 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving EEG based Continuous Speech Recognition
Dec 24, 2019
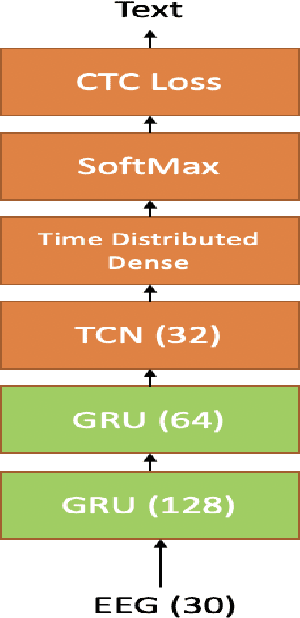
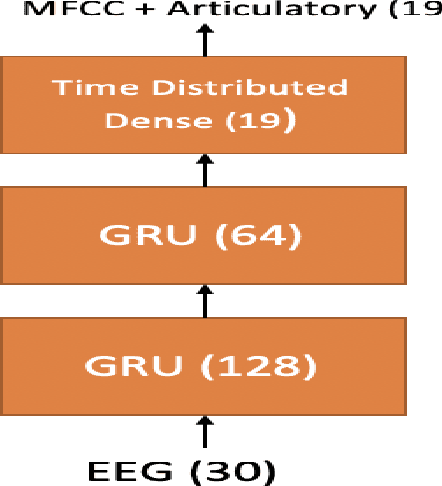
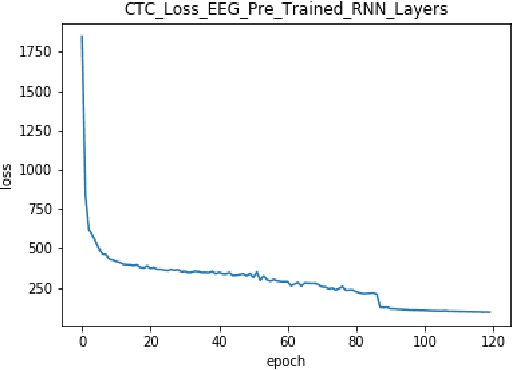
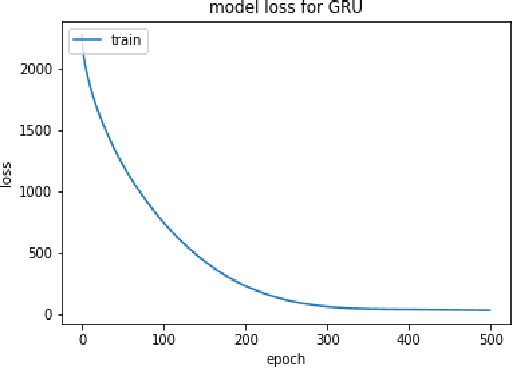
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020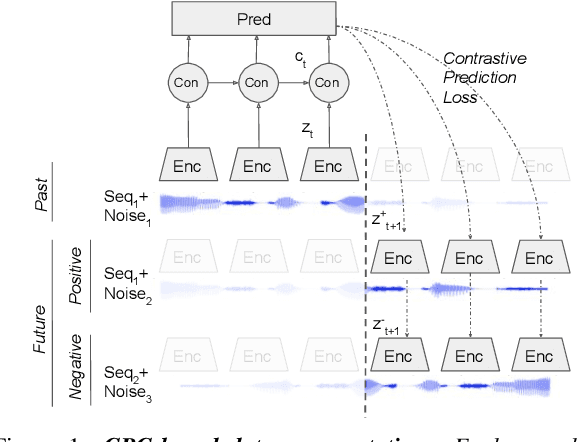
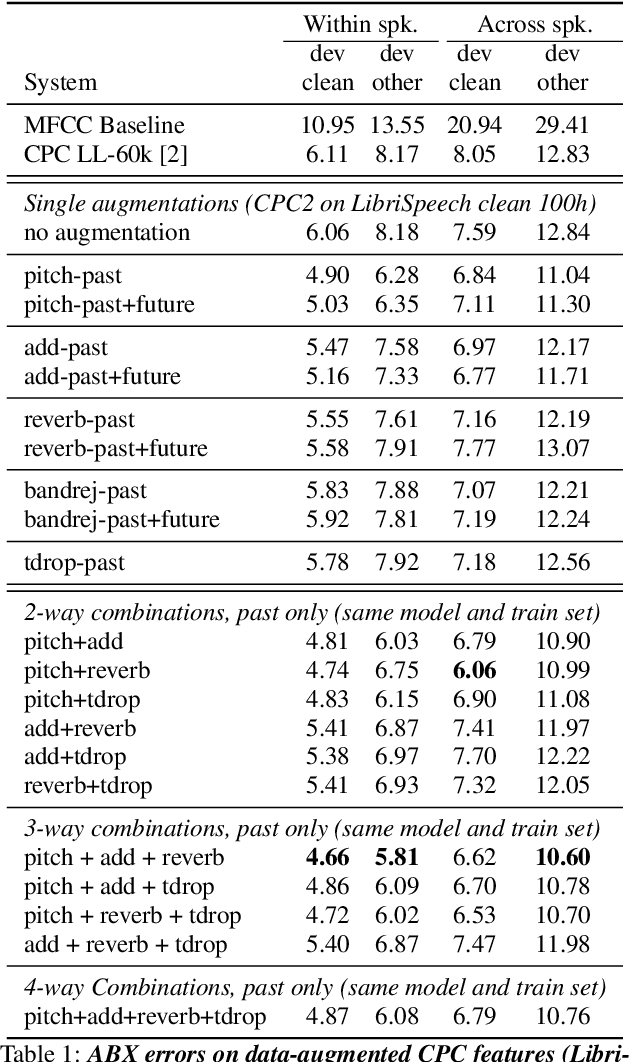
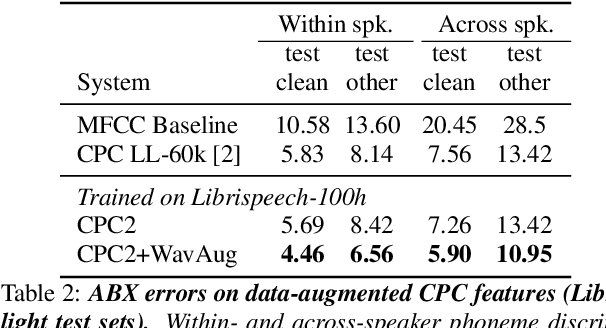
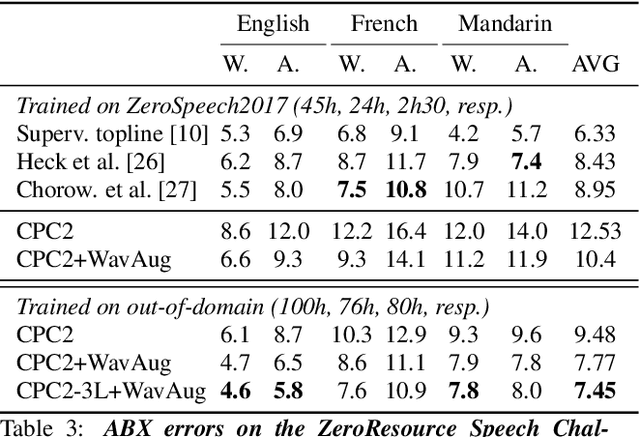
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.
Towards Learning a Universal Non-Semantic Representation of Speech
Feb 25, 2020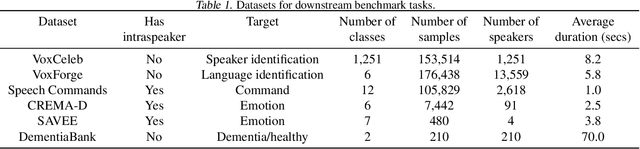
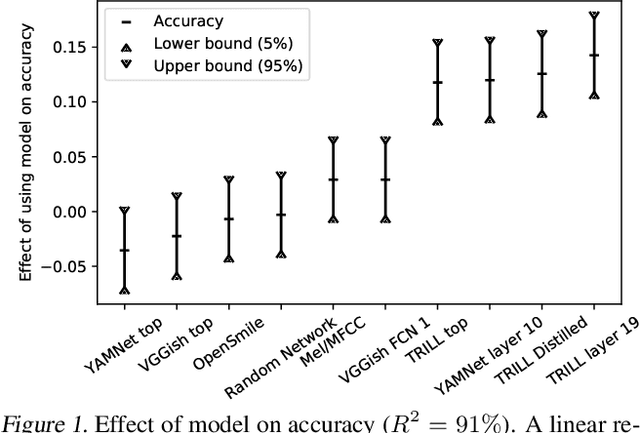
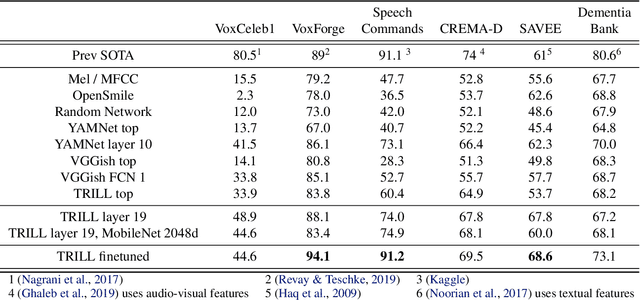
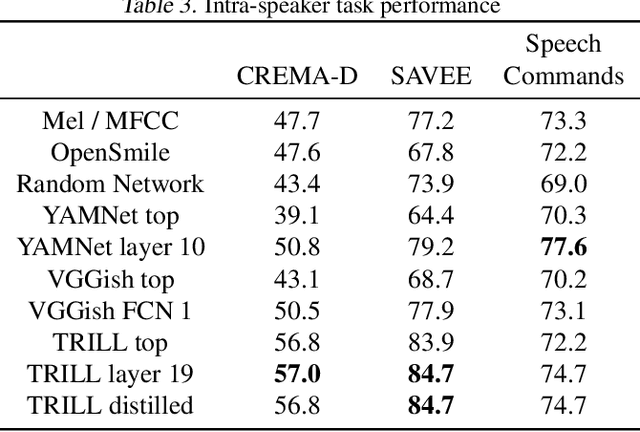
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.
Improving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
May 19, 2020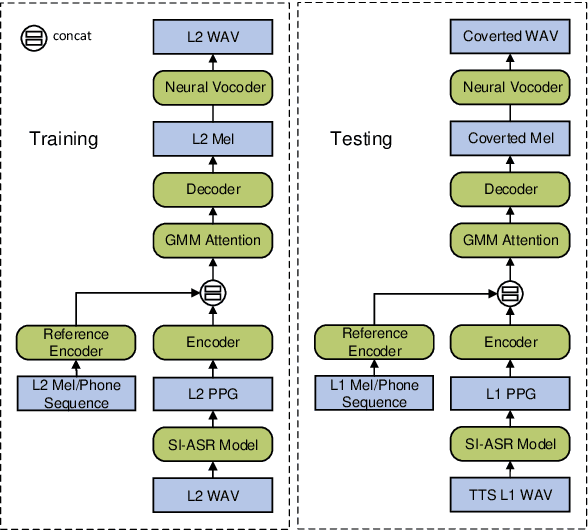
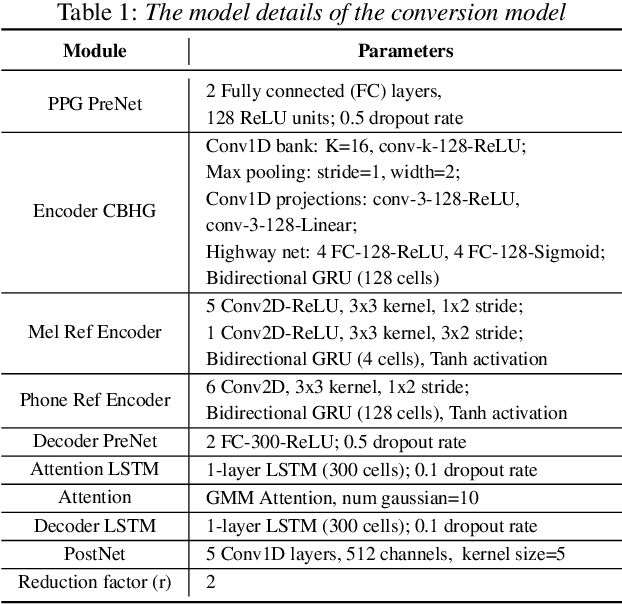
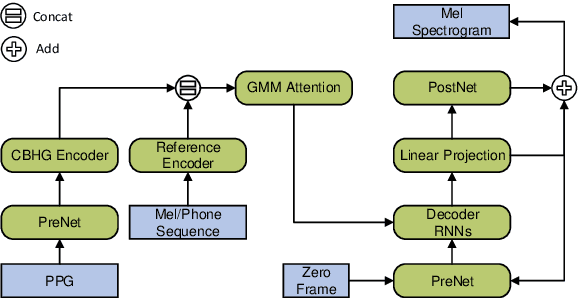
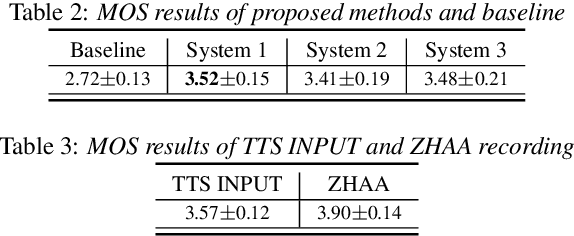
Accent conversion (AC) transforms a non-native speaker's accent into a native accent while maintaining the speaker's voice timbre. In this paper, we propose approaches to improving accent conversion applicability, as well as quality. First of all, we assume no reference speech is available at the conversion stage, and hence we employ an end-to-end text-to-speech system that is trained on native speech to generate native reference speech. To improve the quality and accent of the converted speech, we introduce reference encoders which make us capable of utilizing multi-source information. This is motivated by acoustic features extracted from native reference and linguistic information, which are complementary to conventional phonetic posteriorgrams (PPGs), so they can be concatenated as features to improve a baseline system based only on PPGs. Moreover, we optimize model architecture using GMM-based attention instead of windowed attention to elevate synthesized performance. Experimental results indicate when the proposed techniques are applied the integrated system significantly raises the scores of acoustic quality (30$\%$ relative increase in mean opinion score) and native accent (68$\%$ relative preference) while retaining the voice identity of the non-native speaker.
Improve Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Oct 14, 2021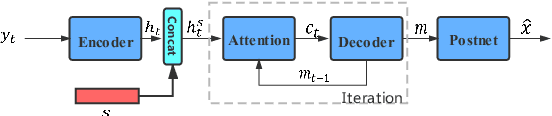
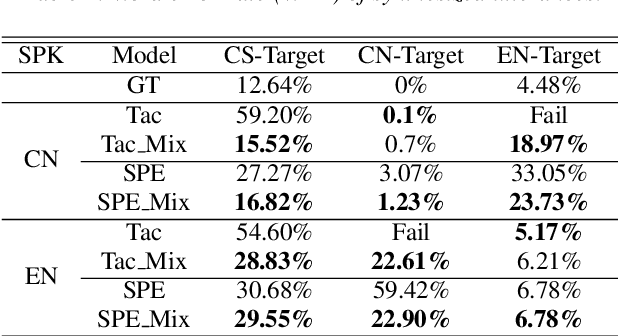
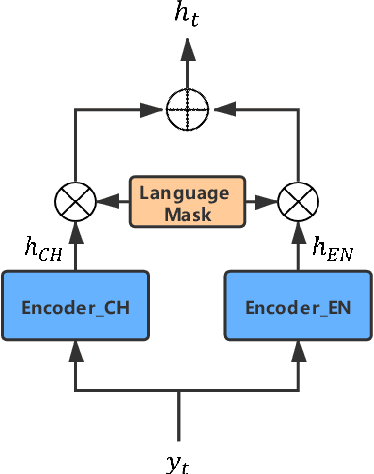
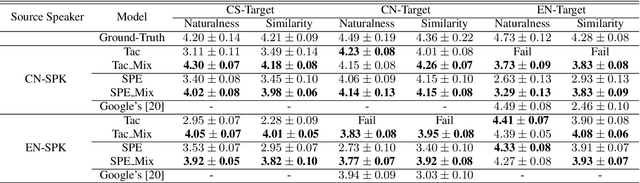
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.
Research on Modeling Units of Transformer Transducer for Mandarin Speech Recognition
Apr 26, 2020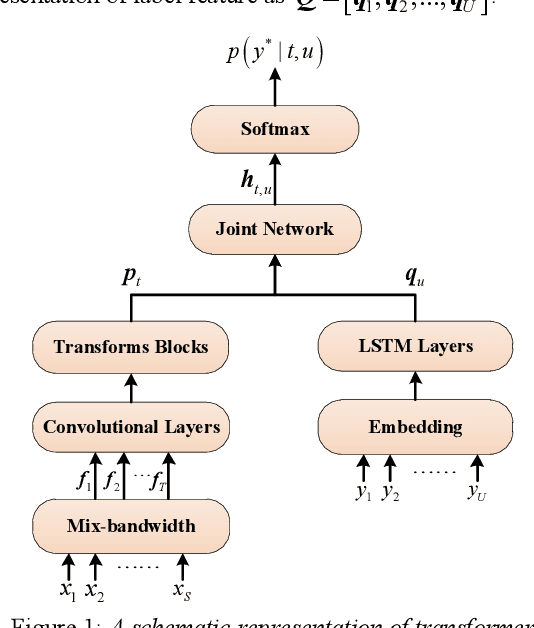
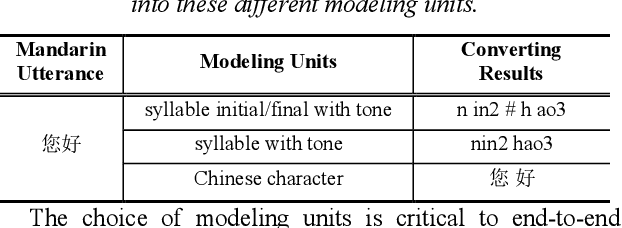
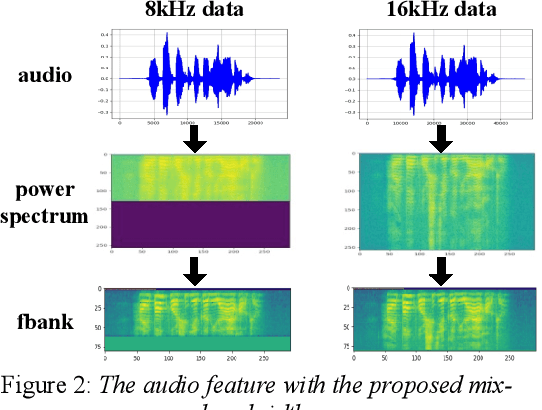
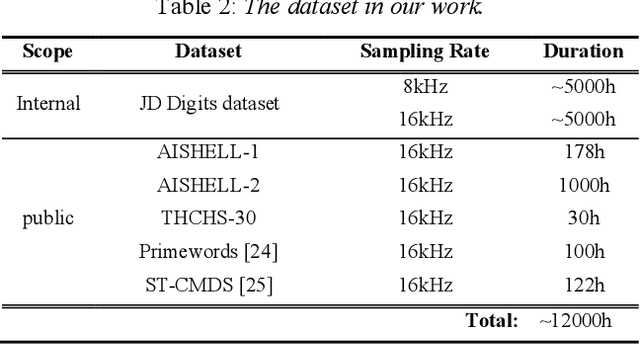
Modeling unit and model architecture are two key factors of Recurrent Neural Network Transducer (RNN-T) in end-to-end speech recognition. To improve the performance of RNN-T for Mandarin speech recognition task, a novel transformer transducer with the combination architecture of self-attention transformer and RNN is proposed. And then the choice of different modeling units for transformer transducer is explored. In addition, we present a new mix-bandwidth training method to obtain a general model that is able to accurately recognize Mandarin speech with different sampling rates simultaneously. All of our experiments are conducted on about 12,000 hours of Mandarin speech with sampling rate in 8kHz and 16kHz. Experimental results show that Mandarin transformer transducer using syllable with tone achieves the best performance. It yields an average of 14.4% and 44.1% relative Word Error Rate (WER) reduction when compared with the models using syllable initial/final with tone and Chinese character, respectively. Also, it outperforms the model based on syllable initial/final with tone with an average of 13.5% relative Character Error Rate (CER) reduction.
Nonlinear Spatial Filtering in Multichannel Speech Enhancement
Apr 22, 2021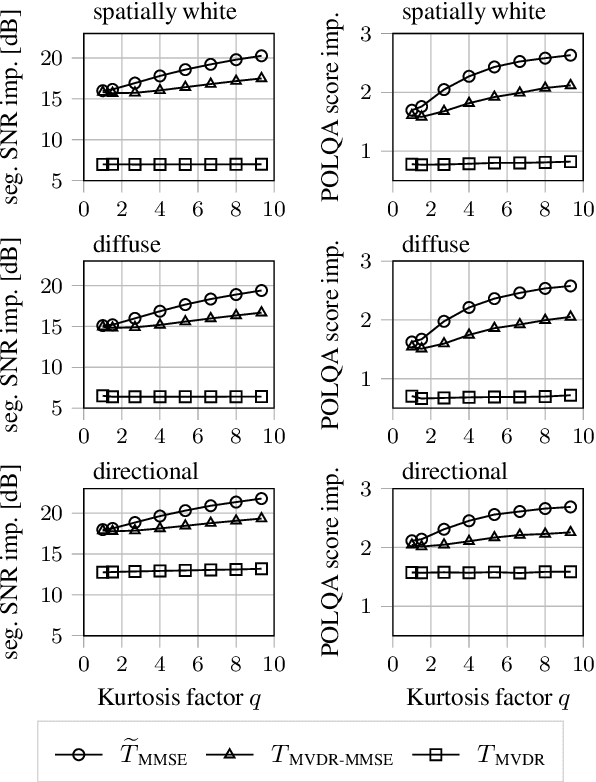
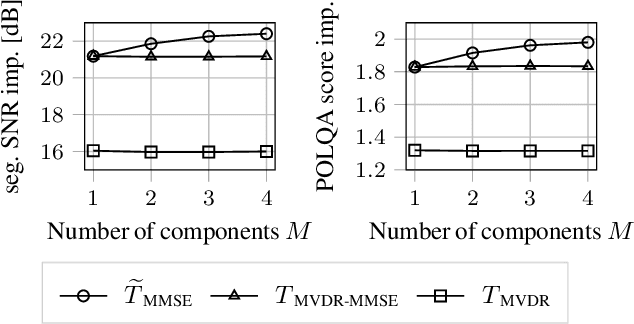
The majority of multichannel speech enhancement algorithms are two-step procedures that first apply a linear spatial filter, a so-called beamformer, and combine it with a single-channel approach for postprocessing. However, the serial concatenation of a linear spatial filter and a postfilter is not generally optimal in the minimum mean square error (MMSE) sense for noise distributions other than a Gaussian distribution. Rather, the MMSE optimal filter is a joint spatial and spectral nonlinear function. While estimating the parameters of such a filter with traditional methods is challenging, modern neural networks may provide an efficient way to learn the nonlinear function directly from data. To see if further research in this direction is worthwhile, in this work we examine the potential performance benefit of replacing the common two-step procedure with a joint spatial and spectral nonlinear filter. We analyze three different forms of non-Gaussianity: First, we evaluate on super-Gaussian noise with a high kurtosis. Second, we evaluate on inhomogeneous noise fields created by five interfering sources using two microphones, and third, we evaluate on real-world recordings from the CHiME3 database. In all scenarios, considerable improvements may be obtained. Most prominently, our analyses show that a nonlinear spatial filter uses the available spatial information more effectively than a linear spatial filter as it is capable of suppressing more than $D-1$ directional interfering sources with a $D$-dimensional microphone array without spatial adaptation.
* Accepted version, 11 pages, 6 figures
Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast
Feb 19, 2021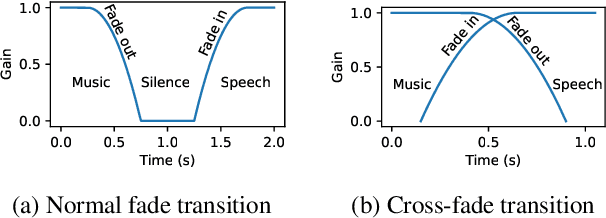
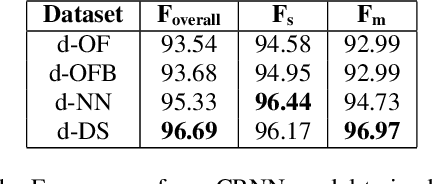
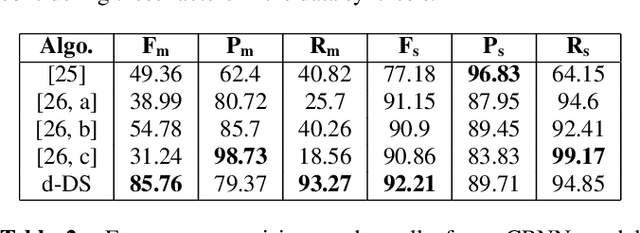
Segmenting audio into homogeneous sections such as music and speech helps us understand the content of audio. It is useful as a pre-processing step to index, store, and modify audio recordings, radio broadcasts and TV programmes. Deep learning models for segmentation are generally trained on copyrighted material, which cannot be shared. Annotating these datasets is time-consuming and expensive and therefore, it significantly slows down research progress. In this study, we present a novel procedure that artificially synthesises data that resembles radio signals. We replicate the workflow of a radio DJ in mixing audio and investigate parameters like fade curves and audio ducking. We trained a Convolutional Recurrent Neural Network (CRNN) on this synthesised data and outperformed state-of-the-art algorithms for music-speech detection. This paper demonstrates the data synthesis procedure as a highly effective technique to generate large datasets to train deep neural networks for audio segmentation.
Word Discovery in Visually Grounded, Self-Supervised Speech Models
Mar 28, 2022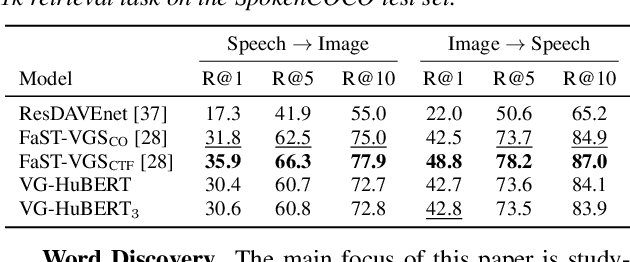

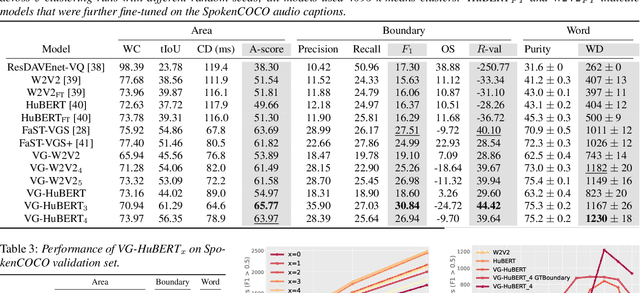
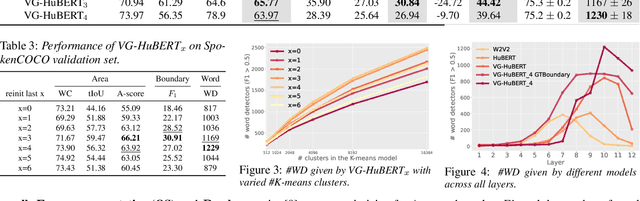
We present a method for visually-grounded spoken term discovery. After training either a HuBERT or wav2vec2.0 model to associate spoken captions with natural images, we show that powerful word segmentation and clustering capability emerges within the model's self-attention heads. Our experiments reveal that this ability is not present to nearly the same extent in the base HuBERT and wav2vec2.0 models, suggesting that the visual grounding task is a crucial component of the word discovery capability we observe. We also evaluate our method on the Buckeye word segmentation and ZeroSpeech spoken term discovery tasks, where we outperform all currently published methods on several metrics.