 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
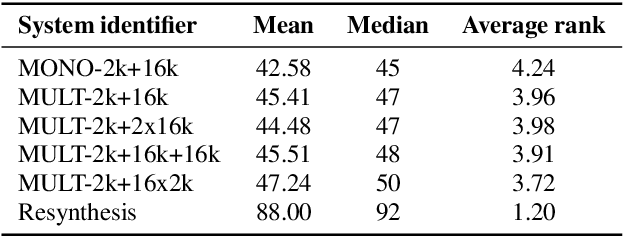
Latent linguistic embedding for cross-lingual text-to-speech and voice conversion
Oct 08, 2020
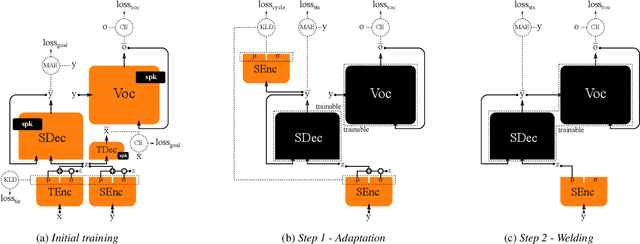
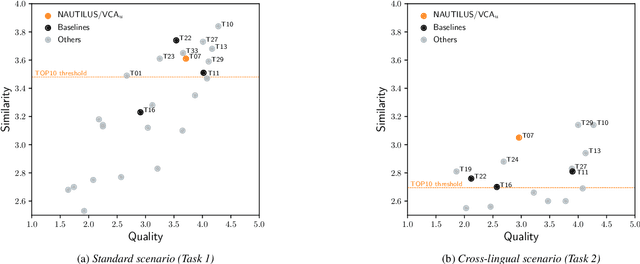
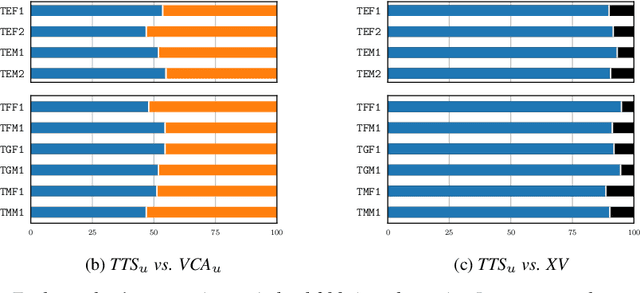
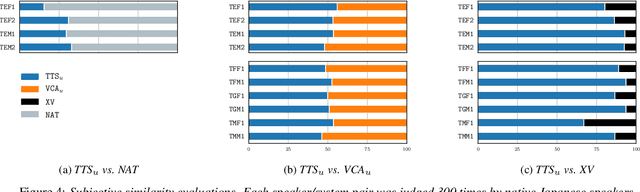
As the recently proposed voice cloning system, NAUTILUS, is capable of cloning unseen voices using untranscribed speech, we investigate the feasibility of using it to develop a unified cross-lingual TTS/VC system. Cross-lingual speech generation is the scenario in which speech utterances are generated with the voices of target speakers in a language not spoken by them originally. This type of system is not simply cloning the voice of the target speaker, but essentially creating a new voice that can be considered better than the original under a specific framing. By using a well-trained English latent linguistic embedding to create a cross-lingual TTS and VC system for several German, Finnish, and Mandarin speakers included in the Voice Conversion Challenge 2020, we show that our method not only creates cross-lingual VC with high speaker similarity but also can be seamlessly used for cross-lingual TTS without having to perform any extra steps. However, the subjective evaluations of perceived naturalness seemed to vary between target speakers, which is one aspect for future improvement.
It's not what you said, it's how you said it: discriminative perception of speech as a multichannel communication system
May 01, 2021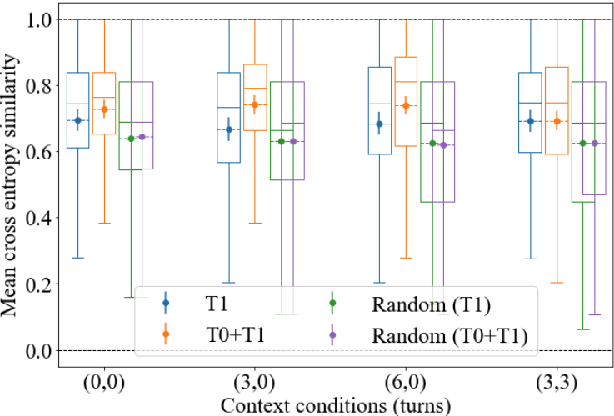
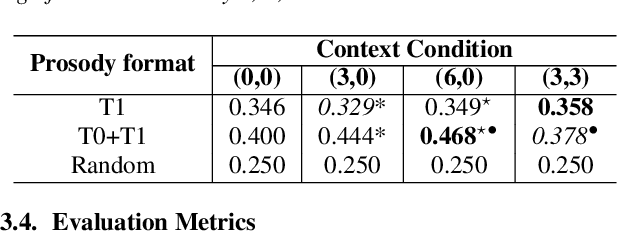
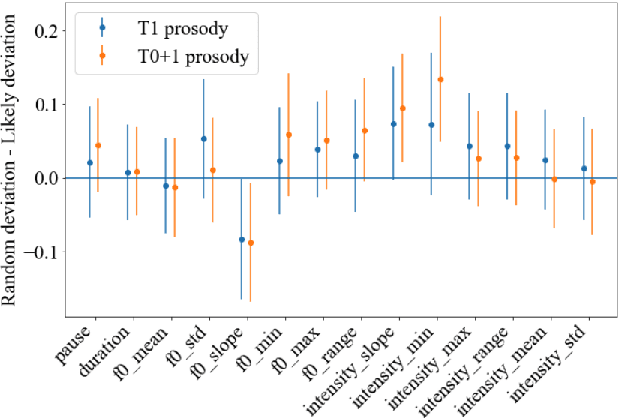
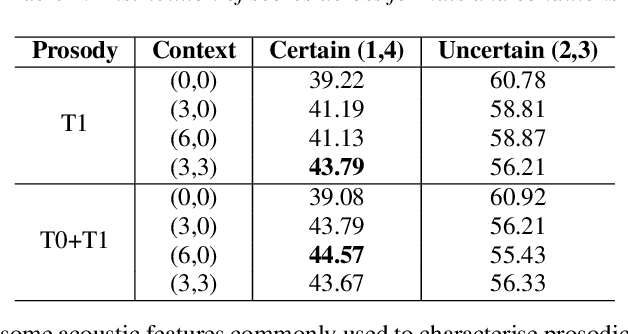
People convey information extremely effectively through spoken interaction using multiple channels of information transmission: the lexical channel of what is said, and the non-lexical channel of how it is said. We propose studying human perception of spoken communication as a means to better understand how information is encoded across these channels, focusing on the question 'What characteristics of communicative context affect listener's expectations of speech?'. To investigate this, we present a novel behavioural task testing whether listeners can discriminate between the true utterance in a dialogue and utterances sampled from other contexts with the same lexical content. We characterize how perception - and subsequent discriminative capability - is affected by different degrees of additional contextual information across both the lexical and non-lexical channel of speech. Results demonstrate that people can effectively discriminate between different prosodic realisations, that non-lexical context is informative, and that this channel provides more salient information than the lexical channel, highlighting the importance of the non-lexical channel in spoken interaction.
Efficient neural speech synthesis for low-resource languages through multilingual modeling
Aug 20, 2020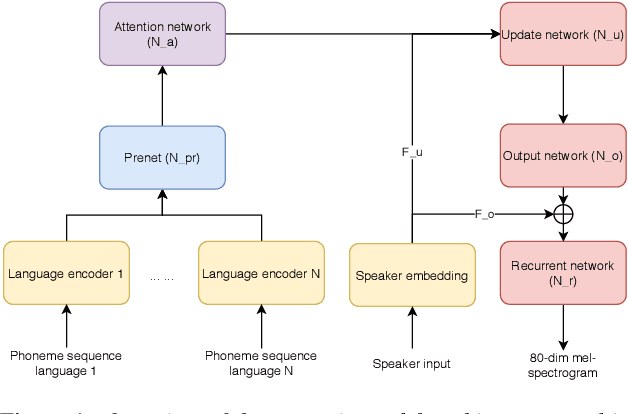

Recent advances in neural TTS have led to models that can produce high-quality synthetic speech. However, these models typically require large amounts of training data, which can make it costly to produce a new voice with the desired quality. Although multi-speaker modeling can reduce the data requirements necessary for a new voice, this approach is usually not viable for many low-resource languages for which abundant multi-speaker data is not available. In this paper, we therefore investigated to what extent multilingual multi-speaker modeling can be an alternative to monolingual multi-speaker modeling, and explored how data from foreign languages may best be combined with low-resource language data. We found that multilingual modeling can increase the naturalness of low-resource language speech, showed that multilingual models can produce speech with a naturalness comparable to monolingual multi-speaker models, and saw that the target language naturalness was affected by the strategy used to add foreign language data.
Two-stage Textual Knowledge Distillation to Speech Encoder for Spoken Language Understanding
Oct 25, 2020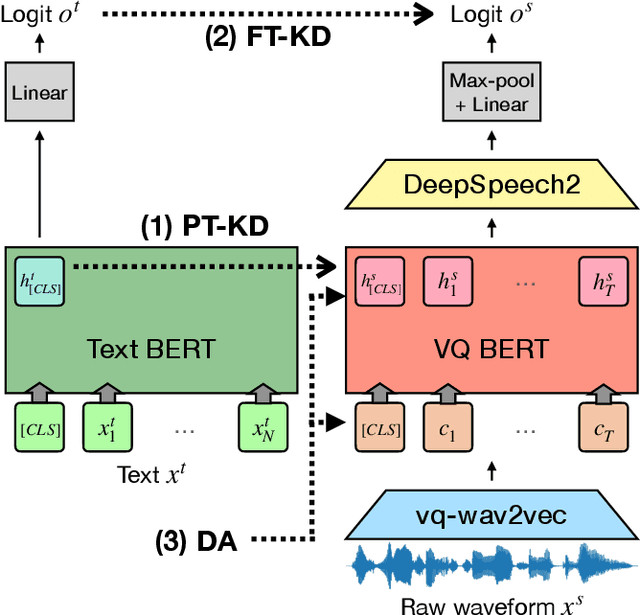
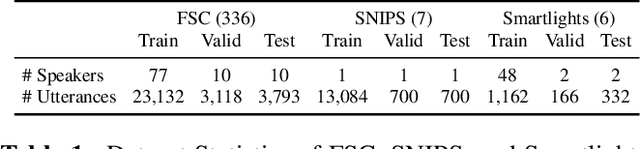
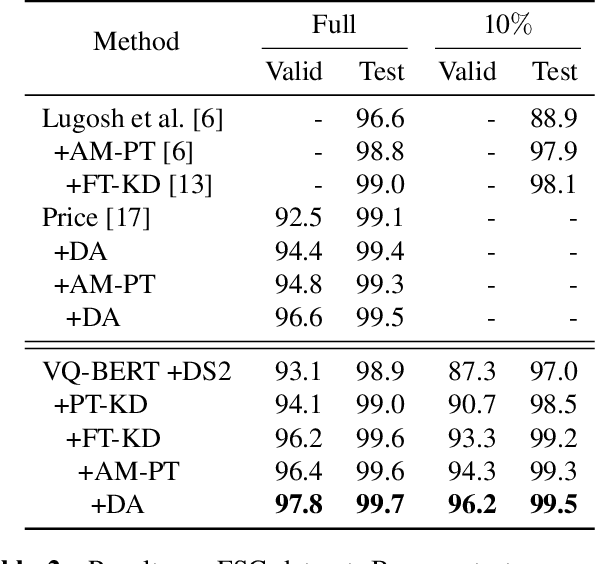
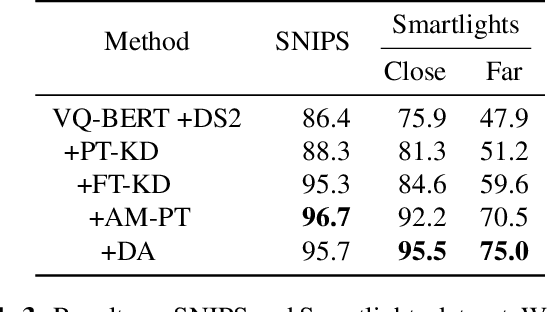
End-to-end approaches open a new way for more accurate and efficient spoken language understanding (SLU) systems by alleviating the drawbacks of traditional pipeline systems. Previous works exploit textual information for an SLU model via pre-training with automatic speech recognition or fine-tuning with knowledge distillation. To utilize textual information more effectively, this work proposes a two-stage textual knowledge distillation method that matches utterance-level representations and predicted logits of two modalities during pre-training and fine-tuning, sequentially. We use vq-wav2vec BERT as a speech encoder because it captures general and rich features. Furthermore, we improve the performance, especially in a low-resource scenario, with data augmentation methods by randomly masking spans of discrete audio tokens and contextualized hidden representations. Consequently, we push the state-of-the-art on the Fluent Speech Commands, achieving 99.7% test accuracy in the full dataset setting and 99.5% in the 10% subset setting. Throughout the ablation studies, we empirically verify that all used methods are crucial to the final performance, providing the best practice for spoken language understanding. Code to reproduce our results will be available upon publication.
Speech Enhancement for Wake-Up-Word detection in Voice Assistants
Jan 29, 2021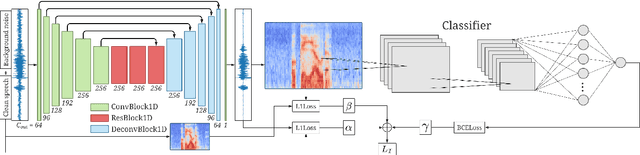
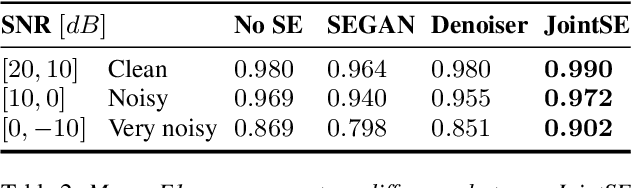
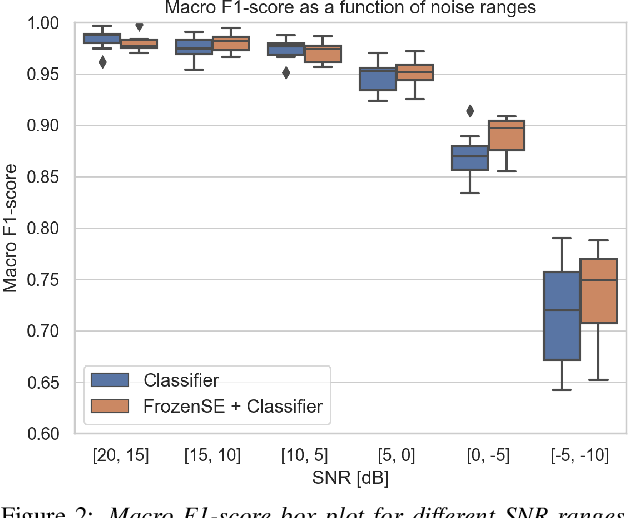
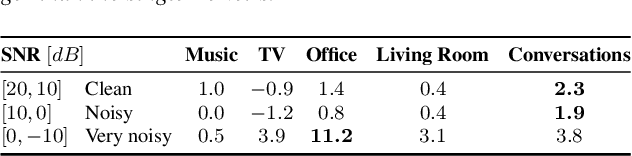
Keyword spotting and in particular Wake-Up-Word (WUW) detection is a very important task for voice assistants. A very common issue of voice assistants is that they get easily activated by background noise like music, TV or background speech that accidentally triggers the device. In this paper, we propose a Speech Enhancement (SE) model adapted to the task of WUW detection that aims at increasing the recognition rate and reducing the false alarms in the presence of these types of noises. The SE model is a fully-convolutional denoising auto-encoder at waveform level and is trained using a log-Mel Spectrogram and waveform reconstruction losses together with the BCE loss of a simple WUW classification network. A new database has been purposely prepared for the task of recognizing the WUW in challenging conditions containing negative samples that are very phonetically similar to the keyword. The database is extended with public databases and an exhaustive data augmentation to simulate different noises and environments. The results obtained by concatenating the SE with a simple and state-of-the-art WUW detectors show that the SE does not have a negative impact on the recognition rate in quiet environments while increasing the performance in the presence of noise, especially when the SE and WUW detector are trained jointly end-to-end.
What do tokens know about their characters and how do they know it?
Jun 06, 2022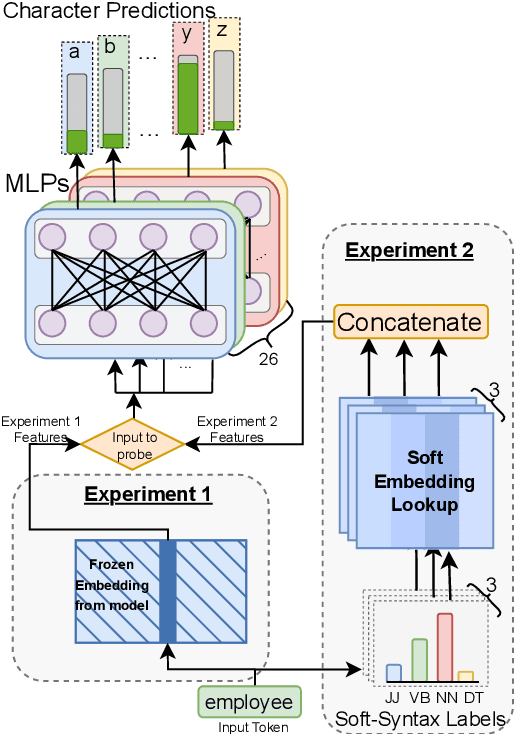
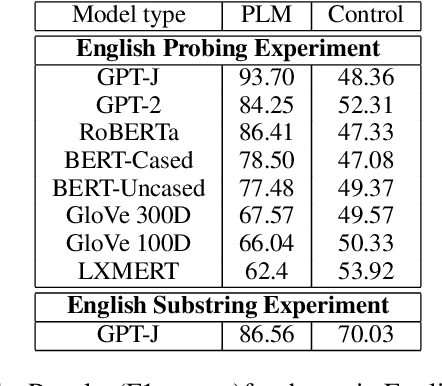
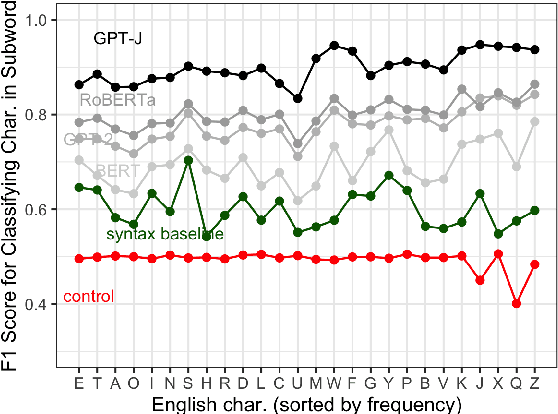
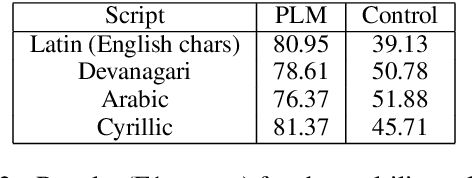
Pre-trained language models (PLMs) that use subword tokenization schemes can succeed at a variety of language tasks that require character-level information, despite lacking explicit access to the character composition of tokens. Here, studying a range of models (e.g., GPT- J, BERT, RoBERTa, GloVe), we probe what word pieces encode about character-level information by training classifiers to predict the presence or absence of a particular alphabetical character in a token, based on its embedding (e.g., probing whether the model embedding for "cat" encodes that it contains the character "a"). We find that these models robustly encode character-level information and, in general, larger models perform better at the task. We show that these results generalize to characters from non-Latin alphabets (Arabic, Devanagari, and Cyrillic). Then, through a series of experiments and analyses, we investigate the mechanisms through which PLMs acquire English-language character information during training and argue that this knowledge is acquired through multiple phenomena, including a systematic relationship between particular characters and particular parts of speech, as well as natural variability in the tokenization of related strings.
CRAB: Class Representation Attentive BERT for Hate Speech Identification in Social Media
Oct 25, 2020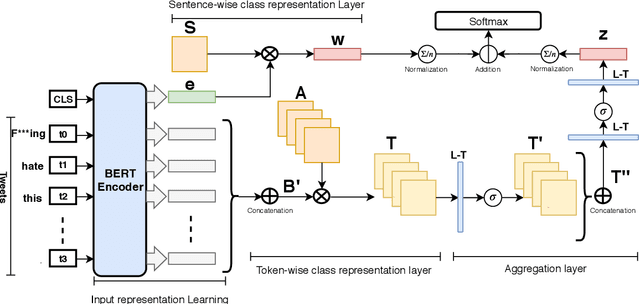
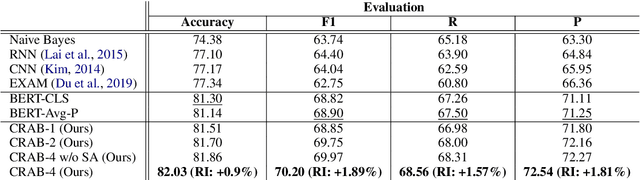
In recent years, social media platforms have hosted an explosion of hate speech and objectionable content. The urgent need for effective automatic hate speech detection models have drawn remarkable investment from companies and researchers. Social media posts are generally short and their semantics could drastically be altered by even a single token. Thus, it is crucial for this task to learn context-aware input representations, and consider relevancy scores between input embeddings and class representations as an additional signal. To accommodate these needs, this paper introduces CRAB (Class Representation Attentive BERT), a neural model for detecting hate speech in social media. The model benefits from two semantic representations: (i) trainable token-wise and sentence-wise class representations, and (ii) contextualized input embeddings from state-of-the-art BERT encoder. To investigate effectiveness of CRAB, we train our model on Twitter data and compare it against strong baselines. Our results show that CRAB achieves 1.89% relative improved Macro-averaged F1 over state-of-the-art baseline. The results of this research open an opportunity for the future research on automated abusive behavior detection in social media
Whose Opinions Matter? Perspective-aware Models to Identify Opinions of Hate Speech Victims in Abusive Language Detection
Jun 30, 2021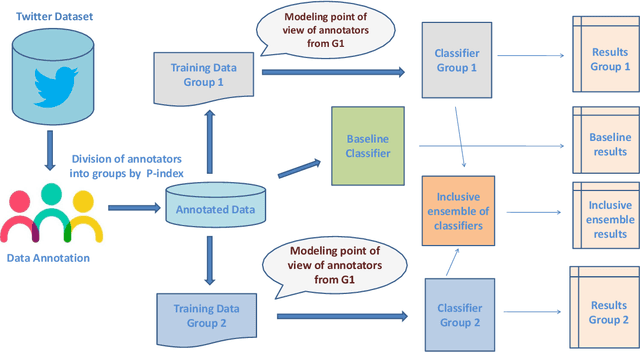
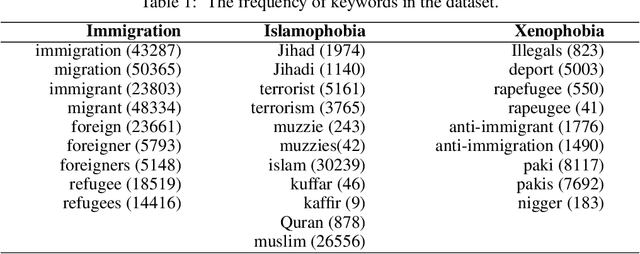
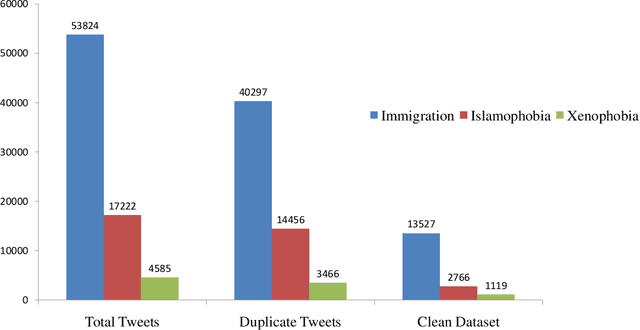

Social media platforms provide users the freedom of expression and a medium to exchange information and express diverse opinions. Unfortunately, this has also resulted in the growth of abusive content with the purpose of discriminating people and targeting the most vulnerable communities such as immigrants, LGBT, Muslims, Jews and women. Because abusive language is subjective in nature, there might be highly polarizing topics or events involved in the annotation of abusive contents such as hate speech (HS). Therefore, we need novel approaches to model conflicting perspectives and opinions coming from people with different personal and demographic backgrounds. In this paper, we present an in-depth study to model polarized opinions coming from different communities under the hypothesis that similar characteristics (ethnicity, social background, culture etc.) can influence the perspectives of annotators on a certain phenomenon. We believe that by relying on this information, we can divide the annotators into groups sharing similar perspectives. We can create separate gold standards, one for each group, to train state-of-the-art deep learning models. We can employ an ensemble approach to combine the perspective-aware classifiers from different groups to an inclusive model. We also propose a novel resource, a multi-perspective English language dataset annotated according to different sub-categories relevant for characterising online abuse: hate speech, aggressiveness, offensiveness and stereotype. By training state-of-the-art deep learning models on this novel resource, we show how our approach improves the prediction performance of a state-of-the-art supervised classifier.
Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-resource Speech Recognition
Jan 24, 2021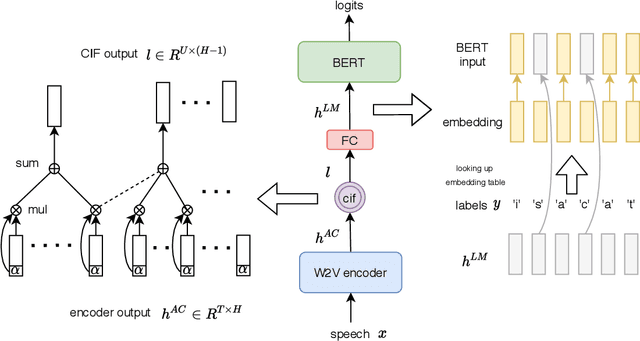
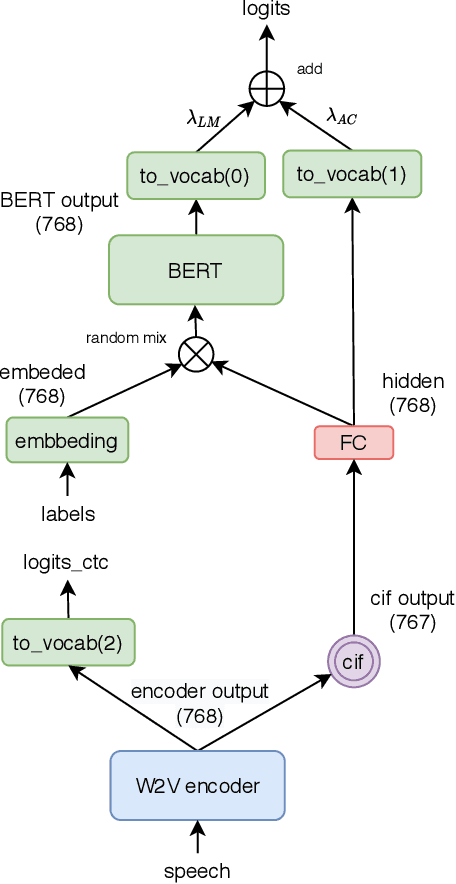
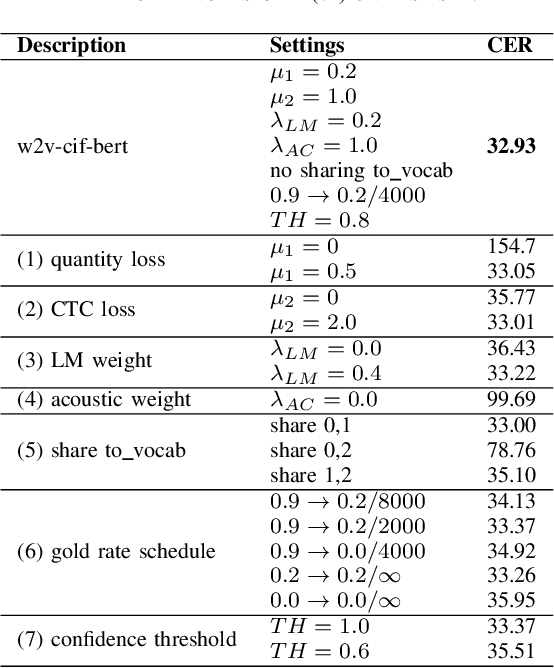
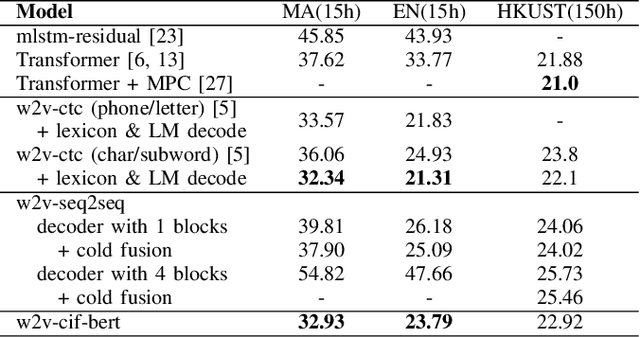
End-to-end models have achieved impressive results on the task of automatic speech recognition (ASR). For low-resource ASR tasks, however, labeled data can hardly satisfy the demand of end-to-end models. Self-supervised acoustic pre-training has already shown its amazing ASR performance, while the transcription is still inadequate for language modeling in end-to-end models. In this work, we fuse a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model. The fused model only needs to learn the transfer from speech to language during fine-tuning on limited labeled data. The length of the two modalities is matched by a monotonic attention mechanism without additional parameters. Besides, a fully connected layer is introduced for the hidden mapping between modalities. We further propose a scheduled fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained linguistic encoder. Experiments show our effective utilizing of pre-trained modules. Our model achieves better recognition performance on CALLHOME corpus (15 hours) than other end-to-end models.
Optimizing Speech Recognition For The Edge
Sep 26, 2019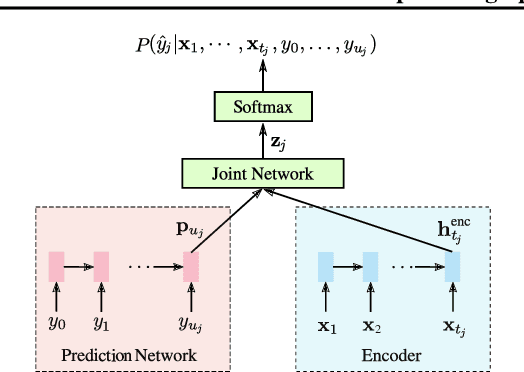
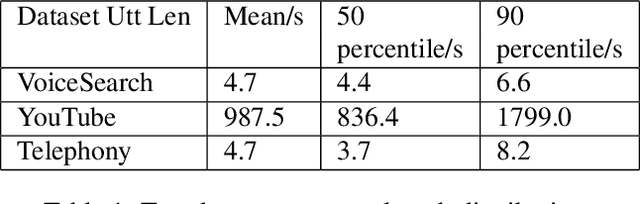
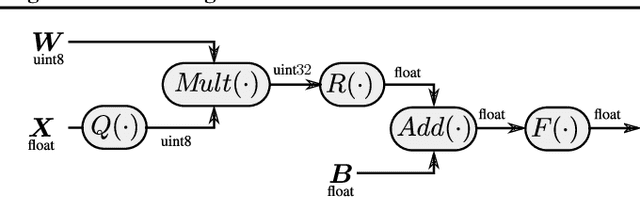
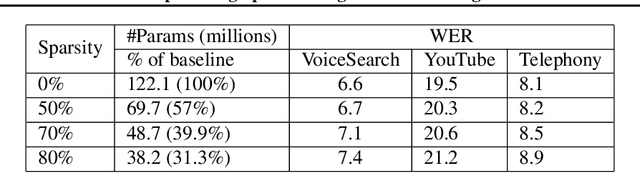
While most deployed speech recognition systems today still run on servers, we are in the midst of a transition towards deployments on edge devices. This leap to the edge is powered by the progression from traditional speech recognition pipelines to end-to-end (E2E) neural architectures, and the parallel development of more efficient neural network topologies and optimization techniques. Thus, we are now able to create highly accurate speech recognizers that are both small and fast enough to execute on typical mobile devices. In this paper, we begin with a baseline RNN-Transducer architecture comprised of Long Short-Term Memory (LSTM) layers. We then experiment with a variety of more computationally efficient layer types, as well as apply optimization techniques like neural connection pruning and parameter quantization to construct a small, high quality, on-device speech recognizer that is an order of magnitude smaller than the baseline system without any optimizations.