 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Denoising Induction Motor Sounds Using an Autoencoder
Aug 08, 2022
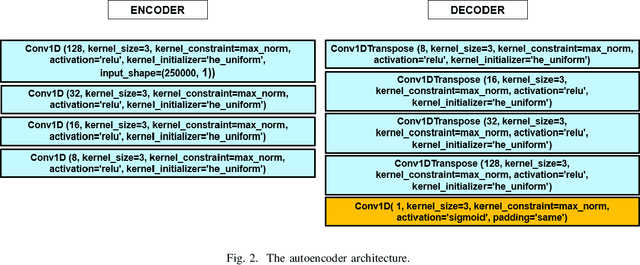
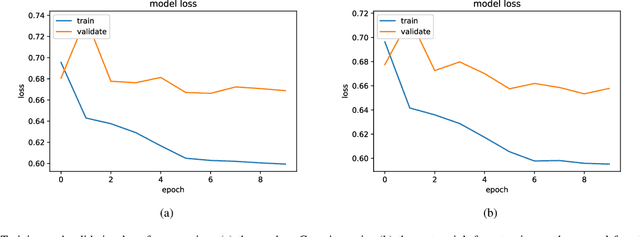
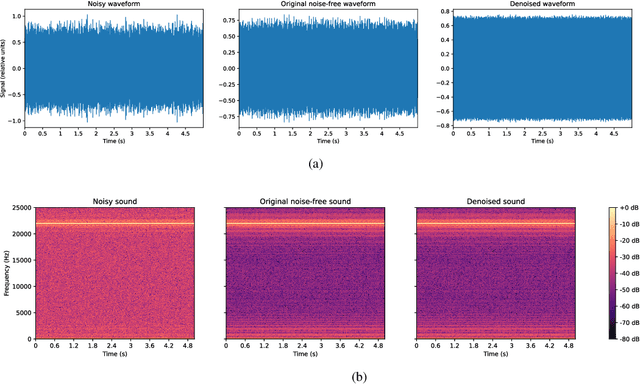
Denoising is the process of removing noise from sound signals while improving the quality and adequacy of the sound signals. Denoising sound has many applications in speech processing, sound events classification, and machine failure detection systems. This paper describes a method for creating an autoencoder to map noisy machine sounds to clean sounds for denoising purposes. There are several types of noise in sounds, for example, environmental noise and generated frequency-dependent noise from signal processing methods. Noise generated by environmental activities is environmental noise. In the factory, environmental noise can be created by vehicles, drilling, people working or talking in the survey area, wind, and flowing water. Those noises appear as spikes in the sound record. In the scope of this paper, we demonstrate the removal of generated noise with Gaussian distribution and the environmental noise with a specific example of the water sink faucet noise from the induction motor sounds. The proposed method was trained and verified on 49 normal function sounds and 197 horizontal misalignment fault sounds from the Machinery Fault Database (MAFAULDA). The mean square error (MSE) was used as the assessment criteria to evaluate the similarity between denoised sounds using the proposed autoencoder and the original sounds in the test set. The MSE is below or equal to 0.14 when denoise both types of noises on 15 testing sounds of the normal function category. The MSE is below or equal to 0.15 when denoising 60 testing sounds on the horizontal misalignment fault category. The low MSE shows that both the generated Gaussian noise and the environmental noise were almost removed from the original sounds with the proposed trained autoencoder.
L3Cube-MahaNLP: Marathi Natural Language Processing Datasets, Models, and Library
May 31, 2022Despite being the third most popular language in India, the Marathi language lacks useful NLP resources. Moreover, popular NLP libraries do not have support for the Marathi language. With L3Cube-MahaNLP, we aim to build resources and a library for Marathi natural language processing. We present datasets and transformer models for supervised tasks like sentiment analysis, named entity recognition, and hate speech detection. We have also published a monolingual Marathi corpus for unsupervised language modeling tasks. Overall we present MahaCorpus, MahaSent, MahaNER, and MahaHate datasets and their corresponding MahaBERT models fine-tuned on these datasets. We aim to move ahead of benchmark datasets and prepare useful resources for Marathi. The resources are available at https://github.com/l3cube-pune/MarathiNLP.
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020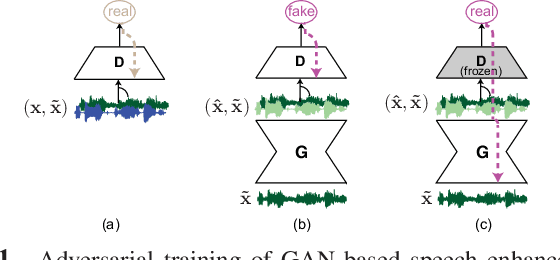
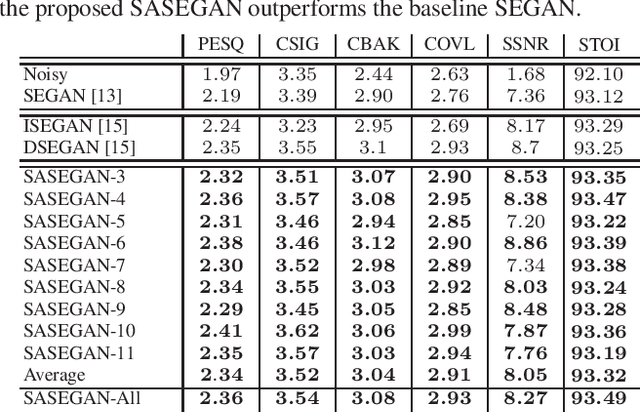
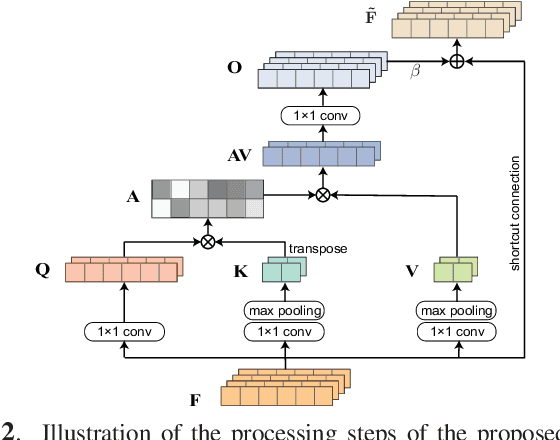
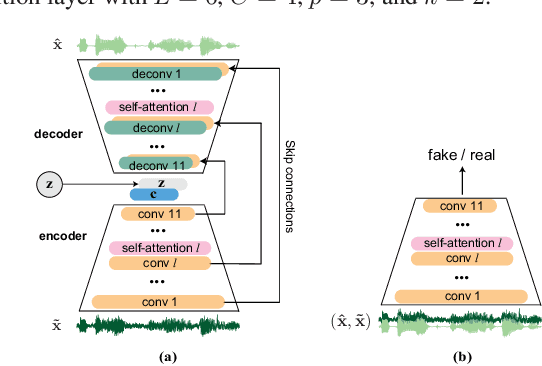
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021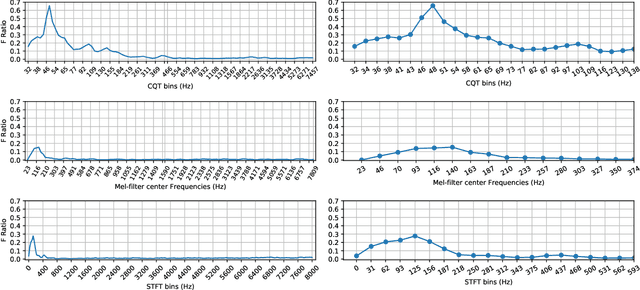
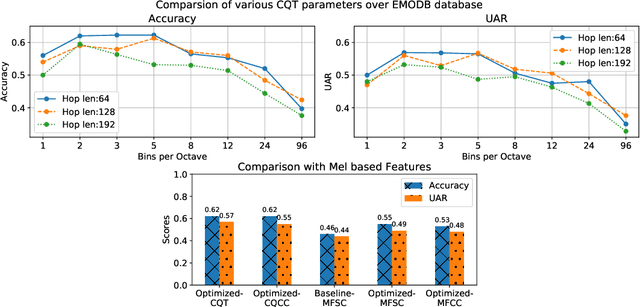

In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.
Role of Artificial Intelligence in Detection of Hateful Speech for Hinglish Data on Social Media
May 11, 2021

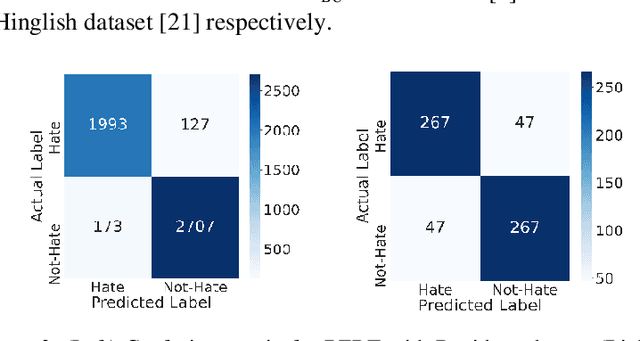

Social networking platforms provide a conduit to disseminate our ideas, views and thoughts and proliferate information. This has led to the amalgamation of English with natively spoken languages. Prevalence of Hindi-English code-mixed data (Hinglish) is on the rise with most of the urban population all over the world. Hate speech detection algorithms deployed by most social networking platforms are unable to filter out offensive and abusive content posted in these code-mixed languages. Thus, the worldwide hate speech detection rate of around 44% drops even more considering the content in Indian colloquial languages and slangs. In this paper, we propose a methodology for efficient detection of unstructured code-mix Hinglish language. Fine-tuning based approaches for Hindi-English code-mixed language are employed by utilizing contextual based embeddings such as ELMo (Embeddings for Language Models), FLAIR, and transformer-based BERT (Bidirectional Encoder Representations from Transformers). Our proposed approach is compared against the pre-existing methods and results are compared for various datasets. Our model outperforms the other methods and frameworks.
Blind Estimation of Room Acoustic Parameters and Speech Transmission Index using MTF-based CNNs
Mar 14, 2021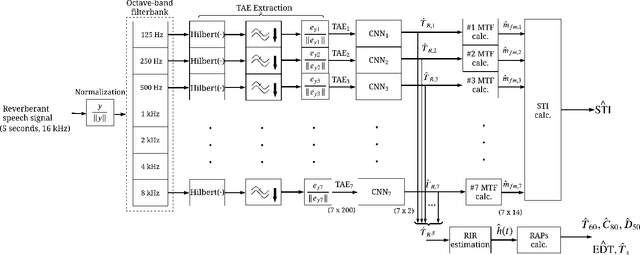
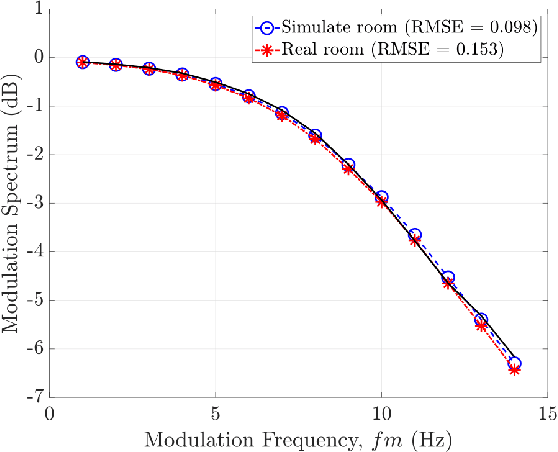
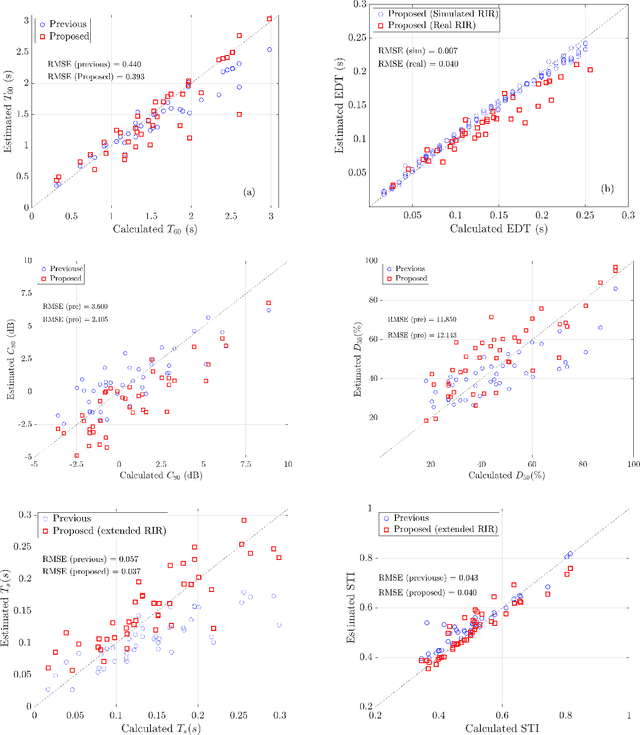
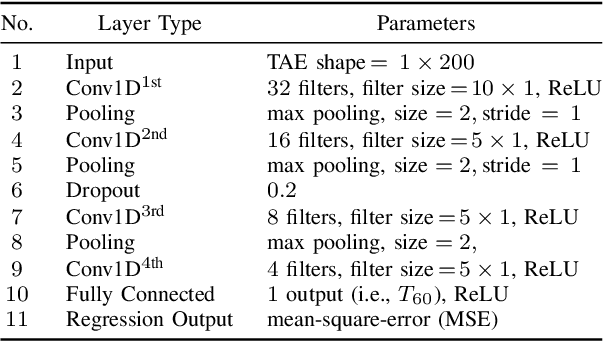
This paper proposes a blind estimation method based on the modulation transfer function and Schroeder model for estimating reverberation time in seven-octave bands. Therefore, the speech transmission index and five room-acoustic parameters can be estimated.
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022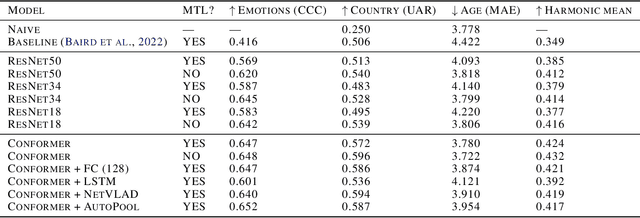
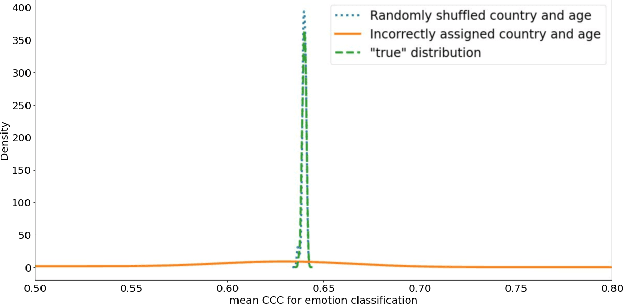
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 05, 2021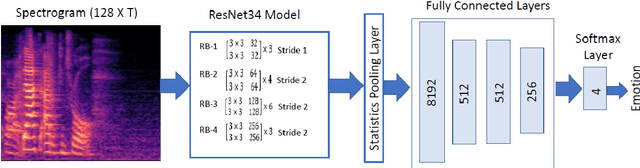
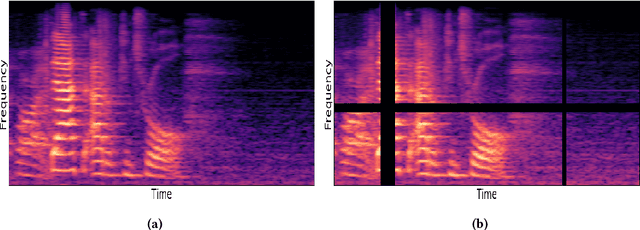
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
Towards A Multi-agent System for Online Hate Speech Detection
May 03, 2021
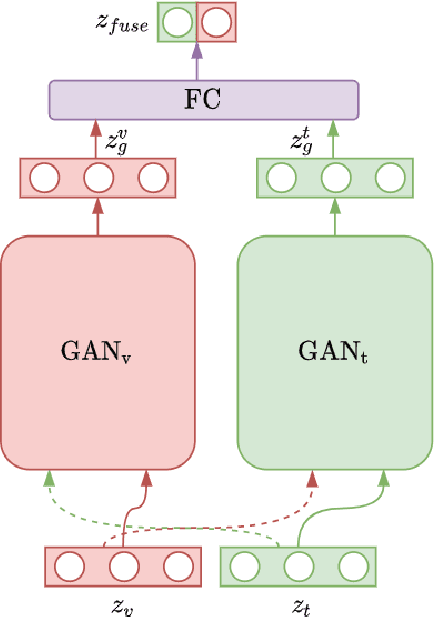
This paper envisions a multi-agent system for detecting the presence of hate speech in online social media platforms such as Twitter and Facebook. We introduce a novel framework employing deep learning techniques to coordinate the channels of textual and im-age processing. Our experimental results aim to demonstrate the effectiveness of our methods for classifying online content, training the proposed neural network model to effectively detect hateful instances in the input. We conclude with a discussion of how our system may be of use to provide recommendations to users who are managing online social networks, showcasing the immense potential of intelligent multi-agent systems towards delivering social good.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022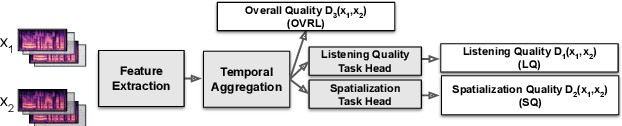

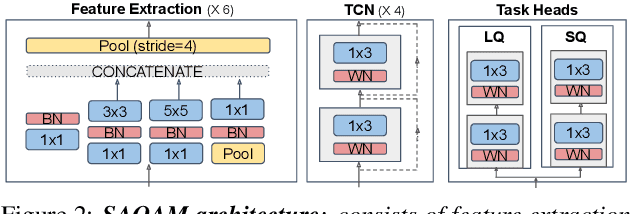

Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.