 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Detecting White Supremacist Hate Speech using Domain Specific Word Embedding with Deep Learning and BERT
Oct 01, 2020

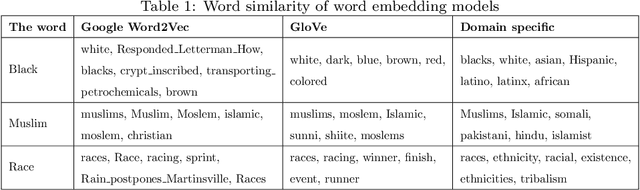
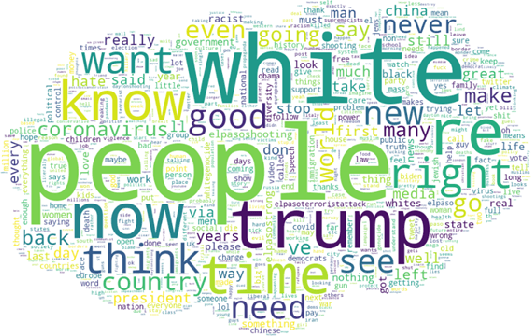
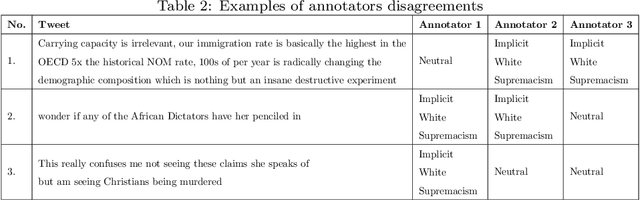
White supremacists embrace a radical ideology that considers white people superior to people of other races. The critical influence of these groups is no longer limited to social media; they also have a significant effect on society in many ways by promoting racial hatred and violence. White supremacist hate speech is one of the most recently observed harmful content on social media.Traditional channels of reporting hate speech have proved inadequate due to the tremendous explosion of information, and therefore, it is necessary to find an automatic way to detect such speech in a timely manner. This research investigates the viability of automatically detecting white supremacist hate speech on Twitter by using deep learning and natural language processing techniques. Through our experiments, we used two approaches, the first approach is by using domain-specific embeddings which are extracted from white supremacist corpus in order to catch the meaning of this white supremacist slang with bidirectional Long Short-Term Memory (LSTM) deep learning model, this approach reached a 0.74890 F1-score. The second approach is by using the one of the most recent language model which is BERT, BERT model provides the state of the art of most NLP tasks. It reached to a 0.79605 F1-score. Both approaches are tested on a balanced dataset given that our experiments were based on textual data only. The dataset was combined from dataset created from Twitter and a Stormfront dataset compiled from that white supremacist forum.
GAN-Aimbots: Using Machine Learning for Cheating in First Person Shooters
May 14, 2022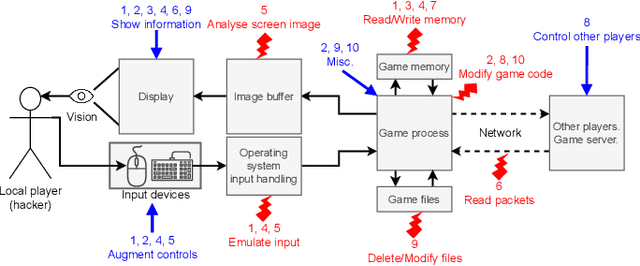
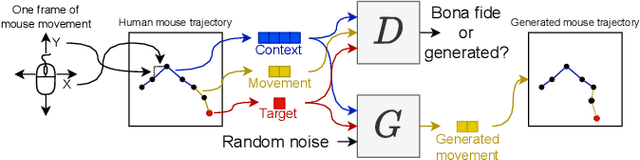
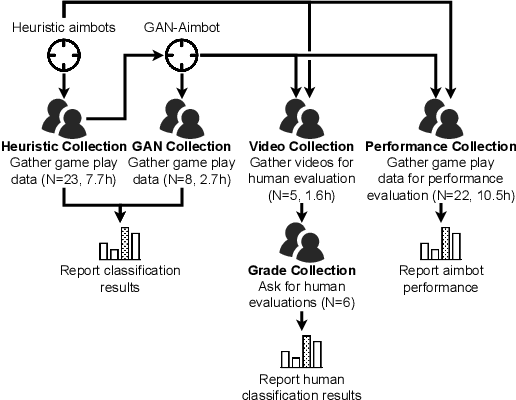
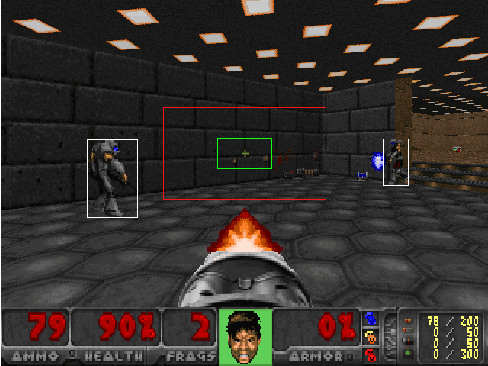
Playing games with cheaters is not fun, and in a multi-billion-dollar video game industry with hundreds of millions of players, game developers aim to improve the security and, consequently, the user experience of their games by preventing cheating. Both traditional software-based methods and statistical systems have been successful in protecting against cheating, but recent advances in the automatic generation of content, such as images or speech, threaten the video game industry; they could be used to generate artificial gameplay indistinguishable from that of legitimate human players. To better understand this threat, we begin by reviewing the current state of multiplayer video game cheating, and then proceed to build a proof-of-concept method, GAN-Aimbot. By gathering data from various players in a first-person shooter game we show that the method improves players' performance while remaining hidden from automatic and manual protection mechanisms. By sharing this work we hope to raise awareness on this issue and encourage further research into protecting the gaming communities.
Robust Speaker Recognition Using Speech Enhancement And Attention Model
Jan 14, 2020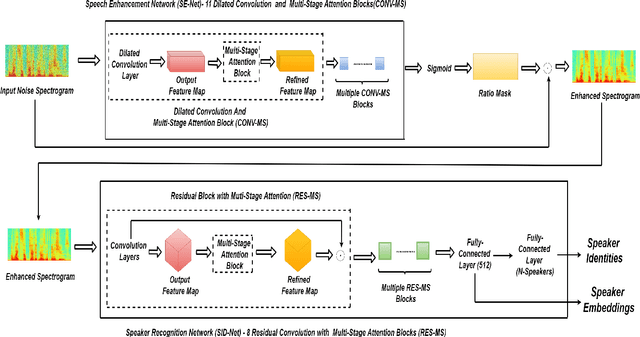
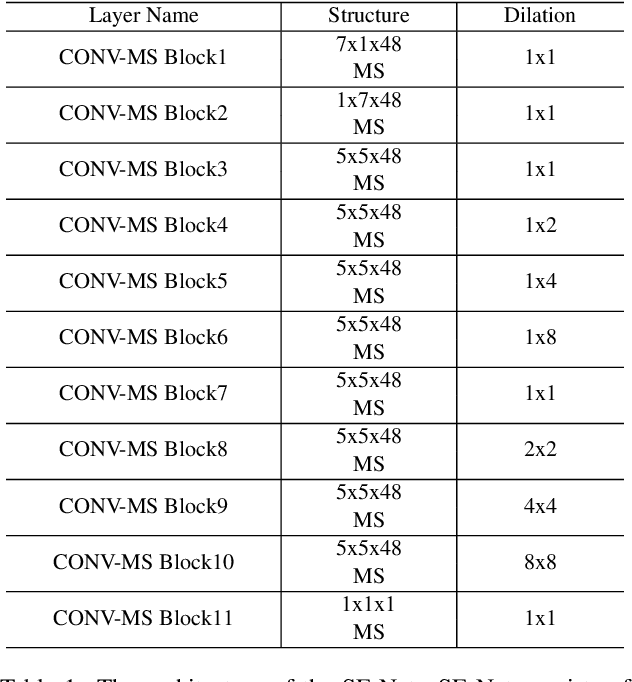
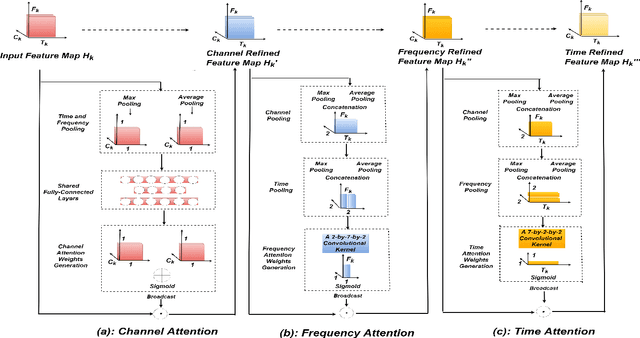
In this paper, a novel architecture for speaker recognition is proposed by cascading speech enhancement and speaker processing. Its aim is to improve speaker recognition performance when speech signals are corrupted by noise. Instead of individually processing speech enhancement and speaker recognition, the two modules are integrated into one framework by a joint optimisation using deep neural networks. Furthermore, to increase robustness against noise, a multi-stage attention mechanism is employed to highlight the speaker related features learned from context information in time and frequency domain. To evaluate speaker identification and verification performance of the proposed approach, we test it on the dataset of VoxCeleb1, one of mostly used benchmark datasets. Moreover, the robustness of our proposed approach is also tested on VoxCeleb1 data when being corrupted by three types of interferences, general noise, music, and babble, at different signal-to-noise ratio (SNR) levels. The obtained results show that the proposed approach using speech enhancement and multi-stage attention models outperforms two strong baselines not using them in most acoustic conditions in our experiments.
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021
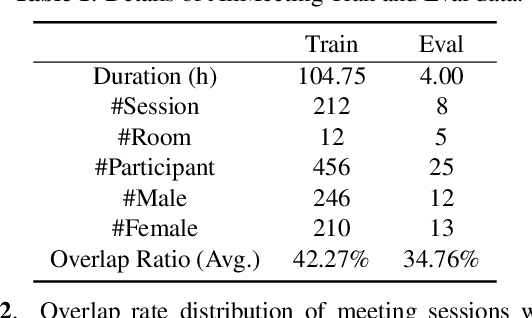
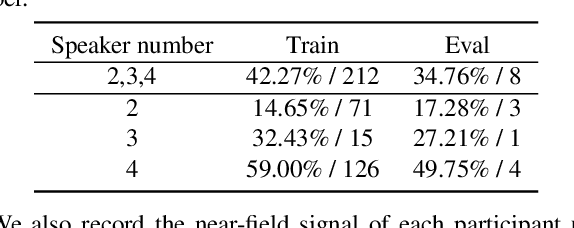
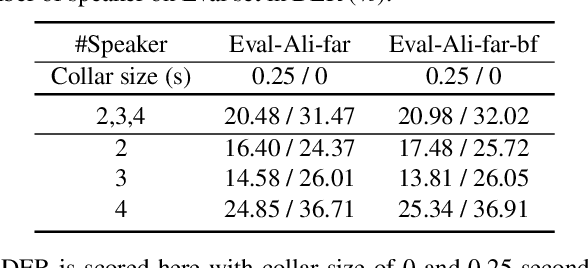
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
Federated Learning with Partial Model Personalization
Apr 08, 2022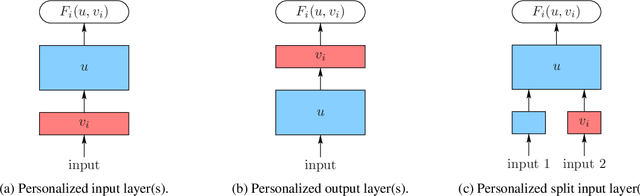

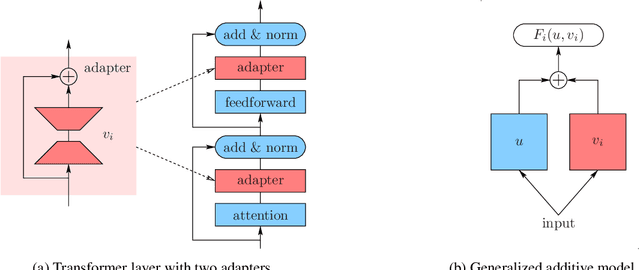

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
Improving EEG based Continuous Speech Recognition
Nov 24, 2019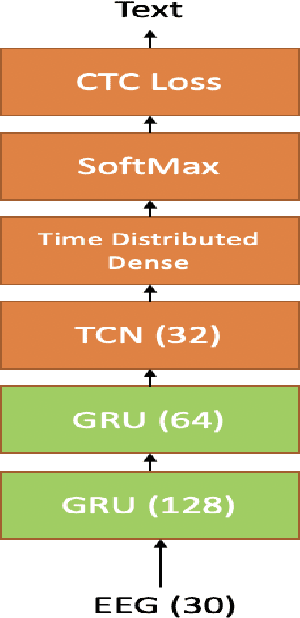
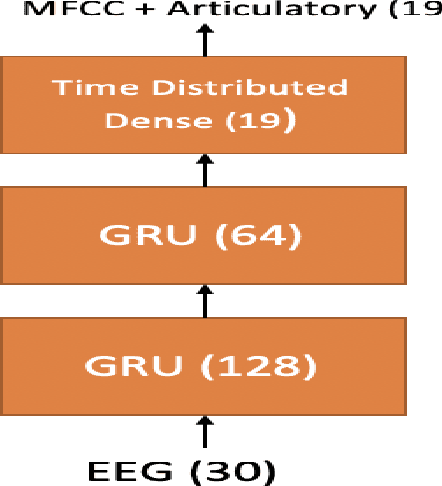
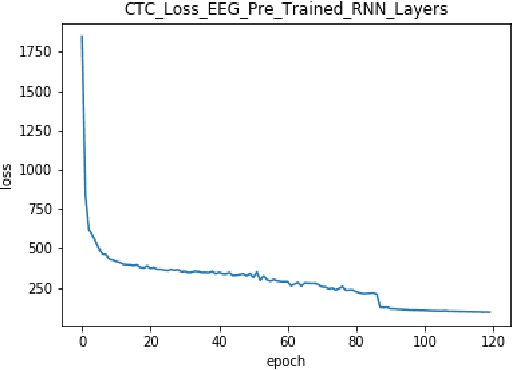
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Glottal Closure and Opening Instant Detection from Speech Signals
Dec 28, 2019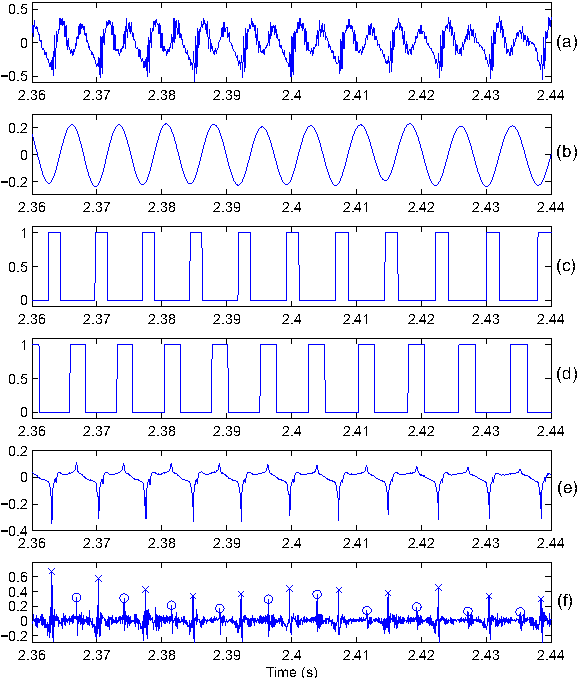
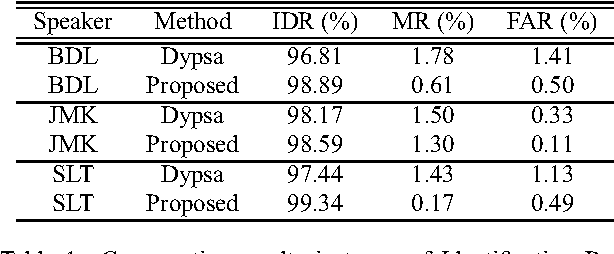
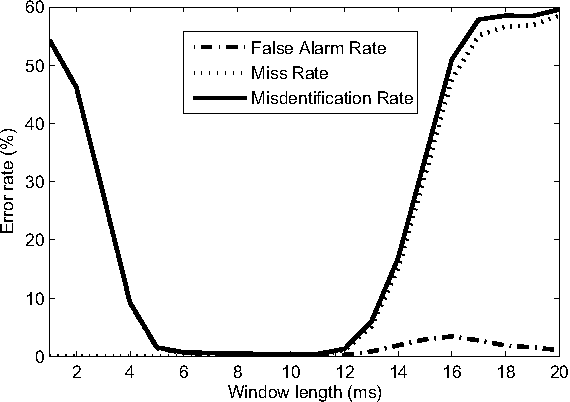
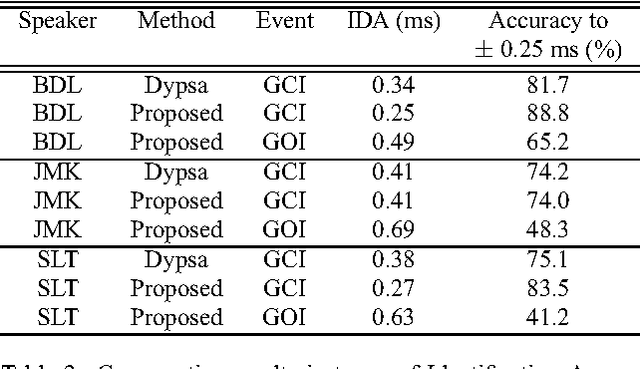
This paper proposes a new procedure to detect Glottal Closure and Opening Instants (GCIs and GOIs) directly from speech waveforms. The procedure is divided into two successive steps. First a mean-based signal is computed, and intervals where speech events are expected to occur are extracted from it. Secondly, at each interval a precise position of the speech event is assigned by locating a discontinuity in the Linear Prediction residual. The proposed method is compared to the DYPSA algorithm on the CMU ARCTIC database. A significant improvement as well as a better noise robustness are reported. Besides, results of GOI identification accuracy are promising for the glottal source characterization.
To train or not to train adversarially: A study of bias mitigation strategies for speaker recognition
Mar 17, 2022
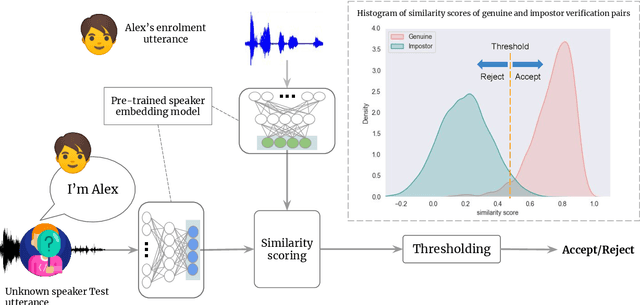
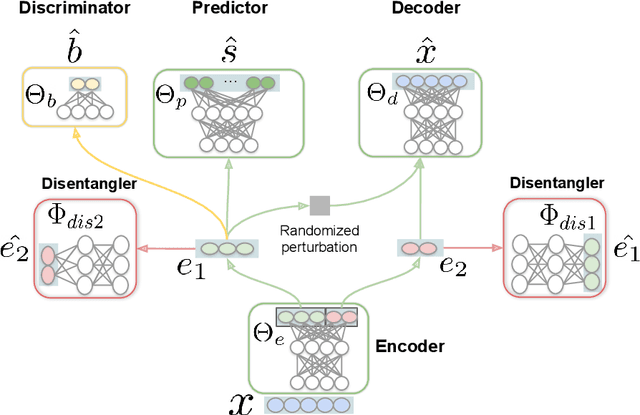
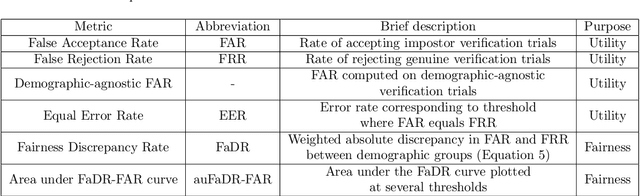
Speaker recognition is increasingly used in several everyday applications including smart speakers, customer care centers and other speech-driven analytics. It is crucial to accurately evaluate and mitigate biases present in machine learning (ML) based speech technologies, such as speaker recognition, to ensure their inclusive adoption. ML fairness studies with respect to various demographic factors in modern speaker recognition systems are lagging compared to other human-centered applications such as face recognition. Existing studies on fairness in speaker recognition systems are largely limited to evaluating biases at specific operating points of the systems, which can lead to false expectations of fairness. Moreover, there are only a handful of bias mitigation strategies developed for speaker recognition systems. In this paper, we systematically evaluate the biases present in speaker recognition systems with respect to gender across a range of system operating points. We also propose adversarial and multi-task learning techniques to improve the fairness of these systems. We show through quantitative and qualitative evaluations that the proposed methods improve the fairness of ASV systems over baseline methods trained using data balancing techniques. We also present a fairness-utility trade-off analysis to jointly examine fairness and the overall system performance. We show that although systems trained using adversarial techniques improve fairness, they are prone to reduced utility. On the other hand, multi-task methods can improve the fairness while retaining the utility. These findings can inform the choice of bias mitigation strategies in the field of speaker recognition.
E2E-based Multi-task Learning Approach to Joint Speech and Accent Recognition
Jun 15, 2021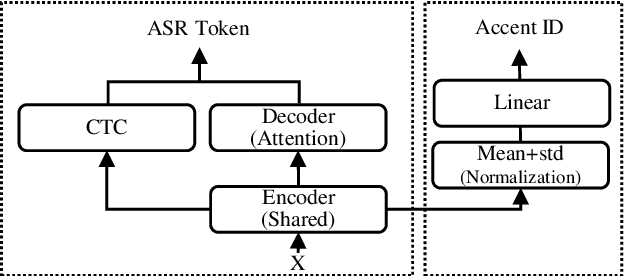
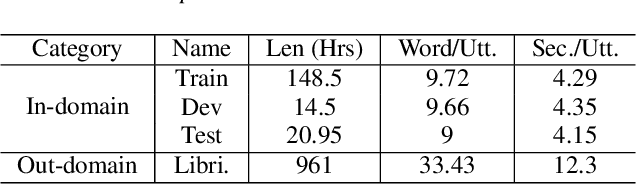
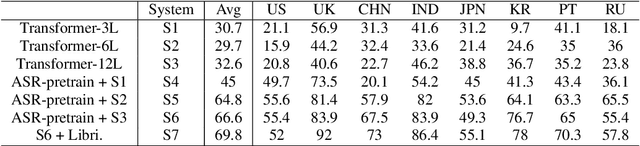
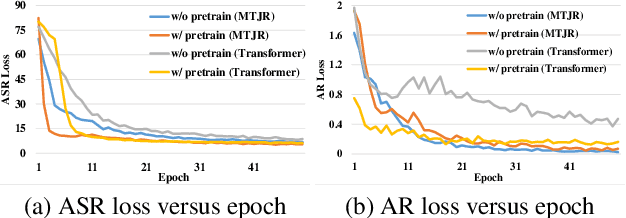
In this paper, we propose a single multi-task learning framework to perform End-to-End (E2E) speech recognition (ASR) and accent recognition (AR) simultaneously. The proposed framework is not only more compact but can also yield comparable or even better results than standalone systems. Specifically, we found that the overall performance is predominantly determined by the ASR task, and the E2E-based ASR pretraining is essential to achieve improved performance, particularly for the AR task. Additionally, we conduct several analyses of the proposed method. First, though the objective loss for the AR task is much smaller compared with its counterpart of ASR task, a smaller weighting factor with the AR task in the joint objective function is necessary to yield better results for each task. Second, we found that sharing only a few layers of the encoder yields better AR results than sharing the overall encoder. Experimentally, the proposed method produces WER results close to the best standalone E2E ASR ones, while it achieves 7.7% and 4.2% relative improvement over standalone and single-task-based joint recognition methods on test set for accent recognition respectively.
Cloud-Based Face and Speech Recognition for Access Control Applications
Apr 23, 2020
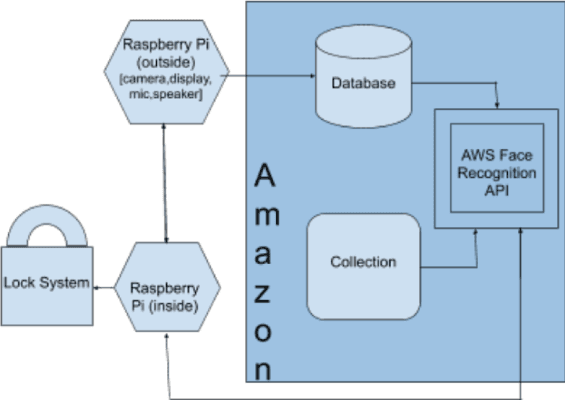
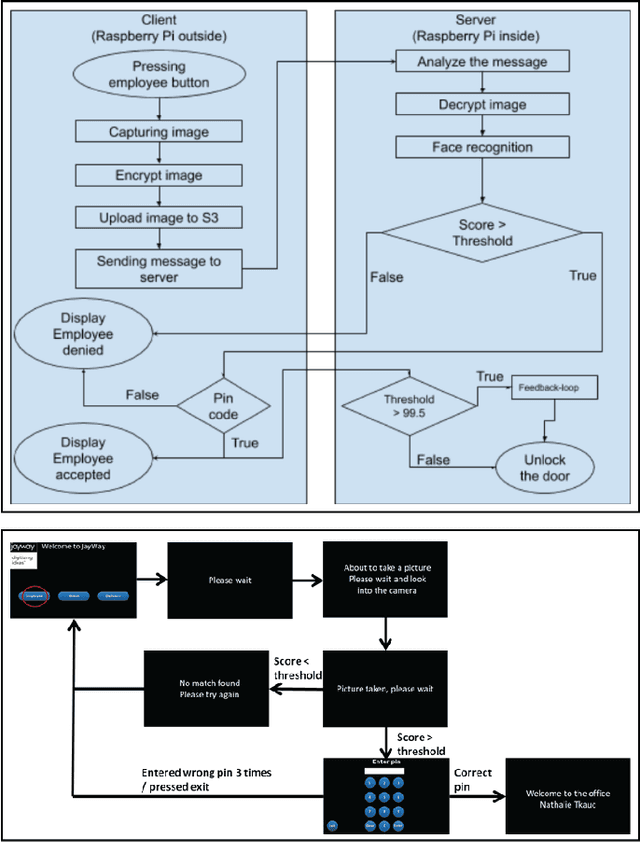
This paper describes the implementation of a system to recognize employees and visitors wanting to gain access to a physical office through face images and speech-to-text recognition. The system helps employees to unlock the entrance door via face recognition without the need of tag-keys or cards. To prevent spoofing attacks and increase security, a randomly generated code is sent to the employee, who then has to type it into the screen. On the other hand, visitors and delivery persons are provided with a speech-to-text service where they utter the name of the employee that they want to meet, and the system then sends a notification to the right employee automatically. The hardware of the system is constituted by two Raspberry Pi, a 7-inch LCD-touch display, a camera, and a sound card with a microphone and speaker. To carry out face recognition and speech-to-text conversion, the cloud-based platforms Amazon Web Services and the Google Speech-to-Text API service are used respectively. The two-step face authentication mechanism for employees provides an increased level of security and protection against spoofing attacks without the need of carrying key-tags or access cards, while disturbances by visitors or couriers are minimized by notifying their arrival to the right employee, without disturbing other co-workers by means of ring-bells.