 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PriMock57: A Dataset Of Primary Care Mock Consultations
Apr 01, 2022
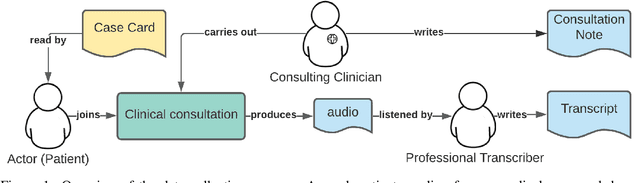
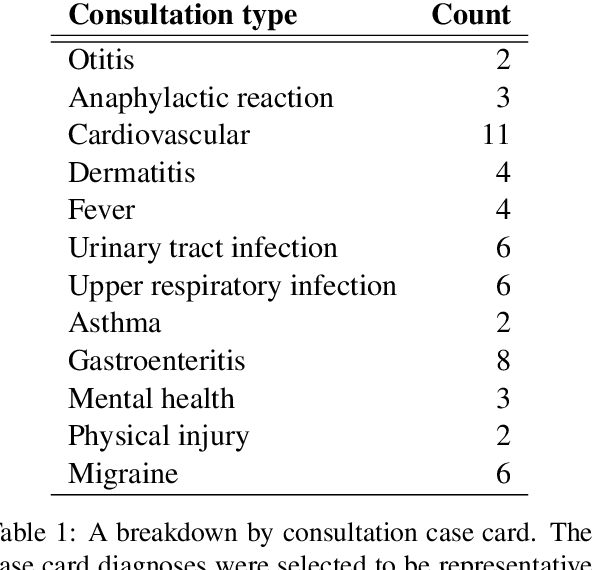

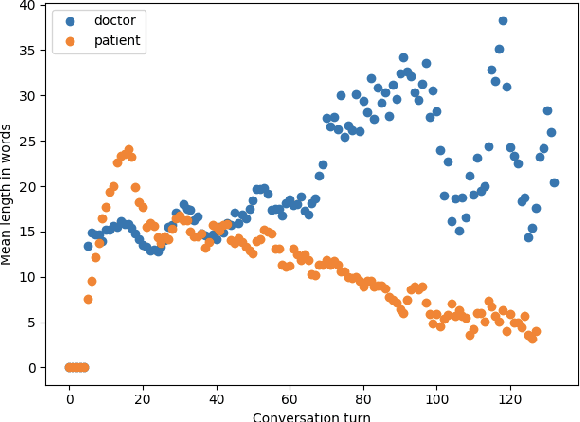
Recent advances in Automatic Speech Recognition (ASR) have made it possible to reliably produce automatic transcripts of clinician-patient conversations. However, access to clinical datasets is heavily restricted due to patient privacy, thus slowing down normal research practices. We detail the development of a public access, high quality dataset comprising of57 mocked primary care consultations, including audio recordings, their manual utterance-level transcriptions, and the associated consultation notes. Our work illustrates how the dataset can be used as a benchmark for conversational medical ASR as well as consultation note generation from transcripts.
Neural Architecture Search for Speech Recognition
Jul 27, 2020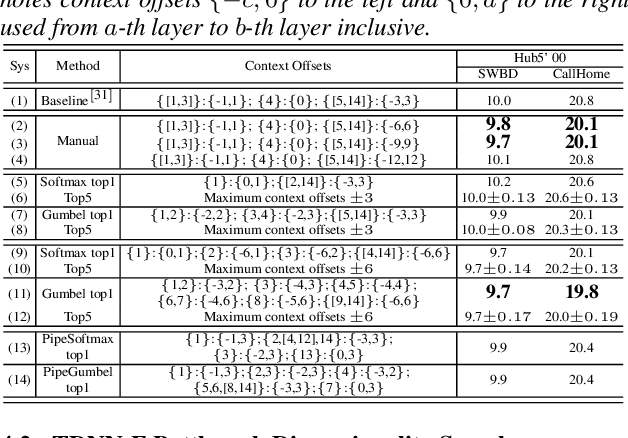
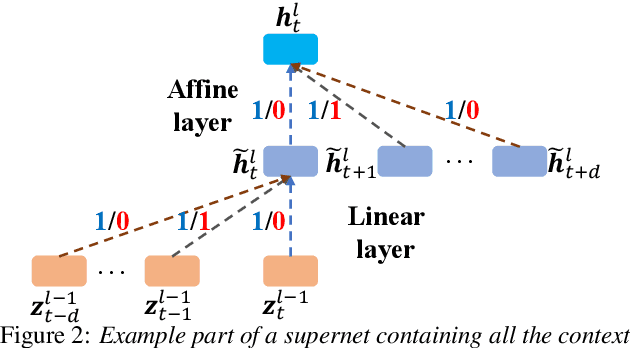
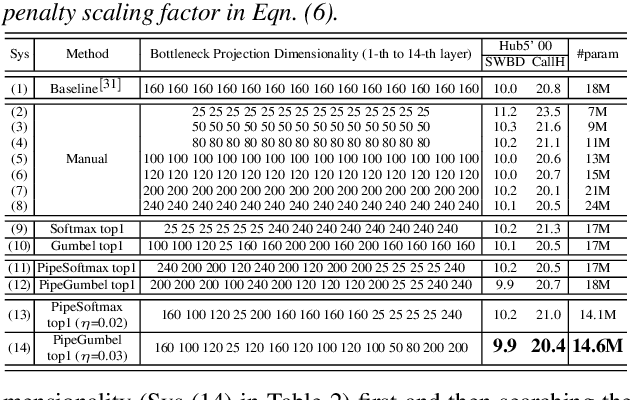
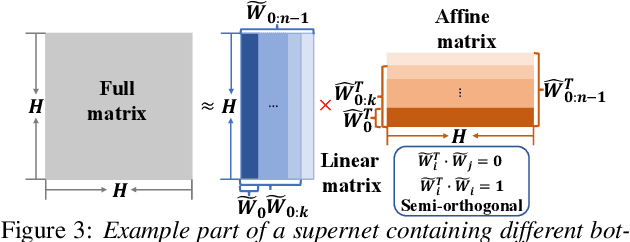
Deep neural networks (DNNs) based automatic speech recognition (ASR) systems are often designed using expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two hyper-parameters that heavily affect the performance and model complexity of state-of-the-art factored time delay neural network (TDNN-F) acoustic models: i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These include the standard DARTS method fully integrating the estimation of architecture weights and TDNN parameters in lattice-free MMI (LF-MMI) training; Gumbel-Softmax DARTS that reduces the confusion between candidate architectures; Pipelined DARTS that circumvents the overfitting of architecture weights using held-out data; and Penalized DARTS that further incorporates resource constraints to adjust the trade-off between performance and system complexity. Parameter sharing among candidate architectures was also used to facilitate efficient search over up to $7^{28}$ different TDNN systems. Experiments conducted on a 300-hour Switchboard conversational telephone speech recognition task suggest the NAS auto-configured TDNN-F systems consistently outperform the baseline LF-MMI trained TDNN-F systems using manual expert configurations. Absolute word error rate reductions up to 1.0% and relative model size reduction of 28% were obtained.
Investigating Brain Connectivity with Graph Neural Networks and GNNExplainer
Jun 04, 2022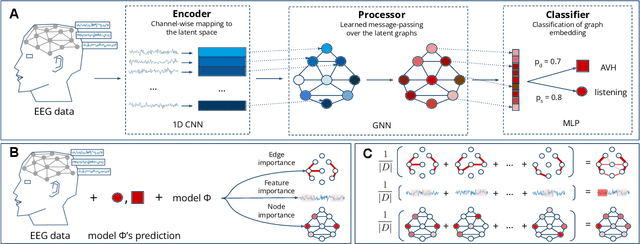
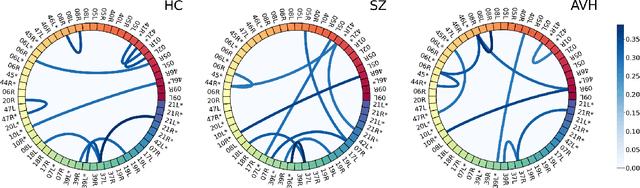
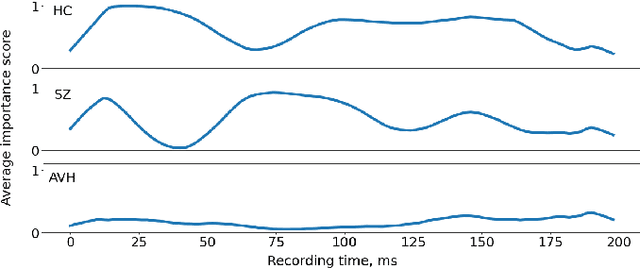
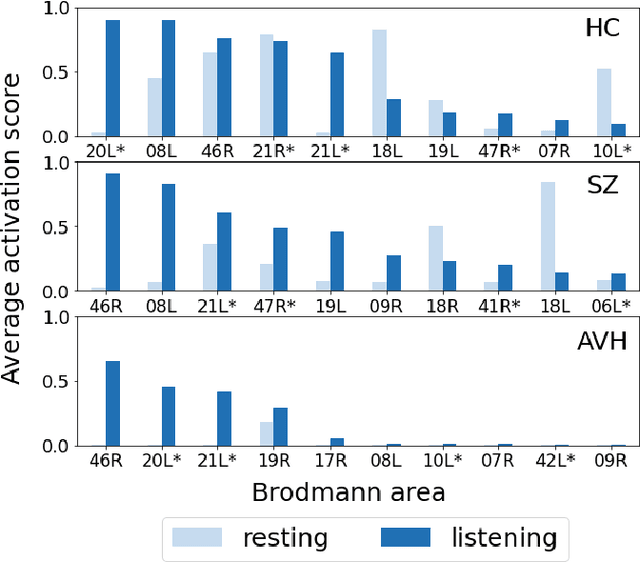
Functional connectivity plays an essential role in modern neuroscience. The modality sheds light on the brain's functional and structural aspects, including mechanisms behind multiple pathologies. One such pathology is schizophrenia which is often followed by auditory verbal hallucinations. The latter is commonly studied by observing functional connectivity during speech processing. In this work, we have made a step toward an in-depth examination of functional connectivity during a dichotic listening task via deep learning for three groups of people: schizophrenia patients with and without auditory verbal hallucinations and healthy controls. We propose a graph neural network-based framework within which we represent EEG data as signals in the graph domain. The framework allows one to 1) predict a brain mental disorder based on EEG recording, 2) differentiate the listening state from the resting state for each group and 3) recognize characteristic task-depending connectivity. Experimental results show that the proposed model can differentiate between the above groups with state-of-the-art performance. Besides, it provides a researcher with meaningful information regarding each group's functional connectivity, which we validated on the current domain knowledge.
Deep Neural Networks for Automatic Speech Processing: A Survey from Large Corpora to Limited Data
Mar 09, 2020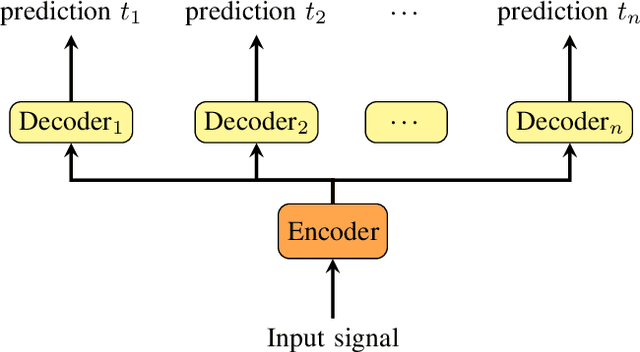
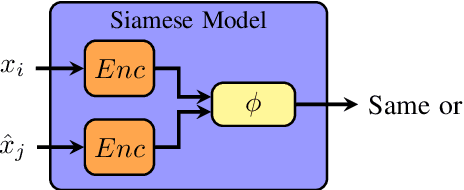
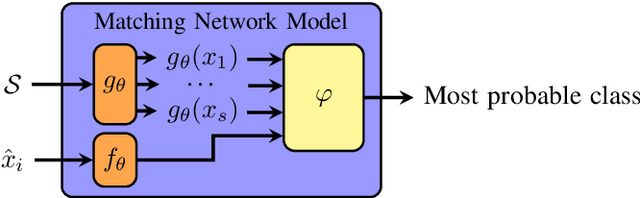
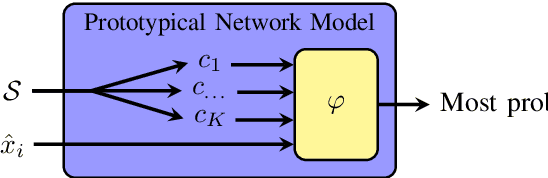
Most state-of-the-art speech systems are using Deep Neural Networks (DNNs). Those systems require a large amount of data to be learned. Hence, learning state-of-the-art frameworks on under-resourced speech languages/problems is a difficult task. Problems could be the limited amount of data for impaired speech. Furthermore, acquiring more data and/or expertise is time-consuming and expensive. In this paper we position ourselves for the following speech processing tasks: Automatic Speech Recognition, speaker identification and emotion recognition. To assess the problem of limited data, we firstly investigate state-of-the-art Automatic Speech Recognition systems as it represents the hardest tasks (due to the large variability in each language). Next, we provide an overview of techniques and tasks requiring fewer data. In the last section we investigate few-shot techniques as we interpret under-resourced speech as a few-shot problem. In that sense we propose an overview of few-shot techniques and perspectives of using such techniques for the focused speech problems in this survey. It occurs that the reviewed techniques are not well adapted for large datasets. Nevertheless, some promising results from the literature encourage the usage of such techniques for speech processing.
Improving EEG based Continuous Speech Recognition
Dec 15, 2019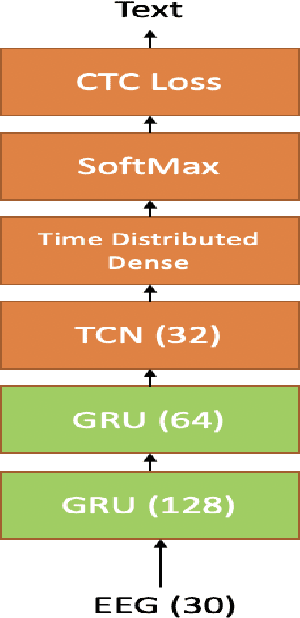
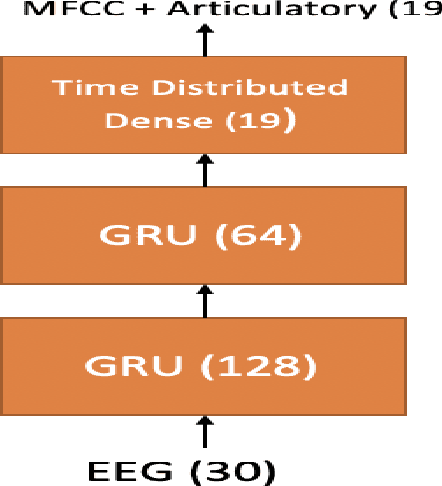
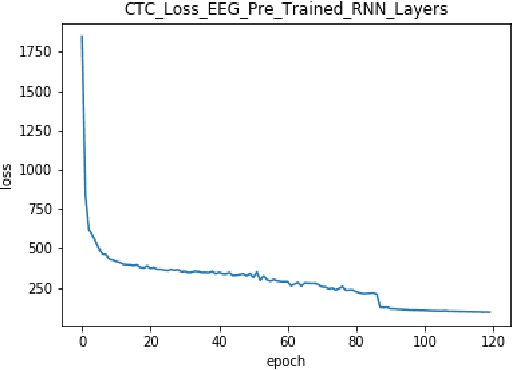
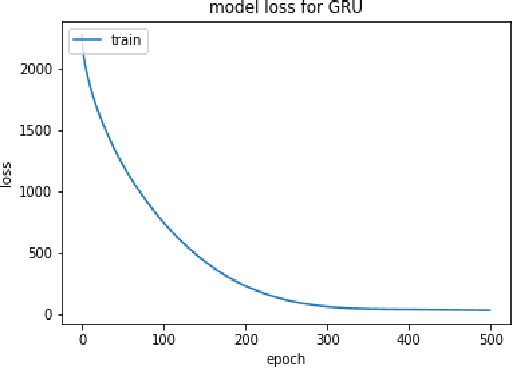
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Breaking Speech Recognizers to Imagine Lyrics
Dec 15, 2019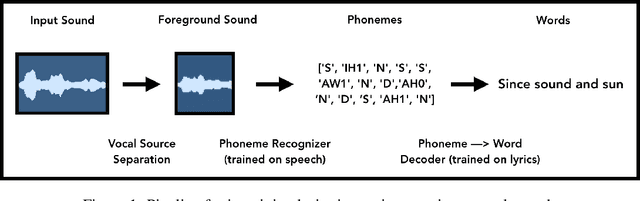

We introduce a new method for generating text, and in particular song lyrics, based on the speech-like acoustic qualities of a given audio file. We repurpose a vocal source separation algorithm and an acoustic model trained to recognize isolated speech, instead inputting instrumental music or environmental sounds. Feeding the "mistakes" of the vocal separator into the recognizer, we obtain a transcription of words \emph{imagined} to be spoken in the input audio. We describe the key components of our approach, present initial analysis, and discuss the potential of the method for machine-in-the-loop collaboration in creative applications.
* 3 pages
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021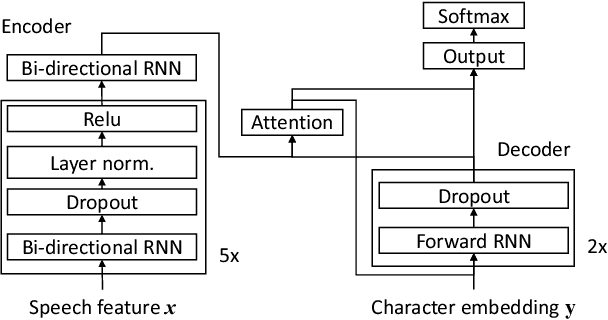
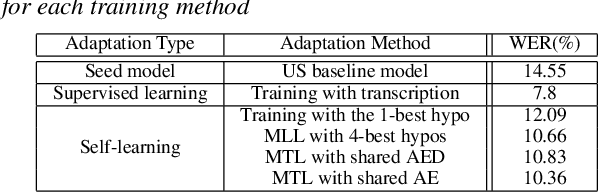
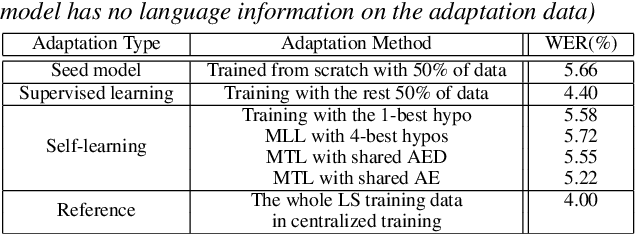
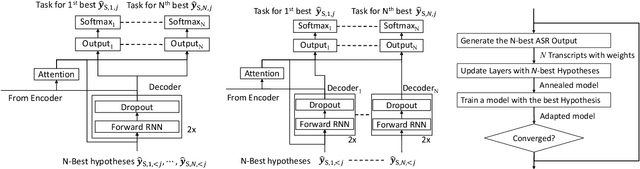
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
How do Voices from Past Speech Synthesis Challenges Compare Today?
May 05, 2021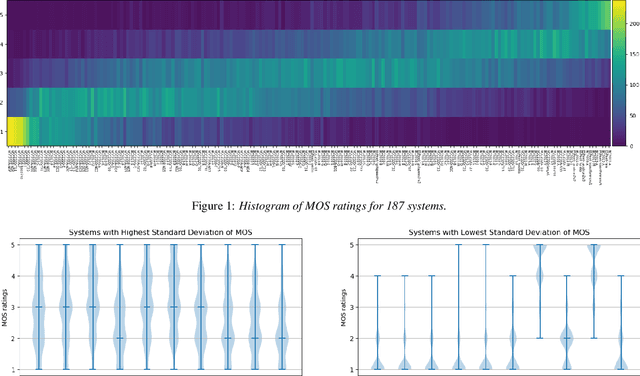
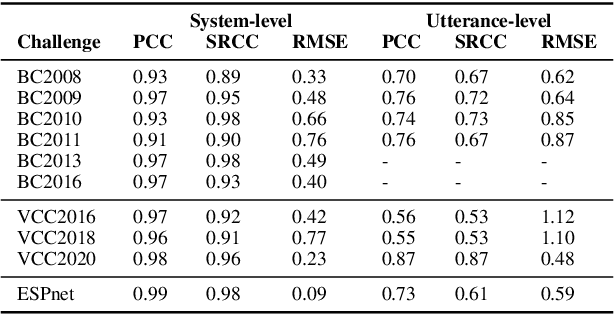

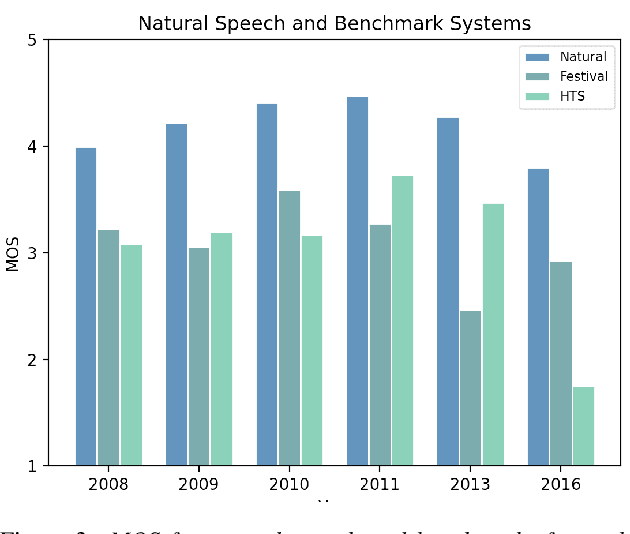
Shared challenges provide a venue for comparing systems trained on common data using a standardized evaluation, and they also provide an invaluable resource for researchers when the data and evaluation results are publicly released. The Blizzard Challenge and Voice Conversion Challenge are two such challenges for text-to-speech synthesis and for speaker conversion, respectively, and their publicly-available system samples and listening test results comprise a historical record of state-of-the-art synthesis methods over the years. In this paper, we revisit these past challenges and conduct a large-scale listening test with samples from many challenges combined. Our aims are to analyze and compare opinions of a large number of systems together, to determine whether and how opinions change over time, and to collect a large-scale dataset of a diverse variety of synthetic samples and their ratings for further research. We found strong correlations challenge by challenge at the system level between the original results and our new listening test. We also observed the importance of the choice of speaker on synthesis quality.
Speech-XLNet: Unsupervised Acoustic Model Pretraining For Self-Attention Networks
Oct 23, 2019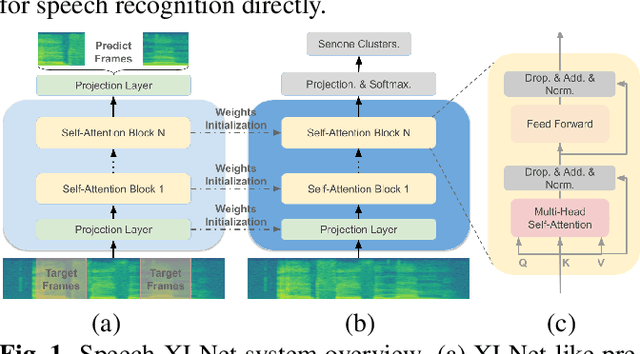
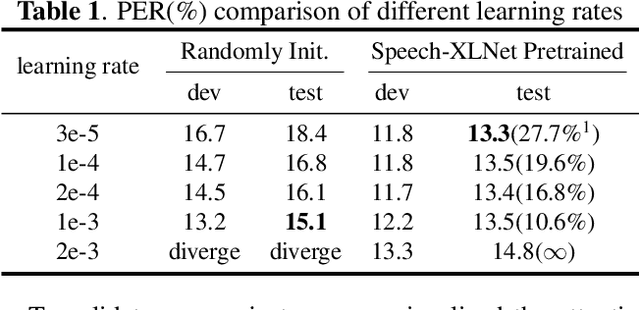
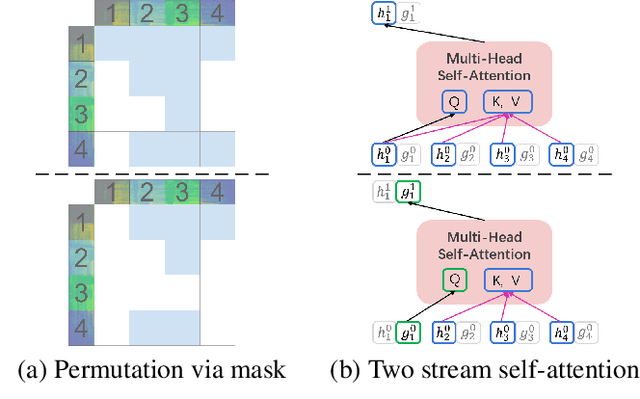
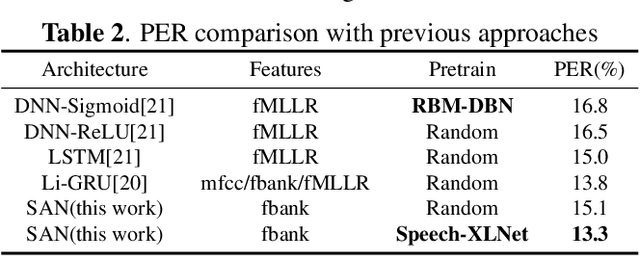
Self-attention network (SAN) can benefit significantly from the bi-directional representation learning through unsupervised pretraining paradigms such as BERT and XLNet. In this paper, we present an XLNet-like pretraining scheme "Speech-XLNet" for unsupervised acoustic model pretraining to learn speech representations with SAN. The pretrained SAN is finetuned under the hybrid SAN/HMM framework. We conjecture that by shuffling the speech frame orders, the permutation in Speech-XLNet serves as a strong regularizer to encourage the SAN to make inferences by focusing on global structures through its attention weights. In addition, Speech-XLNet also allows the model to explore the bi-directional contexts for effective speech representation learning. Experiments on TIMIT and WSJ demonstrate that Speech-XLNet greatly improves the SAN/HMM performance in terms of both convergence speed and recognition accuracy compared to the one trained from randomly initialized weights. Our best systems achieve a relative improvement of 11.9% and 8.3% on the TIMIT and WSJ tasks respectively. In particular, the best system achieves a phone error rate (PER) of 13.3% on the TIMIT test set, which to our best knowledge, is the lowest PER obtained from a single system.
Unsupervised Style and Content Separation by Minimizing Mutual Information for Speech Synthesis
Mar 09, 2020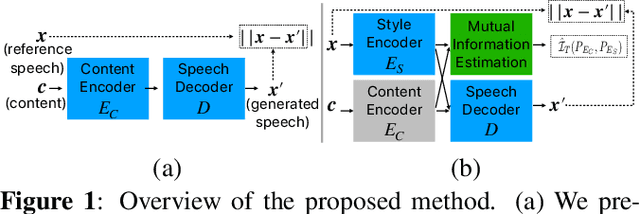
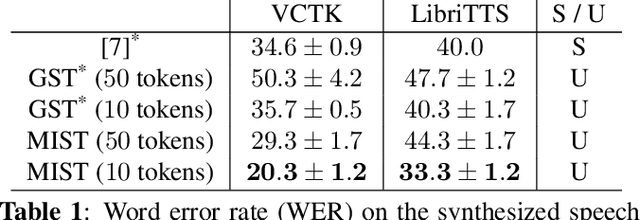
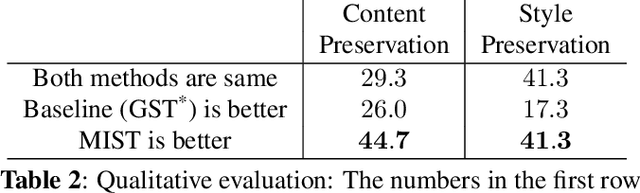
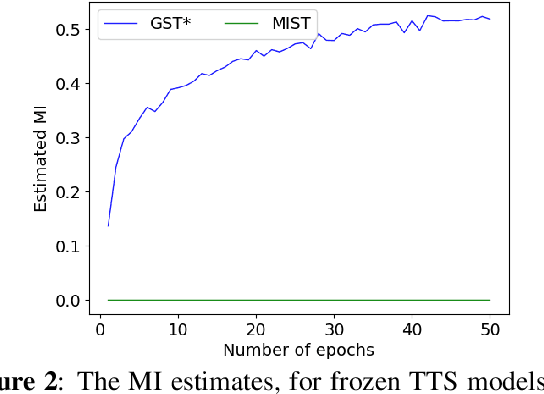
We present a method to generate speech from input text and a style vector that is extracted from a reference speech signal in an unsupervised manner, i.e., no style annotation, such as speaker information, is required. Existing unsupervised methods, during training, generate speech by computing style from the corresponding ground truth sample and use a decoder to combine the style vector with the input text. Training the model in such a way leaks content information into the style vector. The decoder can use the leaked content and ignore some of the input text to minimize the reconstruction loss. At inference time, when the reference speech does not match the content input, the output may not contain all of the content of the input text. We refer to this problem as "content leakage", which we address by explicitly estimating and minimizing the mutual information between the style and the content through an adversarial training formulation. We call our method MIST - Mutual Information based Style Content Separation. The main goal of the method is to preserve the input content in the synthesized speech signal, which we measure by the word error rate (WER) and show substantial improvements over state-of-the-art unsupervised speech synthesis methods.