 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deep F-measure Maximization for End-to-End Speech Understanding
Aug 08, 2020
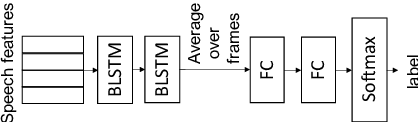
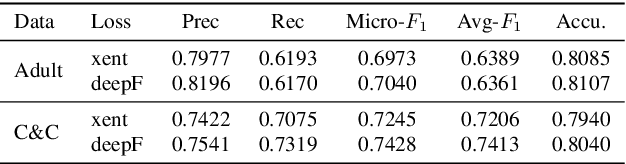
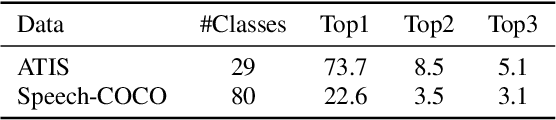
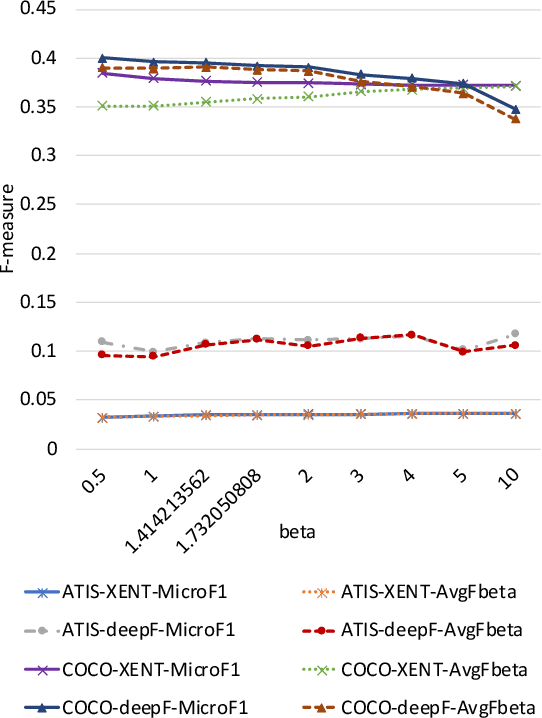
Spoken language understanding (SLU) datasets, like many other machine learning datasets, usually suffer from the label imbalance problem. Label imbalance usually causes the learned model to replicate similar biases at the output which raises the issue of unfairness to the minority classes in the dataset. In this work, we approach the fairness problem by maximizing the F-measure instead of accuracy in neural network model training. We propose a differentiable approximation to the F-measure and train the network with this objective using standard backpropagation. We perform experiments on two standard fairness datasets, Adult, and Communities and Crime, and also on speech-to-intent detection on the ATIS dataset and speech-to-image concept classification on the Speech-COCO dataset. In all four of these tasks, F-measure maximization results in improved micro-F1 scores, with absolute improvements of up to 8% absolute, as compared to models trained with the cross-entropy loss function. In the two multi-class SLU tasks, the proposed approach significantly improves class coverage, i.e., the number of classes with positive recall.
Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-resource Speech Recognition
Jan 24, 2021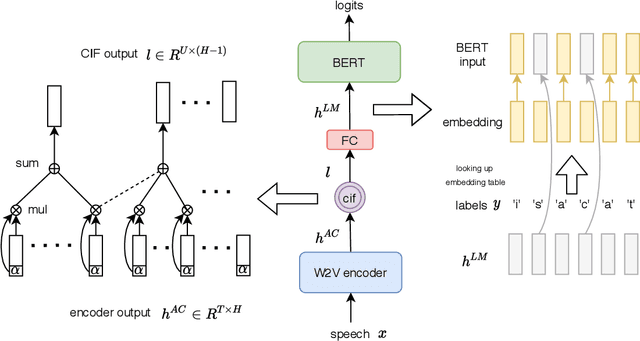
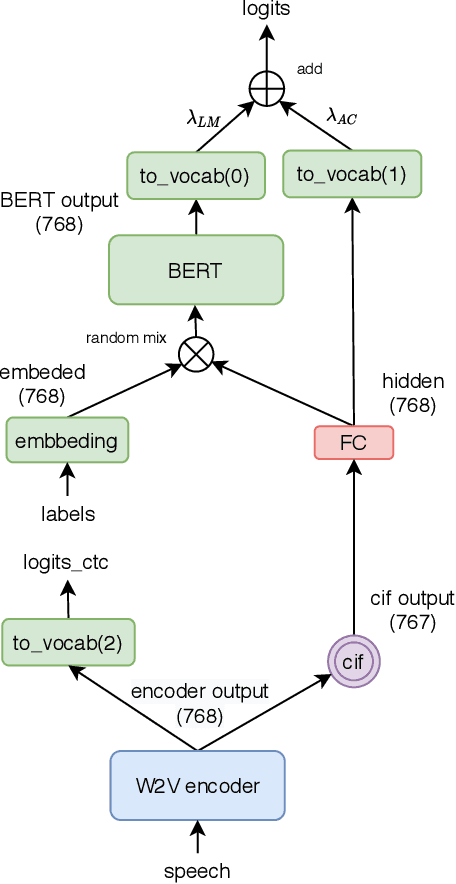
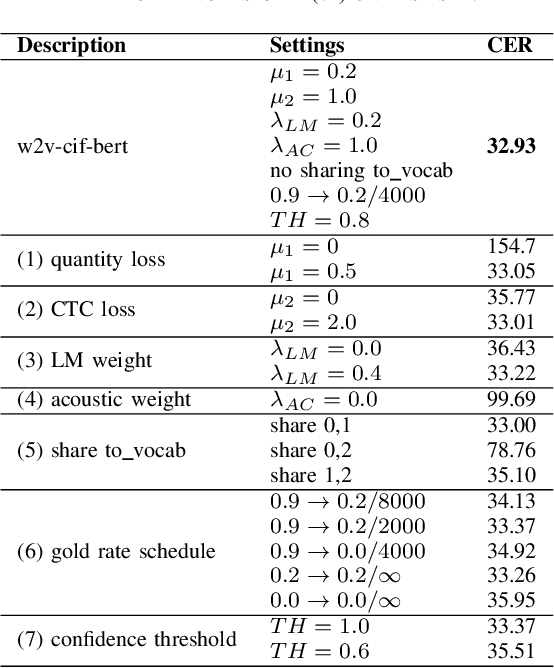
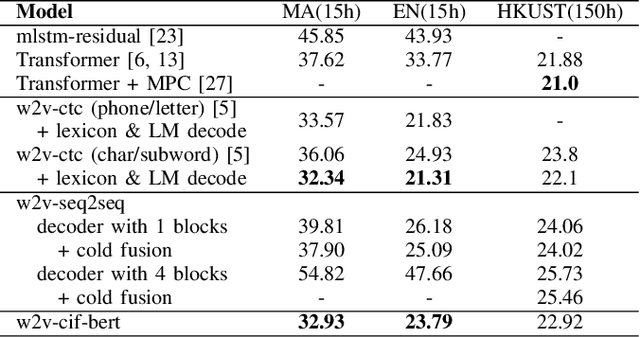
End-to-end models have achieved impressive results on the task of automatic speech recognition (ASR). For low-resource ASR tasks, however, labeled data can hardly satisfy the demand of end-to-end models. Self-supervised acoustic pre-training has already shown its amazing ASR performance, while the transcription is still inadequate for language modeling in end-to-end models. In this work, we fuse a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model. The fused model only needs to learn the transfer from speech to language during fine-tuning on limited labeled data. The length of the two modalities is matched by a monotonic attention mechanism without additional parameters. Besides, a fully connected layer is introduced for the hidden mapping between modalities. We further propose a scheduled fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained linguistic encoder. Experiments show our effective utilizing of pre-trained modules. Our model achieves better recognition performance on CALLHOME corpus (15 hours) than other end-to-end models.
Whose Opinions Matter? Perspective-aware Models to Identify Opinions of Hate Speech Victims in Abusive Language Detection
Jun 30, 2021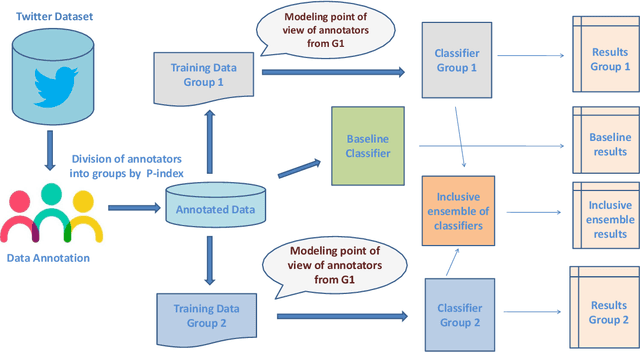
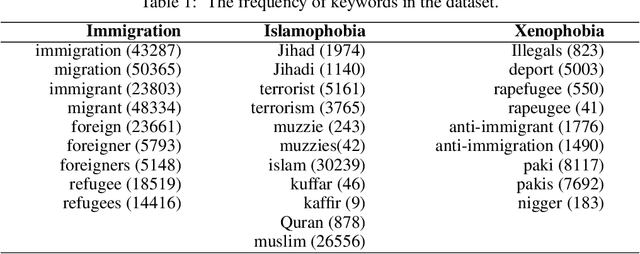
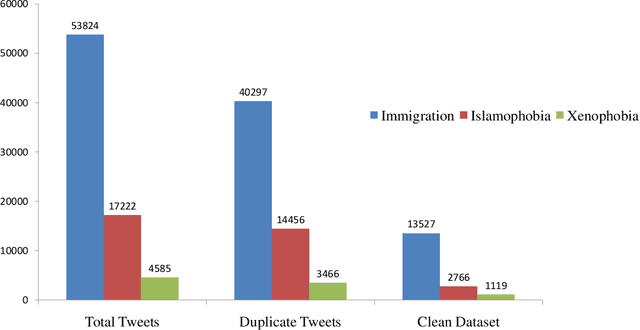

Social media platforms provide users the freedom of expression and a medium to exchange information and express diverse opinions. Unfortunately, this has also resulted in the growth of abusive content with the purpose of discriminating people and targeting the most vulnerable communities such as immigrants, LGBT, Muslims, Jews and women. Because abusive language is subjective in nature, there might be highly polarizing topics or events involved in the annotation of abusive contents such as hate speech (HS). Therefore, we need novel approaches to model conflicting perspectives and opinions coming from people with different personal and demographic backgrounds. In this paper, we present an in-depth study to model polarized opinions coming from different communities under the hypothesis that similar characteristics (ethnicity, social background, culture etc.) can influence the perspectives of annotators on a certain phenomenon. We believe that by relying on this information, we can divide the annotators into groups sharing similar perspectives. We can create separate gold standards, one for each group, to train state-of-the-art deep learning models. We can employ an ensemble approach to combine the perspective-aware classifiers from different groups to an inclusive model. We also propose a novel resource, a multi-perspective English language dataset annotated according to different sub-categories relevant for characterising online abuse: hate speech, aggressiveness, offensiveness and stereotype. By training state-of-the-art deep learning models on this novel resource, we show how our approach improves the prediction performance of a state-of-the-art supervised classifier.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jun 15, 2021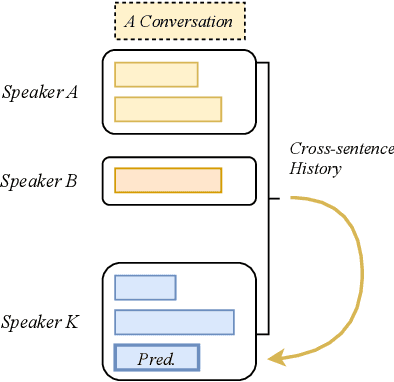
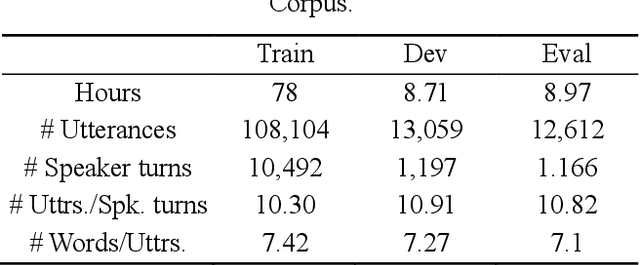
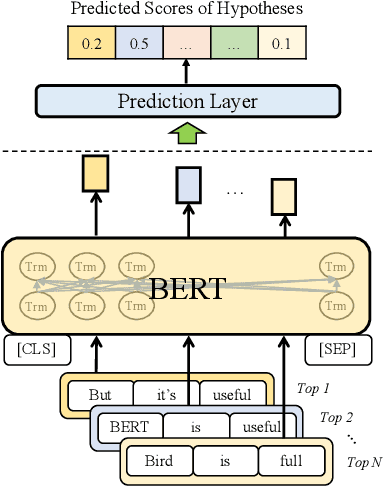
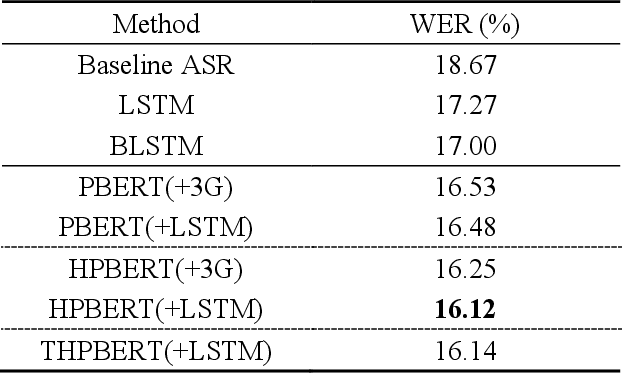
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Improving EEG based continuous speech recognition using GAN
May 29, 2020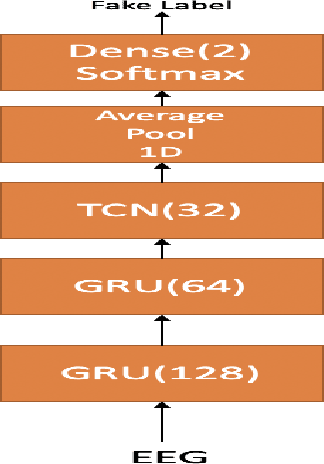
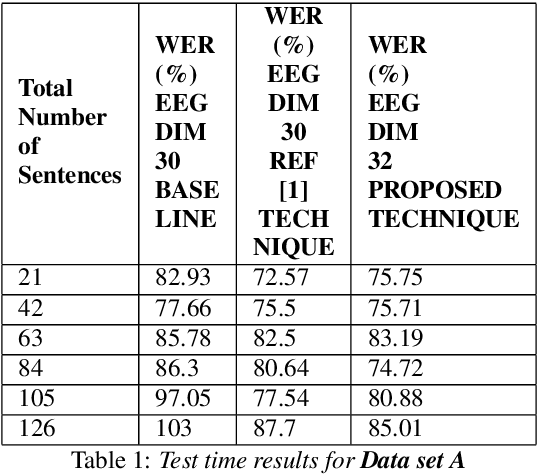
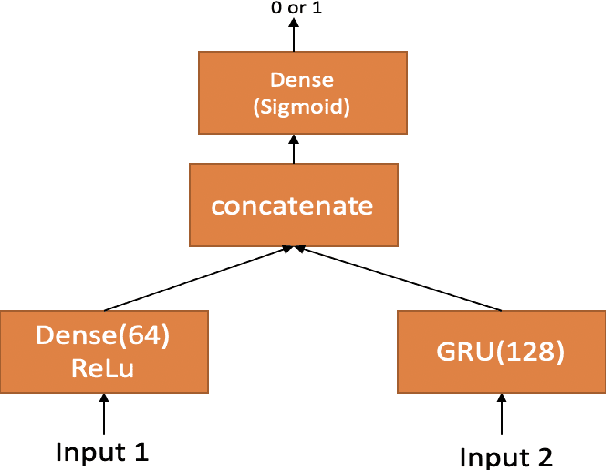
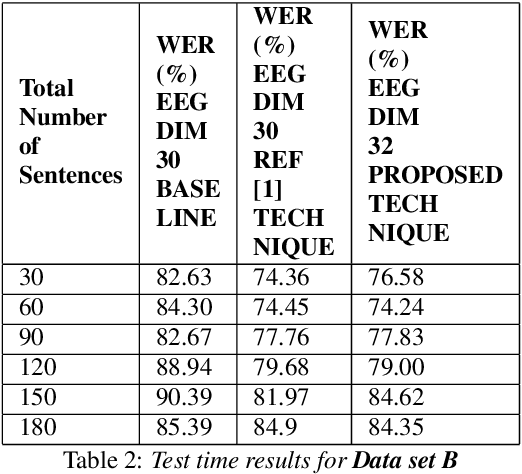
In this paper we demonstrate that it is possible to generate more meaningful electroencephalography (EEG) features from raw EEG features using generative adversarial networks (GAN) to improve the performance of EEG based continuous speech recognition systems. We improve the results demonstrated by authors in [1] using their data sets for for some of the test time experiments and for other cases our results were comparable with theirs. Our proposed approach can be implemented without using any additional sensor information, whereas in [1] authors used additional features like acoustic or articulatory information to improve the performance of EEG based continuous speech recognition systems.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 16, 2020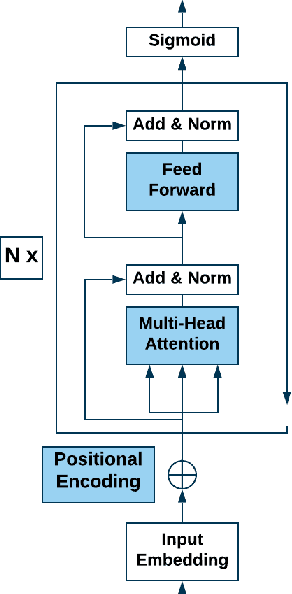

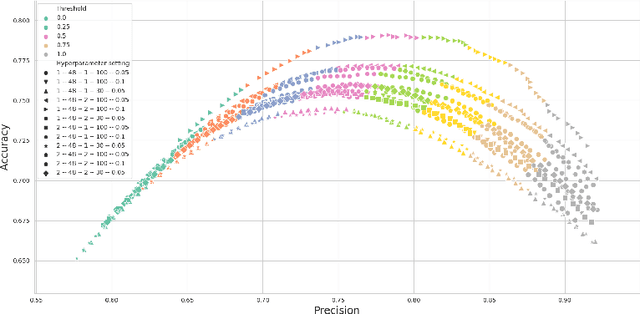
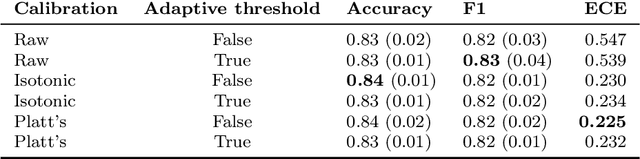
Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
Neural Dubber: Dubbing for Silent Videos According to Scripts
Oct 15, 2021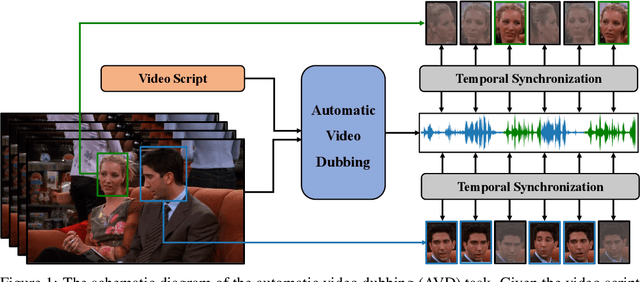
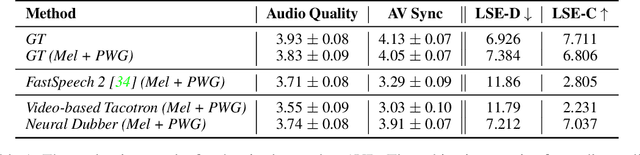
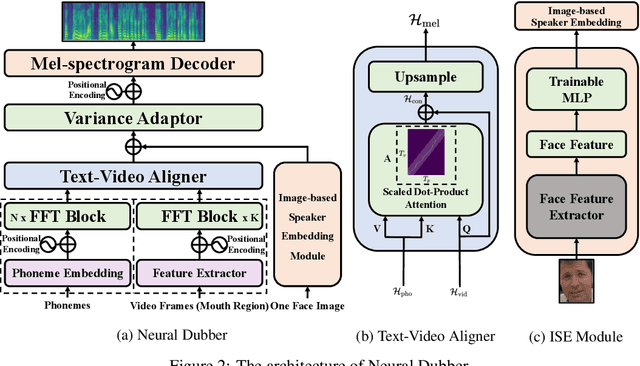
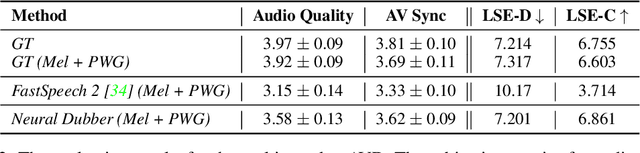
Dubbing is a post-production process of re-recording actors' dialogues, which is extensively used in filmmaking and video production. It is usually performed manually by professional voice actors who read lines with proper prosody, and in synchronization with the pre-recorded videos. In this work, we propose Neural Dubber, the first neural network model to solve a novel automatic video dubbing (AVD) task: synthesizing human speech synchronized with the given silent video from the text. Neural Dubber is a multi-modal text-to-speech (TTS) model that utilizes the lip movement in the video to control the prosody of the generated speech. Furthermore, an image-based speaker embedding (ISE) module is developed for the multi-speaker setting, which enables Neural Dubber to generate speech with a reasonable timbre according to the speaker's face. Experiments on the chemistry lecture single-speaker dataset and LRS2 multi-speaker dataset show that Neural Dubber can generate speech audios on par with state-of-the-art TTS models in terms of speech quality. Most importantly, both qualitative and quantitative evaluations show that Neural Dubber can control the prosody of synthesized speech by the video, and generate high-fidelity speech temporally synchronized with the video.
Deep neural network Based Low-latency Speech Separation with Asymmetric analysis-Synthesis Window Pair
Jun 22, 2021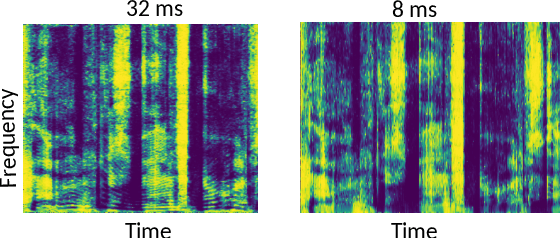
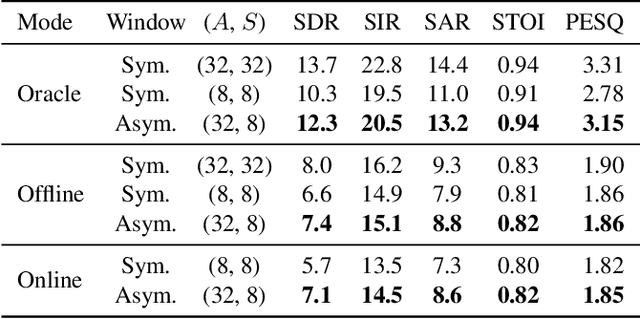
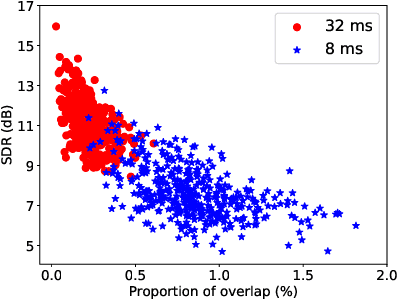
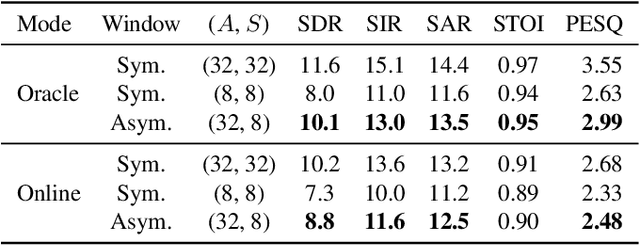
Time-frequency masking or spectrum prediction computed via short symmetric windows are commonly used in low-latency deep neural network (DNN) based source separation. In this paper, we propose the usage of an asymmetric analysis-synthesis window pair which allows for training with targets with better frequency resolution, while retaining the low-latency during inference suitable for real-time speech enhancement or assisted hearing applications. In order to assess our approach across various model types and datasets, we evaluate it with both speaker-independent deep clustering (DC) model and a speaker-dependent mask inference (MI) model. We report an improvement in separation performance of up to 1.5 dB in terms of source-to-distortion ratio (SDR) while maintaining an algorithmic latency of 8 ms.
Hate Speech detection in the Bengali language: A dataset and its baseline evaluation
Dec 17, 2020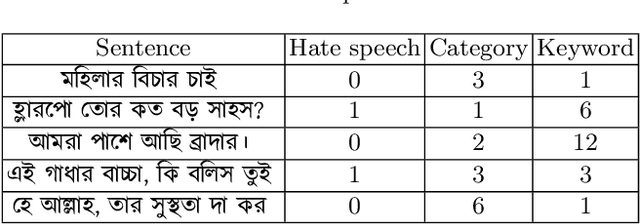
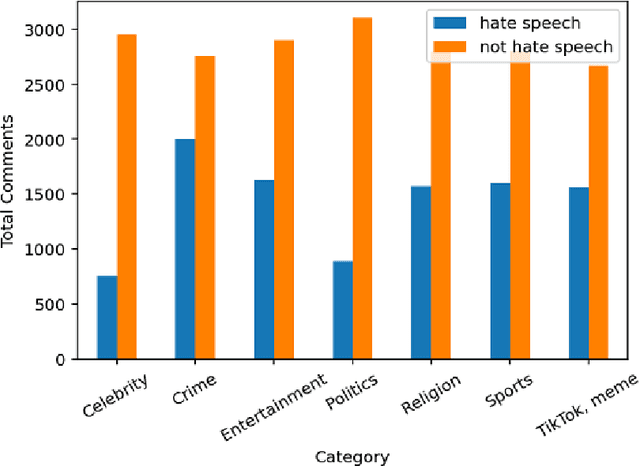
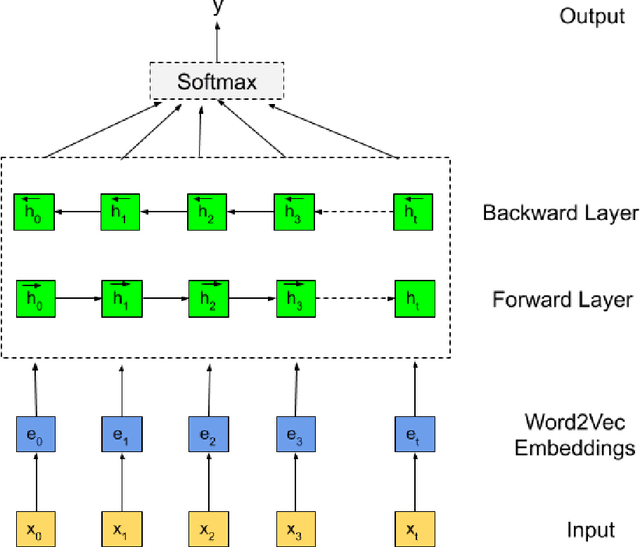
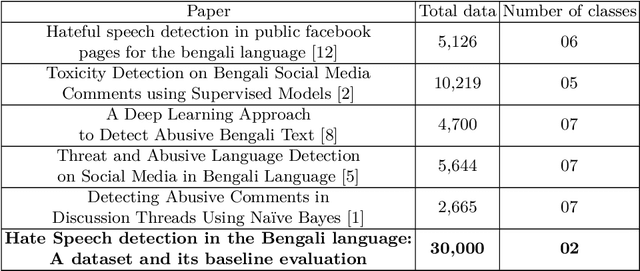
Social media sites such as YouTube and Facebook have become an integral part of everyone's life and in the last few years, hate speech in the social media comment section has increased rapidly. Detection of hate speech on social media websites faces a variety of challenges including small imbalanced data sets, the findings of an appropriate model and also the choice of feature analysis method. further more, this problem is more severe for the Bengali speaking community due to the lack of gold standard labelled datasets. This paper presents a new dataset of 30,000 user comments tagged by crowd sourcing and varified by experts. All the comments are collected from YouTube and Facebook comment section and classified into seven categories: sports, entertainment, religion, politics, crime, celebrity and TikTok & meme. A total of 50 annotators annotated each comment three times and the majority vote was taken as the final annotation. Nevertheless, we have conducted base line experiments and several deep learning models along with extensive pre-trained Bengali word embedding such as Word2Vec, FastText and BengFastText on this dataset to facilitate future research opportunities. The experiment illustrated that although all deep learning models performed well, SVM achieved the best result with 87.5% accuracy. Our core contribution is to make this benchmark dataset available and accessible to facilitate further research in the field of in the field of Bengali hate speech detection.
Adapting End-to-End Speech Recognition for Readable Subtitles
May 25, 2020
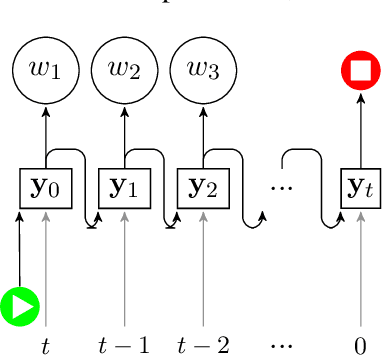

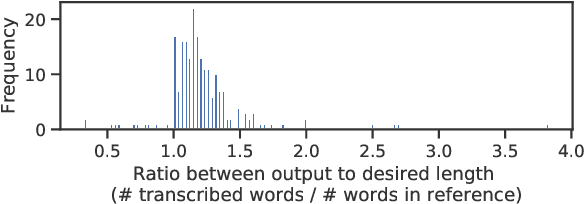
Automatic speech recognition (ASR) systems are primarily evaluated on transcription accuracy. However, in some use cases such as subtitling, verbatim transcription would reduce output readability given limited screen size and reading time. Therefore, this work focuses on ASR with output compression, a task challenging for supervised approaches due to the scarcity of training data. We first investigate a cascaded system, where an unsupervised compression model is used to post-edit the transcribed speech. We then compare several methods of end-to-end speech recognition under output length constraints. The experiments show that with limited data far less than needed for training a model from scratch, we can adapt a Transformer-based ASR model to incorporate both transcription and compression capabilities. Furthermore, the best performance in terms of WER and ROUGE scores is achieved by explicitly modeling the length constraints within the end-to-end ASR system.