 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Unified Speaker Adaptation Method for Speech Synthesis using Transcribed and Untranscribed Speech with Backpropagation
Jun 18, 2019
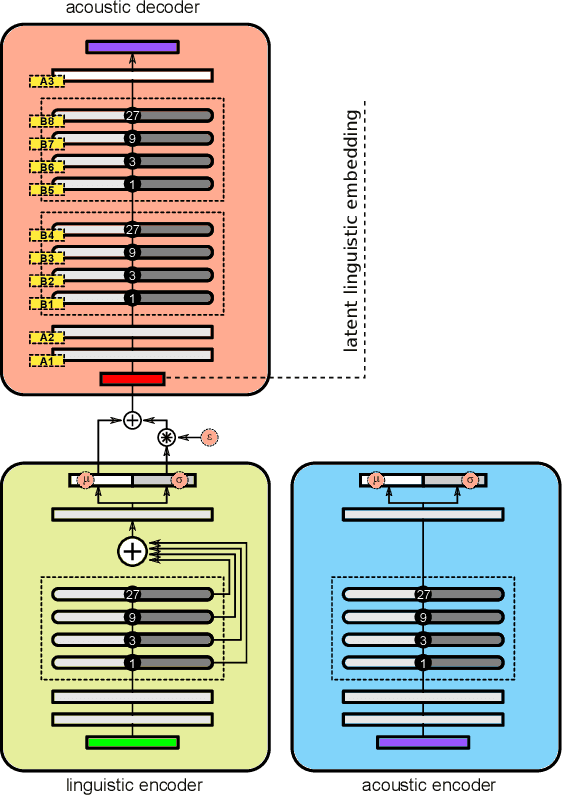
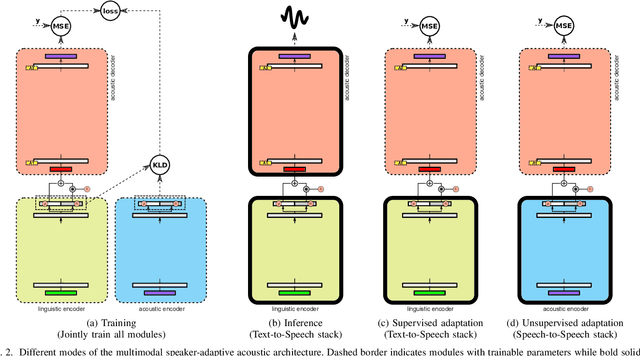
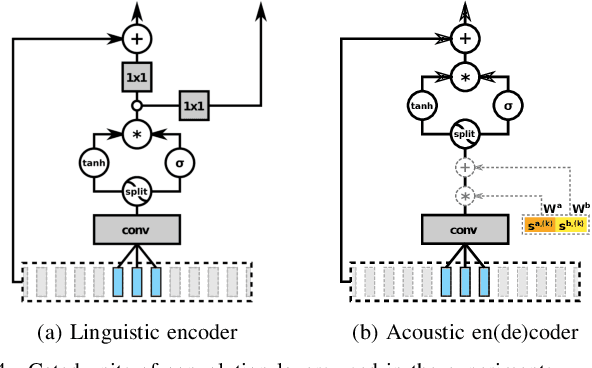
By representing speaker characteristic as a single fixed-length vector extracted solely from speech, we can train a neural multi-speaker speech synthesis model by conditioning the model on those vectors. This model can also be adapted to unseen speakers regardless of whether the transcript of adaptation data is available or not. However, this setup restricts the speaker component to just a single bias vector, which in turn limits the performance of adaptation process. In this study, we propose a novel speech synthesis model, which can be adapted to unseen speakers by fine-tuning part of or all of the network using either transcribed or untranscribed speech. Our methodology essentially consists of two steps: first, we split the conventional acoustic model into a speaker-independent (SI) linguistic encoder and a speaker-adaptive (SA) acoustic decoder; second, we train an auxiliary acoustic encoder that can be used as a substitute for the linguistic encoder whenever linguistic features are unobtainable. The results of objective and subjective evaluations show that adaptation using either transcribed or untranscribed speech with our methodology achieved a reasonable level of performance with an extremely limited amount of data and greatly improved performance with more data. Surprisingly, adaptation with untranscribed speech surpassed the transcribed counterpart in the subjective test, which reveals the limitations of the conventional acoustic model and hints at potential directions for improvements.
FAIR4Cov: Fused Audio Instance and Representation for COVID-19 Detection
Apr 22, 2022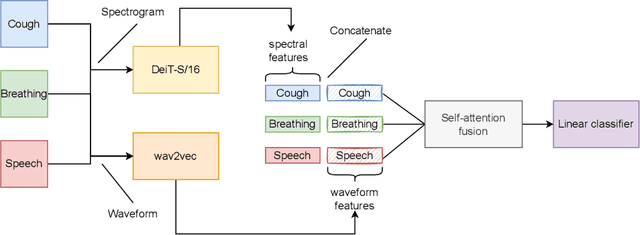
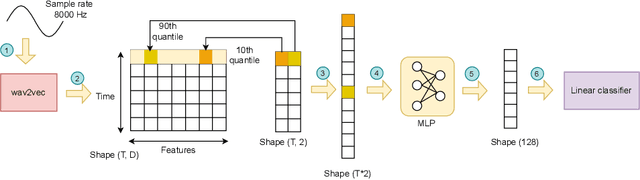
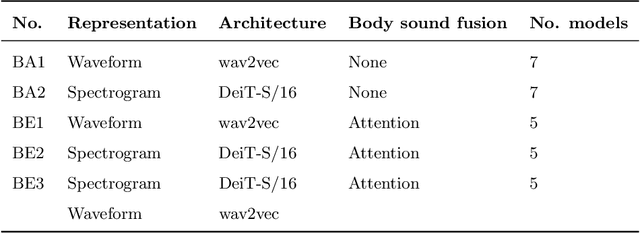
Audio-based classification techniques on body sounds have long been studied to support diagnostic decisions, particularly in pulmonary diseases. In response to the urgency of the COVID-19 pandemic, a growing number of models are developed to identify COVID-19 patients based on acoustic input. Most models focus on cough because the dry cough is the best-known symptom of COVID-19. However, other body sounds, such as breath and speech, have also been revealed to correlate with COVID-19 as well. In this work, rather than relying on a specific body sound, we propose Fused Audio Instance and Representation for COVID-19 Detection (FAIR4Cov). It relies on constructing a joint feature vector obtained from a plurality of body sounds in waveform and spectrogram representation. The core component of FAIR4Cov is a self-attention fusion unit that is trained to establish the relation of multiple body sounds and audio representations and integrate it into a compact feature vector. We set up our experiments on different combinations of body sounds using only waveform, spectrogram, and a joint representation of waveform and spectrogram. Our findings show that the use of self-attention to combine extracted features from cough, breath, and speech sounds leads to the best performance with an Area Under the Receiver Operating Characteristic Curve (AUC) score of 0.8658, a sensitivity of 0.8057, and a specificity of 0.7958. This AUC is 0.0227 higher than the one of the models trained on spectrograms only and 0.0847 higher than the one of the models trained on waveforms only. The results demonstrate that the combination of spectrogram with waveform representation helps to enrich the extracted features and outperforms the models with single representation.
Exploring Speech Enhancement with Generative Adversarial Networks for Robust Speech Recognition
Oct 31, 2018



We investigate the effectiveness of generative adversarial networks (GANs) for speech enhancement, in the context of improving noise robustness of automatic speech recognition (ASR) systems. Prior work demonstrates that GANs can effectively suppress additive noise in raw waveform speech signals, improving perceptual quality metrics; however this technique was not justified in the context of ASR. In this work, we conduct a detailed study to measure the effectiveness of GANs in enhancing speech contaminated by both additive and reverberant noise. Motivated by recent advances in image processing, we propose operating GANs on log-Mel filterbank spectra instead of waveforms, which requires less computation and is more robust to reverberant noise. While GAN enhancement improves the performance of a clean-trained ASR system on noisy speech, it falls short of the performance achieved by conventional multi-style training (MTR). By appending the GAN-enhanced features to the noisy inputs and retraining, we achieve a 7% WER improvement relative to the MTR system.
Large scale evaluation of importance maps in automatic speech recognition
May 21, 2020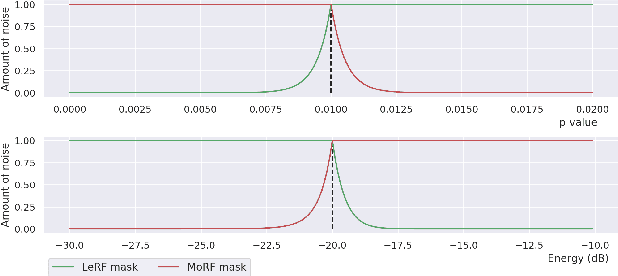
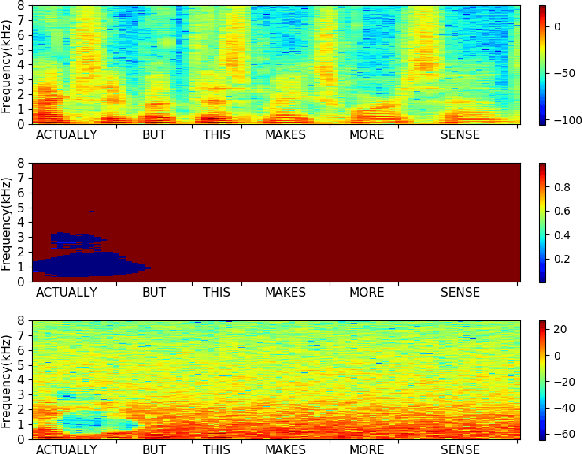
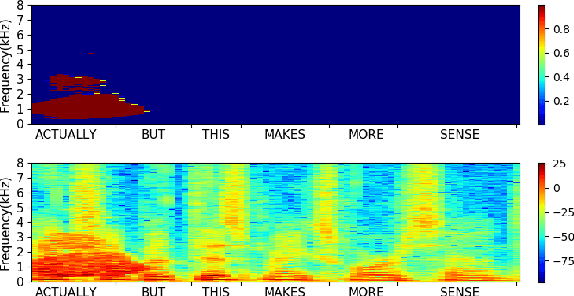
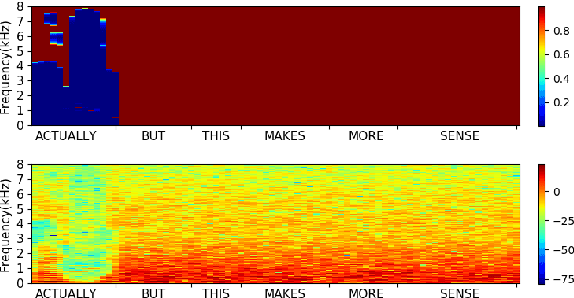
In this paper, we propose a metric that we call the structured saliency benchmark (SSBM) to evaluate importance maps computed for automatic speech recognizers on individual utterances. These maps indicate time-frequency points of the utterance that are most important for correct recognition of a target word. Our evaluation technique is not only suitable for standard classification tasks, but is also appropriate for structured prediction tasks like sequence-to-sequence models. Additionally, we use this approach to perform a large scale comparison of the importance maps created by our previously introduced technique using "bubble noise" to identify important points through correlation with a baseline approach based on smoothed speech energy and forced alignment. Our results show that the bubble analysis approach is better at identifying important speech regions than this baseline on 100 sentences from the AMI corpus.
Bayesian Transformer Language Models for Speech Recognition
Feb 09, 2021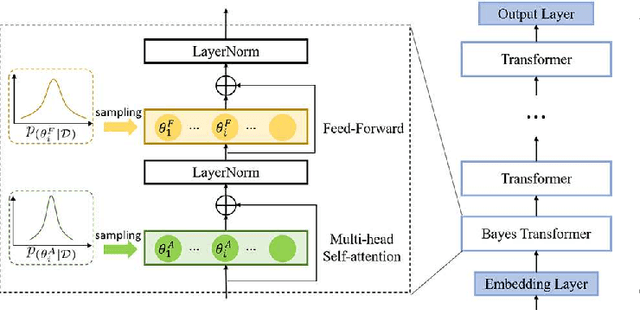
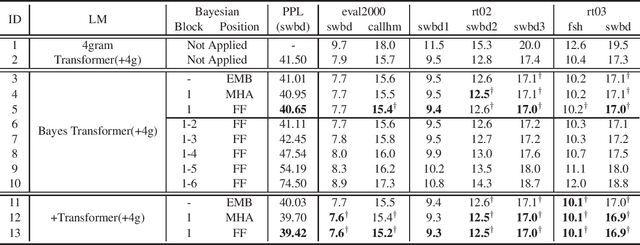
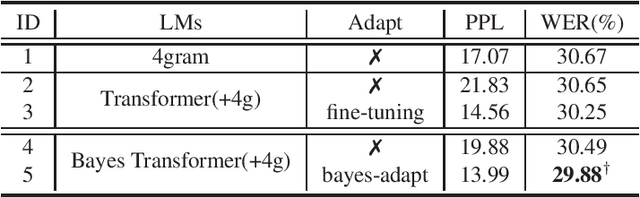
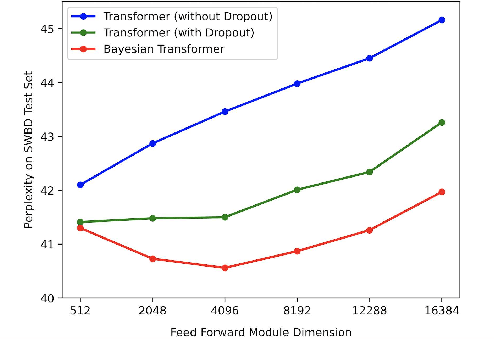
State-of-the-art neural language models (LMs) represented by Transformers are highly complex. Their use of fixed, deterministic parameter estimates fail to account for model uncertainty and lead to over-fitting and poor generalization when given limited training data. In order to address these issues, this paper proposes a full Bayesian learning framework for Transformer LM estimation. Efficient variational inference based approaches are used to estimate the latent parameter posterior distributions associated with different parts of the Transformer model architecture including multi-head self-attention, feed forward and embedding layers. Statistically significant word error rate (WER) reductions up to 0.5\% absolute (3.18\% relative) and consistent perplexity gains were obtained over the baseline Transformer LMs on state-of-the-art Switchboard corpus trained LF-MMI factored TDNN systems with i-Vector speaker adaptation. Performance improvements were also obtained on a cross domain LM adaptation task requiring porting a Transformer LM trained on the Switchboard and Fisher data to a low-resource DementiaBank elderly speech corpus.
Learning Alignment for Multimodal Emotion Recognition from Speech
Sep 06, 2019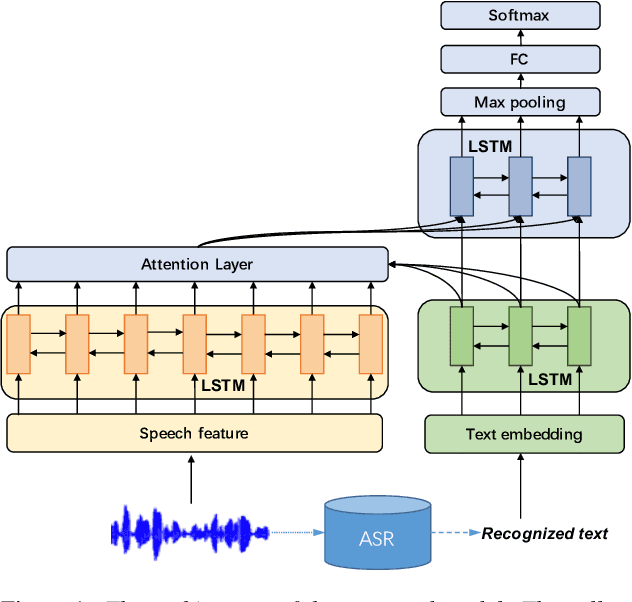
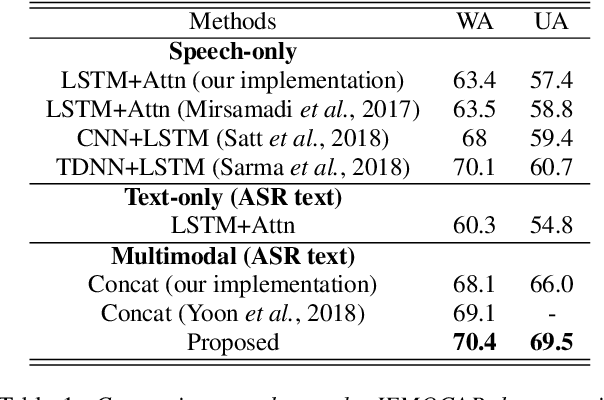
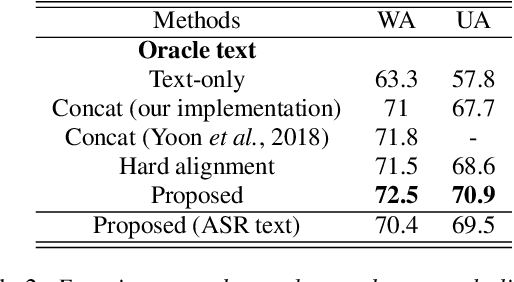
Speech emotion recognition is a challenging problem because human convey emotions in subtle and complex ways. For emotion recognition on human speech, one can either extract emotion related features from audio signals or employ speech recognition techniques to generate text from speech and then apply natural language processing to analyze the sentiment. Further, emotion recognition will be beneficial from using audio-textual multimodal information, it is not trivial to build a system to learn from multimodality. One can build models for two input sources separately and combine them in a decision level, but this method ignores the interaction between speech and text in the temporal domain. In this paper, we propose to use an attention mechanism to learn the alignment between speech frames and text words, aiming to produce more accurate multimodal feature representations. The aligned multimodal features are fed into a sequential model for emotion recognition. We evaluate the approach on the IEMOCAP dataset and the experimental results show the proposed approach achieves the state-of-the-art performance on the dataset.
NLP-CUET@LT-EDI-EACL2021: Multilingual Code-Mixed Hope Speech Detection using Cross-lingual Representation Learner
Feb 28, 2021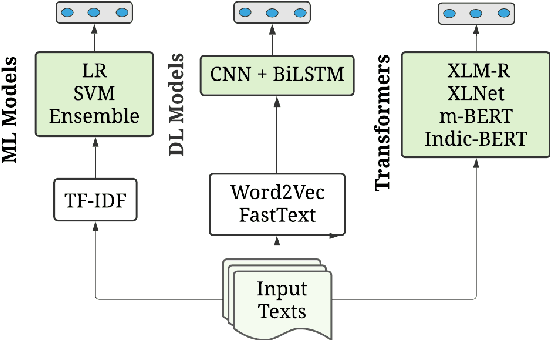
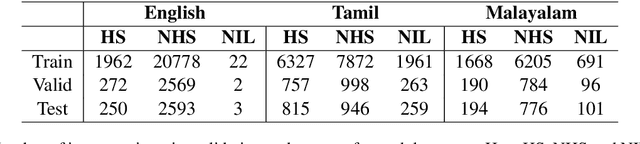
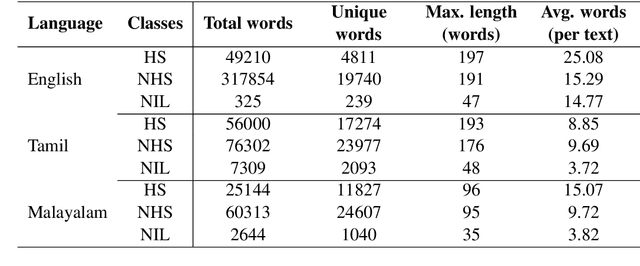
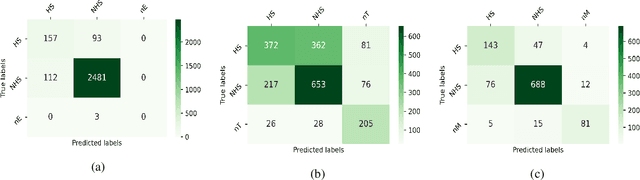
In recent years, several systems have been developed to regulate the spread of negativity and eliminate aggressive, offensive or abusive contents from the online platforms. Nevertheless, a limited number of researches carried out to identify positive, encouraging and supportive contents. In this work, our goal is to identify whether a social media post/comment contains hope speech or not. We propose three distinct models to identify hope speech in English, Tamil and Malayalam language to serve this purpose. To attain this goal, we employed various machine learning (support vector machine, logistic regression, ensemble), deep learning (convolutional neural network + long short term memory) and transformer (m-BERT, Indic-BERT, XLNet, XLM-Roberta) based methods. Results indicate that XLM-Roberta outdoes all other techniques by gaining a weighted $f_1$-score of $0.93$, $0.60$ and $0.85$ respectively for English, Tamil and Malayalam language. Our team has achieved $1^{st}$, $2^{nd}$ and $1^{st}$ rank in these three tasks respectively.
State-of-the-art in speaker recognition
Feb 23, 2022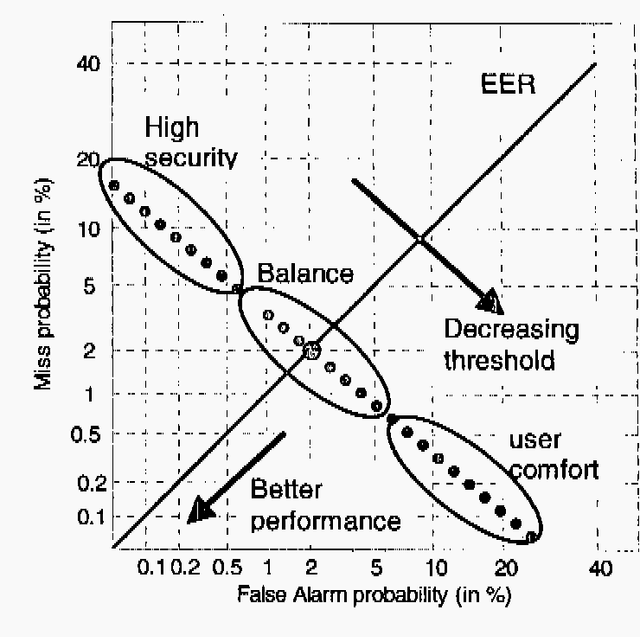
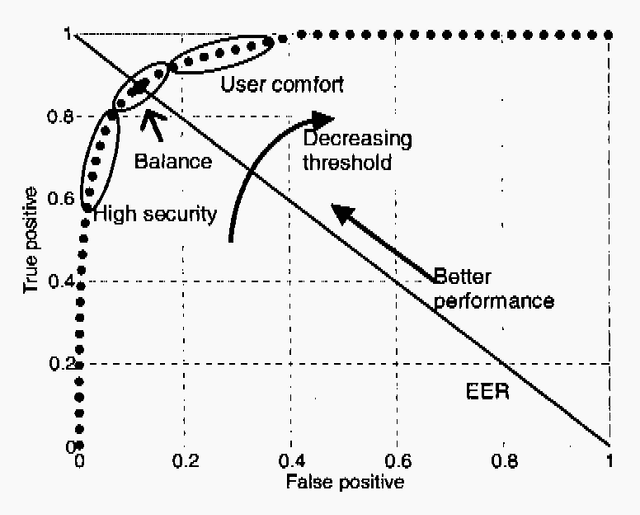
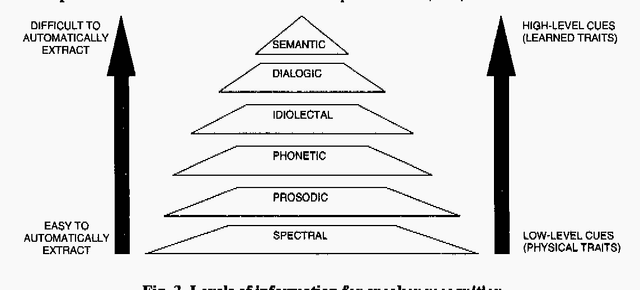
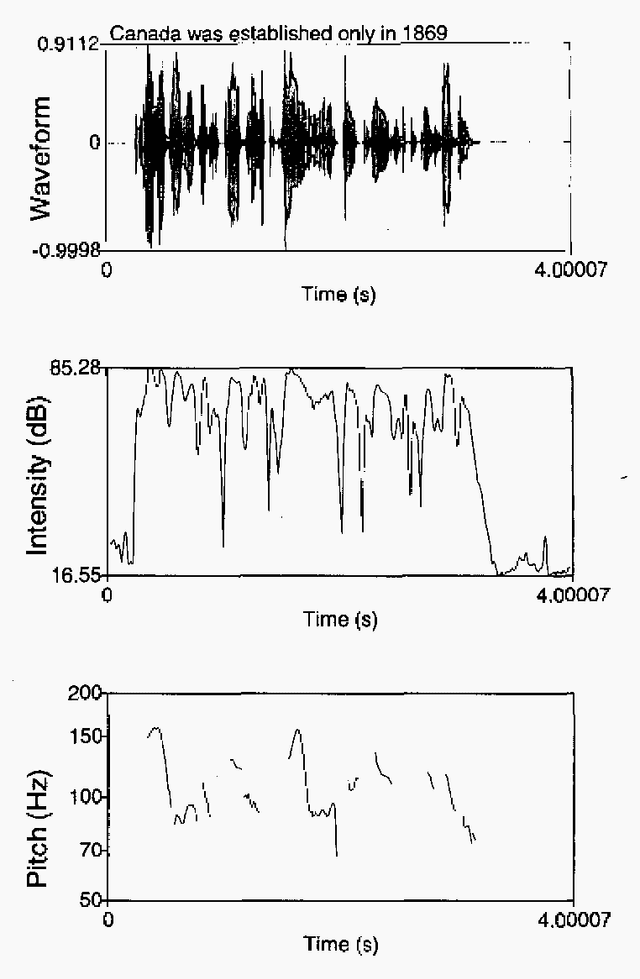
Recent advances in speech technologies have produced new tools that can be used to improve the performance and flexibility of speaker recognition While there are few degrees of freedom or alternative methods when using fingerprint or iris identification techniques, speech offers much more flexibility and different levels for performing recognition: the system can force the user to speak in a particular manner, different for each attempt to enter. Also with voice input the system has other degrees of freedom, such as the use of knowledge/codes that only the user knows, or dialectical/semantical traits that are difficult to forge. This paper offers and overview of the state of the art in speaker recognition, with special emphasis on the pros and contras, and the current research lines. The current research lines include improved classification systems, and the use of high level information by means of probabilistic grammars. In conclusion, speaker recognition is far away from being a technology where all the possibilities have already been explored.
* 7 pages. arXiv admin note: text overlap with arXiv:2202.11459
Seen and Unseen emotional style transfer for voice conversion with a new emotional speech dataset
Oct 28, 2020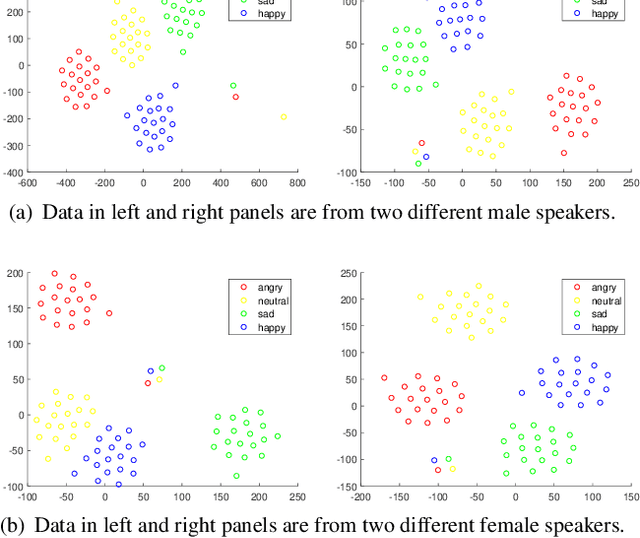

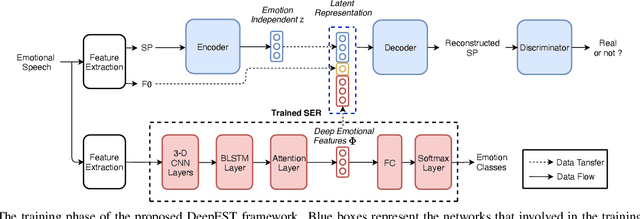
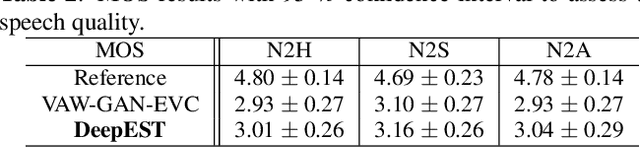
Emotional voice conversion aims to transform emotional prosody in speech while preserving the linguistic content and speaker identity. Prior studies show that it is possible to disentangle emotional prosody using an encoder-decoder network conditioned on discrete representation, such as one-hot emotion labels. Such networks learn to remember a fixed set of emotional styles. In this paper, we propose a novel framework based on variational auto-encoding Wasserstein generative adversarial network (VAW-GAN), which makes use of a pre-trained speech emotion recognition (SER) model to transfer emotional style during training and at run-time inference. In this way, the network is able to transfer both seen and unseen emotional style to a new utterance. We show that the proposed framework achieves remarkable performance by consistently outperforming the baseline framework. This paper also marks the release of an emotional speech dataset (ESD) for voice conversion, which has multiple speakers and languages.
Unsupervised Speech Domain Adaptation Based on Disentangled Representation Learning for Robust Speech Recognition
Apr 12, 2019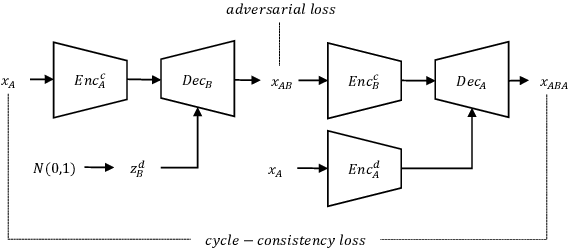
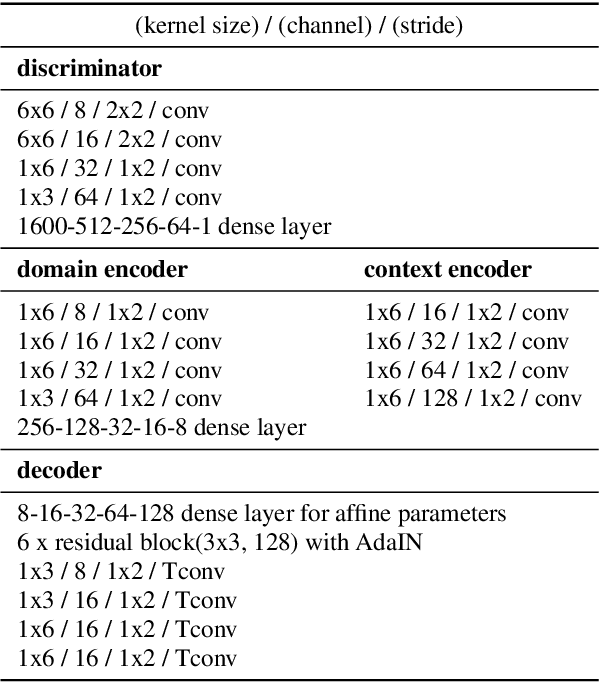
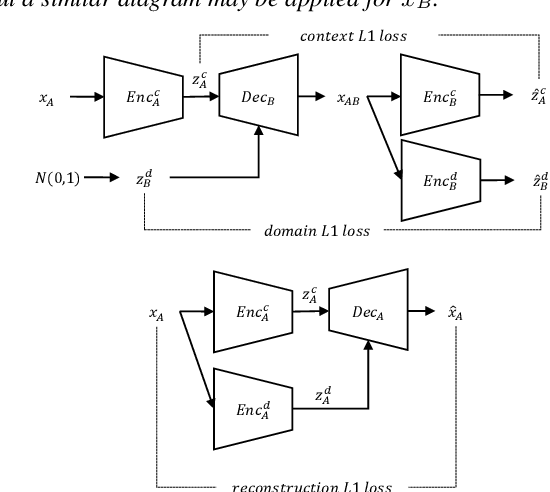
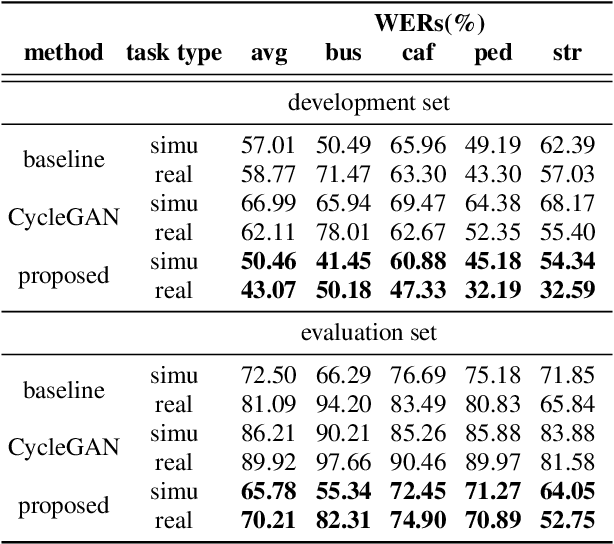
In general, the performance of automatic speech recognition (ASR) systems is significantly degraded due to the mismatch between training and test environments. Recently, a deep-learning-based image-to-image translation technique to translate an image from a source domain to a desired domain was presented, and cycle-consistent adversarial network (CycleGAN) was applied to learn a mapping for speech-to-speech conversion from a speaker to a target speaker. However, this method might not be adequate to remove corrupting noise components for robust ASR because it was designed to convert speech itself. In this paper, we propose a domain adaptation method based on generative adversarial nets (GANs) with disentangled representation learning to achieve robustness in ASR systems. In particular, two separated encoders, context and domain encoders, are introduced to learn distinct latent variables. The latent variables allow us to convert the domain of speech according to its context and domain representation. We improved word accuracies by 6.55~15.70\% for the CHiME4 challenge corpus by applying a noisy-to-clean environment adaptation for robust ASR. In addition, similar to the method based on the CycleGAN, this method can be used for gender adaptation in gender-mismatched recognition.