 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning to Recognise Words using Visually Grounded Speech
May 31, 2020
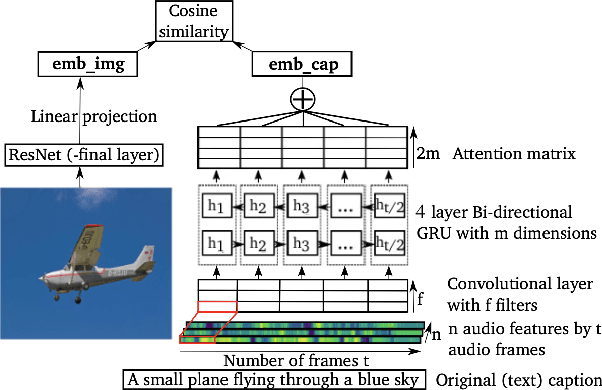
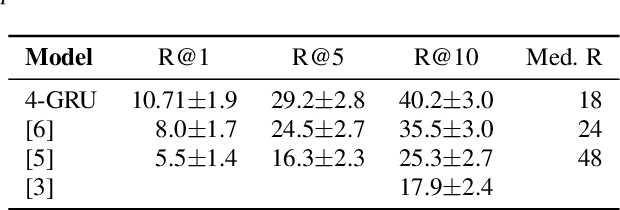
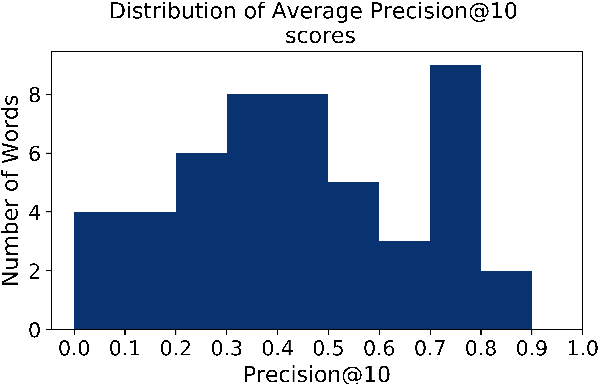

We investigated word recognition in a Visually Grounded Speech model. The model has been trained on pairs of images and spoken captions to create visually grounded embeddings which can be used for speech to image retrieval and vice versa. We investigate whether such a model can be used to recognise words by embedding isolated words and using them to retrieve images of their visual referents. We investigate the time-course of word recognition using a gating paradigm and perform a statistical analysis to see whether well known word competition effects in human speech processing influence word recognition. Our experiments show that the model is able to recognise words, and the gating paradigm reveals that words can be recognised from partial input as well and that recognition is negatively influenced by word competition from the word initial cohort.
Improving End-to-End Models for Set Prediction in Spoken Language Understanding
Jan 28, 2022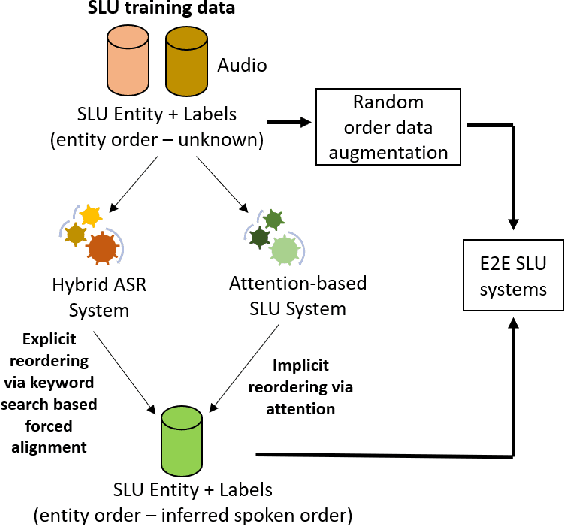

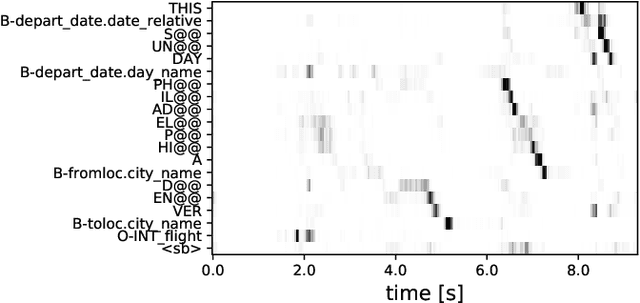
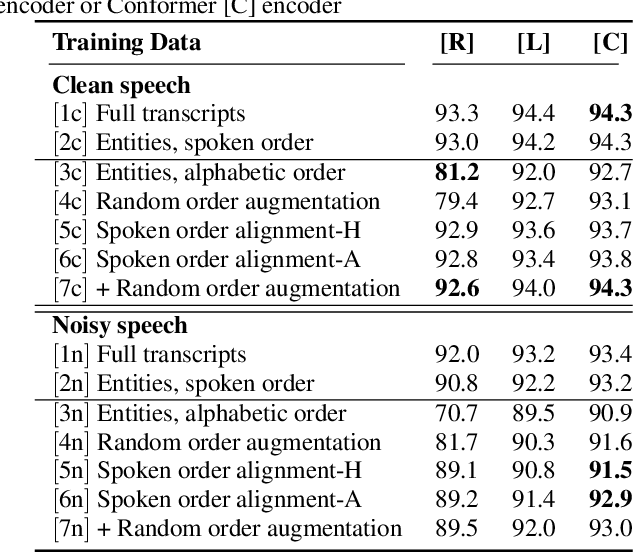
The goal of spoken language understanding (SLU) systems is to determine the meaning of the input speech signal, unlike speech recognition which aims to produce verbatim transcripts. Advances in end-to-end (E2E) speech modeling have made it possible to train solely on semantic entities, which are far cheaper to collect than verbatim transcripts. We focus on this set prediction problem, where entity order is unspecified. Using two classes of E2E models, RNN transducers and attention based encoder-decoders, we show that these models work best when the training entity sequence is arranged in spoken order. To improve E2E SLU models when entity spoken order is unknown, we propose a novel data augmentation technique along with an implicit attention based alignment method to infer the spoken order. F1 scores significantly increased by more than 11% for RNN-T and about 2% for attention based encoder-decoder SLU models, outperforming previously reported results.
Speaker-aware speech-transformer
Jan 02, 2020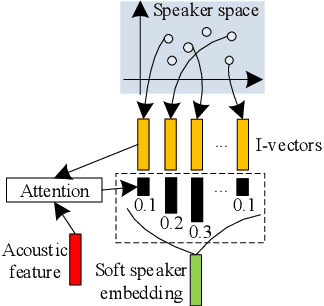
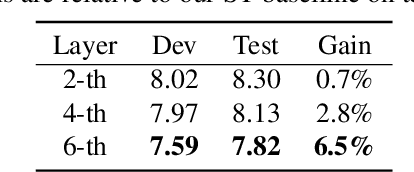
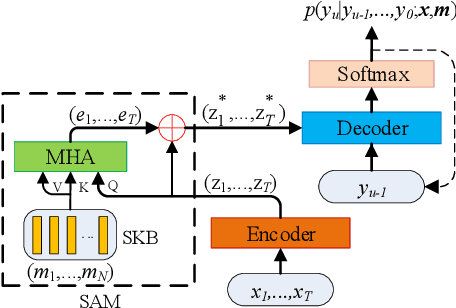
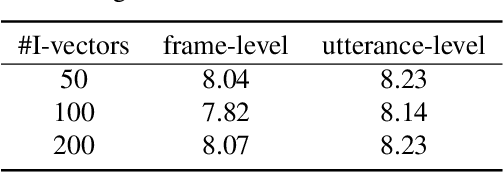
Recently, end-to-end (E2E) models become a competitive alternative to the conventional hybrid automatic speech recognition (ASR) systems. However, they still suffer from speaker mismatch in training and testing condition. In this paper, we use Speech-Transformer (ST) as the study platform to investigate speaker aware training of E2E models. We propose a model called Speaker-Aware Speech-Transformer (SAST), which is a standard ST equipped with a speaker attention module (SAM). The SAM has a static speaker knowledge block (SKB) that is made of i-vectors. At each time step, the encoder output attends to the i-vectors in the block, and generates a weighted combined speaker embedding vector, which helps the model to normalize the speaker variations. The SAST model trained in this way becomes independent of specific training speakers and thus generalizes better to unseen testing speakers. We investigate different factors of SAM. Experimental results on the AISHELL-1 task show that SAST achieves a relative 6.5% CER reduction (CERR) over the speaker-independent (SI) baseline. Moreover, we demonstrate that SAST still works quite well even if the i-vectors in SKB all come from a different data source other than the acoustic training set.
Dialog+ in Broadcasting: First Field Tests Using Deep-Learning-Based Dialogue Enhancement
Dec 17, 2021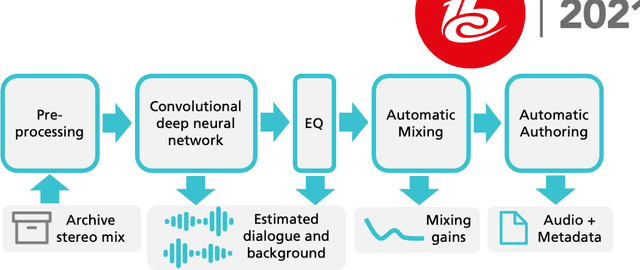
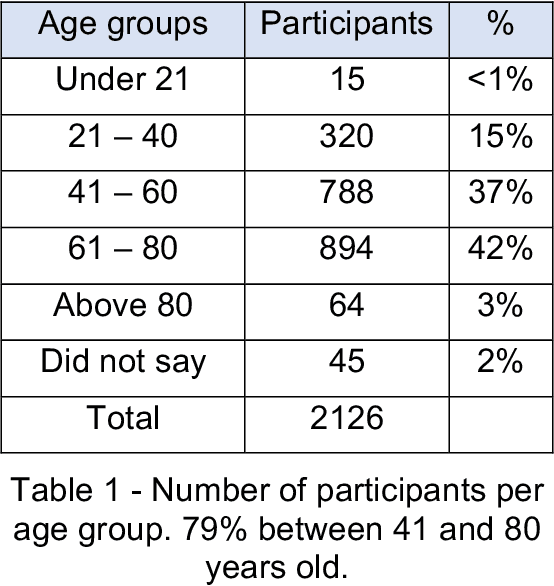


Difficulties in following speech due to loud background sounds are common in broadcasting. Object-based audio, e.g., MPEG-H Audio solves this problem by providing a user-adjustable speech level. While object-based audio is gaining momentum, transitioning to it requires time and effort. Also, lots of content exists, produced and archived outside the object-based workflows. To address this, Fraunhofer IIS has developed a deep-learning solution called Dialog+, capable of enabling speech level personalization also for content with only the final audio tracks available. This paper reports on public field tests evaluating Dialog+, conducted together with Westdeutscher Rundfunk (WDR) and Bayerischer Rundfunk (BR), starting from September 2020. To our knowledge, these are the first large-scale tests of this kind. As part of one of these, a survey with more than 2,000 participants showed that 90% of the people above 60 years old have problems in understanding speech in TV "often" or "very often". Overall, 83% of the participants liked the possibility to switch to Dialog+, including those who do not normally struggle with speech intelligibility. Dialog+ introduces a clear benefit for the audience, filling the gap between object-based broadcasting and traditionally produced material.
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
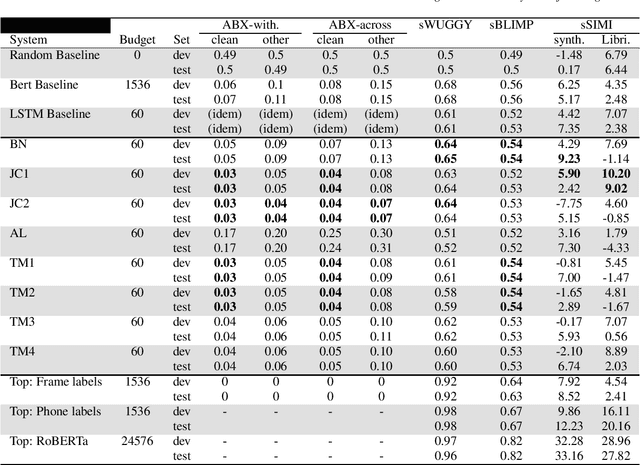
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
Is the Language Familiarity Effect gradual? A computational modelling approach
Jun 27, 2022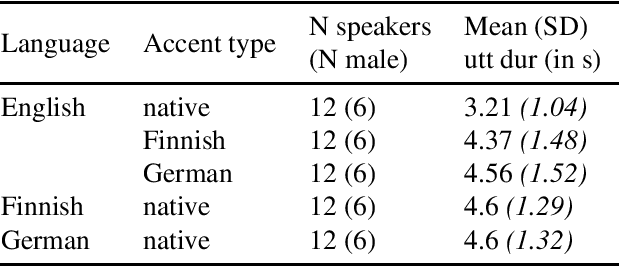
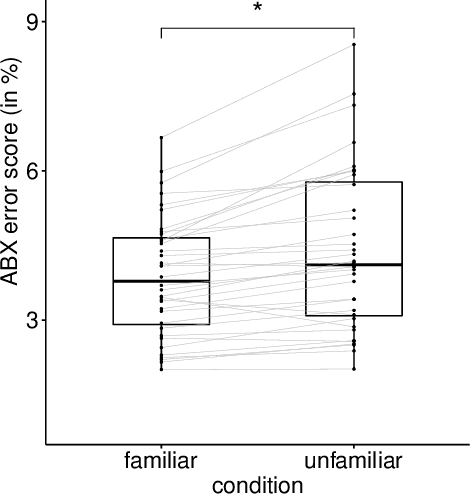

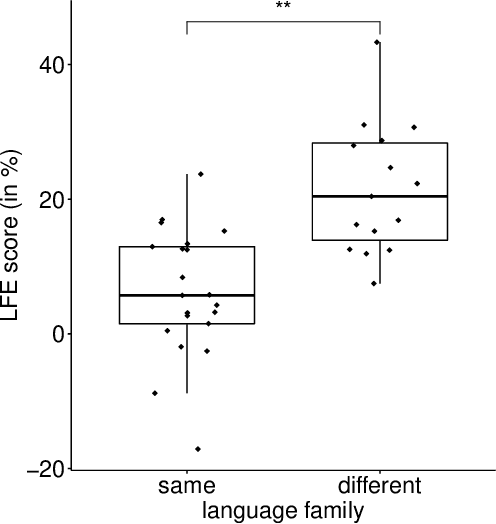
According to the Language Familiarity Effect (LFE), people are better at discriminating between speakers of their native language. Although this cognitive effect was largely studied in the literature, experiments have only been conducted on a limited number of language pairs and their results only show the presence of the effect without yielding a gradual measure that may vary across language pairs. In this work, we show that the computational model of LFE introduced by Thorburn, Feldmand and Schatz (2019) can address these two limitations. In a first experiment, we attest to this model's capacity to obtain a gradual measure of the LFE by replicating behavioural findings on native and accented speech. In a second experiment, we evaluate LFE on a large number of language pairs, including many which have never been tested on humans. We show that the effect is replicated across a wide array of languages, providing further evidence of its universality. Building on the gradual measure of LFE, we also show that languages belonging to the same family yield smaller scores, supporting the idea of an effect of language distance on LFE.
MAC-DO: Charge Based Multi-Bit Analog In-Memory Accelerator Compatible with DRAM Using Output Stationary Mapping
Jul 16, 2022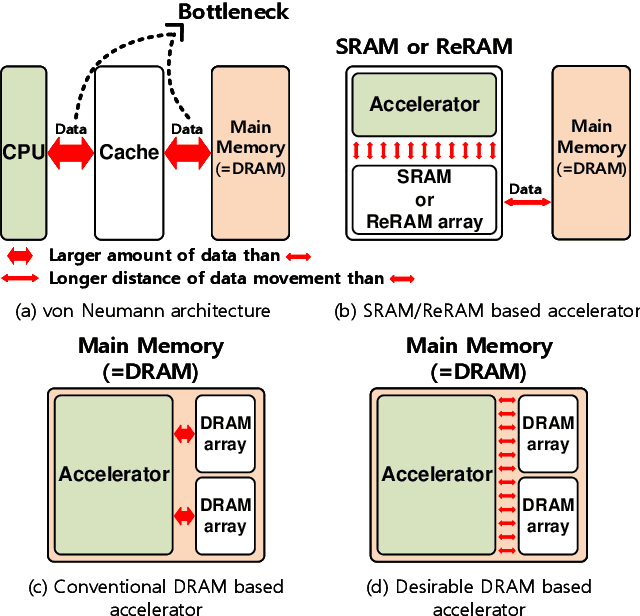
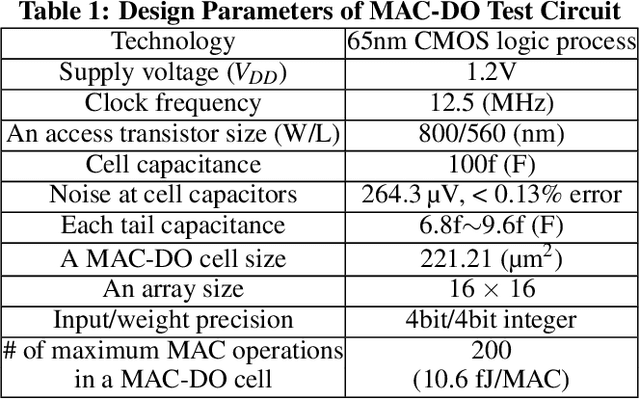
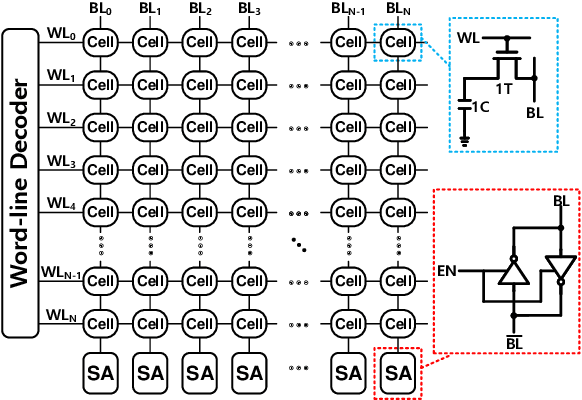
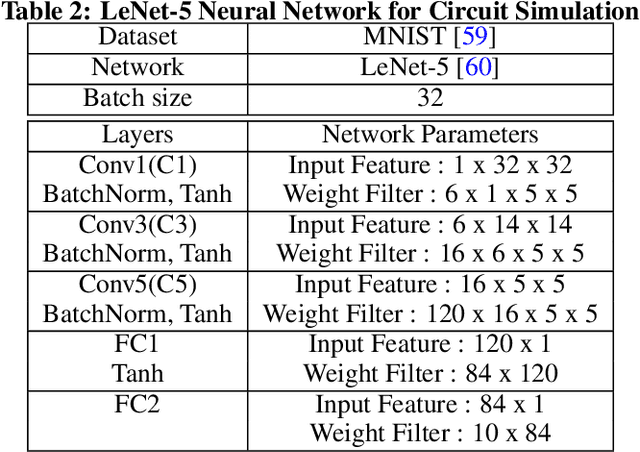
Deep neural networks (DNN) have been proved for its effectiveness in various areas such as classification problems, image processing, video segmentation, and speech recognition. The accelerator-in-memory (AiM) architectures are a promising solution to efficiently accelerate DNNs as they can avoid the memory bottleneck of the traditional von Neumann architecture. As the main memory is usually DRAM in many systems, a highly parallel multiply-accumulate (MAC) array within the DRAM can maximize the benefit of AiM by reducing both the distance and amount of data movement between the processor and the main memory. This paper presents an analog MAC array based AiM architecture named MAC-DO. In contrast with previous in-DRAM accelerators, MAC-DO makes an entire DRAM array participate in MAC computations simultaneously without idle cells, leading to higher throughput and energy efficiency. This improvement is made possible by exploiting a new analog computation method based on charge steering. In addition, MAC-DO innately supports multi-bit MACs with good linearity. MAC-DO is still compatible with current 1T1C DRAM technology without any modifications of a DRAM cell and array. A MAC-DO array can accelerate matrix multiplications based on output stationary mapping and thus supports most of the computations performed in DNNs. Our evaluation using transistor-level simulation shows that a test MAC-DO array with 16 x 16 MAC-DO cells achieves 188.7 TOPS/W, and shows 97.07% Top-1 accuracy for MNIST dataset without retraining.
BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection
May 26, 2020
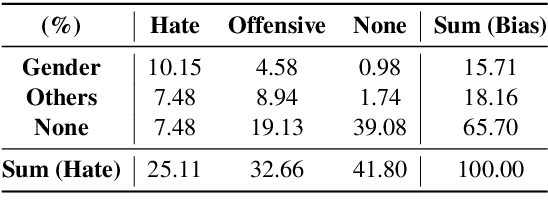
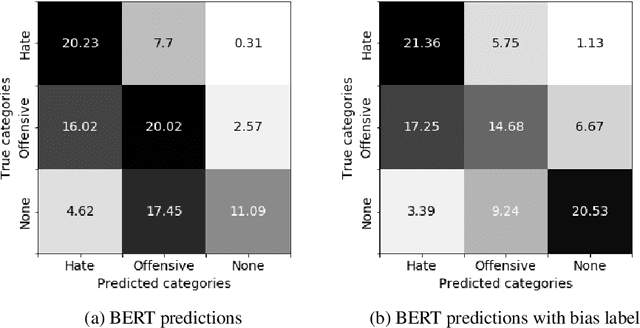
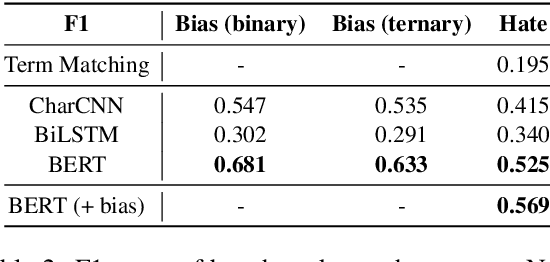
Toxic comments in online platforms are an unavoidable social issue under the cloak of anonymity. Hate speech detection has been actively done for languages such as English, German, or Italian, where manually labeled corpus has been released. In this work, we first present 9.4K manually labeled entertainment news comments for identifying Korean toxic speech, collected from a widely used online news platform in Korea. The comments are annotated regarding social bias and hate speech since both aspects are correlated. The inter-annotator agreement Krippendorff's alpha score is 0.492 and 0.496, respectively. We provide benchmarks using CharCNN, BiLSTM, and BERT, where BERT achieves the highest score on all tasks. The models generally display better performance on bias identification, since the hate speech detection is a more subjective issue. Additionally, when BERT is trained with bias label for hate speech detection, the prediction score increases, implying that bias and hate are intertwined. We make our dataset publicly available and open competitions with the corpus and benchmarks.
Extended U-Net for Speaker Verification in Noisy Environments
Jun 27, 2022



Background noise is a well-known factor that deteriorates the accuracy and reliability of speaker verification (SV) systems by blurring speech intelligibility. Various studies have used separate pretrained enhancement models as the front-end module of the SV system in noisy environments, and these methods effectively remove noises. However, the denoising process of independent enhancement models not tailored to the SV task can also distort the speaker information included in utterances. We argue that the enhancement network and speaker embedding extractor should be fully jointly trained for SV tasks under noisy conditions to alleviate this issue. Therefore, we proposed a U-Net-based integrated framework that simultaneously optimizes speaker identification and feature enhancement losses. Moreover, we analyzed the structural limitations of using U-Net directly for noise SV tasks and further proposed Extended U-Net to reduce these drawbacks. We evaluated the models on the noise-synthesized VoxCeleb1 test set and VOiCES development set recorded in various noisy scenarios. The experimental results demonstrate that the U-Net-based fully joint training framework is more effective than the baseline, and the extended U-Net exhibited state-of-the-art performance versus the recently proposed compensation systems.
Voice Conversion for Whispered Speech Synthesis
Dec 11, 2019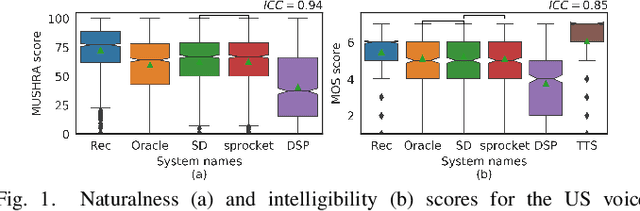
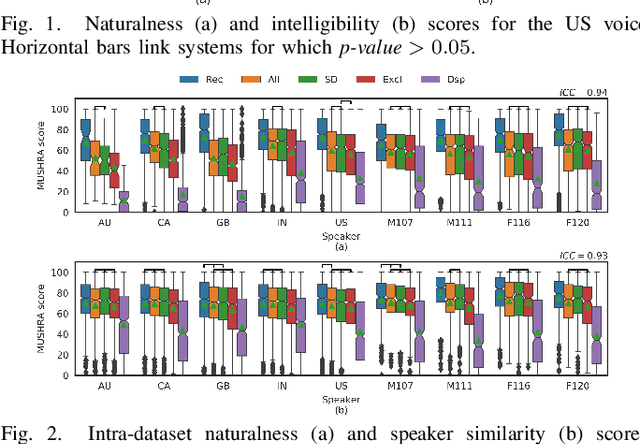
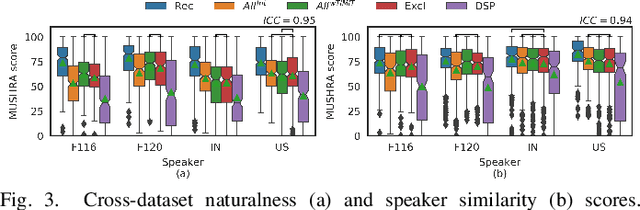
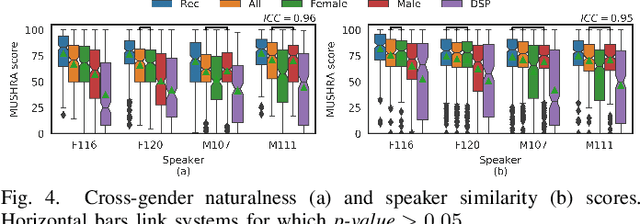
We present an approach to synthesize whisper by applying a handcrafted signal processing recipe and Voice Conversion (VC) techniques to convert normally phonated speech to whispered speech. We investigate using Gaussian Mixture Models (GMM) and Deep Neural Networks (DNN) to model the mapping between acoustic features of normal speech and those of whispered speech. We evaluate naturalness and speaker similarity of the converted whisper on an internal corpus and on the publicly available wTIMIT corpus. We show that applying VC techniques is significantly better than using rule-based signal processing methods and it achieves results that are indistinguishable from copy-synthesis of natural whisper recordings. We investigate the ability of the DNN model to generalize on unseen speakers, when trained with data from multiple speakers. We show that excluding the target speaker from the training set has little or no impact on the perceived naturalness and speaker similarity of the converted whisper. The proposed DNN method is used in the newly released Whisper Mode of Amazon Alexa.