 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Advancing CTC-CRF Based End-to-End Speech Recognition with Wordpieces and Conformers
Jul 08, 2021

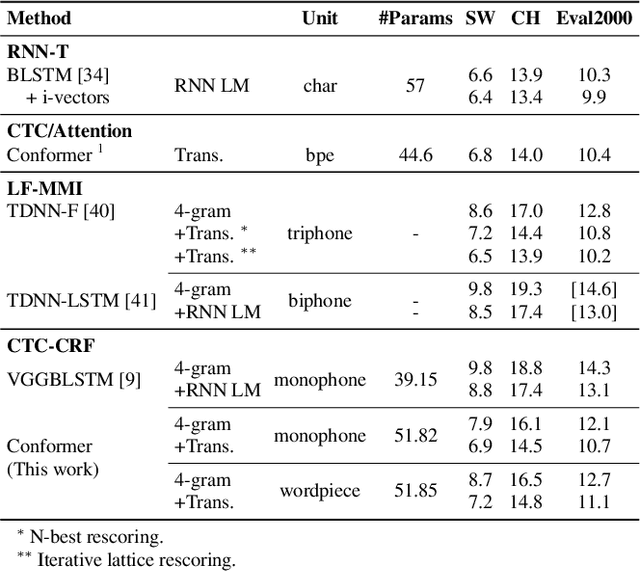
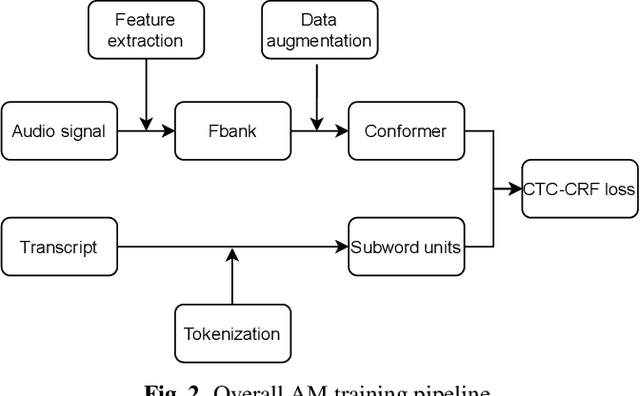
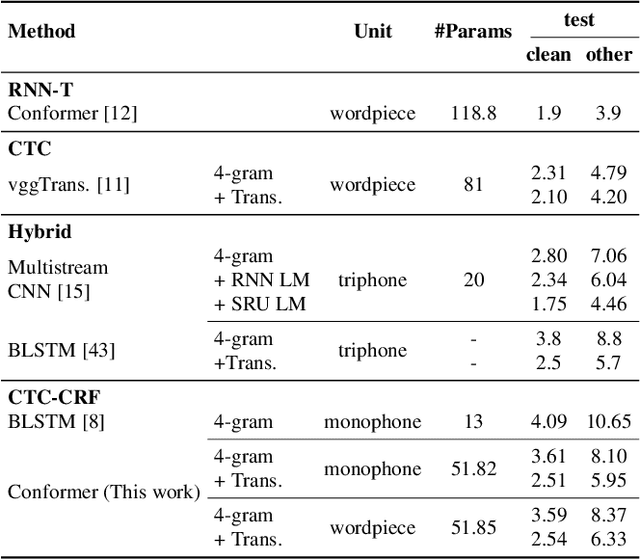
Automatic speech recognition systems have been largely improved in the past few decades and current systems are mainly hybrid-based and end-to-end-based. The recently proposed CTC-CRF framework inherits the data-efficiency of the hybrid approach and the simplicity of the end-to-end approach. In this paper, we further advance CTC-CRF based ASR technique with explorations on modeling units and neural architectures. Specifically, we investigate techniques to enable the recently developed wordpiece modeling units and Conformer neural networks to be succesfully applied in CTC-CRFs. Experiments are conducted on two English datasets (Switchboard, Librispeech) and a German dataset from CommonVoice. Experimental results suggest that (i) Conformer can improve the recognition performance significantly; (ii) Wordpiece-based systems perform slightly worse compared with phone-based systems for the target language with a low degree of grapheme-phoneme correspondence (e.g. English), while the two systems can perform equally strong when such degree of correspondence is high for the target language (e.g. German).
Novel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021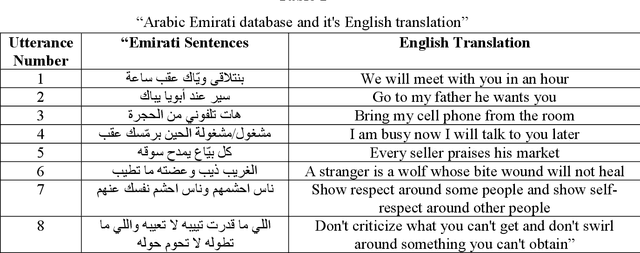
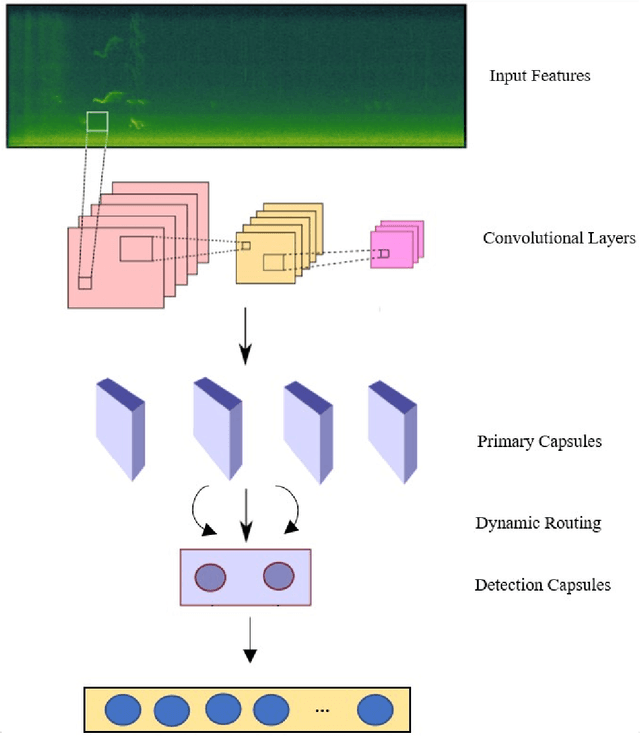
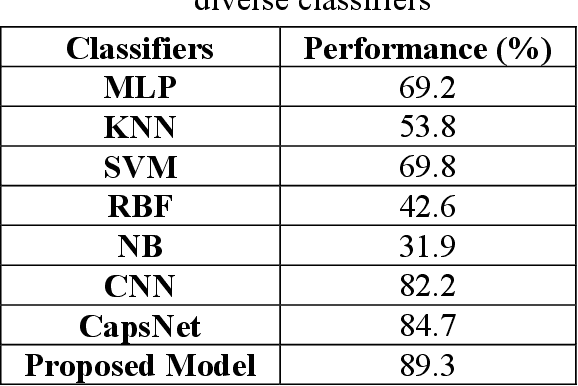
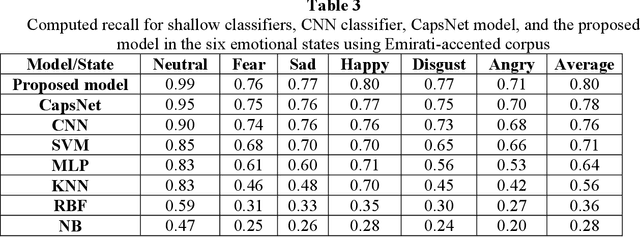
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures
Improving speaker discrimination of target speech extraction with time-domain SpeakerBeam
Jan 23, 2020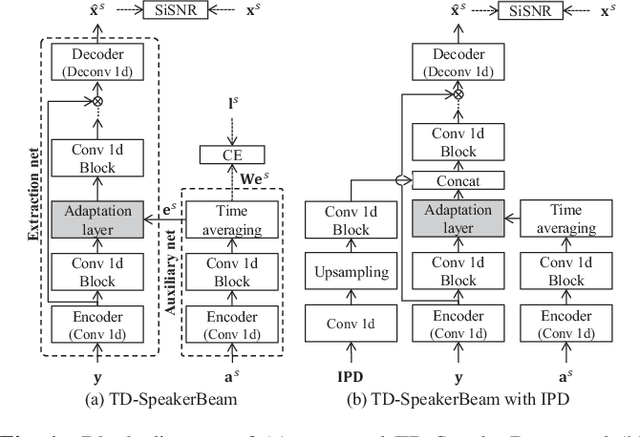
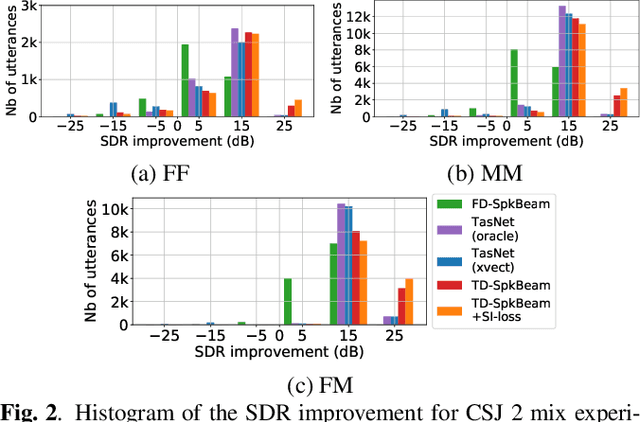
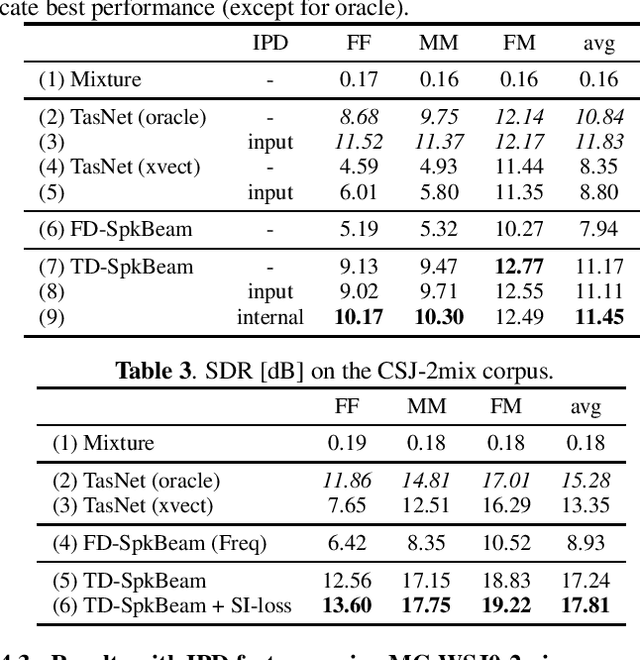
Target speech extraction, which extracts a single target source in a mixture given clues about the target speaker, has attracted increasing attention. We have recently proposed SpeakerBeam, which exploits an adaptation utterance of the target speaker to extract his/her voice characteristics that are then used to guide a neural network towards extracting speech of that speaker. SpeakerBeam presents a practical alternative to speech separation as it enables tracking speech of a target speaker across utterances, and achieves promising speech extraction performance. However, it sometimes fails when speakers have similar voice characteristics, such as in same-gender mixtures, because it is difficult to discriminate the target speaker from the interfering speakers. In this paper, we investigate strategies for improving the speaker discrimination capability of SpeakerBeam. First, we propose a time-domain implementation of SpeakerBeam similar to that proposed for a time-domain audio separation network (TasNet), which has achieved state-of-the-art performance for speech separation. Besides, we investigate (1) the use of spatial features to better discriminate speakers when microphone array recordings are available, (2) adding an auxiliary speaker identification loss for helping to learn more discriminative voice characteristics. We show experimentally that these strategies greatly improve speech extraction performance, especially for same-gender mixtures, and outperform TasNet in terms of target speech extraction.
Evaluating MT Systems: A Theoretical Framework
Feb 11, 2022This paper outlines a theoretical framework using which different automatic metrics can be designed for evaluation of Machine Translation systems. It introduces the concept of {\em cognitive ease} which depends on {\em adequacy} and {\em lack of fluency}. Thus, cognitive ease becomes the main parameter to be measured rather than comprehensibility. The framework allows the components of cognitive ease to be broken up and computed based on different linguistic levels etc. Independence of dimensions and linearly combining them provides for a highly modular approach. The paper places the existing automatic methods in an overall framework, to understand them better and to improve upon them in future. It can also be used to evaluate the newer types of MT systems, such as speech to speech translation and discourse translation.
Cascade versus Direct Speech Translation: Do the Differences Still Make a Difference?
Jun 02, 2021
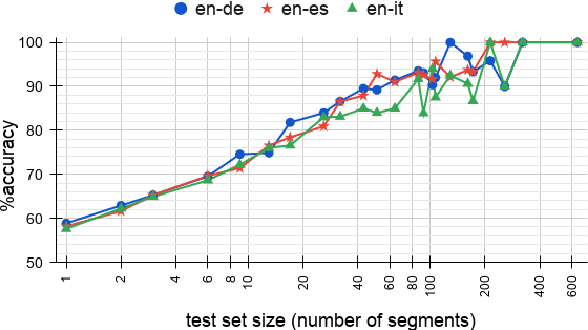
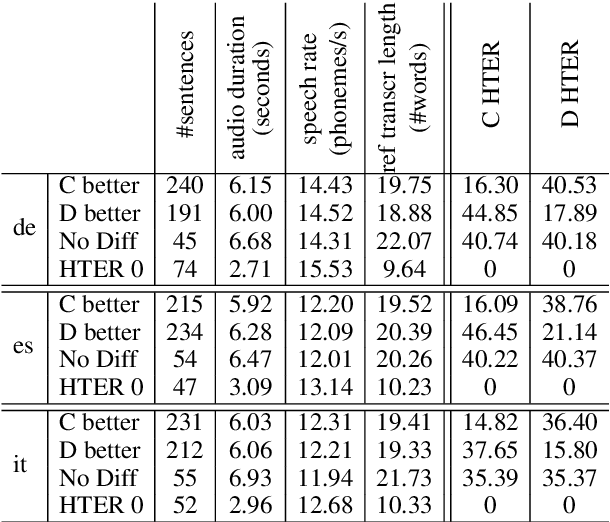

Five years after the first published proofs of concept, direct approaches to speech translation (ST) are now competing with traditional cascade solutions. In light of this steady progress, can we claim that the performance gap between the two is closed? Starting from this question, we present a systematic comparison between state-of-the-art systems representative of the two paradigms. Focusing on three language directions (English-German/Italian/Spanish), we conduct automatic and manual evaluations, exploiting high-quality professional post-edits and annotations. Our multi-faceted analysis on one of the few publicly available ST benchmarks attests for the first time that: i) the gap between the two paradigms is now closed, and ii) the subtle differences observed in their behavior are not sufficient for humans neither to distinguish them nor to prefer one over the other.
Adversarial Feature Learning and Unsupervised Clustering based Speech Synthesis for Found Data with Acoustic and Textual Noise
Apr 28, 2020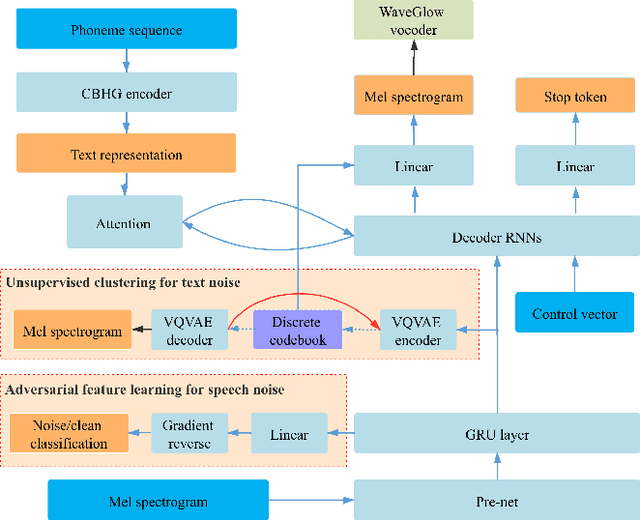
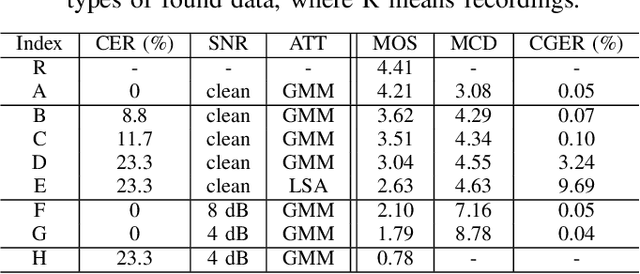
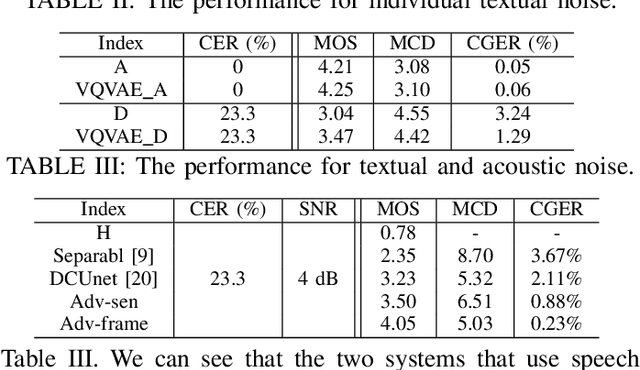
Attention-based sequence-to-sequence (seq2seq) speech synthesis has achieved extraordinary performance. But a studio-quality corpus with manual transcription is necessary to train such seq2seq systems. In this paper, we propose an approach to build high-quality and stable seq2seq based speech synthesis system using challenging found data, where training speech contains noisy interferences (acoustic noise) and texts are imperfect speech recognition transcripts (textual noise). To deal with text-side noise, we propose a VQVAE based heuristic method to compensate erroneous linguistic feature with phonetic information learned directly from speech. As for the speech-side noise, we propose to learn a noise-independent feature in the auto-regressive decoder through adversarial training and data augmentation, which does not need an extra speech enhancement model. Experiments show the effectiveness of the proposed approach in dealing with text-side and speech-side noise. Surpassing the denoising approach based on a state-of-the-art speech enhancement model, our system built on noisy found data can synthesize clean and high-quality speech with MOS close to the system built on the clean counterpart.
Optimizing Speech Emotion Recognition using Manta-Ray Based Feature Selection
Sep 18, 2020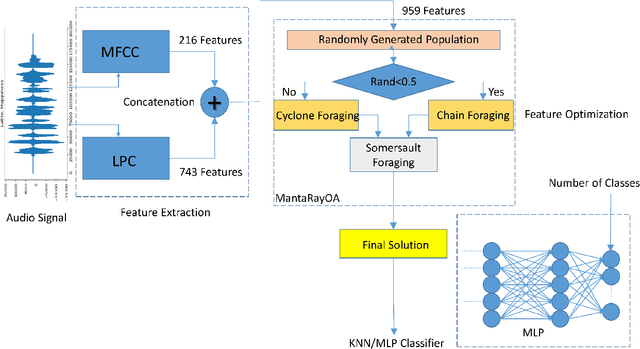
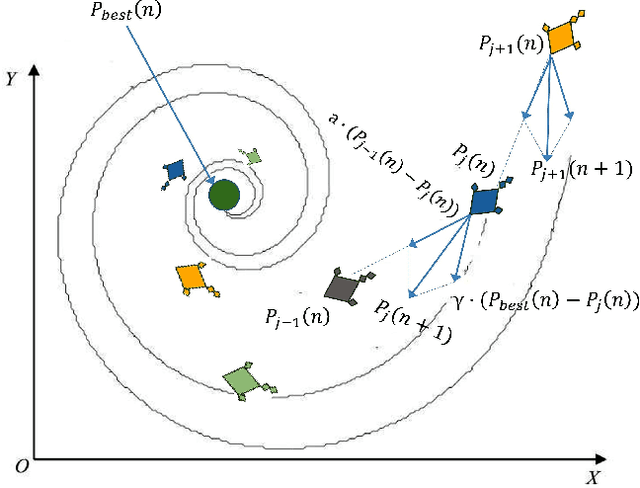
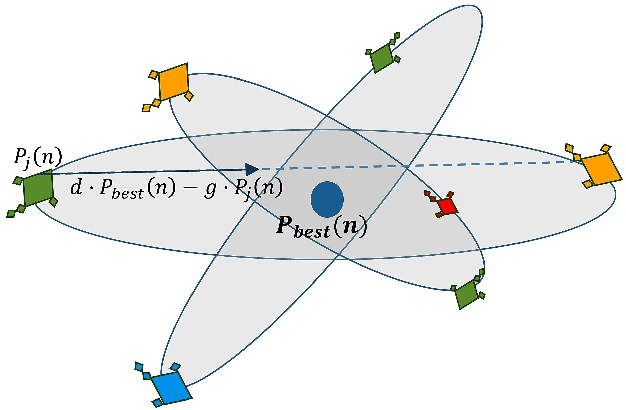
Emotion recognition from audio signals has been regarded as a challenging task in signal processing as it can be considered as a collection of static and dynamic classification tasks. Recognition of emotions from speech data has been heavily relied upon end-to-end feature extraction and classification using machine learning models, though the absence of feature selection and optimization have restrained the performance of these methods. Recent studies have shown that Mel Frequency Cepstral Coefficients (MFCC) have been emerged as one of the most relied feature extraction methods, though it circumscribes the accuracy of classification with a very small feature dimension. In this paper, we propose that the concatenation of features, extracted by using different existing feature extraction methods can not only boost the classification accuracy but also expands the possibility of efficient feature selection. We have used Linear Predictive Coding (LPC) apart from the MFCC feature extraction method, before feature merging. Besides, we have performed a novel application of Manta Ray optimization in speech emotion recognition tasks that resulted in a state-of-the-art result in this field. We have evaluated the performance of our model using SAVEE and Emo-DB, two publicly available datasets. Our proposed method outperformed all the existing methods in speech emotion analysis and resulted in a decent result in these two datasets with a classification accuracy of 97.06% and 97.68% respectively.
PoCoNet: Better Speech Enhancement with Frequency-Positional Embeddings, Semi-Supervised Conversational Data, and Biased Loss
Aug 11, 2020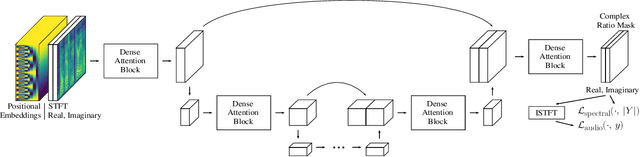
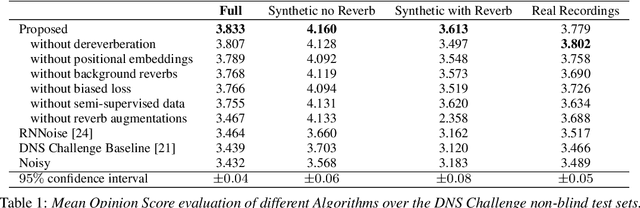
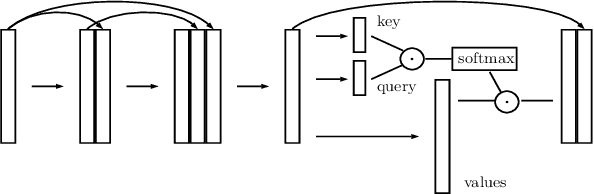
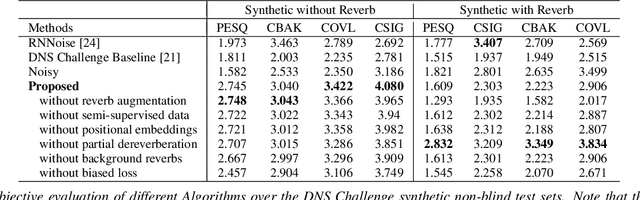
Neural network applications generally benefit from larger-sized models, but for current speech enhancement models, larger scale networks often suffer from decreased robustness to the variety of real-world use cases beyond what is encountered in training data. We introduce several innovations that lead to better large neural networks for speech enhancement. The novel PoCoNet architecture is a convolutional neural network that, with the use of frequency-positional embeddings, is able to more efficiently build frequency-dependent features in the early layers. A semi-supervised method helps increase the amount of conversational training data by pre-enhancing noisy datasets, improving performance on real recordings. A new loss function biased towards preserving speech quality helps the optimization better match human perceptual opinions on speech quality. Ablation experiments and objective and human opinion metrics show the benefits of the proposed improvements.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021
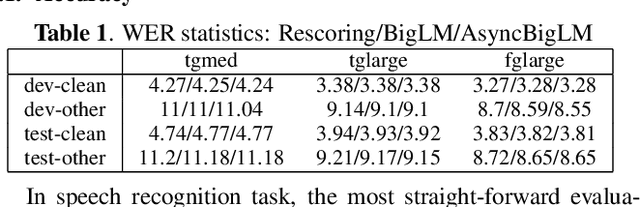
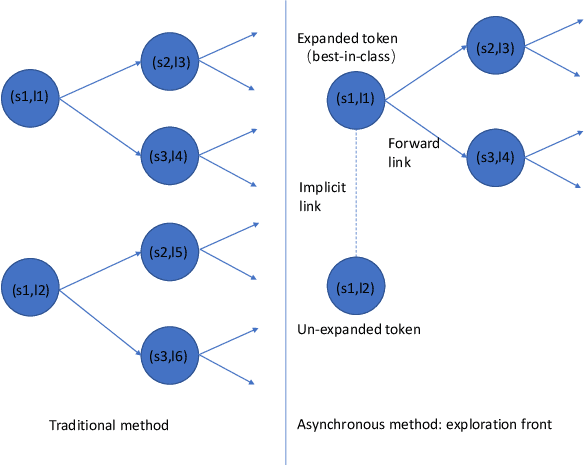
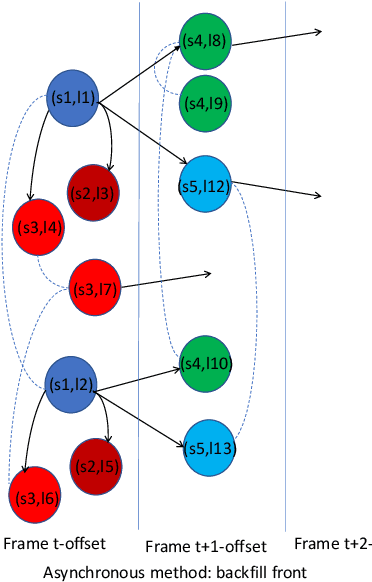
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
Multilingual and Multi-Aspect Hate Speech Analysis
Aug 29, 2019


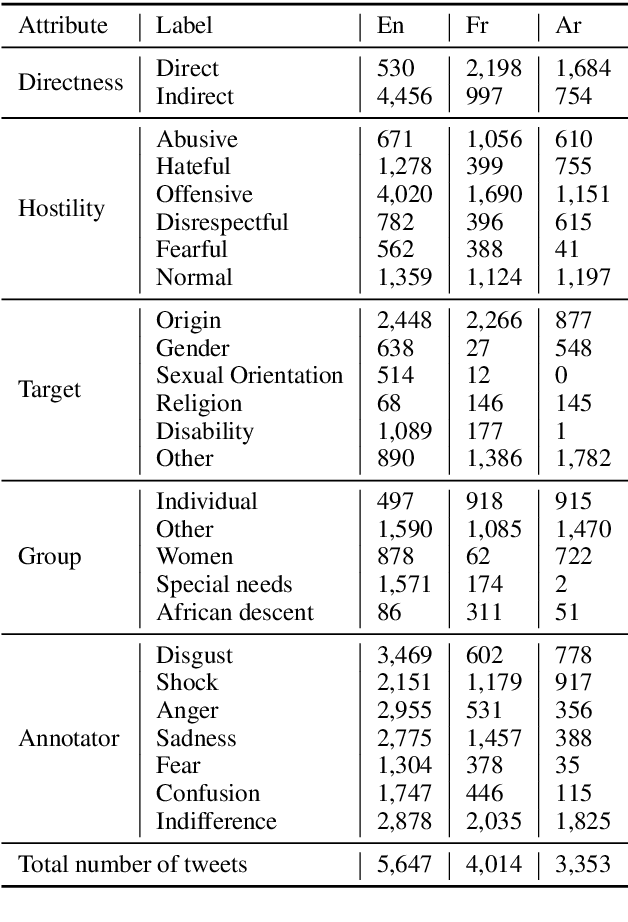
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual multi-aspect hate speech analysis dataset and use it to test the current state-of-the-art multilingual multitask learning approaches. We evaluate our dataset in various classification settings, then we discuss how to leverage our annotations in order to improve hate speech detection and classification in general.