 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020
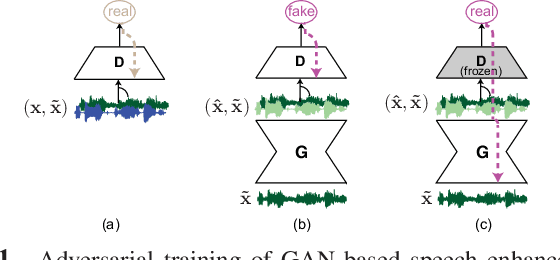
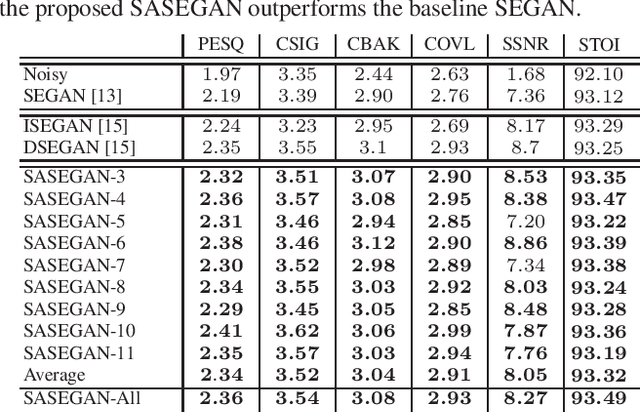
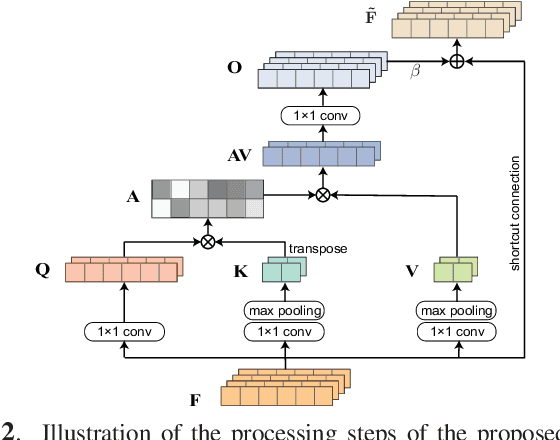
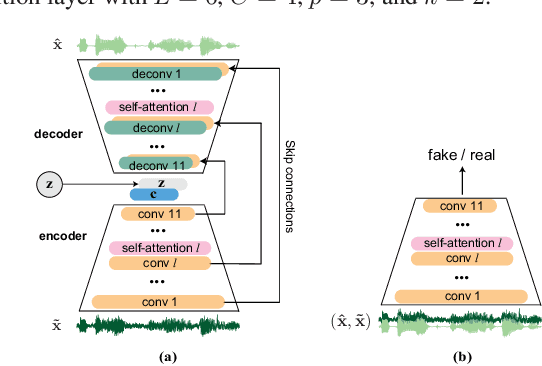
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.
Learning Audio Representations with MLPs
Mar 16, 2022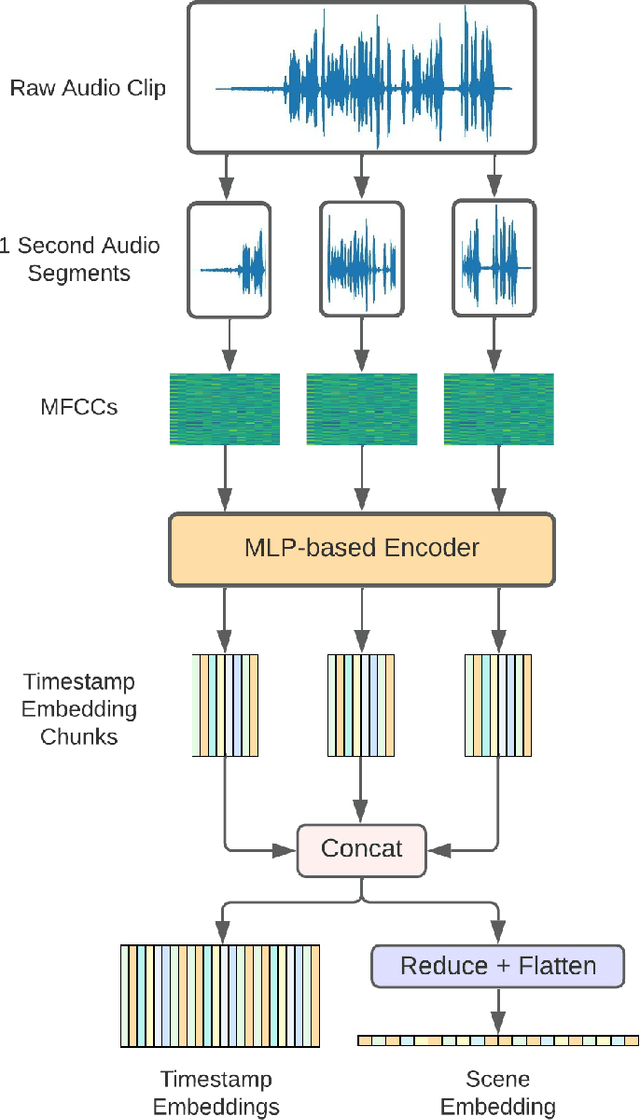
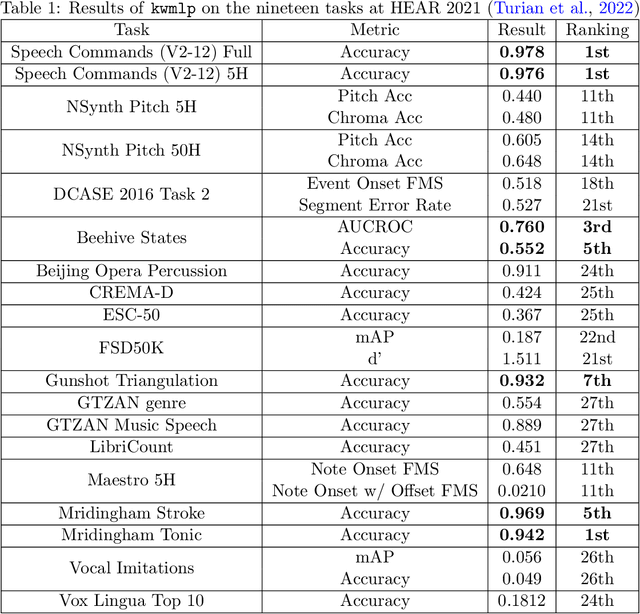
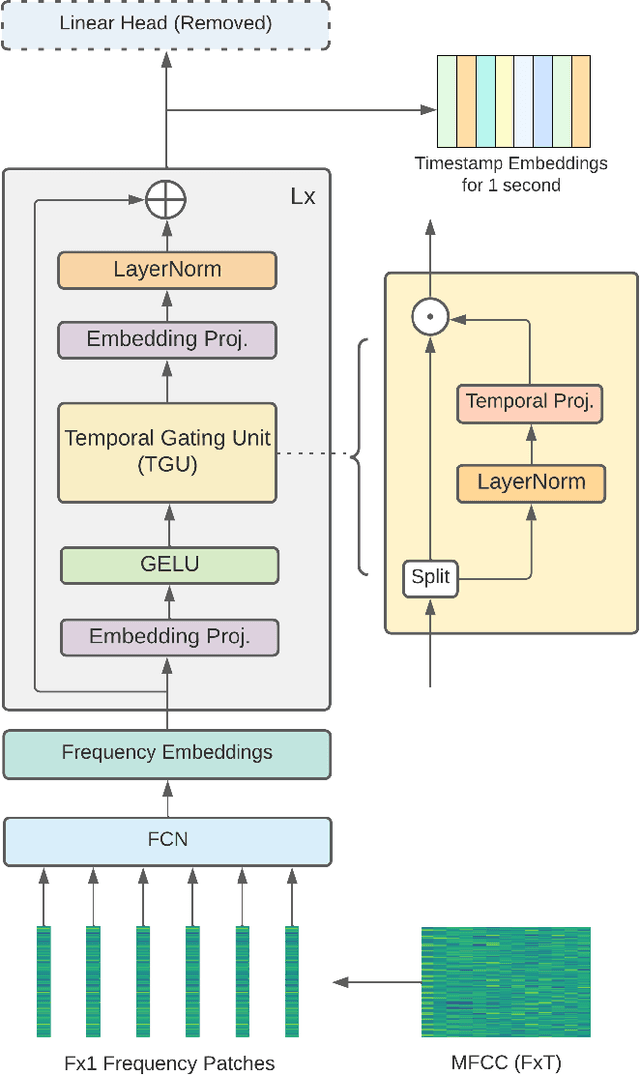
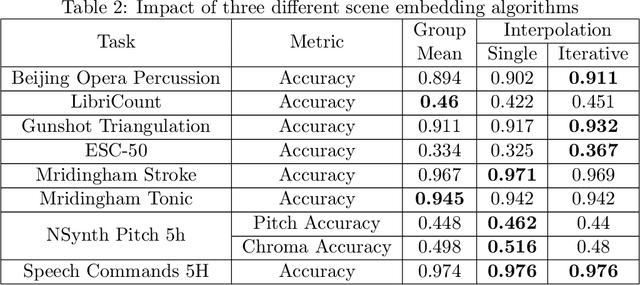
In this paper, we propose an efficient MLP-based approach for learning audio representations, namely timestamp and scene-level audio embeddings. We use an encoder consisting of sequentially stacked gated MLP blocks, which accept 2D MFCCs as inputs. In addition, we also provide a simple temporal interpolation-based algorithm for computing scene-level embeddings from timestamp embeddings. The audio representations generated by our method are evaluated across a diverse set of benchmarks at the Holistic Evaluation of Audio Representations (HEAR) challenge, hosted at the NeurIPS 2021 competition track. We achieved first place on the Speech Commands (full), Speech Commands (5 hours), and the Mridingham Tonic benchmarks. Furthermore, our approach is also the most resource-efficient among all the submitted methods, in terms of both the number of model parameters and the time required to compute embeddings.
Curriculum Pre-training for End-to-End Speech Translation
Apr 21, 2020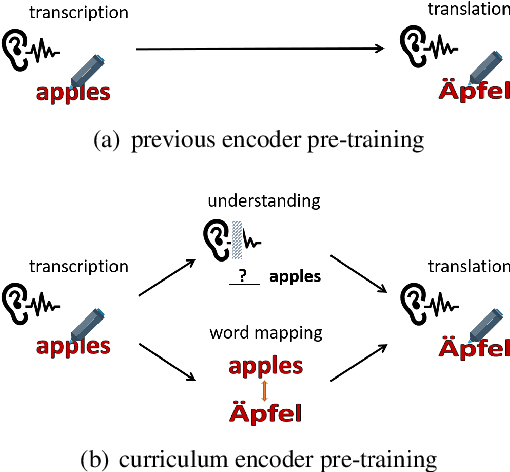
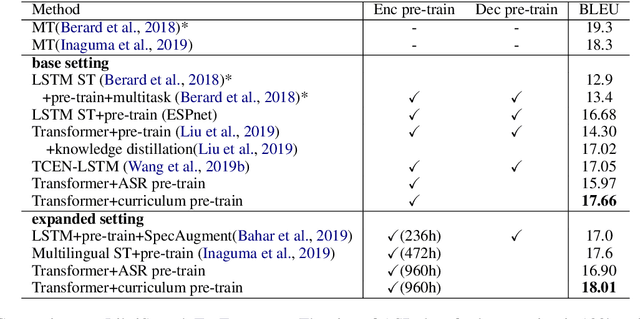
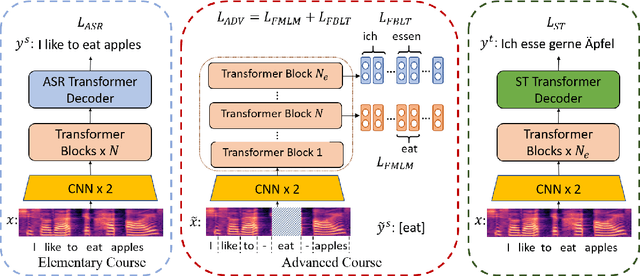
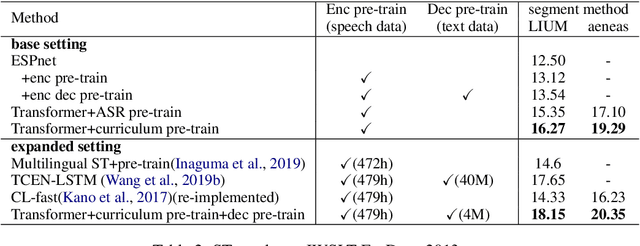
End-to-end speech translation poses a heavy burden on the encoder, because it has to transcribe, understand, and learn cross-lingual semantics simultaneously. To obtain a powerful encoder, traditional methods pre-train it on ASR data to capture speech features. However, we argue that pre-training the encoder only through simple speech recognition is not enough and high-level linguistic knowledge should be considered. Inspired by this, we propose a curriculum pre-training method that includes an elementary course for transcription learning and two advanced courses for understanding the utterance and mapping words in two languages. The difficulty of these courses is gradually increasing. Experiments show that our curriculum pre-training method leads to significant improvements on En-De and En-Fr speech translation benchmarks.
Learning to Mediate Disparities Towards Pragmatic Communication
Mar 25, 2022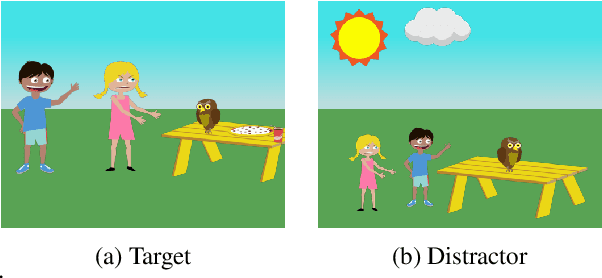

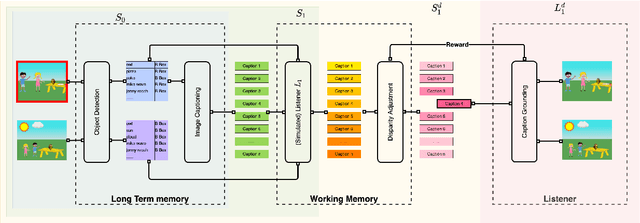
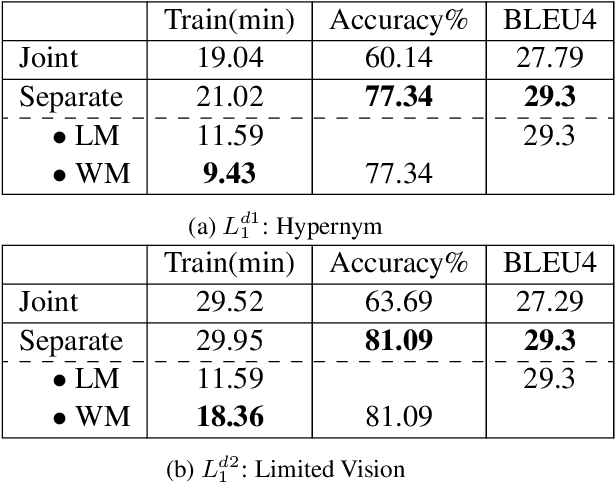
Human communication is a collaborative process. Speakers, on top of conveying their own intent, adjust the content and language expressions by taking the listeners into account, including their knowledge background, personalities, and physical capabilities. Towards building AI agents with similar abilities in language communication, we propose Pragmatic Rational Speaker (PRS), a framework extending Rational Speech Act (RSA). The PRS attempts to learn the speaker-listener disparity and adjust the speech accordingly, by adding a light-weighted disparity adjustment layer into working memory on top of speaker's long-term memory system. By fixing the long-term memory, the PRS only needs to update its working memory to learn and adapt to different types of listeners. To validate our framework, we create a dataset that simulates different types of speaker-listener disparities in the context of referential games. Our empirical results demonstrate that the PRS is able to shift its output towards the language that listener are able to understand, significantly improve the collaborative task outcome.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021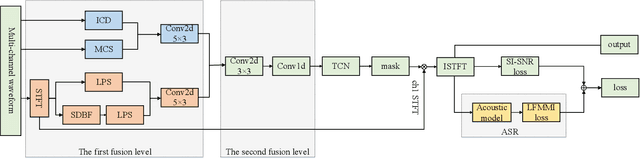
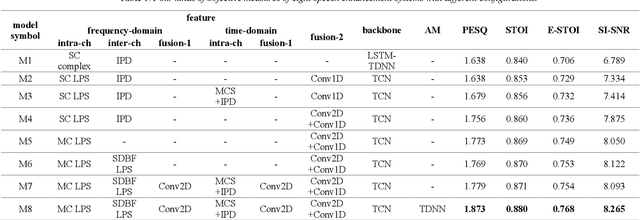
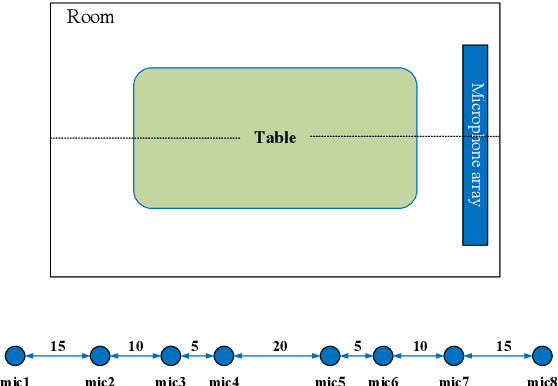

We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.
The USYD-JD Speech Translation System for IWSLT 2021
Jul 24, 2021


This paper describes the University of Sydney& JD's joint submission of the IWSLT 2021 low resource speech translation task. We participated in the Swahili-English direction and got the best scareBLEU (25.3) score among all the participants. Our constrained system is based on a pipeline framework, i.e. ASR and NMT. We trained our models with the officially provided ASR and MT datasets. The ASR system is based on the open-sourced tool Kaldi and this work mainly explores how to make the most of the NMT models. To reduce the punctuation errors generated by the ASR model, we employ our previous work SlotRefine to train a punctuation correction model. To achieve better translation performance, we explored the most recent effective strategies, including back translation, knowledge distillation, multi-feature reranking and transductive finetuning. For model structure, we tried auto-regressive and non-autoregressive models, respectively. In addition, we proposed two novel pre-train approaches, i.e. \textit{de-noising training} and \textit{bidirectional training} to fully exploit the data. Extensive experiments show that adding the above techniques consistently improves the BLEU scores, and the final submission system outperforms the baseline (Transformer ensemble model trained with the original parallel data) by approximately 10.8 BLEU score, achieving the SOTA performance.
HaGRID - HAnd Gesture Recognition Image Dataset
Jun 16, 2022
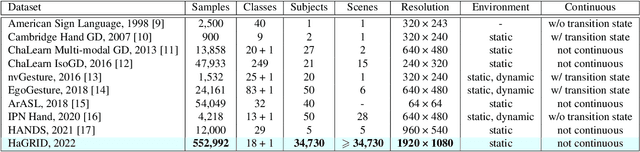
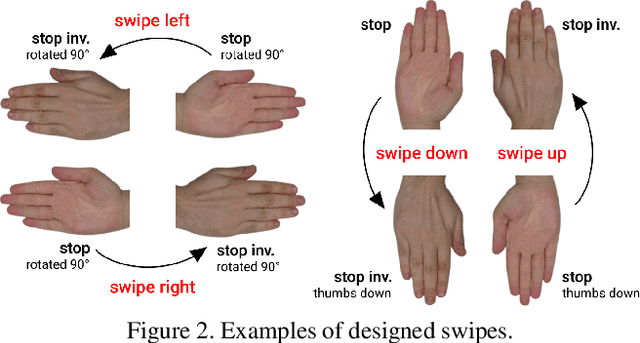
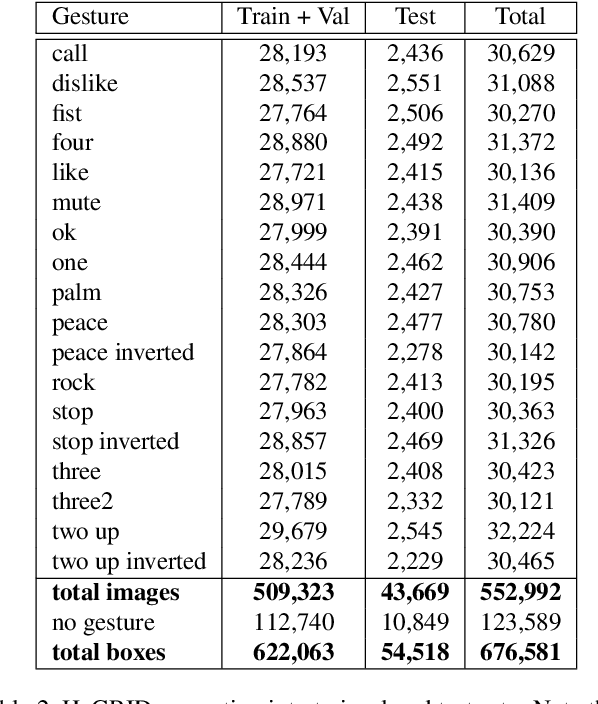
In this paper, we introduce an enormous dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. This dataset contains 552,992 samples divided into 18 classes of gestures. The annotations consist of bounding boxes of hands with gesture labels and markups of leading hands. The proposed dataset allows for building HGR systems, which can be used in video conferencing services, home automation systems, the automotive sector, services for people with speech and hearing impairments, etc. We are especially focused on interaction with devices to manage them. That is why all 18 chosen gestures are functional, familiar to the majority of people, and may be an incentive to take some action. In addition, we used crowdsourcing platforms to collect the dataset and took into account various parameters to ensure data diversity. We describe the challenges of using existing HGR datasets for our task and provide a detailed overview of them. Furthermore, the baselines for the hand detection and gesture classification tasks are proposed.
Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS
Jun 18, 2021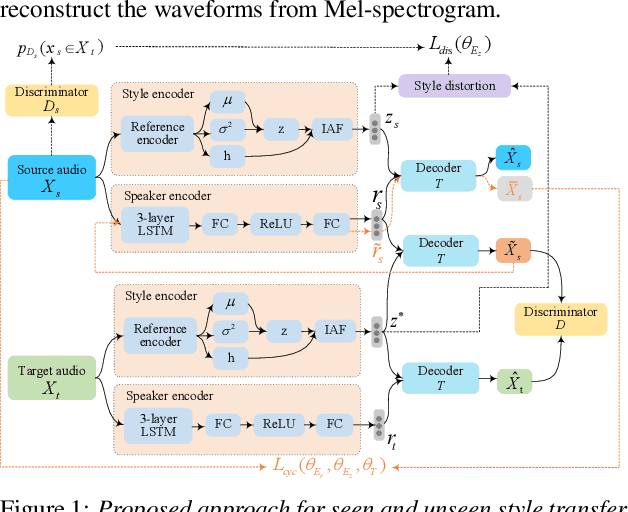
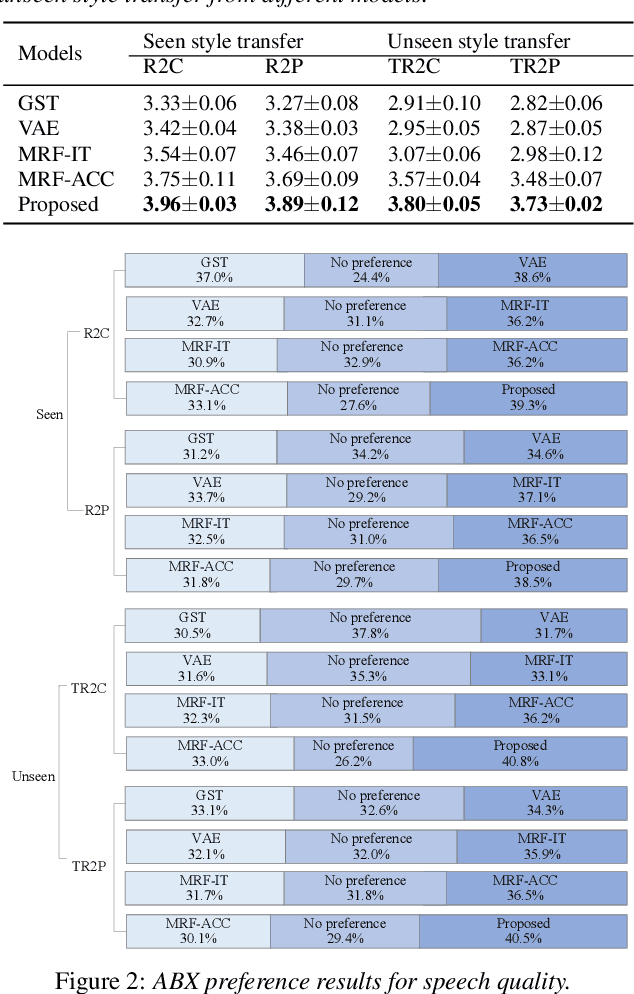
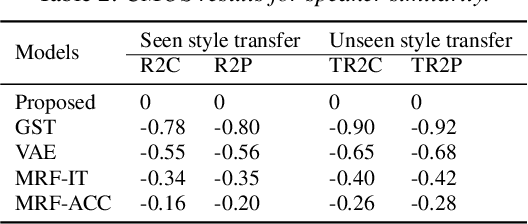

End-to-end neural TTS training has shown improved performance in speech style transfer. However, the improvement is still limited by the training data in both target styles and speakers. Inadequate style transfer performance occurs when the trained TTS tries to transfer the speech to a target style from a new speaker with an unknown, arbitrary style. In this paper, we propose a new approach to style transfer for both seen and unseen styles, with disjoint, multi-style datasets, i.e., datasets of different styles are recorded, each individual style is by one speaker with multiple utterances. To encode the style information, we adopt an inverse autoregressive flow (IAF) structure to improve the variational inference. The whole system is optimized to minimize a weighed sum of four different loss functions: 1) a reconstruction loss to measure the distortions in both source and target reconstructions; 2) an adversarial loss to "fool" a well-trained discriminator; 3) a style distortion loss to measure the expected style loss after the transfer; 4) a cycle consistency loss to preserve the speaker identity of the source after the transfer. Experiments demonstrate, both objectively and subjectively, the effectiveness of the proposed approach for seen and unseen style transfer tasks. The performance of the new approach is better and more robust than those of four baseline systems of the prior art.
Orthros: Non-autoregressive End-to-end Speech Translation with Dual-decoder
Nov 06, 2020
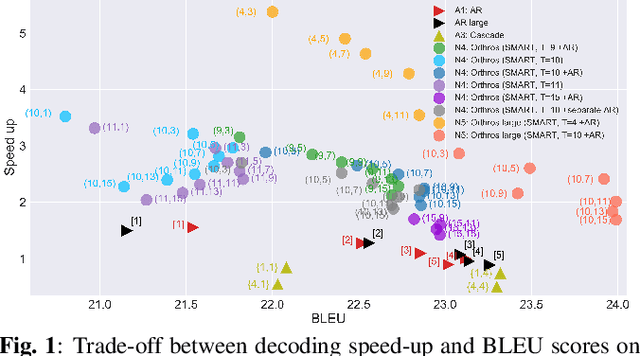
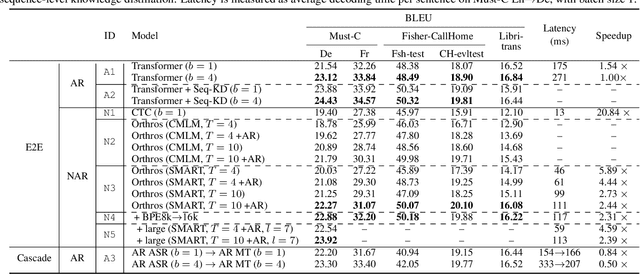
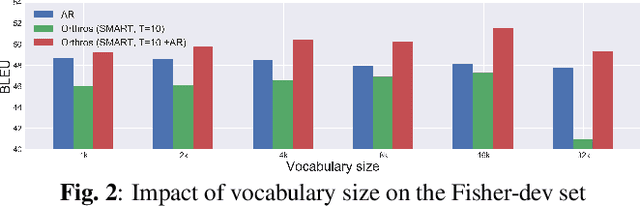
Fast inference speed is an important goal towards real-world deployment of speech translation (ST) systems. End-to-end (E2E) models based on the encoder-decoder architecture are more suitable for this goal than traditional cascaded systems, but their effectiveness regarding decoding speed has not been explored so far. Inspired by recent progress in non-autoregressive (NAR) methods in text-based translation, which generates target tokens in parallel by eliminating conditional dependencies, we study the problem of NAR decoding for E2E-ST. We propose a novel NAR E2E-ST framework, Orthoros, in which both NAR and autoregressive (AR) decoders are jointly trained on the shared speech encoder. The latter is used for selecting better translation among various length candidates generated from the former, which dramatically improves the effectiveness of a large length beam with negligible overhead. We further investigate effective length prediction methods from speech inputs and the impact of vocabulary sizes. Experiments on four benchmarks show the effectiveness of the proposed method in improving inference speed while maintaining competitive translation quality compared to state-of-the-art AR E2E-ST systems.
Spoken Speech Enhancement using EEG
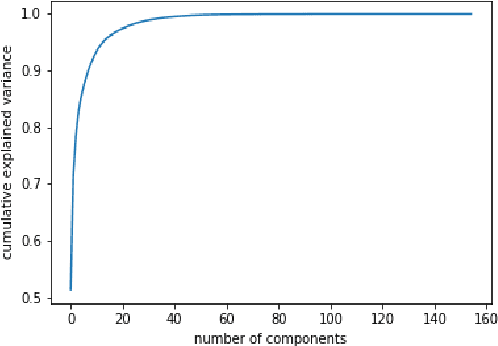
Oct 29, 2019

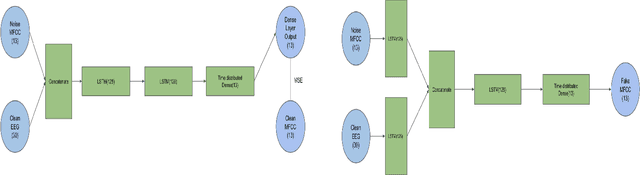
In this paper we demonstrate spoken speech enhancement using electroencephalography (EEG) signals using a generative adversarial network (GAN) based model and Long short-term Memory (LSTM) regression based model. Our results demonstrate that EEG features can be used to clean speech recorded in presence of background noise.