 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CONCSS: Contrastive-based Context Comprehension for Dialogue-appropriate Prosody in Conversational Speech Synthesis
Dec 16, 2023
Conversational speech synthesis (CSS) incorporates historical dialogue as supplementary information with the aim of generating speech that has dialogue-appropriate prosody. While previous methods have already delved into enhancing context comprehension, context representation still lacks effective representation capabilities and context-sensitive discriminability. In this paper, we introduce a contrastive learning-based CSS framework, CONCSS. Within this framework, we define an innovative pretext task specific to CSS that enables the model to perform self-supervised learning on unlabeled conversational datasets to boost the model's context understanding. Additionally, we introduce a sampling strategy for negative sample augmentation to enhance context vectors' discriminability. This is the first attempt to integrate contrastive learning into CSS. We conduct ablation studies on different contrastive learning strategies and comprehensive experiments in comparison with prior CSS systems. Results demonstrate that the synthesized speech from our proposed method exhibits more contextually appropriate and sensitive prosody.
StyleSpeech: Self-supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
Dec 19, 2023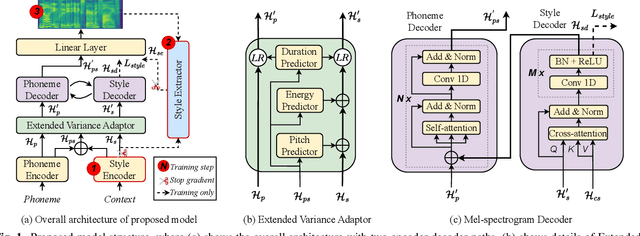

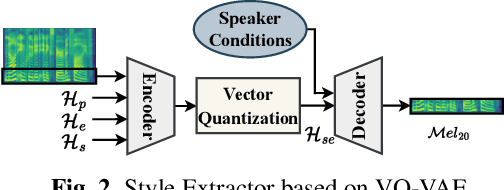
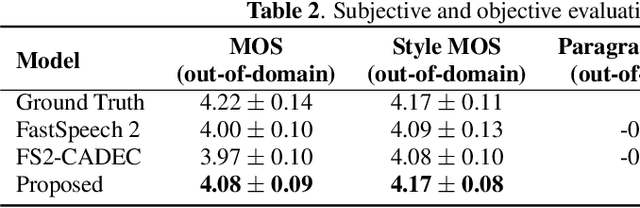
The expressive quality of synthesized speech for audiobooks is limited by generalized model architecture and unbalanced style distribution in the training data. To address these issues, in this paper, we propose a self-supervised style enhancing method with VQ-VAE-based pre-training for expressive audiobook speech synthesis. Firstly, a text style encoder is pre-trained with a large amount of unlabeled text-only data. Secondly, a spectrogram style extractor based on VQ-VAE is pre-trained in a self-supervised manner, with plenty of audio data that covers complex style variations. Then a novel architecture with two encoder-decoder paths is specially designed to model the pronunciation and high-level style expressiveness respectively, with the guidance of the style extractor. Both objective and subjective evaluations demonstrate that our proposed method can effectively improve the naturalness and expressiveness of the synthesized speech in audiobook synthesis especially for the role and out-of-domain scenarios.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Dec 16, 2023With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on small wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
LitE-SNN: Designing Lightweight and Efficient Spiking Neural Network through Spatial-Temporal Compressive Network Search and Joint Optimization
Jan 26, 2024Spiking Neural Networks (SNNs) mimic the information-processing mechanisms of the human brain and are highly energy-efficient, making them well-suited for low-power edge devices. However, the pursuit of accuracy in current studies leads to large, long-timestep SNNs, conflicting with the resource constraints of these devices. In order to design lightweight and efficient SNNs, we propose a new approach named LitESNN that incorporates both spatial and temporal compression into the automated network design process. Spatially, we present a novel Compressive Convolution block (CompConv) to expand the search space to support pruning and mixed-precision quantization while utilizing the shared weights and pruning mask to reduce the computation. Temporally, we are the first to propose a compressive timestep search to identify the optimal number of timesteps under specific computation cost constraints. Finally, we formulate a joint optimization to simultaneously learn the architecture parameters and spatial-temporal compression strategies to achieve high performance while minimizing memory and computation costs. Experimental results on CIFAR10, CIFAR100, and Google Speech Command datasets demonstrate our proposed LitESNNs can achieve competitive or even higher accuracy with remarkably smaller model sizes and fewer computation costs. Furthermore, we validate the effectiveness of our LitESNN on the trade-off between accuracy and resource cost and show the superiority of our joint optimization. Additionally, we conduct energy analysis to further confirm the energy efficiency of LitESNN
On the Parameter Estimation of Sinusoidal Models for Speech and Audio Signals
Jan 02, 2024In this paper, we examine the parameter estimation performance of three well-known sinusoidal models for speech and audio. The first one is the standard Sinusoidal Model (SM), which is based on the Fast Fourier Transform (FFT). The second is the Exponentially Damped Sinusoidal Model (EDSM) which has been proposed in the last decade, and utilizes a subspace method for parameter estimation, and finally the extended adaptive Quasi-Harmonic Model (eaQHM), which has been recently proposed for AM-FM decomposition, and estimates the signal parameters using Least Squares on a set of basis function that are adaptive to the local characteristics of the signal. The parameter estimation of each model is briefly described and its performance is compared to the others in terms of signal reconstruction accuracy versus window size on a variety of synthetic signals and versus the number of sinusoids on real signals. The latter include highly non stationary signals, such as singing voices and guitar solos. The advantages and disadvantages of each model are presented via synthetic signals and then the application on real signals is discussed. Conclusively, eaQHM outperforms EDS in medium-to-large window size analysis, whereas EDSM yields higher reconstruction values for smaller analysis window sizes. Thus, a future research direction appears to be the merge of adaptivity of the eaQHM and parameter estimation robustness of the EDSM in a new paradigm for high-quality analysis and resynthesis of general audio signals.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Dec 13, 2023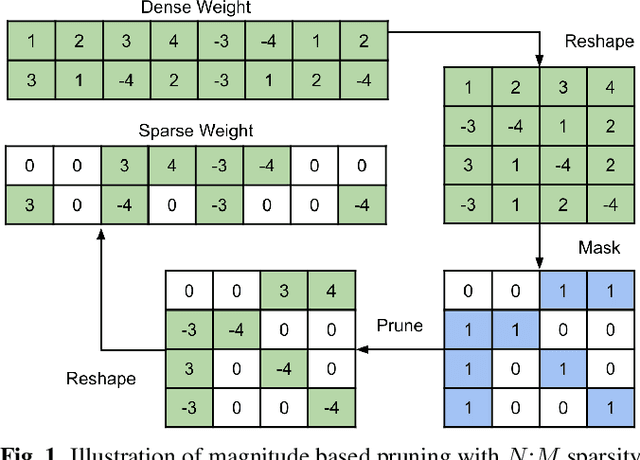
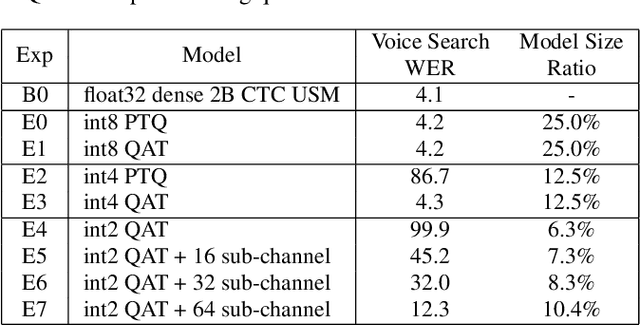
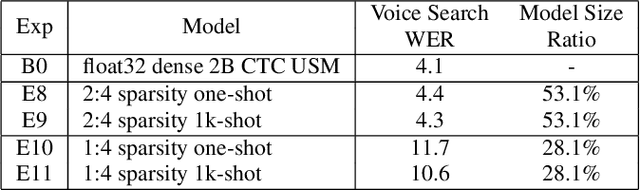
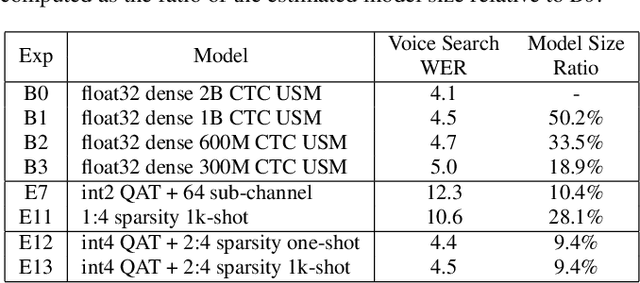
End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Study of cognitive component of auditory attention to natural speech events
Dec 19, 2023Event-related potentials (ERP) have been used to address a wide range of research questions in neuroscience and cognitive psychology including selective auditory attention. The recent progress in auditory attention decoding (AAD) methods is based on algorithms that find a relation between the audio envelope and the neurophysiological response. The most popular approach is based on the reconstruction of the audio envelope based on EEG signals. However, these methods are mainly based on the neurophysiological entrainment to physical attributes of the sensory stimulus and are generally limited by a long detection window. This study proposes a novel approach to auditory attention decoding by looking at higher-level cognitive responses to natural speech. To investigate if natural speech events elicit cognitive ERP components and how these components are affected by attention mechanisms, we designed a series of four experimental paradigms with increasing complexity: a word category oddball paradigm, a word category oddball paradigm with competing speakers, and competing speech streams with and without specific targets. We recorded the electroencephalogram (EEG) from 32 scalp electrodes and 12 in-ear electrodes (ear-EEG) from 24 participants. A cognitive ERP component, which we believe is related to the well-known P3b component, was observed at parietal electrode sites with a latency of approximately 620 ms. The component is statistically most significant for the simplest paradigm and gradually decreases in strength with increasing complexity of the paradigm. We also show that the component can be observed in the in-ear EEG signals by using spatial filtering. The cognitive component elicited by auditory attention may contribute to decoding auditory attention from electrophysiological recordings and its presence in the ear-EEG signals is promising for future applications within hearing aids.
Toward A Reinforcement-Learning-Based System for Adjusting Medication to Minimize Speech Disfluency
Dec 12, 2023We propose a Reinforcement-Learning-based system that would automatically prescribe a hypothetical patient medications that may help the patient with their mental-health-related speech disfluency, and adjust the medication and the dosages in response to data from the patient. We demonstrate the components of the system: a module that detects and evaluates speech disfluency on a large dataset we built, and a Reinforcement Learning algorithm that automatically finds good combinations of medications. To support the two modules, we collect data on the effect of psychiatric medications for speech disfluency from the literature, and build a plausible patient simulation system. We demonstrate that the Reinforcement Learning system is, under some circumstances, able to converge to a good medication regime. We collect and label a dataset of people with possible speech disfluency and demonstrate our methods using that dataset. Our work is a proof of concept: we show that there is promise in the idea of using automatic data collection to address disfluency.