 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Neural Architecture Search for Speech Recognition
Jul 17, 2020
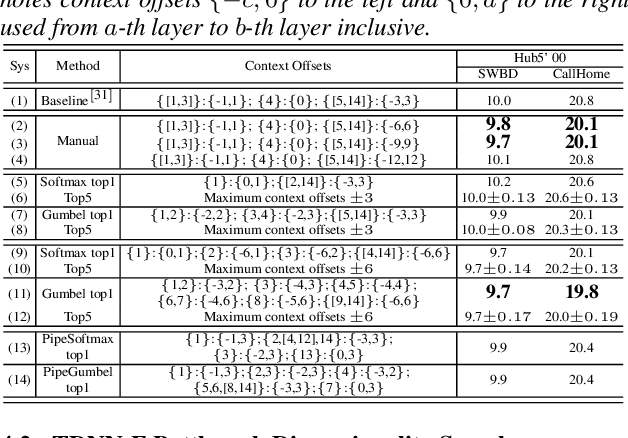
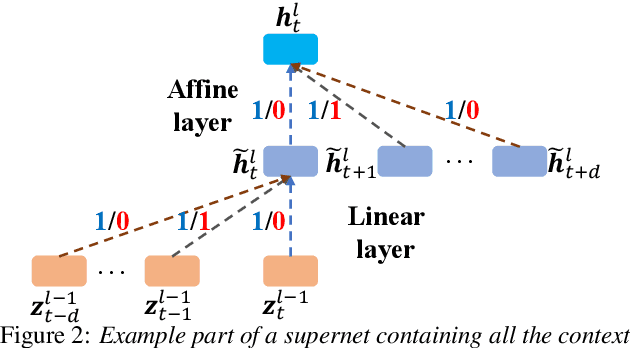
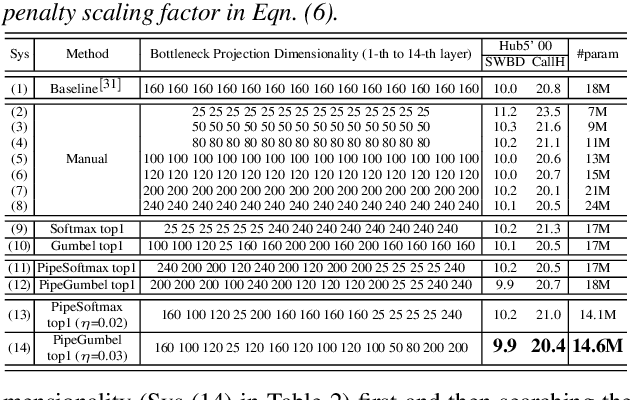
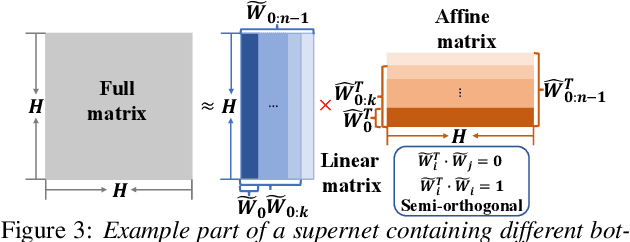
Deep neural networks (DNNs) based automatic speech recognition (ASR) systems are often designed using expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two hyper-parameters that heavily affect the performance and model complexity of state-of-the-art factored time delay neural network (TDNN-F) acoustic models: i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These include the standard DARTS method fully integrating the estimation of architecture weights and TDNN parameters in lattice-free MMI (LF-MMI) training; Gumbel-Softmax DARTS that reduces the confusion between candidate architectures; Pipelined DARTS that circumvents the overfitting of architecture weights using held-out data; and Penalized DARTS that further incorporates resource constraints to adjust the trade-off between performance and system complexity. Parameter sharing among candidate architectures was also used to facilitate efficient search over up to $7^{28}$ different TDNN systems. Experiments conducted on a 300-hour Switchboard conversational telephone speech recognition task suggest the NAS auto-configured TDNN-F systems consistently outperform the baseline LF-MMI trained TDNN-F systems using manual expert configurations. Absolute word error rate reductions up to 1.0% and relative model size reduction of 28% were obtained.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jun 18, 2021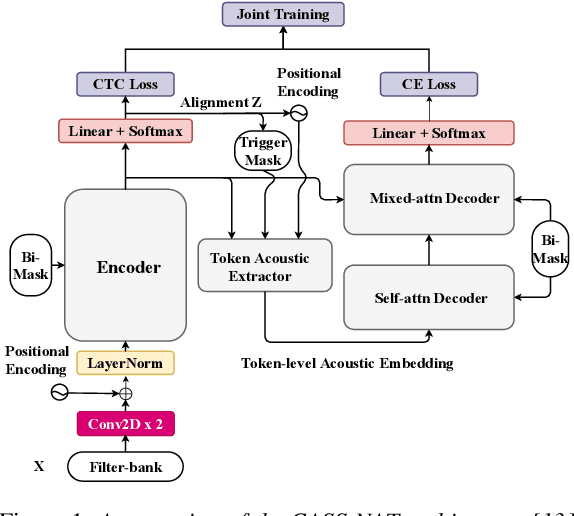
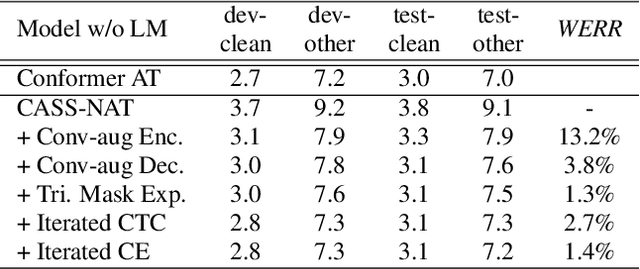
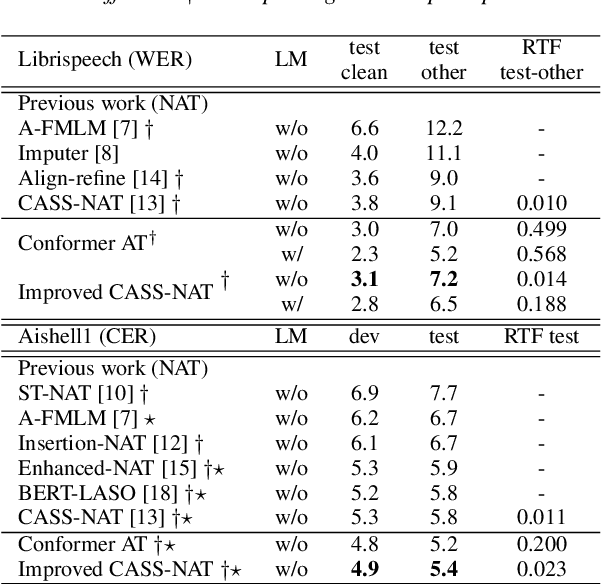
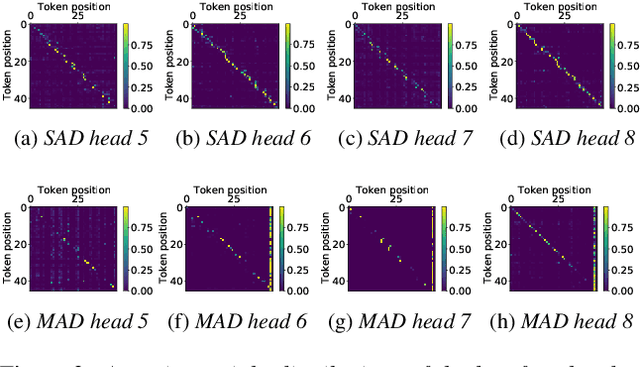
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
The Open corpus of the Veps and Karelian languages: overview and applications
Jun 08, 2022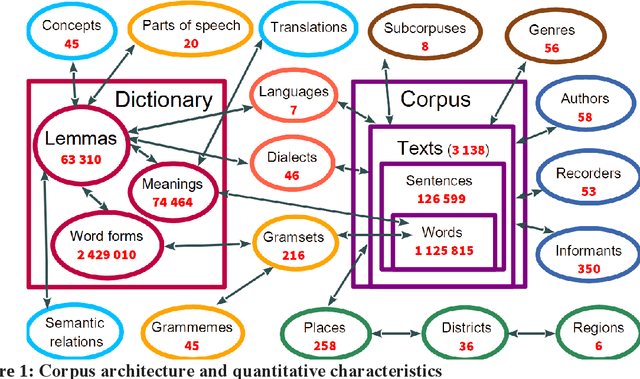
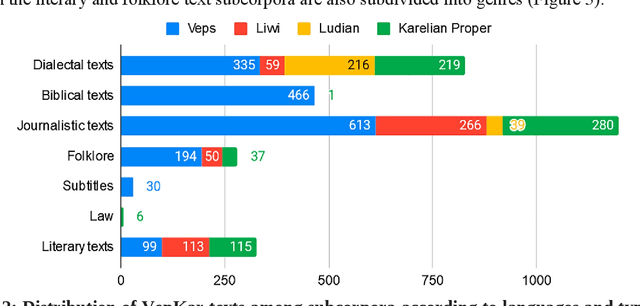
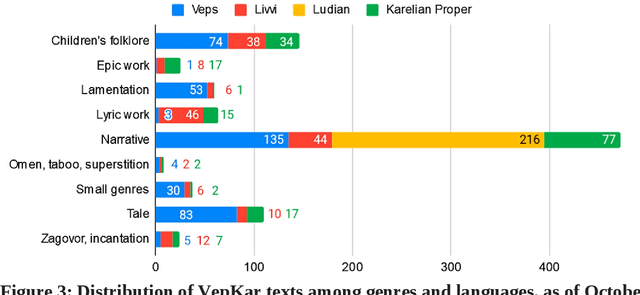
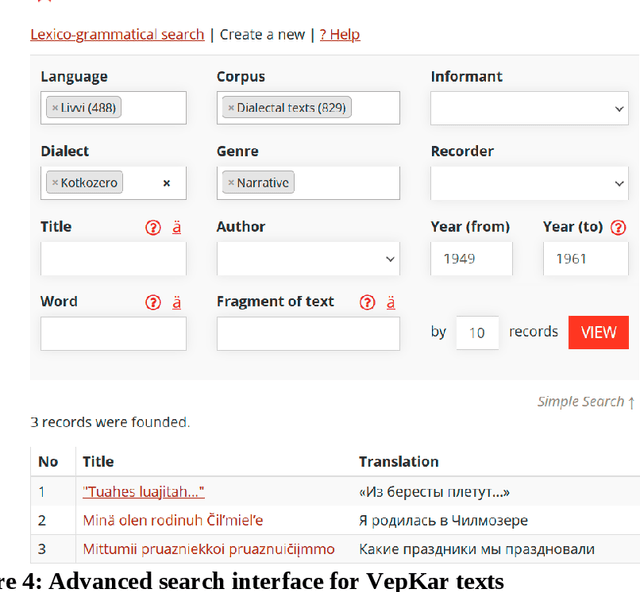
A growing priority in the study of Baltic-Finnic languages of the Republic of Karelia has been the methods and tools of corpus linguistics. Since 2016, linguists, mathematicians, and programmers at the Karelian Research Centre have been working with the Open Corpus of the Veps and Karelian Languages (VepKar), which is an extension of the Veps Corpus created in 2009. The VepKar corpus comprises texts in Karelian and Veps, multifunctional dictionaries linked to them, and software with an advanced system of search using various criteria of the texts (language, genre, etc.) and numerous linguistic categories (lexical and grammatical search in texts was implemented thanks to the generator of word forms that we created earlier). A corpus of 3000 texts was compiled, texts were uploaded and marked up, the system for classifying texts into languages, dialects, types and genres was introduced, and the word-form generator was created. Future plans include developing a speech module for working with audio recordings and a syntactic tagging module using morphological analysis outputs. Owing to continuous functional advancements in the corpus manager and ongoing VepKar enrichment with new material and text markup, users can handle a wide range of scientific and applied tasks. In creating the universal national VepKar corpus, its developers and managers strive to preserve and exhibit as fully as possible the state of the Veps and Karelian languages in the 19th-21st centuries.
* 9 pages, 9 figures, published in the journal
Deep representation of EEG data from Spatio-Spectral Feature Images
Jun 20, 2022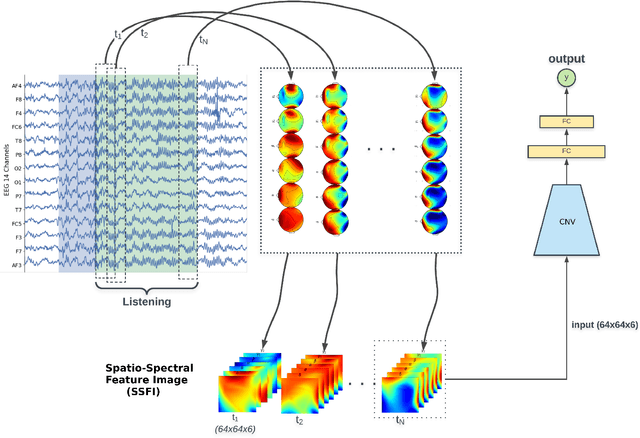
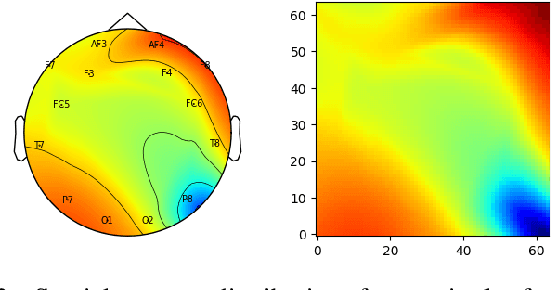
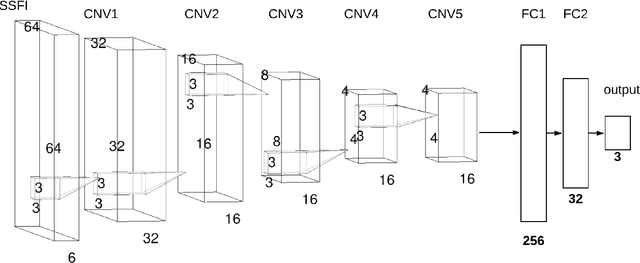
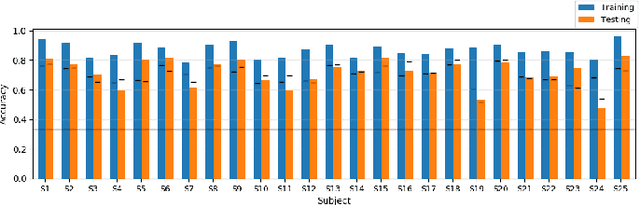
Unlike conventional data such as natural images, audio and speech, raw multi-channel Electroencephalogram (EEG) data are difficult to interpret. Modern deep neural networks have shown promising results in EEG studies, however finding robust invariant representations of EEG data across subjects remains a challenge, due to differences in brain folding structures. Thus, invariant representations of EEG data would be desirable to improve our understanding of the brain activity and to use them effectively during transfer learning. In this paper, we propose an approach to learn deep representations of EEG data by exploiting spatial relationships between recording electrodes and encoding them in a Spatio-Spectral Feature Images. We use multi-channel EEG signals from the PhyAAt dataset for auditory tasks and train a Convolutional Neural Network (CNN) on 25 subjects individually. Afterwards, we generate the input patterns that activate deep neurons across all the subjects. The generated pattern can be seen as a map of the brain activity in different spatial regions. Our analysis reveals the existence of specific brain regions related to different tasks. Low-level features focusing on larger regions and high-level features focusing on a smaller and very specific cluster of regions are also identified. Interestingly, similar patterns are found across different subjects although the activities appear in different regions. Our analysis also reveals common brain regions across subjects, which can be used as generalized representations. Our proposed approach allows us to find more interpretable representations of EEG data, which can further be used for effective transfer learning.
Word Segmentation on Discovered Phone Units with Dynamic Programming and Self-Supervised Scoring
Feb 24, 2022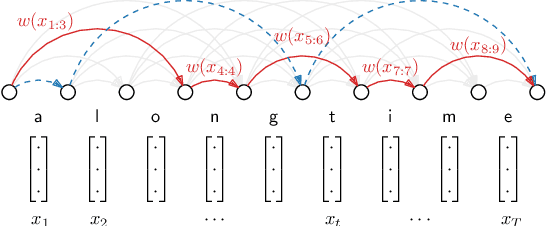
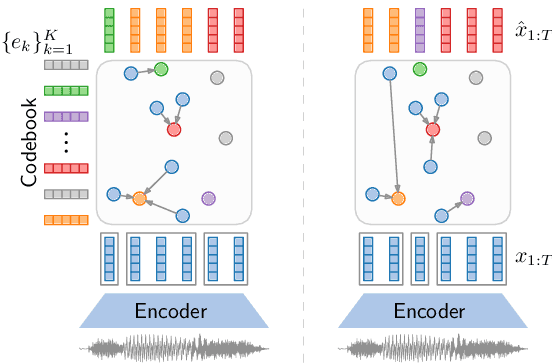
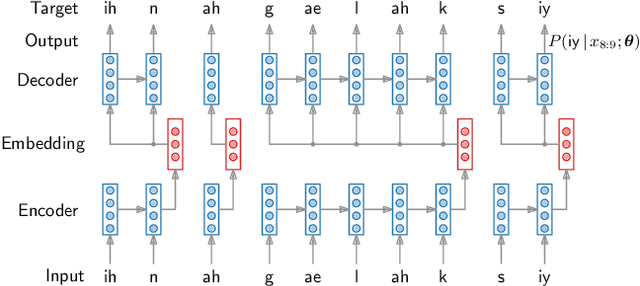
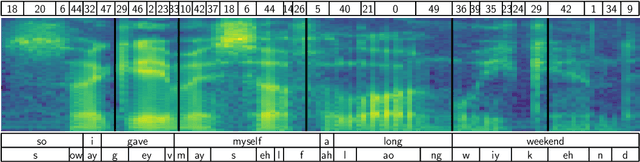
Recent work on unsupervised speech segmentation has used self-supervised models with a phone segmentation module and a word segmentation module that are trained jointly. This paper compares this joint methodology with an older idea: bottom-up phone-like unit discovery is performed first, and symbolic word segmentation is then performed on top of the discovered units (without influencing the lower level). I specifically describe a duration-penalized dynamic programming (DPDP) procedure that can be used for either phone or word segmentation by changing the self-supervised scoring network that gives segment costs. For phone discovery, DPDP is applied with a contrastive predictive coding clustering model, while for word segmentation it is used with an autoencoding recurrent neural network. The two models are chained in order to segment speech. This approach gives comparable word segmentation results to state-of-the-art joint self-supervised models on an English benchmark. On French and Mandarin data, it outperforms previous systems on the ZeroSpeech benchmarks. Analysis shows that the chained DPDP system segments shorter filler words well, but longer words might require an external top-down signal.
Towards Fluent Translations from Disfluent Speech
Nov 07, 2018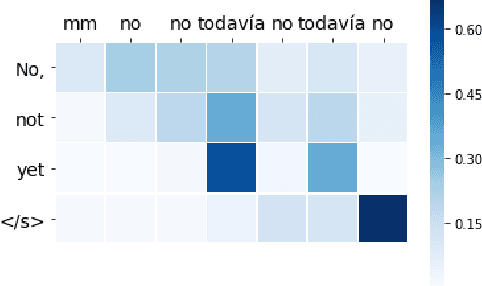
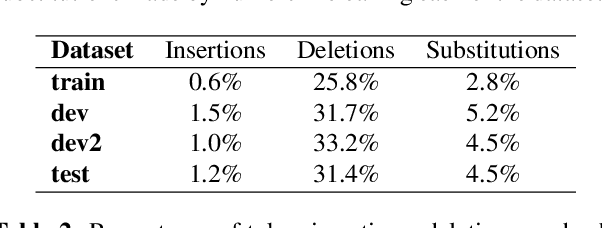
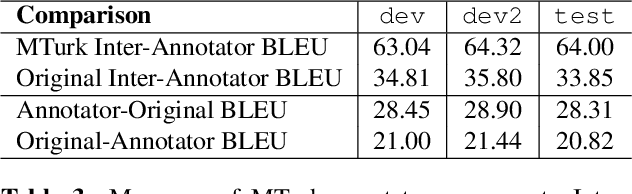
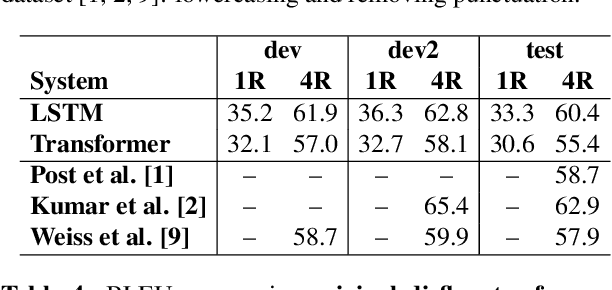
When translating from speech, special consideration for conversational speech phenomena such as disfluencies is necessary. Most machine translation training data consists of well-formed written texts, causing issues when translating spontaneous speech. Previous work has introduced an intermediate step between speech recognition (ASR) and machine translation (MT) to remove disfluencies, making the data better-matched to typical translation text and significantly improving performance. However, with the rise of end-to-end speech translation systems, this intermediate step must be incorporated into the sequence-to-sequence architecture. Further, though translated speech datasets exist, they are typically news or rehearsed speech without many disfluencies (e.g. TED), or the disfluencies are translated into the references (e.g. Fisher). To generate clean translations from disfluent speech, cleaned references are necessary for evaluation. We introduce a corpus of cleaned target data for the Fisher Spanish-English dataset for this task. We compare how different architectures handle disfluencies and provide a baseline for removing disfluencies in end-to-end translation.
Low-activity supervised convolutional spiking neural networks applied to speech commands recognition
Nov 13, 2020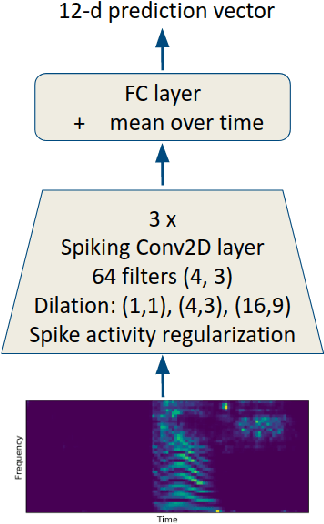
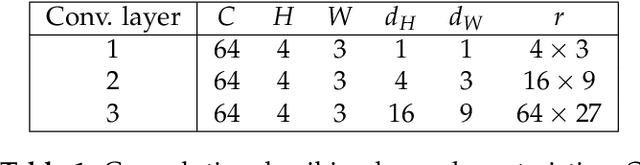

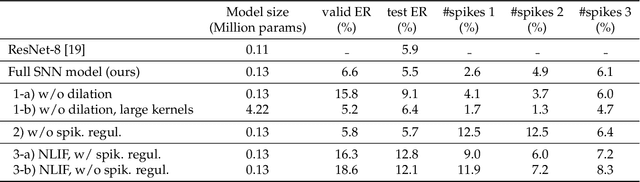
Deep Neural Networks (DNNs) are the current state-of-the-art models in many speech related tasks. There is a growing interest, though, for more biologically realistic, hardware friendly and energy efficient models, named Spiking Neural Networks (SNNs). Recently, it has been shown that SNNs can be trained efficiently, in a supervised manner, using backpropagation with a surrogate gradient trick. In this work, we report speech command (SC) recognition experiments using supervised SNNs. We explored the Leaky-Integrate-Fire (LIF) neuron model for this task, and show that a model comprised of stacked dilated convolution spiking layers can reach an error rate very close to standard DNNs on the Google SC v1 dataset: 5.5%, while keeping a very sparse spiking activity, below 5%, thank to a new regularization term. We also show that modeling the leakage of the neuron membrane potential is useful, since the LIF model outperformed its non-leaky model counterpart significantly.
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022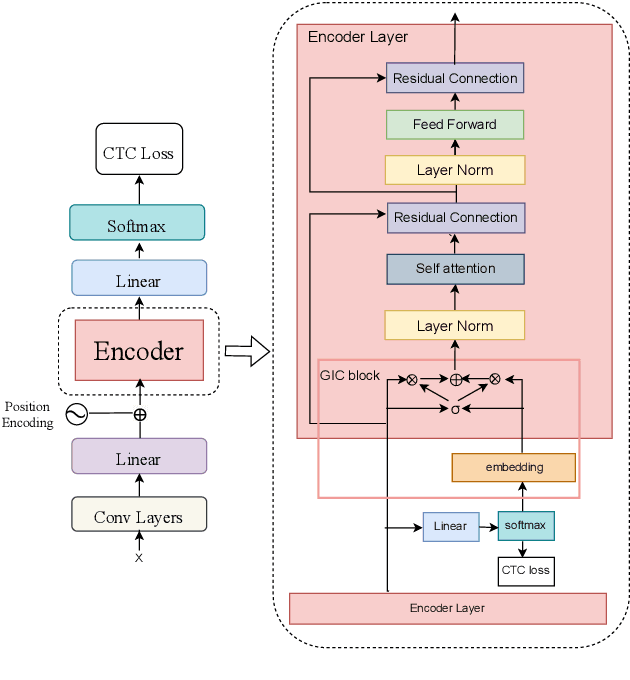
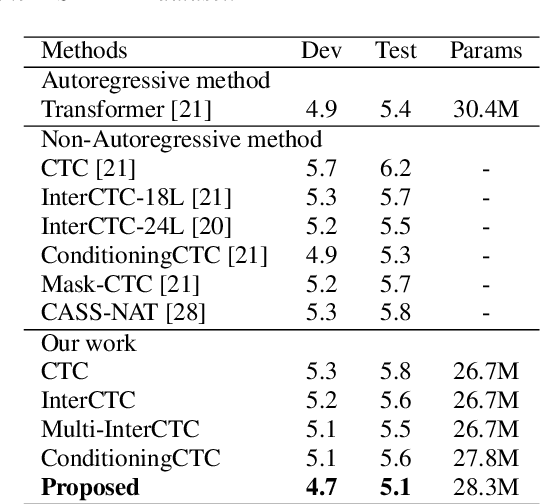
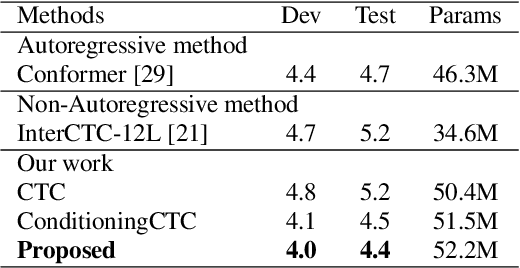
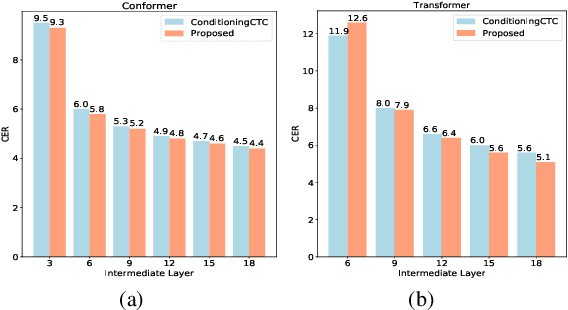
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.
Robust Stuttering Detection via Multi-task and Adversarial Learning
Apr 04, 2022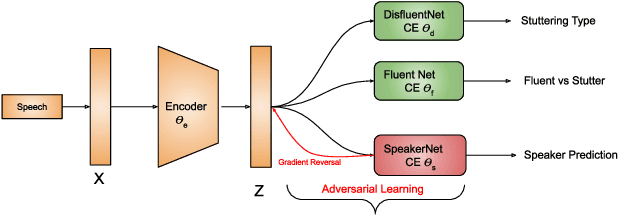
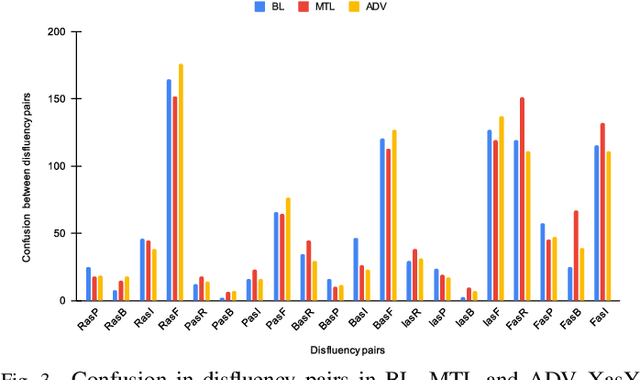
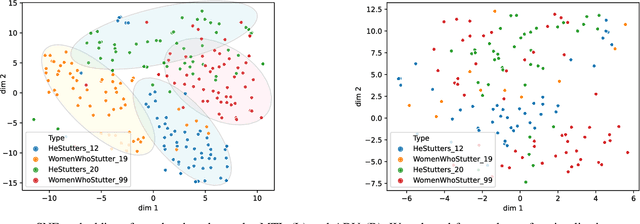
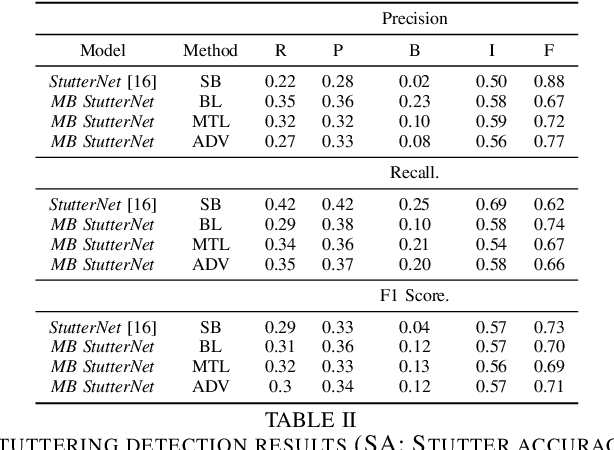
By automatic detection and identification of stuttering, speech pathologists can track the progression of disfluencies of persons who stutter (PWS). In this paper, we investigate the impact of multi-task (MTL) and adversarial learning (ADV) to learn robust stutter features. This is the first-ever preliminary study where MTL and ADV have been employed in stuttering identification (SI). We evaluate our system on the SEP-28k stuttering dataset consisting of 20 hours (approx) of data from 385 podcasts. Our methods show promising results and outperform the baseline in various disfluency classes. We achieve up to 10%, 6.78%, and 2% improvement in repetitions, blocks, and interjections respectively over the baseline.
Two-Pass End-to-End ASR Model Compression
Jan 08, 2022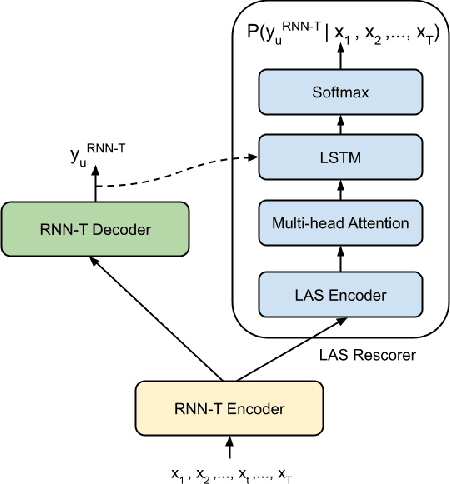

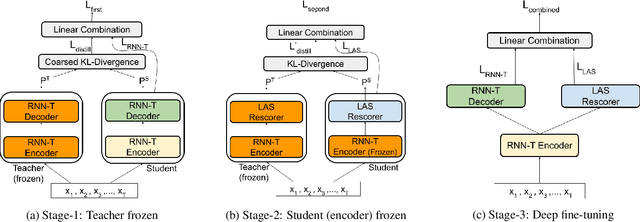
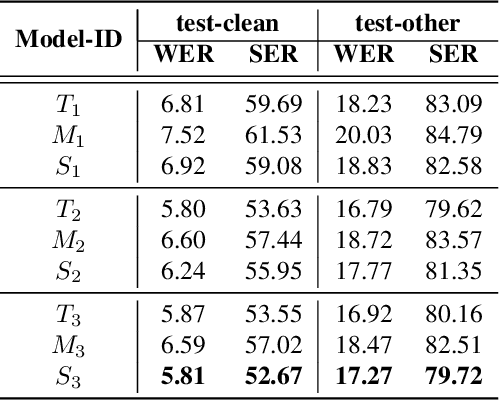
Speech recognition on smart devices is challenging owing to the small memory footprint. Hence small size ASR models are desirable. With the use of popular transducer-based models, it has become possible to practically deploy streaming speech recognition models on small devices [1]. Recently, the two-pass model [2] combining RNN-T and LAS modules has shown exceptional performance for streaming on-device speech recognition. In this work, we propose a simple and effective approach to reduce the size of the two-pass model for memory-constrained devices. We employ a popular knowledge distillation approach in three stages using the Teacher-Student training technique. In the first stage, we use a trained RNN-T model as a teacher model and perform knowledge distillation to train the student RNN-T model. The second stage uses the shared encoder and trains a LAS rescorer for student model using the trained RNN-T+LAS teacher model. Finally, we perform deep-finetuning for the student model with a shared RNN-T encoder, RNN-T decoder, and LAS rescorer. Our experimental results on standard LibriSpeech dataset show that our system can achieve a high compression rate of 55% without significant degradation in the WER compared to the two-pass teacher model.