 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Mar 29, 2022
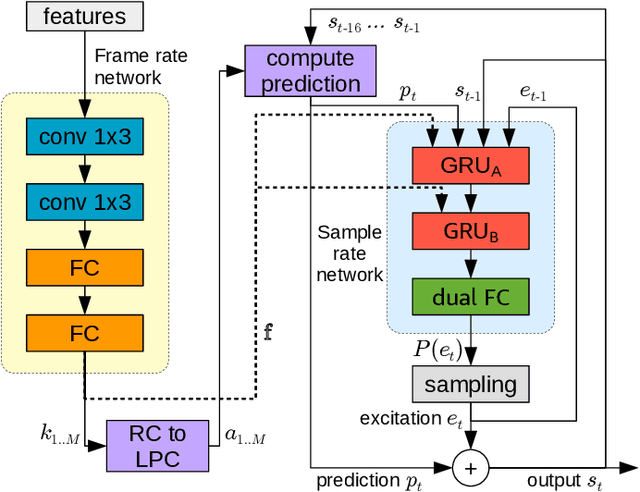
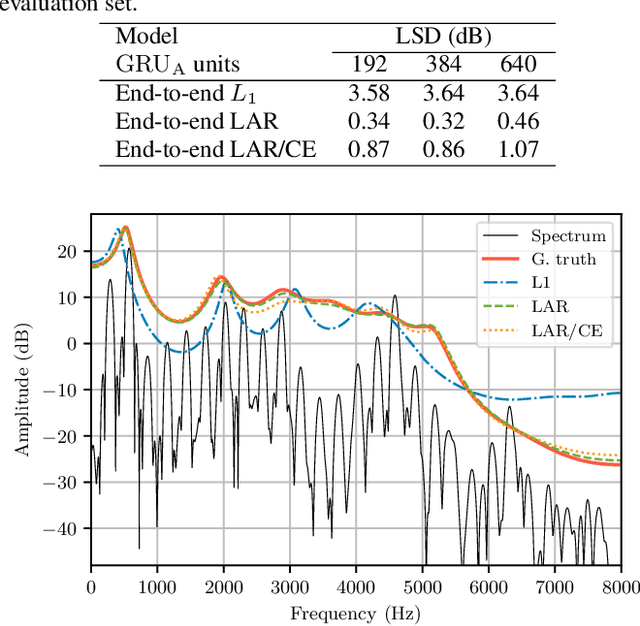
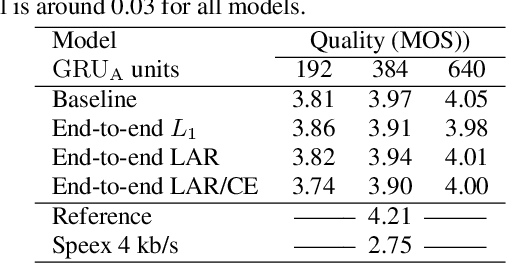
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction (LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients from the input features in the frame rate network. Results show that the proposed end-to-end approach equals or exceeds the quality of the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
A Sparsity-promoting Dictionary Model for Variational Autoencoders
Mar 29, 2022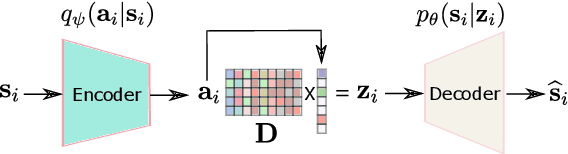
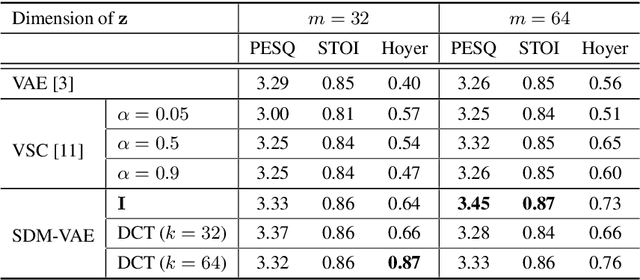
Structuring the latent space in probabilistic deep generative models, e.g., variational autoencoders (VAEs), is important to yield more expressive models and interpretable representations, and to avoid overfitting. One way to achieve this objective is to impose a sparsity constraint on the latent variables, e.g., via a Laplace prior. However, such approaches usually complicate the training phase, and they sacrifice the reconstruction quality to promote sparsity. In this paper, we propose a simple yet effective methodology to structure the latent space via a sparsity-promoting dictionary model, which assumes that each latent code can be written as a sparse linear combination of a dictionary's columns. In particular, we leverage a computationally efficient and tuning-free method, which relies on a zero-mean Gaussian latent prior with learnable variances. We derive a variational inference scheme to train the model. Experiments on speech generative modeling demonstrate the advantage of the proposed approach over competing techniques, since it promotes sparsity while not deteriorating the output speech quality.
Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS
Jun 18, 2021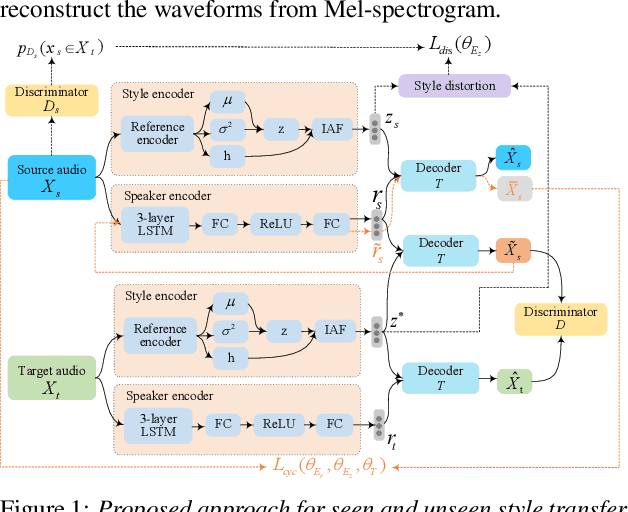
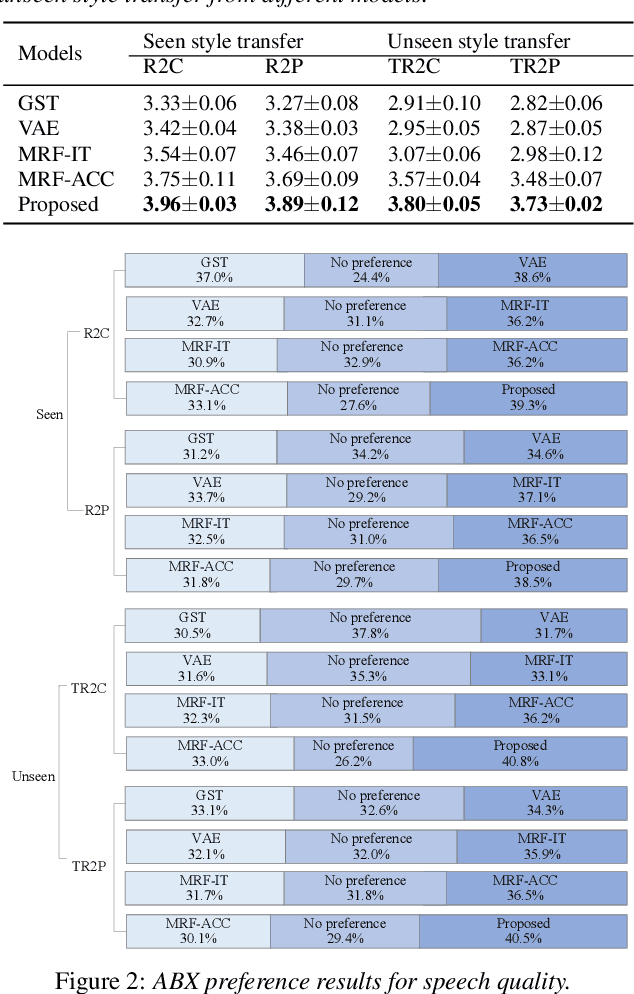
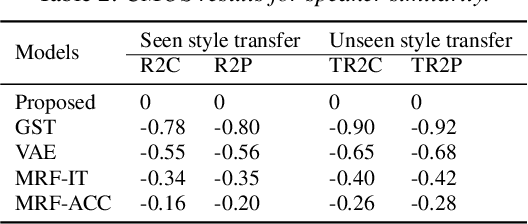

End-to-end neural TTS training has shown improved performance in speech style transfer. However, the improvement is still limited by the training data in both target styles and speakers. Inadequate style transfer performance occurs when the trained TTS tries to transfer the speech to a target style from a new speaker with an unknown, arbitrary style. In this paper, we propose a new approach to style transfer for both seen and unseen styles, with disjoint, multi-style datasets, i.e., datasets of different styles are recorded, each individual style is by one speaker with multiple utterances. To encode the style information, we adopt an inverse autoregressive flow (IAF) structure to improve the variational inference. The whole system is optimized to minimize a weighed sum of four different loss functions: 1) a reconstruction loss to measure the distortions in both source and target reconstructions; 2) an adversarial loss to "fool" a well-trained discriminator; 3) a style distortion loss to measure the expected style loss after the transfer; 4) a cycle consistency loss to preserve the speaker identity of the source after the transfer. Experiments demonstrate, both objectively and subjectively, the effectiveness of the proposed approach for seen and unseen style transfer tasks. The performance of the new approach is better and more robust than those of four baseline systems of the prior art.
The USYD-JD Speech Translation System for IWSLT 2021
Jul 24, 2021


This paper describes the University of Sydney& JD's joint submission of the IWSLT 2021 low resource speech translation task. We participated in the Swahili-English direction and got the best scareBLEU (25.3) score among all the participants. Our constrained system is based on a pipeline framework, i.e. ASR and NMT. We trained our models with the officially provided ASR and MT datasets. The ASR system is based on the open-sourced tool Kaldi and this work mainly explores how to make the most of the NMT models. To reduce the punctuation errors generated by the ASR model, we employ our previous work SlotRefine to train a punctuation correction model. To achieve better translation performance, we explored the most recent effective strategies, including back translation, knowledge distillation, multi-feature reranking and transductive finetuning. For model structure, we tried auto-regressive and non-autoregressive models, respectively. In addition, we proposed two novel pre-train approaches, i.e. \textit{de-noising training} and \textit{bidirectional training} to fully exploit the data. Extensive experiments show that adding the above techniques consistently improves the BLEU scores, and the final submission system outperforms the baseline (Transformer ensemble model trained with the original parallel data) by approximately 10.8 BLEU score, achieving the SOTA performance.
What Do We See in Them? Identifying Dimensions of Partner Models for Speech Interfaces Using a Psycholexical Approach
Feb 03, 2021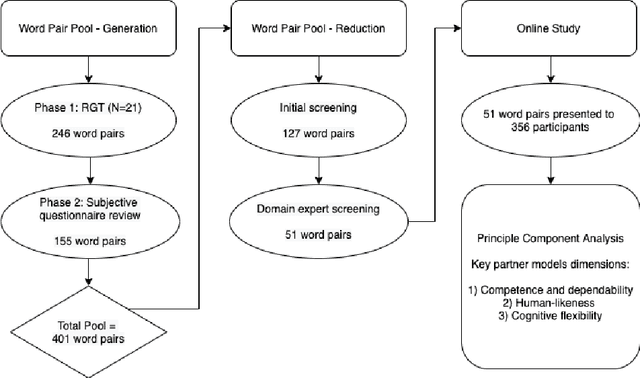

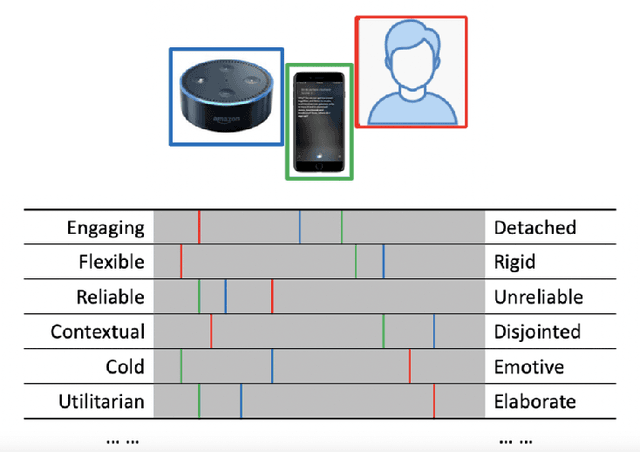

Perceptions of system competence and communicative ability, termed partner models, play a significant role in speech interface interaction. Yet we do not know what the core dimensions of this concept are. Taking a psycholexical approach, our paper is the first to identify the key dimensions that define partner models in speech agent interaction. Through a repertory grid study (N=21), a review of key subjective questionnaires, an expert review of resulting word pairs and an online study of 356 user of speech interfaces, we identify three key dimensions that make up a users' partner model: 1) perceptions toward competence and capability; 2) assessment of human-likeness; and 3) a system's perceived cognitive flexibility. We discuss the implications for partner modelling as a concept, emphasising the importance of salience and the dynamic nature of these perceptions.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021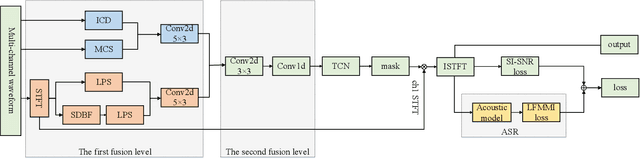
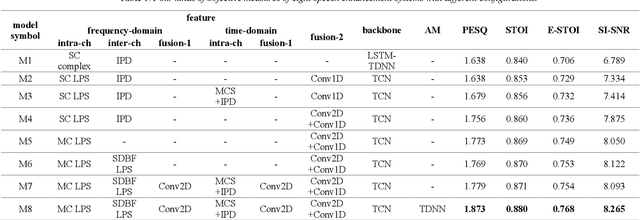
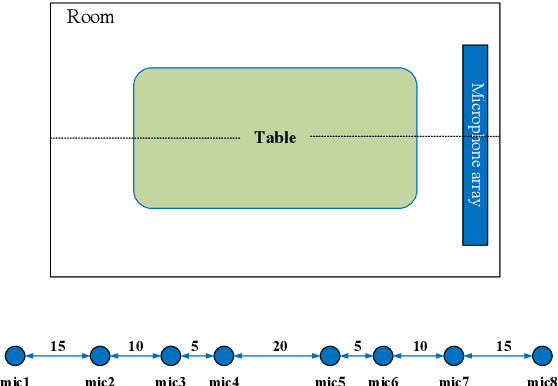

We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.
Internal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 14, 2021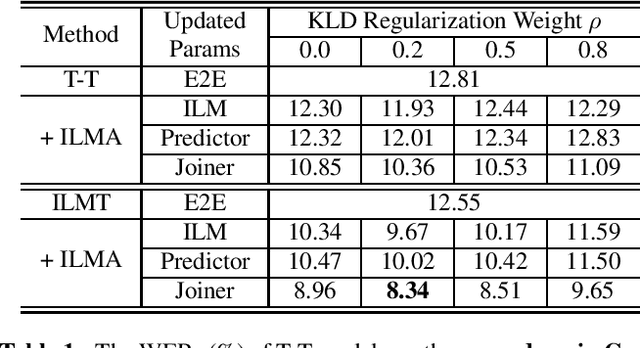
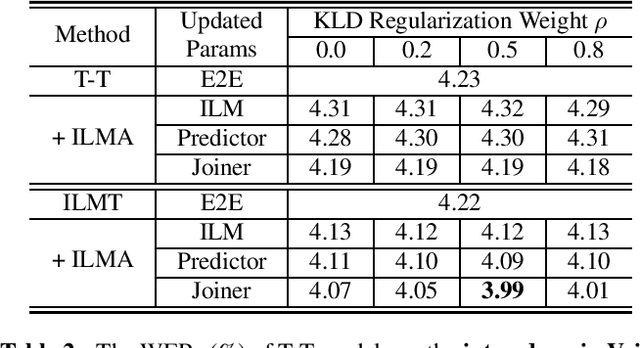
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
Hierarchical Context-Aware Transformers for Non-Autoregressive Text to Speech
Jun 29, 2021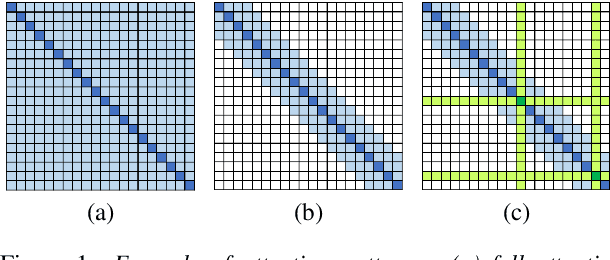
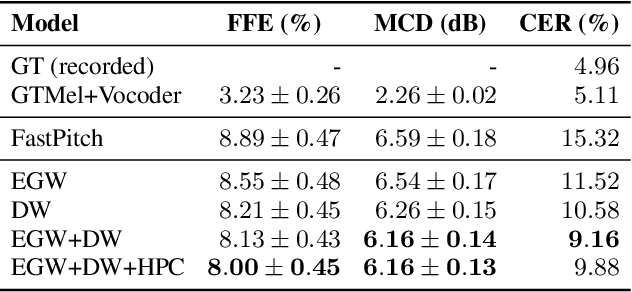
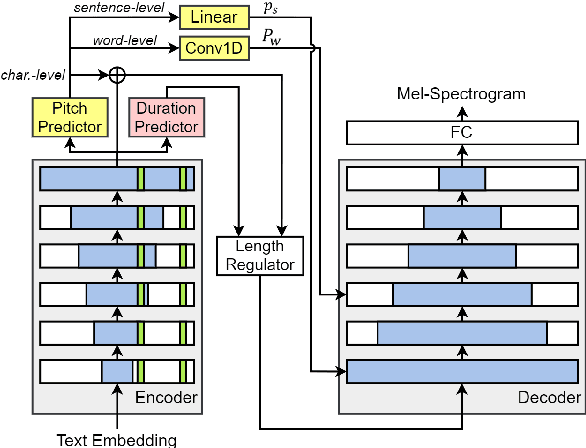
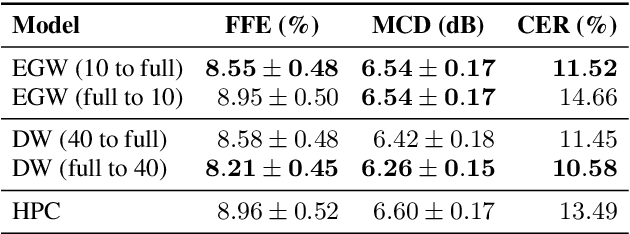
In this paper, we propose methods for improving the modeling performance of a Transformer-based non-autoregressive text-to-speech (TNA-TTS) model. Although the text encoder and audio decoder handle different types and lengths of data (i.e., text and audio), the TNA-TTS models are not designed considering these variations. Therefore, to improve the modeling performance of the TNA-TTS model we propose a hierarchical Transformer structure-based text encoder and audio decoder that are designed to accommodate the characteristics of each module. For the text encoder, we constrain each self-attention layer so the encoder focuses on a text sequence from the local to the global scope. Conversely, the audio decoder constrains its self-attention layers to focus in the reverse direction, i.e., from global to local scope. Additionally, we further improve the pitch modeling accuracy of the audio decoder by providing sentence and word-level pitch as conditions. Various objective and subjective evaluations verified that the proposed method outperformed the baseline TNA-TTS.
Perception-Aware Attack: Creating Adversarial Music via Reverse-Engineering Human Perception
Jul 26, 2022

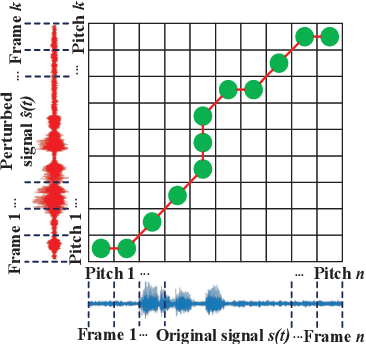

Recently, adversarial machine learning attacks have posed serious security threats against practical audio signal classification systems, including speech recognition, speaker recognition, and music copyright detection. Previous studies have mainly focused on ensuring the effectiveness of attacking an audio signal classifier via creating a small noise-like perturbation on the original signal. It is still unclear if an attacker is able to create audio signal perturbations that can be well perceived by human beings in addition to its attack effectiveness. This is particularly important for music signals as they are carefully crafted with human-enjoyable audio characteristics. In this work, we formulate the adversarial attack against music signals as a new perception-aware attack framework, which integrates human study into adversarial attack design. Specifically, we conduct a human study to quantify the human perception with respect to a change of a music signal. We invite human participants to rate their perceived deviation based on pairs of original and perturbed music signals, and reverse-engineer the human perception process by regression analysis to predict the human-perceived deviation given a perturbed signal. The perception-aware attack is then formulated as an optimization problem that finds an optimal perturbation signal to minimize the prediction of perceived deviation from the regressed human perception model. We use the perception-aware framework to design a realistic adversarial music attack against YouTube's copyright detector. Experiments show that the perception-aware attack produces adversarial music with significantly better perceptual quality than prior work.
Self supervised learning for robust voice cloning
Apr 07, 2022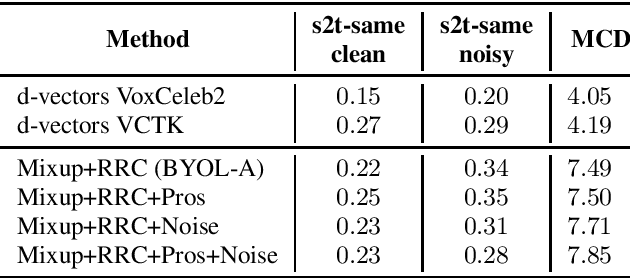
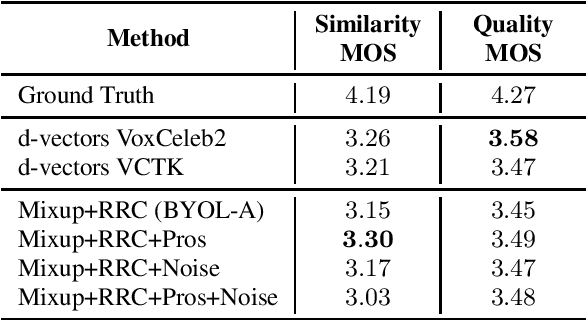
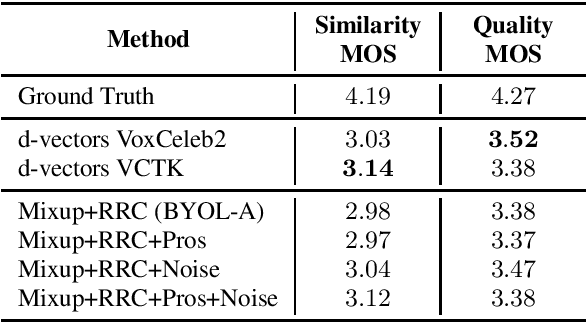
Voice cloning is a difficult task which requires robust and informative features incorporated in a high quality TTS system in order to effectively copy an unseen speaker's voice. In our work, we utilize features learned in a self-supervised framework via the Bootstrap Your Own Latent (BYOL) method, which is shown to produce high quality speech representations when specific audio augmentations are applied to the vanilla algorithm. We further extend the augmentations in the training procedure to aid the resulting features to capture the speaker identity and to make them robust to noise and acoustic conditions. The learned features are used as pre-trained utterance-level embeddings and as inputs to a Non-Attentive Tacotron based architecture, aiming to achieve multispeaker speech synthesis without utilizing additional speaker features. This method enables us to train our model in an unlabeled multispeaker dataset as well as use unseen speaker embeddings to copy a speaker's voice. Subjective and objective evaluations are used to validate the proposed model, as well as the robustness to the acoustic conditions of the target utterance.