 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Generative Pre-Training for Speech with Autoregressive Predictive Coding
Oct 23, 2019
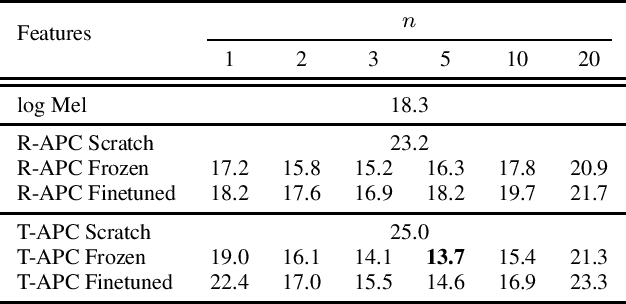
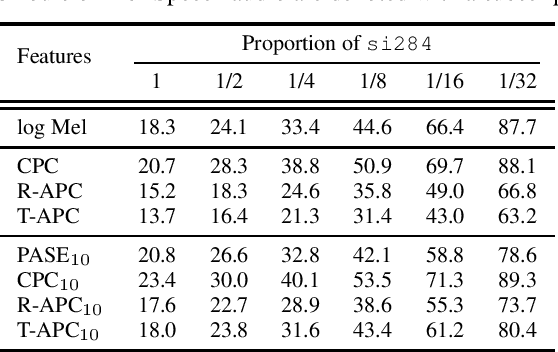
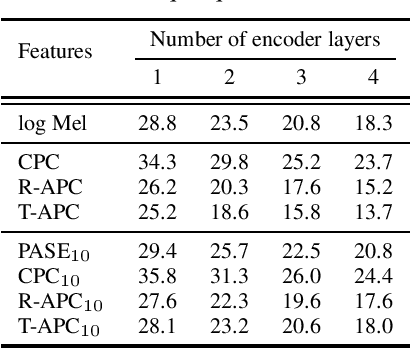
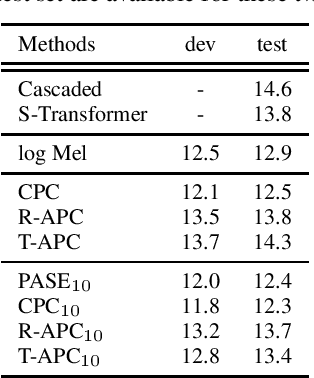
Learning meaningful and general representations from unannotated speech that are applicable to a wide range of tasks remains challenging. In this paper we propose to use autoregressive predictive coding (APC), a recently proposed self-supervised objective, as a generative pre-training approach for learning meaningful, non-specific, and transferable speech representations. We pre-train APC on large-scale unlabeled data and conduct transfer learning experiments on three speech applications that require different information about speech characteristics to perform well: speech recognition, speech translation, and speaker identification. Extensive experiments show that APC not only outperforms surface features (e.g., log Mel spectrograms) and other popular representation learning methods on all three tasks, but is also effective at reducing downstream labeled data size and model parameters. We also investigate the use of Transformers for modeling APC and find it superior to RNNs.
Deep Residual Local Feature Learning for Speech Emotion Recognition
Nov 19, 2020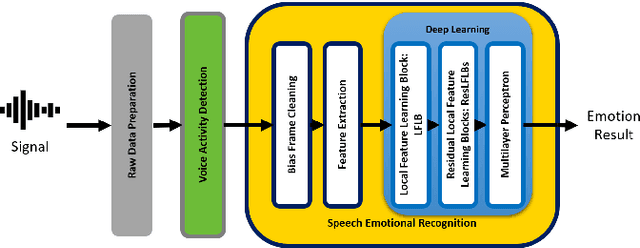
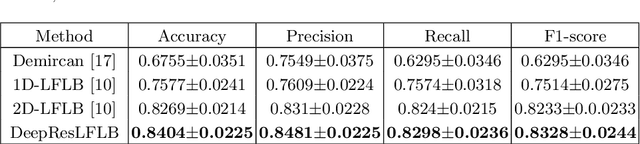
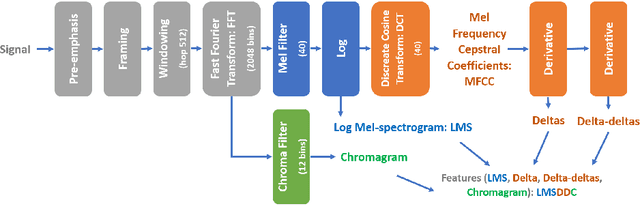

Speech Emotion Recognition (SER) is becoming a key role in global business today to improve service efficiency, like call center services. Recent SERs were based on a deep learning approach. However, the efficiency of deep learning depends on the number of layers, i.e., the deeper layers, the higher efficiency. On the other hand, the deeper layers are causes of a vanishing gradient problem, a low learning rate, and high time-consuming. Therefore, this paper proposed a redesign of existing local feature learning block (LFLB). The new design is called a deep residual local feature learning block (DeepResLFLB). DeepResLFLB consists of three cascade blocks: LFLB, residual local feature learning block (ResLFLB), and multilayer perceptron (MLP). LFLB is built for learning local correlations along with extracting hierarchical correlations; DeepResLFLB can take advantage of repeatedly learning to explain more detail in deeper layers using residual learning for solving vanishing gradient and reducing overfitting; and MLP is adopted to find the relationship of learning and discover probability for predicted speech emotions and gender types. Based on two available published datasets: EMODB and RAVDESS, the proposed DeepResLFLB can significantly improve performance when evaluated by standard metrics: accuracy, precision, recall, and F1-score.
Voice Conversion Can Improve ASR in Very Low-Resource Settings
Nov 04, 2021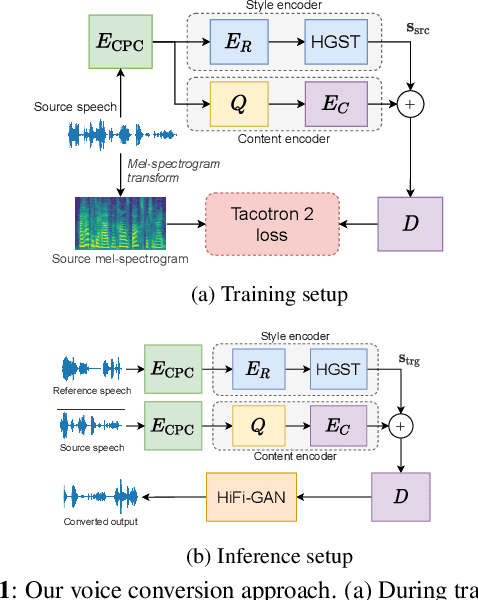
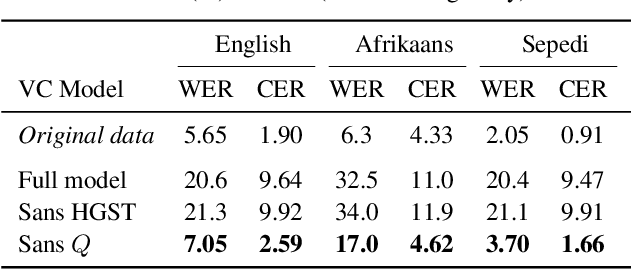
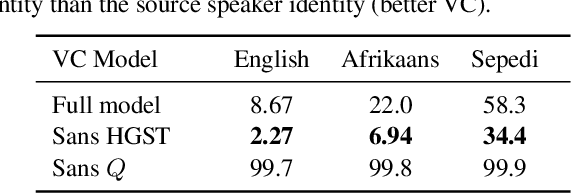

Voice conversion (VC) has been proposed to improve speech recognition systems in low-resource languages by using it to augment limited training data. But until recently, practical issues such as compute speed have limited the use of VC for this purpose. Moreover, it is still unclear whether a VC model trained on one well-resourced language can be applied to speech from another low-resource language for the purpose of data augmentation. In this work we assess whether a VC system can be used cross-lingually to improve low-resource speech recognition. Concretely, we combine several recent techniques to design and train a practical VC system in English, and then use this system to augment data for training a speech recognition model in several low-resource languages. We find that when using a sensible amount of augmented data, speech recognition performance is improved in all four low-resource languages considered.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 10, 2020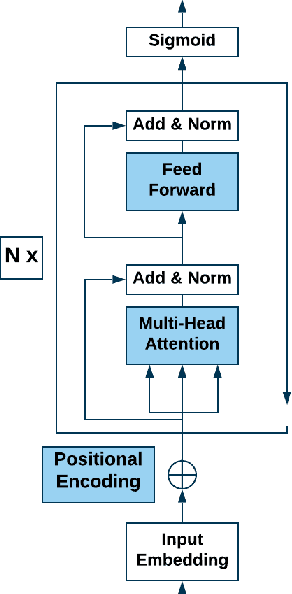

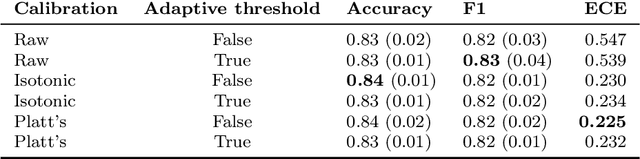
Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jul 22, 2021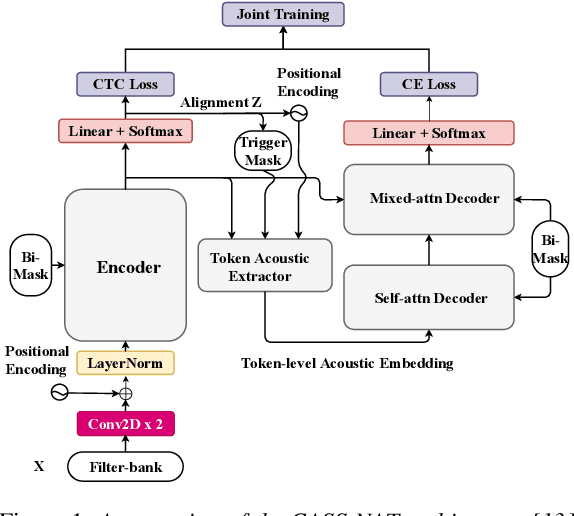
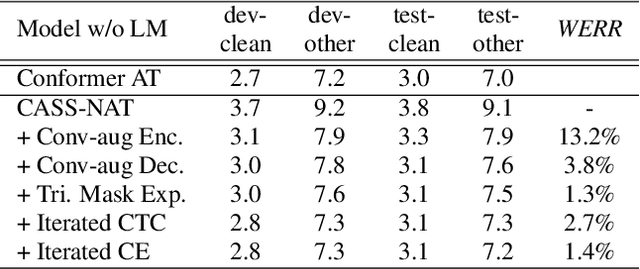
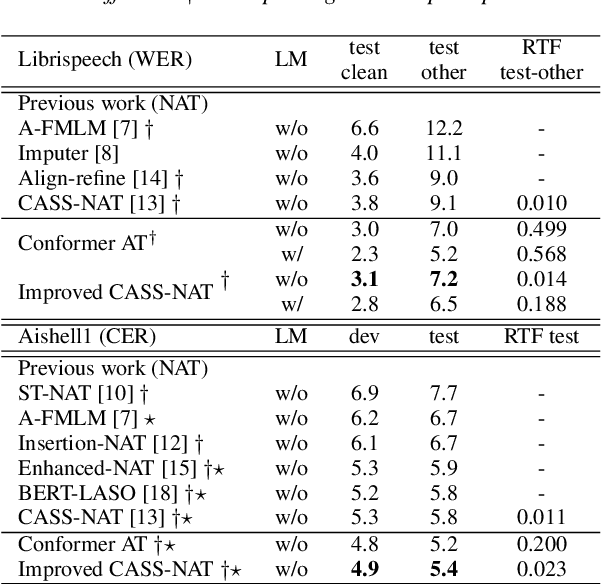
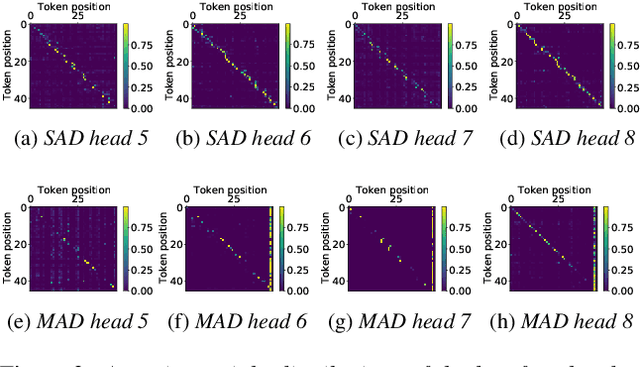
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Self-Supervised Learning from Contrastive Mixtures for Personalized Speech Enhancement
Nov 06, 2020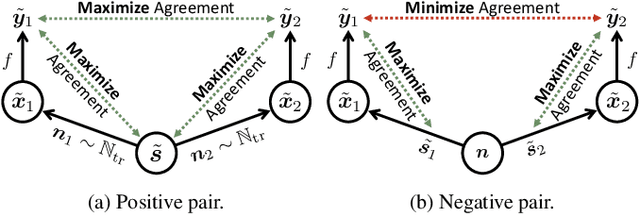


This work explores how self-supervised learning can be universally used to discover speaker-specific features towards enabling personalized speech enhancement models. We specifically address the few-shot learning scenario where access to cleaning recordings of a test-time speaker is limited to a few seconds, but noisy recordings of the speaker are abundant. We develop a simple contrastive learning procedure which treats the abundant noisy data as makeshift training targets through pairwise noise injection: the model is pretrained to maximize agreement between pairs of differently deformed identical utterances and to minimize agreement between pairs of similarly deformed nonidentical utterances. Our experiments compare the proposed pretraining approach with two baseline alternatives: speaker-agnostic fully-supervised pretraining, and speaker-specific self-supervised pretraining without contrastive loss terms. Of all three approaches, the proposed method using contrastive mixtures is found to be most robust to model compression (using 85% fewer parameters) and reduced clean speech (requiring only 3 seconds).
Towards the Objective Speech Assessment of Smoking Status based on Voice Features: A Review of the Literature
Jun 15, 2021
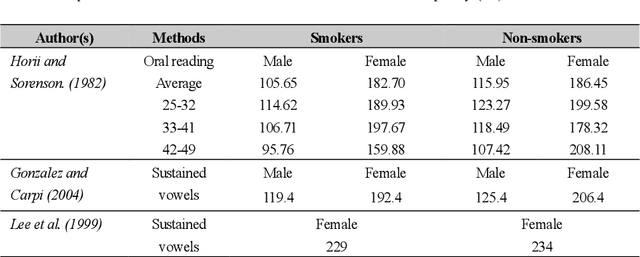
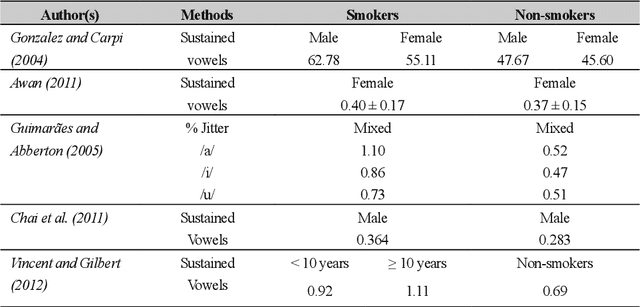
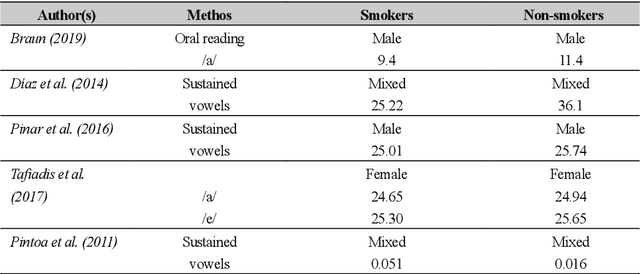
In smoking cessation clinical research and practice, objective validation of self-reported smoking status is crucial for ensuring the reliability of the primary outcome, that is, smoking abstinence. Speech signals convey important information about a speaker, such as age, gender, body size, emotional state, and health state. We investigated (1) if smoking could measurably alter voice features, (2) if smoking cessation could lead to changes in voice, and therefore (3) if the voice-based smoking status assessment has the potential to be used as an objective smoking cessation validation method.
Single Channel Speech Enhancement Using Temporal Convolutional Recurrent Neural Networks
Feb 02, 2020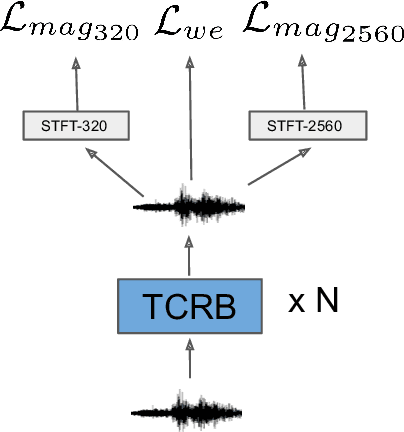
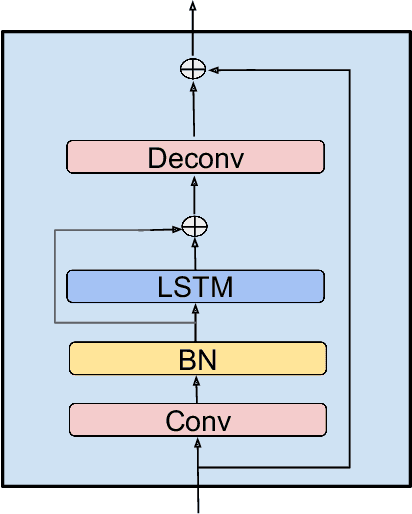

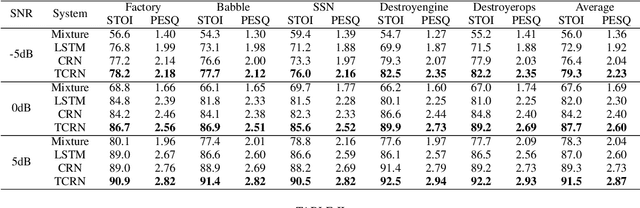
In recent decades, neural network based methods have significantly improved the performace of speech enhancement. Most of them estimate time-frequency (T-F) representation of target speech directly or indirectly, then resynthesize waveform using the estimated T-F representation. In this work, we proposed the temporal convolutional recurrent network (TCRN), an end-to-end model that directly map noisy waveform to clean waveform. The TCRN, which is combined convolution and recurrent neural network, is able to efficiently and effectively leverage short-term ang long-term information. Futuremore, we present the architecture that repeatedly downsample and upsample speech during forward propagation. We show that our model is able to improve the performance of model, compared with existing convolutional recurrent networks. Futuremore, We present several key techniques to stabilize the training process. The experimental results show that our model consistently outperforms existing speech enhancement approaches, in terms of speech intelligibility and quality.
Deficient Basis Estimation of Noise Spatial Covariance Matrix for Rank-Constrained Spatial Covariance Matrix Estimation Method in Blind Speech Extraction
May 06, 2021
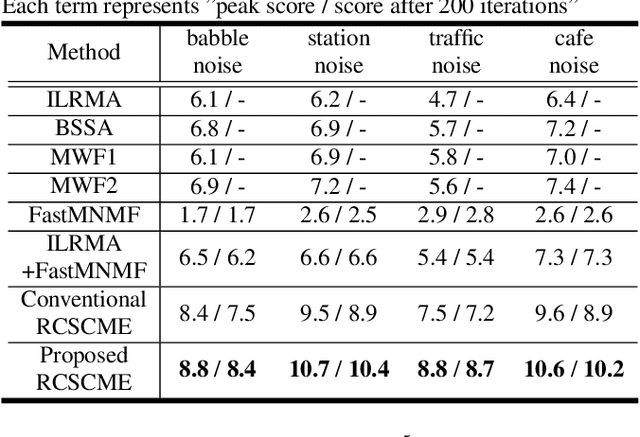
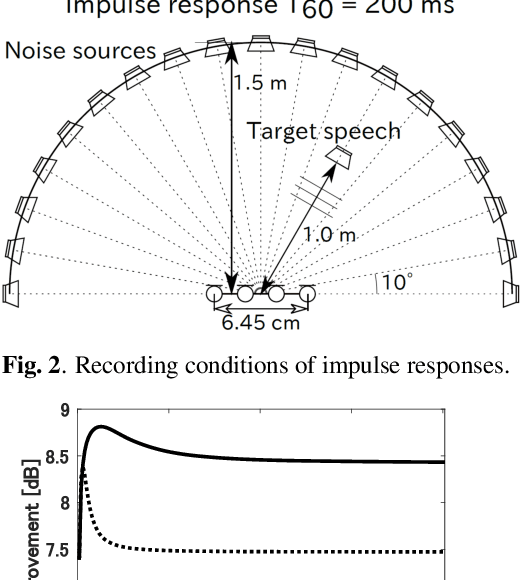
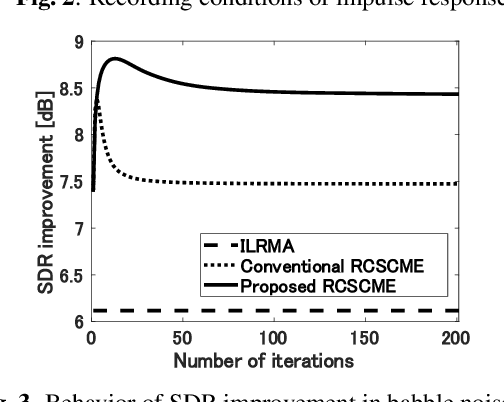
Rank-constrained spatial covariance matrix estimation (RCSCME) is a state-of-the-art blind speech extraction method applied to cases where one directional target speech and diffuse noise are mixed. In this paper, we proposed a new algorithmic extension of RCSCME. RCSCME complements a deficient one rank of the diffuse noise spatial covariance matrix, which cannot be estimated via preprocessing such as independent low-rank matrix analysis, and estimates the source model parameters simultaneously. In the conventional RCSCME, a direction of the deficient basis is fixed in advance and only the scale is estimated; however, the candidate of this deficient basis is not unique in general. In the proposed RCSCME model, the deficient basis itself can be accurately estimated as a vector variable by solving a vector optimization problem. Also, we derive new update rules based on the EM algorithm. We confirm that the proposed method outperforms conventional methods under several noise conditions.
Learning to Rank Microphones for Distant Speech Recognition
Apr 13, 2021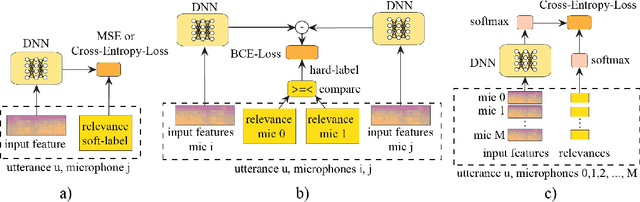
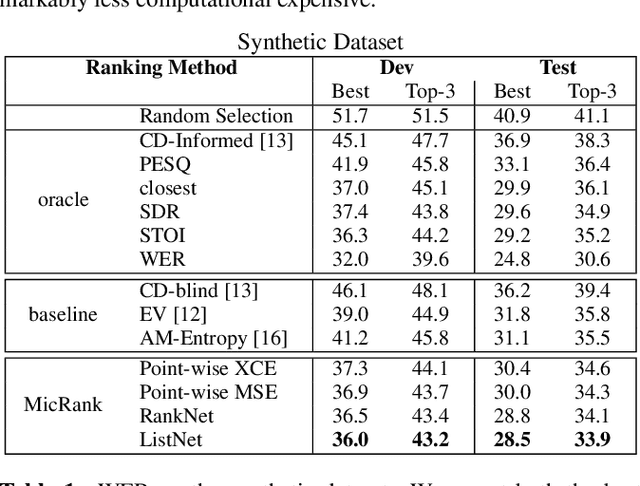
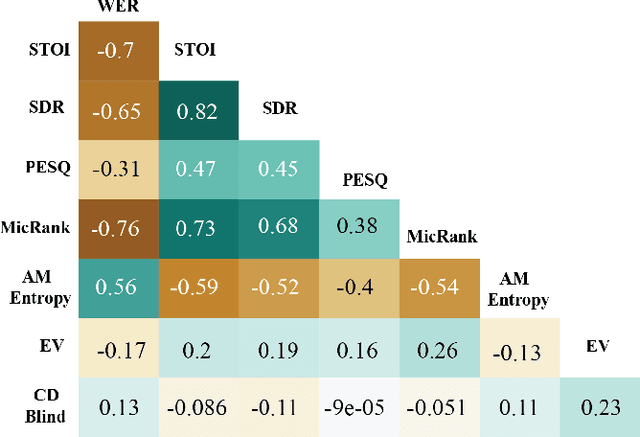
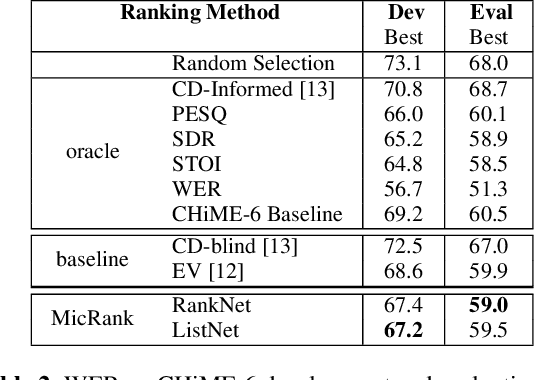
Fully exploiting ad-hoc microphone networks for distant speech recognition is still an open issue. Empirical evidence shows that being able to select the best microphone leads to significant improvements in recognition without any additional effort on front-end processing. Current channel selection techniques either rely on signal, decoder or posterior-based features. Signal-based features are inexpensive to compute but do not always correlate with recognition performance. Instead decoder and posterior-based features exhibit better correlation but require substantial computational resources. In this work, we tackle the channel selection problem by proposing MicRank, a learning to rank framework where a neural network is trained to rank the available channels using directly the recognition performance on the training set. The proposed approach is agnostic with respect to the array geometry and type of recognition back-end. We investigate different learning to rank strategies using a synthetic dataset developed on purpose and the CHiME-6 data. Results show that the proposed approach is able to considerably improve over previous selection techniques, reaching comparable and in some instances better performance than oracle signal-based measures.