 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech Enhancement using Self-Adaptation and Multi-Head Self-Attention
Feb 14, 2020

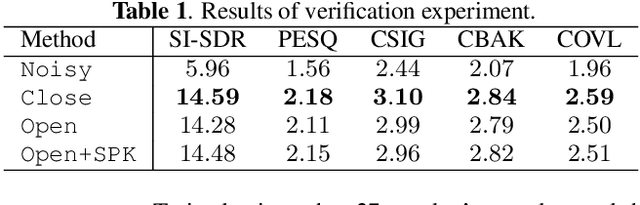
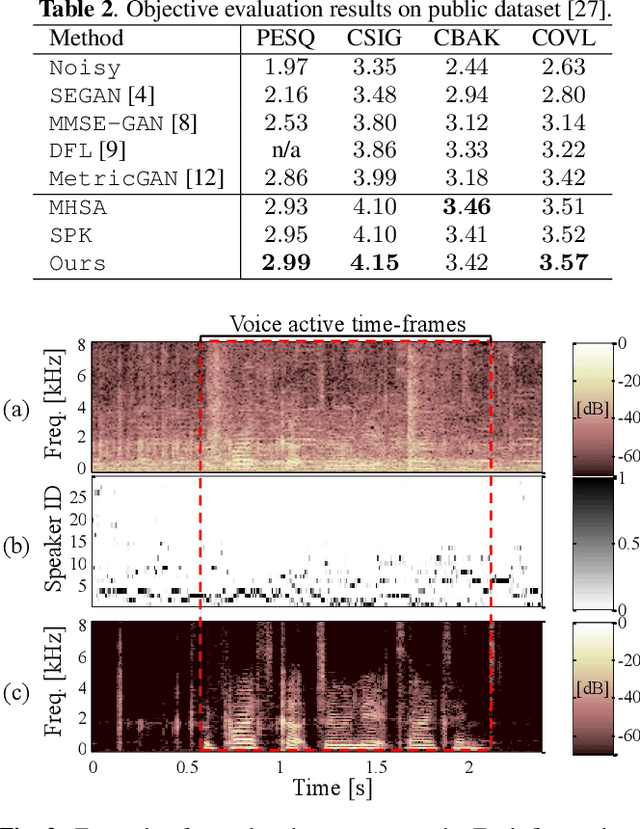
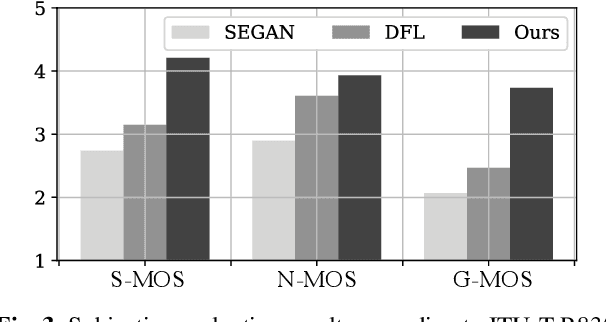
This paper investigates a self-adaptation method for speech enhancement using auxiliary speaker-aware features; we extract a speaker representation used for adaptation directly from the test utterance. Conventional studies of deep neural network (DNN)--based speech enhancement mainly focus on building a speaker independent model. Meanwhile, in speech applications including speech recognition and synthesis, it is known that model adaptation to the target speaker improves the accuracy. Our research question is whether a DNN for speech enhancement can be adopted to unknown speakers without any auxiliary guidance signal in test-phase. To achieve this, we adopt multi-task learning of speech enhancement and speaker identification, and use the output of the final hidden layer of speaker identification branch as an auxiliary feature. In addition, we use multi-head self-attention for capturing long-term dependencies in the speech and noise. Experimental results on a public dataset show that our strategy achieves the state-of-the-art performance and also outperform conventional methods in terms of subjective quality.
Internal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 06, 2021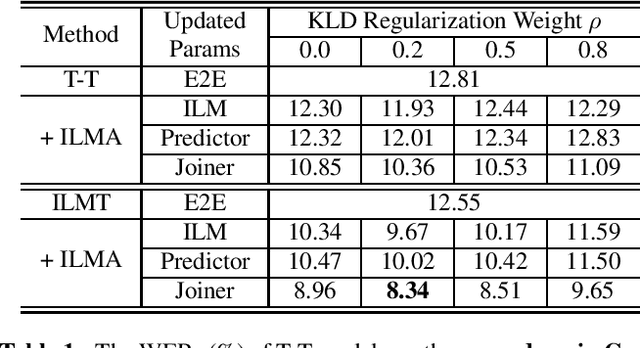
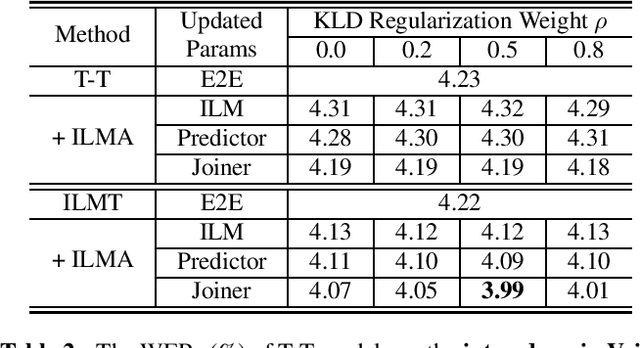
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
Knowledge Authoring with Factual English
Aug 05, 2022
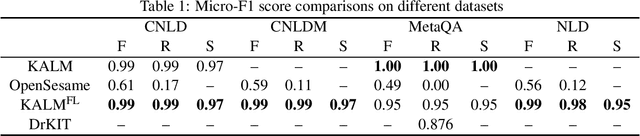

Knowledge representation and reasoning (KRR) systems represent knowledge as collections of facts and rules. Like databases, KRR systems contain information about domains of human activities like industrial enterprises, science, and business. KRRs can represent complex concepts and relations, and they can query and manipulate information in sophisticated ways. Unfortunately, the KRR technology has been hindered by the fact that specifying the requisite knowledge requires skills that most domain experts do not have, and professional knowledge engineers are hard to find. One solution could be to extract knowledge from English text, and a number of works have attempted to do so (OpenSesame, Google's Sling, etc.). Unfortunately, at present, extraction of logical facts from unrestricted natural language is still too inaccurate to be used for reasoning, while restricting the grammar of the language (so-called controlled natural language, or CNL) is hard for the users to learn and use. Nevertheless, some recent CNL-based approaches, such as the Knowledge Authoring Logic Machine (KALM), have shown to have very high accuracy compared to others, and a natural question is to what extent the CNL restrictions can be lifted. In this paper, we address this issue by transplanting the KALM framework to a neural natural language parser, mStanza. Here we limit our attention to authoring facts and queries and therefore our focus is what we call factual English statements. Authoring other types of knowledge, such as rules, will be considered in our followup work. As it turns out, neural network based parsers have problems of their own and the mistakes they make range from part-of-speech tagging to lemmatization to dependency errors. We present a number of techniques for combating these problems and test the new system, KALMFL (i.e., KALM for factual language), on a number of benchmarks, which show KALMFL achieves correctness in excess of 95%.
* In Proceedings ICLP 2022, arXiv:2208.02685
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
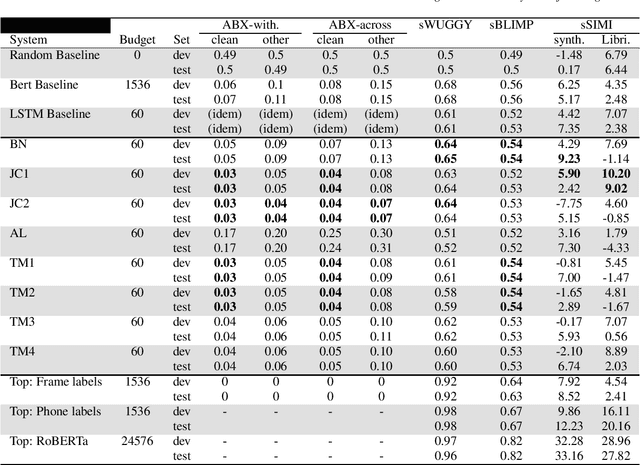
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
Nov 06, 2020
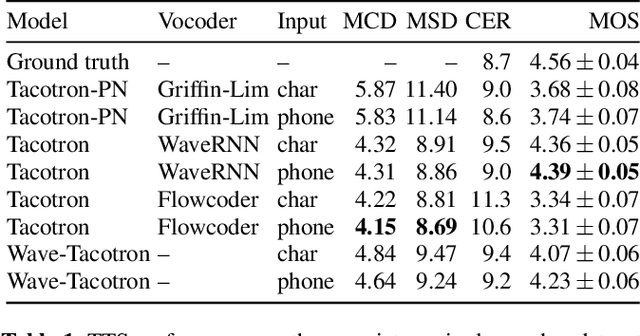
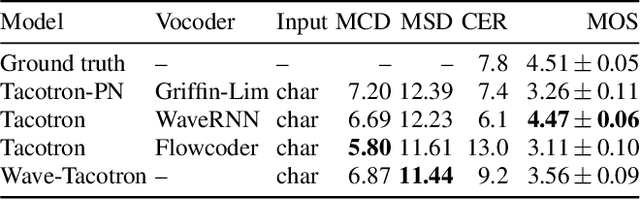
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.
Towards Natural Bilingual and Code-Switched Speech Synthesis Based on Mix of Monolingual Recordings and Cross-Lingual Voice Conversion
Oct 16, 2020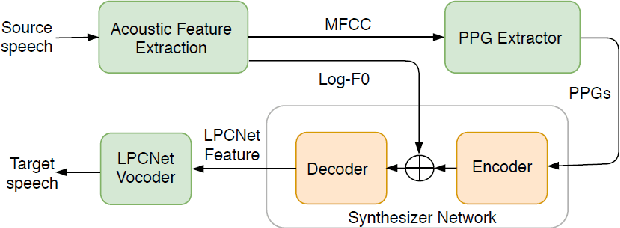

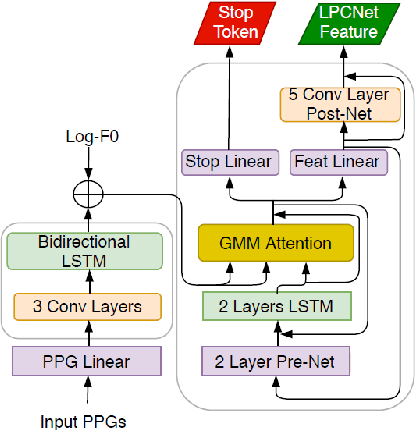
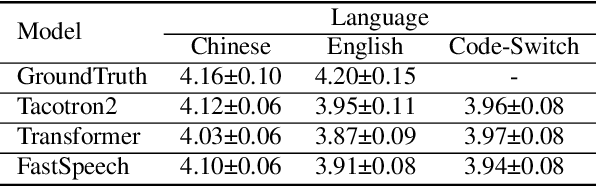
Recent state-of-the-art neural text-to-speech (TTS) synthesis models have dramatically improved intelligibility and naturalness of generated speech from text. However, building a good bilingual or code-switched TTS for a particular voice is still a challenge. The main reason is that it is not easy to obtain a bilingual corpus from a speaker who achieves native-level fluency in both languages. In this paper, we explore the use of Mandarin speech recordings from a Mandarin speaker, and English speech recordings from another English speaker to build high-quality bilingual and code-switched TTS for both speakers. A Tacotron2-based cross-lingual voice conversion system is employed to generate the Mandarin speaker's English speech and the English speaker's Mandarin speech, which show good naturalness and speaker similarity. The obtained bilingual data are then augmented with code-switched utterances synthesized using a Transformer model. With these data, three neural TTS models -- Tacotron2, Transformer and FastSpeech are applied for building bilingual and code-switched TTS. Subjective evaluation results show that all the three systems can produce (near-)native-level speech in both languages for each of the speaker.
Quadrupedal Robotic Guide Dog with Vocal Human-Robot Interaction
Nov 25, 2021
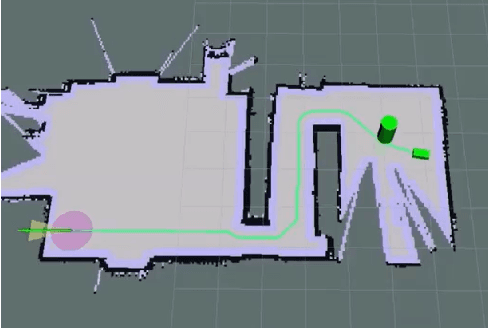
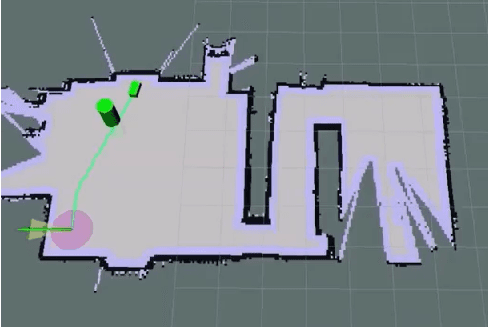
Guide dogs play a critical role in the lives of many, however training them is a time- and labor-intensive process. We are developing a method to allow an autonomous robot to physically guide humans using direct human-robot communication. The proposed algorithm will be deployed on a Unitree A1 quadrupedal robot and will autonomously navigate the person to their destination while communicating with the person using a speech interface compatible with the robot. This speech interface utilizes cloud based services such as Amazon Polly and Google Cloud to serve as the text-to-speech and speech-to-text engines.
Hierarchical Attention Network for Evaluating Therapist Empathy in Counseling Session
Mar 31, 2022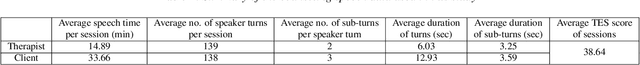
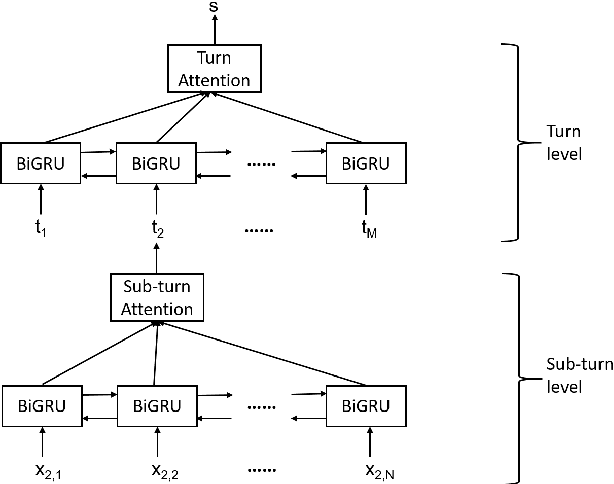
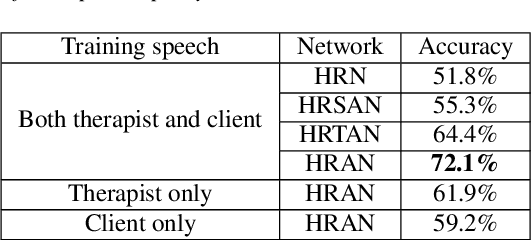
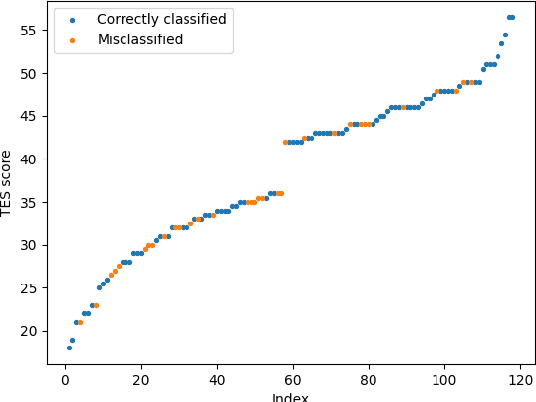
Counseling typically takes the form of spoken conversation between a therapist and a client. The empathy level expressed by the therapist is considered to be an essential quality factor of counseling outcome. This paper proposes a hierarchical recurrent network combined with two-level attention mechanisms to determine the therapist's empathy level solely from the acoustic features of conversational speech in a counseling session. The experimental results show that the proposed model can achieve an accuracy of 72.1% in classifying the therapist's empathy level as being "high" or "low". It is found that the speech from both the therapist and the client are contributing to predicting the empathy level that is subjectively rated by an expert observer. By analyzing speaker turns assigned with high attention weights, it is observed that 2 to 6 consecutive turns should be considered together to provide useful clues for detecting empathy, and the observer tends to take the whole session into consideration when rating the therapist empathy, instead of relying on a few specific speaker turns.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022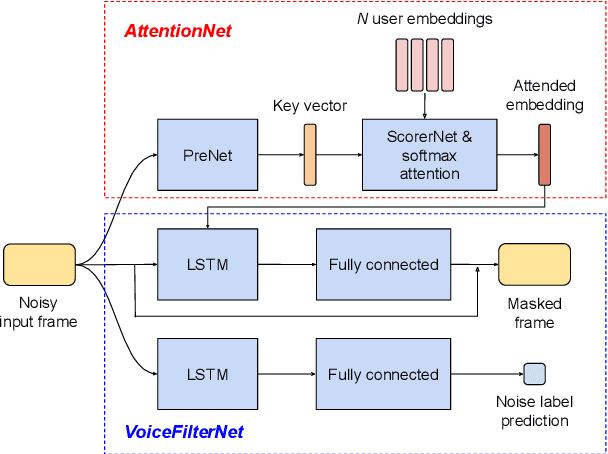
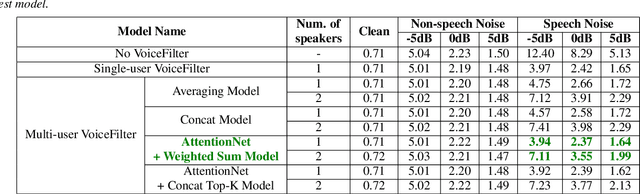
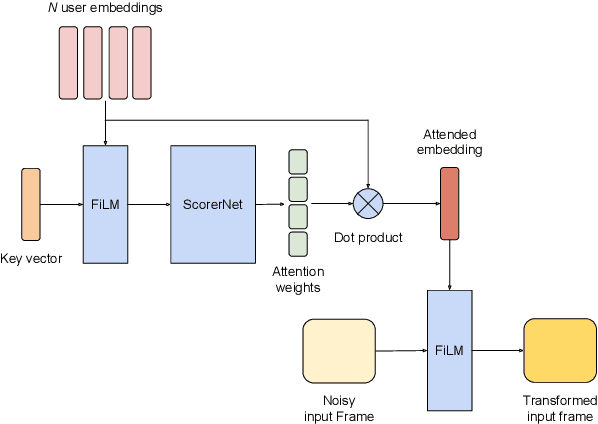
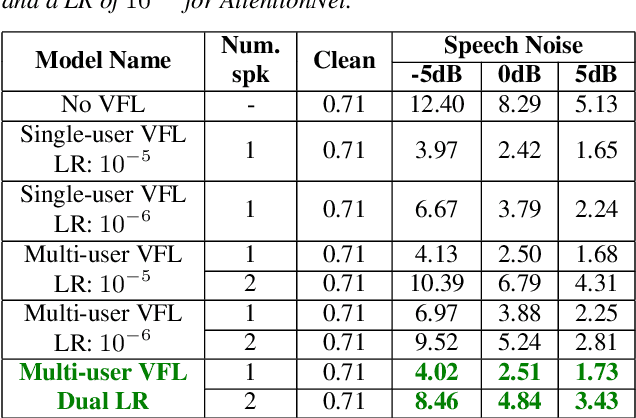
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022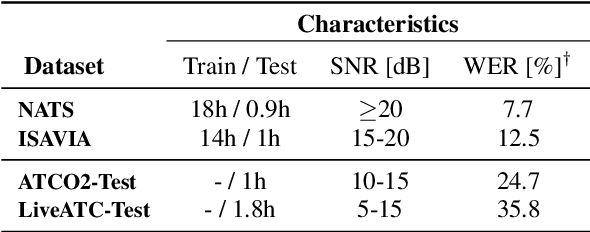
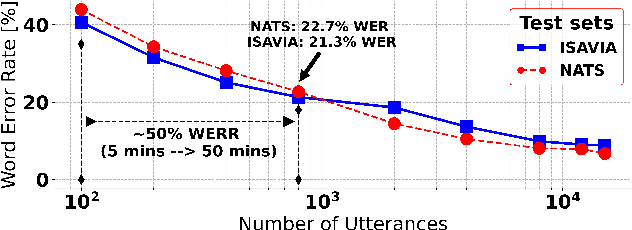
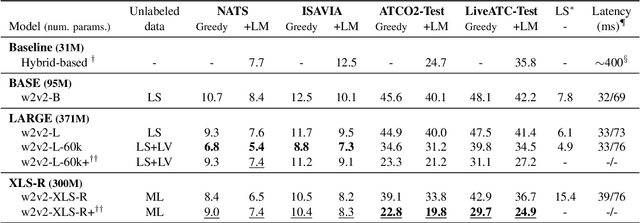
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.