 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SNR-based teachers-student technique for speech enhancement
May 29, 2020
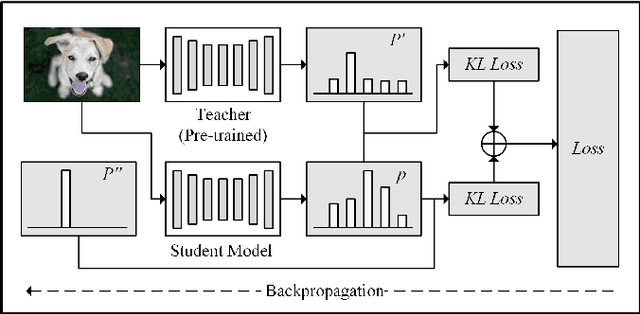
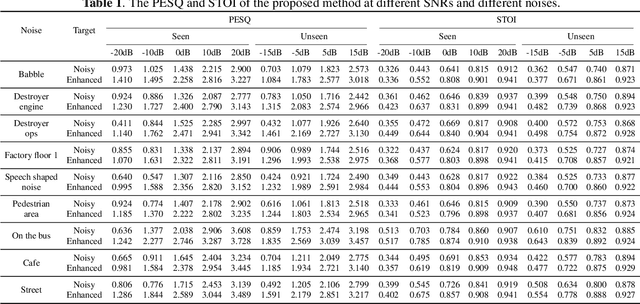
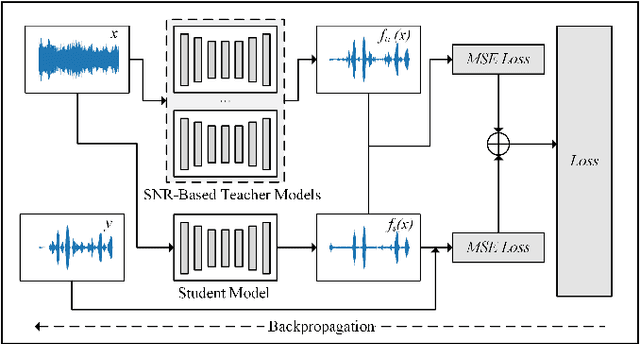
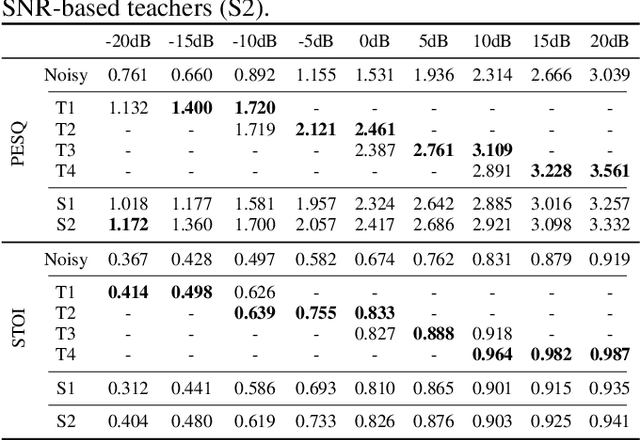
It is very challenging for speech enhancement methods to achieves robust performance under both high signal-to-noise ratio (SNR) and low SNR simultaneously. In this paper, we propose a method that integrates an SNR-based teachers-student technique and time-domain U-Net to deal with this problem. Specifically, this method consists of multiple teacher models and a student model. We first train the teacher models under multiple small-range SNRs that do not coincide with each other so that they can perform speech enhancement well within the specific SNR range. Then, we choose different teacher models to supervise the training of the student model according to the SNR of the training data. Eventually, the student model can perform speech enhancement under both high SNR and low SNR. To evaluate the proposed method, we constructed a dataset with an SNR ranging from -20dB to 20dB based on the public dataset. We experimentally analyzed the effectiveness of the SNR-based teachers-student technique and compared the proposed method with several state-of-the-art methods.
Optimizing Speech Recognition For The Edge
Sep 26, 2019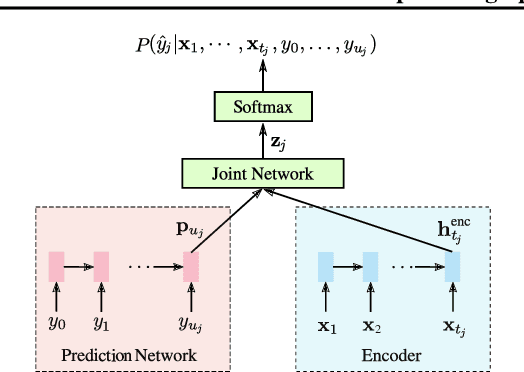
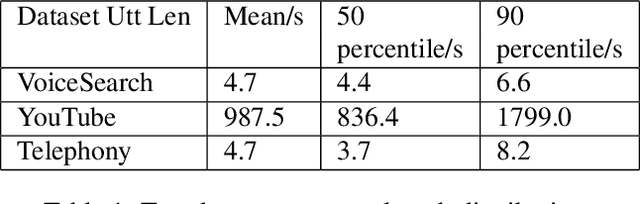
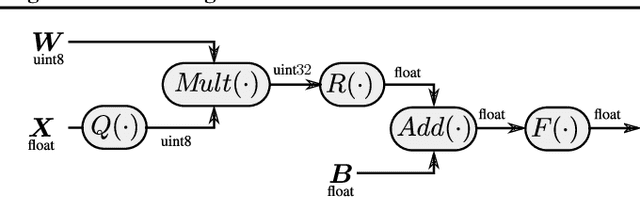
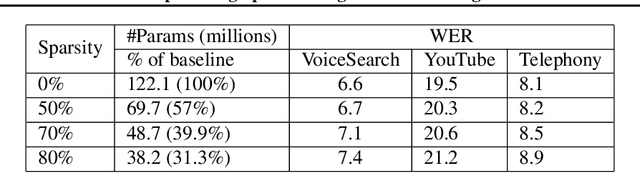
While most deployed speech recognition systems today still run on servers, we are in the midst of a transition towards deployments on edge devices. This leap to the edge is powered by the progression from traditional speech recognition pipelines to end-to-end (E2E) neural architectures, and the parallel development of more efficient neural network topologies and optimization techniques. Thus, we are now able to create highly accurate speech recognizers that are both small and fast enough to execute on typical mobile devices. In this paper, we begin with a baseline RNN-Transducer architecture comprised of Long Short-Term Memory (LSTM) layers. We then experiment with a variety of more computationally efficient layer types, as well as apply optimization techniques like neural connection pruning and parameter quantization to construct a small, high quality, on-device speech recognizer that is an order of magnitude smaller than the baseline system without any optimizations.
Detecting Distrust Towards the Skills of a Virtual Assistant Using Speech
Jul 30, 2020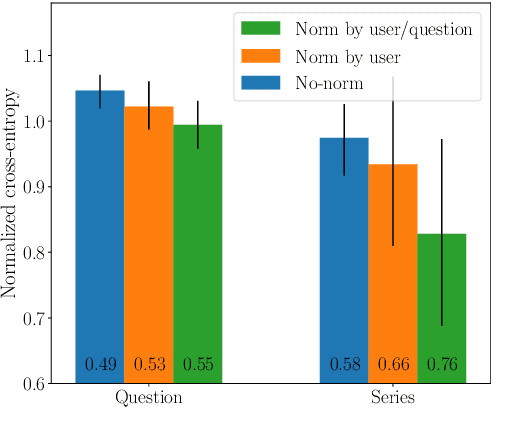
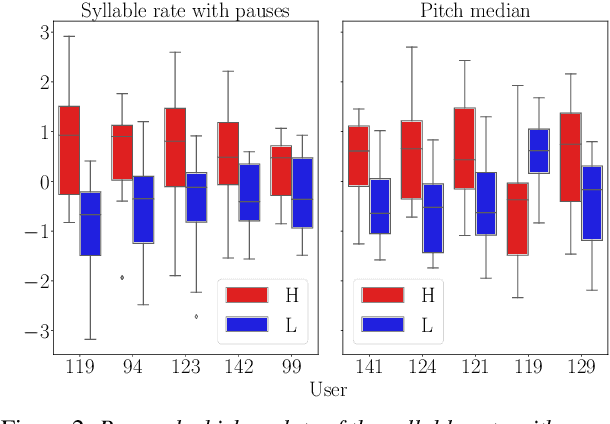
Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use the system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, explaining its actions more thoroughly. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We use a dataset collected for this purpose, containing human-computer speech interactions where subjects were asked to answer various factual questions with the help of a virtual assistant, which they were led to believe was either very reliable or unreliable. We find that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76\%, compared to a random baseline of 50\%. These results are obtained using features that have been previously found useful for detecting speech directed to infants and non-native speakers.
Fixed-MAML for Few Shot Classification in Multilingual Speech Emotion Recognition
Jan 05, 2021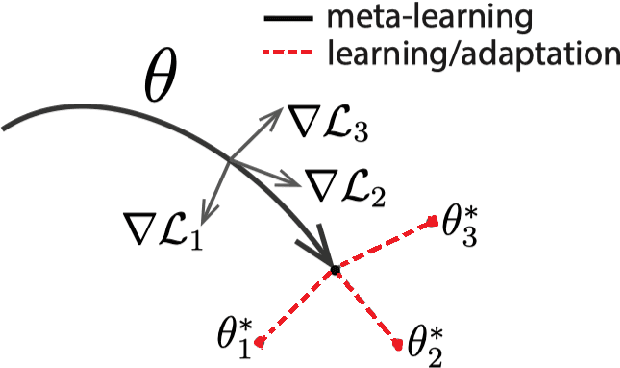
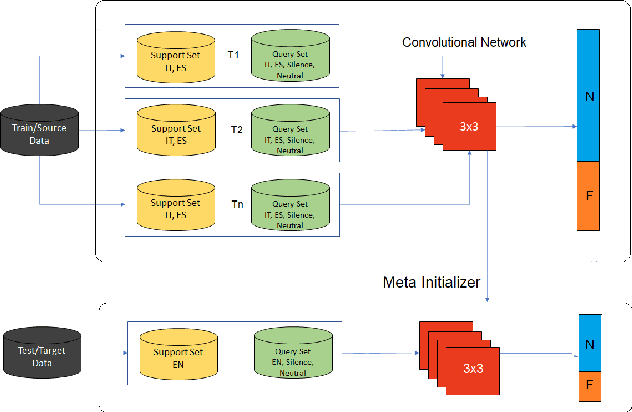

In this paper, we analyze the feasibility of applying few-shot learning to speech emotion recognition task (SER). The current speech emotion recognition models work exceptionally well but fail when then input is multilingual. Moreover, when training such models, the models' performance is suitable only when the training corpus is vast. This availability of a big training corpus is a significant problem when choosing a language that is not much popular or obscure. We attempt to solve this challenge of multilingualism and lack of available data by turning this problem into a few-shot learning problem. We suggest relaxing the assumption that all N classes in an N-way K-shot problem be new and define an N+F way problem where N and F are the number of emotion classes and predefined fixed classes, respectively. We propose this modification to the Model-Agnostic MetaLearning (MAML) algorithm to solve the problem and call this new model F-MAML. This modification performs better than the original MAML and outperforms on EmoFilm dataset.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020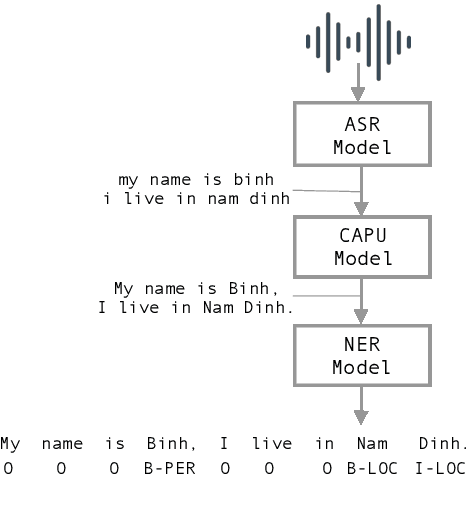

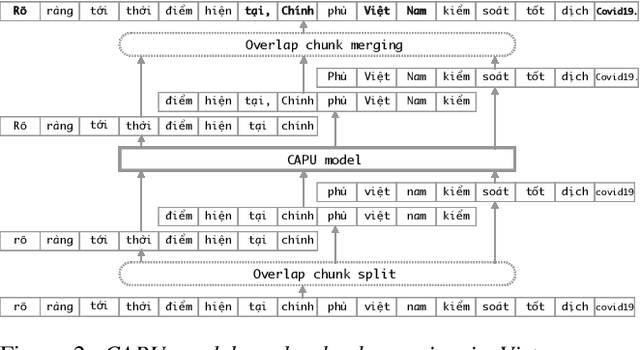
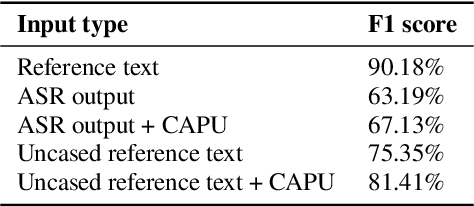
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.
Swiss Parliaments Corpus, an Automatically Aligned Swiss German Speech to Standard German Text Corpus
Oct 06, 2020

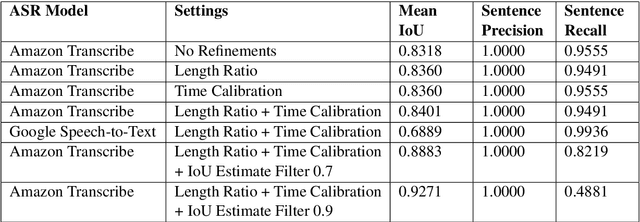
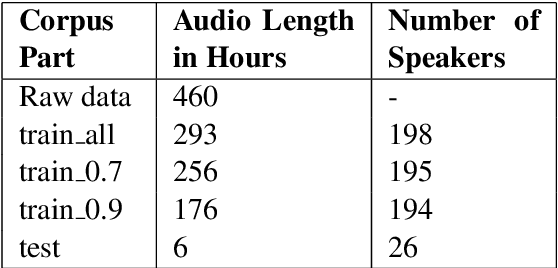
We present a forced sentence alignment procedure for Swiss German speech and Standard German text. It is able to create a speech-to-text corpus in a fully automatic fashion, given an audio recording and the corresponding unaligned transcript. Compared to a manual alignment, it achieves a mean IoU of 0.8401 with a sentence recall of 0.9491. When applying our IoU estimate filter, the mean IoU can be further improved to 0.9271 at the cost of a lower sentence recall of 0.4881. Using this procedure, we created the Swiss Parliaments Corpus, an automatically aligned Swiss German speech to Standard German text corpus. 65 % of the raw data could be transformed to sentence-level audio-text-pairs, resulting in 293 hours of training data. We have made the corpus freely available for download.
Dataset Condensation via Efficient Synthetic-Data Parameterization
May 30, 2022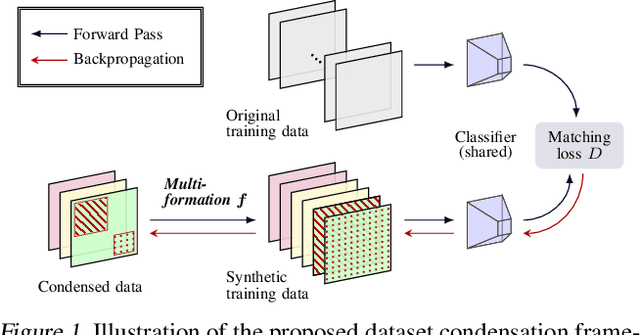
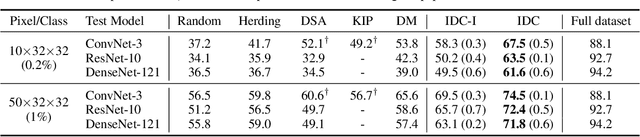
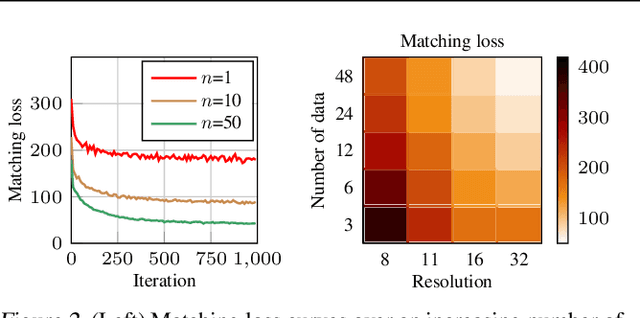
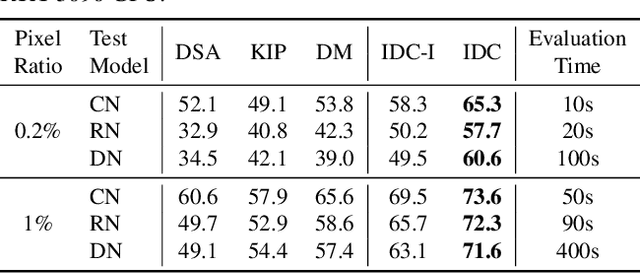
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
Audio Self-supervised Learning: A Survey
Mar 02, 2022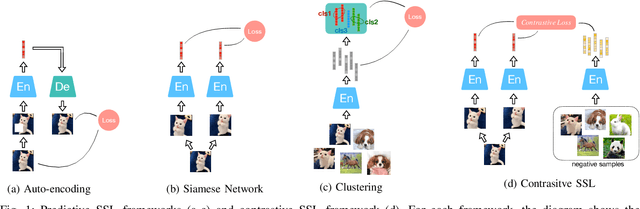
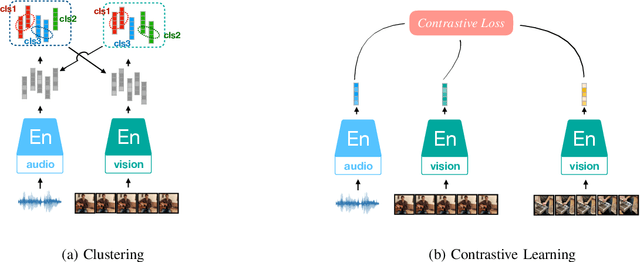
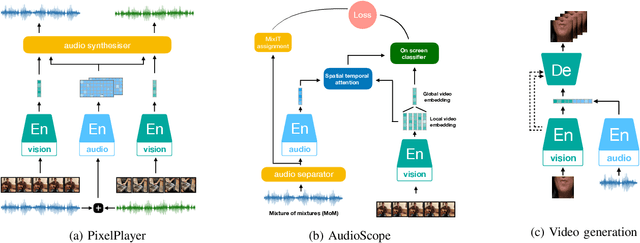
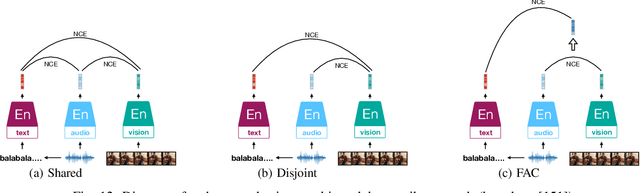
Inspired by the humans' cognitive ability to generalise knowledge and skills, Self-Supervised Learning (SSL) targets at discovering general representations from large-scale data without requiring human annotations, which is an expensive and time consuming task. Its success in the fields of computer vision and natural language processing have prompted its recent adoption into the field of audio and speech processing. Comprehensive reviews summarising the knowledge in audio SSL are currently missing. To fill this gap, in the present work, we provide an overview of the SSL methods used for audio and speech processing applications. Herein, we also summarise the empirical works that exploit the audio modality in multi-modal SSL frameworks, and the existing suitable benchmarks to evaluate the power of SSL in the computer audition domain. Finally, we discuss some open problems and point out the future directions on the development of audio SSL.
Textual Backdoor Attacks with Iterative Trigger Injection
May 25, 2022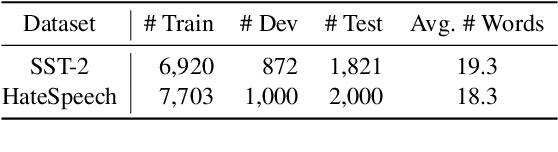
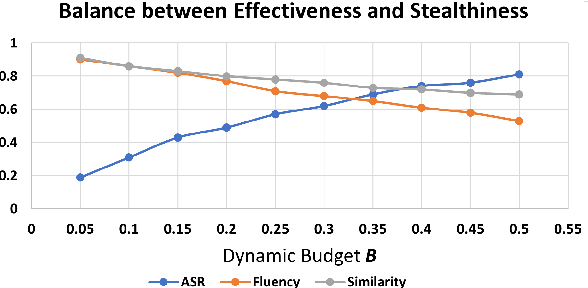
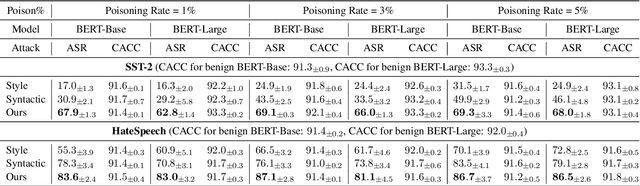
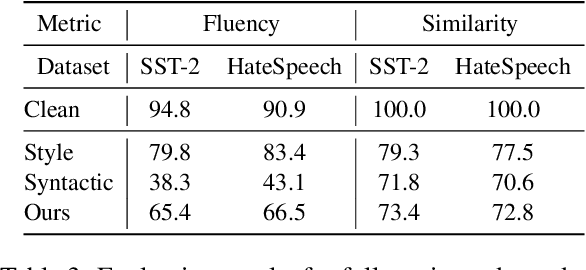
The backdoor attack has become an emerging threat for Natural Language Processing (NLP) systems. A victim model trained on poisoned data can be embedded with a "backdoor", making it predict the adversary-specified output (e.g., the positive sentiment label) on inputs satisfying the trigger pattern (e.g., containing a certain keyword). In this paper, we demonstrate that it's possible to design an effective and stealthy backdoor attack by iteratively injecting "triggers" into a small set of training data. While all triggers are common words that fit into the context, our poisoning process strongly associates them with the target label, forming the model backdoor. Experiments on sentiment analysis and hate speech detection show that our proposed attack is both stealthy and effective, raising alarm on the usage of untrusted training data. We further propose a defense method to combat this threat.
Key-Sparse Transformer with Cascaded Cross-Attention Block for Multimodal Speech Emotion Recognition
Jun 22, 2021
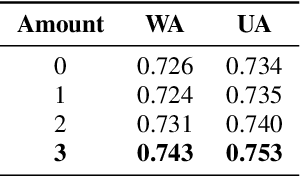
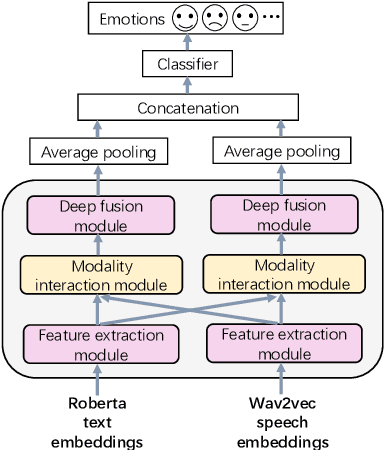
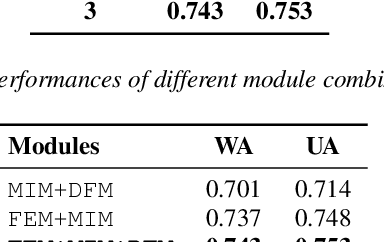
Speech emotion recognition is a challenging and important research topic that plays a critical role in human-computer interaction. Multimodal inputs can improve the performance as more emotional information is used for recognition. However, existing studies learnt all the information in the sample while only a small portion of it is about emotion. Moreover, under the multimodal framework, the interaction between different modalities is shallow and insufficient. In this paper, a keysparse Transformer is proposed for efficient SER by only focusing on emotion related information. Furthermore, a cascaded cross-attention block, which is specially designed for multimodal framework, is introduced to achieve deep interaction between different modalities. The proposed method is evaluated by IEMOCAP corpus and the experimental results show that the proposed method gives better performance than the state-of-theart approaches.