 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Look, Listen and Recognise: Character-Aware Audio-Visual Subtitling
Jan 22, 2024
The goal of this paper is automatic character-aware subtitle generation. Given a video and a minimal amount of metadata, we propose an audio-visual method that generates a full transcript of the dialogue, with precise speech timestamps, and the character speaking identified. The key idea is to first use audio-visual cues to select a set of high-precision audio exemplars for each character, and then use these exemplars to classify all speech segments by speaker identity. Notably, the method does not require face detection or tracking. We evaluate the method over a variety of TV sitcoms, including Seinfeld, Fraiser and Scrubs. We envision this system being useful for the automatic generation of subtitles to improve the accessibility of the vast amount of videos available on modern streaming services. Project page : \url{https://www.robots.ox.ac.uk/~vgg/research/look-listen-recognise/}
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023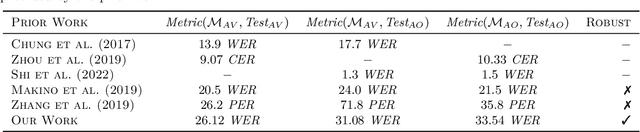
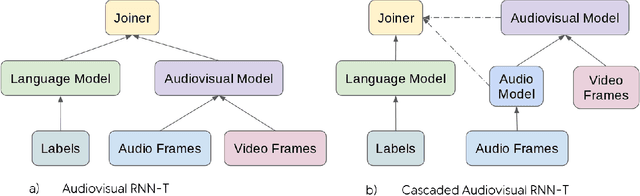
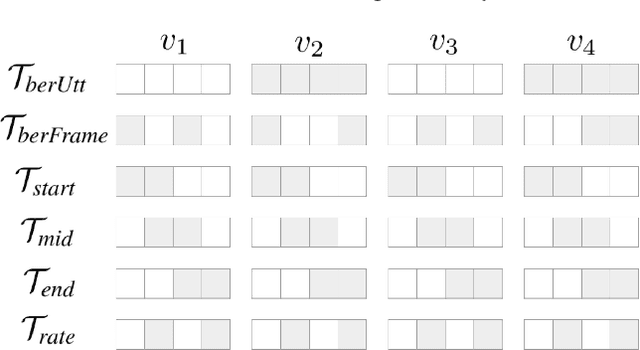
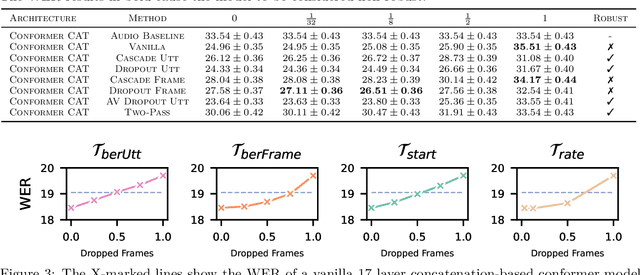
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Continuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Jan 29, 2024Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.
Acoustic Local Positioning With Encoded Emission Beacons
Feb 04, 2024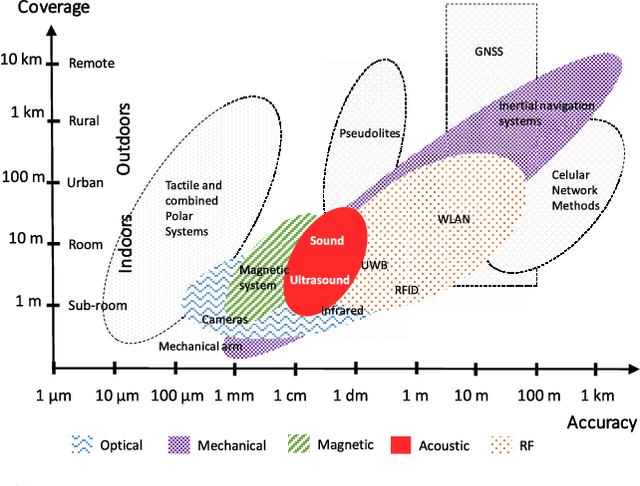
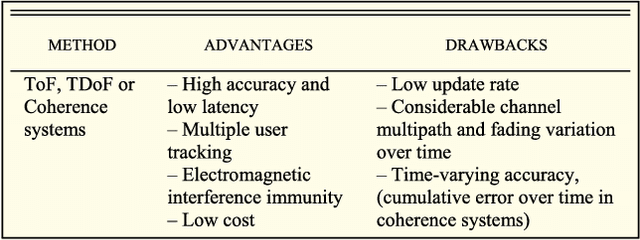
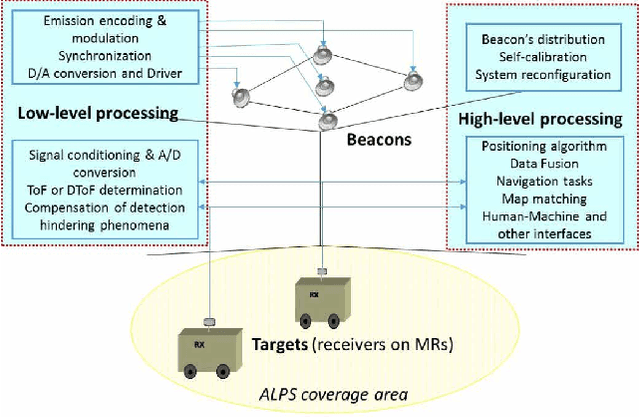
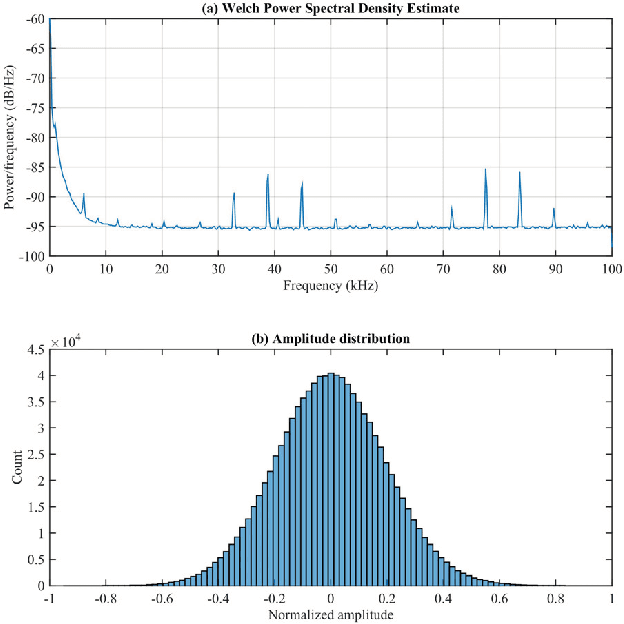
Acoustic local positioning systems (ALPSs) are an interesting alternative for indoor positioning due to certain advantages over other approaches, including their relatively high accuracy, low cost, and room-level signal propagation. Centimeter-level or fine-grained indoor positioning can be an asset for robot navigation, guiding a person to, for instance, a particular piece in a museum or to a specific product in a shop, targeted advertising, or augmented reality. In airborne system applications, acoustic positioning can be based on using opportunistic signals or sounds produced by the person or object to be located (e.g., noise from appliances or the speech from a speaker) or from encoded emission beacons (or anchors) specifically designed for this purpose. This work presents a review of the different challenges that designers of systems based on encoded emission beacons must address in order to achieve suitable performance. At low-level processing, the waveform design (coding and modulation) and the processing of the received signal are key factors to address such drawbacks as multipath propagation, multiple-access interference, nearfar effect, or Doppler shifting. With regards to high-level system design, the issues to be addressed are related to the distribution of beacons, ease of deployment, and calibration and positioning algorithms, including the possible fusion of information. Apart from theoretical discussions, this work also includes the description of an ALPS that was implemented, installed in a large area and tested for mobile robot navigation. In addition to practical interest for real applications, airborne ALPSs can also be used as an excellent platform to test complex algorithms, which can be subsequently adapted for other positioning systems, such as underwater acoustic systems or ultrawideband radiofrequency (UWB RF) systems.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
MCMChaos: Improvising Rap Music with MCMC Methods and Chaos Theory
Jan 15, 2024A novel freestyle rap software, MCMChaos 0.0.1, based on rap music transcriptions created in previous research is presented. The software has three different versions, each making use of different mathematical simulation methods: collapsed gibbs sampler and lorenz attractor simulation. As far as we know, these simulation methods have never been used in rap music generation before. The software implements Python Text-to-Speech processing (pyttxs) to convert text wrangled from the MCFlow corpus into English speech. In each version, values simulated from each respective mathematical model alter the rate of speech, volume, and (in the multiple voice case) the voice of the text-to-speech engine on a line-by-line basis. The user of the software is presented with a real-time graphical user interface (GUI) which instantaneously changes the initial values read into the mathematical simulation methods. Future research might attempt to allow for more user control and autonomy.
Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters
Feb 01, 2024Mixture of Experts (MoE) architectures have recently started burgeoning due to their ability to scale model's capacity while maintaining the computational cost affordable. Furthermore, they can be applied to both Transformers and State Space Models, the current state-of-the-art models in numerous fields. While MoE has been mostly investigated for the pre-training stage, its use in parameter-efficient transfer learning settings is under-explored. To narrow this gap, this paper attempts to demystify the use of MoE for parameter-efficient fine-tuning of Audio Spectrogram Transformers to audio and speech downstream tasks. Specifically, we propose Soft Mixture of Adapters (Soft-MoA). It exploits adapters as the experts and, leveraging the recent Soft MoE method, it relies on a soft assignment between the input tokens and experts to keep the computational time limited. Extensive experiments across 4 benchmarks demonstrate that Soft-MoA outperforms the single adapter method and performs on par with the dense MoA counterpart. We finally present ablation studies on key elements of Soft-MoA, showing for example that Soft-MoA achieves better scaling with more experts, as well as ensuring that all experts contribute to the computation of the output tokens, thus dispensing with the expert imbalance issue.
Efficient Training Spiking Neural Networks with Parallel Spiking Unit
Feb 01, 2024Efficient parallel computing has become a pivotal element in advancing artificial intelligence. Yet, the deployment of Spiking Neural Networks (SNNs) in this domain is hampered by their inherent sequential computational dependency. This constraint arises from the need for each time step's processing to rely on the preceding step's outcomes, significantly impeding the adaptability of SNN models to massively parallel computing environments. Addressing this challenge, our paper introduces the innovative Parallel Spiking Unit (PSU) and its two derivatives, the Input-aware PSU (IPSU) and Reset-aware PSU (RPSU). These variants skillfully decouple the leaky integration and firing mechanisms in spiking neurons while probabilistically managing the reset process. By preserving the fundamental computational attributes of the spiking neuron model, our approach enables the concurrent computation of all membrane potential instances within the SNN, facilitating parallel spike output generation and substantially enhancing computational efficiency. Comprehensive testing across various datasets, including static and sequential images, Dynamic Vision Sensor (DVS) data, and speech datasets, demonstrates that the PSU and its variants not only significantly boost performance and simulation speed but also augment the energy efficiency of SNNs through enhanced sparsity in neural activity. These advancements underscore the potential of our method in revolutionizing SNN deployment for high-performance parallel computing applications.
PAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.