 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Comparing Performance of Different Linguistically-Backed Word Embeddings for Cyberbullying Detection
Jun 04, 2022
In most cases, word embeddings are learned only from raw tokens or in some cases, lemmas. This includes pre-trained language models like BERT. To investigate on the potential of capturing deeper relations between lexical items and structures and to filter out redundant information, we propose to preserve the morphological, syntactic and other types of linguistic information by combining them with the raw tokens or lemmas. This means, for example, including parts-of-speech or dependency information within the used lexical features. The word embeddings can then be trained on the combinations instead of just raw tokens. It is also possible to later apply this method to the pre-training of huge language models and possibly enhance their performance. This would aid in tackling problems which are more sophisticated from the point of view of linguistic representation, such as detection of cyberbullying.
Multimodal Representation Learning With Text and Images
Apr 30, 2022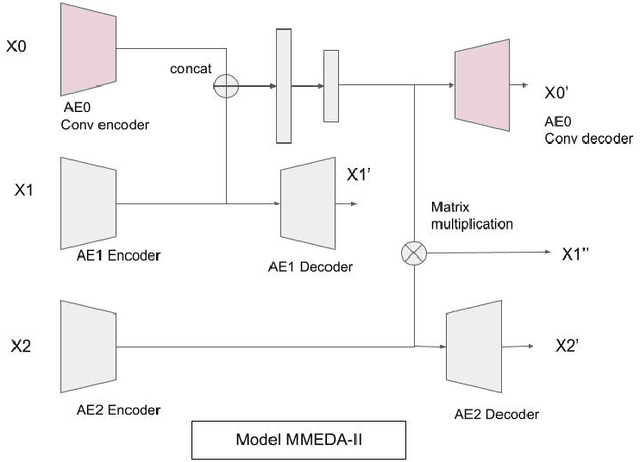
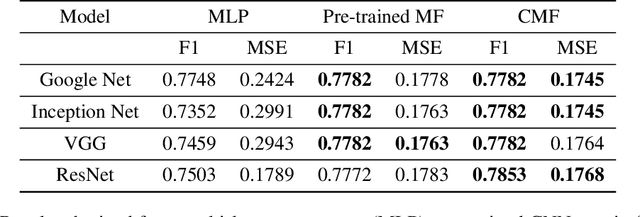
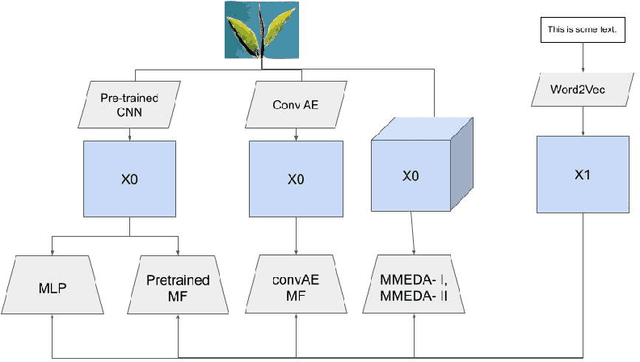
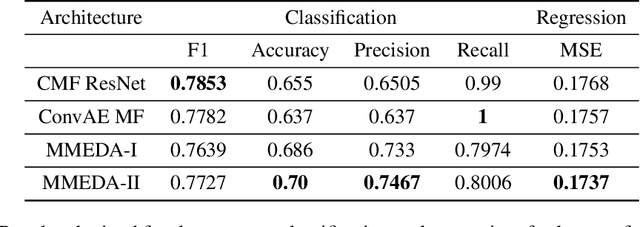
In recent years, multimodal AI has seen an upward trend as researchers are integrating data of different types such as text, images, speech into modelling to get the best results. This project leverages multimodal AI and matrix factorization techniques for representation learning, on text and image data simultaneously, thereby employing the widely used techniques of Natural Language Processing (NLP) and Computer Vision. The learnt representations are evaluated using downstream classification and regression tasks. The methodology adopted can be extended beyond the scope of this project as it uses Auto-Encoders for unsupervised representation learning.
GraphSpeech: Syntax-Aware Graph Attention Network For Neural Speech Synthesis
Oct 23, 2020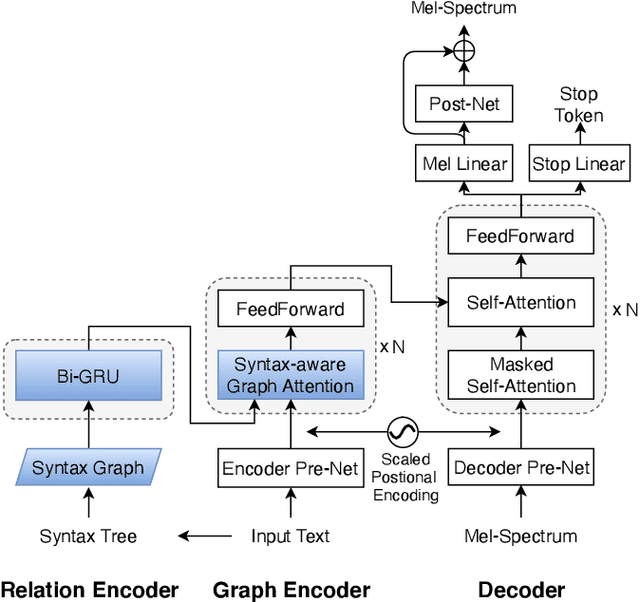

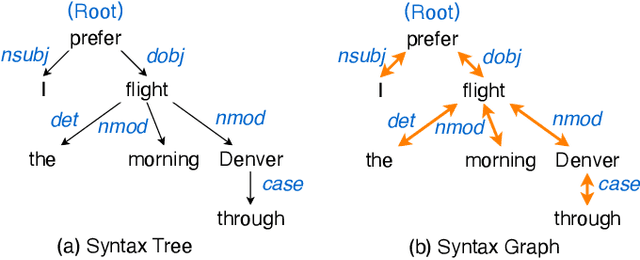

Attention-based end-to-end text-to-speech synthesis (TTS) is superior to conventional statistical methods in many ways. Transformer-based TTS is one of such successful implementations. While Transformer TTS models the speech frame sequence well with a self-attention mechanism, it does not associate input text with output utterances from a syntactic point of view at sentence level. We propose a novel neural TTS model, denoted as GraphSpeech, that is formulated under graph neural network framework. GraphSpeech encodes explicitly the syntactic relation of input lexical tokens in a sentence, and incorporates such information to derive syntactically motivated character embeddings for TTS attention mechanism. Experiments show that GraphSpeech consistently outperforms the Transformer TTS baseline in terms of spectrum and prosody rendering of utterances.
Gaze-Vergence-Controlled See-Through Vision in Augmented Reality
Jul 06, 2022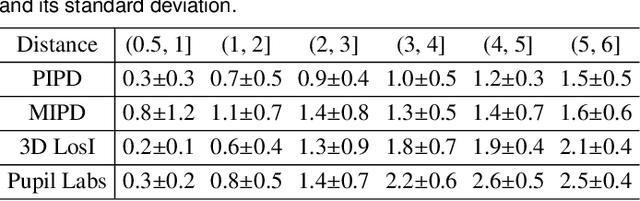
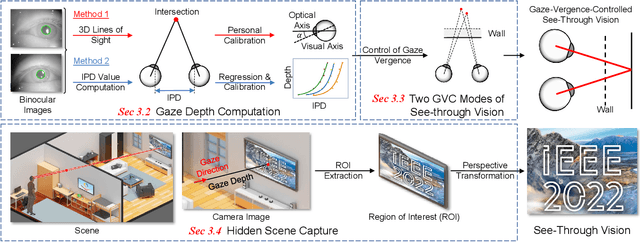
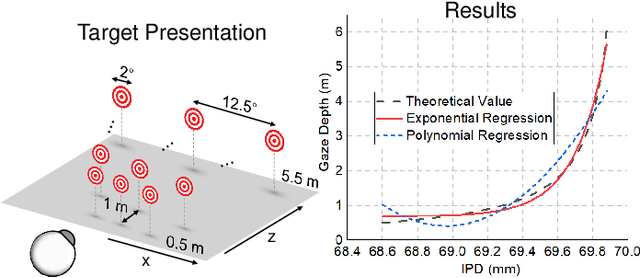
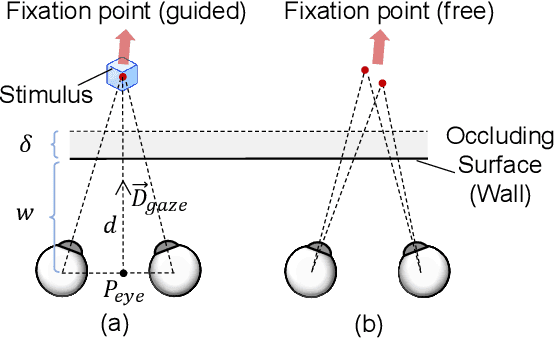
Augmented Reality (AR) see-through vision is an interesting research topic since it enables users to see through a wall and see the occluded objects. Most existing research focuses on the visual effects of see-through vision, while the interaction method is less studied. However, we argue that using common interaction modalities, e.g., midair click and speech, may not be the optimal way to control see-through vision. This is because when we want to see through something, it is physically related to our gaze depth/vergence and thus should be naturally controlled by the eyes. Following this idea, this paper proposes a novel gaze-vergence-controlled (GVC) see-through vision technique in AR. Since gaze depth is needed, we build a gaze tracking module with two infrared cameras and the corresponding algorithm and assemble it into the Microsoft HoloLens 2 to achieve gaze depth estimation. We then propose two different GVC modes for see-through vision to fit different scenarios. Extensive experimental results demonstrate that our gaze depth estimation is efficient and accurate. By comparing with conventional interaction modalities, our GVC techniques are also shown to be superior in terms of efficiency and more preferred by users. Finally, we present four example applications of gaze-vergence-controlled see-through vision.
Adversarial Text Normalization
Jun 08, 2022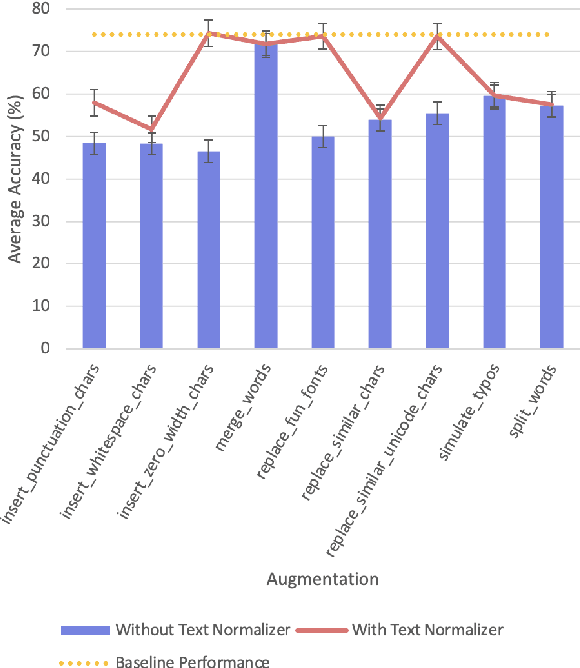
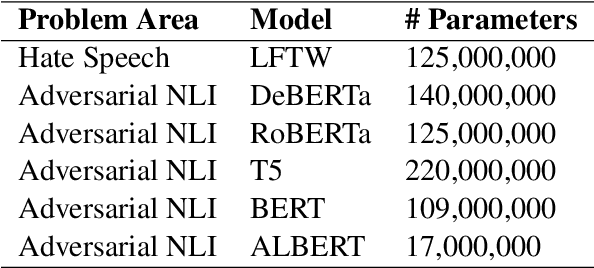

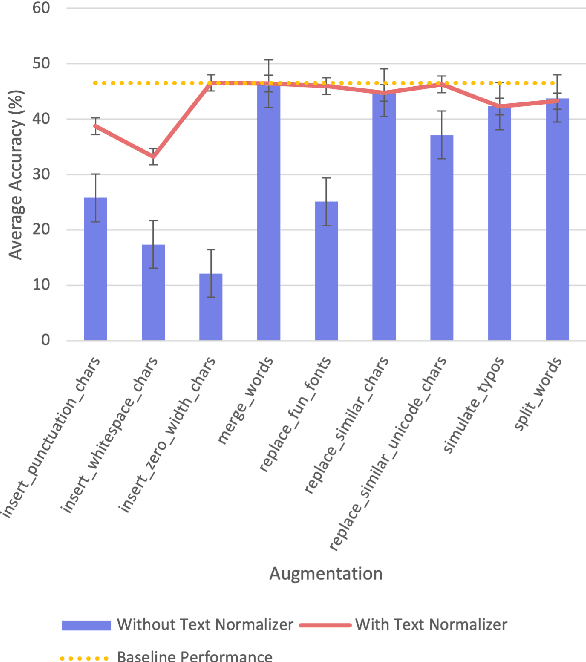
Text-based adversarial attacks are becoming more commonplace and accessible to general internet users. As these attacks proliferate, the need to address the gap in model robustness becomes imminent. While retraining on adversarial data may increase performance, there remains an additional class of character-level attacks on which these models falter. Additionally, the process to retrain a model is time and resource intensive, creating a need for a lightweight, reusable defense. In this work, we propose the Adversarial Text Normalizer, a novel method that restores baseline performance on attacked content with low computational overhead. We evaluate the efficacy of the normalizer on two problem areas prone to adversarial attacks, i.e. Hate Speech and Natural Language Inference. We find that text normalization provides a task-agnostic defense against character-level attacks that can be implemented supplementary to adversarial retraining solutions, which are more suited for semantic alterations.
Comparing the Benefit of Synthetic Training Data for Various Automatic Speech Recognition Architectures
Apr 12, 2021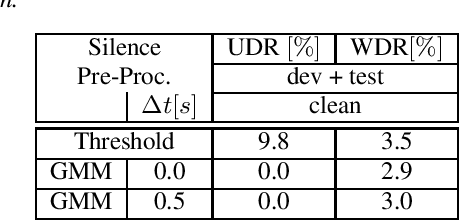
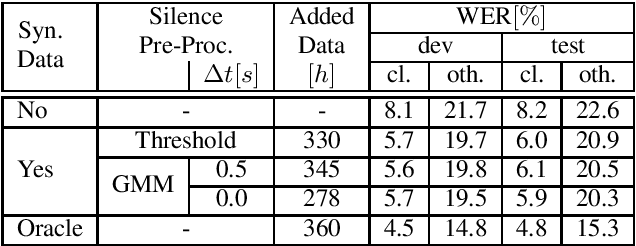
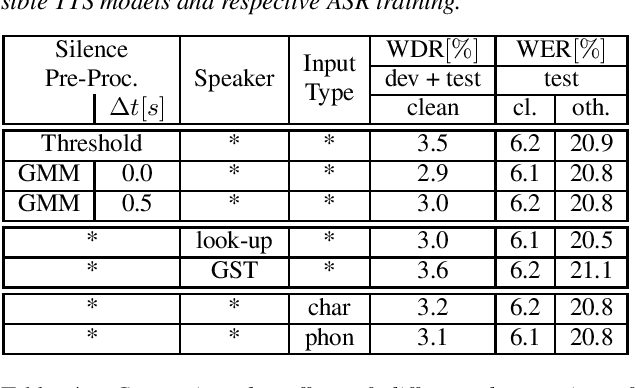
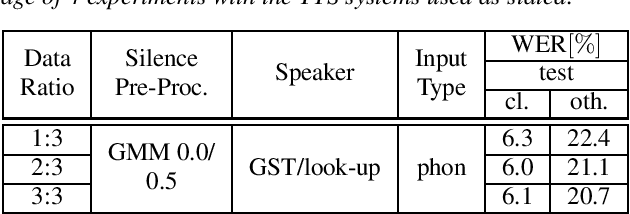
Recent publications on automatic-speech-recognition (ASR) have a strong focus on attention encoder-decoder (AED) architectures which work well for large datasets, but tend to overfit when applied in low resource scenarios. One solution to tackle this issue is to generate synthetic data with a trained text-to-speech system (TTS) if additional text is available. This was successfully applied in many publications with AED systems. We present a novel approach of silence correction in the data pre-processing for TTS systems which increases the robustness when training on corpora targeted for ASR applications. In this work we do not only show the successful application of synthetic data for AED systems, but also test the same method on a highly optimized state-of-the-art Hybrid ASR system and a competitive monophone based system using connectionist-temporal-classification (CTC). We show that for the later systems the addition of synthetic data only has a minor effect, but they still outperform the AED systems by a large margin on LibriSpeech-100h. We achieve a final word-error-rate of 3.3%/10.0% with a Hybrid system on the clean/noisy test-sets, surpassing any previous state-of-the-art systems that do not include unlabeled audio data.
Continuous Speech Recognition using EEG and Video
Dec 19, 2019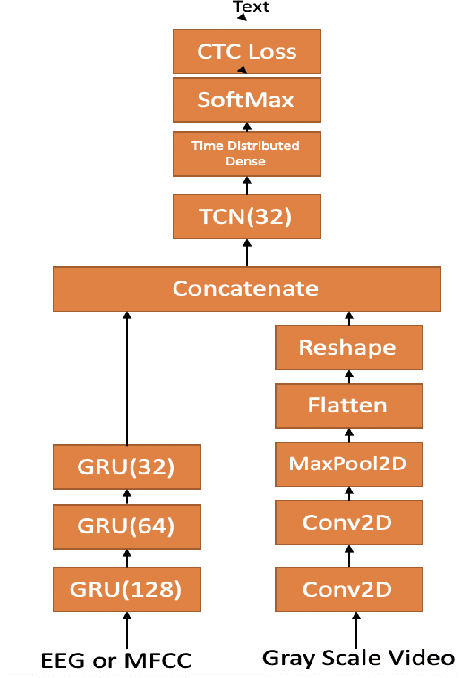
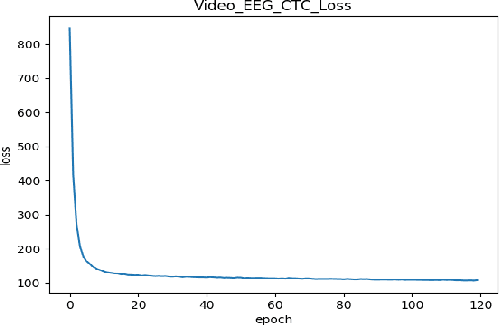
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition.
Improving Prosody Modelling with Cross-Utterance BERT Embeddings for End-to-end Speech Synthesis
Nov 06, 2020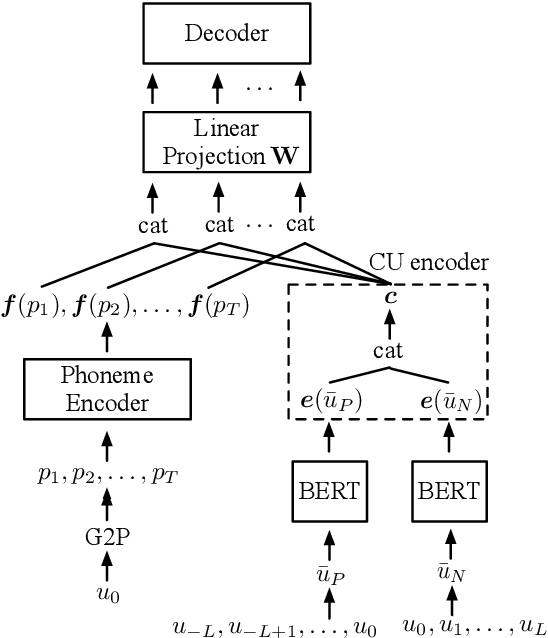
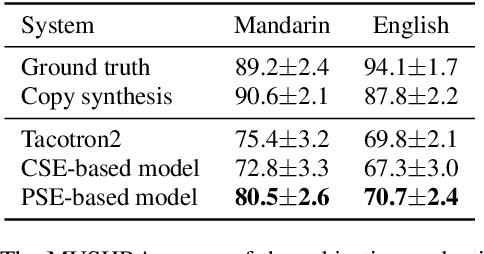
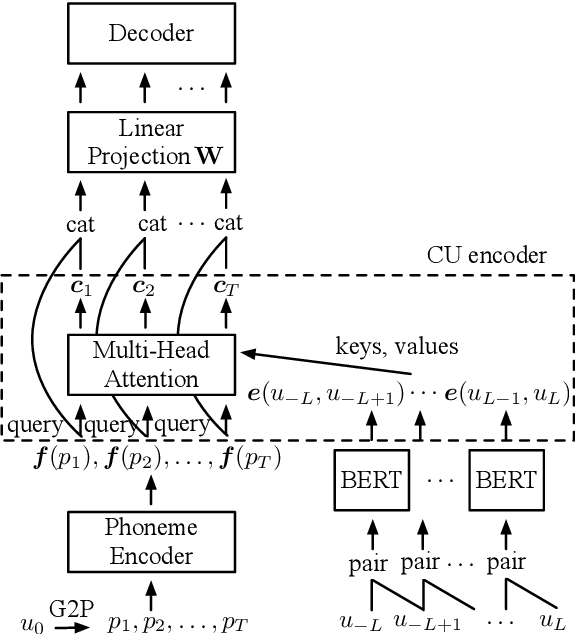
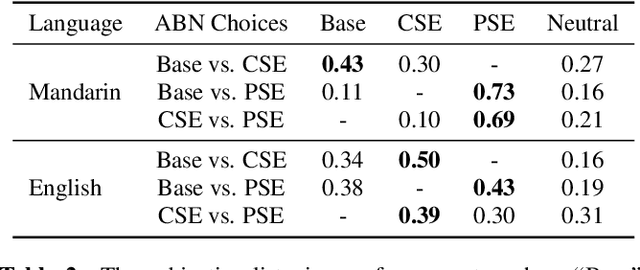
Despite prosody is related to the linguistic information up to the discourse structure, most text-to-speech (TTS) systems only take into account that within each sentence, which makes it challenging when converting a paragraph of texts into natural and expressive speech. In this paper, we propose to use the text embeddings of the neighboring sentences to improve the prosody generation for each utterance of a paragraph in an end-to-end fashion without using any explicit prosody features. More specifically, cross-utterance (CU) context vectors, which are produced by an additional CU encoder based on the sentence embeddings extracted by a pre-trained BERT model, are used to augment the input of the Tacotron2 decoder. Two types of BERT embeddings are investigated, which leads to the use of different CU encoder structures. Experimental results on a Mandarin audiobook dataset and the LJ-Speech English audiobook dataset demonstrate the use of CU information can improve the naturalness and expressiveness of the synthesized speech. Subjective listening testing shows most of the participants prefer the voice generated using the CU encoder over that generated using standard Tacotron2. It is also found that the prosody can be controlled indirectly by changing the neighbouring sentences.
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.