 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker verification-derived loss and data augmentation for DNN-based multispeaker speech synthesis
Jun 03, 2021
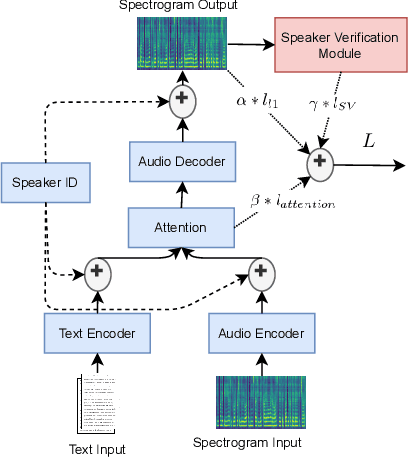
Building multispeaker neural network-based text-to-speech synthesis systems commonly relies on the availability of large amounts of high quality recordings from each speaker and conditioning the training process on the speaker's identity or on a learned representation of it. However, when little data is available from each speaker, or the number of speakers is limited, the multispeaker TTS can be hard to train and will result in poor speaker similarity and naturalness. In order to address this issue, we explore two directions: forcing the network to learn a better speaker identity representation by appending an additional loss term; and augmenting the input data pertaining to each speaker using waveform manipulation methods. We show that both methods are efficient when evaluated with both objective and subjective measures. The additional loss term aids the speaker similarity, while the data augmentation improves the intelligibility of the multispeaker TTS system.
Cloud-Based Face and Speech Recognition for Access Control Applications
May 08, 2020
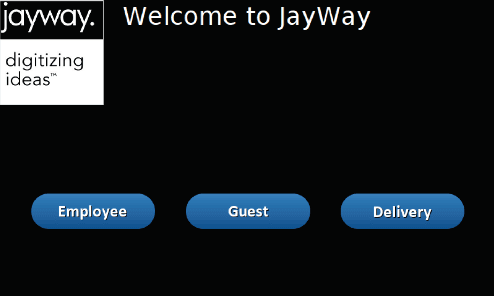
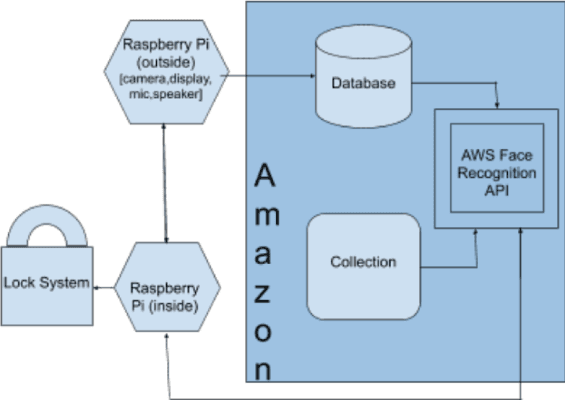
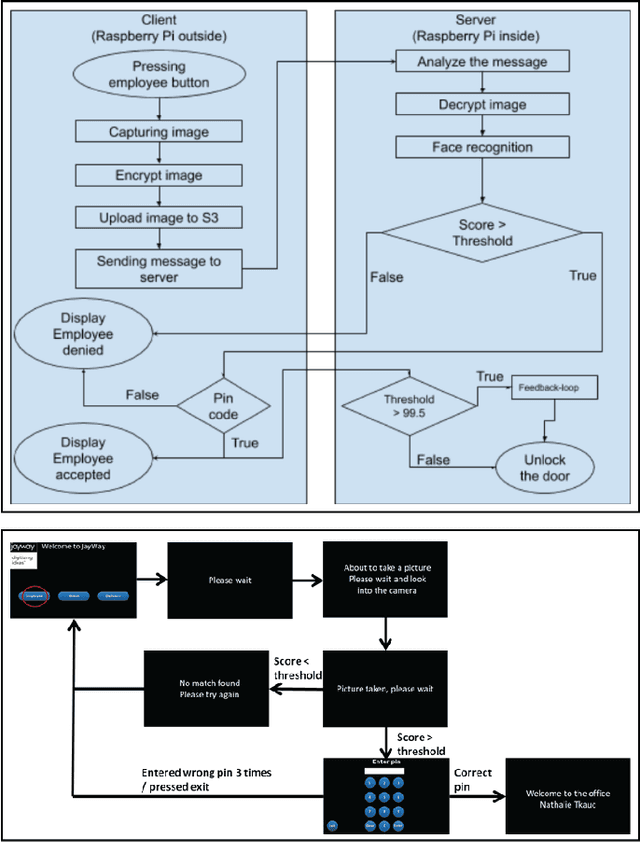
This paper describes the implementation of a system to recognize employees and visitors wanting to gain access to a physical office through face images and speech-to-text recognition. The system helps employees to unlock the entrance door via face recognition without the need of tag-keys or cards. To prevent spoofing attacks and increase security, a randomly generated code is sent to the employee, who then has to type it into the screen. On the other hand, visitors and delivery persons are provided with a speech-to-text service where they utter the name of the employee that they want to meet, and the system then sends a notification to the right employee automatically. The hardware of the system is constituted by two Raspberry Pi, a 7-inch LCD-touch display, a camera, and a sound card with a microphone and speaker. To carry out face recognition and speech-to-text conversion, the cloud-based platforms Amazon Web Services and the Google Speech-to-Text API service are used respectively. The two-step face authentication mechanism for employees provides an increased level of security and protection against spoofing attacks without the need of carrying key-tags or access cards, while disturbances by visitors or couriers are minimized by notifying their arrival to the right employee, without disturbing other co-workers by means of ring-bells.
Parallel Neural Text-to-Speech
Jun 05, 2019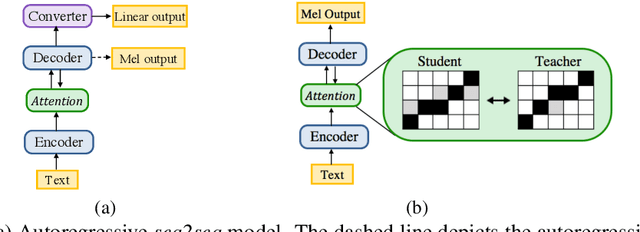
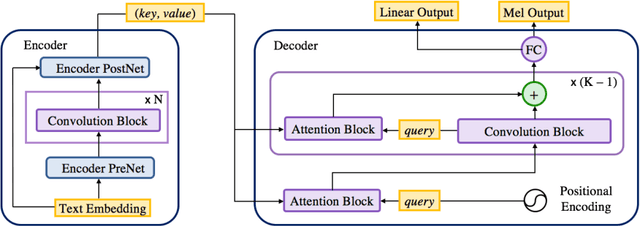

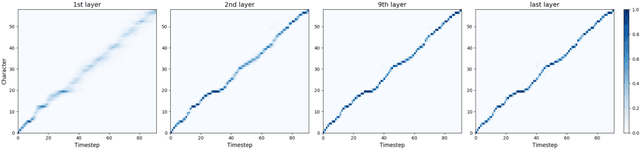
In this work, we propose a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and obtains about 46.7 times speed-up over Deep Voice 3 at synthesis while maintaining comparable speech quality using a WaveNet vocoder. Interestingly, it has even fewer attention errors than the autoregressive model on the challenging test sentences. Furthermore, we build the first fully parallel neural text-to-speech system by applying the inverse autoregressive flow~(IAF) as the parallel neural vocoder. Our system can synthesize speech from text through a single feed-forward pass. We also explore a novel approach to train the IAF from scratch as a generative model for raw waveform, which avoids the need for distillation from a separately trained WaveNet.
Merkel Podcast Corpus: A Multimodal Dataset Compiled from 16 Years of Angela Merkel's Weekly Video Podcasts
May 24, 2022
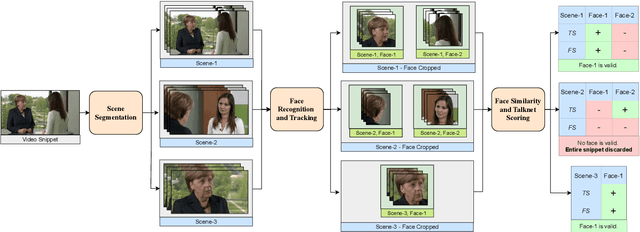
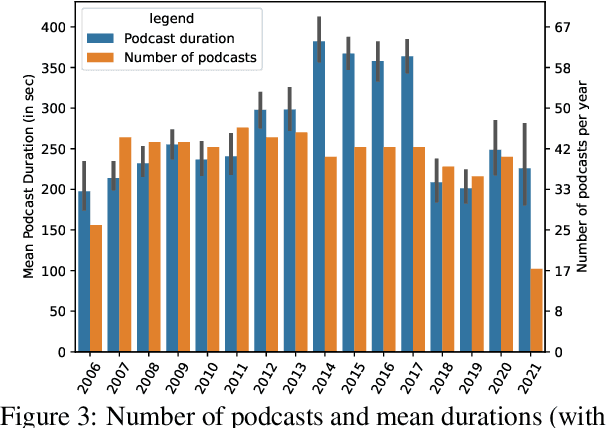
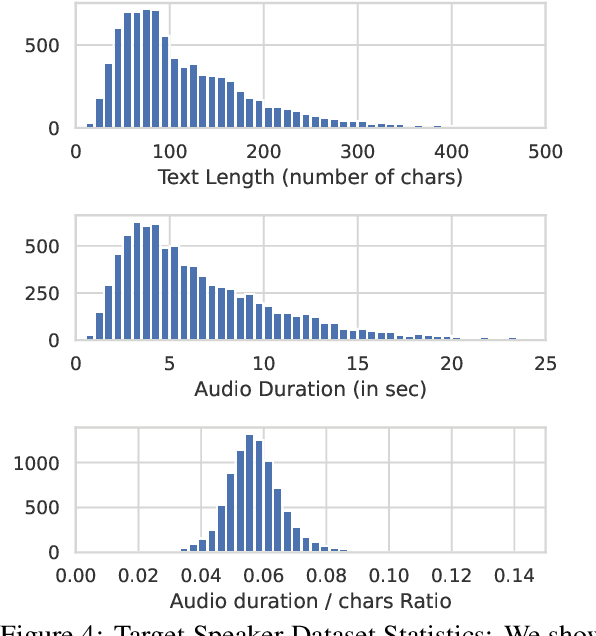
We introduce the Merkel Podcast Corpus, an audio-visual-text corpus in German collected from 16 years of (almost) weekly Internet podcasts of former German chancellor Angela Merkel. To the best of our knowledge, this is the first single speaker corpus in the German language consisting of audio, visual and text modalities of comparable size and temporal extent. We describe the methods used with which we have collected and edited the data which involves downloading the videos, transcripts and other metadata, forced alignment, performing active speaker recognition and face detection to finally curate the single speaker dataset consisting of utterances spoken by Angela Merkel. The proposed pipeline is general and can be used to curate other datasets of similar nature, such as talk show contents. Through various statistical analyses and applications of the dataset in talking face generation and TTS, we show the utility of the dataset. We argue that it is a valuable contribution to the research community, in particular, due to its realistic and challenging material at the boundary between prepared and spontaneous speech.
Hierarchical Prosody Modeling for Non-Autoregressive Speech Synthesis
Nov 17, 2020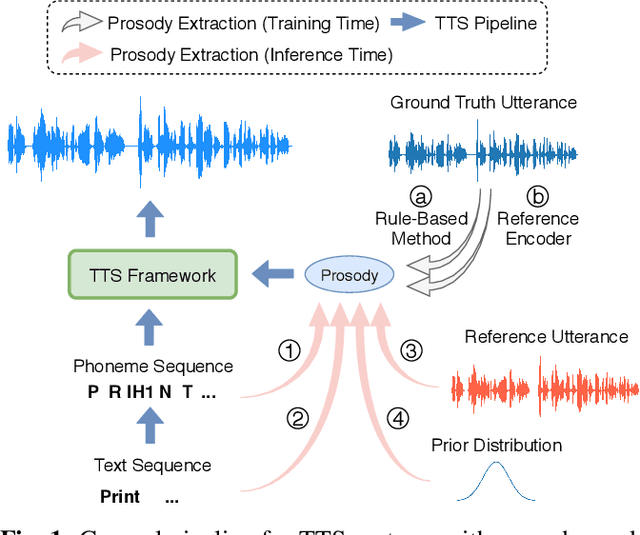
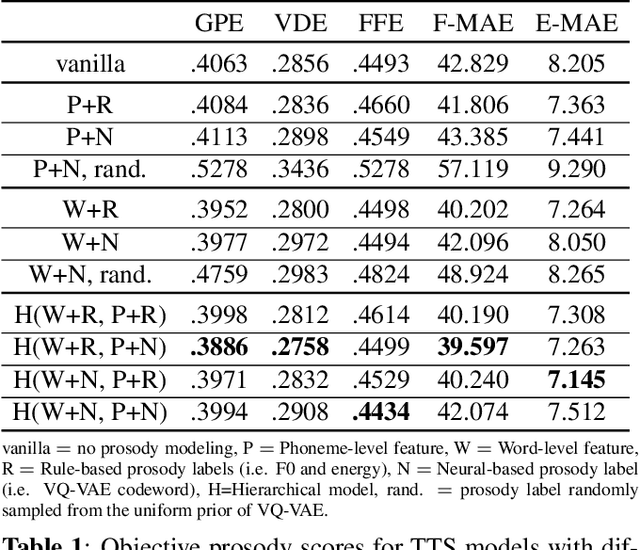
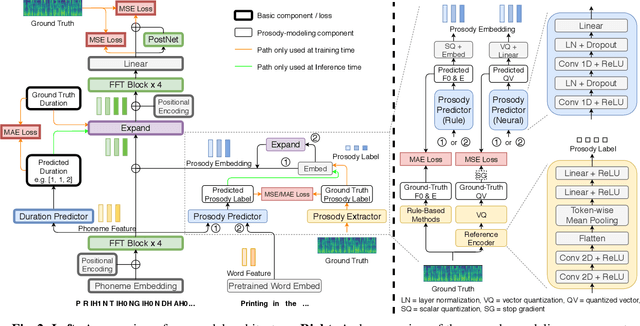
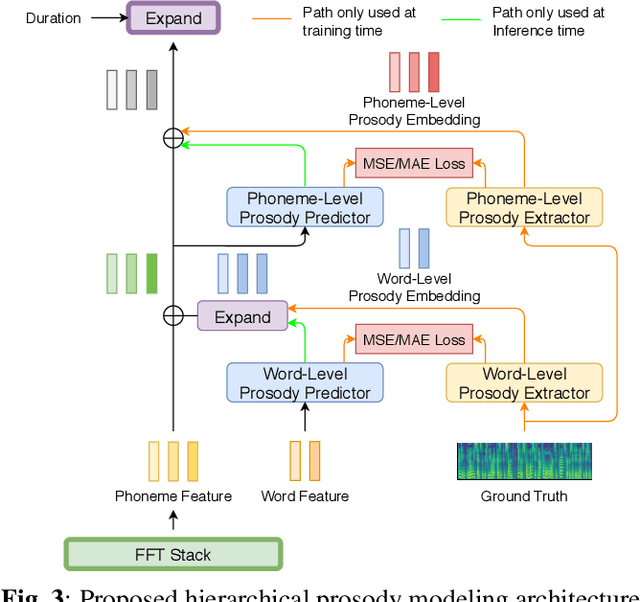
Prosody modeling is an essential component in modern text-to-speech (TTS) frameworks. By explicitly providing prosody features to the TTS model, the style of synthesized utterances can thus be controlled. However, predicting natural and reasonable prosody at inference time is challenging. In this work, we analyzed the behavior of non-autoregressive TTS models under different prosody-modeling settings and proposed a hierarchical architecture, in which the prediction of phoneme-level prosody features are conditioned on the word-level prosody features. The proposed method outperforms other competitors in terms of audio quality and prosody naturalness in our objective and subjective evaluation.
Unsupervised pre-traing for sequence to sequence speech recognition
Oct 28, 2019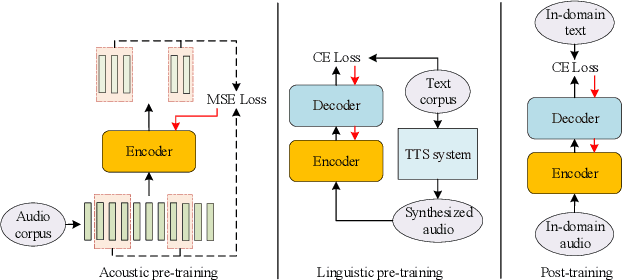

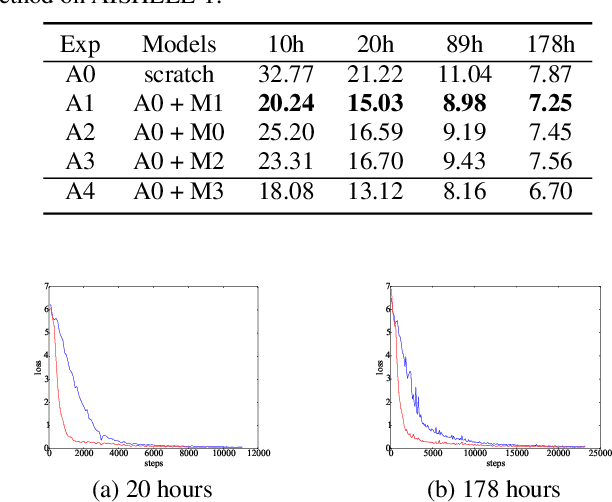
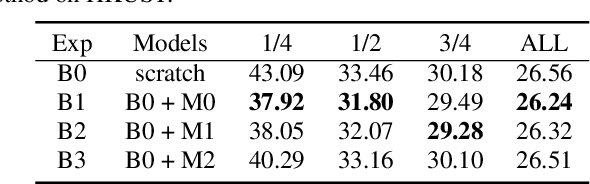
This paper proposes a novel approach to pre-train encoder-decoder sequence-to-sequence (seq2seq) model with unpaired speech and transcripts respectively. Our pre-training method is divided into two stages, named acoustic pre-trianing and linguistic pre-training. In the acoustic pre-training stage, we use a large amount of speech to pre-train the encoder by predicting masked speech feature chunks with its context. In the linguistic pre-training stage, we generate synthesized speech from a large number of transcripts using a single-speaker text to speech (TTS) system, and use the synthesized paired data to pre-train decoder. This two-stage pre-training method integrates rich acoustic and linguistic knowledge into seq2seq model, which will benefit downstream automatic speech recognition (ASR) tasks. The unsupervised pre-training is finished on AISHELL-2 dataset and we apply the pre-trained model to multiple paired data ratios of AISHELL-1 and HKUST. We obtain relative character error rate reduction (CERR) from 38.24% to 7.88% on AISHELL-1 and from 12.00% to 1.20% on HKUST. Besides, we apply our pretrained model to a cross-lingual case with CALLHOME dataset. For all six languages in CALLHOME dataset, our pre-training method makes model outperform baseline consistently.
Vietnamese Hate and Offensive Detection using PhoBERT-CNN and Social Media Streaming Data
Jun 01, 2022

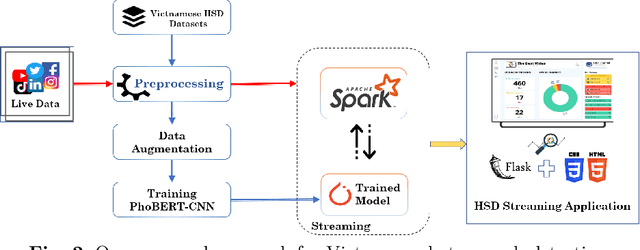

Society needs to develop a system to detect hate and offense to build a healthy and safe environment. However, current research in this field still faces four major shortcomings, including deficient pre-processing techniques, indifference to data imbalance issues, modest performance models, and lacking practical applications. This paper focused on developing an intelligent system capable of addressing these shortcomings. Firstly, we proposed an efficient pre-processing technique to clean comments collected from Vietnamese social media. Secondly, a novel hate speech detection (HSD) model, which is the combination of a pre-trained PhoBERT model and a Text-CNN model, was proposed for solving tasks in Vietnamese. Thirdly, EDA techniques are applied to deal with imbalanced data to improve the performance of classification models. Besides, various experiments were conducted as baselines to compare and investigate the proposed model's performance against state-of-the-art methods. The experiment results show that the proposed PhoBERT-CNN model outperforms SOTA methods and achieves an F1-score of 67,46% and 98,45% on two benchmark datasets, ViHSD and HSD-VLSP, respectively. Finally, we also built a streaming HSD application to demonstrate the practicality of our proposed system.
Distinguishing Homophenes Using Multi-Head Visual-Audio Memory for Lip Reading
Apr 04, 2022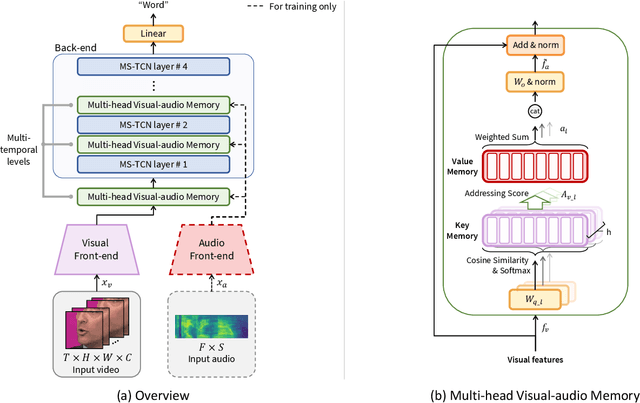
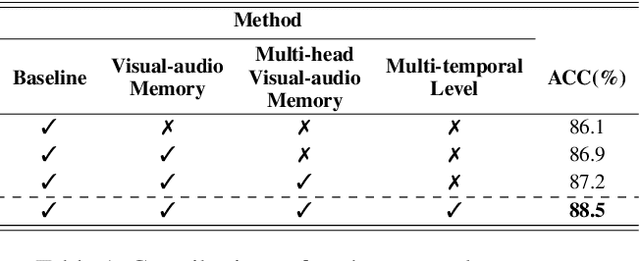
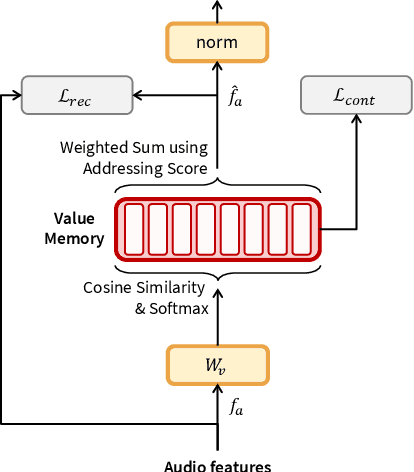

Recognizing speech from silent lip movement, which is called lip reading, is a challenging task due to 1) the inherent information insufficiency of lip movement to fully represent the speech, and 2) the existence of homophenes that have similar lip movement with different pronunciations. In this paper, we try to alleviate the aforementioned two challenges in lip reading by proposing a Multi-head Visual-audio Memory (MVM). Firstly, MVM is trained with audio-visual datasets and remembers audio representations by modelling the inter-relationships of paired audio-visual representations. At the inference stage, visual input alone can extract the saved audio representation from the memory by examining the learned inter-relationships. Therefore, the lip reading model can complement the insufficient visual information with the extracted audio representations. Secondly, MVM is composed of multi-head key memories for saving visual features and one value memory for saving audio knowledge, which is designed to distinguish the homophenes. With the multi-head key memories, MVM extracts possible candidate audio features from the memory, which allows the lip reading model to consider the possibility of which pronunciations can be represented from the input lip movement. This also can be viewed as an explicit implementation of the one-to-many mapping of viseme-to-phoneme. Moreover, MVM is employed in multi-temporal levels to consider the context when retrieving the memory and distinguish the homophenes. Extensive experimental results verify the effectiveness of the proposed method in lip reading and in distinguishing the homophenes.
Few-Shot Speaker Identification Using Depthwise Separable Convolutional Network with Channel Attention
Apr 24, 2022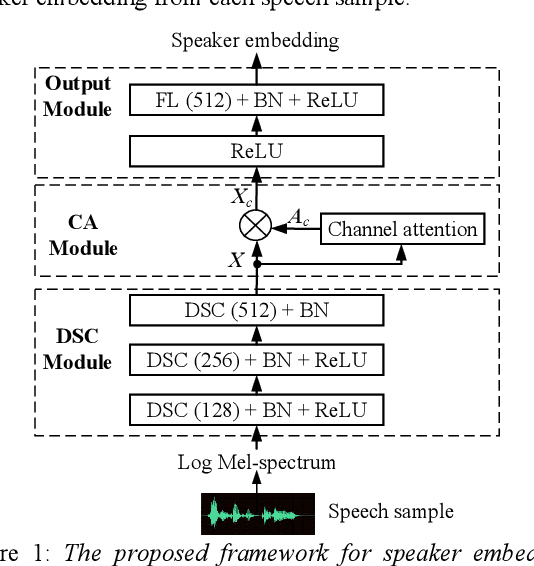
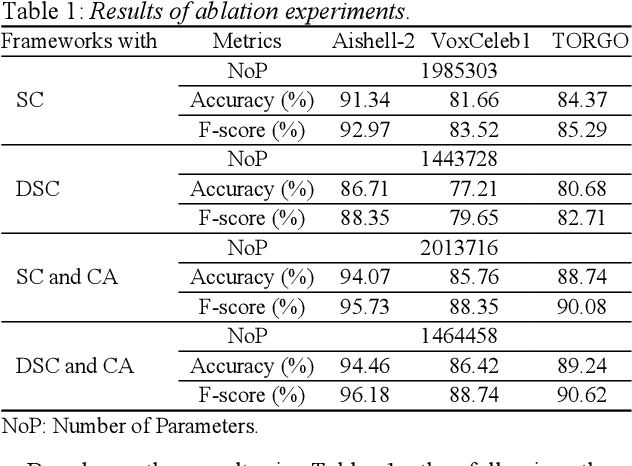
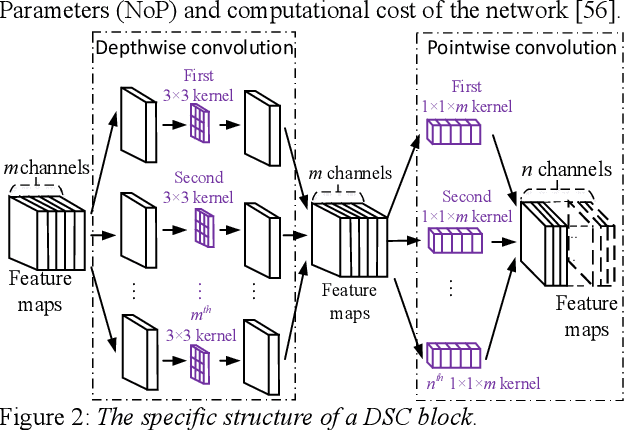
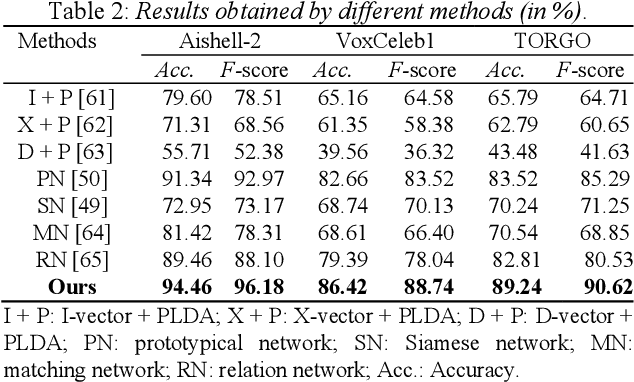
Although few-shot learning has attracted much attention from the fields of image and audio classification, few efforts have been made on few-shot speaker identification. In the task of few-shot learning, overfitting is a tough problem mainly due to the mismatch between training and testing conditions. In this paper, we propose a few-shot speaker identification method which can alleviate the overfitting problem. In the proposed method, the model of a depthwise separable convolutional network with channel attention is trained with a prototypical loss function. Experimental datasets are extracted from three public speech corpora: Aishell-2, VoxCeleb1 and TORGO. Experimental results show that the proposed method exceeds state-of-the-art methods for few-shot speaker identification in terms of accuracy and F-score.
Neural Architecture Search for Speech Recognition
Jul 17, 2020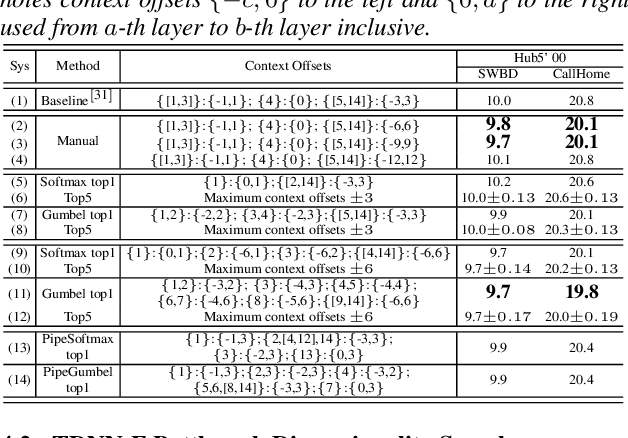
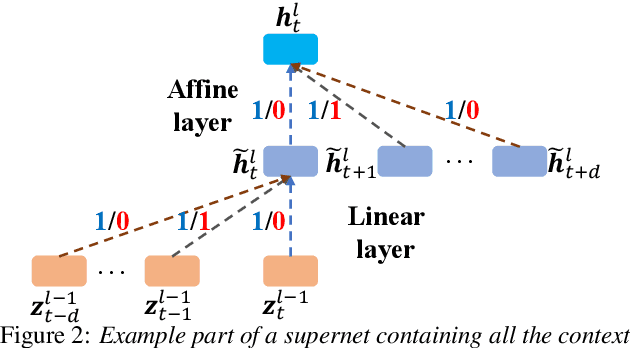
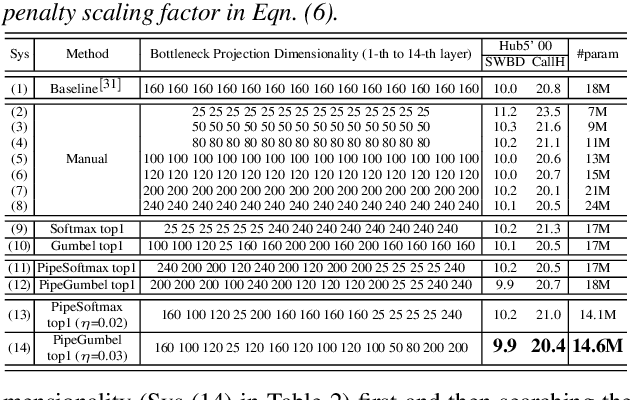
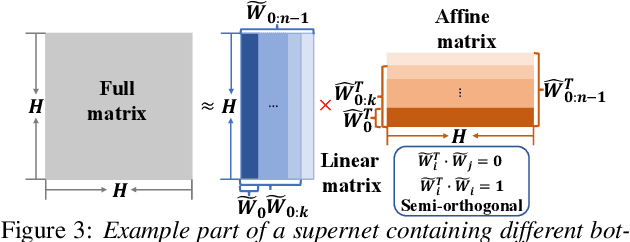
Deep neural networks (DNNs) based automatic speech recognition (ASR) systems are often designed using expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two hyper-parameters that heavily affect the performance and model complexity of state-of-the-art factored time delay neural network (TDNN-F) acoustic models: i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These include the standard DARTS method fully integrating the estimation of architecture weights and TDNN parameters in lattice-free MMI (LF-MMI) training; Gumbel-Softmax DARTS that reduces the confusion between candidate architectures; Pipelined DARTS that circumvents the overfitting of architecture weights using held-out data; and Penalized DARTS that further incorporates resource constraints to adjust the trade-off between performance and system complexity. Parameter sharing among candidate architectures was also used to facilitate efficient search over up to $7^{28}$ different TDNN systems. Experiments conducted on a 300-hour Switchboard conversational telephone speech recognition task suggest the NAS auto-configured TDNN-F systems consistently outperform the baseline LF-MMI trained TDNN-F systems using manual expert configurations. Absolute word error rate reductions up to 1.0% and relative model size reduction of 28% were obtained.