 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Countering hate on social media: Large scale classification of hate and counter speech
Jun 04, 2020
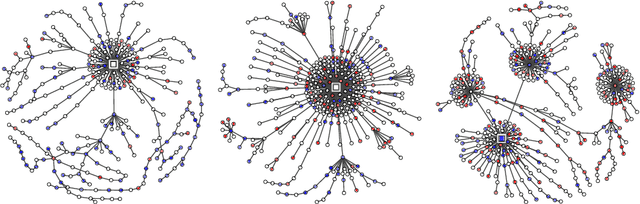
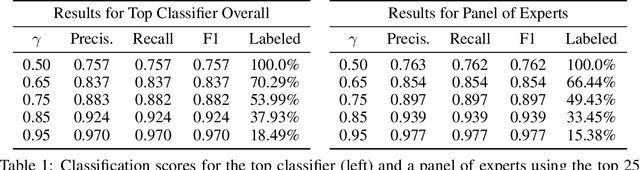
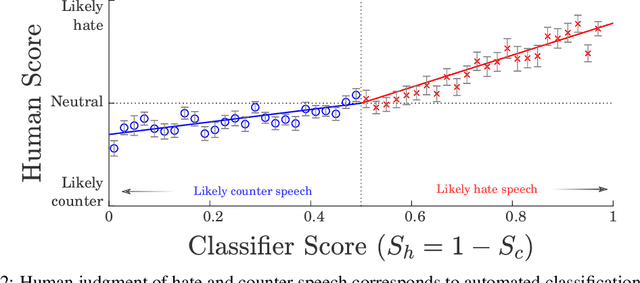
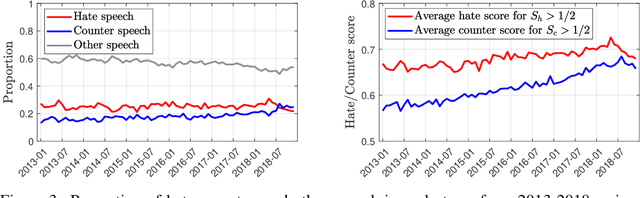
Hateful rhetoric is plaguing online discourse, fostering extreme societal movements and possibly giving rise to real-world violence. A potential solution to this growing global problem is citizen-generated counter speech where citizens actively engage in hate-filled conversations to attempt to restore civil non-polarized discourse. However, its actual effectiveness in curbing the spread of hatred is unknown and hard to quantify. One major obstacle to researching this question is a lack of large labeled data sets for training automated classifiers to identify counter speech. Here we made use of a unique situation in Germany where self-labeling groups engaged in organized online hate and counter speech. We used an ensemble learning algorithm which pairs a variety of paragraph embeddings with regularized logistic regression functions to classify both hate and counter speech in a corpus of millions of relevant tweets from these two groups. Our pipeline achieved macro F1 scores on out of sample balanced test sets ranging from 0.76 to 0.97---accuracy in line and even exceeding the state of the art. On thousands of tweets, we used crowdsourcing to verify that the judgments made by the classifier are in close alignment with human judgment. We then used the classifier to discover hate and counter speech in more than 135,000 fully-resolved Twitter conversations occurring from 2013 to 2018 and study their frequency and interaction. Altogether, our results highlight the potential of automated methods to evaluate the impact of coordinated counter speech in stabilizing conversations on social media.
Incorporating Symbolic Sequential Modeling for Speech Enhancement
Apr 30, 2019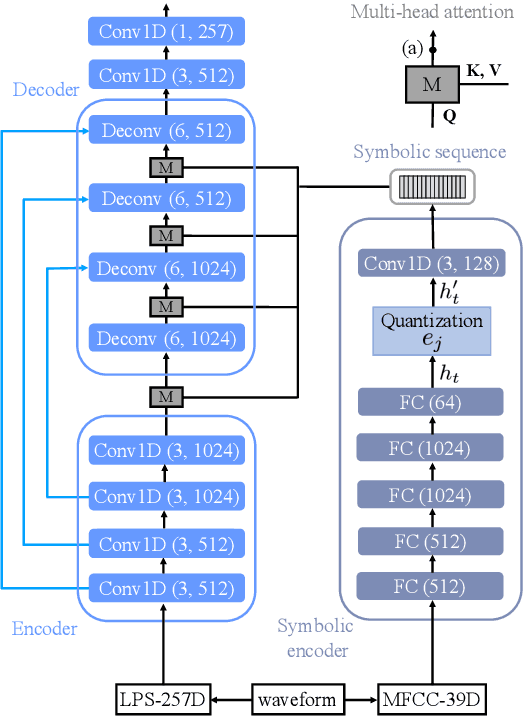
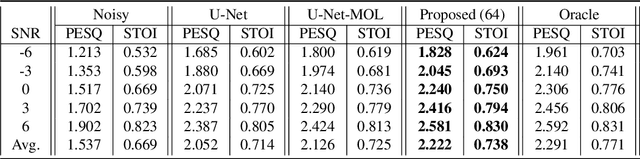
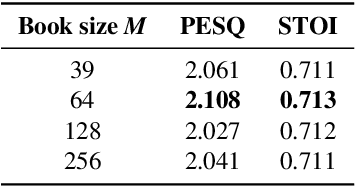
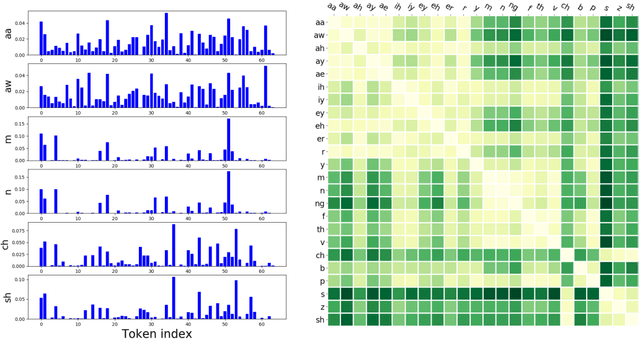
In a noisy environment, a lossy speech signal can be automatically restored by a listener if he/she knows the language well. That is, with the built-in knowledge of a "language model", a listener may effectively suppress noise interference and retrieve the target speech signals. Accordingly, we argue that familiarity with the underlying linguistic content of spoken utterances benefits speech enhancement (SE) in noisy environments. In this study, in addition to the conventional modeling for learning the acoustic noisy-clean speech mapping, an abstract symbolic sequential modeling is incorporated into the SE framework. This symbolic sequential modeling can be regarded as a "linguistic constraint" in learning the acoustic noisy-clean speech mapping function. In this study, the symbolic sequences for acoustic signals are obtained as discrete representations with a Vector Quantized Variational Autoencoder algorithm. The obtained symbols are able to capture high-level phoneme-like content from speech signals. The experimental results demonstrate that the proposed framework can significantly improve the SE performance in terms of perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI) on the TIMIT dataset.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020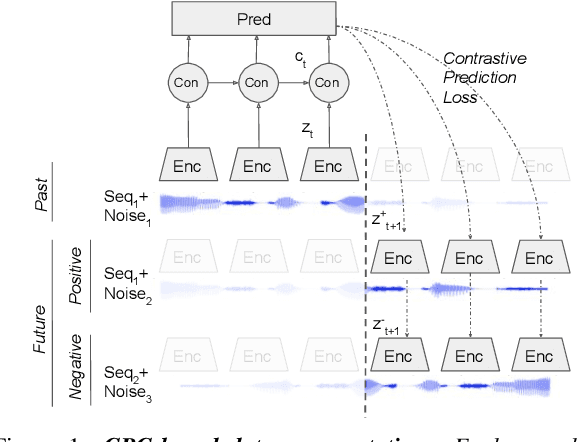
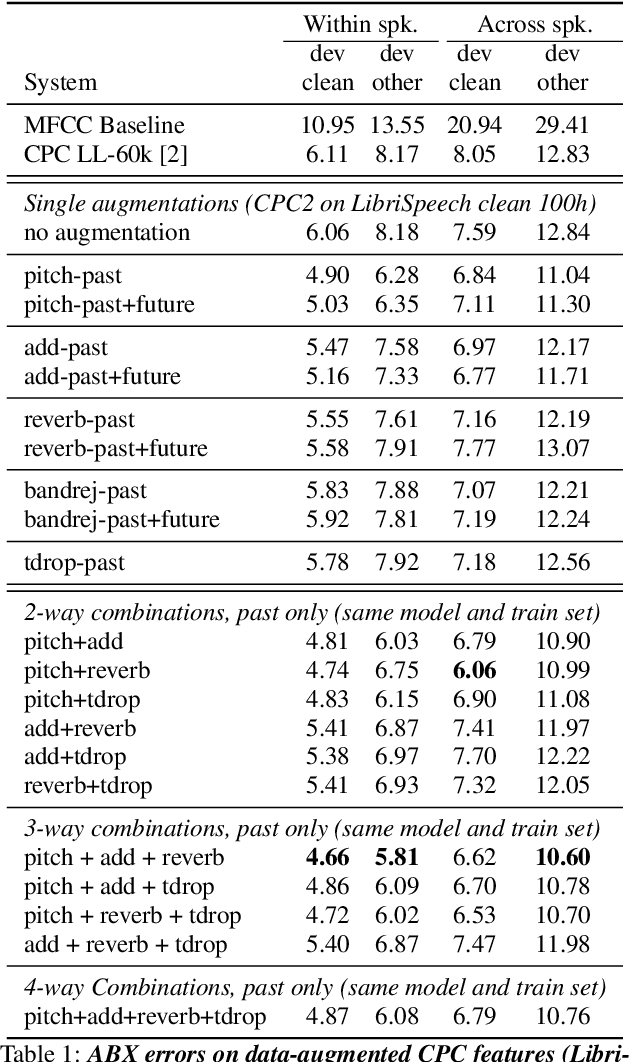
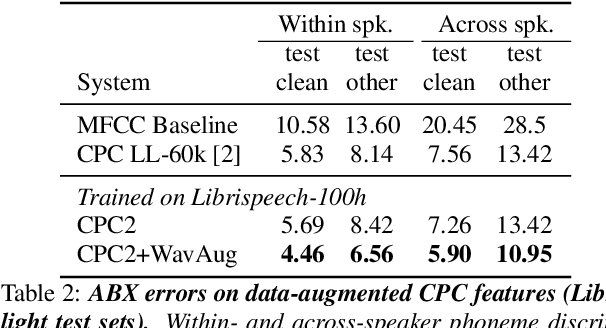
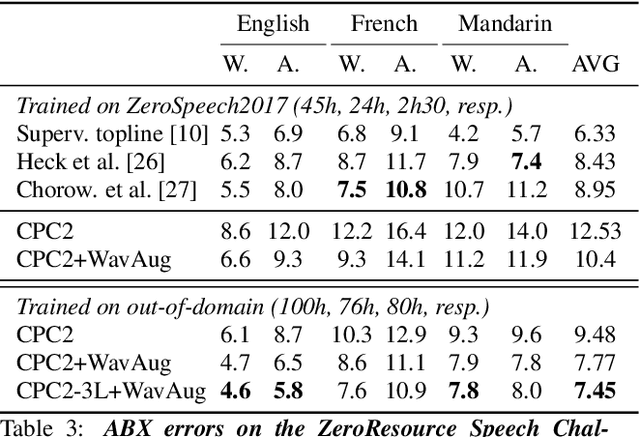
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.
Lattice Transformer for Speech Translation
Jun 13, 2019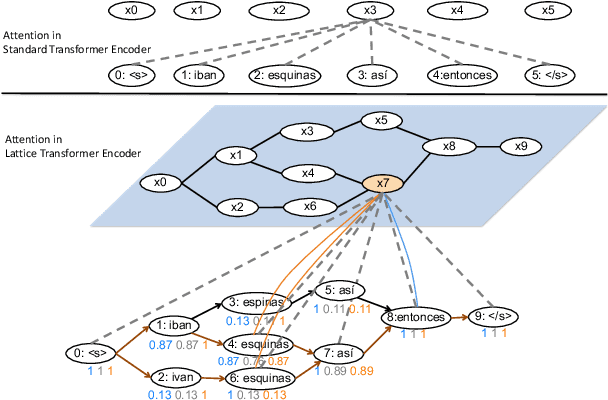

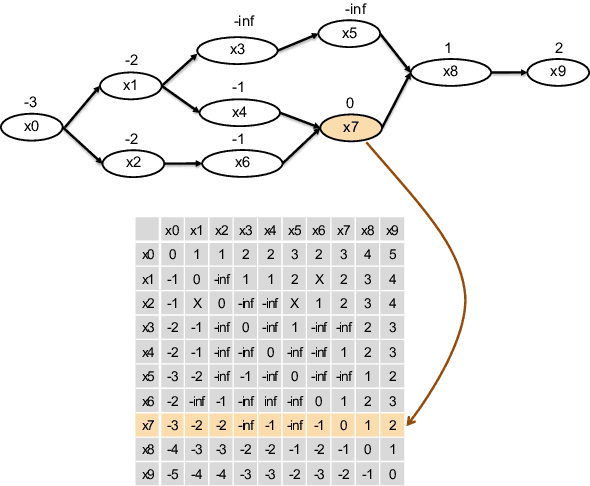
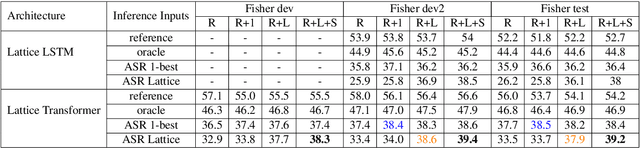
Recent advances in sequence modeling have highlighted the strengths of the transformer architecture, especially in achieving state-of-the-art machine translation results. However, depending on the up-stream systems, e.g., speech recognition, or word segmentation, the input to translation system can vary greatly. The goal of this work is to extend the attention mechanism of the transformer to naturally consume the lattice in addition to the traditional sequential input. We first propose a general lattice transformer for speech translation where the input is the output of the automatic speech recognition (ASR) which contains multiple paths and posterior scores. To leverage the extra information from the lattice structure, we develop a novel controllable lattice attention mechanism to obtain latent representations. On the LDC Spanish-English speech translation corpus, our experiments show that lattice transformer generalizes significantly better and outperforms both a transformer baseline and a lattice LSTM. Additionally, we validate our approach on the WMT 2017 Chinese-English translation task with lattice inputs from different BPE segmentations. In this task, we also observe the improvements over strong baselines.
Unsupervised Speech Enhancement Based on Multichannel NMF-Informed Beamforming for Noise-Robust Automatic Speech Recognition
Mar 31, 2019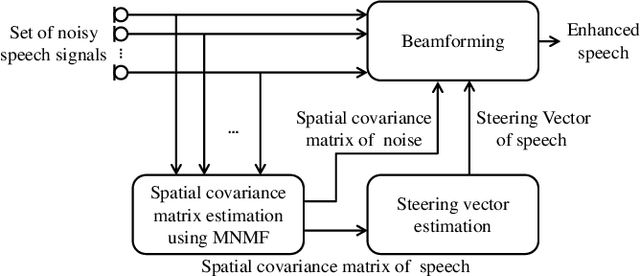
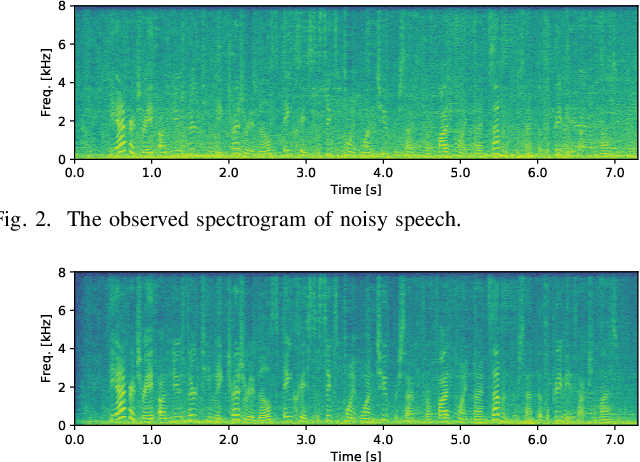
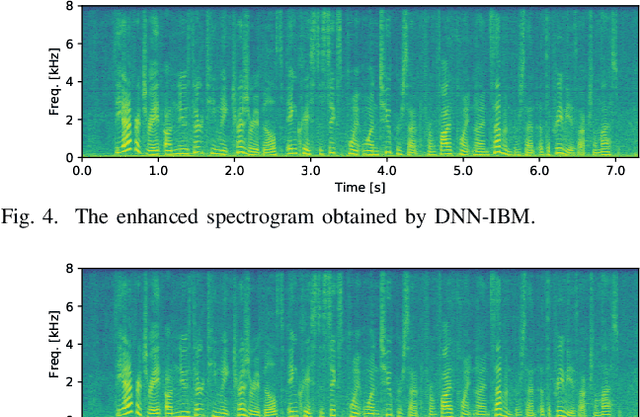

This paper describes multichannel speech enhancement for improving automatic speech recognition (ASR) in noisy environments. Recently, the minimum variance distortionless response (MVDR) beamforming has widely been used because it works well if the steering vector of speech and the spatial covariance matrix (SCM) of noise are given. To estimating such spatial information, conventional studies take a supervised approach that classifies each time-frequency (TF) bin into noise or speech by training a deep neural network (DNN). The performance of ASR, however, is degraded in an unknown noisy environment. To solve this problem, we take an unsupervised approach that decomposes each TF bin into the sum of speech and noise by using multichannel nonnegative matrix factorization (MNMF). This enables us to accurately estimate the SCMs of speech and noise not from observed noisy mixtures but from separated speech and noise components. In this paper we propose online MVDR beamforming by effectively initializing and incrementally updating the parameters of MNMF. Another main contribution is to comprehensively investigate the performances of ASR obtained by various types of spatial filters, i.e., time-invariant and variant versions of MVDR beamformers and those of rank-1 and full-rank multichannel Wiener filters, in combination with MNMF. The experimental results showed that the proposed method outperformed the state-of-the-art DNN-based beamforming method in unknown environments that did not match training data.
How do Voices from Past Speech Synthesis Challenges Compare Today?
May 05, 2021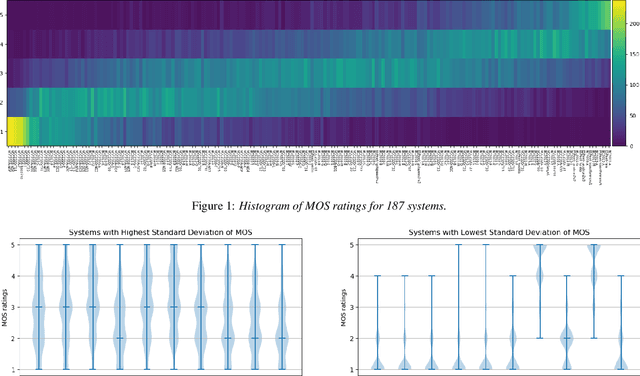
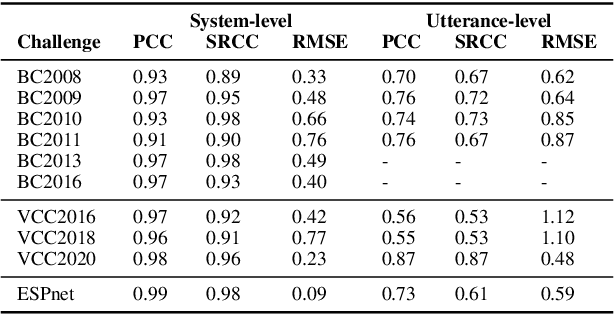

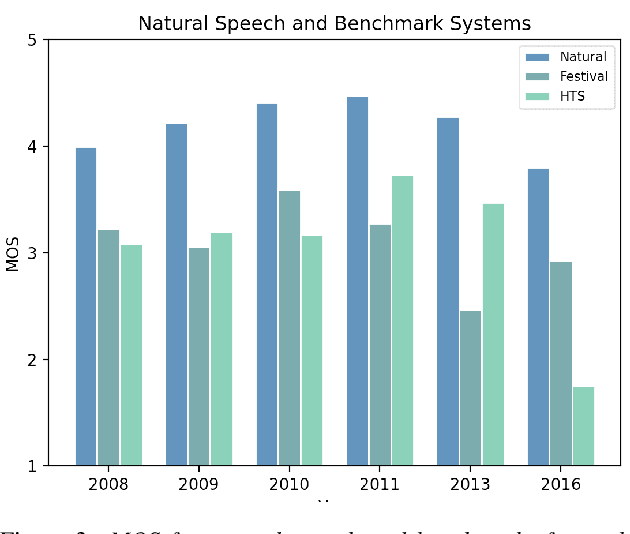
Shared challenges provide a venue for comparing systems trained on common data using a standardized evaluation, and they also provide an invaluable resource for researchers when the data and evaluation results are publicly released. The Blizzard Challenge and Voice Conversion Challenge are two such challenges for text-to-speech synthesis and for speaker conversion, respectively, and their publicly-available system samples and listening test results comprise a historical record of state-of-the-art synthesis methods over the years. In this paper, we revisit these past challenges and conduct a large-scale listening test with samples from many challenges combined. Our aims are to analyze and compare opinions of a large number of systems together, to determine whether and how opinions change over time, and to collect a large-scale dataset of a diverse variety of synthetic samples and their ratings for further research. We found strong correlations challenge by challenge at the system level between the original results and our new listening test. We also observed the importance of the choice of speaker on synthesis quality.
BERT-LID: Leveraging BERT to Improve Spoken Language Identification
Mar 01, 2022

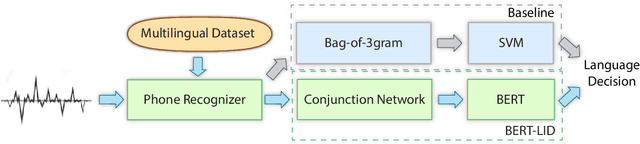
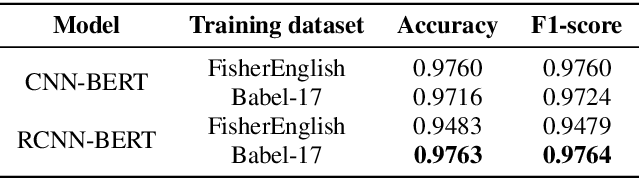
Language identification is a task of automatically determining the identity of a language conveyed by a spoken segment. It has a profound impact on the multilingual interoperability of an intelligent speech system. Despite language identification attaining high accuracy on medium or long utterances (>3s), the performance on short utterances (<=1s) is still far from satisfactory. We propose an effective BERT-based language identification system (BERT-LID) to improve language identification performance, especially on short-duration speech segments. To adapt BERT into the LID pipeline, we drop in a conjunction network prior to BERT to accommodate the frame-level Phonetic Posteriorgrams(PPG) derived from the frontend phone recognizer and then fine-tune the conjunction network and BERT pre-trained model together. We evaluate several variations within this piped framework, including combining BERT with CNN, LSTM, DPCNN, and RCNN. The experimental results demonstrate that the best-performing model is RCNN-BERT. Compared with the prior works, our RCNN-BERT model can improve the accuracy by about 5% on long-segment identification and 18% on short-segment identification. The outperformance of our model, especially on the short-segment task, demonstrates the applicability of our proposed BERT-based approach on language identification.
Improving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
May 19, 2020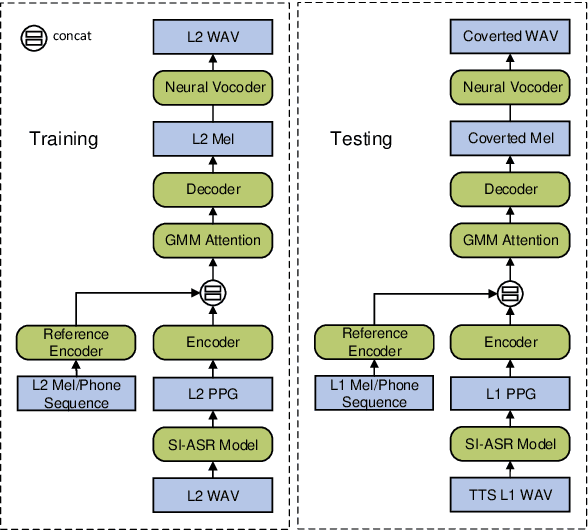
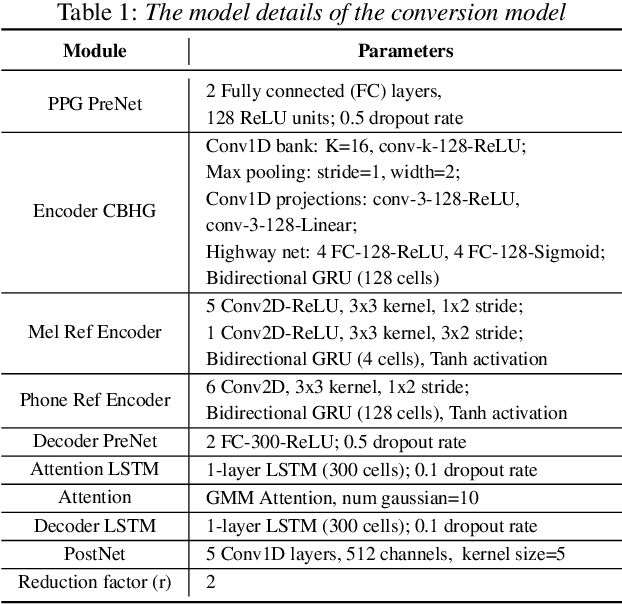
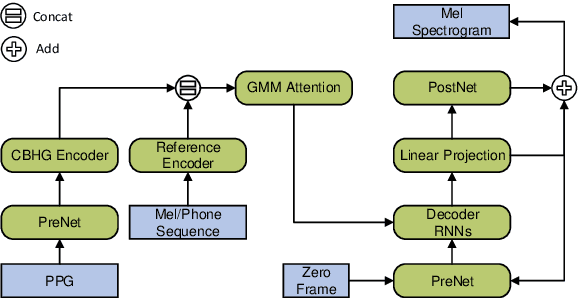
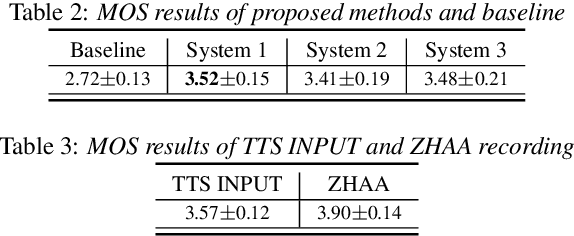
Accent conversion (AC) transforms a non-native speaker's accent into a native accent while maintaining the speaker's voice timbre. In this paper, we propose approaches to improving accent conversion applicability, as well as quality. First of all, we assume no reference speech is available at the conversion stage, and hence we employ an end-to-end text-to-speech system that is trained on native speech to generate native reference speech. To improve the quality and accent of the converted speech, we introduce reference encoders which make us capable of utilizing multi-source information. This is motivated by acoustic features extracted from native reference and linguistic information, which are complementary to conventional phonetic posteriorgrams (PPGs), so they can be concatenated as features to improve a baseline system based only on PPGs. Moreover, we optimize model architecture using GMM-based attention instead of windowed attention to elevate synthesized performance. Experimental results indicate when the proposed techniques are applied the integrated system significantly raises the scores of acoustic quality (30$\%$ relative increase in mean opinion score) and native accent (68$\%$ relative preference) while retaining the voice identity of the non-native speaker.
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021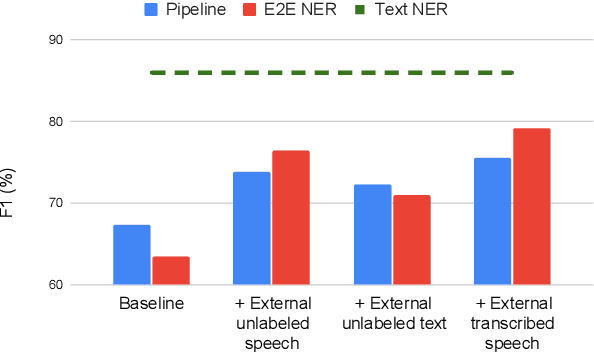

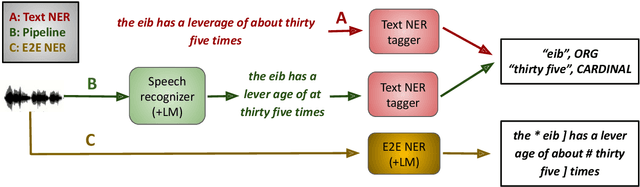
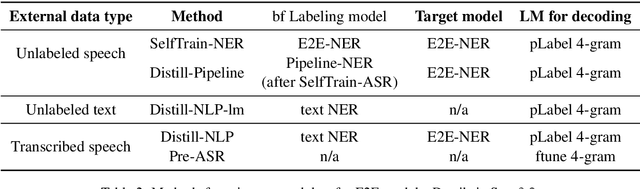
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
Towards Learning a Universal Non-Semantic Representation of Speech
Feb 25, 2020
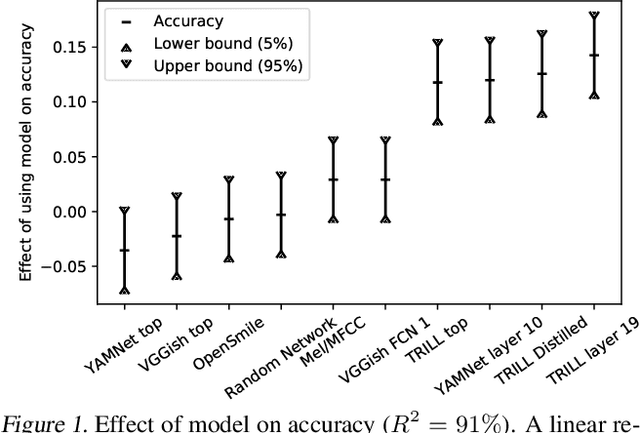
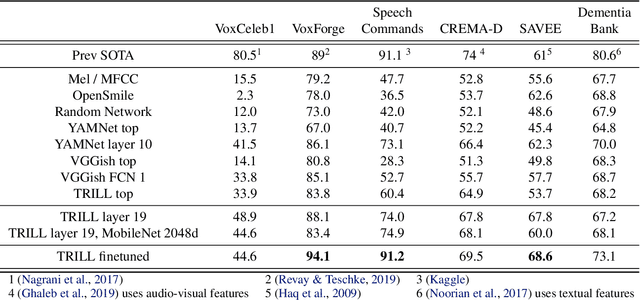
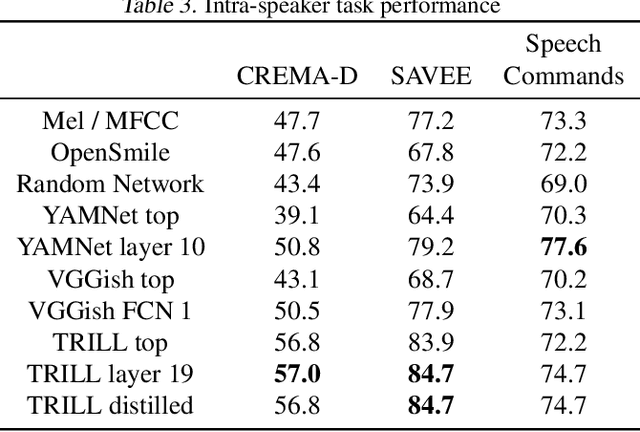
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.