 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Comparison of Speech Representations for Automatic Quality Estimation in Multi-Speaker Text-to-Speech Synthesis
Feb 28, 2020
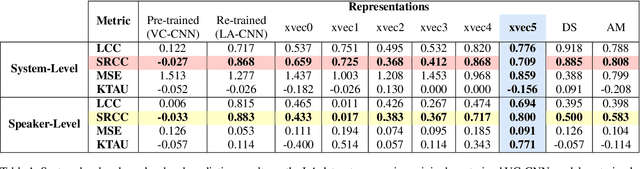
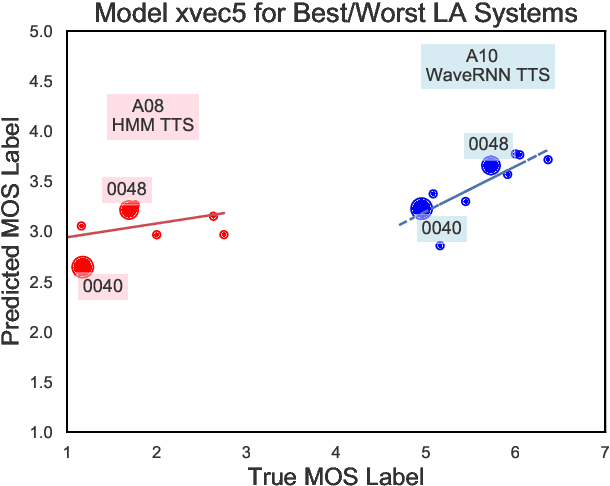

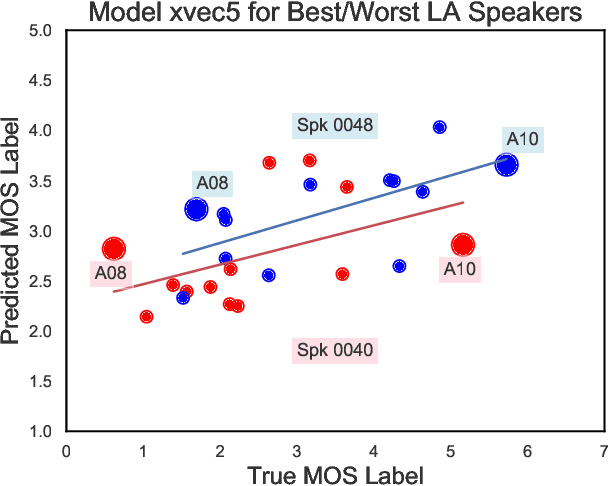
We aim to characterize how different speakers contribute to the perceived output quality of multi-speaker Text-to-Speech (TTS) synthesis. We automatically rate the quality of TTS using a neural network (NN) trained on human mean opinion score (MOS) ratings. First, we train and evaluate our NN model on 13 different TTS and voice conversion (VC) systems from the ASVSpoof 2019 Logical Access (LA) Dataset. Since it is not known how best to represent speech for this task, we compare 8 different representations alongside MOSNet frame-based features. Our representations include image-based spectrogram features and x-vector embeddings that explicitly model different types of noise such as T60 reverberation time. Our NN predicts MOS with a high correlation to human judgments. We report prediction correlation and error. A key finding is the quality achieved for certain speakers seems consistent, regardless of the TTS or VC system. It is widely accepted that some speakers give higher quality than others for building a TTS system: our method provides an automatic way to identify such speakers. Finally, to see if our quality prediction models generalize, we predict quality scores for synthetic speech using a separate multi-speaker TTS system that was trained on LibriTTS data, and conduct our own MOS listening test to compare human ratings with our NN predictions.
FastSpeech 2: Fast and High-Quality End-to-End Text-to-Speech
Jun 08, 2020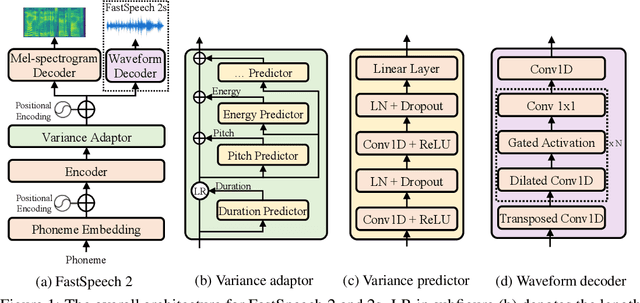
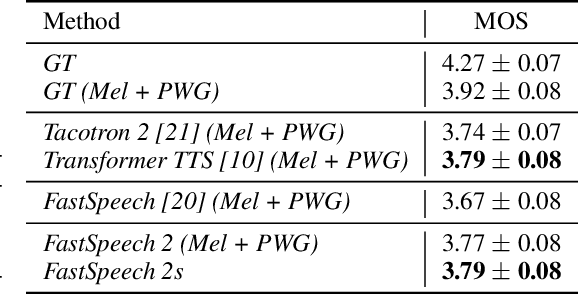
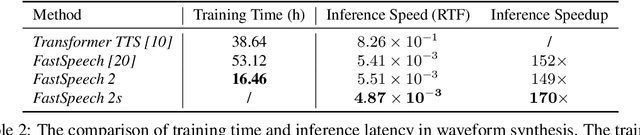
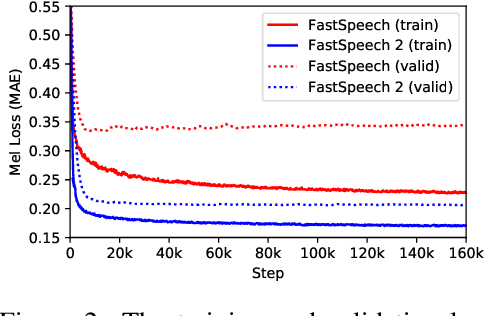
Advanced text-to-speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs during training and use predicted values during inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of full end-to-end training and even faster inference than FastSpeech. Experimental results show that 1) FastSpeech 2 and 2s outperform FastSpeech in voice quality with much simplified training pipeline and reduced training time; 2) FastSpeech 2 and 2s can match the voice quality of autoregressive models while enjoying much faster inference speed.
Latency-Controlled Neural Architecture Search for Streaming Speech Recognition
May 08, 2021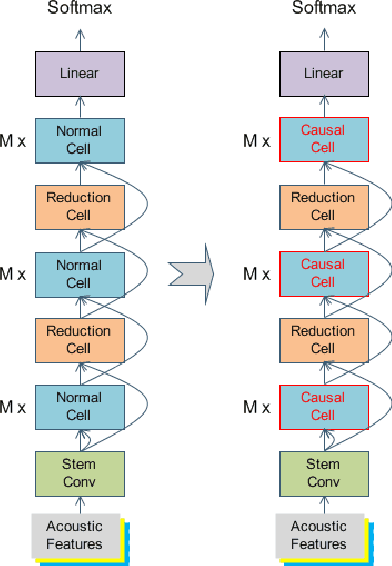


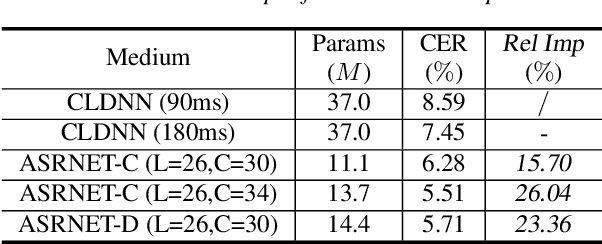
Recently, neural architecture search (NAS) has attracted much attention and has been explored for automatic speech recognition (ASR). Our prior work has shown promising results compared with hand-designed neural networks. In this work, we focus on streaming ASR scenarios and propose the latency-controlled NAS for acoustic modeling. First, based on the vanilla neural architecture, normal cells are altered to be causal cells, in order to control the total latency of the neural network. Second, a revised operation space with a smaller receptive field is proposed to generate the final architecture with low latency. Extensive experiments show that: 1) Based on the proposed neural architecture, the neural networks with a medium latency of 550ms (millisecond) and a low latency of 190ms can be learned in the vanilla and revised operation space respectively. 2) For the low latency setting, the evaluation network can achieve more than 19\% (average on the four test sets) relative improvements compared with the hybrid CLDNN baseline, on a 10k-hour large-scale dataset. Additional 11\% relative improvements can be achieved if the latency of the neural network is relaxed to the medium latency setting.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
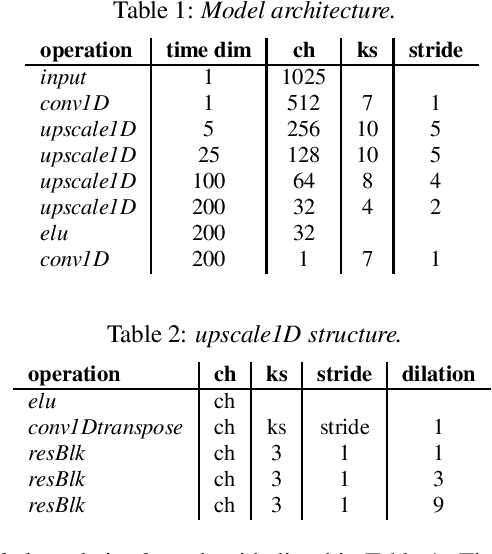
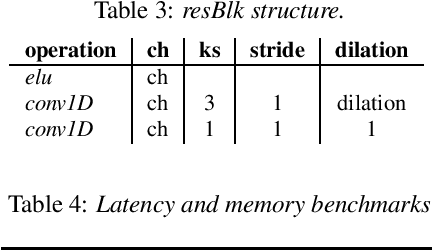

With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.
DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality metric to evaluate Noise Suppressors
Oct 28, 2020
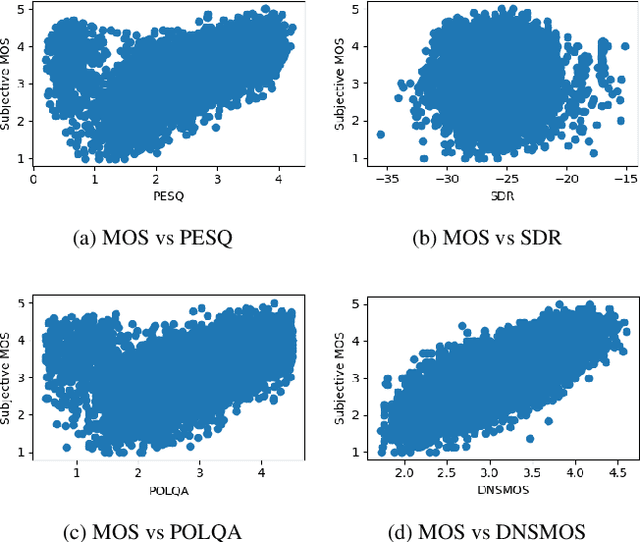
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. The conventional and widely used metrics require a reference clean speech signal, which is unavailable in real recordings. The no-reference approaches correlate poorly with human ratings and are not widely adopted in the research community. One of the biggest use cases of these perceptual objective metrics is to evaluate noise suppression algorithms. This paper introduces a multi-stage self-teaching based perceptual objective metric that is designed to evaluate noise suppressors. The proposed method generalizes well in challenging test conditions with a high correlation to human ratings.
Cross Lingual Cross Corpus Speech Emotion Recognition
Mar 18, 2020
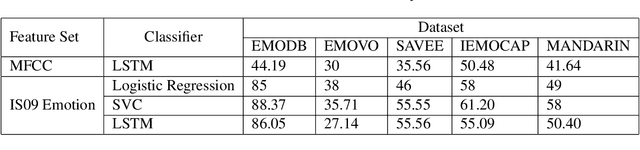
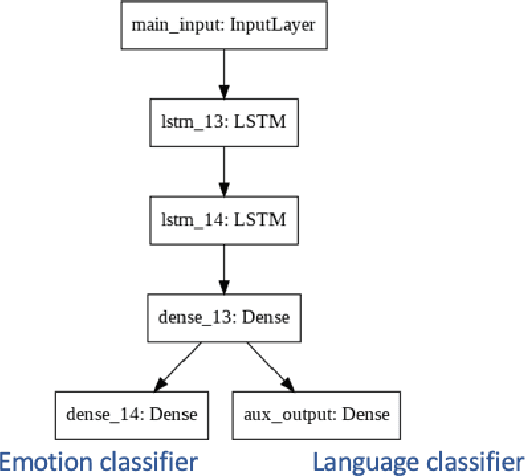
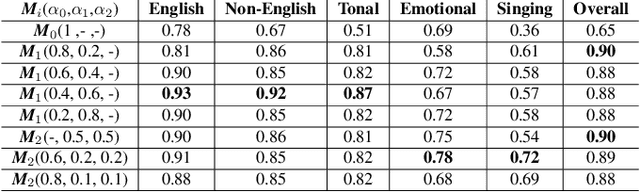
The majority of existing speech emotion recognition models are trained and evaluated on a single corpus and a single language setting. These systems do not perform as well when applied in a cross-corpus and cross-language scenario. This paper presents results for speech emotion recognition for 4 languages in both single corpus and cross corpus setting. Additionally, since multi-task learning (MTL) with gender, naturalness and arousal as auxiliary tasks has shown to enhance the generalisation capabilities of the emotion models, this paper introduces language ID as another auxiliary task in MTL framework to explore the role of spoken language on emotion recognition which has not been studied yet.
Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
Nov 26, 2019

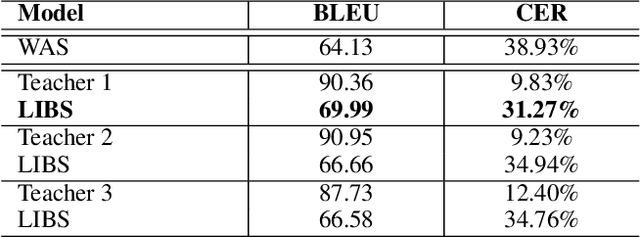

Lip reading has witnessed unparalleled development in recent years thanks to deep learning and the availability of large-scale datasets. Despite the encouraging results achieved, the performance of lip reading, unfortunately, remains inferior to the one of its counterpart speech recognition, due to the ambiguous nature of its actuations that makes it challenging to extract discriminant features from the lip movement videos. In this paper, we propose a new method, termed as Lip by Speech (LIBS), of which the goal is to strengthen lip reading by learning from speech recognizers. The rationale behind our approach is that the features extracted from speech recognizers may provide complementary and discriminant clues, which are formidable to be obtained from the subtle movements of the lips, and consequently facilitate the training of lip readers. This is achieved, specifically, by distilling multi-granularity knowledge from speech recognizers to lip readers. To conduct this cross-modal knowledge distillation, we utilize an efficacious alignment scheme to handle the inconsistent lengths of the audios and videos, as well as an innovative filtering strategy to refine the speech recognizer's prediction. The proposed method achieves the new state-of-the-art performance on the CMLR and LRS2 datasets, outperforming the baseline by a margin of 7.66% and 2.75% in character error rate, respectively.
Semantic Characteristics of Schizophrenic Speech
Apr 16, 2019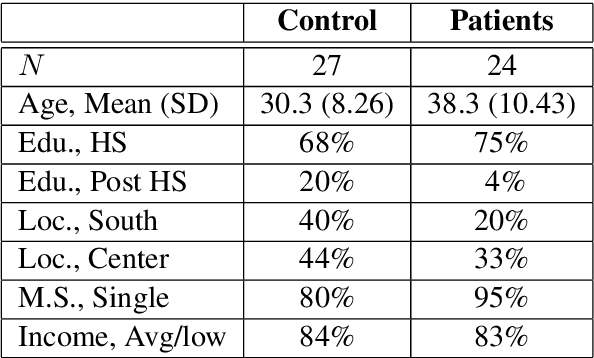
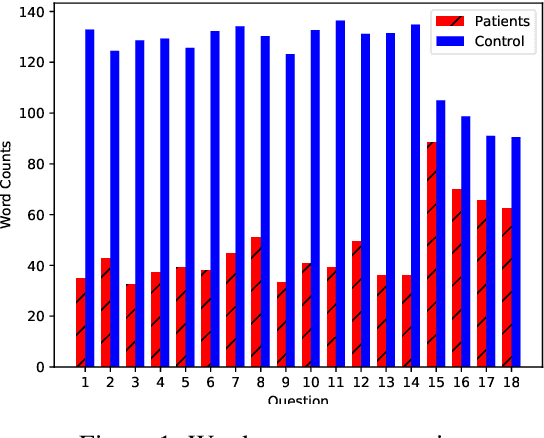

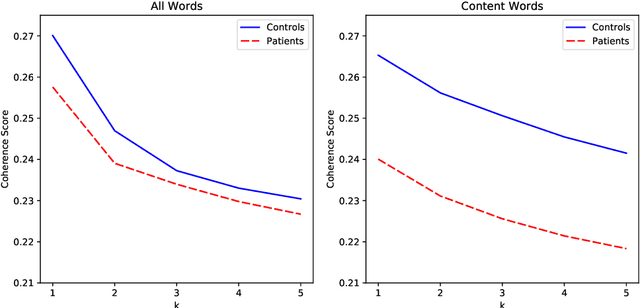
Natural language processing tools are used to automatically detect disturbances in transcribed speech of schizophrenia inpatients who speak Hebrew. We measure topic mutation over time and show that controls maintain more cohesive speech than inpatients. We also examine differences in how inpatients and controls use adjectives and adverbs to describe content words and show that the ones used by controls are more common than the those of inpatients. We provide experimental results and show their potential for automatically detecting schizophrenia in patients by means only of their speech patterns.
Reduction of Subjective Listening Effort for TV Broadcast Signals with Recurrent Neural Networks
Nov 02, 2021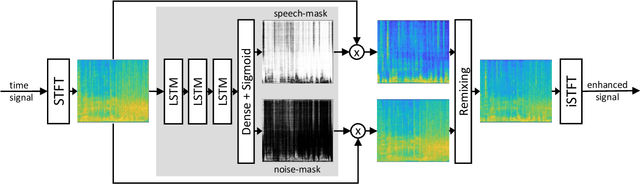
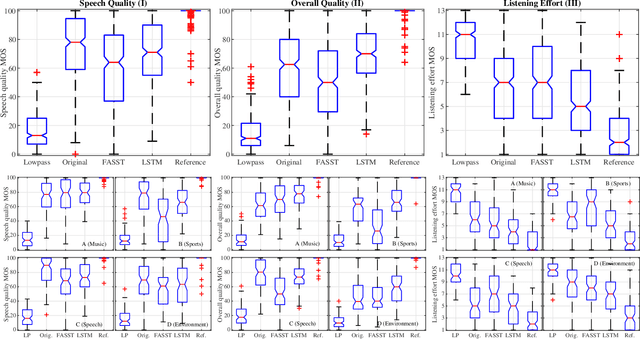


Listening to the audio of TV broadcast signals can be challenging for hearing-impaired as well as normal-hearing listeners, especially when background sounds are prominent or too loud compared to the speech signal. This can result in a reduced satisfaction and increased listening effort of the listeners. Since the broadcast sound is usually premixed, we perform a subjective evaluation for quantifying the potential of speech enhancement systems based on audio source separation and recurrent neural networks (RNN). Recently, RNNs have shown promising results in the context of sound source separation and real-time signal processing. In this paper, we separate the speech from the background signals and remix the separated sounds at a higher signal-to-noise ratio. This differs from classic speech enhancement, where usually only the extracted speech signal is exploited. The subjective evaluation with 20 normal-hearing subjects on real TV-broadcast material shows that our proposed enhancement system is able to reduce the listening effort by around 2 points on a 13-point listening effort rating scale and increases the perceived sound quality compared to the original mixture.
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition
Dec 03, 2020
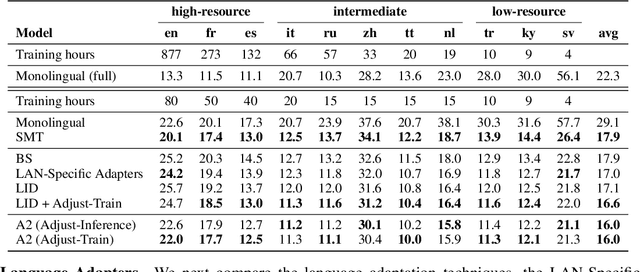
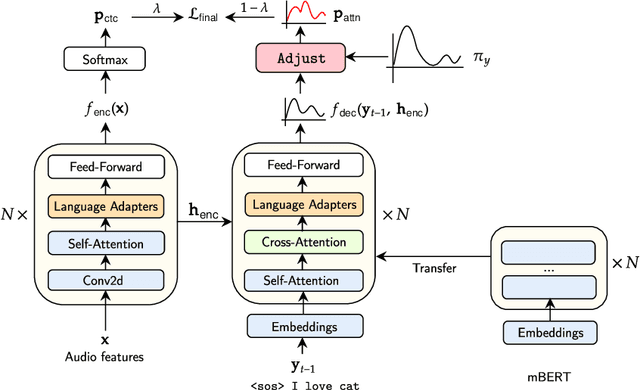
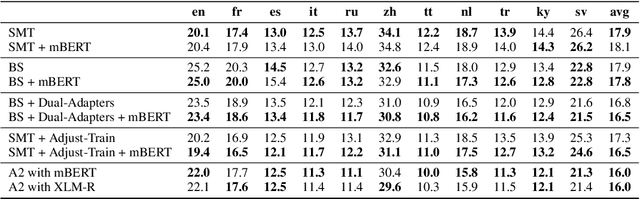
One crucial challenge of real-world multilingual speech recognition is the long-tailed distribution problem, where some resource-rich languages like English have abundant training data, but a long tail of low-resource languages have varying amounts of limited training data. To overcome the long-tail problem, in this paper, we propose Adapt-and-Adjust (A2), a transformer-based multi-task learning framework for end-to-end multilingual speech recognition. The A2 framework overcomes the long-tail problem via three techniques: (1) exploiting a pretrained multilingual language model (mBERT) to improve the performance of low-resource languages; (2) proposing dual adapters consisting of both language-specific and language-agnostic adaptation with minimal additional parameters; and (3) overcoming the class imbalance, either by imposing class priors in the loss during training or adjusting the logits of the softmax output during inference. Extensive experiments on the CommonVoice corpus show that A2 significantly outperforms conventional approaches.