 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
audino: A Modern Annotation Tool for Audio and Speech
Jun 09, 2020
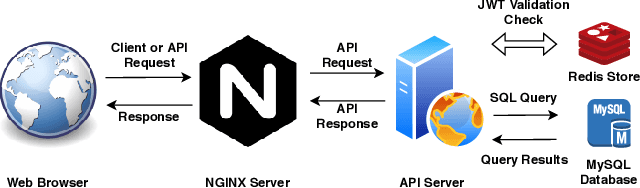
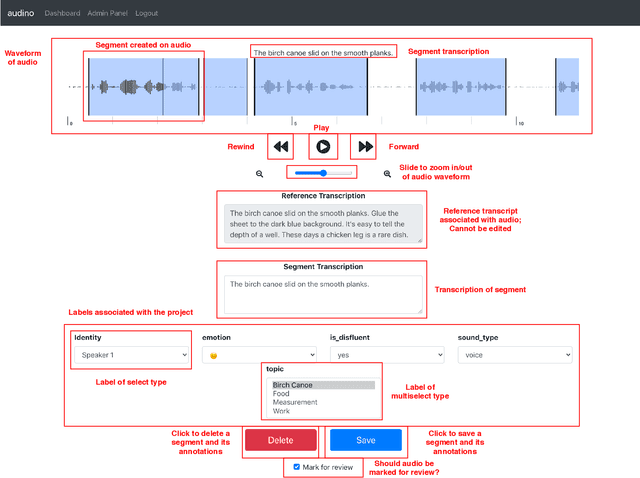
In this paper, we introduce a collaborative and modern annotation tool for audio and speech: audino. The tool allows annotators to define and describe temporal segmentation in audios. These segments can be labelled and transcribed easily using a dynamically generated form. An admin can centrally control user roles and project assignment through the admin dashboard. The dashboard also enables describing labels and their values. The annotations can easily be exported in JSON format for further processing. The tool allows audio data to be uploaded and assigned to a user through a key-based API. The flexibility available in the annotation tool enables annotation for Speech Scoring, Voice Activity Detection (VAD), Speaker Diarisation, Speaker Identification, Speech Recognition, Emotion Recognition tasks and more. The MIT open source license allows it to be used for academic and commercial projects.
Multi-task Language Modeling for Improving Speech Recognition of Rare Words
Nov 25, 2020

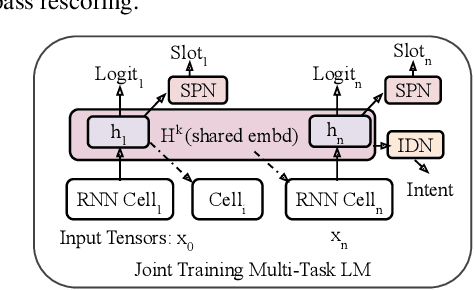
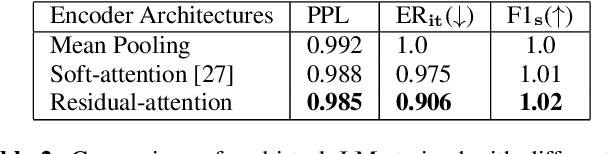
End-to-end automatic speech recognition (ASR) systems are increasingly popular due to their relative architectural simplicity and competitive performance. However, even though the average accuracy of these systems may be high, the performance on rare content words often lags behind hybrid ASR systems. To address this problem, second-pass rescoring is often applied. In this paper, we propose a second-pass system with multi-task learning, utilizing semantic targets (such as intent and slot prediction) to improve speech recognition performance. We show that our rescoring model with trained with these additional tasks outperforms the baseline rescoring model, trained with only the language modeling task, by 1.4% on a general test and by 2.6% on a rare word test set in term of word-error-rate relative (WERR).
Easy Adaptation to Mitigate Gender Bias in Multilingual Text Classification
Apr 12, 2022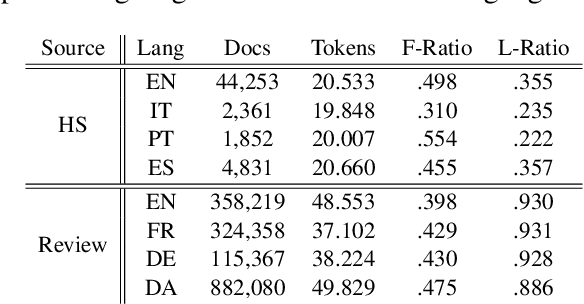
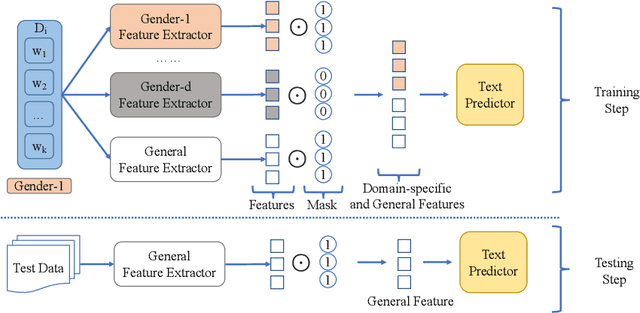
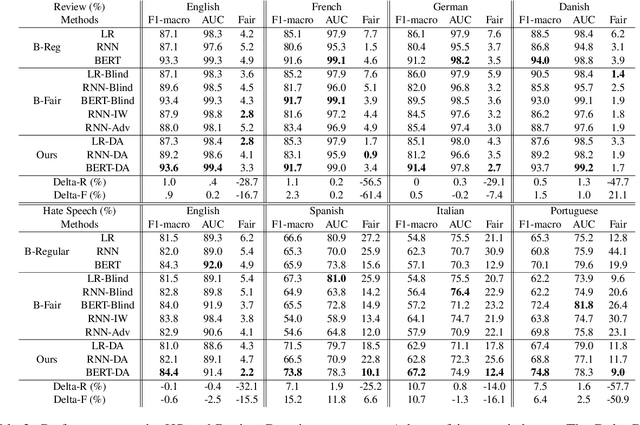
Existing approaches to mitigate demographic biases evaluate on monolingual data, however, multilingual data has not been examined. In this work, we treat the gender as domains (e.g., male vs. female) and present a standard domain adaptation model to reduce the gender bias and improve performance of text classifiers under multilingual settings. We evaluate our approach on two text classification tasks, hate speech detection and rating prediction, and demonstrate the effectiveness of our approach with three fair-aware baselines.
Deep Learning Models for Multilingual Hate Speech Detection
Apr 15, 2020
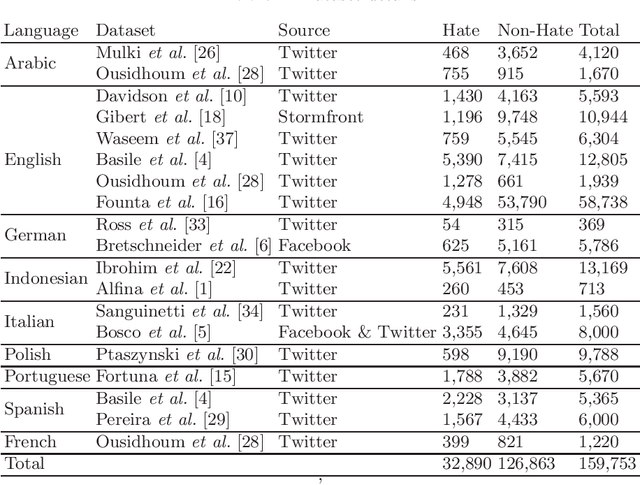
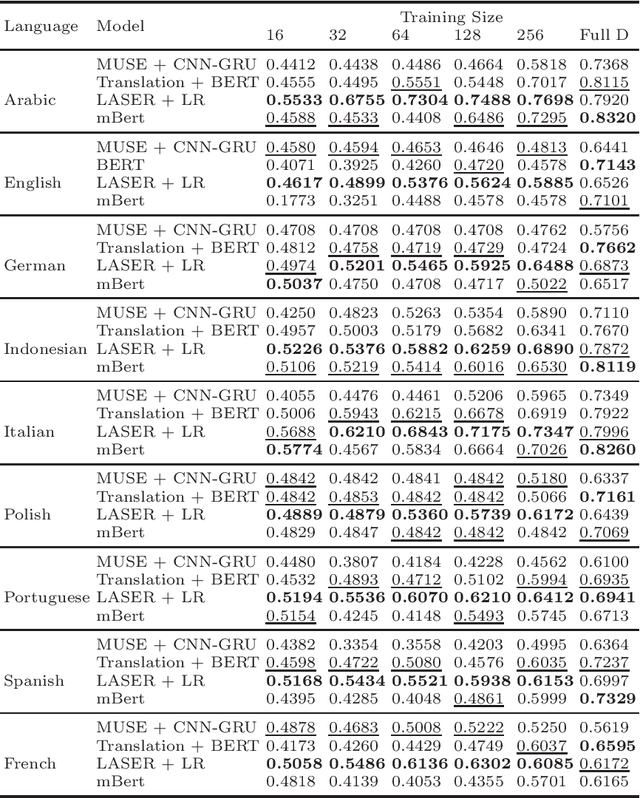
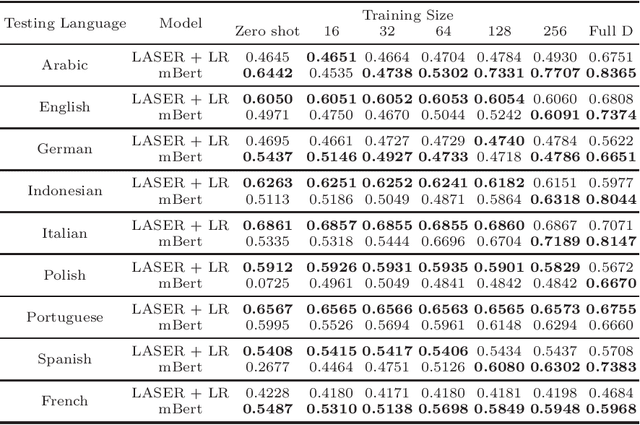
Hate speech detection is a challenging problem with most of the datasets available in only one language: English. In this paper, we conduct a large scale analysis of multilingual hate speech in 9 languages from 16 different sources. We observe that in low resource setting, simple models such as LASER embedding with logistic regression performs the best, while in high resource setting BERT based models perform better. In case of zero-shot classification, languages such as Italian and Portuguese achieve good results. Our proposed framework could be used as an efficient solution for low-resource languages. These models could also act as good baselines for future multilingual hate speech detection tasks. We have made our code and experimental settings public for other researchers at https://github.com/punyajoy/DE-LIMIT.
Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
Apr 09, 2021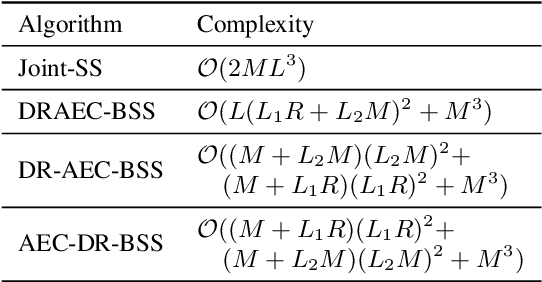
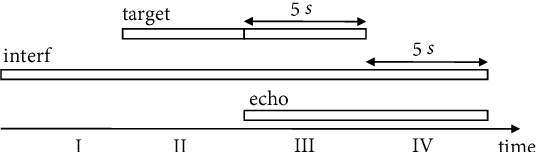
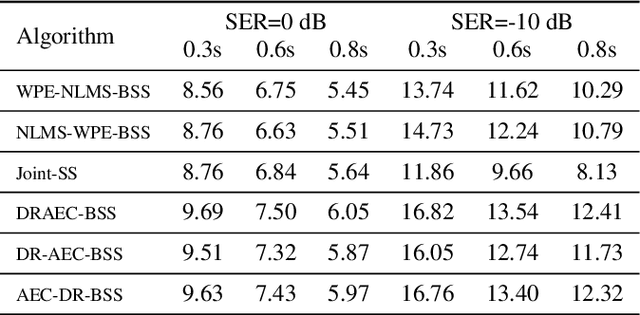
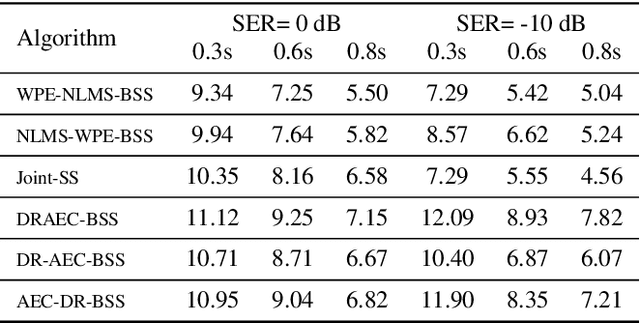
This paper presents a joint source separation algorithm that simultaneously reduces acoustic echo, reverberation and interfering sources. Target speeches are separated from the mixture by maximizing independence with respect to the other sources. It is shown that the separation process can be decomposed into cascading sub-processes that separately relate to acoustic echo cancellation, speech dereverberation and source separation, all of which are solved using the auxiliary function based independent component/vector analysis techniques, and their solving orders are exchangeable. The cascaded solution not only leads to lower computational complexity but also better separation performance than the vanilla joint algorithm.
Are discrete units necessary for Spoken Language Modeling?
Mar 11, 2022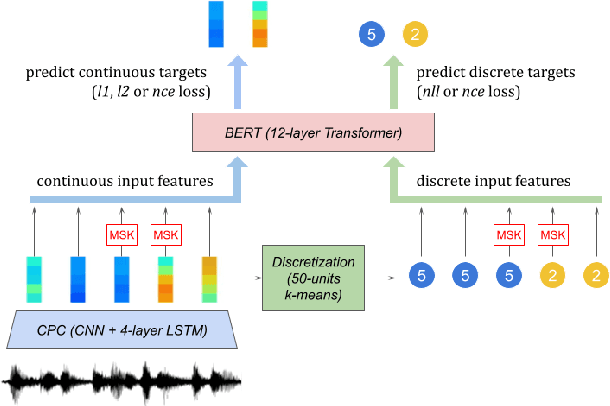
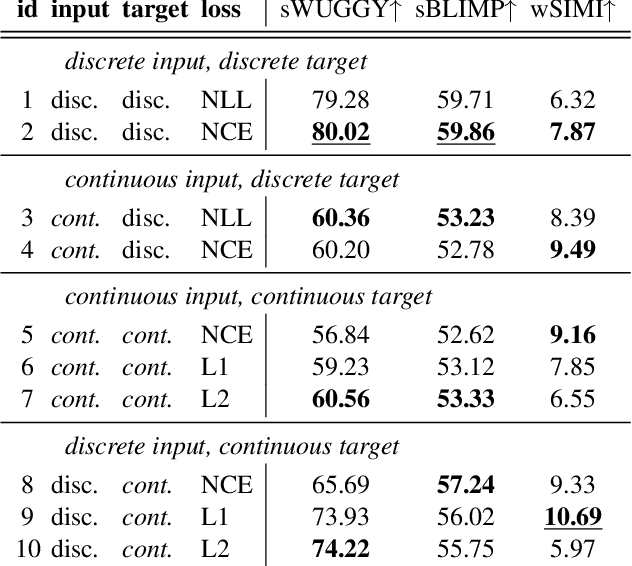
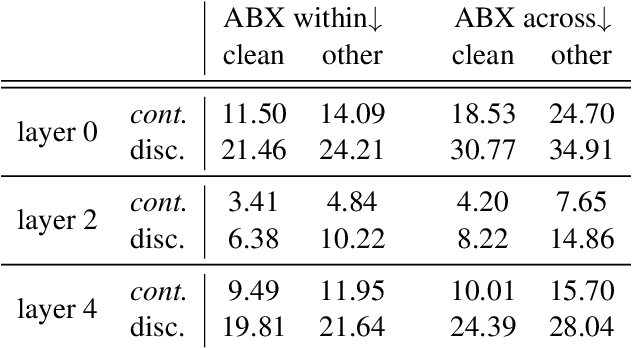
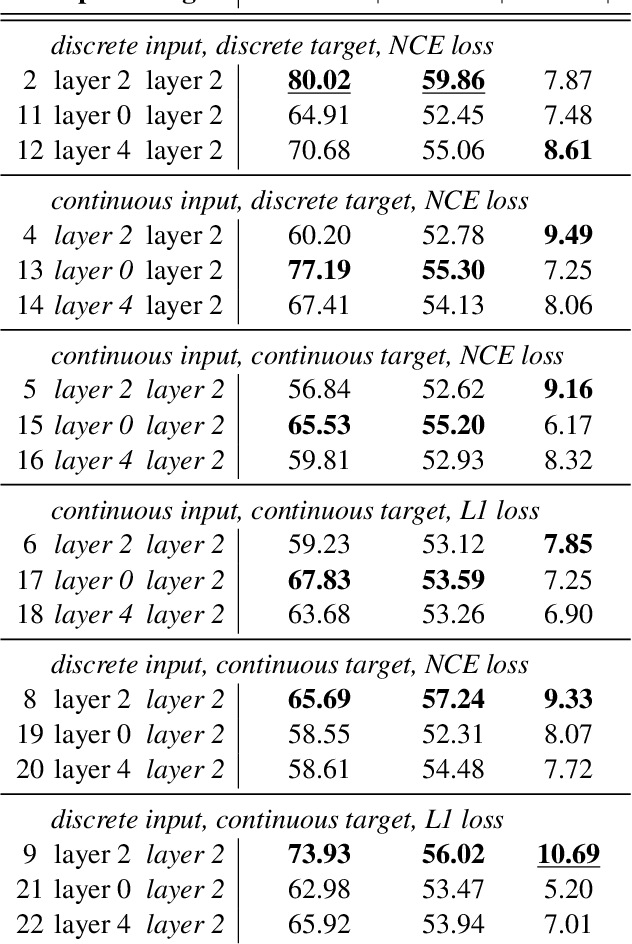
Recent work in spoken language modeling shows the possibility of learning a language unsupervisedly from raw audio without any text labels. The approach relies first on transforming the audio into a sequence of discrete units (or pseudo-text) and then training a language model directly on such pseudo-text. Is such a discrete bottleneck necessary, potentially introducing irreversible errors in the encoding of the speech signal, or could we learn a language model without discrete units at all? In this work, show that discretization is indeed essential for good results in spoken language modeling, but that can omit the discrete bottleneck if we use using discrete target features from a higher level than the input features. We also show that an end-to-end model trained with discrete target like HuBERT achieves similar results as the best language model trained on pseudo-text on a set of zero-shot spoken language modeling metrics from the Zero Resource Speech Challenge 2021.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020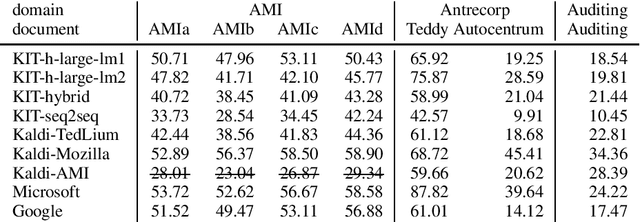
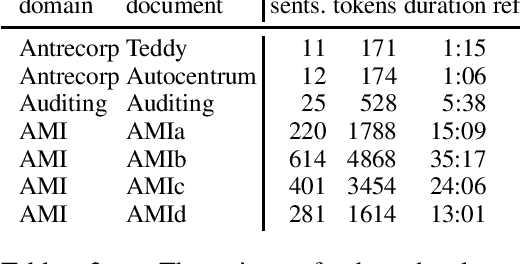
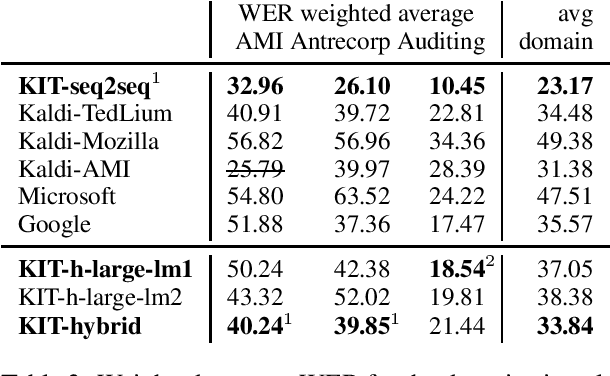

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021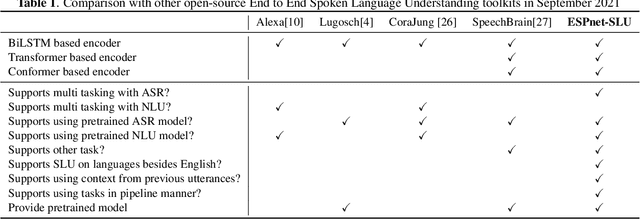
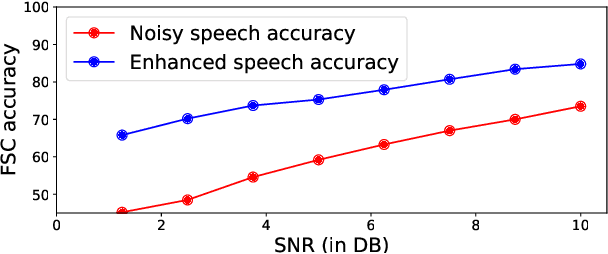
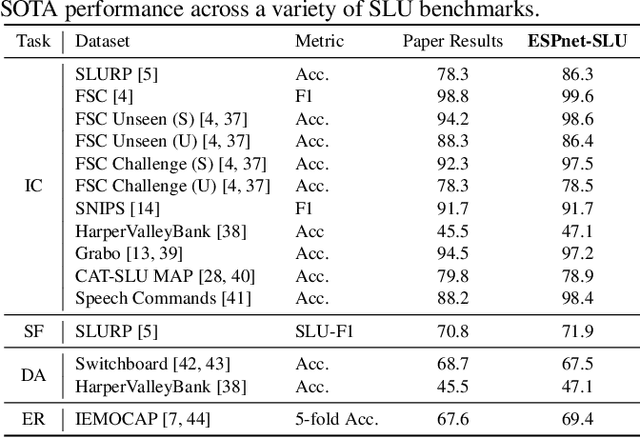

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021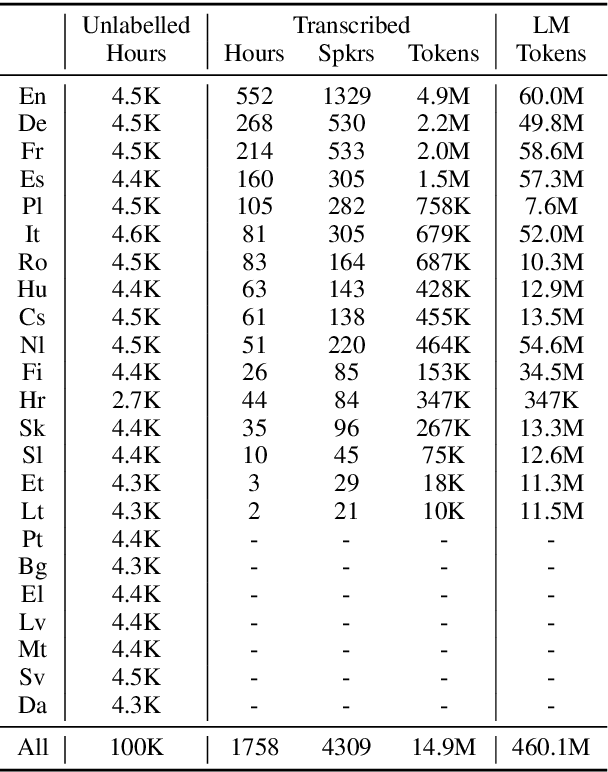
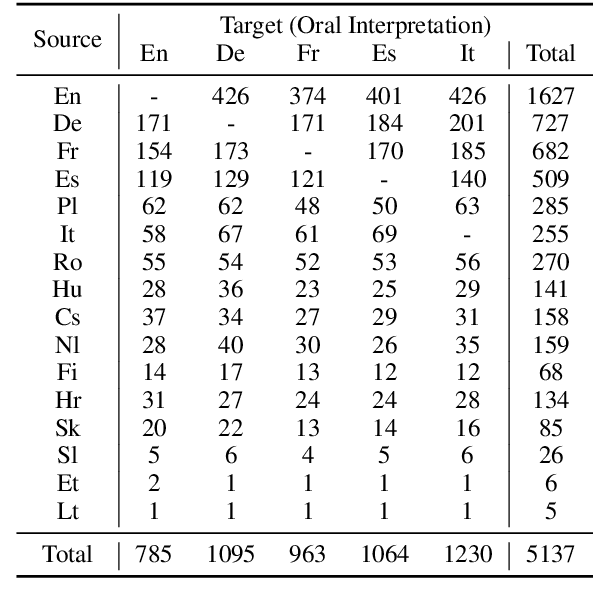

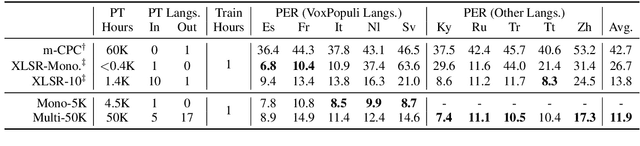
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
A Step Towards Preserving Speakers' Identity While Detecting Depression Via Speaker Disentanglement
Jun 29, 2022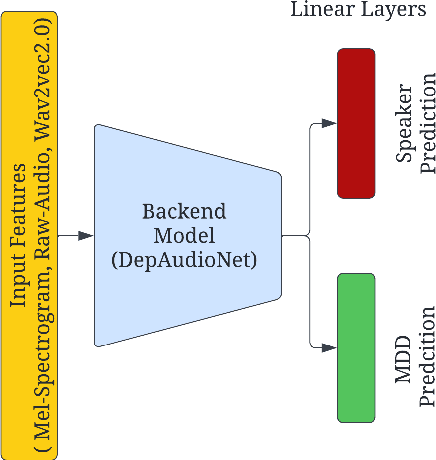
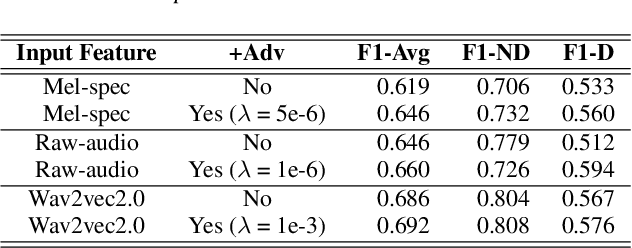
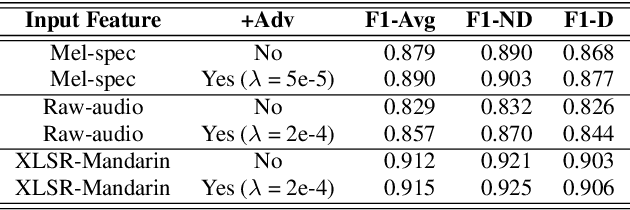

Preserving a patient's identity is a challenge for automatic, speech-based diagnosis of mental health disorders. In this paper, we address this issue by proposing adversarial disentanglement of depression characteristics and speaker identity. The model used for depression classification is trained in a speaker-identity-invariant manner by minimizing depression prediction loss and maximizing speaker prediction loss during training. The effectiveness of the proposed method is demonstrated on two datasets - DAIC-WOZ (English) and CONVERGE (Mandarin), with three feature sets (Mel-spectrograms, raw-audio signals, and the last-hidden-state of Wav2vec2.0), using a modified DepAudioNet model. With adversarial training, depression classification improves for every feature when compared to the baseline. Wav2vec2.0 features with adversarial learning resulted in the best performance (F1-score of 69.2% for DAIC-WOZ and 91.5% for CONVERGE). Analysis of the class-separability measure (J-ratio) of the hidden states of the DepAudioNet model shows that when adversarial learning is applied, the backend model loses some speaker-discriminability while it improves depression-discriminability. These results indicate that there are some components of speaker identity that may not be useful for depression detection and minimizing their effects provides a more accurate diagnosis of the underlying disorder and can safeguard a speaker's identity.