 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Speech Enhancement Based on Multichannel NMF-Informed Beamforming for Noise-Robust Automatic Speech Recognition
Mar 31, 2019
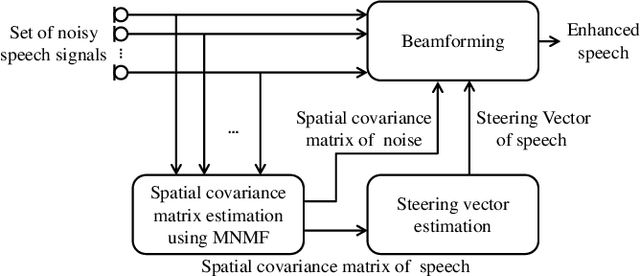
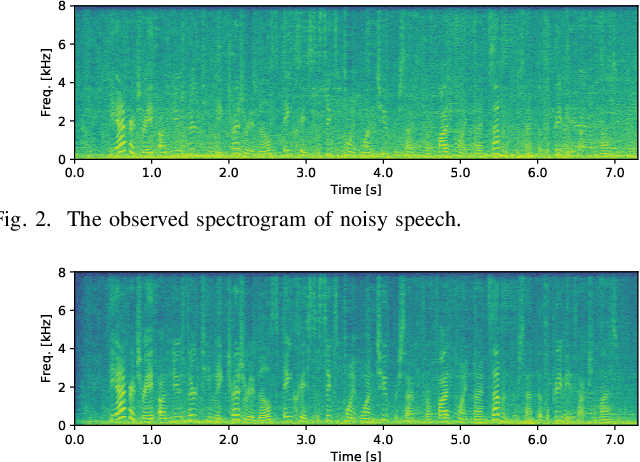
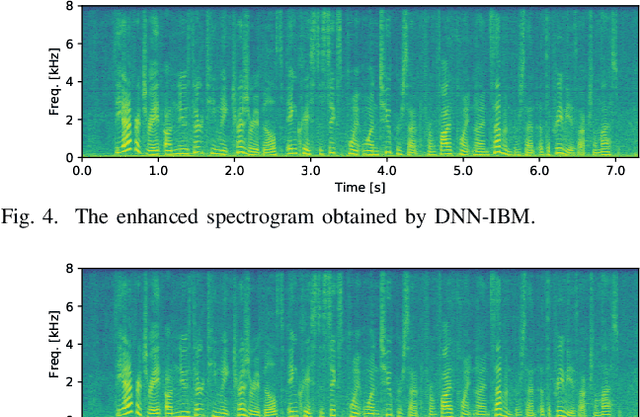

This paper describes multichannel speech enhancement for improving automatic speech recognition (ASR) in noisy environments. Recently, the minimum variance distortionless response (MVDR) beamforming has widely been used because it works well if the steering vector of speech and the spatial covariance matrix (SCM) of noise are given. To estimating such spatial information, conventional studies take a supervised approach that classifies each time-frequency (TF) bin into noise or speech by training a deep neural network (DNN). The performance of ASR, however, is degraded in an unknown noisy environment. To solve this problem, we take an unsupervised approach that decomposes each TF bin into the sum of speech and noise by using multichannel nonnegative matrix factorization (MNMF). This enables us to accurately estimate the SCMs of speech and noise not from observed noisy mixtures but from separated speech and noise components. In this paper we propose online MVDR beamforming by effectively initializing and incrementally updating the parameters of MNMF. Another main contribution is to comprehensively investigate the performances of ASR obtained by various types of spatial filters, i.e., time-invariant and variant versions of MVDR beamformers and those of rank-1 and full-rank multichannel Wiener filters, in combination with MNMF. The experimental results showed that the proposed method outperformed the state-of-the-art DNN-based beamforming method in unknown environments that did not match training data.
Correlating Subword Articulation with Lip Shapes for Embedding Aware Audio-Visual Speech Enhancement
Sep 21, 2020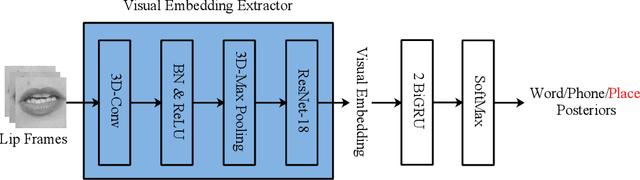
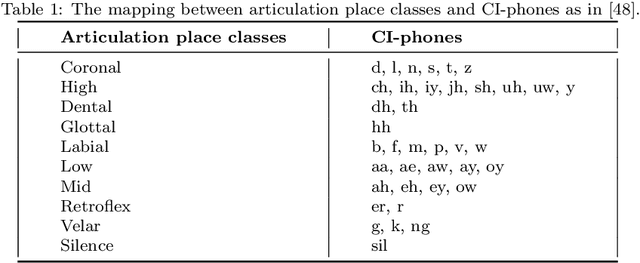

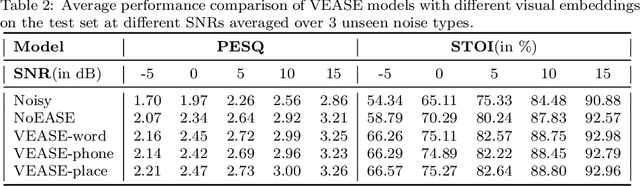
In this paper, we propose a visual embedding approach to improving embedding aware speech enhancement (EASE) by synchronizing visual lip frames at the phone and place of articulation levels. We first extract visual embedding from lip frames using a pre-trained phone or articulation place recognizer for visual-only EASE (VEASE). Next, we extract audio-visual embedding from noisy speech and lip videos in an information intersection manner, utilizing a complementarity of audio and visual features for multi-modal EASE (MEASE). Experiments on the TCD-TIMIT corpus corrupted by simulated additive noises show that our proposed subword based VEASE approach is more effective than conventional embedding at the word level. Moreover, visual embedding at the articulation place level, leveraging upon a high correlation between place of articulation and lip shapes, shows an even better performance than that at the phone level. Finally the proposed MEASE framework, incorporating both audio and visual embedding, yields significantly better speech quality and intelligibility than those obtained with the best visual-only and audio-only EASE systems.
Countering hate on social media: Large scale classification of hate and counter speech
Jun 05, 2020
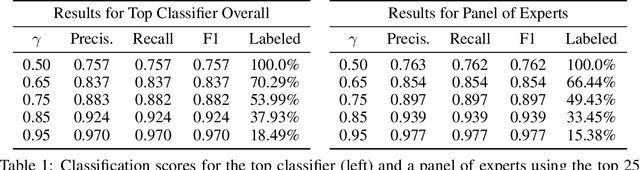
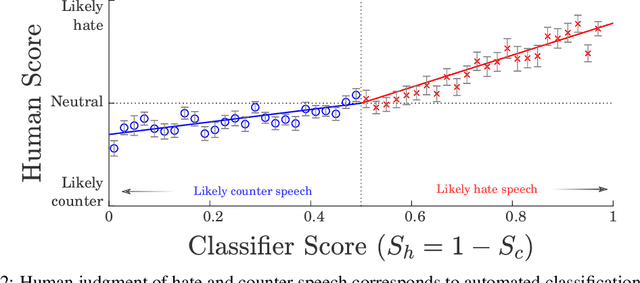
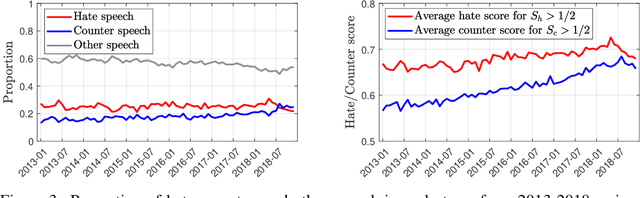
Hateful rhetoric is plaguing online discourse, fostering extreme societal movements and possibly giving rise to real-world violence. A potential solution to this growing global problem is citizen-generated counter speech where citizens actively engage in hate-filled conversations to attempt to restore civil non-polarized discourse. However, its actual effectiveness in curbing the spread of hatred is unknown and hard to quantify. One major obstacle to researching this question is a lack of large labeled data sets for training automated classifiers to identify counter speech. Here we made use of a unique situation in Germany where self-labeling groups engaged in organized online hate and counter speech. We used an ensemble learning algorithm which pairs a variety of paragraph embeddings with regularized logistic regression functions to classify both hate and counter speech in a corpus of millions of relevant tweets from these two groups. Our pipeline achieved macro F1 scores on out of sample balanced test sets ranging from 0.76 to 0.97---accuracy in line and even exceeding the state of the art. On thousands of tweets, we used crowdsourcing to verify that the judgments made by the classifier are in close alignment with human judgment. We then used the classifier to discover hate and counter speech in more than 135,000 fully-resolved Twitter conversations occurring from 2013 to 2018 and study their frequency and interaction. Altogether, our results highlight the potential of automated methods to evaluate the impact of coordinated counter speech in stabilizing conversations on social media.
WaveCRN: An Efficient Convolutional Recurrent Neural Network for End-to-end Speech Enhancement
Apr 12, 2020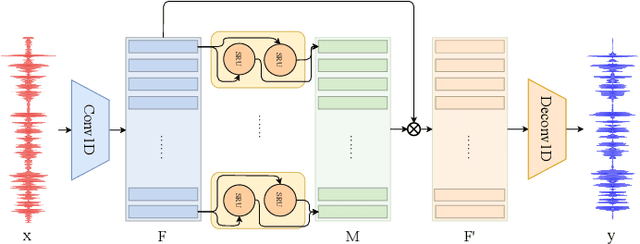
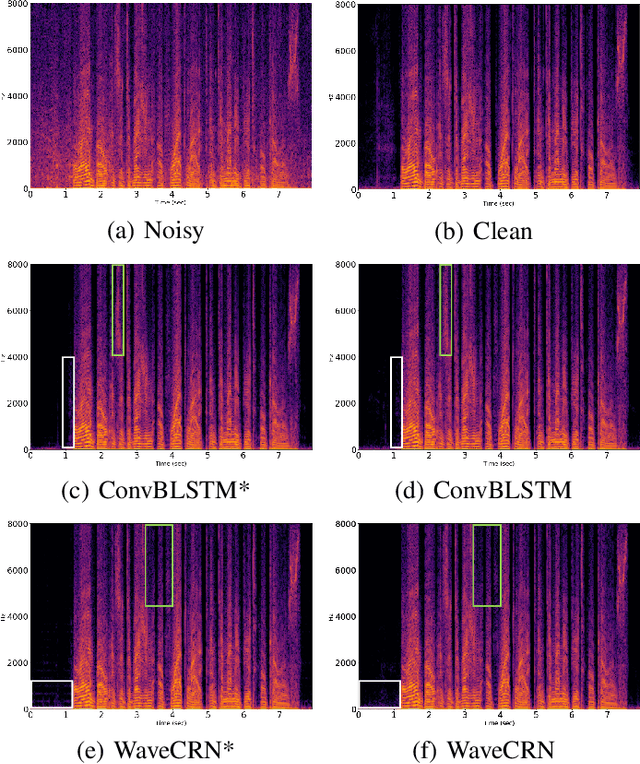
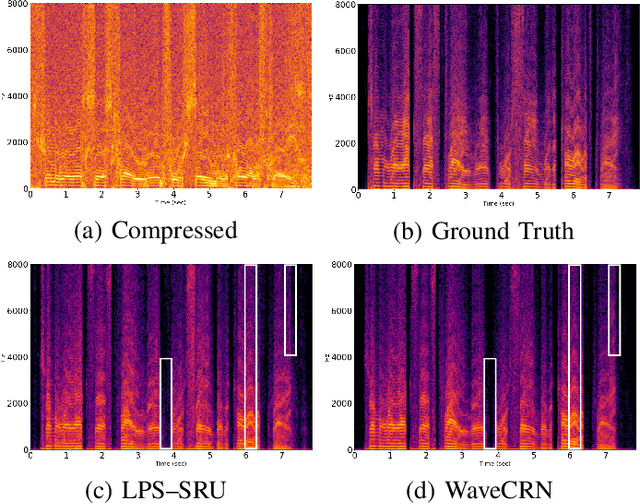
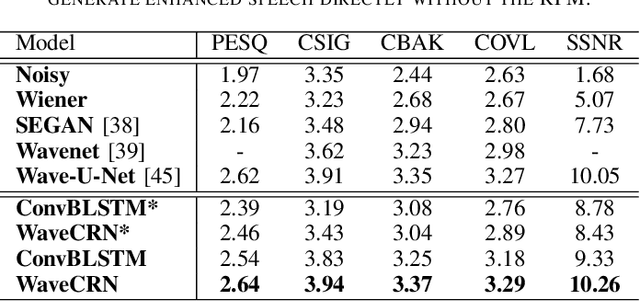
Due to the simple design pipeline, end-to-end (E2E) neural models for speech enhancement (SE) have attracted great interest. In order to improve the performance of the E2E model, the locality and temporal sequential properties of speech should be efficiently taken into account when modelling. However, in most current E2E models for SE, these properties are either not fully considered or are too complex to be realized. In this paper, we propose an efficient E2E SE model, termed WaveCRN. In WaveCRN, the speech locality feature is captured by a convolutional neural network (CNN), while the temporal sequential property of the locality feature is modeled by stacked simple recurrent units (SRU). Unlike a conventional temporal sequential model that uses a long short-term memory (LSTM) network, which is difficult to parallelize, SRU can be efficiently parallelized in calculation with even fewer model parameters. In addition, in order to more effectively suppress the noise components in the input noisy speech, we derive a novel restricted feature masking (RFM) approach that performs enhancement on the feature maps in the hidden layers; this is different from the approach that applies the estimated ratio mask on the noisy spectral features, which is commonly used in speech separation methods. Experimental results on speech denoising and compressed speech restoration tasks confirm that with the lightweight architecture of SRU and the feature-mapping-based RFM, WaveCRN performs comparably with other state-of-the-art approaches with notably reduced model complexity and inference time.
Improve Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Oct 14, 2021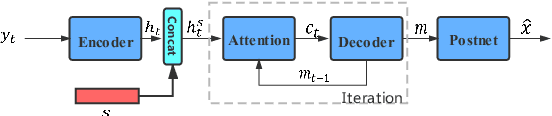
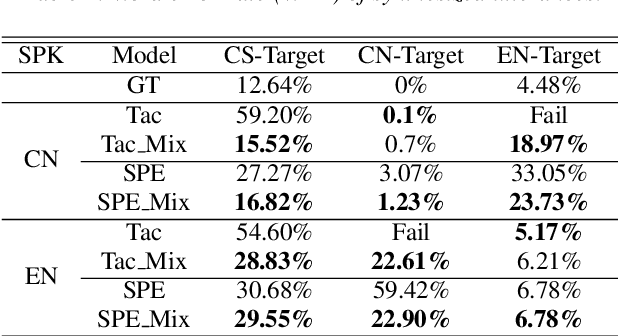
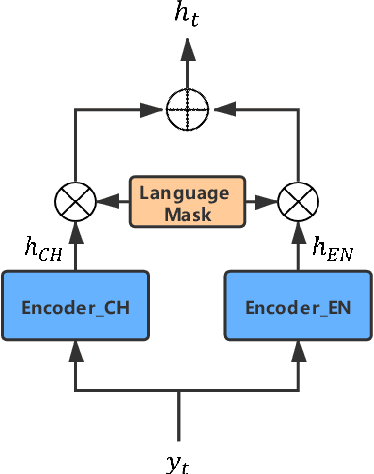
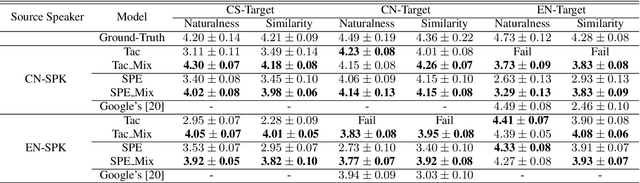
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.
PriMock57: A Dataset Of Primary Care Mock Consultations
Apr 01, 2022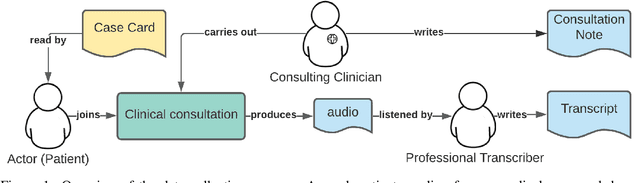
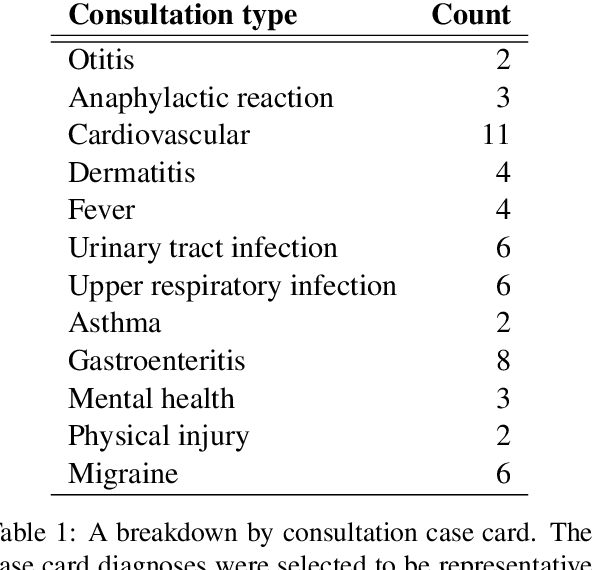

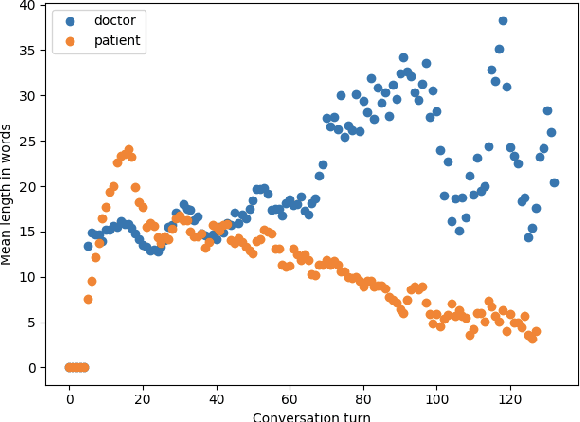
Recent advances in Automatic Speech Recognition (ASR) have made it possible to reliably produce automatic transcripts of clinician-patient conversations. However, access to clinical datasets is heavily restricted due to patient privacy, thus slowing down normal research practices. We detail the development of a public access, high quality dataset comprising of57 mocked primary care consultations, including audio recordings, their manual utterance-level transcriptions, and the associated consultation notes. Our work illustrates how the dataset can be used as a benchmark for conversational medical ASR as well as consultation note generation from transcripts.
Investigating Brain Connectivity with Graph Neural Networks and GNNExplainer
Jun 04, 2022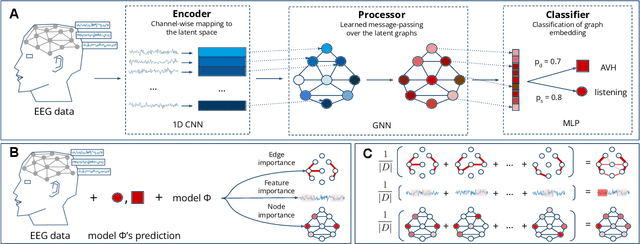
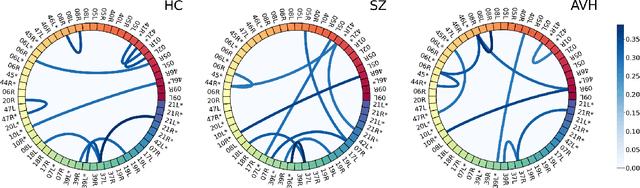
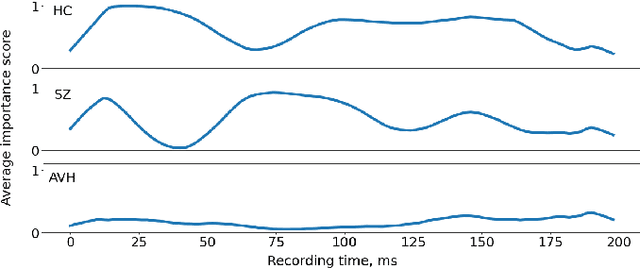
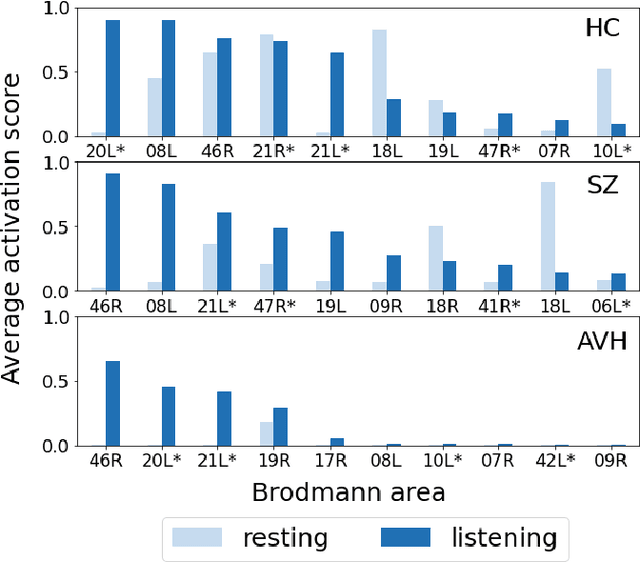
Functional connectivity plays an essential role in modern neuroscience. The modality sheds light on the brain's functional and structural aspects, including mechanisms behind multiple pathologies. One such pathology is schizophrenia which is often followed by auditory verbal hallucinations. The latter is commonly studied by observing functional connectivity during speech processing. In this work, we have made a step toward an in-depth examination of functional connectivity during a dichotic listening task via deep learning for three groups of people: schizophrenia patients with and without auditory verbal hallucinations and healthy controls. We propose a graph neural network-based framework within which we represent EEG data as signals in the graph domain. The framework allows one to 1) predict a brain mental disorder based on EEG recording, 2) differentiate the listening state from the resting state for each group and 3) recognize characteristic task-depending connectivity. Experimental results show that the proposed model can differentiate between the above groups with state-of-the-art performance. Besides, it provides a researcher with meaningful information regarding each group's functional connectivity, which we validated on the current domain knowledge.
Word Discovery in Visually Grounded, Self-Supervised Speech Models
Mar 28, 2022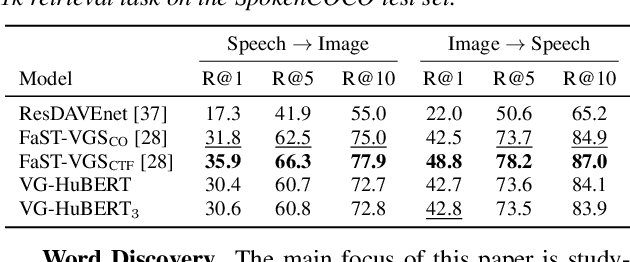

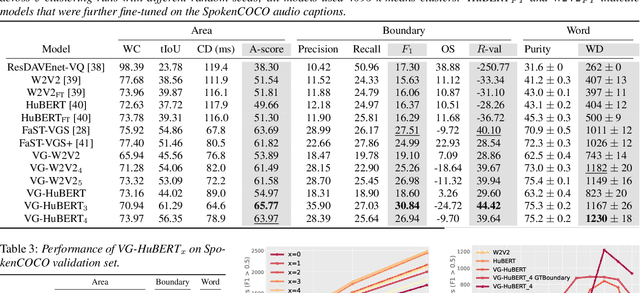
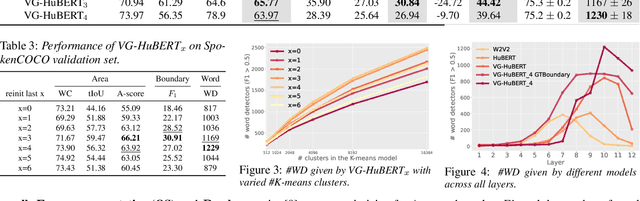
We present a method for visually-grounded spoken term discovery. After training either a HuBERT or wav2vec2.0 model to associate spoken captions with natural images, we show that powerful word segmentation and clustering capability emerges within the model's self-attention heads. Our experiments reveal that this ability is not present to nearly the same extent in the base HuBERT and wav2vec2.0 models, suggesting that the visual grounding task is a crucial component of the word discovery capability we observe. We also evaluate our method on the Buckeye word segmentation and ZeroSpeech spoken term discovery tasks, where we outperform all currently published methods on several metrics.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020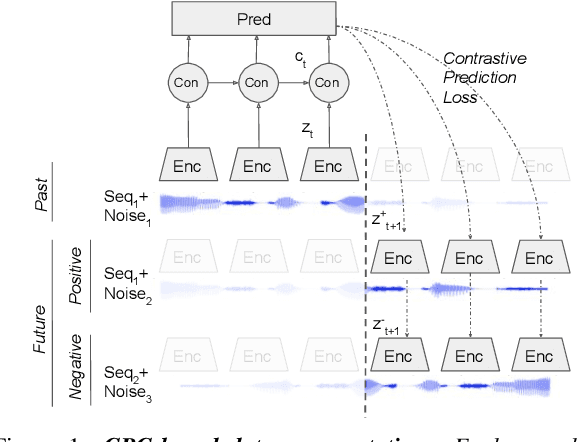
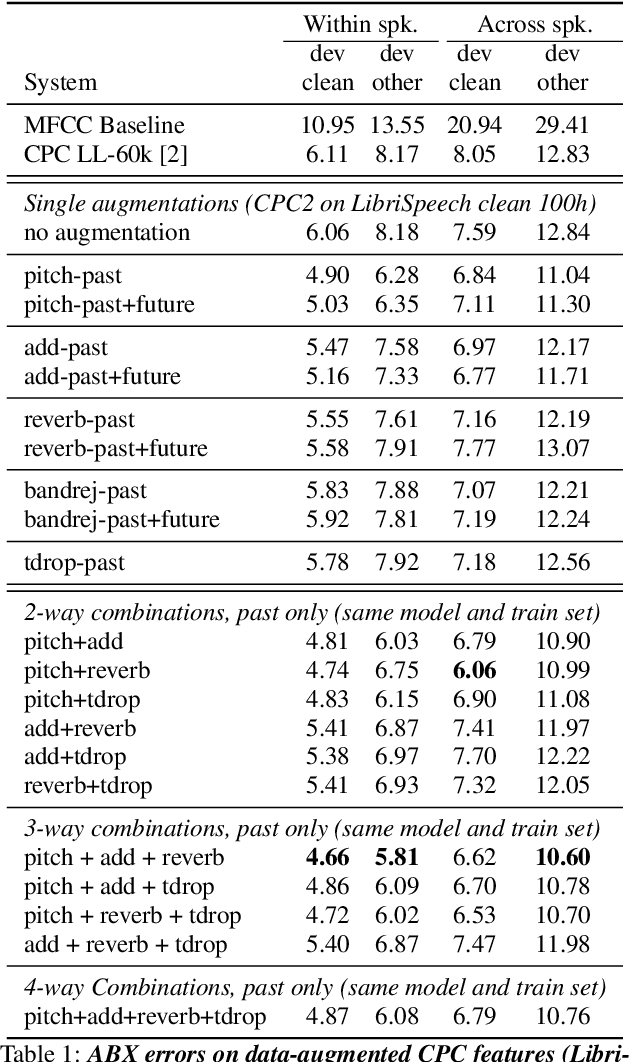
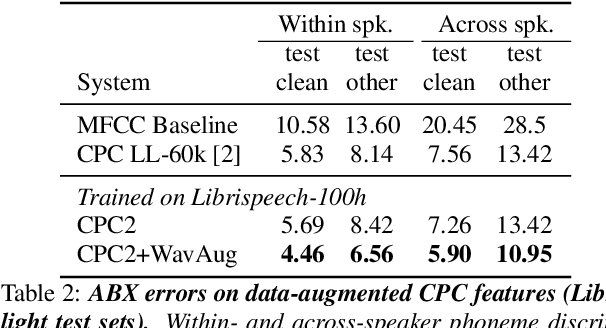
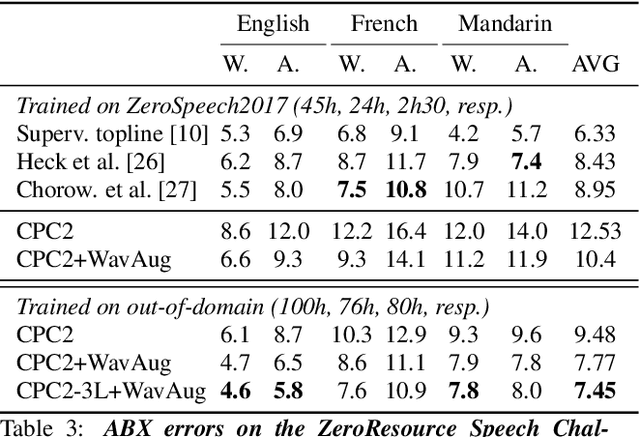
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.