 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Post-Training Embedding Alignment for Decoupling Enrollment and Runtime Speaker Recognition Models
Jan 23, 2024
Automated speaker identification (SID) is a crucial step for the personalization of a wide range of speech-enabled services. Typical SID systems use a symmetric enrollment-verification framework with a single model to derive embeddings both offline for voice profiles extracted from enrollment utterances, and online from runtime utterances. Due to the distinct circumstances of enrollment and runtime, such as different computation and latency constraints, several applications would benefit from an asymmetric enrollment-verification framework that uses different models for enrollment and runtime embedding generation. To support this asymmetric SID where each of the two models can be updated independently, we propose using a lightweight neural network to map the embeddings from the two independent models to a shared speaker embedding space. Our results show that this approach significantly outperforms cosine scoring in a shared speaker logit space for models that were trained with a contrastive loss on large datasets with many speaker identities. This proposed Neural Embedding Speaker Space Alignment (NESSA) combined with an asymmetric update of only one of the models delivers at least 60% of the performance gain achieved by updating both models in the standard symmetric SID approach.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages
Enhancement of a Text-Independent Speaker Verification System by using Feature Combination and Parallel-Structure Classifiers
Jan 26, 2024Speaker Verification (SV) systems involve mainly two individual stages: feature extraction and classification. In this paper, we explore these two modules with the aim of improving the performance of a speaker verification system under noisy conditions. On the one hand, the choice of the most appropriate acoustic features is a crucial factor for performing robust speaker verification. The acoustic parameters used in the proposed system are: Mel Frequency Cepstral Coefficients (MFCC), their first and second derivatives (Deltas and Delta- Deltas), Bark Frequency Cepstral Coefficients (BFCC), Perceptual Linear Predictive (PLP), and Relative Spectral Transform - Perceptual Linear Predictive (RASTA-PLP). In this paper, a complete comparison of different combinations of the previous features is discussed. On the other hand, the major weakness of a conventional Support Vector Machine (SVM) classifier is the use of generic traditional kernel functions to compute the distances among data points. However, the kernel function of an SVM has great influence on its performance. In this work, we propose the combination of two SVM-based classifiers with different kernel functions: Linear kernel and Gaussian Radial Basis Function (RBF) kernel with a Logistic Regression (LR) classifier. The combination is carried out by means of a parallel structure approach, in which different voting rules to take the final decision are considered. Results show that significant improvement in the performance of the SV system is achieved by using the combined features with the combined classifiers either with clean speech or in the presence of noise. Finally, to enhance the system more in noisy environments, the inclusion of the multiband noise removal technique as a preprocessing stage is proposed.
Distributed Speech Dereverberation Using Weighted Prediction Error
Dec 05, 2023Speech dereverberation aims to alleviate the negative impact of late reverberant reflections. The weighted prediction error (WPE) method is a well-established technique known for its superior performance in dereverberation. However, in scenarios where microphone nodes are dispersed, the centralized approach of the WPE method requires aggregating all observations for inverse filtering, resulting in a significant computational burden. This paper introduces a distributed speech dereverberation method that emphasizes low computational complexity at each node. Specifically, we leverage the distributed adaptive node-specific signal estimation (DANSE) algorithm within the multichannel linear prediction (MCLP) process. This approach empowers each node to perform local operations with reduced complexity while achieving the global performance through inter-node cooperation. Experimental results validate the effectiveness of our proposed method, showcasing its ability to achieve efficient speech dereverberation in dispersed microphone node scenarios.
Ultra-lightweight Neural Differential DSP Vocoder For High Quality Speech Synthesis
Jan 19, 2024Neural vocoders model the raw audio waveform and synthesize high-quality audio, but even the highly efficient ones, like MB-MelGAN and LPCNet, fail to run real-time on a low-end device like a smartglass. A pure digital signal processing (DSP) based vocoder can be implemented via lightweight fast Fourier transforms (FFT), and therefore, is a magnitude faster than any neural vocoder. A DSP vocoder often gets a lower audio quality due to consuming over-smoothed acoustic model predictions of approximate representations for the vocal tract. In this paper, we propose an ultra-lightweight differential DSP (DDSP) vocoder that uses a jointly optimized acoustic model with a DSP vocoder, and learns without an extracted spectral feature for the vocal tract. The model achieves audio quality comparable to neural vocoders with a high average MOS of 4.36 while being efficient as a DSP vocoder. Our C++ implementation, without any hardware-specific optimization, is at 15 MFLOPS, surpasses MB-MelGAN by 340 times in terms of FLOPS, and achieves a vocoder-only RTF of 0.003 and overall RTF of 0.044 while running single-threaded on a 2GHz Intel Xeon CPU.
Deep Photonic Reservoir Computer for Speech Recognition
Dec 11, 2023Speech recognition is a critical task in the field of artificial intelligence and has witnessed remarkable advancements thanks to large and complex neural networks, whose training process typically requires massive amounts of labeled data and computationally intensive operations. An alternative paradigm, reservoir computing, is energy efficient and is well adapted to implementation in physical substrates, but exhibits limitations in performance when compared to more resource-intensive machine learning algorithms. In this work we address this challenge by investigating different architectures of interconnected reservoirs, all falling under the umbrella of deep reservoir computing. We propose a photonic-based deep reservoir computer and evaluate its effectiveness on different speech recognition tasks. We show specific design choices that aim to simplify the practical implementation of a reservoir computer while simultaneously achieving high-speed processing of high-dimensional audio signals. Overall, with the present work we hope to help the advancement of low-power and high-performance neuromorphic hardware.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023
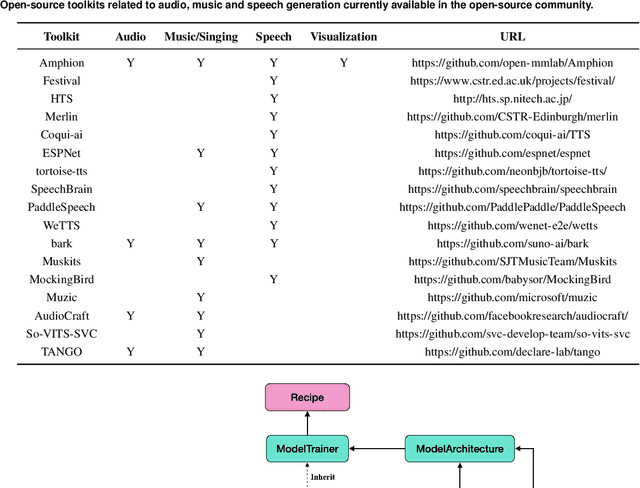
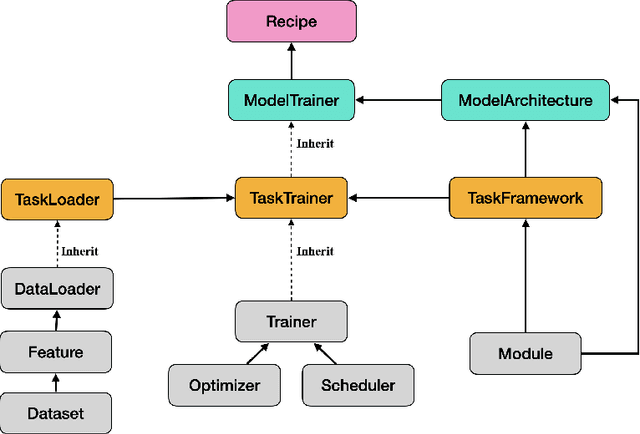
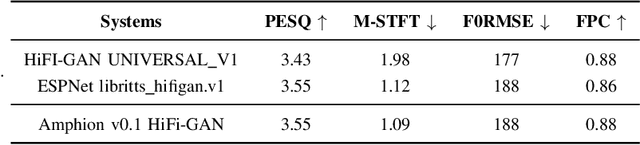
Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
StyleCap: Automatic Speaking-Style Captioning from Speech Based on Speech and Language Self-supervised Learning Models
Nov 28, 2023We propose StyleCap, a method to generate natural language descriptions of speaking styles appearing in speech. Although most of conventional techniques for para-/non-linguistic information recognition focus on the category classification or the intensity estimation of pre-defined labels, they cannot provide the reasoning of the recognition result in an interpretable manner. As a first step towards an end-to-end method for generating speaking-style prompts from speech, i.e., automatic speaking-style captioning, StyleCap uses paired data of speech and natural language descriptions to train neural networks that predict prefix vectors fed into a large language model (LLM)-based text decoder from a speech representation vector. We explore an appropriate text decoder and speech feature representation suitable for this new task. The experimental results demonstrate that our StyleCap leveraging richer LLMs for the text decoder, speech self-supervised learning (SSL) features, and sentence rephrasing augmentation improves the accuracy and diversity of generated speaking-style captions. Samples of speaking-style captions generated by our StyleCap are publicly available.
E-chat: Emotion-sensitive Spoken Dialogue System with Large Language Models
Jan 06, 2024This study focuses on emotion-sensitive spoken dialogue in human-machine speech interaction. With the advancement of Large Language Models (LLMs), dialogue systems can handle multimodal data, including audio. Recent models have enhanced the understanding of complex audio signals through the integration of various audio events. However, they are unable to generate appropriate responses based on emotional speech. To address this, we introduce the Emotional chat Model (E-chat), a novel spoken dialogue system capable of comprehending and responding to emotions conveyed from speech. This model leverages an emotion embedding extracted by a speech encoder, combined with LLMs, enabling it to respond according to different emotional contexts. Additionally, we introduce the E-chat200 dataset, designed explicitly for emotion-sensitive spoken dialogue. In various evaluation metrics, E-chat consistently outperforms baseline LLMs, demonstrating its potential in emotional comprehension and human-machine interaction.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.