 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Dual Causal/Non-Causal Self-Attention for Streaming End-to-End Speech Recognition
Jul 02, 2021
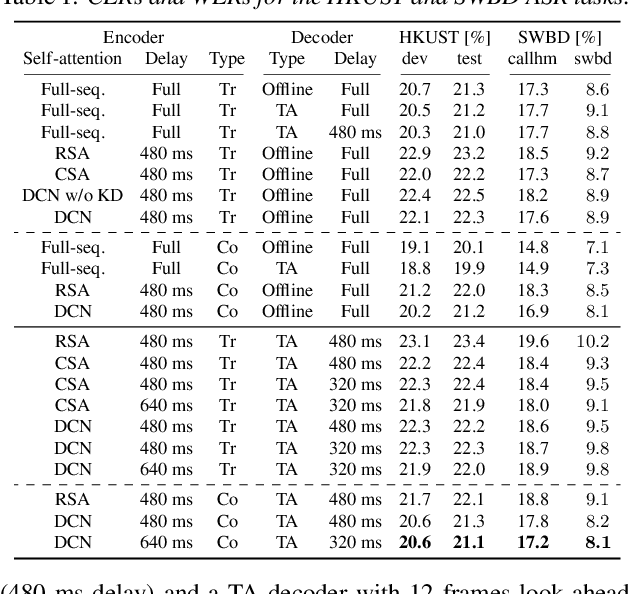
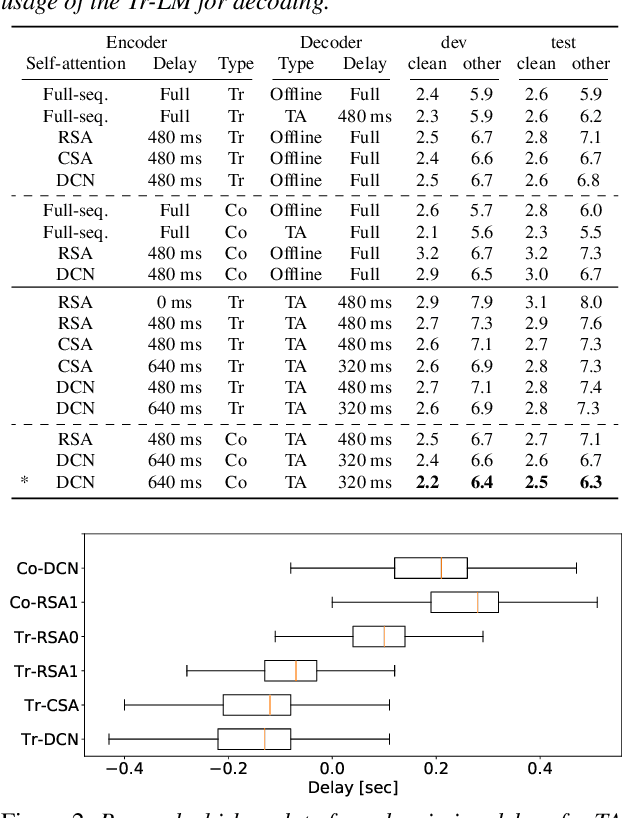
Attention-based end-to-end automatic speech recognition (ASR) systems have recently demonstrated state-of-the-art results for numerous tasks. However, the application of self-attention and attention-based encoder-decoder models remains challenging for streaming ASR, where each word must be recognized shortly after it was spoken. In this work, we present the dual causal/non-causal self-attention (DCN) architecture, which in contrast to restricted self-attention prevents the overall context to grow beyond the look-ahead of a single layer when used in a deep architecture. DCN is compared to chunk-based and restricted self-attention using streaming transformer and conformer architectures, showing improved ASR performance over restricted self-attention and competitive ASR results compared to chunk-based self-attention, while providing the advantage of frame-synchronous processing. Combined with triggered attention, the proposed streaming end-to-end ASR systems obtained state-of-the-art results on the LibriSpeech, HKUST, and Switchboard ASR tasks.
SQ-VAE: Variational Bayes on Discrete Representation with Self-annealed Stochastic Quantization
May 16, 2022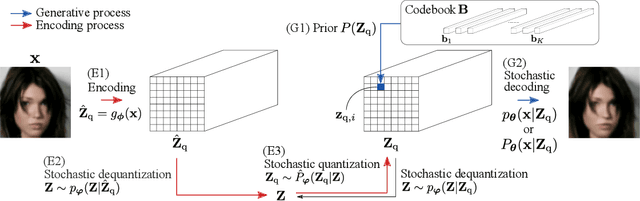

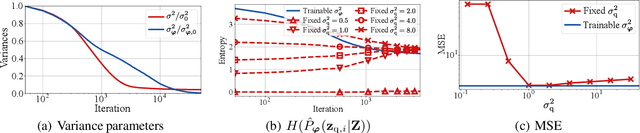
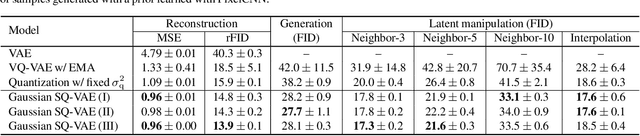
One noted issue of vector-quantized variational autoencoder (VQ-VAE) is that the learned discrete representation uses only a fraction of the full capacity of the codebook, also known as codebook collapse. We hypothesize that the training scheme of VQ-VAE, which involves some carefully designed heuristics, underlies this issue. In this paper, we propose a new training scheme that extends the standard VAE via novel stochastic dequantization and quantization, called stochastically quantized variational autoencoder (SQ-VAE). In SQ-VAE, we observe a trend that the quantization is stochastic at the initial stage of the training but gradually converges toward a deterministic quantization, which we call self-annealing. Our experiments show that SQ-VAE improves codebook utilization without using common heuristics. Furthermore, we empirically show that SQ-VAE is superior to VAE and VQ-VAE in vision- and speech-related tasks.
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Jun 22, 2020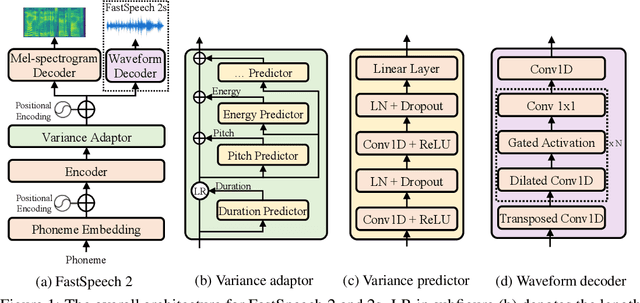
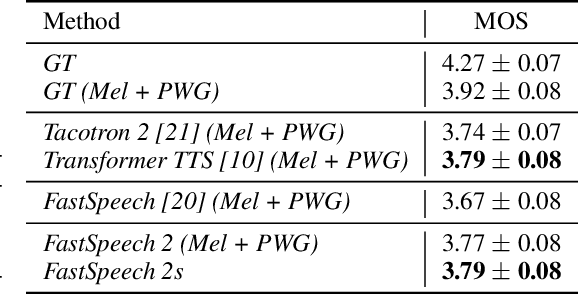
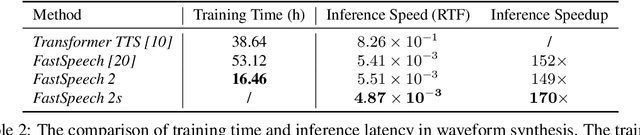
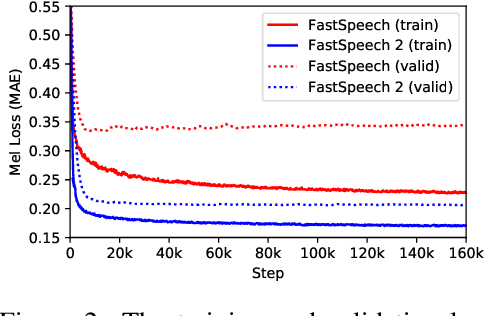
Advanced text to speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs during training and use predicted values during inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of full end-to-end training and even faster inference than FastSpeech. Experimental results show that 1) FastSpeech 2 and 2s outperform FastSpeech in voice quality with much simplified training pipeline and reduced training time; 2) FastSpeech 2 and 2s can match the voice quality of autoregressive models while enjoying much faster inference speed.
Estimating articulatory movements in speech production with transformer networks
Apr 11, 2021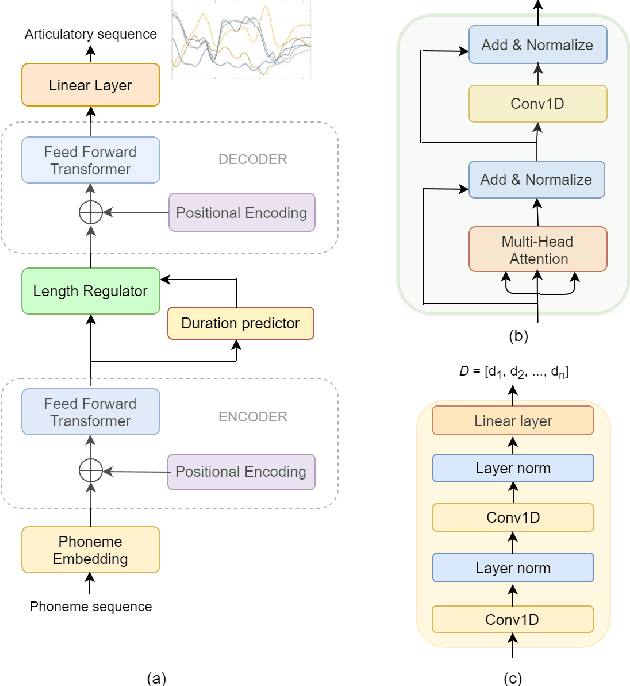
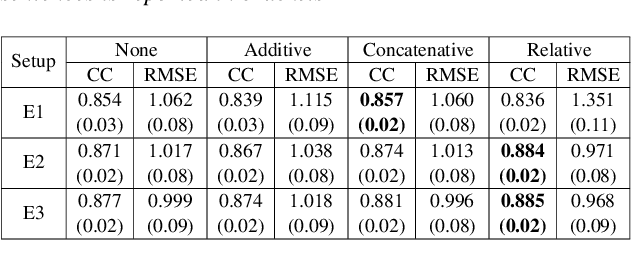
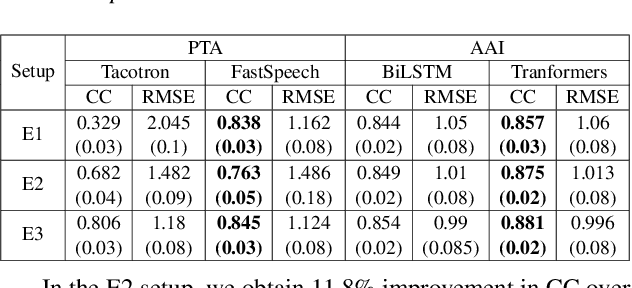
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.
Robustness of end-to-end Automatic Speech Recognition Models -- A Case Study using Mozilla DeepSpeech
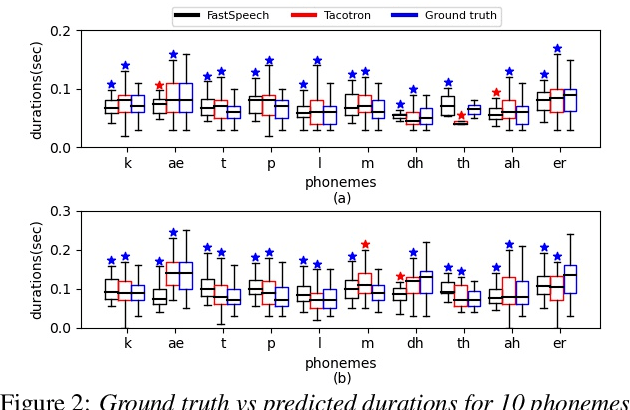
May 08, 2021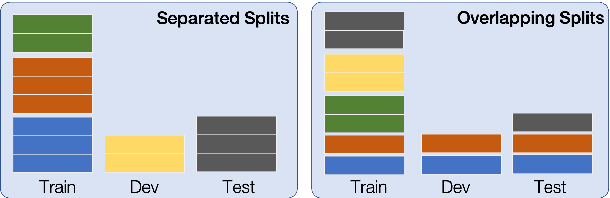

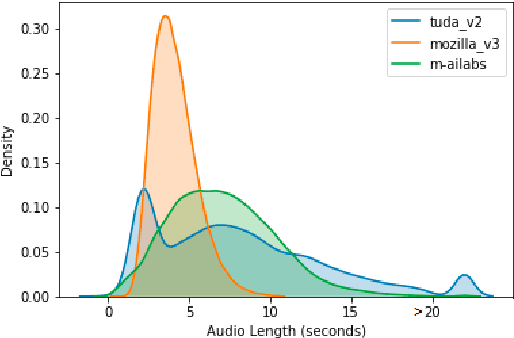
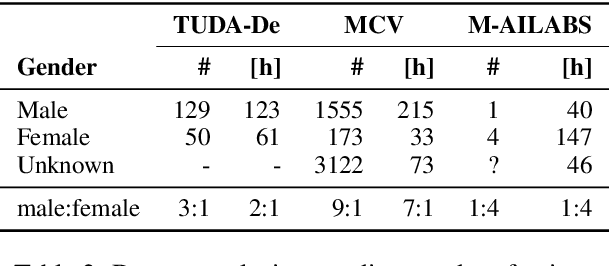
When evaluating the performance of automatic speech recognition models, usually word error rate within a certain dataset is used. Special care must be taken in understanding the dataset in order to report realistic performance numbers. We argue that many performance numbers reported probably underestimate the expected error rate. We conduct experiments controlling for selection bias, gender as well as overlap (between training and test data) in content, voices, and recording conditions. We find that content overlap has the biggest impact, but other factors like gender also play a role.
DeepSpectrumLite: A Power-Efficient Transfer Learning Framework for Embedded Speech and Audio Processing from Decentralised Data
Apr 23, 2021
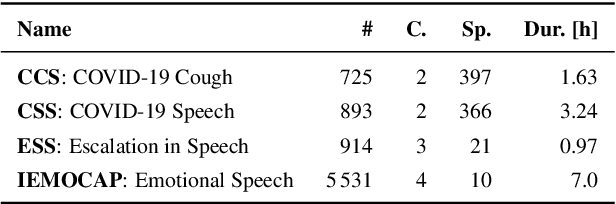
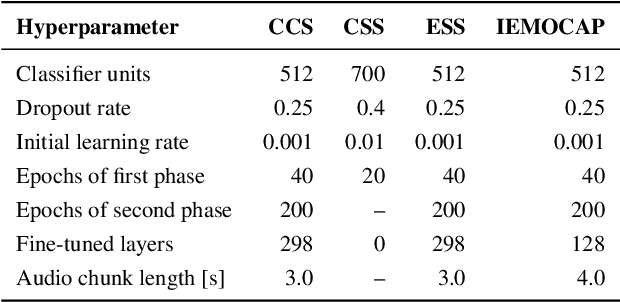

Deep neural speech and audio processing systems have a large number of trainable parameters, a relatively complex architecture, and require a vast amount of training data and computational power. These constraints make it more challenging to integrate such systems into embedded devices and utilise them for real-time, real-world applications. We tackle these limitations by introducing DeepSpectrumLite, an open-source, lightweight transfer learning framework for on-device speech and audio recognition using pre-trained image convolutional neural networks (CNNs). The framework creates and augments Mel-spectrogram plots on-the-fly from raw audio signals which are then used to finetune specific pre-trained CNNs for the target classification task. Subsequently, the whole pipeline can be run in real-time with a mean inference lag of 242.0 ms when a DenseNet121 model is used on a consumer-grade Motorola moto e7 plus smartphone. DeepSpectrumLite operates decentralised, eliminating the need for data upload for further processing. By obtaining state-of-the-art results on a set of paralinguistics tasks, we demonstrate the suitability of the proposed transfer learning approach for embedded audio signal processing, even when data is scarce. We provide an extensive command-line interface for users and developers which is comprehensively documented and publicly available at https://github.com/DeepSpectrum/DeepSpectrumLite.
KUCST@LT-EDI-ACL2022: Detecting Signs of Depression from Social Media Text
Apr 09, 2022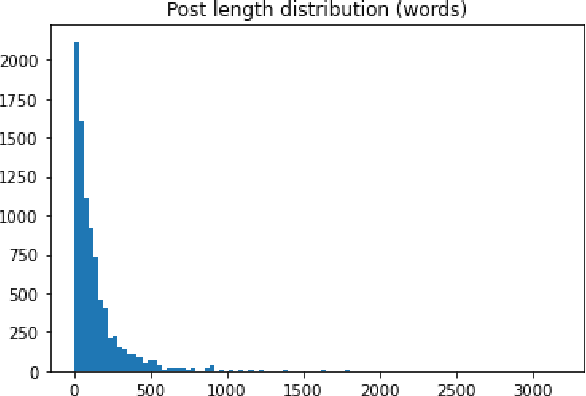
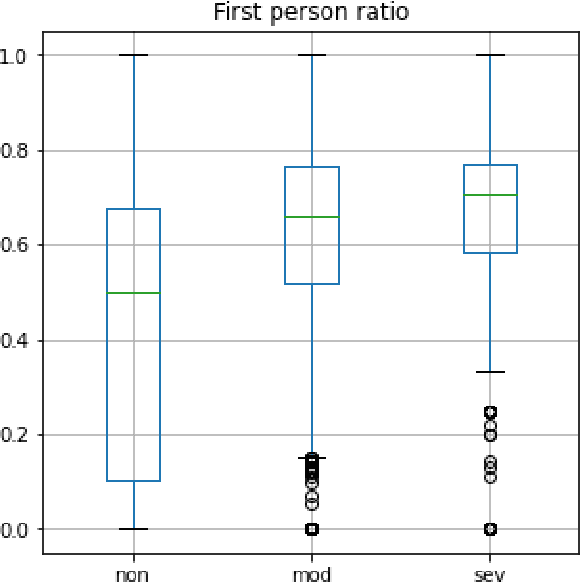
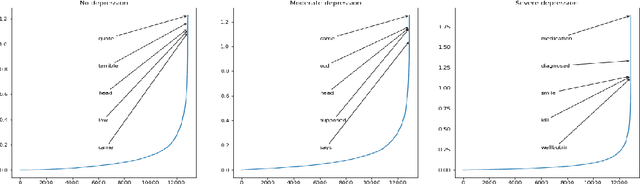
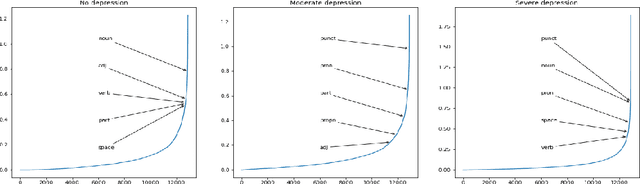
In this paper we present our approach for detecting signs of depression from social media text. Our model relies on word unigrams, part-of-speech tags, readabilitiy measures and the use of first, second or third person and the number of words. Our best model obtained a macro F1-score of 0.439 and ranked 25th, out of 31 teams. We further take advantage of the interpretability of the Logistic Regression model and we make an attempt to interpret the model coefficients with the hope that these will be useful for further research on the topic.
FAIR4Cov: Fused Audio Instance and Representation for COVID-19 Detection
Apr 22, 2022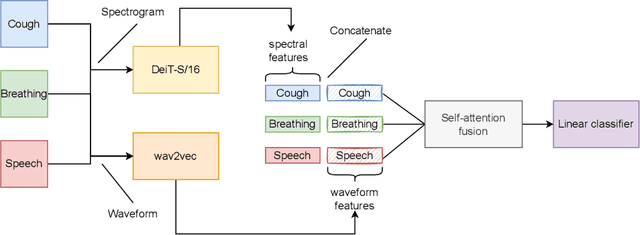
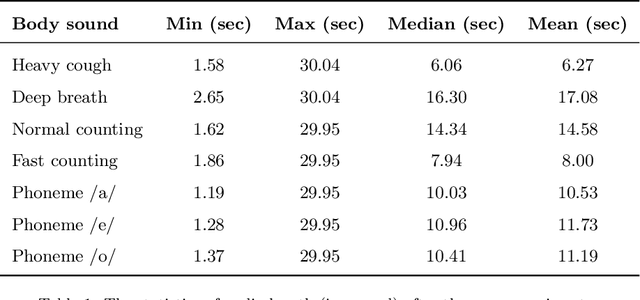
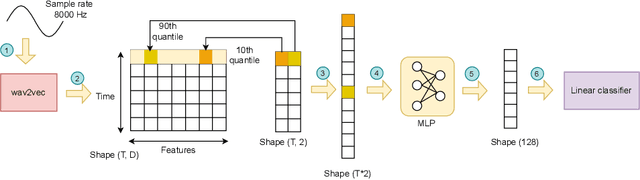
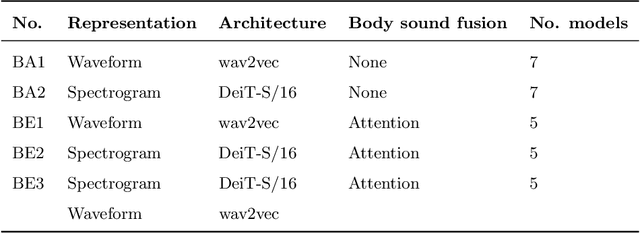
Audio-based classification techniques on body sounds have long been studied to support diagnostic decisions, particularly in pulmonary diseases. In response to the urgency of the COVID-19 pandemic, a growing number of models are developed to identify COVID-19 patients based on acoustic input. Most models focus on cough because the dry cough is the best-known symptom of COVID-19. However, other body sounds, such as breath and speech, have also been revealed to correlate with COVID-19 as well. In this work, rather than relying on a specific body sound, we propose Fused Audio Instance and Representation for COVID-19 Detection (FAIR4Cov). It relies on constructing a joint feature vector obtained from a plurality of body sounds in waveform and spectrogram representation. The core component of FAIR4Cov is a self-attention fusion unit that is trained to establish the relation of multiple body sounds and audio representations and integrate it into a compact feature vector. We set up our experiments on different combinations of body sounds using only waveform, spectrogram, and a joint representation of waveform and spectrogram. Our findings show that the use of self-attention to combine extracted features from cough, breath, and speech sounds leads to the best performance with an Area Under the Receiver Operating Characteristic Curve (AUC) score of 0.8658, a sensitivity of 0.8057, and a specificity of 0.7958. This AUC is 0.0227 higher than the one of the models trained on spectrograms only and 0.0847 higher than the one of the models trained on waveforms only. The results demonstrate that the combination of spectrogram with waveform representation helps to enrich the extracted features and outperforms the models with single representation.
End-to-End Speech Recognition from Federated Acoustic Models
Apr 29, 2021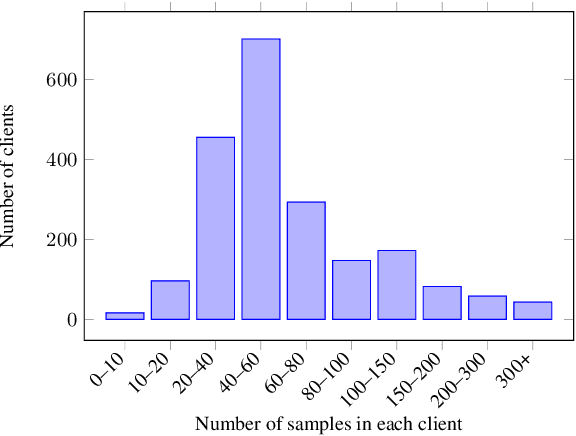

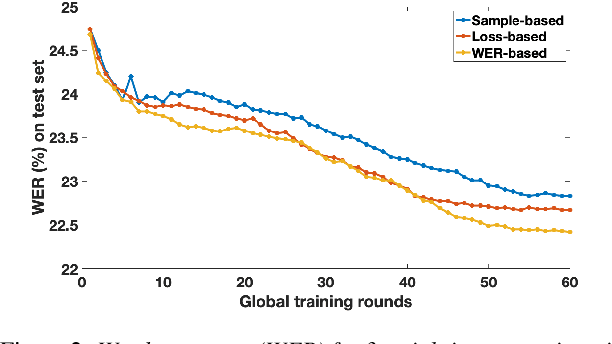
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.
Deep Double-Side Learning Ensemble Model for Few-Shot Parkinson Speech Recognition
Jun 20, 2020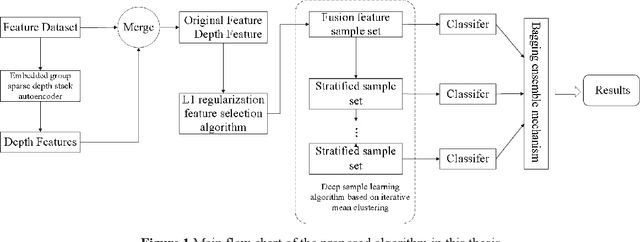

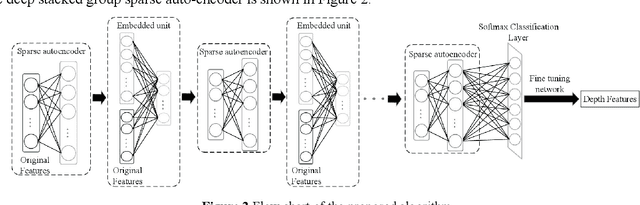

Diagnosis and therapeutic effect assessment of Parkinson disease based on voice data are very important,but its few-shot learning problem is challenging.Although deep learning is good at automatic feature extraction, it suffers from few-shot learning problem. Therefore, the general effective method is first conduct feature extraction based on prior knowledge, and then carry out feature reduction for subsequent classification. However, there are two major problems: 1) Structural information among speech features has not been mined and new features of higher quality have not been reconstructed. 2) Structural information between data samples has not been mined and new samples with higher quality have not been reconstructed. To solve these two problems, based on the existing Parkinson speech feature data set, a deep double-side learning ensemble model is designed in this paper that can reconstruct speech features and samples deeply and simultaneously. As to feature reconstruction, an embedded deep stacked group sparse auto-encoder is designed in this paper to conduct nonlinear feature transformation, so as to acquire new high-level deep features, and then the deep features are fused with original speech features by L1 regularization feature selection method. As to speech sample reconstruction, a deep sample learning algorithm is designed in this paper based on iterative mean clustering to conduct samples transformation, so as to obtain new high-level deep samples. Finally, the bagging ensemble learning mode is adopted to fuse the deep feature learning algorithm and the deep samples learning algorithm together, thereby constructing a deep double-side learning ensemble model. At the end of this paper, two representative speech datasets of Parkinson's disease were used for verification. The experimental results show that the proposed algorithm are effective.