 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Disfluencies and Human Speech Transcription Errors
Apr 08, 2019

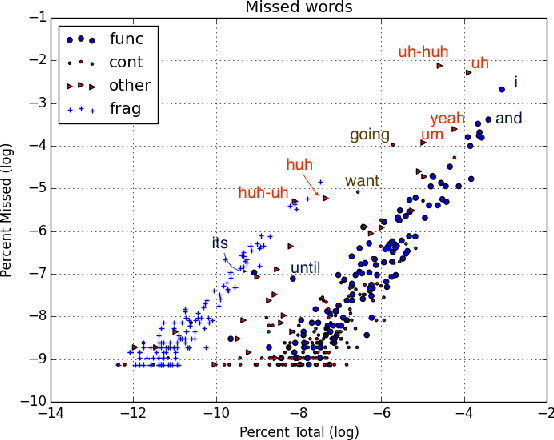
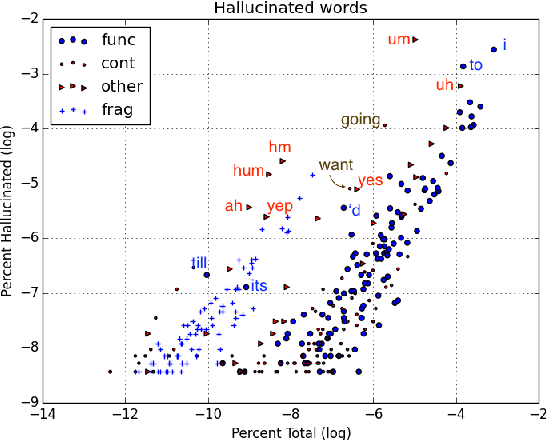
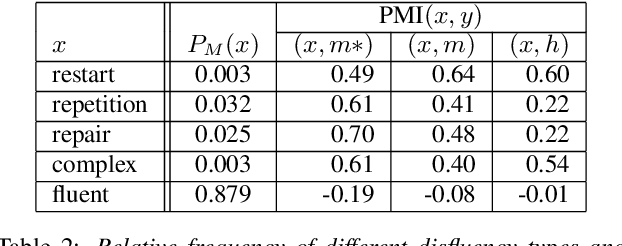
This paper explores contexts associated with errors in transcrip-tion of spontaneous speech, shedding light on human perceptionof disfluencies and other conversational speech phenomena. Anew version of the Switchboard corpus is provided with disfluency annotations for careful speech transcripts, together with results showing the impact of transcription errors on evaluation of automatic disfluency detection.
Comparison of Speech Representations for Automatic Quality Estimation in Multi-Speaker Text-to-Speech Synthesis
Feb 28, 2020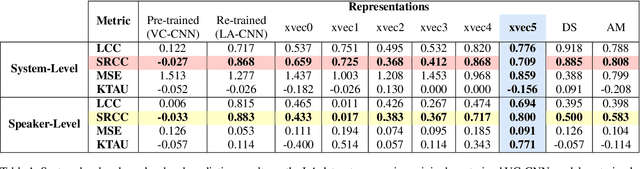
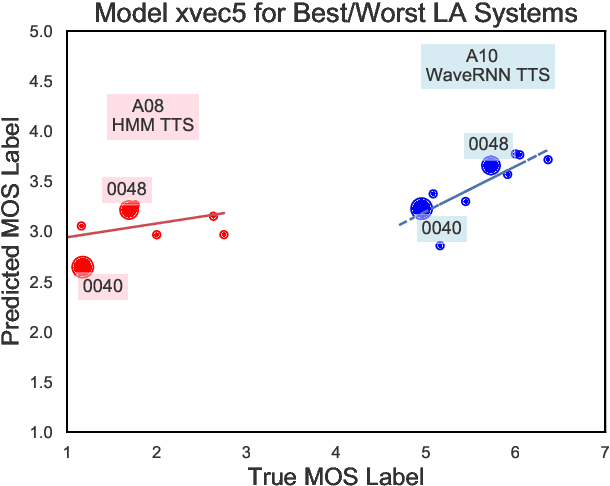

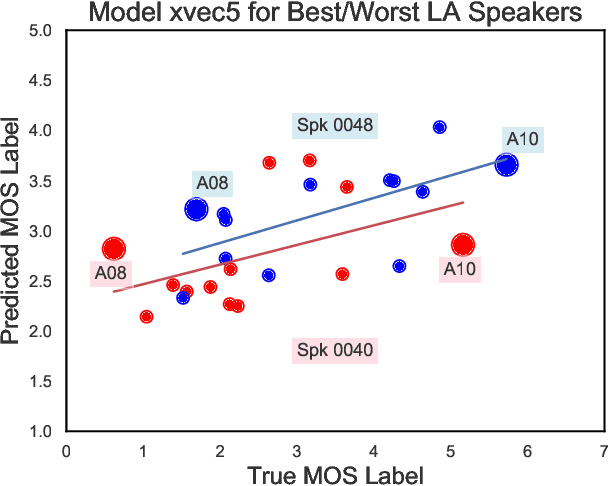
We aim to characterize how different speakers contribute to the perceived output quality of multi-speaker Text-to-Speech (TTS) synthesis. We automatically rate the quality of TTS using a neural network (NN) trained on human mean opinion score (MOS) ratings. First, we train and evaluate our NN model on 13 different TTS and voice conversion (VC) systems from the ASVSpoof 2019 Logical Access (LA) Dataset. Since it is not known how best to represent speech for this task, we compare 8 different representations alongside MOSNet frame-based features. Our representations include image-based spectrogram features and x-vector embeddings that explicitly model different types of noise such as T60 reverberation time. Our NN predicts MOS with a high correlation to human judgments. We report prediction correlation and error. A key finding is the quality achieved for certain speakers seems consistent, regardless of the TTS or VC system. It is widely accepted that some speakers give higher quality than others for building a TTS system: our method provides an automatic way to identify such speakers. Finally, to see if our quality prediction models generalize, we predict quality scores for synthetic speech using a separate multi-speaker TTS system that was trained on LibriTTS data, and conduct our own MOS listening test to compare human ratings with our NN predictions.
Transferring neural speech waveform synthesizers to musical instrument sounds generation
Oct 27, 2019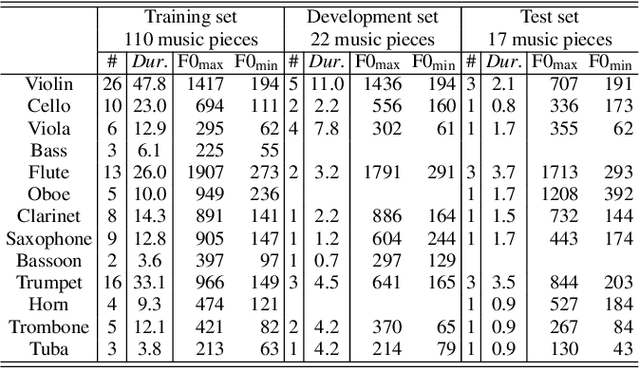
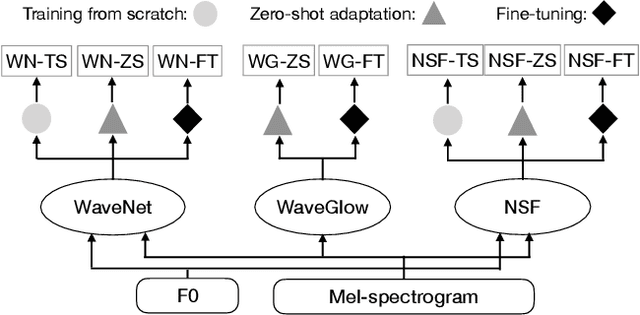
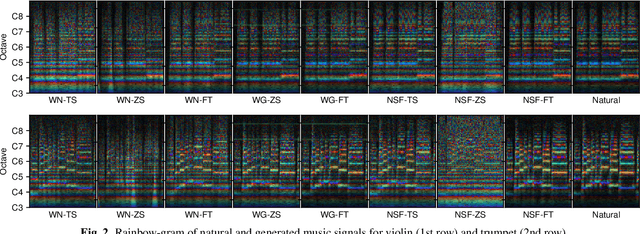
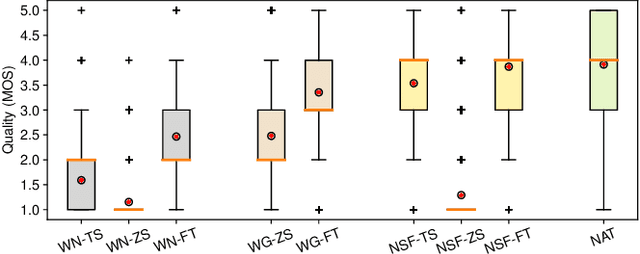
Recent neural waveform synthesizers such as WaveNet, WaveGlow, and the neural-source-filter (NSF) model have shown good performance in speech synthesis despite their different methods of waveform generation. The similarity between speech and music audio synthesis techniques suggests interesting avenues to explore in terms of the best way to apply speech synthesizers in the music domain. This work compares three neural synthesizers used for musical instrument sounds generation under three scenarios: training from scratch on music data, zero-shot learning from the speech domain, and fine-tuning-based adaptation from the speech to the music domain. The results of a large-scale perceptual test demonstrated that the performance of three synthesizers improved when they were pre-trained on speech data and fine-tuned on music data, which indicates the usefulness of knowledge from speech data for music audio generation. Among the synthesizers, WaveGlow showed the best potential in zero-shot learning while NSF performed best in the other scenarios and could generate samples that were perceptually close to natural audio.
PriMock57: A Dataset Of Primary Care Mock Consultations
Apr 01, 2022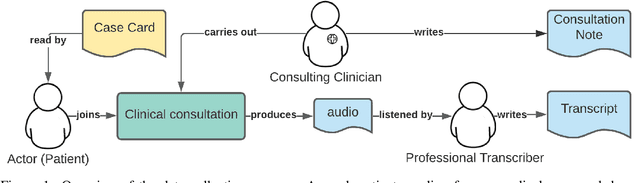
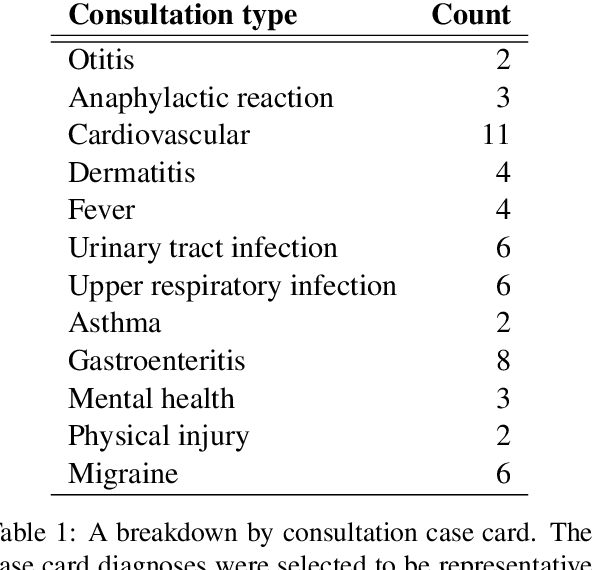

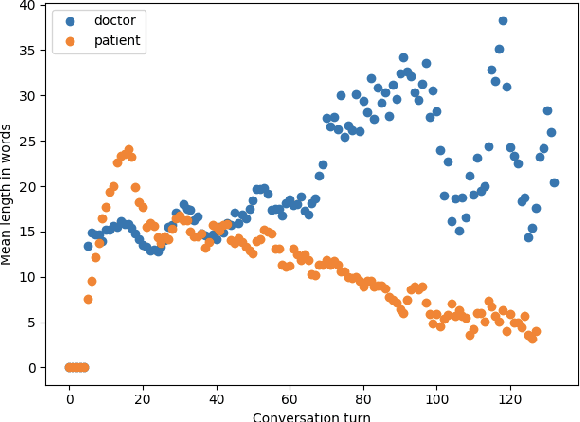
Recent advances in Automatic Speech Recognition (ASR) have made it possible to reliably produce automatic transcripts of clinician-patient conversations. However, access to clinical datasets is heavily restricted due to patient privacy, thus slowing down normal research practices. We detail the development of a public access, high quality dataset comprising of57 mocked primary care consultations, including audio recordings, their manual utterance-level transcriptions, and the associated consultation notes. Our work illustrates how the dataset can be used as a benchmark for conversational medical ASR as well as consultation note generation from transcripts.
Cross Lingual Cross Corpus Speech Emotion Recognition
Mar 18, 2020
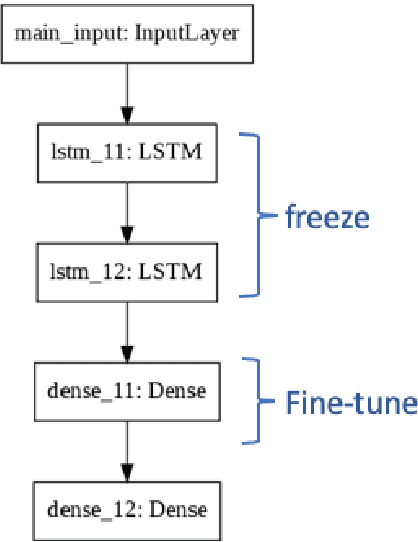
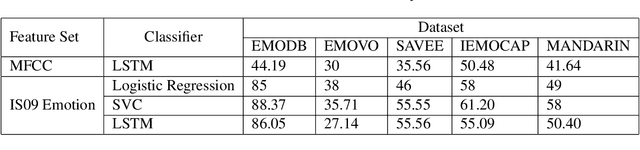
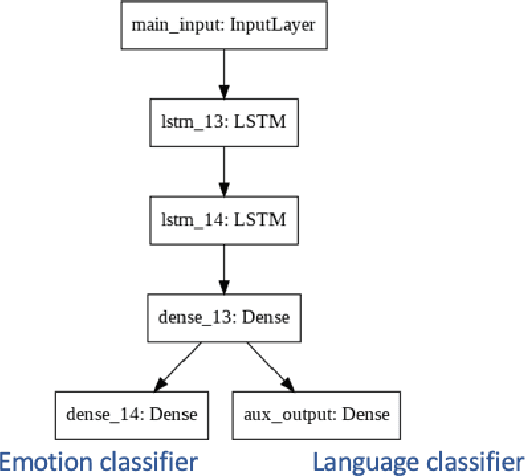
The majority of existing speech emotion recognition models are trained and evaluated on a single corpus and a single language setting. These systems do not perform as well when applied in a cross-corpus and cross-language scenario. This paper presents results for speech emotion recognition for 4 languages in both single corpus and cross corpus setting. Additionally, since multi-task learning (MTL) with gender, naturalness and arousal as auxiliary tasks has shown to enhance the generalisation capabilities of the emotion models, this paper introduces language ID as another auxiliary task in MTL framework to explore the role of spoken language on emotion recognition which has not been studied yet.
Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
Nov 26, 2019

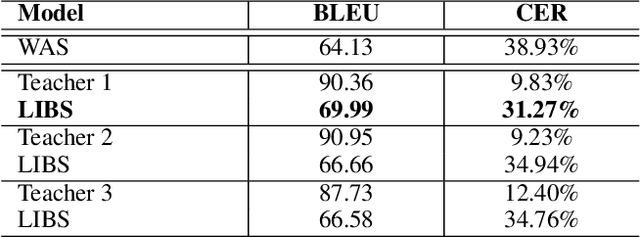

Lip reading has witnessed unparalleled development in recent years thanks to deep learning and the availability of large-scale datasets. Despite the encouraging results achieved, the performance of lip reading, unfortunately, remains inferior to the one of its counterpart speech recognition, due to the ambiguous nature of its actuations that makes it challenging to extract discriminant features from the lip movement videos. In this paper, we propose a new method, termed as Lip by Speech (LIBS), of which the goal is to strengthen lip reading by learning from speech recognizers. The rationale behind our approach is that the features extracted from speech recognizers may provide complementary and discriminant clues, which are formidable to be obtained from the subtle movements of the lips, and consequently facilitate the training of lip readers. This is achieved, specifically, by distilling multi-granularity knowledge from speech recognizers to lip readers. To conduct this cross-modal knowledge distillation, we utilize an efficacious alignment scheme to handle the inconsistent lengths of the audios and videos, as well as an innovative filtering strategy to refine the speech recognizer's prediction. The proposed method achieves the new state-of-the-art performance on the CMLR and LRS2 datasets, outperforming the baseline by a margin of 7.66% and 2.75% in character error rate, respectively.
Multi-speaker Text-to-speech Synthesis Using Deep Gaussian Processes
Aug 07, 2020Multi-speaker speech synthesis is a technique for modeling multiple speakers' voices with a single model. Although many approaches using deep neural networks (DNNs) have been proposed, DNNs are prone to overfitting when the amount of training data is limited. We propose a framework for multi-speaker speech synthesis using deep Gaussian processes (DGPs); a DGP is a deep architecture of Bayesian kernel regressions and thus robust to overfitting. In this framework, speaker information is fed to duration/acoustic models using speaker codes. We also examine the use of deep Gaussian process latent variable models (DGPLVMs). In this approach, the representation of each speaker is learned simultaneously with other model parameters, and therefore the similarity or dissimilarity of speakers is considered efficiently. We experimentally evaluated two situations to investigate the effectiveness of the proposed methods. In one situation, the amount of data from each speaker is balanced (speaker-balanced), and in the other, the data from certain speakers are limited (speaker-imbalanced). Subjective and objective evaluation results showed that both the DGP and DGPLVM synthesize multi-speaker speech more effective than a DNN in the speaker-balanced situation. We also found that the DGPLVM outperforms the DGP significantly in the speaker-imbalanced situation.
Improve Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Oct 14, 2021
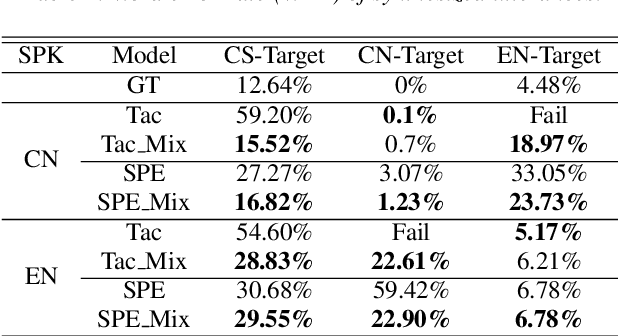
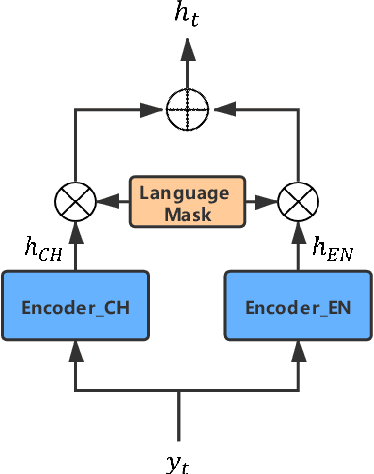
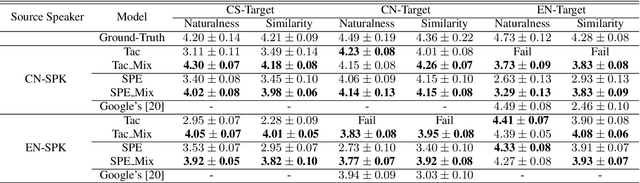
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.
Improving Cross-Lingual Transfer Learning for End-to-End Speech Recognition with Speech Translation
Jun 09, 2020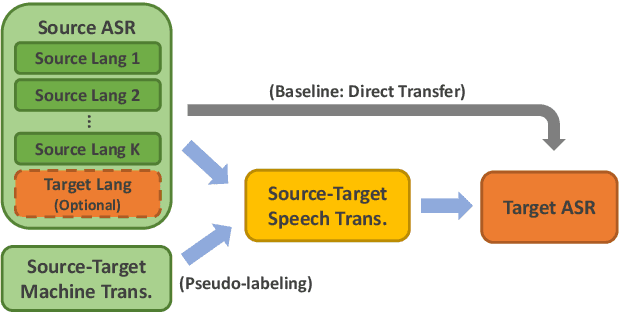
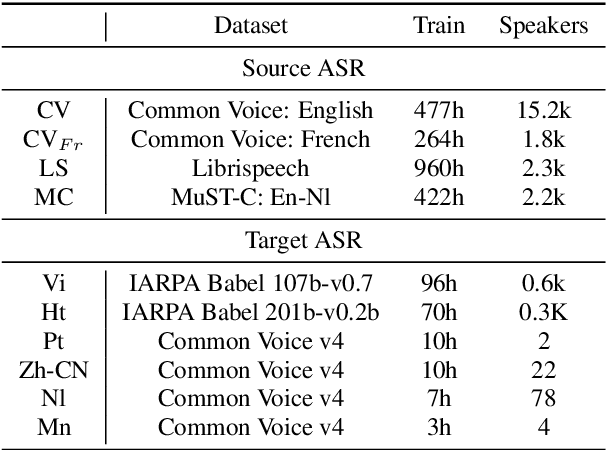
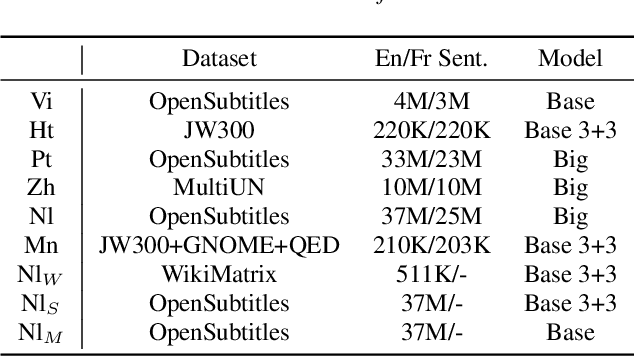
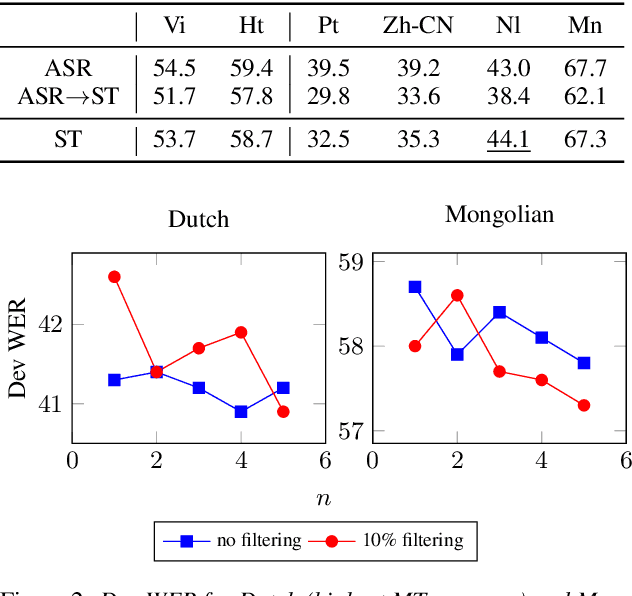
Transfer learning from high-resource languages is known to be an efficient way to improve end-to-end automatic speech recognition (ASR) for low-resource languages. Pre-trained or jointly trained encoder-decoder models, however, do not share the language modeling (decoder) for the same language, which is likely to be inefficient for distant target languages. We introduce speech-to-text translation (ST) as an auxiliary task to incorporate additional knowledge of the target language and enable transferring from that target language. Specifically, we first translate high-resource ASR transcripts into a target low-resource language, with which a ST model is trained. Both ST and target ASR share the same attention-based encoder-decoder architecture and vocabulary. The former task then provides a fully pre-trained model for the latter, bringing up to 24.6% word error rate (WER) reduction to the baseline (direct transfer from high-resource ASR). We show that training ST with human translations is not necessary. ST trained with machine translation (MT) pseudo-labels brings consistent gains. It can even outperform those using human labels when transferred to target ASR by leveraging only 500K MT examples. Even with pseudo-labels from low-resource MT (200K examples), ST-enhanced transfer brings up to 8.9% WER reduction to direct transfer.
Word Discovery in Visually Grounded, Self-Supervised Speech Models
Mar 28, 2022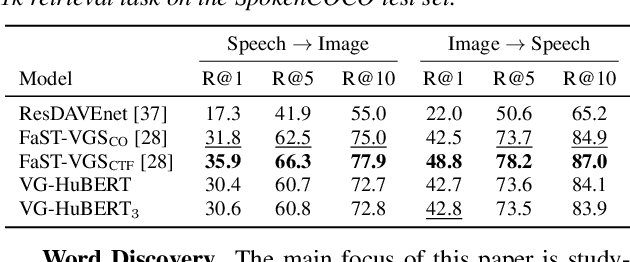

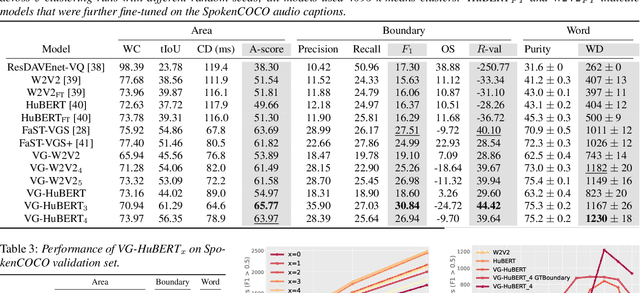
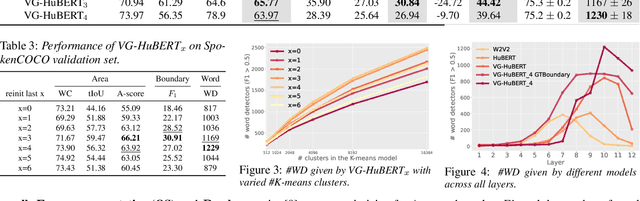
We present a method for visually-grounded spoken term discovery. After training either a HuBERT or wav2vec2.0 model to associate spoken captions with natural images, we show that powerful word segmentation and clustering capability emerges within the model's self-attention heads. Our experiments reveal that this ability is not present to nearly the same extent in the base HuBERT and wav2vec2.0 models, suggesting that the visual grounding task is a crucial component of the word discovery capability we observe. We also evaluate our method on the Buckeye word segmentation and ZeroSpeech spoken term discovery tasks, where we outperform all currently published methods on several metrics.