 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MultiQT: Multimodal Learning for Real-Time Question Tracking in Speech
May 12, 2020
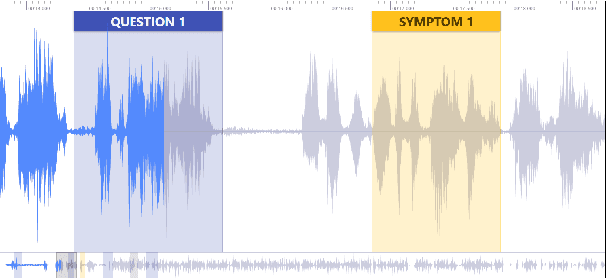

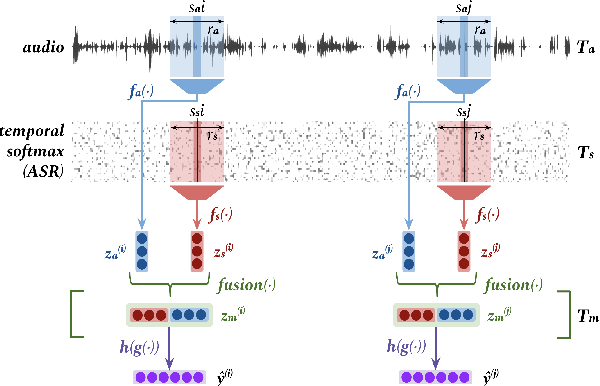

We address a challenging and practical task of labeling questions in speech in real time during telephone calls to emergency medical services in English, which embeds within a broader decision support system for emergency call-takers. We propose a novel multimodal approach to real-time sequence labeling in speech. Our model treats speech and its own textual representation as two separate modalities or views, as it jointly learns from streamed audio and its noisy transcription into text via automatic speech recognition. Our results show significant gains of jointly learning from the two modalities when compared to text or audio only, under adverse noise and limited volume of training data. The results generalize to medical symptoms detection where we observe a similar pattern of improvements with multimodal learning.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021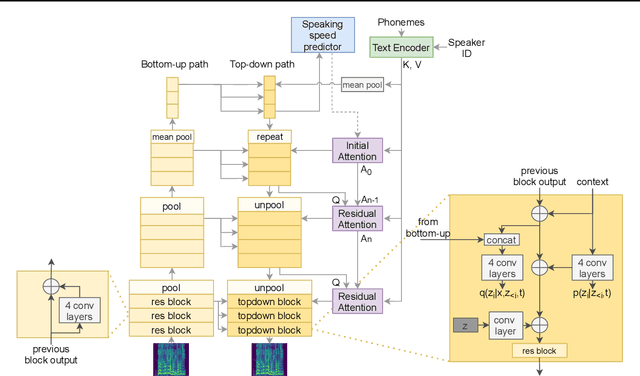
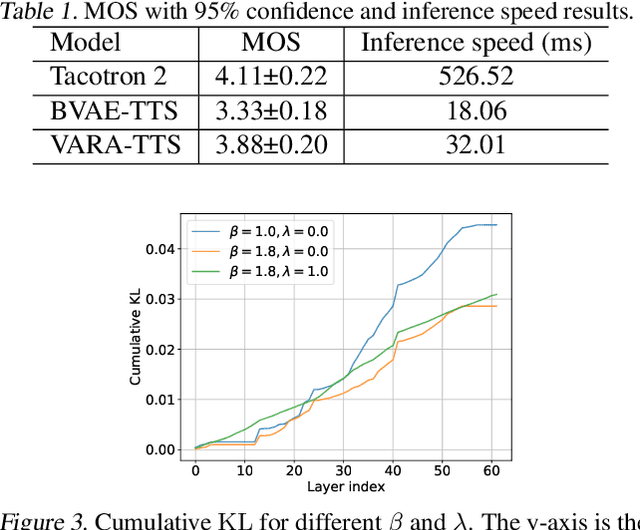

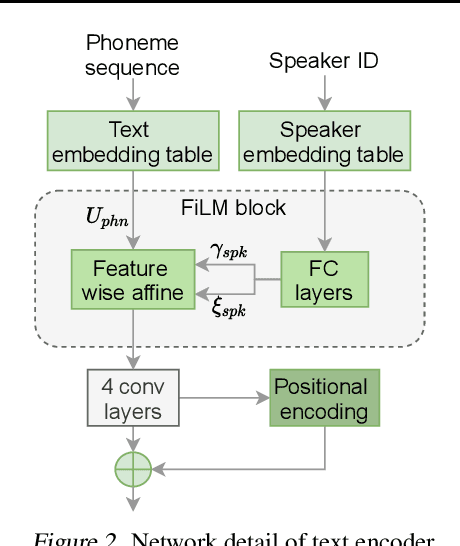
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.
Modeling Profanity and Hate Speech in Social Media with Semantic Subspaces
Jun 18, 2021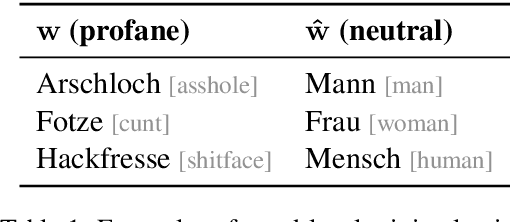
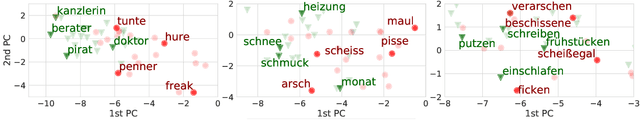

Hate speech and profanity detection suffer from data sparsity, especially for languages other than English, due to the subjective nature of the tasks and the resulting annotation incompatibility of existing corpora. In this study, we identify profane subspaces in word and sentence representations and explore their generalization capability on a variety of similar and distant target tasks in a zero-shot setting. This is done monolingually (German) and cross-lingually to closely-related (English), distantly-related (French) and non-related (Arabic) tasks. We observe that, on both similar and distant target tasks and across all languages, the subspace-based representations transfer more effectively than standard BERT representations in the zero-shot setting, with improvements between F1 +10.9 and F1 +42.9 over the baselines across all tested monolingual and cross-lingual scenarios.
Whither the Priors for (Vocal) Interactivity?
Mar 16, 2022
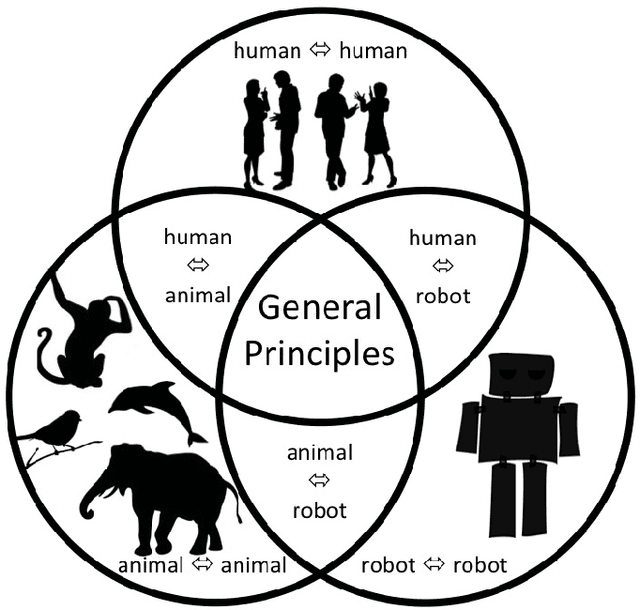
Voice-based communication is often cited as one of the most `natural' ways in which humans and robots might interact, and the recent availability of accurate automatic speech recognition and intelligible speech synthesis has enabled researchers to integrate advanced off-the-shelf spoken language technology components into their robot platforms. Despite this, the resulting interactions are anything but `natural'. It transpires that simply giving a robot a voice doesn't mean that a user will know how (or when) to talk to it, and the resulting `conversations' tend to be stilted, one-sided and short. On the surface, these difficulties might appear to be fairly trivial consequences of users' unfamiliarity with robots (and \emph{vice versa}), and that any problems would be mitigated by long-term use by the human, coupled with `deep learning' by the robot. However, it is argued here that such communication failures are indicative of a deeper malaise: a fundamental lack of basic principles -- \emph{priors} -- underpinning not only speech-based interaction in particular, but (vocal) interactivity in general. This is evidenced not only by the fact that contemporary spoken language systems already require training data sets that are orders-of-magnitude greater than that experienced by a young child, but also by the lack of design principles for creating effective communicative human-robot interaction. This short position paper identifies some of the key areas where theoretical insights might help overcome these shortfalls.
Object Localization Assistive System Based on CV and Vibrotactile Encoding
Jun 19, 2022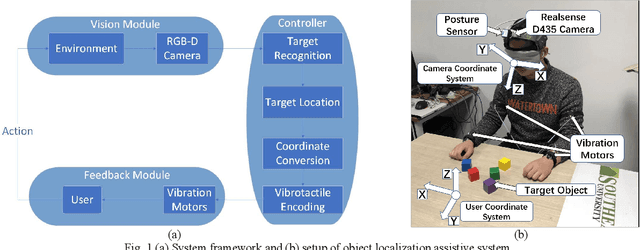
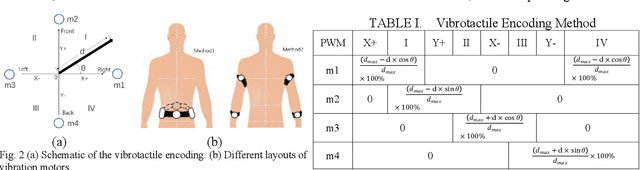
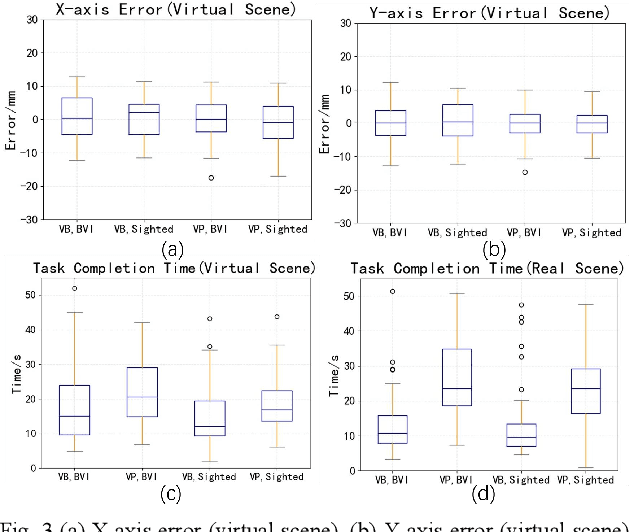
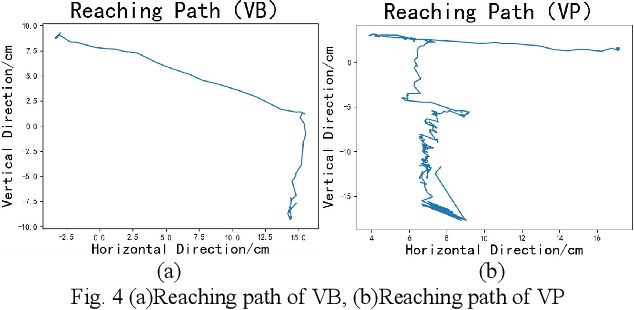
Intelligent assistive systems can navigate blind people, but most of them could only give non-intuitive cues or inefficient guidance. Based on computer vision and vibrotactile encoding, this paper presents an interactive system that provides blind people with intuitive spatial cognition. Different from the traditional auditory feedback strategy based on speech cues, this paper firstly introduces a vibration-encoded feedback method that leverages the haptic neural pathway and enables the users to interact with objects other than manipulating an assistance device. Based on this strategy, a wearable visual module based on an RGB-D camera is adopted for 3D spatial object localization, which contributes to accurate perception and quick object localization in the real environment. The experimental results on target blind individuals indicate that vibrotactile feedback reduces the task completion time by over 25% compared with the mainstream voice prompt feedback scheme. The proposed object localization system provides a more intuitive spatial navigation and comfortable wearability for blindness assistance.
Training Keyword Spotters with Limited and Synthesized Speech Data
Jan 31, 2020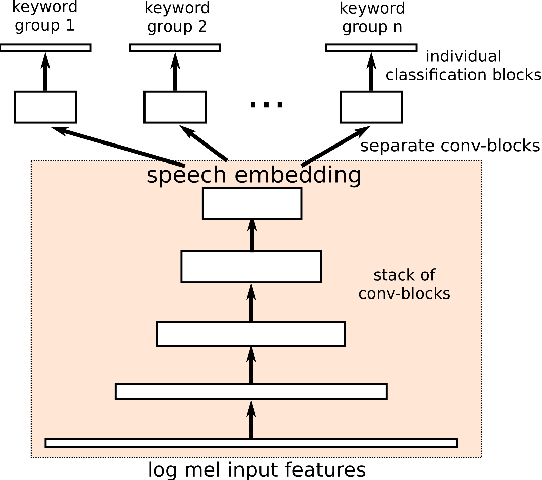
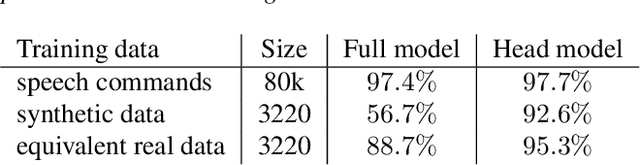
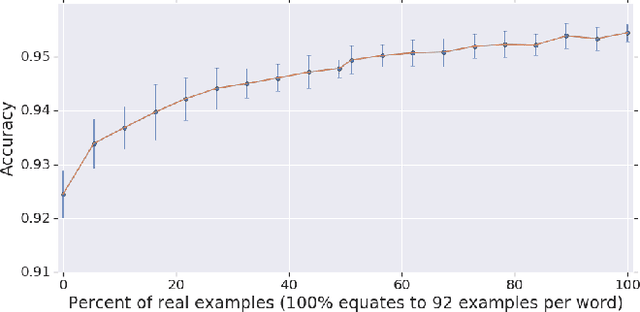
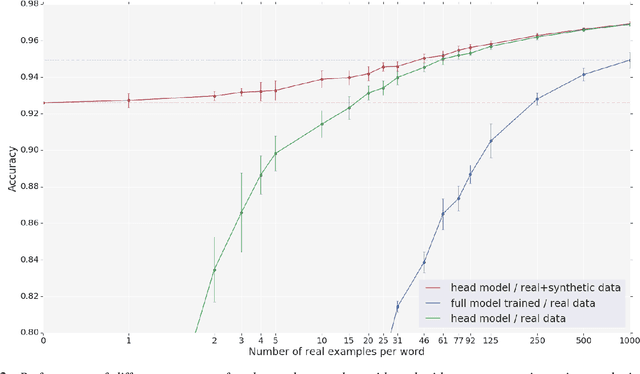
With the rise of low power speech-enabled devices, there is a growing demand to quickly produce models for recognizing arbitrary sets of keywords. As with many machine learning tasks, one of the most challenging parts in the model creation process is obtaining a sufficient amount of training data. In this paper, we explore the effectiveness of synthesized speech data in training small, spoken term detection models of around 400k parameters. Instead of training such models directly on the audio or low level features such as MFCCs, we use a pre-trained speech embedding model trained to extract useful features for keyword spotting models. Using this speech embedding, we show that a model which detects 10 keywords when trained on only synthetic speech is equivalent to a model trained on over 500 real examples. We also show that a model without our speech embeddings would need to be trained on over 4000 real examples to reach the same accuracy.
Fast Classification Learning with Neural Networks and Conceptors for Speech Recognition and Car Driving Maneuvers
Feb 10, 2021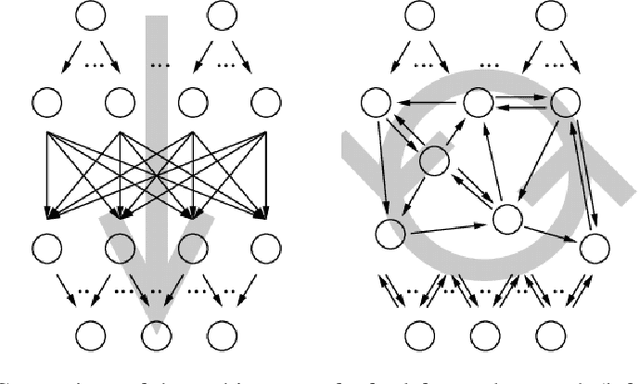
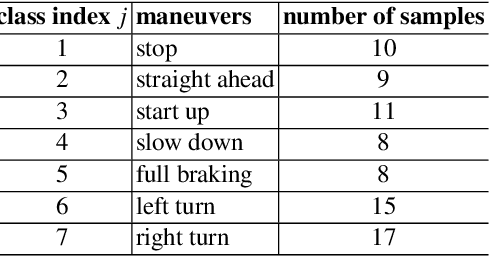
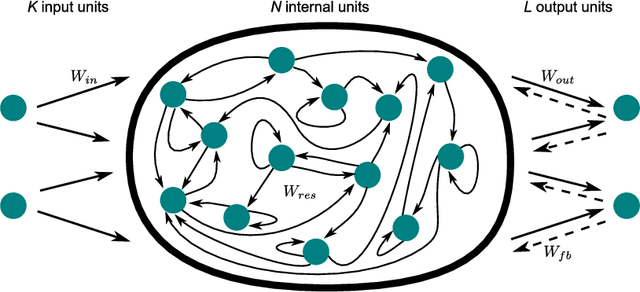
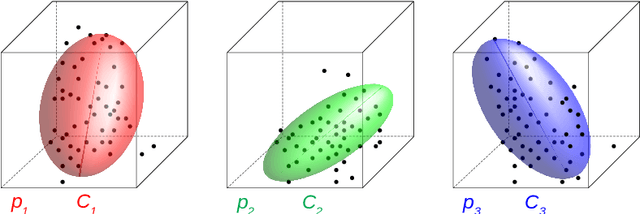
Recurrent neural networks are a powerful means in diverse applications. We show that, together with so-called conceptors, they also allow fast learning, in contrast to other deep learning methods. In addition, a relatively small number of examples suffices to train neural networks with high accuracy. We demonstrate this with two applications, namely speech recognition and detecting car driving maneuvers. We improve the state-of-the art by application-specific preparation techniques: For speech recognition, we use mel frequency cepstral coefficients leading to a compact representation of the frequency spectra, and detecting car driving maneuvers can be done without the commonly used polynomial interpolation, as our evaluation suggests.
Learning Audio Representations with MLPs
Mar 16, 2022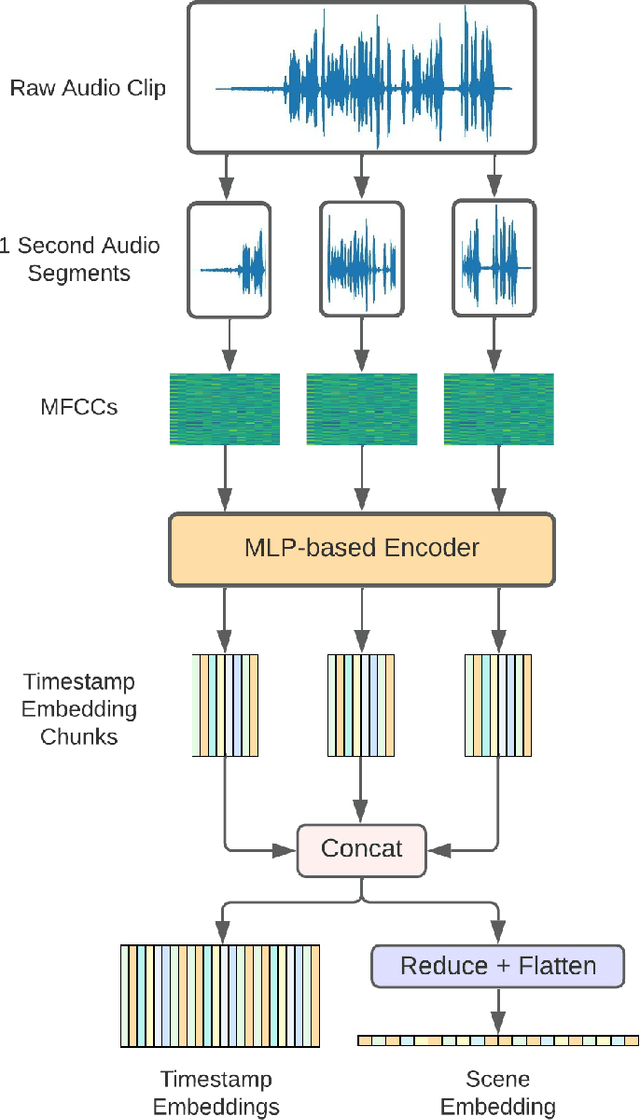
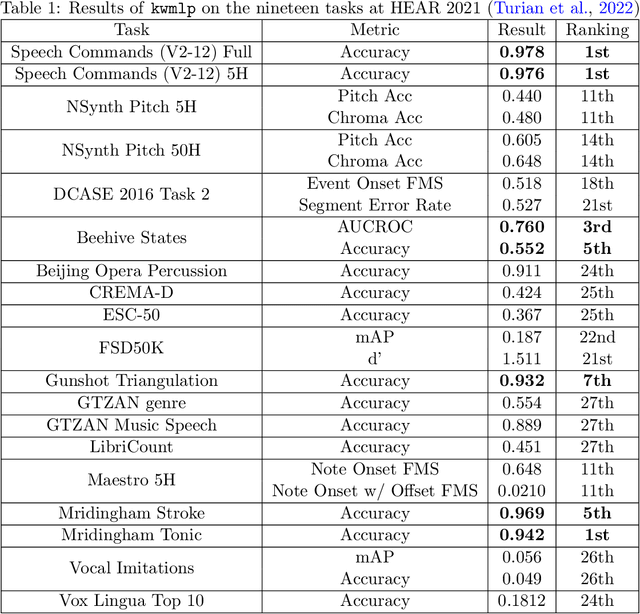
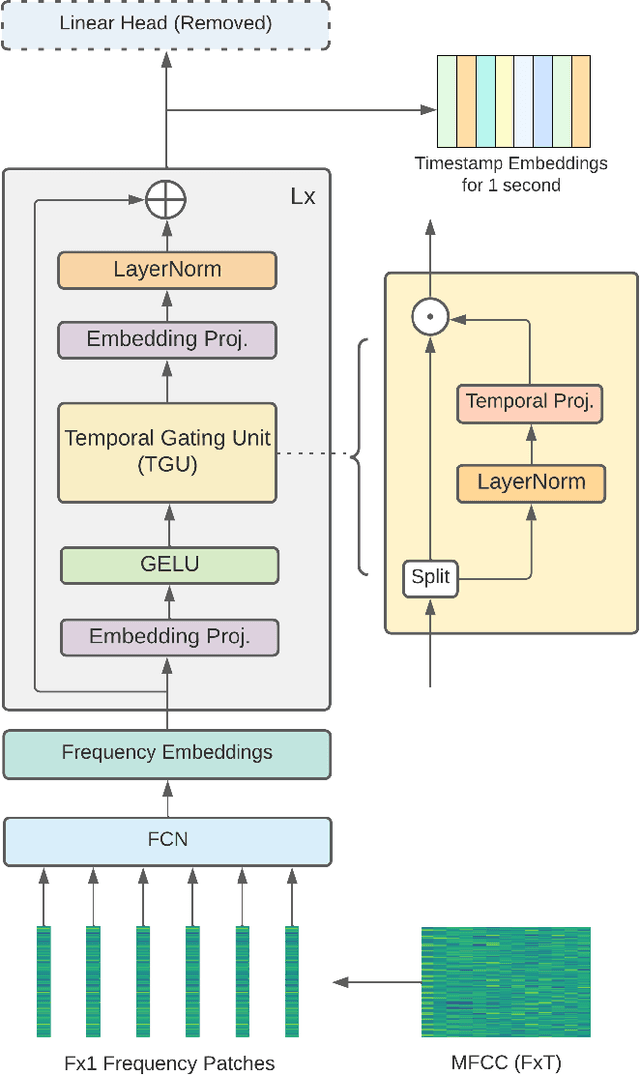
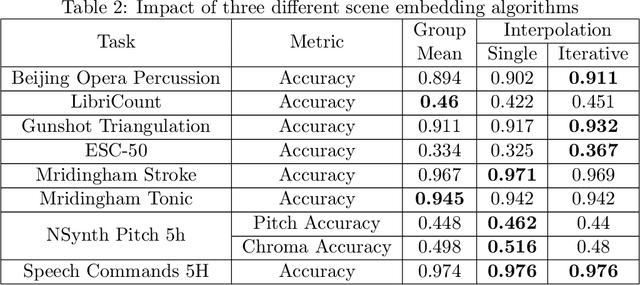
In this paper, we propose an efficient MLP-based approach for learning audio representations, namely timestamp and scene-level audio embeddings. We use an encoder consisting of sequentially stacked gated MLP blocks, which accept 2D MFCCs as inputs. In addition, we also provide a simple temporal interpolation-based algorithm for computing scene-level embeddings from timestamp embeddings. The audio representations generated by our method are evaluated across a diverse set of benchmarks at the Holistic Evaluation of Audio Representations (HEAR) challenge, hosted at the NeurIPS 2021 competition track. We achieved first place on the Speech Commands (full), Speech Commands (5 hours), and the Mridingham Tonic benchmarks. Furthermore, our approach is also the most resource-efficient among all the submitted methods, in terms of both the number of model parameters and the time required to compute embeddings.
Transformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment
May 06, 2022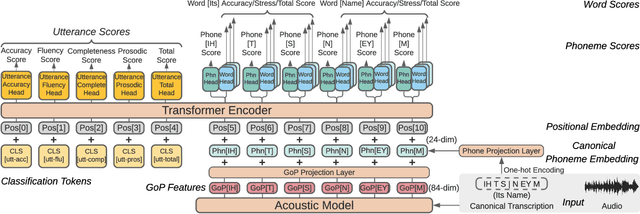
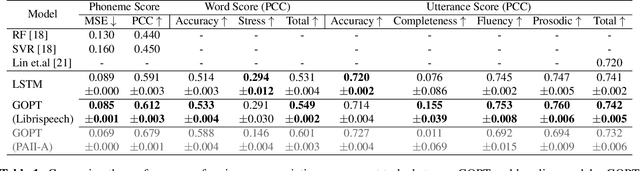
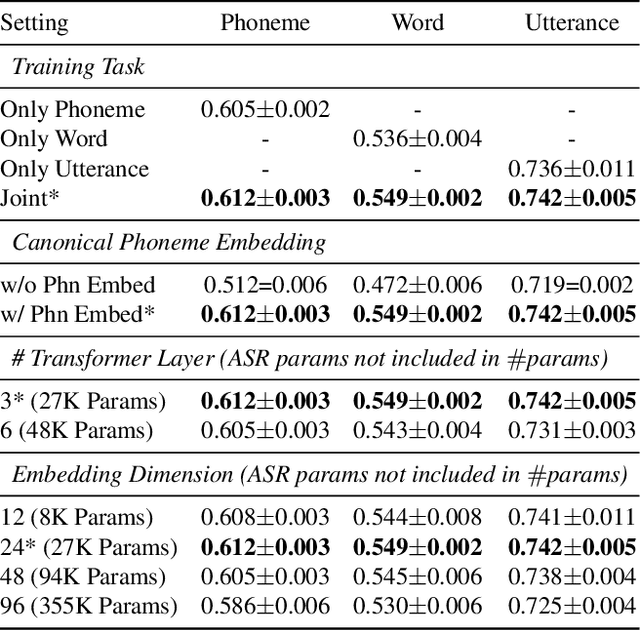

Automatic pronunciation assessment is an important technology to help self-directed language learners. While pronunciation quality has multiple aspects including accuracy, fluency, completeness, and prosody, previous efforts typically only model one aspect (e.g., accuracy) at one granularity (e.g., at the phoneme-level). In this work, we explore modeling multi-aspect pronunciation assessment at multiple granularities. Specifically, we train a Goodness Of Pronunciation feature-based Transformer (GOPT) with multi-task learning. Experiments show that GOPT achieves the best results on speechocean762 with a public automatic speech recognition (ASR) acoustic model trained on Librispeech.
Speaker-aware speech-transformer
Jan 02, 2020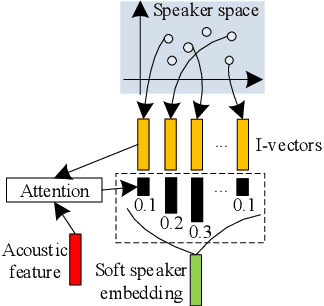
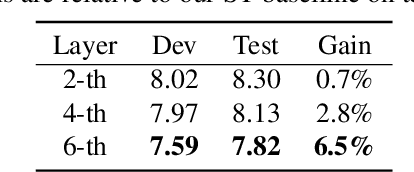
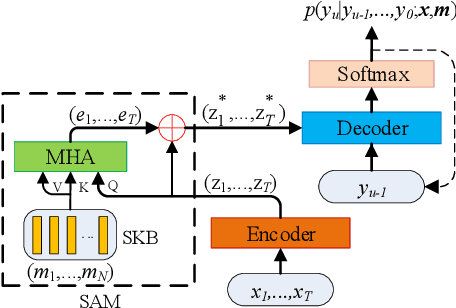
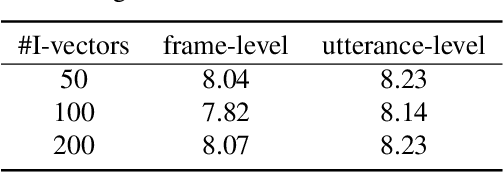
Recently, end-to-end (E2E) models become a competitive alternative to the conventional hybrid automatic speech recognition (ASR) systems. However, they still suffer from speaker mismatch in training and testing condition. In this paper, we use Speech-Transformer (ST) as the study platform to investigate speaker aware training of E2E models. We propose a model called Speaker-Aware Speech-Transformer (SAST), which is a standard ST equipped with a speaker attention module (SAM). The SAM has a static speaker knowledge block (SKB) that is made of i-vectors. At each time step, the encoder output attends to the i-vectors in the block, and generates a weighted combined speaker embedding vector, which helps the model to normalize the speaker variations. The SAST model trained in this way becomes independent of specific training speakers and thus generalizes better to unseen testing speakers. We investigate different factors of SAM. Experimental results on the AISHELL-1 task show that SAST achieves a relative 6.5% CER reduction (CERR) over the speaker-independent (SI) baseline. Moreover, we demonstrate that SAST still works quite well even if the i-vectors in SKB all come from a different data source other than the acoustic training set.