 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
POSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling
Sep 07, 2021
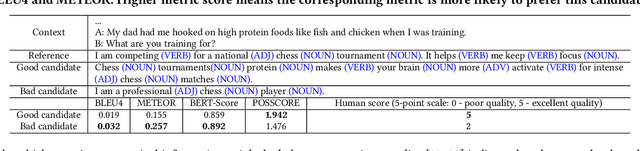
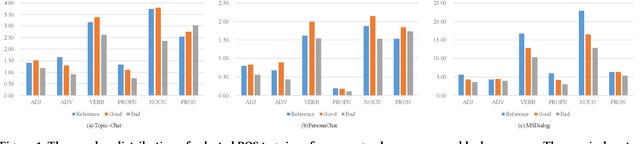
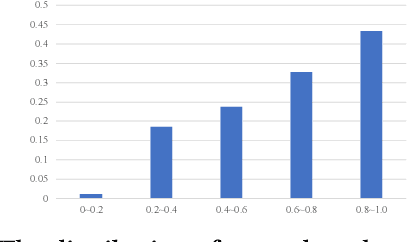
Conversational search systems, such as Google Assistant and Microsoft Cortana, provide a new search paradigm where users are allowed, via natural language dialogues, to communicate with search systems. Evaluating such systems is very challenging since search results are presented in the format of natural language sentences. Given the unlimited number of possible responses, collecting relevance assessments for all the possible responses is infeasible. In this paper, we propose POSSCORE, a simple yet effective automatic evaluation method for conversational search. The proposed embedding-based metric takes the influence of part of speech (POS) of the terms in the response into account. To the best knowledge, our work is the first to systematically demonstrate the importance of incorporating syntactic information, such as POS labels, for conversational search evaluation. Experimental results demonstrate that our metrics can correlate with human preference, achieving significant improvements over state-of-the-art baseline metrics.
HASOCOne@FIRE-HASOC2020: Using BERT and Multilingual BERT models for Hate Speech Detection
Jan 22, 2021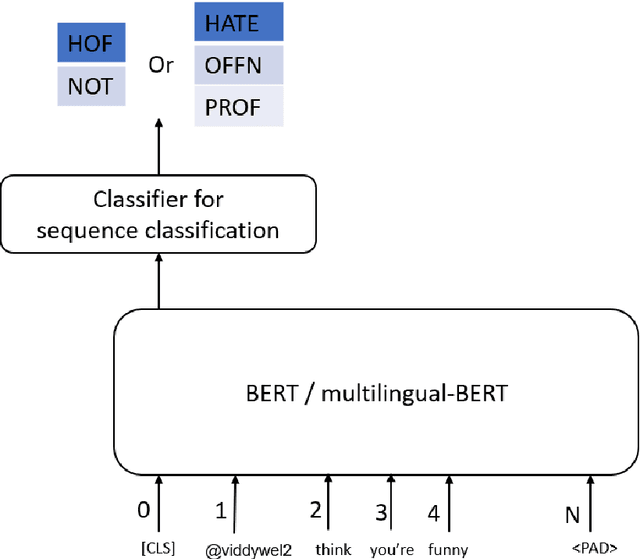
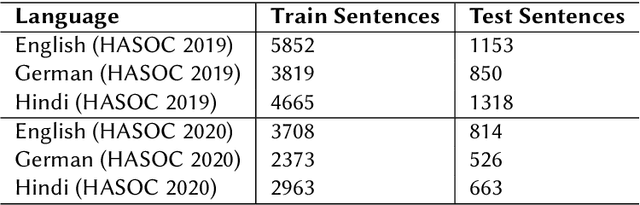
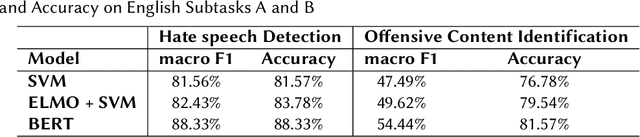
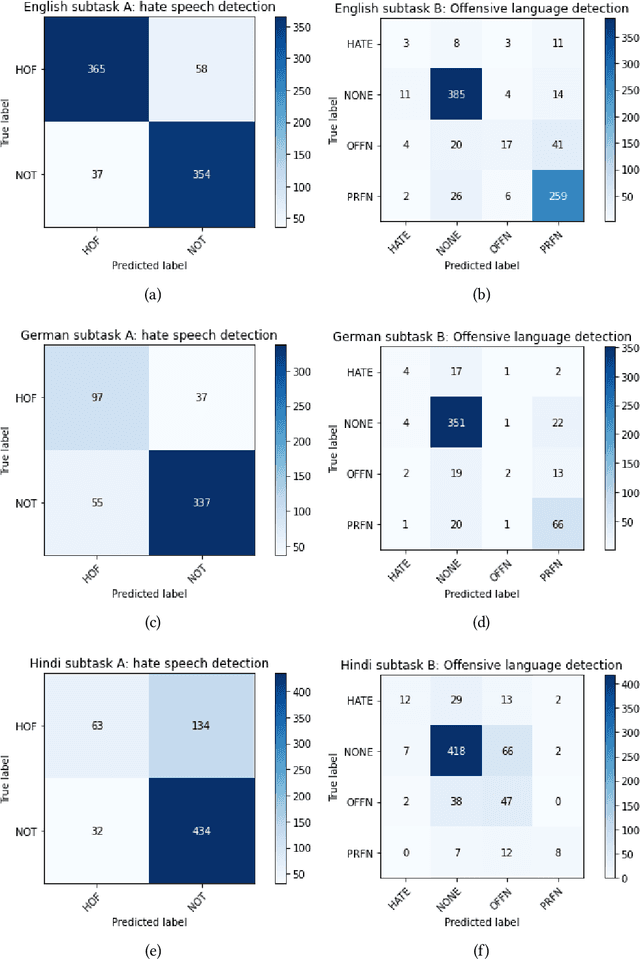
Hateful and Toxic content has become a significant concern in today's world due to an exponential rise in social media. The increase in hate speech and harmful content motivated researchers to dedicate substantial efforts to the challenging direction of hateful content identification. In this task, we propose an approach to automatically classify hate speech and offensive content. We have used the datasets obtained from FIRE 2019 and 2020 shared tasks. We perform experiments by taking advantage of transfer learning models. We observed that the pre-trained BERT model and the multilingual-BERT model gave the best results. The code is made publically available at https://github.com/suman101112/hasoc-fire-2020.
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022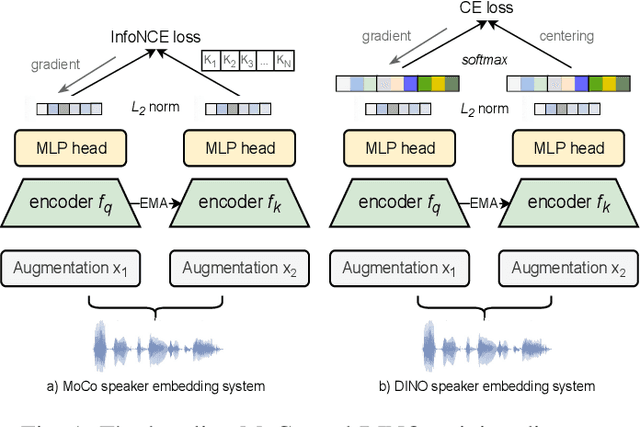
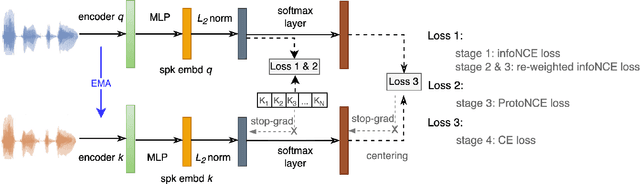
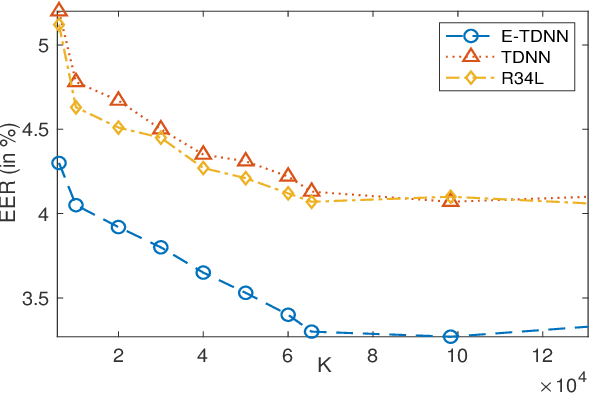
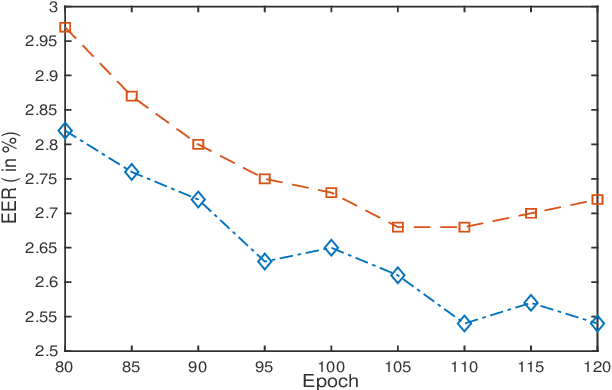
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
Long-Term, in-the-Wild Study of Feedback about Speech Intelligibility for K-12 Students Attending Class via a Telepresence Robot
Aug 24, 2021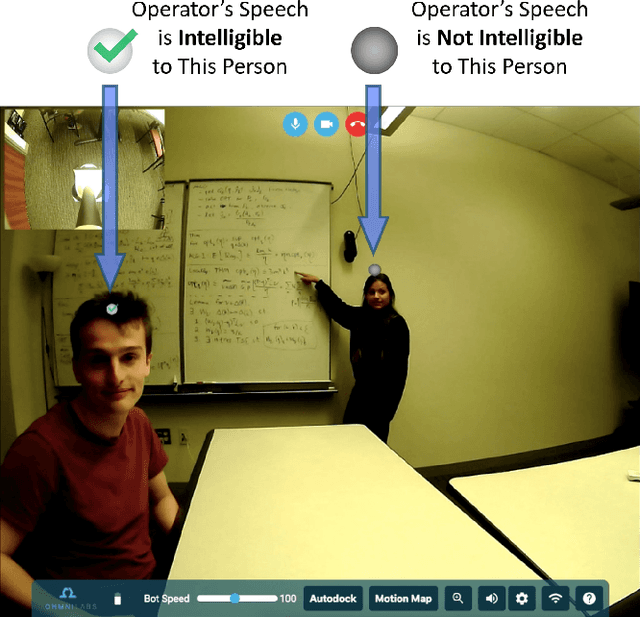

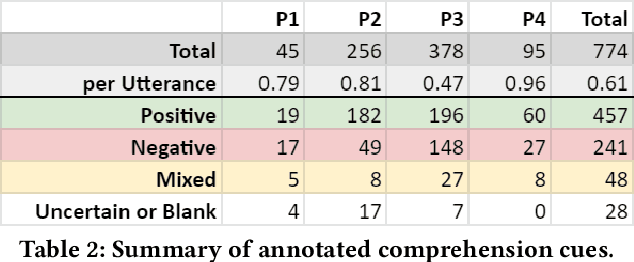
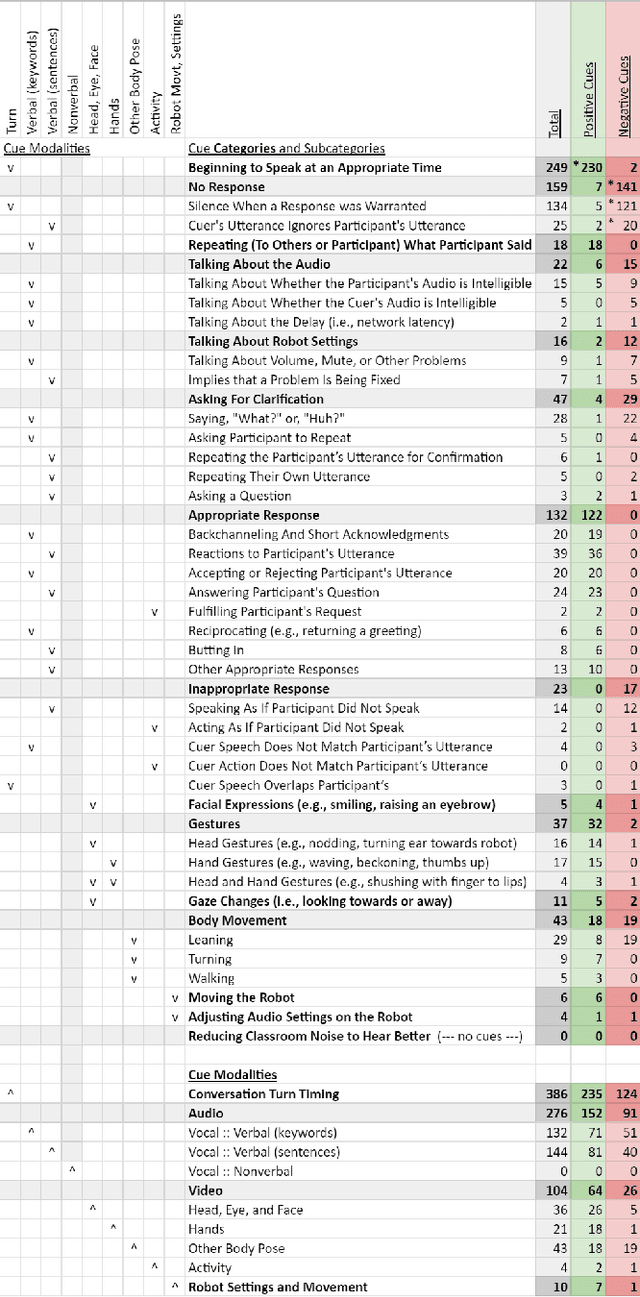
Telepresence robots offer presence, embodiment, and mobility to remote users, making them promising options for homebound K-12 students. It is difficult, however, for robot operators to know how well they are being heard in remote and noisy classroom environments. One solution is to estimate the operator's speech intelligibility to their listeners in order to provide feedback about it to the operator. This work contributes the first evaluation of a speech intelligibility feedback system for homebound K-12 students attending class remotely. In our four long-term, in-the-wild deployments we found that students speak at different volumes instead of adjusting the robot's volume, and that detailed audio calibration and network latency feedback are needed. We also contribute the first findings about the types and frequencies of multimodal comprehension cues given to homebound students by listeners in the classroom. By annotating and categorizing over 700 cues, we found that the most common cue modalities were conversation turn timing and verbal content. Conversation turn timing cues occurred more frequently overall, whereas verbal content cues contained more information and might be the most frequent modality for negative cues. Our work provides recommendations for telepresence systems that could intervene to ensure that remote users are being heard.
An exhaustive variable selection study for linear models of soundscape emotions: rankings and Gibbs analysis
Jul 26, 2022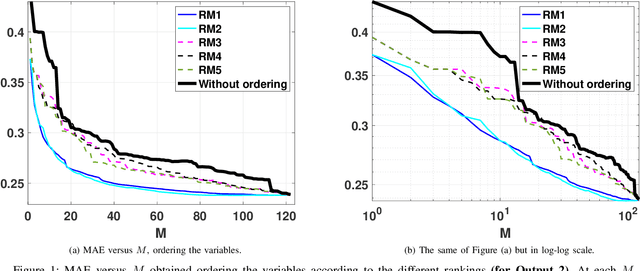
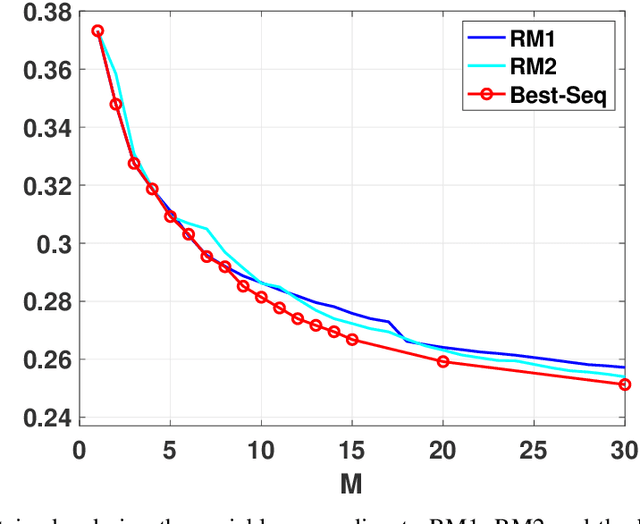
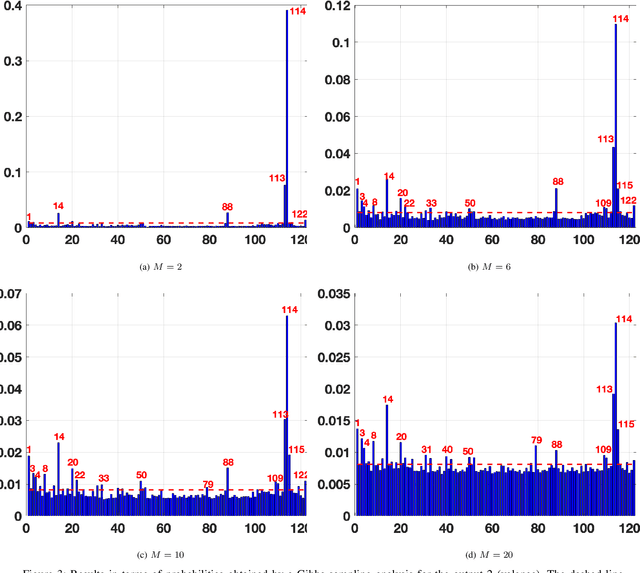

In the last decade, soundscapes have become one of the most active topics in Acoustics, providing a holistic approach to the acoustic environment, which involves human perception and context. Soundscapes-elicited emotions are central and substantially subtle and unnoticed (compared to speech or music). Currently, soundscape emotion recognition is a very active topic in the literature. We provide an exhaustive variable selection study (i.e., a selection of the soundscapes indicators) to a well-known dataset (emo-soundscapes). We consider linear soundscape emotion models for two soundscapes descriptors: arousal and valence. Several ranking schemes and procedures for selecting the number of variables are applied. We have also performed an alternating optimization scheme for obtaining the best sequences keeping fixed a certain number of features. Furthermore, we have designed a novel technique based on Gibbs sampling, which provides a more complete and clear view of the relevance of each variable. Finally, we have also compared our results with the analysis obtained by the classical methods based on p-values. As a result of our study, we suggest two simple and parsimonious linear models of only 7 and 16 variables (within the 122 possible features) for the two outputs (arousal and valence), respectively. The suggested linear models provide very good and competitive performance, with $R^2>0.86$ and $R^2>0.63$ (values obtained after a cross-validation procedure), respectively.
* published in IEEE-ACM Transactions on Audio, Speech and Language Processing
Tight Integrated End-to-End Training for Cascaded Speech Translation
Nov 24, 2020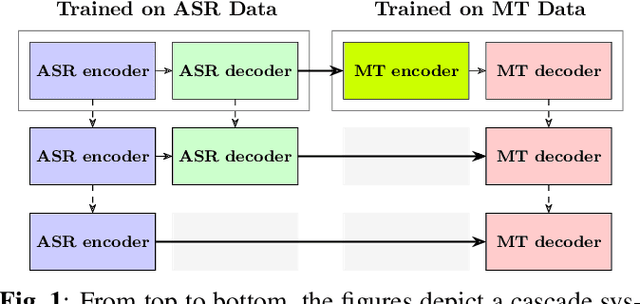
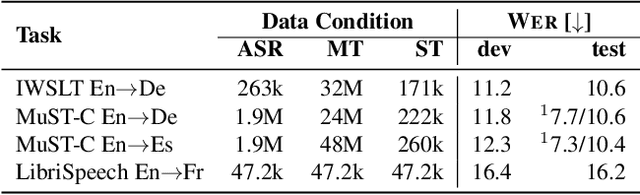
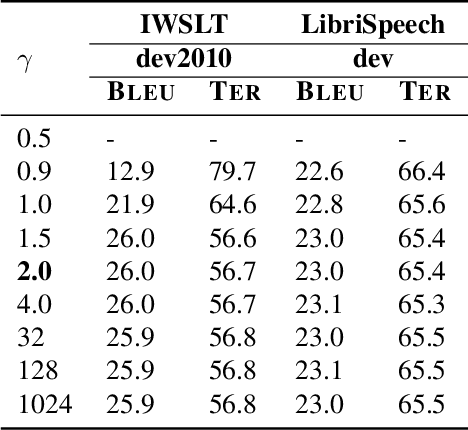
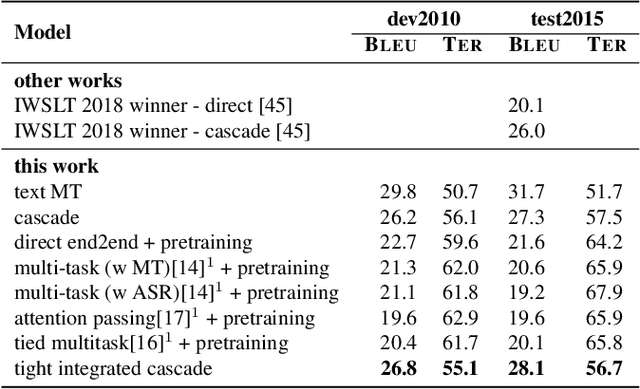
A cascaded speech translation model relies on discrete and non-differentiable transcription, which provides a supervision signal from the source side and helps the transformation between source speech and target text. Such modeling suffers from error propagation between ASR and MT models. Direct speech translation is an alternative method to avoid error propagation; however, its performance is often behind the cascade system. To use an intermediate representation and preserve the end-to-end trainability, previous studies have proposed using two-stage models by passing the hidden vectors of the recognizer into the decoder of the MT model and ignoring the MT encoder. This work explores the feasibility of collapsing the entire cascade components into a single end-to-end trainable model by optimizing all parameters of ASR and MT models jointly without ignoring any learned parameters. It is a tightly integrated method that passes renormalized source word posterior distributions as a soft decision instead of one-hot vectors and enables backpropagation. Therefore, it provides both transcriptions and translations and achieves strong consistency between them. Our experiments on four tasks with different data scenarios show that the model outperforms cascade models up to 1.8% in BLEU and 2.0% in TER and is superior compared to direct models.
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021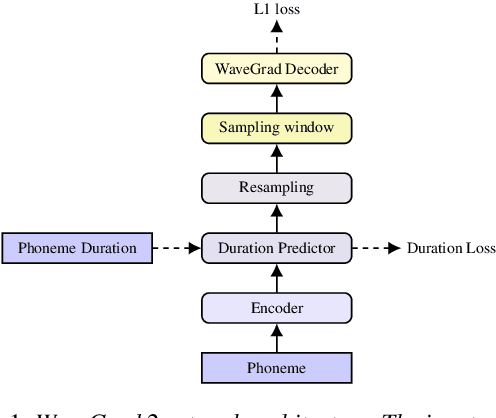
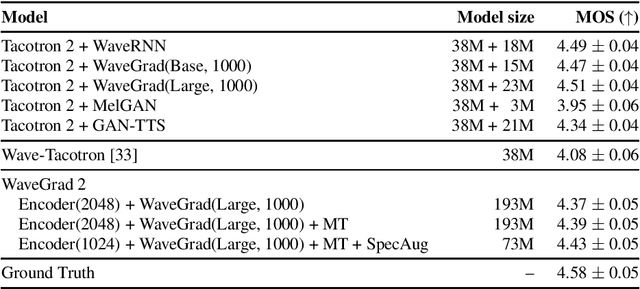
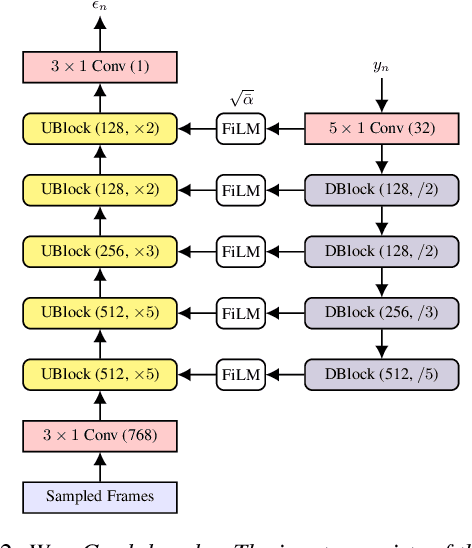

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint
May 10, 2020
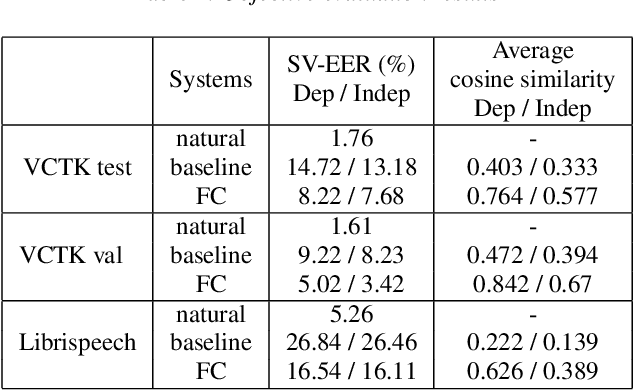
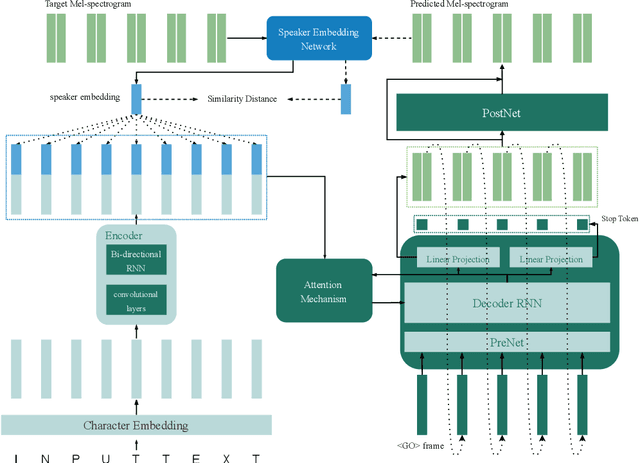
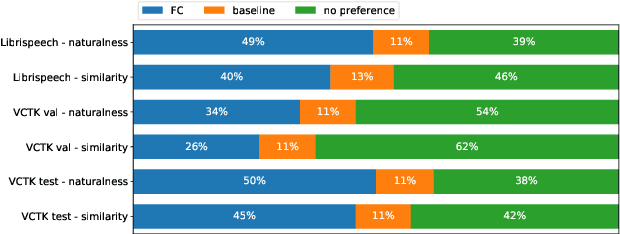
High-fidelity speech can be synthesized by end-to-end text-to-speech models in recent years. However, accessing and controlling speech attributes such as speaker identity, prosody, and emotion in a text-to-speech system remains a challenge. This paper presents a system involving feedback constraint for multispeaker speech synthesis. We manage to enhance the knowledge transfer from the speaker verification to the speech synthesis by engaging the speaker verification network. The constraint is taken by an added loss related to the speaker identity, which is centralized to improve the speaker similarity between the synthesized speech and its natural reference audio. The model is trained and evaluated on publicly available datasets. Experimental results, including visualization on speaker embedding space, show significant improvement in terms of speaker identity cloning in the spectrogram level. Synthesized samples are available online for listening. (https://caizexin.github.io/mlspk-syn-samples/index.html)
The NiuTrans End-to-End Speech Translation System \\for IWSLT 2021 Offline Task
Jul 06, 2021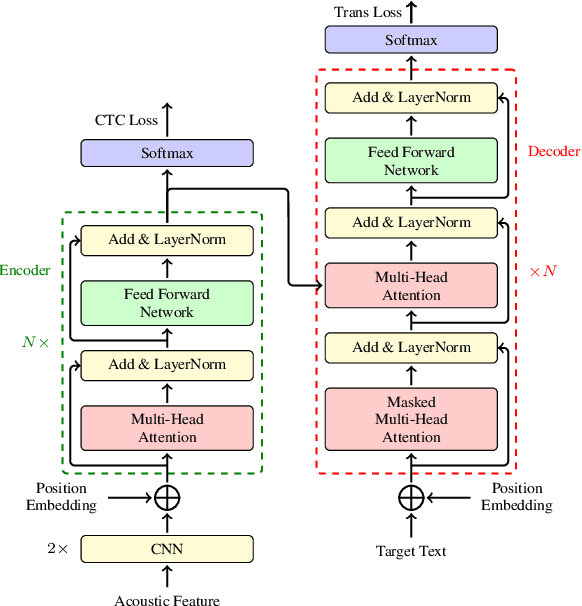
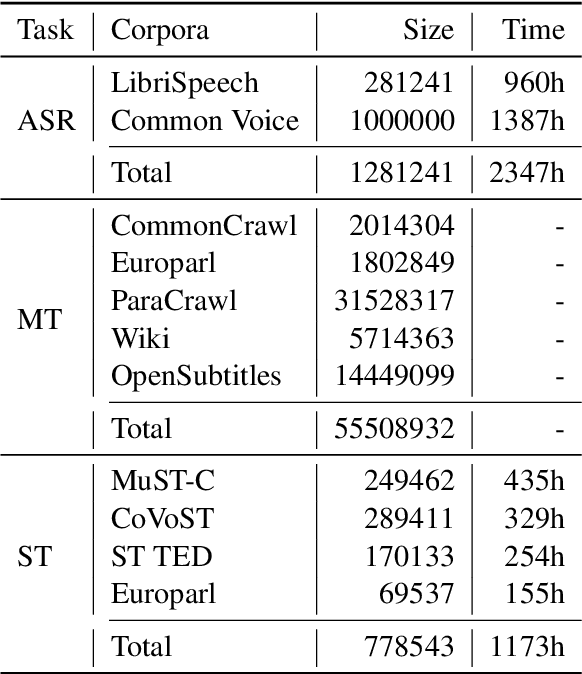
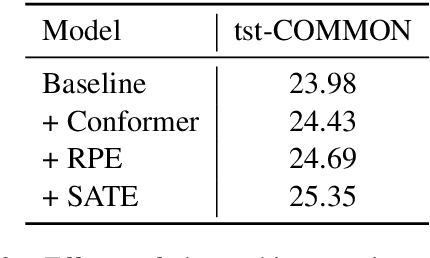
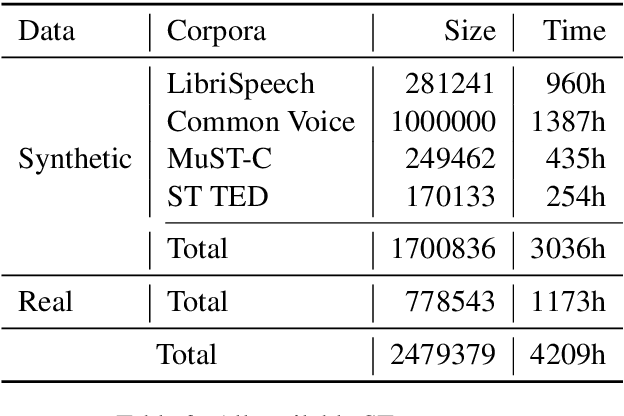
This paper describes the submission of the NiuTrans end-to-end speech translation system for the IWSLT 2021 offline task, which translates from the English audio to German text directly without intermediate transcription. We use the Transformer-based model architecture and enhance it by Conformer, relative position encoding, and stacked acoustic and textual encoding. To augment the training data, the English transcriptions are translated to German translations. Finally, we employ ensemble decoding to integrate the predictions from several models trained with the different datasets. Combining these techniques, we achieve 33.84 BLEU points on the MuST-C En-De test set, which shows the enormous potential of the end-to-end model.
Super-Human Performance in Online Low-latency Recognition of Conversational Speech
Oct 07, 2020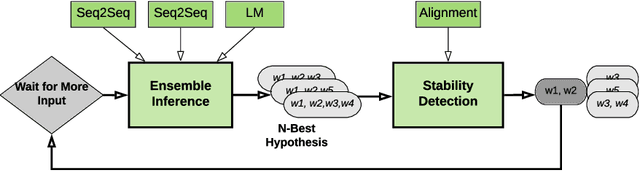
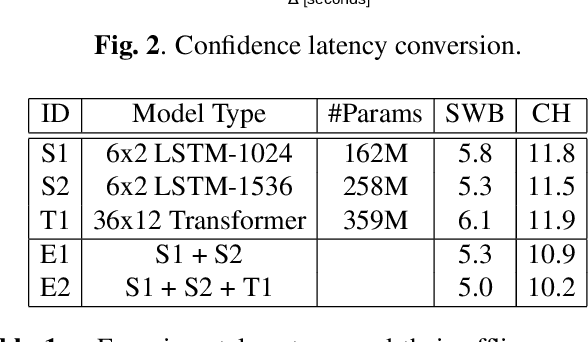
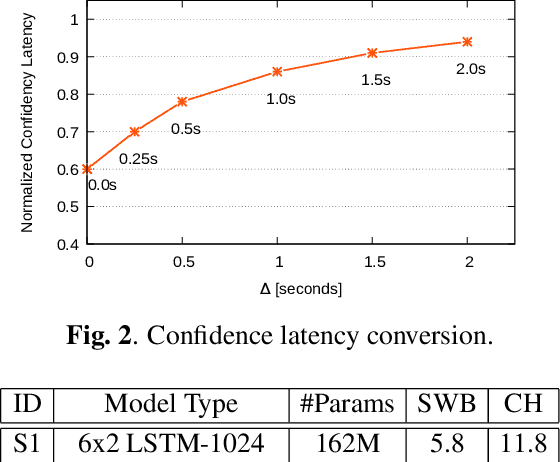
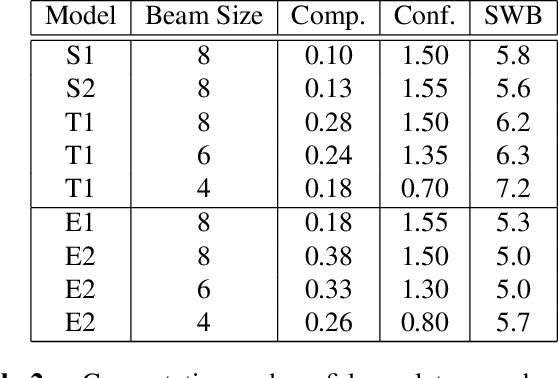
Achieving super-human performance in recognizing human speech has been a goal for several decades, as researchers have worked on increasingly challenging tasks. In the 1990's it was discovered, that conversational speech between two humans turns out to be considerably more difficult than read speech as hesitations, disfluencies, false starts and sloppy articulation complicate acoustic processing and require robust handling of acoustic, lexical and language context, jointly. Early attempts even with statistical models could only reach error rates in excess of 50% and far from human performance (WER of around 5.5%). Neural hybrid models and recent attention based encoder-decoder models have considerably improved performance as such context can now be learned in an integral fashion. However processing such contexts requires presentation of an entire utterance and thus introduces unwanted delays before a recognition result can be output. In this paper, we address performance as well as latency. We present results for a system that is able to achieve super-human performance (at a WER or 5.0%, over the Switchboard conversational benchmark) at a latency of only 1 second behind a speaker's speech. The system uses attention based encoder-decoder networks, but can also be configured to use ensembles with Transformer based models at low latency.