 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Noise Robust TTS for Low Resource Speakers using Pre-trained Model and Speech Enhancement
May 26, 2020
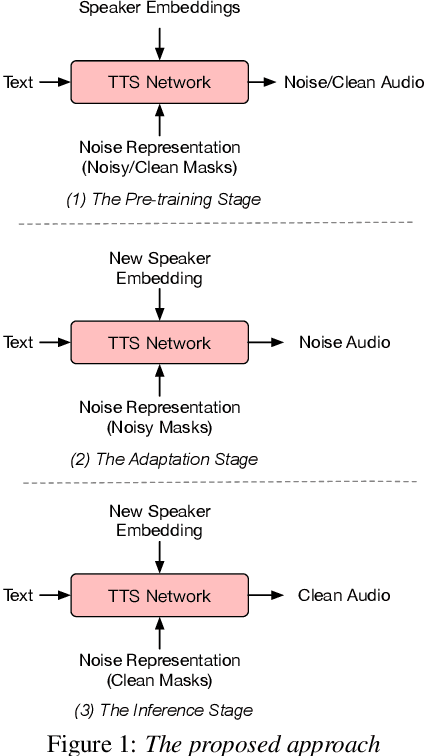
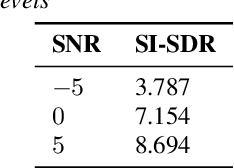
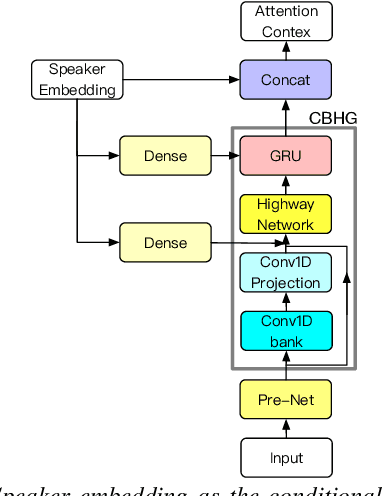
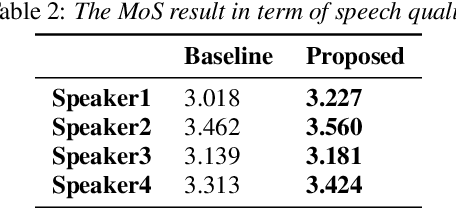
With the popularity of deep neural network, speech synthesis task has achieved significant improvements based on the end-to-end encoder-decoder framework in the recent days. More and more applications relying on speech synthesis technology have been widely used in our daily life. Robust speech synthesis model depends on high quality and customized data which needs lots of collecting efforts. It is worth investigating how to take advantage of low-quality and low resource voice data which can be easily obtained from the Internet for usage of synthesizing personalized voice. In this paper, the proposed end-to-end speech synthesis model uses both speaker embedding and noise representation as conditional inputs to model speaker and noise information respectively. Firstly, the speech synthesis model is pre-trained with both multi-speaker clean data and noisy augmented data; then the pre-trained model is adapted on noisy low-resource new speaker data; finally, by setting the clean speech condition, the model can synthesize the new speaker's clean voice. Experimental results show that the speech generated by the proposed approach has better subjective evaluation results than the method directly fine-tuning pre-trained multi-speaker speech synthesis model with denoised new speaker data.
Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
Apr 09, 2021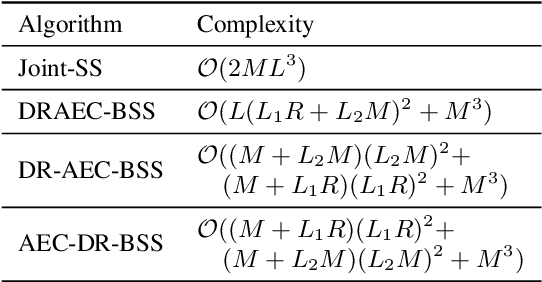
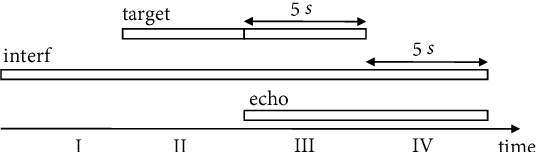
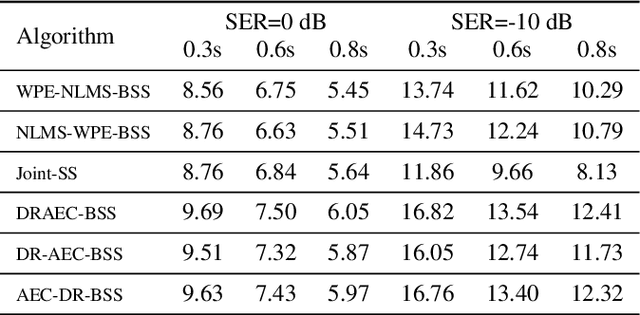
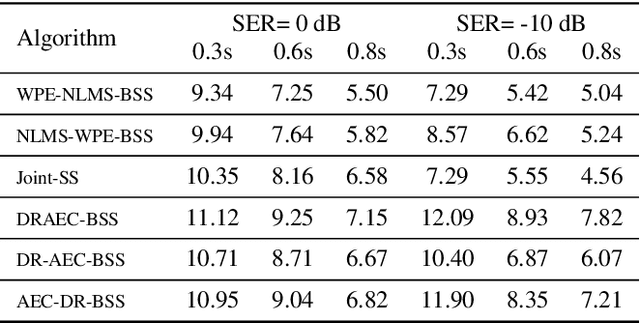
This paper presents a joint source separation algorithm that simultaneously reduces acoustic echo, reverberation and interfering sources. Target speeches are separated from the mixture by maximizing independence with respect to the other sources. It is shown that the separation process can be decomposed into cascading sub-processes that separately relate to acoustic echo cancellation, speech dereverberation and source separation, all of which are solved using the auxiliary function based independent component/vector analysis techniques, and their solving orders are exchangeable. The cascaded solution not only leads to lower computational complexity but also better separation performance than the vanilla joint algorithm.
Speech Corpus of Ainu Folklore and End-to-end Speech Recognition for Ainu Language
Feb 19, 2020
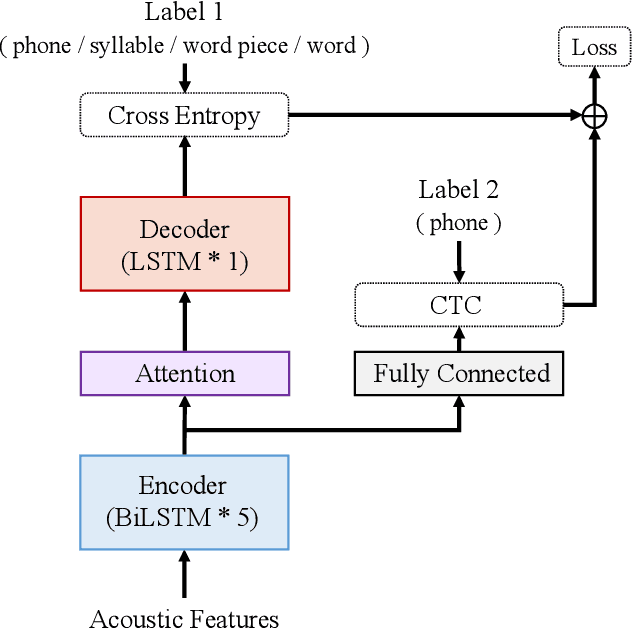
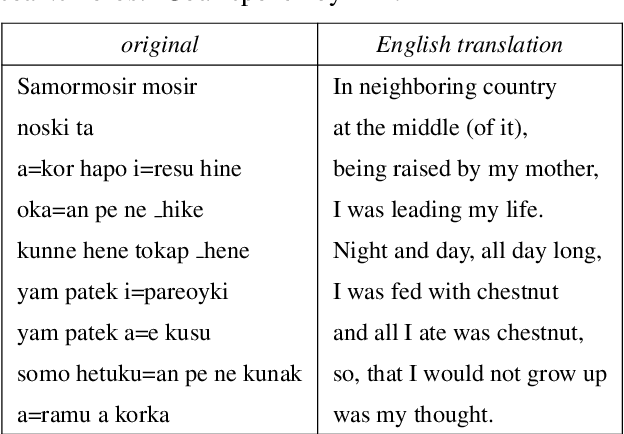
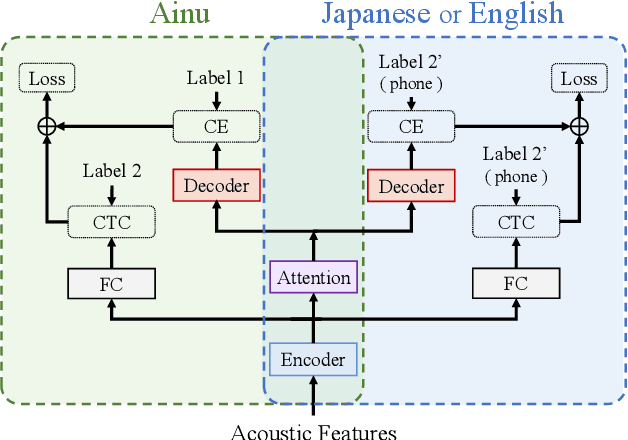
Ainu is an unwritten language that has been spoken by Ainu people who are one of the ethnic groups in Japan. It is recognized as critically endangered by UNESCO and archiving and documentation of its language heritage is of paramount importance. Although a considerable amount of voice recordings of Ainu folklore has been produced and accumulated to save their culture, only a quite limited parts of them are transcribed so far. Thus, we started a project of automatic speech recognition (ASR) for the Ainu language in order to contribute to the development of annotated language archives. In this paper, we report speech corpus development and the structure and performance of end-to-end ASR for Ainu. We investigated four modeling units (phone, syllable, word piece, and word) and found that the syllable-based model performed best in terms of both word and phone recognition accuracy, which were about 60% and over 85% respectively in speaker-open condition. Furthermore, word and phone accuracy of 80% and 90% has been achieved in a speaker-closed setting. We also found out that a multilingual ASR training with additional speech corpora of English and Japanese further improves the speaker-open test accuracy.
Analysis of Deep Clustering as Preprocessing for Automatic Speech Recognition of Sparsely Overlapping Speech
May 09, 2019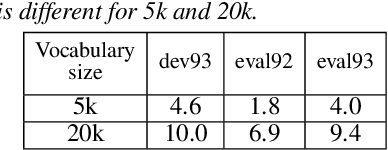
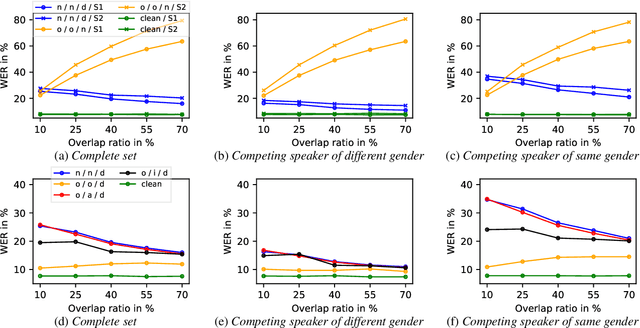
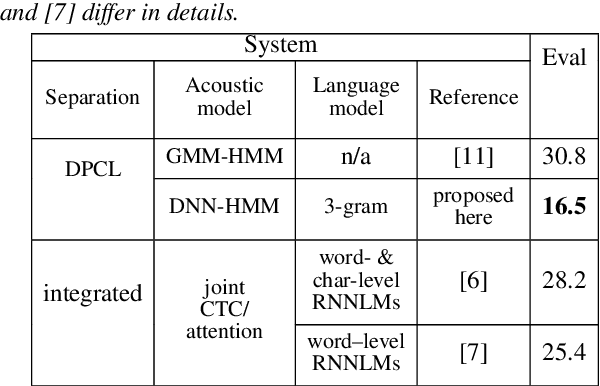
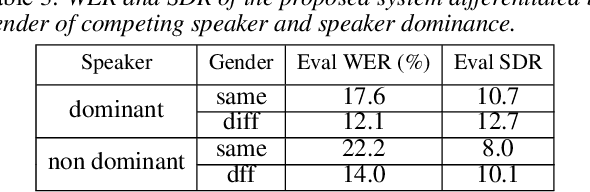
Significant performance degradation of automatic speech recognition (ASR) systems is observed when the audio signal contains cross-talk. One of the recently proposed approaches to solve the problem of multi-speaker ASR is the deep clustering (DPCL) approach. Combining DPCL with a state-of-the-art hybrid acoustic model, we obtain a word error rate (WER) of 16.5 % on the commonly used wsj0-2mix dataset, which is the best performance reported thus far to the best of our knowledge. The wsj0-2mix dataset contains simulated cross-talk where the speech of multiple speakers overlaps for almost the entire utterance. In a more realistic ASR scenario the audio signal contains significant portions of single-speaker speech and only part of the signal contains speech of multiple competing speakers. This paper investigates obstacles of applying DPCL as a preprocessing method for ASR in such a scenario of sparsely overlapping speech. To this end we present a data simulation approach, closely related to the wsj0-2mix dataset, generating sparsely overlapping speech datasets of arbitrary overlap ratio. The analysis of applying DPCL to sparsely overlapping speech is an important interim step between the fully overlapping datasets like wsj0-2mix and more realistic ASR datasets, such as CHiME-5 or AMI.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022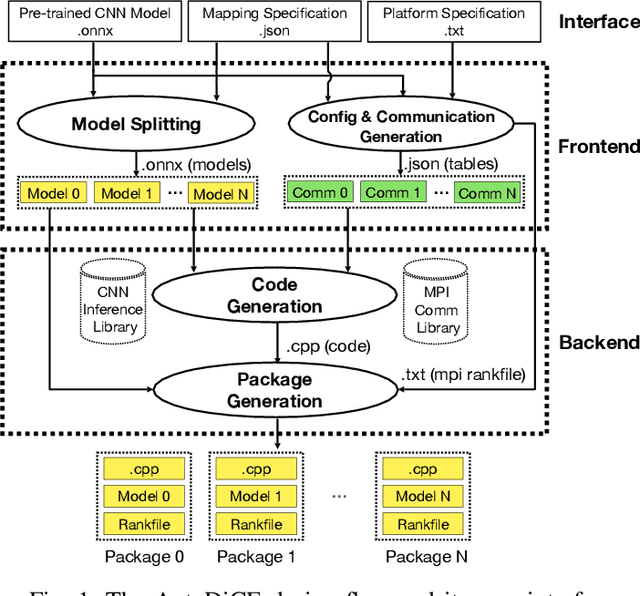
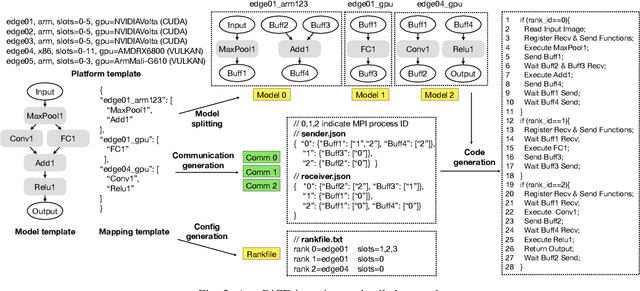
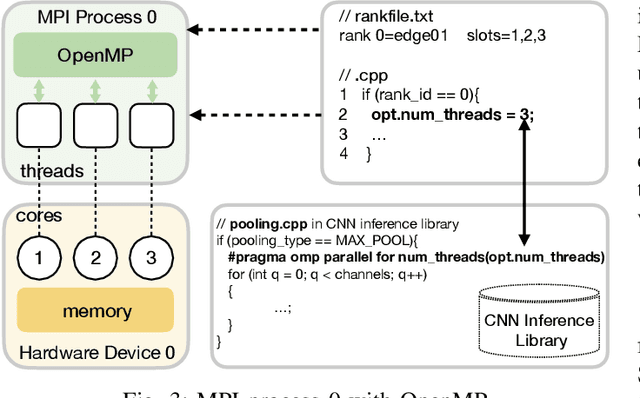
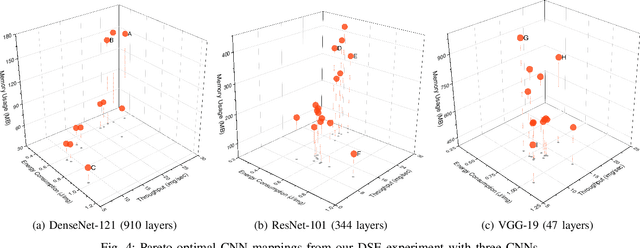
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.
Multitask Training with Text Data for End-to-End Speech Recognition
Oct 27, 2020
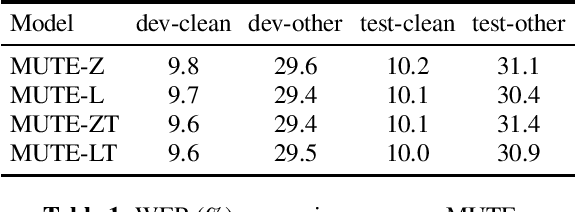

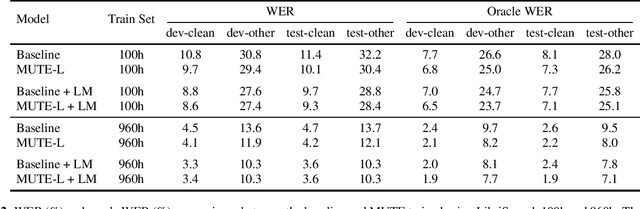
We propose a multitask training method for attention-based end-to-end speech recognition models to better incorporate language level information. We regularize the decoder in a sequence-to-sequence architecture by multitask training it on both the speech recognition task and a next-token prediction language modeling task. Trained on either the 100 hour subset of LibriSpeech or the full 960 hour dataset, the proposed method leads to an 11% relative performance improvement over the baseline and is comparable to language model shallow fusion, without requiring an additional neural network during decoding. Analyses of sample output sentences and the word error rate on rare words demonstrate that the proposed method can incorporate language level information effectively.
Comparing acoustic analyses of speech data collected remotely
Mar 01, 2021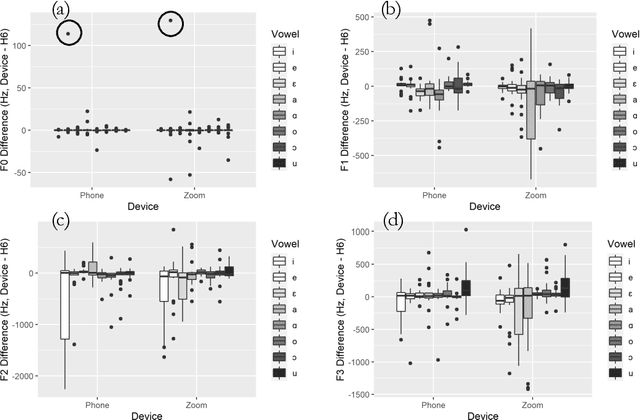
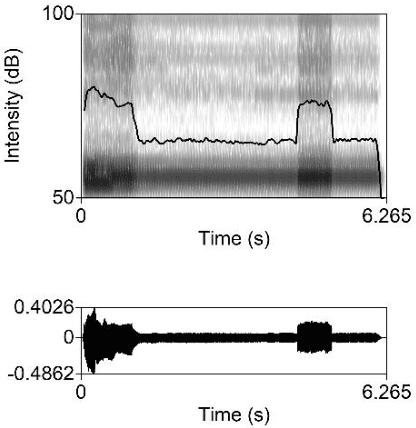
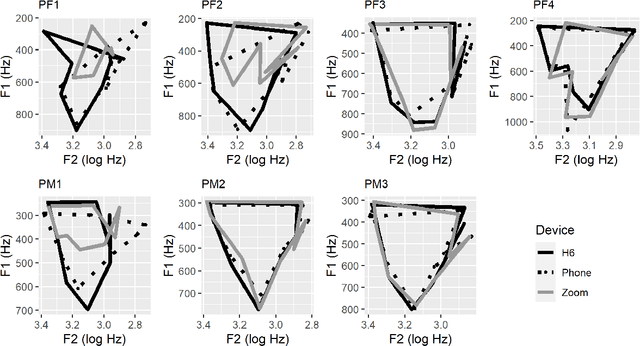
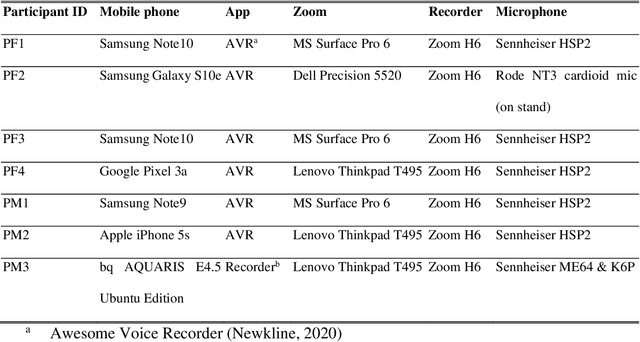
Face-to-face speech data collection has been next to impossible globally due to COVID-19 restrictions. To address this problem, simultaneous recordings of three repetitions of the cardinal vowels were made using a Zoom H6 Handy Recorder with external microphone (henceforth H6) and compared with two alternatives accessible to potential participants at home: the Zoom meeting application (henceforth Zoom) and two lossless mobile phone applications (Awesome Voice Recorder, and Recorder; henceforth Phone). F0 was tracked accurately by all devices; however, for formant analysis (F1, F2, F3) Phone performed better than Zoom, i.e. more similarly to H6. Zoom recordings also exhibited unexpected drops in intensity. The results suggest that lossless format phone recordings present a viable option for at least some phonetic studies.
Collar-aware Training for Streaming Speaker Change Detection in Broadcast Speech
May 14, 2022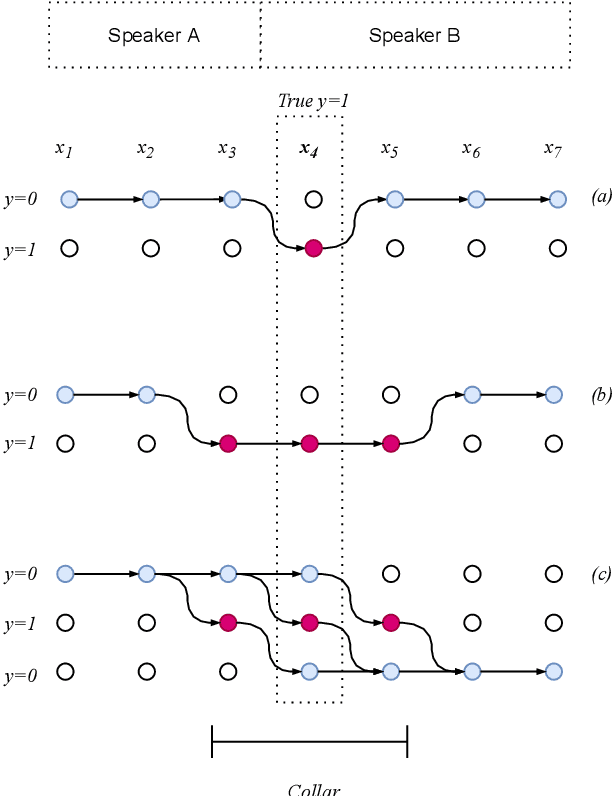
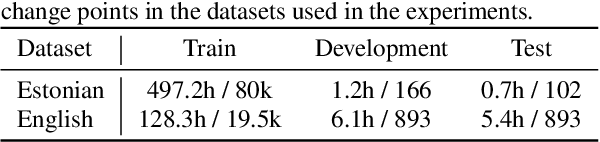

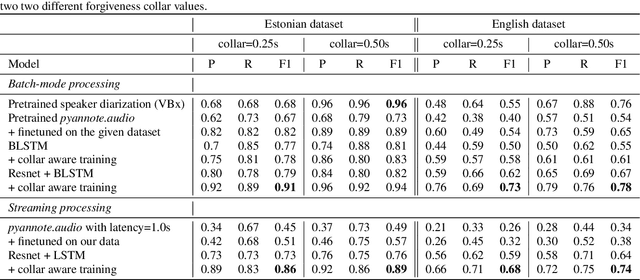
In this paper, we present a novel training method for speaker change detection models. Speaker change detection is often viewed as a binary sequence labelling problem. The main challenges with this approach are the vagueness of annotated change points caused by the silences between speaker turns and imbalanced data due to the majority of frames not including a speaker change. Conventional training methods tackle these by artificially increasing the proportion of positive labels in the training data. Instead, the proposed method uses an objective function which encourages the model to predict a single positive label within a specified collar. This is done by marginalizing over all possible subsequences that have exactly one positive label within the collar. Experiments on English and Estonian datasets show large improvements over the conventional training method. Additionally, the model outputs have peaks concentrated to a single frame, removing the need for post-processing to find the exact predicted change point which is particularly useful for streaming applications.
Syntax Controlled Knowledge Graph-to-Text Generation with Order and Semantic Consistency
Jul 02, 2022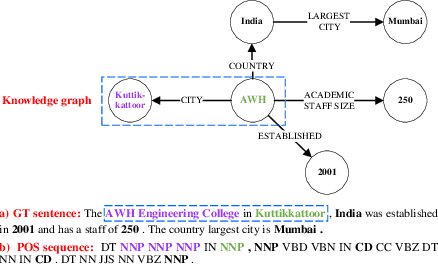
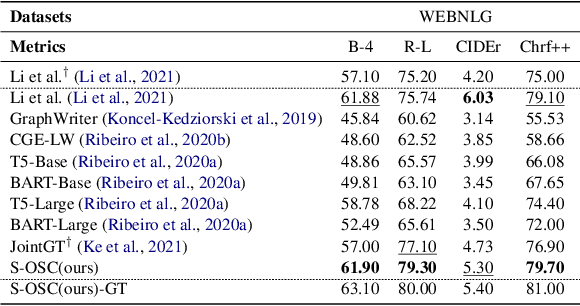
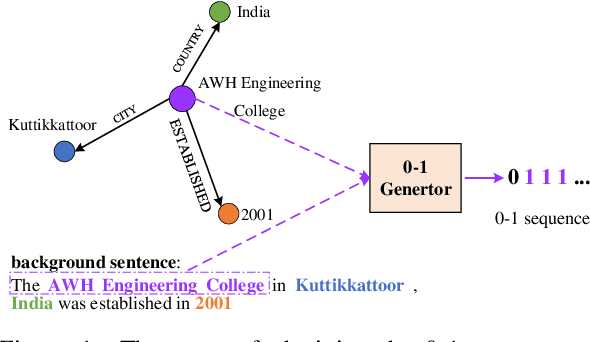
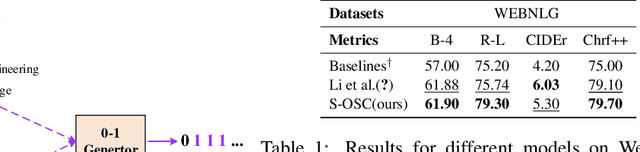
The knowledge graph (KG) stores a large amount of structural knowledge, while it is not easy for direct human understanding. Knowledge graph-to-text (KG-to-text) generation aims to generate easy-to-understand sentences from the KG, and at the same time, maintains semantic consistency between generated sentences and the KG. Existing KG-to-text generation methods phrase this task as a sequence-to-sequence generation task with linearized KG as input and consider the consistency issue of the generated texts and KG through a simple selection between decoded sentence word and KG node word at each time step. However, the linearized KG order is commonly obtained through a heuristic search without data-driven optimization. In this paper, we optimize the knowledge description order prediction under the order supervision extracted from the caption and further enhance the consistency of the generated sentences and KG through syntactic and semantic regularization. We incorporate the Part-of-Speech (POS) syntactic tags to constrain the positions to copy words from the KG and employ a semantic context scoring function to evaluate the semantic fitness for each word in its local context when decoding each word in the generated sentence. Extensive experiments are conducted on two datasets, WebNLG and DART, and achieve state-of-the-art performances.
SkinAugment: Auto-Encoding Speaker Conversions for Automatic Speech Translation
Feb 27, 2020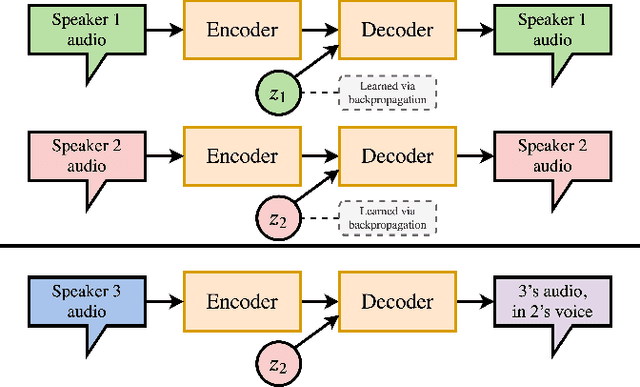
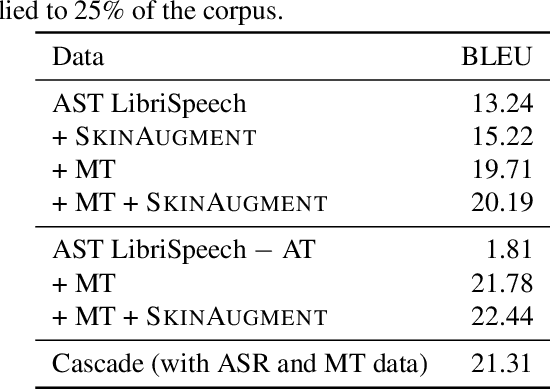
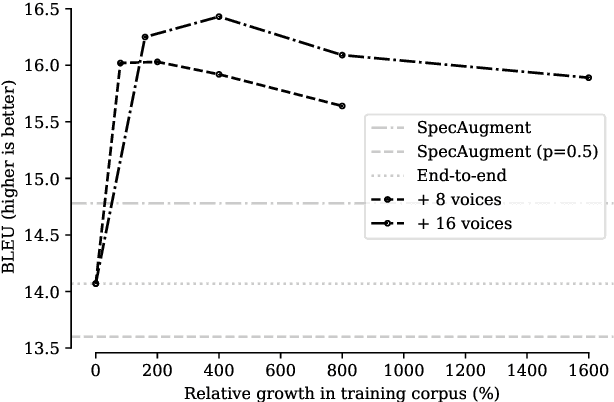
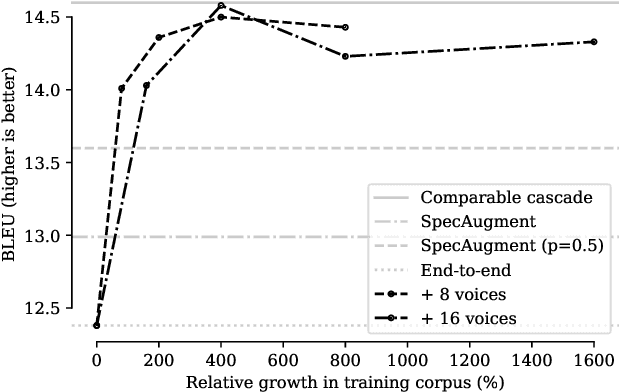
We propose autoencoding speaker conversion for training data augmentation in automatic speech translation. This technique directly transforms an audio sequence, resulting in audio synthesized to resemble another speaker's voice. Our method compares favorably to SpecAugment on English$\to$French and English$\to$Romanian automatic speech translation (AST) tasks as well as on a low-resource English automatic speech recognition (ASR) task. Further, in ablations, we show the benefits of both quantity and diversity in augmented data. Finally, we show that we can combine our approach with augmentation by machine-translated transcripts to obtain a competitive end-to-end AST model that outperforms a very strong cascade model on an English$\to$French AST task. Our method is sufficiently general that it can be applied to other speech generation and analysis tasks.