 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PoCoNet: Better Speech Enhancement with Frequency-Positional Embeddings, Semi-Supervised Conversational Data, and Biased Loss
Aug 11, 2020
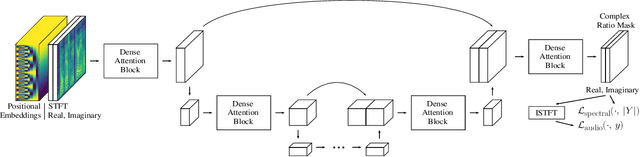
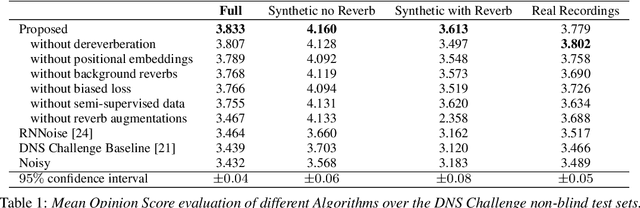
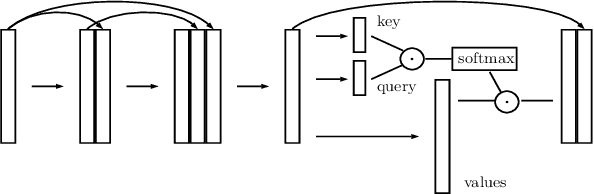
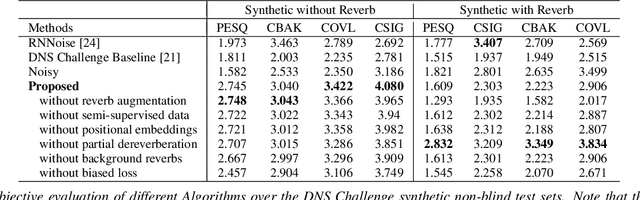
Neural network applications generally benefit from larger-sized models, but for current speech enhancement models, larger scale networks often suffer from decreased robustness to the variety of real-world use cases beyond what is encountered in training data. We introduce several innovations that lead to better large neural networks for speech enhancement. The novel PoCoNet architecture is a convolutional neural network that, with the use of frequency-positional embeddings, is able to more efficiently build frequency-dependent features in the early layers. A semi-supervised method helps increase the amount of conversational training data by pre-enhancing noisy datasets, improving performance on real recordings. A new loss function biased towards preserving speech quality helps the optimization better match human perceptual opinions on speech quality. Ablation experiments and objective and human opinion metrics show the benefits of the proposed improvements.
Evaluating MT Systems: A Theoretical Framework
Feb 11, 2022This paper outlines a theoretical framework using which different automatic metrics can be designed for evaluation of Machine Translation systems. It introduces the concept of {\em cognitive ease} which depends on {\em adequacy} and {\em lack of fluency}. Thus, cognitive ease becomes the main parameter to be measured rather than comprehensibility. The framework allows the components of cognitive ease to be broken up and computed based on different linguistic levels etc. Independence of dimensions and linearly combining them provides for a highly modular approach. The paper places the existing automatic methods in an overall framework, to understand them better and to improve upon them in future. It can also be used to evaluate the newer types of MT systems, such as speech to speech translation and discourse translation.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021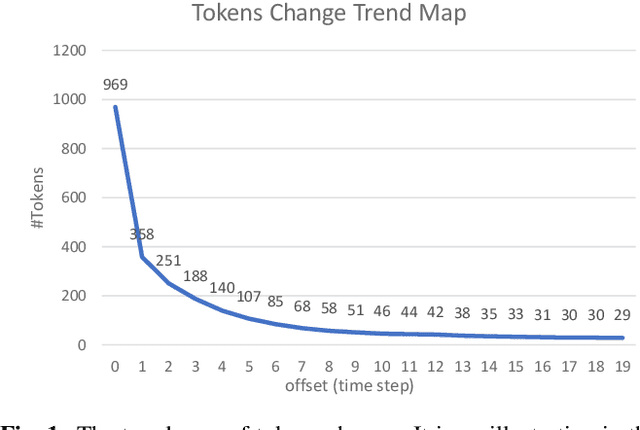
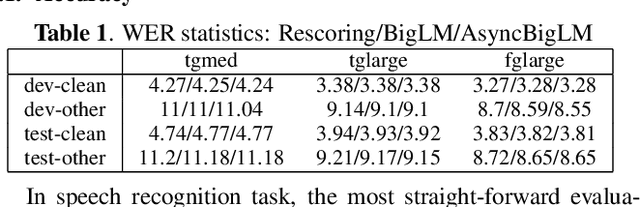
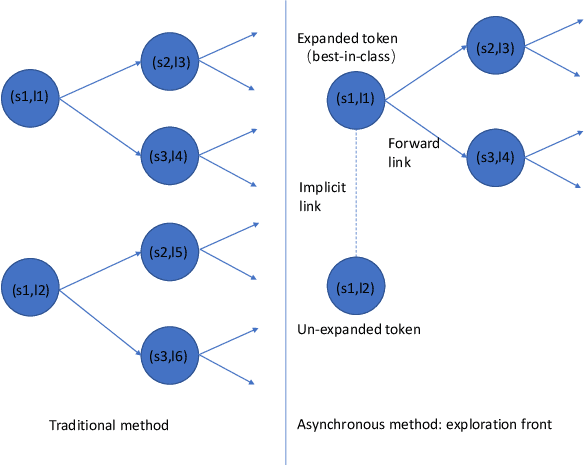
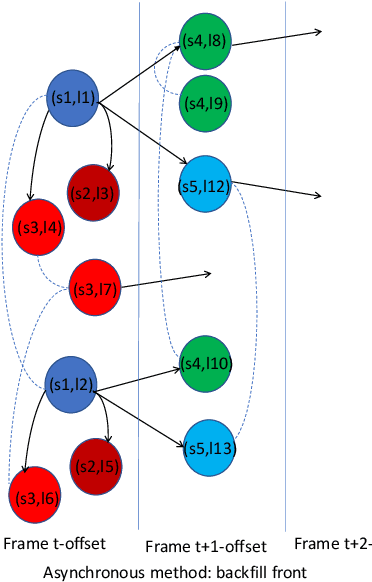
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
Multilingual and Multi-Aspect Hate Speech Analysis
Aug 29, 2019


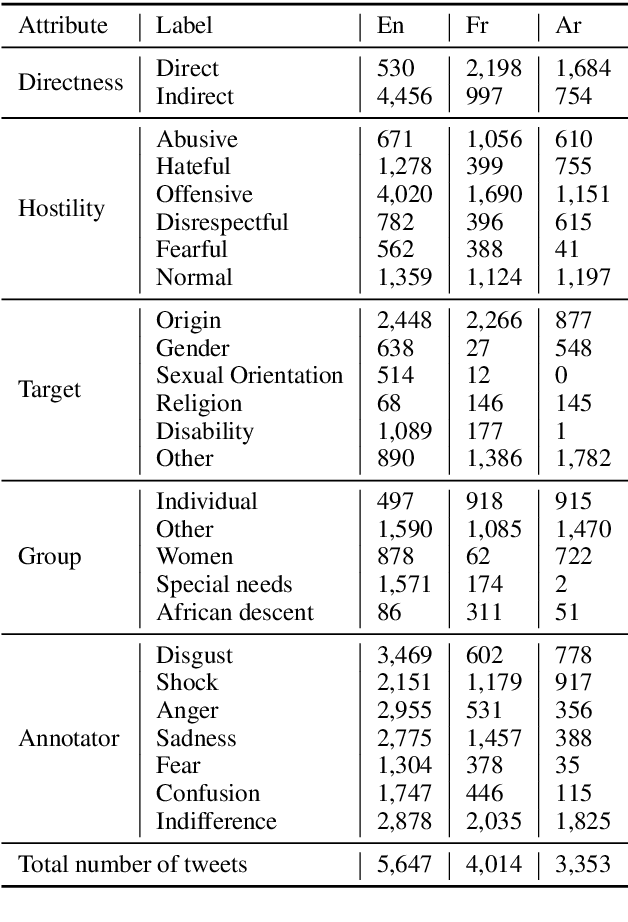
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual multi-aspect hate speech analysis dataset and use it to test the current state-of-the-art multilingual multitask learning approaches. We evaluate our dataset in various classification settings, then we discuss how to leverage our annotations in order to improve hate speech detection and classification in general.
Decentralizing Feature Extraction with Quantum Convolutional Neural Network for Automatic Speech Recognition
Oct 26, 2020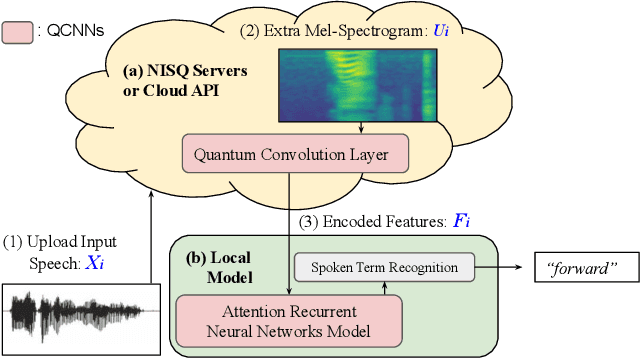

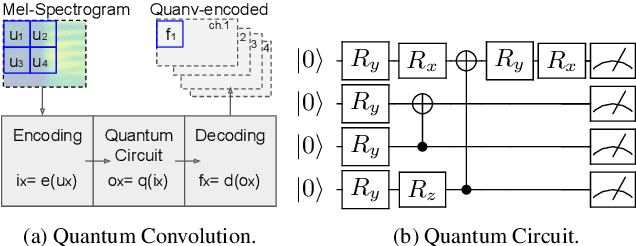
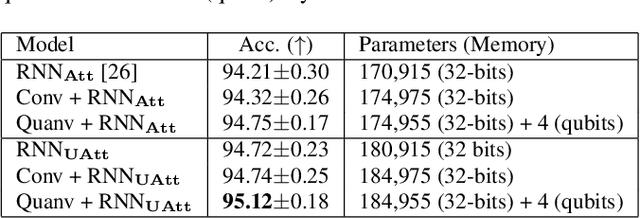
We propose a novel decentralized feature extraction approach in federated learning to address privacy-preservation issues for speech recognition. It is built upon a quantum convolutional neural network (QCNN) composed of a quantum circuit encoder for feature extraction, and a recurrent neural network (RNN) based end-to-end acoustic model (AM). To enhance model parameter protection in a decentralized architecture, an input speech is first up-streamed to a quantum computing server to extract Mel-spectrogram, and the corresponding convolutional features are encoded using a quantum circuit algorithm with random parameters. The encoded features are then down-streamed to the local RNN model for the final recognition. The proposed decentralized framework takes advantage of the quantum learning progress to secure models and to avoid privacy leakage attacks. Testing on the Google Speech Commands Dataset, the proposed QCNN encoder attains a competitive accuracy of 95.12\% in a decentralized model, which is better than the previous architectures using centralized RNN models with convolutional features. We also conduct an in-depth study of different quantum circuit encoder architectures to provide insights into designing QCNN-based feature extractors. Finally, neural saliency analyses demonstrate a high correlation between the proposed QCNN features, class activation maps, and the input Mel-spectrogram.
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
Apr 04, 2021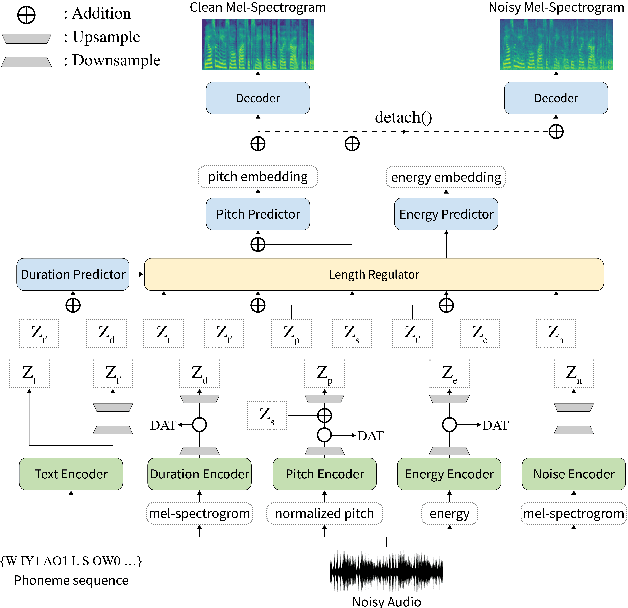
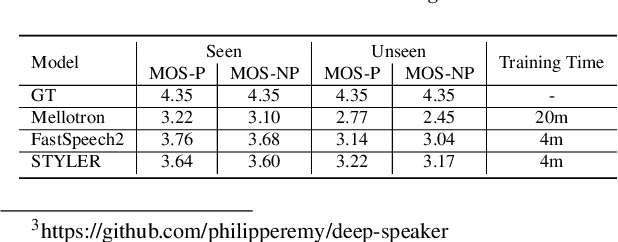
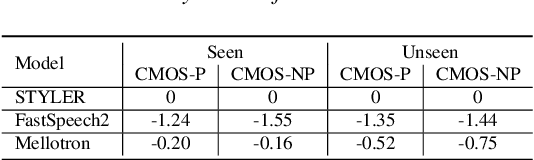
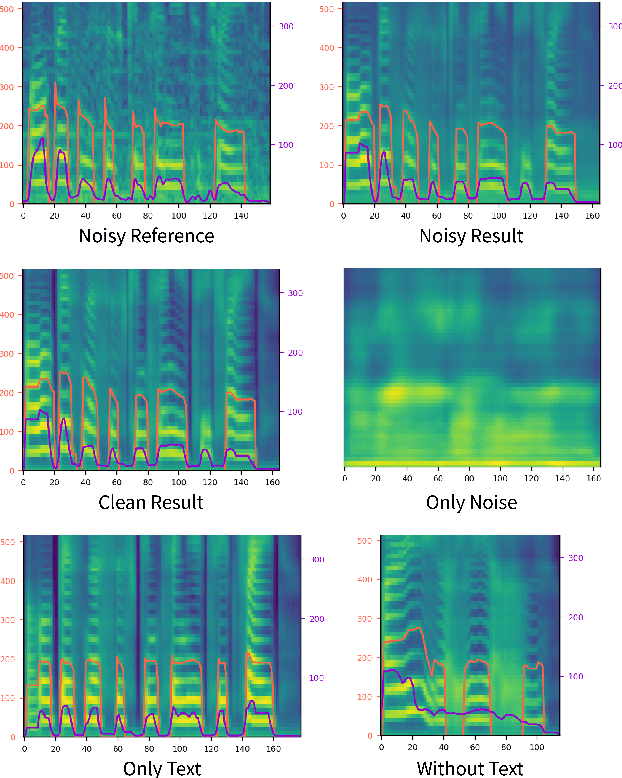
Previous works on neural text-to-speech (TTS) have been addressed on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, there has been no attempt to solve all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable TTS framework with high-speed and robust synthesis. Our novel audio-text aligning method called Mel Calibrator and excluding autoregressive decoding enable rapid training and inference and robust synthesis on unseen data. Also, disentangled style factor modeling under supervision enlarges the controllability in synthesizing process leading to expressive TTS. On top of it, a novel noise modeling pipeline using domain adversarial training and Residual Decoding empowers noise-robust style transfer, decomposing the noise without any additional label. Various experiments demonstrate that STYLER is more effective in speed and robustness than expressive TTS with autoregressive decoding and more expressive and controllable than reading style non-autoregressive TTS. Synthesis samples and experiment results are provided via our demo page, and code is available publicly.
Introducing the Talk Markup Language (TalkML):Adding a little social intelligence to industrial speech interfaces
May 24, 2021



Virtual Personal Assistants like Siri have great potential but such developments hit the fundamental problem of how to make computational devices that understand human speech. Natural language understanding is one of the more disappointing failures of AI research and it seems there is something we computer scientists don't get about the nature of language. Of course philosophers and linguists think quite differently about language and this paper describes how we have taken ideas from other disciplines and implemented them. The background to the work is to take seriously the notion of language as action and look at what people actually do with language using the techniques of Conversation Analysis. The observation has been that human communication is (behind the scenes) about the management of social relations as well as the (foregrounded) passing of information. To claim this is one thing but to implement it requires a mechanism. The mechanism described here is based on the notion of language being intentional - we think intentionally, talk about them and recognise them in others - and cooperative in that we are compelled to help out. The way we are compelled points to a solution to the ever present problem of keeping the human on topic. The approach has led to a recent success in which we significantly improve user satisfaction independent of task completion. Talk Markup Language (TalkML) is a draft alternative to VoiceXML that, we propose, greatly simplifies the scripting of interaction by providing default behaviours for no input and not recognised speech events.
DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language
Dec 28, 2020
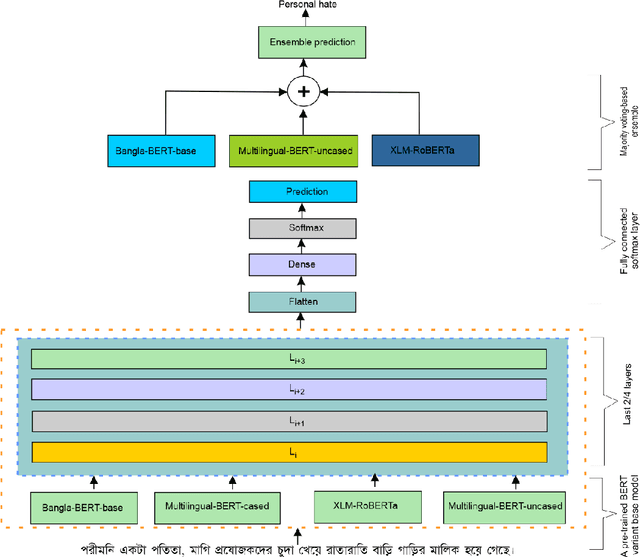
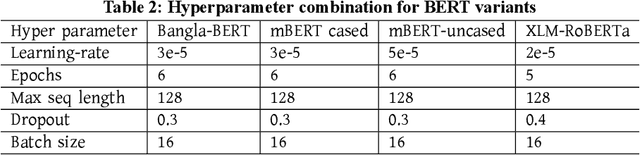
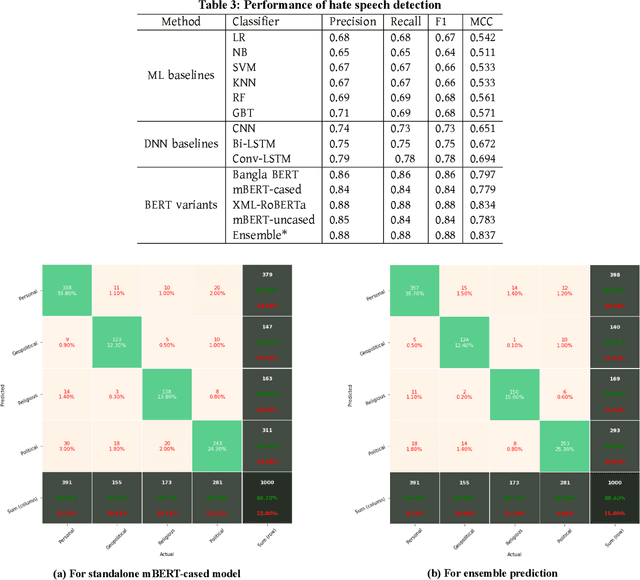
Exponential growths of social media and micro-blogging sites not only provide platforms for empowering freedom of expressions and individual voices, but also enables people to express anti-social behavior like online harassment, cyberbullying, and hate speech. Numerous works have been proposed to utilize these data for social and anti-social behavior analysis, by predicting the contexts mostly for highly-resourced languages like English. However, some languages such as Bengali are under-resourced that lack of computational resources for natural language processing(NLP). In this paper, we propose an explainable approach for hate speech detection from under-resourced Bengali language, which we called DeepHateExplainer. In our approach, Bengali texts are first comprehensively preprocessed, before classifying them into political, personal, geopolitical, and religious hates, by employing neural ensemble of different transformer-based neural architectures(i.e., monolingual Bangla BERT-base, multilingual BERT-cased and uncased, and XLM-RoBERTa), followed by identifying important terms with sensitivity analysis and layer-wise relevance propagation(LRP) to provide human-interpretable explanations. Evaluations against several machine learning~(linear and tree-based models) and deep neural networks (i.e., CNN, Bi-LSTM, and Conv-LSTM with word embeddings) baselines yield F1 scores of 84%, 90%, 88%, and 88%, for political, personal, geopolitical, and religious hates, respectively, during 3-fold cross-validation tests.
Dim Wihl Gat Tun: The Case for Linguistic Expertise in NLP for Underdocumented Languages
Mar 17, 2022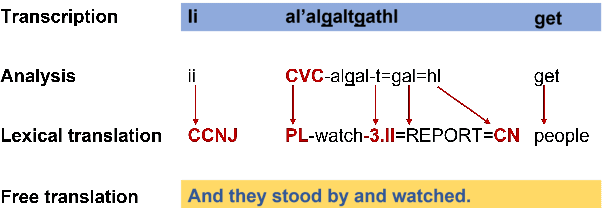
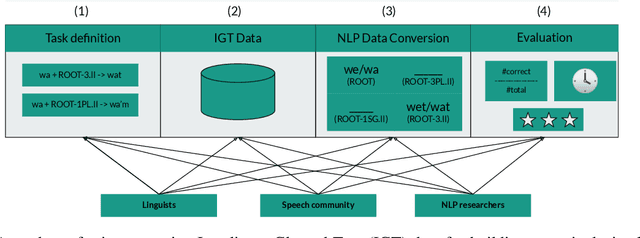
Recent progress in NLP is driven by pretrained models leveraging massive datasets and has predominantly benefited the world's political and economic superpowers. Technologically underserved languages are left behind because they lack such resources. Hundreds of underserved languages, nevertheless, have available data sources in the form of interlinear glossed text (IGT) from language documentation efforts. IGT remains underutilized in NLP work, perhaps because its annotations are only semi-structured and often language-specific. With this paper, we make the case that IGT data can be leveraged successfully provided that target language expertise is available. We specifically advocate for collaboration with documentary linguists. Our paper provides a roadmap for successful projects utilizing IGT data: (1) It is essential to define which NLP tasks can be accomplished with the given IGT data and how these will benefit the speech community. (2) Great care and target language expertise is required when converting the data into structured formats commonly employed in NLP. (3) Task-specific and user-specific evaluation can help to ascertain that the tools which are created benefit the target language speech community. We illustrate each step through a case study on developing a morphological reinflection system for the Tsimchianic language Gitksan.
Generative Adversarial Training Data Adaptation for Very Low-resource Automatic Speech Recognition
May 19, 2020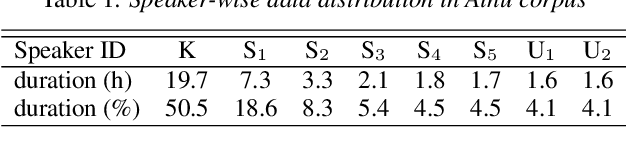
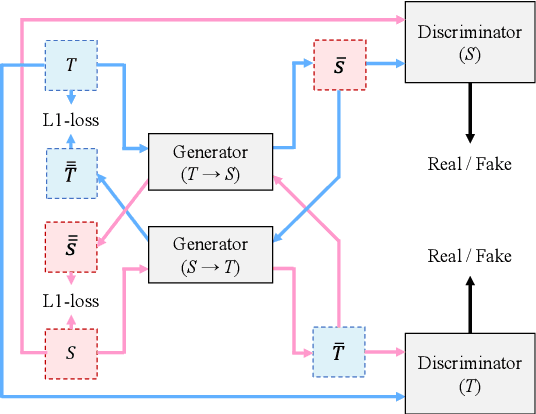
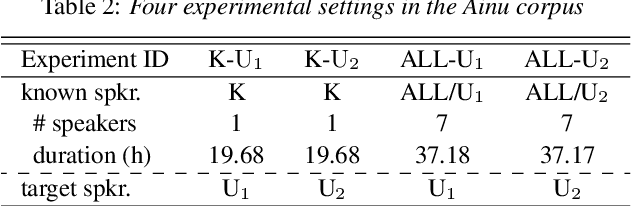
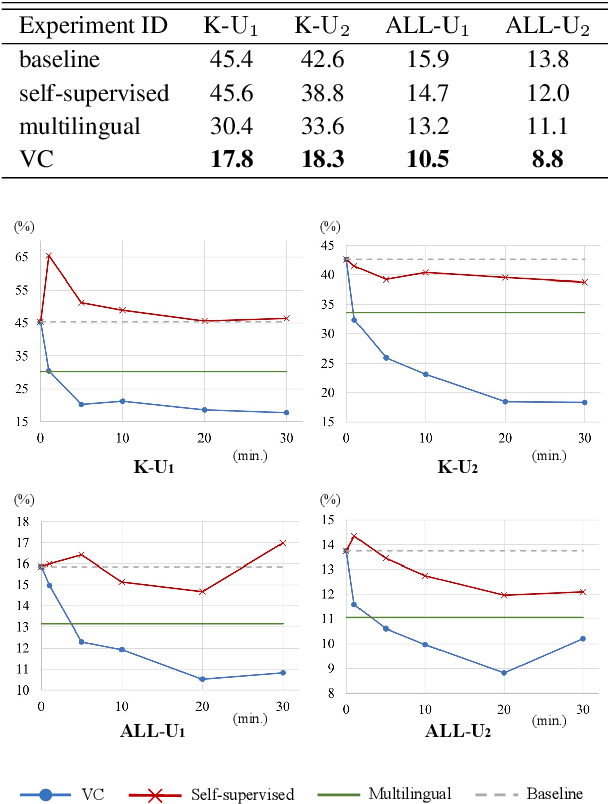
It is important to transcribe and archive speech data of endangered languages for preserving heritages of verbal culture and automatic speech recognition (ASR) is a powerful tool to facilitate this process. However, since endangered languages do not generally have large corpora with many speakers, the performance of ASR models trained on them are considerably poor in general. Nevertheless, we are often left with a lot of recordings of spontaneous speech data that have to be transcribed. In this work, for mitigating this speaker sparsity problem, we propose to convert the whole training speech data and make it sound like the test speaker in order to develop a highly accurate ASR system for this speaker. For this purpose, we utilize a CycleGAN-based non-parallel voice conversion technology to forge a labeled training data that is close to the test speaker's speech. We evaluated this speaker adaptation approach on two low-resource corpora, namely, Ainu and Mboshi. We obtained 35-60% relative improvement in phone error rate on the Ainu corpus, and 40% relative improvement was attained on the Mboshi corpus. This approach outperformed two conventional methods namely unsupervised adaptation and multilingual training with these two corpora.