficient architecture in neural speech processing is paramount to success in keyword spotting deployment. However, it is very challenging for lightweight models to achieve noise robustness with concise neural operations. In a real-world application, the user environment is typically noisy and may also contain reverberations. We proposed a novel feature interactive convolutional model with merely 100K parameters to tackle this under the noisy far-field condition. The interactive unit is proposed in place of the attention module that promotes the flow of information with more efficient computations. Moreover, curriculum-based multi-condition training is adopted to attain better noise robustness. Our model achieves 98.2% top-1 accuracy on Google Speech Command V2-12 and is competitive against large transformer models under the designed noise condition.
Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
May 06, 2022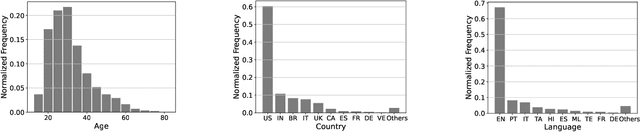
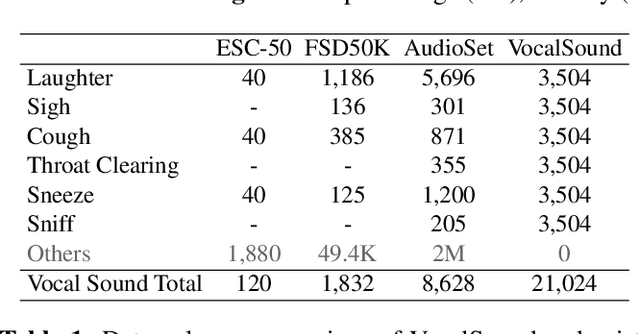
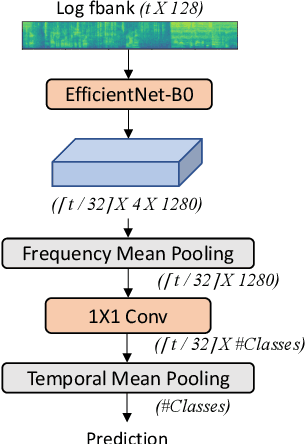
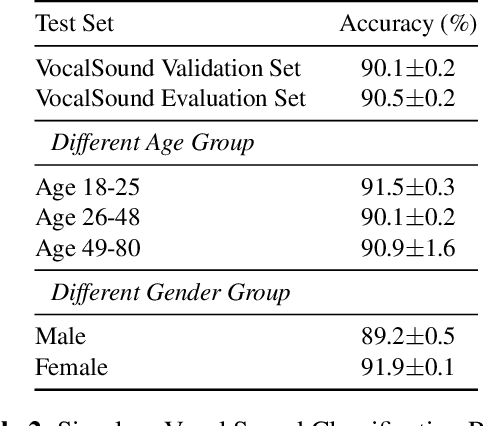
Recognizing human non-speech vocalizations is an important task and has broad applications such as automatic sound transcription and health condition monitoring. However, existing datasets have a relatively small number of vocal sound samples or noisy labels. As a consequence, state-of-the-art audio event classification models may not perform well in detecting human vocal sounds. To support research on building robust and accurate vocal sound recognition, we have created a VocalSound dataset consisting of over 21,000 crowdsourced recordings of laughter, sighs, coughs, throat clearing, sneezes, and sniffs from 3,365 unique subjects. Experiments show that the vocal sound recognition performance of a model can be significantly improved by 41.9% by adding VocalSound dataset to an existing dataset as training material. In addition, different from previous datasets, the VocalSound dataset contains meta information such as speaker age, gender, native language, country, and health condition.
Pre-training for low resource speech-to-intent applications
Mar 30, 2021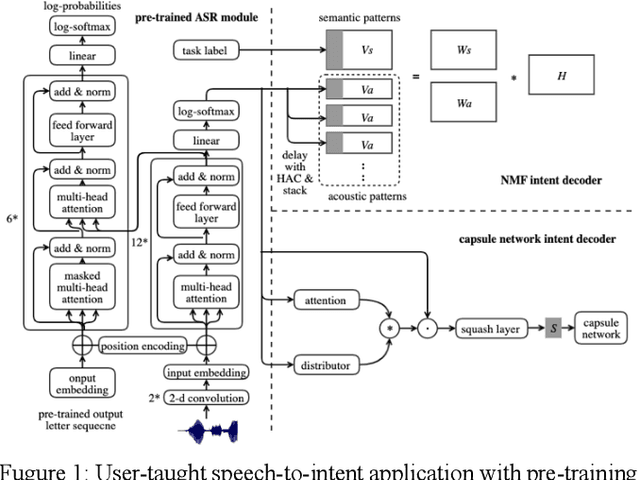
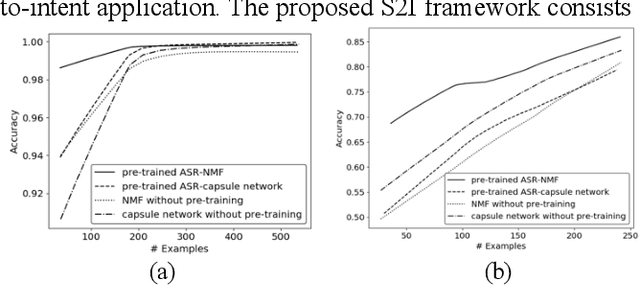
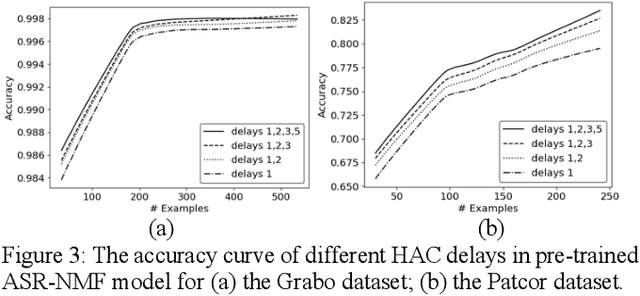
Designing a speech-to-intent (S2I) agent which maps the users' spoken commands to the agents' desired task actions can be challenging due to the diverse grammatical and lexical preference of different users. As a remedy, we discuss a user-taught S2I system in this paper. The user-taught system learns from scratch from the users' spoken input with action demonstration, which ensure it is fully matched to the users' way of formulating intents and their articulation habits. The main issue is the scarce training data due to the user effort involved. Existing state-of-art approaches in this setting are based on non-negative matrix factorization (NMF) and capsule networks. In this paper we combine the encoder of an end-to-end ASR system with the prior NMF/capsule network-based user-taught decoder, and investigate whether pre-training methodology can reduce training data requirements for the NMF and capsule network. Experimental results show the pre-trained ASR-NMF framework significantly outperforms other models, and also, we discuss limitations of pre-training with different types of command-and-control(C&C) applications.
DCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement
Jun 16, 2021
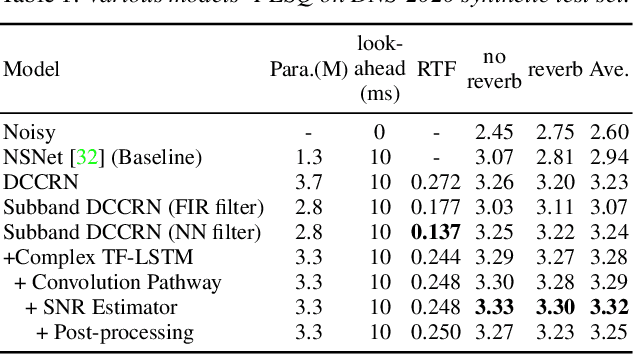
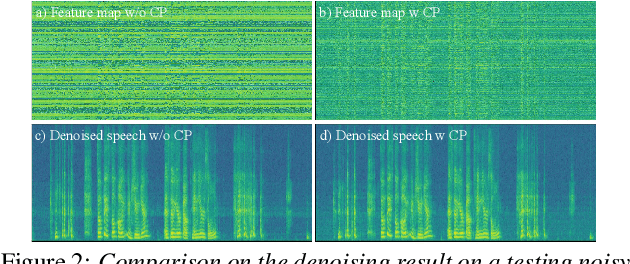

Deep complex convolution recurrent network (DCCRN), which extends CRN with complex structure, has achieved superior performance in MOS evaluation in Interspeech 2020 deep noise suppression challenge (DNS2020). This paper further extends DCCRN with the following significant revisions. We first extend the model to sub-band processing where the bands are split and merged by learnable neural network filters instead of engineered FIR filters, leading to a faster noise suppressor trained in an end-to-end manner. Then the LSTM is further substituted with a complex TF-LSTM to better model temporal dependencies along both time and frequency axes. Moreover, instead of simply concatenating the output of each encoder layer to the input of the corresponding decoder layer, we use convolution blocks to first aggregate essential information from the encoder output before feeding it to the decoder layers. We specifically formulate the decoder with an extra a priori SNR estimation module to maintain good speech quality while removing noise. Finally a post-processing module is adopted to further suppress the unnatural residual noise. The new model, named DCCRN+, has surpassed the original DCCRN as well as several competitive models in terms of PESQ and DNSMOS, and has achieved superior performance in the new Interspeech 2021 DNS challenge